We're already tracking which variables are hoisted context variables, so if we see a mutation of a frozen value we can emit a custom error message to help users identify the problem.
AnalyzeFunctions had logic to reset the mutable ranges of context variables after visiting inner function expressions. However, there was a bug in that logic: InferReactiveScopeVariables makes all the identifiers in a scope point to the same mutable range instance. That meant that it was possible for a later function expression to indirectly cause an earlier function expressions' context variables to get a non-zero mutable range.
The fix is to not just reset start/end of context var ranges, but assign a new range instance. Thanks for the help on debugging, @mofeiz!
Squashed, review-friendly version of the stack from
https://github.com/facebook/react/pull/33488.
This is new version of our mutability and inference model, designed to
replace the core algorithm for determining the sets of instructions
involved in constructing a given value or set of values. The new model
replaces InferReferenceEffects, InferMutableRanges (and all of its
subcomponents), and parts of AnalyzeFunctions. The new model does not
use per-Place effect values, but in order to make this drop-in the end
_result_ of the inference adds these per-Place effects.
I'll write up a larger document on the model, first i'm doing some
housekeeping to rebase the PR.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/33494).
* #33571
* #33558
* #33547
* #33543
* #33533
* #33532
* #33530
* #33526
* #33522
* #33518
* #33514
* #33513
* #33512
* #33504
* #33500
* #33497
* #33496
* #33495
* __->__ #33494
* #33572
This was really meant to be there from the beginning. A `cache()`:ed
entry has a life time. On the server this ends when the render finishes.
On the client this ends when the cache of that scope gets refreshed.
When a cache is no longer needed, it should be possible to abort any
outstanding network requests or other resources. That's what
`cacheSignal()` gives you. It returns an `AbortSignal` which aborts when
the cache lifetime is done based on the same execution scope as a
`cache()`ed function - i.e. `AsyncLocalStorage` on the server or the
render scope on the client.
```js
import {cacheSignal} from 'react';
async function Component() {
await fetch(url, { signal: cacheSignal() });
}
```
For `fetch` in particular, a patch should really just do this
automatically for you. But it's useful for other resources like database
connections.
Another reason it's useful to have a `cacheSignal()` is to ignore any
errors that might have triggered from the act of being aborted. This is
just a general useful JavaScript pattern if you have access to a signal:
```js
async function getData(id, signal) {
try {
await queryDatabase(id, { signal });
} catch (x) {
if (!signal.aborted) {
logError(x); // only log if it's a real error and not due to cancellation
}
return null;
}
}
```
This just gets you a convenient way to get to it without drilling
through so a more idiomatic code in React might look something like.
```js
import {cacheSignal} from "react";
async function getData(id) {
try {
await queryDatabase(id);
} catch (x) {
if (!cacheSignal()?.aborted) {
logError(x);
}
return null;
}
}
```
If it's called outside of a React render, we normally treat any cached
functions as uncached. They're not an error call. They can still load
data. It's just not cached. This is not like an aborted signal because
then you couldn't issue any requests. It's also not like an infinite
abort signal because it's not actually cached forever. Therefore,
`cacheSignal()` returns `null` when called outside of a React render
scope.
Notably the `signal` option passed to `renderToReadableStream` in both
SSR (Fizz) and RSC (Flight Server) is not the same instance that comes
out of `cacheSignal()`. If you abort the `signal` passed in, then the
`cacheSignal()` is also aborted with the same reason. However, the
`cacheSignal()` can also get aborted if the render completes
successfully or fatally errors during render - allowing any outstanding
work that wasn't used to clean up. In the future we might also expand on
this to give different
[`TaskSignal`](https://developer.mozilla.org/en-US/docs/Web/API/TaskSignal)
to different scopes to pass different render or network priorities.
On the client version of `"react"` this exposes a noop (both for
Fiber/Fizz) due to `disableClientCache` flag but it's exposed so that
you can write shared code.
As discussed in chat, this is a simple fix to stop introducing labels
inside expressions.
The useMemo-with-optional test was added in
d70b2c2c4e
and crashes for the same reason- an unexpected label as a value block
terminal.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/33548).
* __->__ #33548
* #33546
Previously the experimental workflow relied on the canary one running
first to avoid race conditions. However, I didn't account for the fact
that the canary one can now be skipped.
It may be useful at times to publish only specific packages as an
experimental tag. For example, if we need to cherry pick some fixes for
an old release, we can first do so by creating that as an experimental
release just for that package to allow for quick testing by downstream
projects.
Similar to .github/workflows/runtime_releases_from_npm_manual.yml I
added three options (`dry`, `only_packages`, `skip_packages`) to
`runtime_prereleases.yml` which both the manual and nightly workflows
reuse. I also added a discord notification when the manual workflow is
run.
## Summary
The devtools Components tab's component tree view currently has a
behavior where the indentation of each level of the tree scales based on
the available width of the view. If the view is narrow or component
names are long, all indentation showing the hierarchy of the tree scales
down with the view width until there is no indentation at all. This
makes it impossible to see the nesting of the tree, making the tree view
much less useful. With long component names and deep hierarchies this
issue is particularly egregious. For comparison, the Chrome Dev Tools
Elements panel uses a fixed indentation size, so it doesn't suffer from
this issue.
This PR adds a minimum pixel value for the indentation width, so that
even when the window is narrow some indentation will still be visible,
maintaining the visual representation of the component tree hierarchy.
Alternatively, we could match the behavior of the Chrome Dev Tools and
just use a constant indentation width.
## How did you test this change?
- tests (yarn test-build-devtools)
- tested in browser:
- added an alternate left/right split pane layout to
react-devtools-shell to test with
(https://github.com/facebook/react/pull/33516)
- tested resizing the tree view in different layout modes
### before this change:
https://github.com/user-attachments/assets/470991f1-dc05-473f-a2cb-4f7333f6bae4
with a long component name:
https://github.com/user-attachments/assets/1568fc64-c7d7-4659-bfb1-9bfc9592fb9d
### after this change:
https://github.com/user-attachments/assets/f60bd7fc-97f6-4680-9656-f0db3d155411
with a long component name:
https://github.com/user-attachments/assets/6ac3f58c-42ea-4c5a-9a52-c3b397f37b45
## Summary
This PR adds a 'Layout' selector to the devtools shell main example, as
well as a resizable split pane, allowing more realistic testing of how
the devtools behaves when used in a vertical or horizontal layout and at
different sizes (e.g. when resizing the Chrome Dev Tools pane).
## How did you test this change?
https://github.com/user-attachments/assets/81179413-7b46-47a9-bc52-4f7ec414e8be
This bug was reported via our wg and appears to only affect values
created as a ref.
Currently, postfix operators used in a callback gets compiled to:
```js
modalId.current = modalId.current + 1; // 1
const id = modalId.current; // 1
return id;
```
which is semantically incorrect. The postfix increment operator should
return the value before incrementing. In other words something like this
should have been compiled instead:
```js
const id = modalId.current; // 0
modalId.current = modalId.current + 1; // 1
return id;
```
This bug does not trigger when the incremented value is a plain
primitive, instead there is a TODO bailout.
Stacked on #33482.
There's a flaw with getting information from the execution context of
the ping. For the soft-deprecated "throw a promise" technique, this is a
bit unreliable because you could in theory throw the same one multiple
times. Similarly, a more fundamental flaw with that API is that it
doesn't allow for tracking the information of Promises that are already
synchronously able to resolve.
This stops tracking the async debug info in the case of throwing a
Promise and only when you render a Promise. That means some loss of data
but we should just warn for throwing a Promise anyway.
Instead, this also adds support for tracking `use()`d thenables and
forwarding `_debugInfo` from then. This is done by extracting the info
from the Promise after the fact instead of in the resolve so that it
only happens once at the end after the pings are done.
This also supports passing the same Promise in multiple places and
tracking the debug info at each location, even if it was already
instrumented with a synchronous value by the time of the second use.
Previously you weren't guaranteed to have only advancing time entries,
you could jump back in time, but now it omits unnecessary duplicates and
clamps automatically if you emit a previous time entry to enforce
forwards order only.
The reason I didn't do this originally is because `await` can jump in
the order because we're trying to encode a graph into a flat timeline
for simplicity of the protocol and consumers.
```js
async function a() {
await fetch1();
await fetch2();
}
async function b() {
await fetch3();
}
async function foo() {
const p = a();
await b();
return p;
}
```
This can effectively create two parallel sequences:
```
--1.................----2.......--
------3......---------------------
```
This can now be flattened to either:
```
--1.................3---2.......--
```
Or:
```
------3......1......----2.......--
```
Depending on which one we visit first. Regardless, information is lost.
I'd say that the second one is worse encoding of this scenario because
it pretends that we weren't waiting for part of the timespan that we
were. To solve this I think we should probably make `emitAsyncSequence`
create a temporary flat list and then sort it by start time before
emitting.
Although we weren't actually blocked since there was some CPU time that
was able to proceed to get to 3. So maybe the second one is actually
better. If we wanted that consistently we'd have to figure out what the
intersection was.
---------
Co-authored-by: Hendrik Liebau <mail@hendrik-liebau.de>
Includes #31412.
The issue is that `pushTreeFork` stores some global state when reconcile
children. This gets popped by `popTreeContext` in `completeWork`.
Normally `completeWork` returns its own `Fiber` again if it wants to do
a second pass which will call `pushTreeFork` again in the next pass.
However, `SuspenseList` doesn't return itself, it returns the next child
to work on.
The fix is to keep track of the count and push it again it when we
return the next child to attempt.
There are still some outstanding issues with hydration. Like the
backwards test still has the wrong behavior in it because it hydrates
backwards and so it picks up the DOM nodes in reverse order.
`tail="hidden"` also doesn't work correctly.
There's also another issue with `useId` and `AsyncIterable` in
SuspenseList when there's an unknown number of children. We don't
support those showing one at a time yet though so it's not an issue yet.
To fix it we need to add variable total count to the `useId` algorithm.
E.g. by falling back to varint encoding.
---------
Co-authored-by: Rick Hanlon <rickhanlonii@fb.com>
Co-authored-by: Ricky <rickhanlonii@gmail.com>
This adds some I/O to go get the third party thing to test how it
overlaps.
With #33482, this is what it looks like. The await gets cut off when the
third party component starts rendering. I.e. after the latency to start.
<img width="735" alt="Screenshot 2025-06-08 at 5 42 46 PM"
src="https://github.com/user-attachments/assets/f68d9a84-05a1-4125-b3f0-8f3e4eaaa5c1"
/>
This doesn't fully simulate everything because it should actually also
simulate each chunk of the stream coming back too. We could wrap the
ReadableStream to simulate that. In that scenario, it would probably get
some awaits on the chunks at the end too.
## Summary
In react-native props that are passed as function get converted to a
boolean (`true`). This is the default pattern for event handlers in
react-native.
However, there are reasons for why you might want to opt-out of this
behavior, and instead, pass along the actual function as the prop.
Right now, there is no way to do this, and props that are functions
always get set to `true`.
The `ViewConfig` attributes already have the API for a `process`
function. I simply moved the check for the process function up, so if a
ViewConfig's prop attribute configured a process function this is always
called first.
This provides an API to opt out of the default behavior.
This is the accompanied PR for react-native:
- https://github.com/facebook/react-native/pull/48777
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
I modified the code manually in a template react-native app and
confirmed its working. This is a code path you only need in very special
cases, thus it's a bit hard to provide a test for this. I recorded a
video where you can see that the changes are active and the prop is
being passed as native value.
For this I created a custom native component with a view config that
looked like this:
```js
const viewConfig = {
uiViewClassName: 'CustomView',
bubblingEventTypes: {},
directEventTypes: {},
validAttributes: {
nativeProp: {
process: (nativeProp) => {
// Identity function that simply returns the prop function callback
// to opt out of this prop being set to `true` as its a function
return nativeProp
},
},
},
}
```
https://github.com/user-attachments/assets/493534b2-a508-4142-a760-0b1b24419e19
Additionally I made sure that this doesn't conflict with any existing
view configs in react native. In general, this shouldn't be a breaking
change, as for existing view configs it didn't made a difference if you
simply set `myProp: true` or `myProp: { process: () => {...} }` because
as soon as it was detected that the prop is a function the config
wouldn't be used (which is what this PR fixes).
Probably everyone, including the react-native core components use
`myProp: true` for callback props, so this change should be fine.
Technically the async call graph spans basically all the way back to the
start of the app potentially, but we don't want to include everything.
Similarly we don't want to include everything from previous components
in every child component. So we need some heuristics for filtering out
data.
We roughly want to be able to inspect is what might contribute to a
Suspense loading sequence even if it didn't this time e.g. due to a race
condition.
One flaw with the previous approach was that awaiting a cached promise
in a sibling that happened to finish after another sibling would be
excluded. However, in a different race condition that might end up being
used so I wanted to include an empty "await" in that scenario to have
some association from that component.
However, for data that resolved fully before the request even started,
it's a little different. This can be things that are part of the start
up sequence of the app or externally cached data. We decided that this
should be excluded because it doesn't contribute to the loading sequence
in the expected scenario. I.e. if it's cached. Things that end up being
cache misses would still be included. If you want to test externally
cached data misses, then it's up to you or the framework to simulate
those. E.g. by dropping the cache. This also helps free up some noise
since static / cached data can be excluded in visualizations.
I also apply this principle to forwarding debug info. If you reuse a
cached RSC payload, then the Server Component render time and its awaits
gets clamped to the caller as if it has zero render/await time. The I/O
entry is still back dated but if it was fully resolved before we started
then it's completely excluded.
I noticed that the ThirdPartyComponent in the fixture was showing the
wrong stack and the `"use third-party"` is in the wrong location.
<img width="628" alt="Screenshot 2025-06-06 at 11 22 11 PM"
src="https://github.com/user-attachments/assets/f0013380-d79e-4765-b371-87fd61b3056b"
/>
When creating the initial JSX inside the third party server, we should
make sure that it has no owner. In a real cross-server environment you
get this by default by just executing in different context. But since
the fixture example is inside the same AsyncLocalStorage as the parent
it already has an owner which gets transferred. So we should make sure
that were we create the JSX has no owner to simulate this.
When we then parse a null owner on the receiving side, we replace its
owner/stack with the owner/stack of the call to `createFrom...` to
connect them. This worked fine with only two environments. The bug was
that when we did this and then transferred the result to a third
environment we took the original parsed stack trace. We should instead
parse a new one from the replaced stack in the current environment.
The second bug was that the `"use third-party"` badge ends up in the
wrong place when we do this kind of thing. Because the stack of the
thing entering the new environment is the call to `createFrom...` which
is in the old environment even though the component itself executes in
the new environment. So to see if there's a change we should be
comparing the current environment of the task to the owner's environment
instead of the next environment after the task.
After:
<img width="494" alt="Screenshot 2025-06-07 at 1 13 28 AM"
src="https://github.com/user-attachments/assets/e2e870ba-f125-4526-a853-bd29f164cf09"
/>
This effectively lets us consume Web Streams in a Node build. In fact
the Node entry point is now just adding Node stream APIs.
For the client, this is simple because the configs are not actually
stream type specific. The server is a little trickier.
Reverts #33457, #33456 and #33442.
There are too many issues with wrappers, lazy init, stateful modules,
duplicate instantiation of async_hooks and duplication of code.
Instead, we'll just do a wrapper polyfill that uses Node Streams
internally.
I kept the client indirection files that I added for consistency with
the server though.
When deeply nested Suspense boundaries inside a fallback of another
boundary resolve it is possible to encounter situations where you either
attempt to flush an aborted Segment or you have a boundary without any
root segment. We intended for both of these conditions to be impossible
to arrive at legitimately however it turns out in this situation you
can. The fix is two-fold
1. allow flushing aborted segments by simply skipping them. This does
remove some protection against future misconfiguraiton of React because
it is no longer an invariant that you hsould never attempt to flush an
aborted segment but there are legitimate cases where this can come up
and simply omitting the segment is fine b/c we know that the user will
never observe this. A semantically better solution would be to avoid
flushing boudaries inside an unneeded fallback but to do this we would
need to track all boundaries inside a fallback or create back pointers
which add to memory overhead and possibly make GC harder to do
efficiently. By flushing extra we're maintaining status quo and only
suffer in performance not with broken semantics.
2. when queuing completed segments allow for queueing aborted segments
and if we are eliding the enqueued segment allow for child segments that
are errored to be enqueued too. This will mean that we can maintain the
invariant that a boundary must have a root segment the first time we
flush it, it just might be aborted (see point 1 above).
This change has two seemingly similar test cases to exercise this fix.
The reason we need both is that when you have empty segments you hit
different code paths within Fizz and so each one (without this fix)
triggers a different error pathway.
This change also includes a fix to our tests where we were not
appropriately setting CSPnonce back to null at the start of each test so
in some contexts scripts would not run for some tests
Adding throttling or delaying on images, can obviously impact metrics.
However, it's all in the name of better actual user experience overall.
(Note that it's not strictly worse even for metric. Often it's actually
strictly better due to less work being done overall thanks to batching.)
Metrics can impact things like search ranking but I believe this is on a
curve. If you're already pretty good, then a slight delay won't suddenly
make you rank in a completely different category. Similarly, if you're
already pretty bad then a slight delay won't make it suddenly way worse.
It's still in the same realm. It's just one weight of many. I don't
think this will make a meaningful practical impact and if it does,
that's probably a bug in the weights that will get fixed.
However, because there's a race to try to "make everything green" in
terms of web vitals, if you go from green to yellow only because of some
throttling or suspensey images, it can feel bad. Therefore this
implements a heuristic where if the only reason we'd miss a specific
target is because of throttling or suspensey images, then we shorten the
timeout to hit the metric. This is a worse user experience because it
can lead to extra flashing but feeling good about "green" matters too.
If you then have another reveal that happens to be the largest
contentful paint after that, then that's throttled again so that it
doesn't become flashy after that. If you've already missed the deadline
then you're not going to hit your metric target anyway. It can affect
average but not median.
This is mainly about LCP. It doesn't affect FCP since that doesn't have
a throttle. If your LCP is the same as your FCP then it also doesn't
matter.
We assume that `performance.now()`'s zero point starts at the "start of
the navigation" which makes this simple. Even if we used the
`PerformanceNavigationTiming` API it would just tell us the same thing.
This only implements for Fizz since these metrics tend to currently only
by tracked for initial loads, but with soft navs tracking we could
consider implementing the same for Fiber throttles.
Follow up to #33442. This is the bundled version.
To keep type check passes from exploding and the maintainance of the
annoying `paths: []` list small, this doesn't add this to flow type
checks. We might miss some config but every combination should already
be covered by other one passes.
I also don't add any jest tests because to test these double export
entry points we need conditional importing to cover builds and
non-builds which turns out to be difficult for the Flight builds so
these aren't covered by any basic build tests.
This approach is what I'm going for, for the other bundlers too.
We want to make sure that we can block the reveal of a well designed
complete shell reliably. In the Suspense model, client transitions don't
have any way to implicitly resolve. This means you need to use Suspense
or SuspenseList to explicitly split the document. Relying on implicit
would mean you can't add a Suspense boundary later where needed. So we
highly encourage the use of them around large content.
However, if you have constructed a too large shell (e.g. by not adding
any Suspense boundaries at all) then that might take too long to render
on the client. We shouldn't punish users (or overzealous metrics
tracking tools like search engines) in that scenario.
This opts out of render blocking if the shell ends up too large to be
intentional and too slow to load. Instead it deopts to showing the
content split up in arbitrary ways (browser default). It only does this
for SSR, and not client navs so it's not reliable.
In fact, we issue an error to `onError`. This error is recoverable in
that the document is still produced. It's up to your framework to decide
if this errors the build or just surface it for action later.
What should be the limit though? There's a trade off here. If this limit
is too low then you can't fit a reasonably well built UI within it
without getting errors. If it's too high then things that accidentally
fall below it might take too long to load.
I came up with 512kB of uncompressed shell HTML. See the comment in code
for the rationale for this number. TL;DR: Data and theory indicates that
having this much content inside `rel="expect"` doesn't meaningfully
change metrics. Research of above-the-fold content on various websites
indicate that this can comfortable fit all of them which should be
enough for any intentional initial paint.
Block the view transition on suspensey images Up to 500ms just like the
client.
We can't use `decode()` because a bug in Chrome where those are blocked
on `startViewTransition` finishing we instead rely on sync decoding but
also that the image is live when it's animating in and we assume it
doesn't start visible.
However, we can block the View Transition from starting on the `"load"`
or `"error"` events.
The nice thing about blocking inside `startViewTransition` is that we
have already done the layout so we can only wait on images that are
within the viewport at this point. We might want to do that in Fiber
too. If many image doesn't have fixed size but need to load first, they
can all end up in the viewport. We might consider only doing this for
images that have a fixed size or only a max number that doesn't have a
fixed size.
## Summary
Enables the `enableEagerAlternateStateNodeCleanup` feature flag for all
variants, while maintaining the `__VARIANT__` for the internal React
Native flavor for backtesting reasons.
## How did you test this change?
```
$ yarn test
```
When I added the `ready_for_review` event in #32344, no notifications
for opened draft PRs were sent due to some other condition. This is not
the case anymore, so we need to exclude draft PRs from triggering a
notification when the workflow is run because of an `opened` event. This
event is still needed because the `ready_for_review` event only fires
when an existing draft PR is converted to a non-draft state. It does not
trigger for pull requests that are opened directly as ready-for-review.
We highly recommend using Node Streams in Node.js because it's much
faster and it is less likely to cause issues when chained in things like
compression algorithms that need explicit flushing which the Web Streams
ecosystem doesn't have a good solution for. However, that said, people
want to be able to use the worse option for various reasons.
The `.edge` builds aren't technically intended for Node.js. A Node.js
environments needs to be patched in various ways to support it. It's
also less optimal since it can't use [Node.js exclusive
features](https://github.com/facebook/react/pull/33388) and have to use
[the lowest common
denominator](https://github.com/facebook/react/pull/27399) such as JS
implementations instead of native.
This adds a Web Streams build of Fizz but exclusively for Node.js so
that in it we can rely on Node.js modules. The main difference compared
to Edge is that SSR now uses `createHash` from the `"crypto"` module and
imports `TextEncoder` from `"util"`. We use `setImmediate` instead of
`setTimeout`.
The public API is just `react-dom/server` which in Node.js automatically
imports `react-dom/server.node` which re-exports the legacy bundle, Node
Streams bundle and Node Web Streams bundle. The main downside is if your
bundler isn't smart to DCE this barrel file.
With Flight the difference is larger but that's a bigger lift.
Stacked on #33403.
When a Promise is coming from React such as when it's passed from
another environment, we should forward the debug information from that
environment. We already do that when rendered as a child.
This makes it possible to also `await promise` and have the information
from that instrumented promise carry through to the next render.
This is a bit tricky because the current protocol is that we have to
read it from the Promise after it resolves so it has time to be assigned
to the promise. `async_hooks` doesn't pass us the instance (even though
it has it) when it gets resolved so we need to keep it around. However,
we have to be very careful because if we get this wrong it'll cause a
memory leak since we retain things by `asyncId` and then manually listen
for `destroy()` which can only be called once a Promise is GC:ed, which
it can't be if we retain it. We have to therefore use a `WeakRef` in
case it never resolves, and then read the `_debugInfo` when it resolves.
We could maybe install a setter or something instead but that's also
heavy.
The other issues is that we don't use native Promises in
ReactFlightClient so our instrumented promises aren't picked up by the
`async_hooks` implementation and so we never get a handle to our
thenable instance. To solve this we can create a native wrapper only in
DEV.
We want to change the defaults for `revealOrder` and `tail` on
SuspenseList. This is an intermediate step to allow experimental users
to upgrade.
To explicitly specify these options I added `revealOrder="independent"`
and `tail="visible"`.
I then added warnings if `undefined` or `null` is passed. You must now
always explicitly specify them. However, semantics are still preserved
for now until the next step.
We also want to change the rendering order of the `children` prop for
`revealOrder="backwards"`. As an intermediate step I first added
`revealOrder="unstable_legacy-backwards"` option. This will only be
temporary until all users can switch to the new `"backwards"` semantics
once we flip it in the next step.
I also clarified the types that the directional props requires iterable
children but not iterable inside of those. Rows with multiple items can
be modeled as explicit fragments.
Stacked on #33402.
There's a bug in Chrome Performance tracking which uses the enclosing
line/column instead of the callsite in stacks.
For our fake eval:ed functions that represents functions on the server,
we can position the enclosing function body at the position of the
callsite to simulate getting the right line.
Unfortunately, that doesn't give us exactly the right callsite when it's
used for other purposes that uses the callsite like console logs and
error reporting and stacks inside breakpoints. So I don't think we want
to always do this.
For ReactAsyncInfo/ReactIOInfo, the only thing we're going to use the
fake task for is the Performance tracking, so it doesn't have any
downsides until Chrome fixes the bug and we'd have to revert it.
Therefore this PR uses that techniques only for those entries.
We could do this for Server Components too but we're going to use those
for other things too like console logs. I don't think it's worth
duplicating the Task objects. That would also make it inconsistent with
Client Components.
For Client Components, we could in theory also generate fake evals but
that would be way slower since there's so many of them and currently we
rely on the native implementation for those. So doesn't seem worth
fixing.
But since we can at least fix it for RSC I/O/awaits we can do this hack.
Stacked on #33400.
<img width="1261" alt="Screenshot 2025-06-01 at 10 27 47 PM"
src="https://github.com/user-attachments/assets/a5a73ee2-49e0-4851-84ac-e0df6032efb5"
/>
This is emitted with the start/end time and stack of the "await". Which
may be different than the thing that started the I/O.
These awaits aren't quite as simple as just every await since you can
start a sequence in parallel there can actually be multiple overlapping
awaits and there can be CPU work interleaved with the await on the same
component.
```js
function getData() {
await fetch(...);
await fetch(...);
}
const promise = getData();
doWork();
await promise;
```
This has two "I/O" awaits but those are actually happening in parallel
with `doWork()`.
Since these also could have started before we started rendering this
sequence (e.g. a component) we have to clamp it so that we don't
consider awaits that start before the component.
What we're conceptually trying to convey is the time this component was
blocked due to that I/O resource. Whether it's blocked from completing
the last result or if it's blocked from issuing a waterfall request.
Stacked on #33395.
This lets us keep track of which environment this was fetched and
awaited.
Currently the IO and await is in the same environment. It's just kept
when forwarded. Once we support forwarding information from a Promise
fetched from another environment and awaited in this environment then
the await can end up being in a different environment.
There's a question of when the await is inside Flight itself such as
when you return a promise fetched from another environment whether that
should mean that the await is in the current environment. I don't think
so since the original stack trace is the best stack trace. It's only if
you `await` it in user space in this environment first that this might
happen and even then it should only be considered if there wasn't a
better await earlier or if reading from the other environment was itself
I/O.
The timing of *when* we read `environmentName()` is a little interesting
here too.
Stacked on #33394.
This lets us create async stack traces to the owner that was in context
when the I/O was started or awaited.
<img width="615" alt="Screenshot 2025-06-01 at 12 31 52 AM"
src="https://github.com/user-attachments/assets/6ff5a146-33d6-4a4b-84af-1b57e73047d4"
/>
This owner might not be the immediate closest parent where the I/O was
awaited.
Stacked on #33392.
This adds another track to the Performance Track called `"Server
Requests"`.
<img width="1015" alt="Screenshot 2025-06-01 at 12 02 14 AM"
src="https://github.com/user-attachments/assets/c4d164c4-cfdf-4e14-9a87-3f011f65fd20"
/>
This logs the flat list of I/O awaited on by Server Components. There
will be other views that are more focused on what data blocks a specific
Component or Suspense boundary but this is just the list of all the I/O
basically so you can get an overview of those waterfalls without the
noise of all the Component trees and rendering. It's similar to what the
"Network" track is on the client.
I've been going back and forth on what to call this track but I went
with `"Server Requests"` for now. The idea is that the name should
communicate that this is something that happens on the server and is a
pairing with the `"Server Components"` track. Although we don't use that
feature, since it's missing granularity, it's also similar to "Server
Timings".
Stacked on #33390.
The stack trace doesn't include the thing you called when calling into
ignore listed content. We consider the ignore listed content
conceptually the abstraction that you called that's interesting.
This extracts the name of the first ignore listed function that was
called from user space. For example `"fetch"`. So we can know what kind
of request this is.
This could be enhanced and tweaked with heuristics in the future. For
example, when you create a Promise yourself and call I/O inside of it
like my `delay` examples, then we use that Promise as the I/O node but
its stack doesn't have the actual I/O performed. It might be better to
use the inner I/O node in that case. E.g. `setTimeout`. Currently I pick
the name from the first party code instead - in my example `delay`.
Another case that could be improved is the case where your whole
component is third-party. In that case we still log the I/O but it has
no context about what kind of I/O since the whole stack is ignored it
just gets the component name for example. We could for example look at
the first name that is in a different package than the package name of
the ignored listed component. So if
`node_modules/my-component-library/index.js` calls into
`node_modules/mysql/connection.js` then we could use the name from the
inner.
Stacked on #33388.
This encodes the I/O entries as their own row type (`"J"`). This makes
it possible to parse them directly without first parsing the debug info
for each component. E.g. if you're just interested in logging the I/O
without all the places it was awaited.
This is not strictly necessary since the debug info is also readily
available without parsing the actual trees. (That's how the Server
Components Performance Track works.) However, we might want to exclude
this information in profiling builds while retaining some limited form
of I/O tracking.
It also allows for logging side-effects that are not awaited if we
wanted to.
This lets us track what data each Server Component depended on. This
will be used by Performance Track and React DevTools.
We use Node.js `async_hooks`. This has a number of downside. It is
Node.js specific so this feature is not available in other runtimes
until something equivalent becomes available. It's [discouraged by
Node.js docs](https://nodejs.org/api/async_hooks.html#async-hooks). It's
also slow which makes this approach only really viable in development
mode. At least with stack traces. However, it's really the only solution
that gives us the data that we need.
The [Diagnostic
Channel](https://nodejs.org/api/diagnostics_channel.html) API is not
sufficient. Not only is many Node.js built-in APIs missing but all
libraries like databases are also missing. Were as `async_hooks` covers
pretty much anything async in the Node.js ecosystem.
However, even if coverage was wider it's not actually showing the
information we want. It's not enough to show the low level I/O that is
happening because that doesn't provide the context. We need the stack
trace in user space code where it was initiated and where it was
awaited. It's also not each low level socket operation that we want to
surface but some higher level concept which can span a sequence of I/O
operations but as far as user space is concerned.
Therefore this solution is anchored on stack traces and ignore listing
to determine what the interesting span is. It is somewhat
Promise-centric (and in particular async/await) because it allows us to
model an abstract span instead of just random I/O. Async/await points
are also especially useful because this allows Async Stacks to show the
full sequence which is not supported by random callbacks. However, if no
Promises are involved we still to our best to show the stack causing
plain I/O callbacks.
Additionally, we don't want to track all possible I/O. For example,
side-effects like logging that doesn't affect the rendering performance
doesn't need to be included. We only want to include things that
actually block the rendering output. We also need to track which data
blocks each component so that we can track which data caused a
particular subtree to suspend.
We can do this using `async_hooks` because we can track the graph of
what resolved what and then spawned what.
To track what suspended what, something has to resolve. Therefore it
needs to run to completion before we can show what it was suspended on.
So something that never resolves, won't be tracked for example.
We use the `async_hooks` in `ReactFlightServerConfigDebugNode` to build
up an `ReactFlightAsyncSequence` graph that collects the stack traces
for basically all I/O and Promises allocated in the whole app. This is
pretty heavy, especially the stack traces, but it's because we don't
know which ones we'll need until they resolve. We don't materialize the
stacks until we need them though.
Once they end up pinging the Flight runtime, we collect which current
executing task that pinged the runtime and then log the sequence that
led up until that runtime into the RSC protocol. Currently we only
include things that weren't already resolved before we started rendering
this task/component, so that we don't log the entire history each time.
Each operation is split into two parts. First a `ReactIOInfo` which
represents an I/O operation and its start/end time. Basically the start
point where it was start. This is basically represents where you called
`new Promise()` or when entering an `async function` which has an
implied Promise. It can be started in a different component than where
it's awaited and it can be awaited in multiple places. Therefore this is
global information and not associated with a specific Component.
The second part is `ReactAsyncInfo`. This represents where this I/O was
`await`:ed or `.then()` called. This is associated with a point in the
tree (usually the Promise that's a direct child of a Component). Since
you can have multiple different I/O awaited in a sequence technically it
forms a dependency graph but to simplify the model these awaits as
flattened into the `ReactDebugInfo` list. Basically it contains each
await in a sequence that affected this part from unblocking.
This means that the same `ReactAsyncInfo` can appear in mutliple
components if they all await the same `ReactIOInfo` but the same Promise
only appears once.
Promises that are only resolved by other Promises or immediately are not
considered here. Only if they're resolved by an I/O operation. We pick
the Promise basically on the border between user space code and ignored
listed code (`node_modules`) to pick the most specific span but abstract
enough to not give too much detail irrelevant to the current audience.
Similarly, the deepest `await` in user space is marked as the relevant
`await` point.
This feature is only available in the `node` builds of React. Not if you
use the `edge` builds inside of Node.js.
---------
Co-authored-by: Sebastian "Sebbie" Silbermann <silbermann.sebastian@gmail.com>
Alternative to #33421. The difference is that this also adds an
underscore between the "R" and the ID.
The reason we wanted to use special characters is because we use the
full spectrum of A-Z 0-9 in our ID generation so we can basically
collide with any common word (or anyone using a similar algorithm,
base64 or even base16). It's a little less likely that someone would put
`_R_` specifically unless you generate like two IDs separated by
underscore.

## Summary
This tool leverages DevTools to get the component tree from the
currently open React App. This gives realtime information to agents
about the state of the app.
## How did you test this change?
Tested integration with Claude Desktop
This is a babel bug + edge case.
Babel compact mode produces invalid JavaScript (i.e. parse error) when
given a `NumericLiteral` with a negative value.
See https://codesandbox.io/p/devbox/5d47fr for repro.
## Summary
While investigating the root cause of #33208, I noticed a clear typo for
one of the validation files.
## How did you test this change?
Inside `/react/compiler/packages/babel-plugin-react-compiler` I ran the
test script successfully:
<img width="415" alt="Screenshot at May 22 16-43-06"
src="https://github.com/user-attachments/assets/3fe8c5e1-37ce-4a31-b35e-7e323e57cd9d"
/>
## Summary
We completed testing on these internally, so can cleanup the separate
fast and slow paths and remove the `enableShallowPropDiffing` flag which
we're not pursuing.
## How did you test this change?
```
yarn test ReactNativeAttributePayloadFabric
```
fixes https://github.com/facebook/react/issues/32449
This is my first time touching this code. There are multiple systems in
place here and I wouldn't be surprised to learn that this has to be
handled in some other areas too. I have found some other style-related
code areas but I had no time yet to double-check them.
cc @gnoff
This is the same technique we do for the client except we don't check
whether this is newly created font loading to keep code small.
Unfortunately, we can't use this technique for Suspensey images. They'll
need to block before we call `startViewTransition` in a separate
refactor. This is due to a bug in Chrome where `img.decode()` doesn't
resolve until `startViewTransition` does.
There seems to be some bugs still to work out in Chrome. See #33187.
Additionally, since you can't really rely on this function existing
across browsers, it's hard to depend on its behavior anyway. In fact,
you now have a source of inconsistent behaviors across browsers to deal
with.
Ideally it would also be more widely spread in fake DOM implementations
like JSDOM so that we can use it unconditionally. #33177.
We still want to enable this since it's a great feature but maybe not
until it's more widely available cross-browsers with fewer bugs.
Summary:
To prepare for automatic effect dependencies, some codebases may want to
codemod
existing useEffect calls with no deps to include an explicit undefined
second argument
in order to preserve the "run on every render" behavior. In sufficiently
large codebases,
this may require a temporary enforcement period where all effects
provide an explicit
dependencies argument.
Outside of migration, relying on a component to render can lead to real
bugs,
especially when working with memoization.
## Summary
This PR fixes a likely incorrect condition in the
`scheduleUpdateOnFiber` function inside `ReactFiberWorkLoop.js`.
Previously, the code checked:
```js
(executionContext & RenderContext) !== NoLanes
````
However, `NoLanes` is part of the lane priority system, not the
execution context flags. The intent here seems to be to detect whether
the current execution context includes `RenderContext`, which should be
compared against `NoContext`, not `NoLanes`.
This fix replaces `NoLanes` with `NoContext` for semantic correctness
and consistency with other checks throughout the codebase.
**Fixes
[[#33169](https://github.com/facebook/react/issues/33169)](https://github.com/facebook/react/issues/33169)**
---
## How did you test this change?
I ran the following commands to validate correctness and ensure nothing
was broken:
* `yarn lint`
* `yarn linc`
* `yarn test`
* `yarn test --prod`
* `yarn flow`
* `yarn prettier`
All checks passed. Since this is a minor internal logic fix and doesn't
change public behavior or APIs, no additional tests are necessary at
this time.
## Summary
I am writing code that isn't so good, so I saw this error message many
times. It appears to have a typo. This PR fixes the typo.
## How did you test this change?
Ran the tests
Inferred effect dependencies now include optional chains.
This is a temporary solution while
https://github.com/facebook/react/pull/32099 and its followups are
worked on. Ideally, we should model reactive scope dependencies in the
IR similarly to `ComputeIR` -- dependencies should be hoisted and all
references rewritten to use the hoisted dependencies.
`
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/33326).
* __->__ #33326
* #33325
* #32286
Stacked on #33330.
This walks the element tree to activate the various classes under
different scenarios. There are some edge case things that are a little
different since we can't express every scenario without virtual nodes.
The main thing that's still missing though is avoiding animating updates
if it can be contained to a layout or enter/exit/share if they're out of
the viewport. I.e. layout stuff.
Follow up to #33293.
This solves a race condition when boundaries are added to the batch
after the `startViewTransition` call.
This doesn't matter yet but it will once we start assigning names before
the `startViewTransition` call.
A possible alternative solution might be to ensure the names are added
synchronously in the event that adds to the batch. It's possible to keep
adding to a batch until the snapshot has happened.
I believe that these mean the same thing. We don't have to emit the
attribute if it's `none` for these cases because if there is no matching
scenario we won't apply the animation in this case.
The only case where we have to emit `none` in the attribute is for
`vt-update` because those can block updates from propagating upwards.
Follow up to #33321.
We can mark boundaries that were blocked in the prerender as postponed
but without anything to replayed inside them. That way they're not
emitted in the prerender but is unblocked when replayed.
Technically this does some unnecessary replaying of the path to the
otherwise already completed boundary but it simplifies our model by just
marking the boundary as needing replaying.
This uses the richer `serverAct` helper that we already use in other
tests.
This avoids using the `Scheduler`. We don't use that package on the
server so it doesn't make sense to simulate going through it.
Additionally, we really should be getting rid of it on the client too to
favor `postTask` polyfills.
When a new child of a fragment instance is inserted, we need to notify
the instance to keep any relevant tracking up to date. For example, we
automatically observe the new child with any active
IntersectionObserver.
For mutable renderers (DOM), we reuse the existing traversal in
`commitPlacement` that does the insertions for HostComponents. Immutable
renderers (Fabric) exit this path before the traversal though, so
currently we can't notify the fragment instances.
Here I've created a separate traversal in `commitPlacement`,
specifically for immutable renders when `enableFragmentRefs` is on.
There's an interesting case when a SuspenseList is partially prerendered
but some of the completed boundaries are blocked by rows to be resumed.
This handles it but just unblocking the future rows to avoid stalling.
However, the correct semantics will need special handling in the
postponed state.
We have many cases internally where the `containerInstance` resolves to
a comment node. `restoreRootViewTransitionName` is called when
`enableViewTransition` is on, even without introducing a
`<ViewTransition />`. So that means it can crash pages because
`containerInstance.style` is `undefined` just by turning on the flag.
This skips cancel/restore of root view transition name if a comment node is the root.
I missed setting the `keyPath` because the `renderChildrenArray` that
this is forked from doesn't need to set a path but since this is
rendered from the `SuspenseList` element it needs it.
Stacked on #33311.
When a row contains Suspense boundaries that themselves depend on CSS,
they will not resolve until the CSS has loaded on the client. We need
future rows in a list to be blocked until this happens. We could do
something in the runtime but a simpler approach is to just add those CSS
dependencies to all those boundaries as well.
To do this, we first hoist the HoistableState from a completed boundary
onto its parent row. Then when the row finishes do we hoist it onto the
next row and onto any boundaries within that row.
Stacked on #33308.
For "together" mode, we can be a self-blocking row that adds all its
boundaries to the blocked set, but there's no parent row that unblocks
it.
A particular quirk of this mode is that it's not enough to just unblock
them all on the server together. Because if one boundary downloads all
its html and then issues a complete instruction it'll appear before the
others while streaming in. What we actually want is to reveal them all
in a single batch.
This implementation takes a short cut by unblocking the rows in
`flushPartialBoundary`. That ensures that all the segments of every
boundary has a chance to flush before we start emitting any of the
complete boundary instructions. Once the last one unblocks, all the
complete boundary instructions are queued. Ideally this would be a
single `<script>` tag so that they can't be split up even if we get a
chunk containing some of them.
~A downside of this approach is that we always outline these boundaries.
We could inline them if they all complete before the parent flushes.
E.g. by checking if the row is blocked only by its own boundaries and if
all the boundaries would fit without getting outlined, then we can
inline them all at once.~ I went ahead and did this because it solves an
issue with `renderToString` where it doesn't support the script runtime
so it can only handle this if inlined.
Follow up to #33306.
If we're nested inside a SuspenseList and we have a row, then we can
point our last row to block the parent row and unblock the parent when
the last child unblocks.
We support AsyncIterable (more so when it's a cached form like in coming
from Flight) as children.
This fixes some warnings and bugs when passed to SuspenseList.
Ideally SuspenseList with `tail="hidden"` should support unblocking
before the full result has resolved but that's an optimization on top.
We also might want to change semantics for this for
`revealOrder="backwards"` so it becomes possible to stream items in
reverse order.
Basically we track a `SuspenseListRow` on the task. These keep track of
"pending tasks" that block the row. A row is blocked by:
- First itself completing rendering.
- A previous row completing.
- Any tasks inside the row and before the Suspense boundary inside the
row. This is mainly because we don't yet know if we'll discover more
SuspenseBoundaries.
- Previous row's SuspenseBoundaries completing.
If a boundary might get outlined, then we can't consider it completed
until we have written it because it determined whether other future
boundaries in the row can finish.
This is just handling basic semantics. Features not supported yet that
need follow ups later:
- CSS dependencies of previous rows should be added as dependencies of
future row's suspense boundary. Because otherwise if the client is
blocked on CSS then a previous row could be blocked but the server
doesn't know it.
- I need a second pass on nested SuspenseList semantics.
- `revealOrder="together"`
- `tail="hidden"`/`tail="collapsed"`. This needs some new runtime
semantics to the Fizz runtime and to allow the hydration to handle
missing rows in the HTML. This should also be future compatible with
AsyncIterable where we don't know how many rows upfront.
- Need to double check resuming semantics.
---------
Co-authored-by: Sebastian "Sebbie" Silbermann <silbermann.sebastian@gmail.com>
When needed.
For the external runtime we always include this wrapper.
For others, we only include it if we have an ViewTransitions affecting.
If we discover the ViewTransitions late, then we can upgrade an already
emitted instruction.
This doesn't yet do anything useful with it, that's coming in a follow
up. This is just the mechanism for how it gets installed.
We decremented `allPendingTasks` after invoking `onShellReady`. Which
means that in that scope it wasn't considered fully complete.
Since the pattern for flushing in Node.js is to start piping in
`onShellReady` and that's how you can get sync behavior, this led us to
think that we had more work left to do. For example we emitted the
`writeShellTimeInstruction` in this scenario before.
Stacked on #33194 and #33200.
When Suspense boundaries reveal during streaming, the Fizz runtime will
be responsible for animating the reveal if necessary (not in this PR).
However, for the future runtime to know what to do it needs to know
about the `<ViewTransition>` configuration to apply.
Ofc, these are virtual nodes that disappear from the HTML. We could
model them as comments like we do with other virtual nodes like Suspense
and Activity. However, that doesn't let us target them with
querySelector and CSS (for no-JS transitions). We also don't have to
model every ViewTransition since not every combination can happen using
only the server runtime. So instead this collapses `<ViewTransition>`
and applies the configuration to the inner DOM nodes.
```js
<ViewTransition name="hi">
<div />
<div />
</ViewTransition>
```
Becomes:
```html
<div vt-name="hi" vt-update="auto"></div>
<div vt-name="hi_1" vt-update="auto"></div>
```
I use `vt-` prefix as opposed to `data-` to keep these virtual
attributes away from user specific ones but we're effectively claiming
this namespace.
There are four triggers `vt-update`, `vt-enter`, `vt-exit` and
`vt-share`. The server resolves which ones might apply to this DOM node.
The value represents the class name (after resolving
view-transition-type mappings) or `"auto"` if no specific class name is
needed but this is still a trigger.
The value can also be `"none"`. This is different from missing because
for example an `vt-update="none"` will block mutations inside it from
triggering the boundary where as a missing `vt-update` would bubble up
to be handled by a parent.
`vt-name` is technically only necessary when `vt-share` is specified to
find a pair. However, since an explicit name can also be used to target
specific CSS selectors, we include it even for other cases.
We want to exclude as many of these annotations as possible.
`vt-enter` can only affect the first DOM node inside a Suspense
boundary's content since the reveal would cause it to enter but nothing
deeper inside. Similarly `vt-exit` can only affect the first DOM node
inside a fallback. So for every other case we can exclude them. (For
future MPA ViewTransitions of the whole document it might also be
something we annotate to children inside the `<body>` as well.) Ideally
we'd only include `vt-enter` for Suspense boundaries that actually
flushed a fallback but since we prepare all that content earlier it's
hard to know.
`vt-share` can be anywhere inside an fallback or content. Technically we
don't have to include it outside the root most Suspense boundary or for
boundaries that are inlined into the root shell. However, this is tricky
to detect. It would also not be correct for future MPA ViewTransitions
because in that case the shared scenario can affect anything in the two
documents so it needs to be in every node everywhere which is
effectively what we do. If a `share` class is specified but it has no
explicit name, we can exclude it since it can't match anything.
`vt-update` is only necessary if something below or a sibling might
update like a Suspense boundary. However, since we don't know when
rendering a segment if it'll later asynchronously add a Suspense
boundary later we have to assume that anywhere might have a child. So
these are always included. We collapse to use the inner most one when
directly nested though since that's the one that ends up winning.
There are some weird edge cases that can't be fully modeled by the lack
of virtual nodes.
Removes the `isFallback` flag on Tasks and tracks it on the
formatContext instead.
Less memory and avoids passing and tracking extra arguments to all the
pushStartInstance branches that doesn't need it.
We'll need to be able to track more Suspense related contexts on this
for View Transitions anyway.
This is a partial revert of #33094. It's true that we don't need the
server and client ViewTransition names to line up. However the server
does need to be able to generate deterministic names for itself. The
cheapest way to do that is using the useId algorithm. When it's used by
the server, the client needs to also materialize an ID even if it
doesn't use it.
And that doesn't disable with `update="none"`.
The principle here is that we want the content of a Portal to animate if
other things are animating with it but if other things aren't animating
then we don't.
Stacked on #33160, #33162, #33186 and #33188.
We have a special case that's awkward for default indicators. When you
start a new async Transition from `React.startTransition` then there's
not yet any associated root with the Transition because you haven't
necessarily `setState` on anything yet until the promise resolves.
That's what `entangleAsyncAction` handles by creating a lane that
everything entangles with until all async actions are done.
If there are no sync updates before the end of the event, we should
trigger a default indicator until either the async action completes
without update or if it gets entangled with some roots we should keep it
going until those roots are done.
Stacked on #33160.
By default, if `onDefaultTransitionIndicator` is not overridden, this
will trigger a fake Navigation event using the Navigation API. This is
intercepted to create an on-going navigation until we complete the
Transition. Basically each default Transition is simulated as a
Navigation.
This triggers the native browser loading state (in Chrome at least). So
now by default the browser spinner spins during a Transition if no other
loading state is provided. Firefox and Safari hasn't shipped Navigation
API yet and even in the flag Safari has, it doesn't actually trigger the
native loading state.
To ensures that you can still use other Navigations concurrently, we
don't start our fake Navigation if there's one on-going already.
Similarly if our fake Navigation gets interrupted by another. We wait
for on-going ones to finish and then start a new fake one if we're
supposed to be still pending.
There might be other routers on the page that might listen to intercept
Navigation Events. Typically you'd expect them not to trigger a refetch
when navigating to the same state. However, if they want to detect this
we provide the `"react-transition"` string in the `info` field for this
purpose.
Stacked on #33160.
The purpose of this is to avoid calling `onDefaultTransitionIndicator`
when a Default priority update acts as the loading indicator, but still
call it when unrelated Default updates happens nearby.
When we schedule Default priority work that gets batched with other
events in the same frame more or less. This helps optimize by doing less
work. However, that batching means that we can't separate work from one
setState from another. If we would consider all Default priority work in
a frame when determining whether to show the default we might never show
it in cases like when you have a recurring timer updating something.
This instead flushes the Default priority work eagerly along with the
sync work at the end of the event, if this event scheduled any
Transition work. This is then used to determine if the default indicator
needs to be shown.
Stacked on #33159.
This implements `onDefaultTransitionIndicator`.
The sequence is:
1) In `markRootUpdated` we schedule Transition updates as needing
`indicatorLanes` on the root. This tracks the lanes that currently need
an indicator to either start or remain going until this lane commits.
2) Track mutations during any commit. We use the same hook that view
transitions use here but instead of tracking it just per view transition
scope, we also track a global boolean for the whole root.
3) If a sync/default commit had any mutations, then we clear the
indicator lane for the `currentEventTransitionLane`. This requires that
the lane is still active while we do these commits. See #33159. In other
words, a sync update gets associated with the current transition and it
is assumed to be rendering the loading state for that corresponding
transition so we don't need a default indicator for this lane.
4) At the end of `processRootScheduleInMicrotask`, right before we're
about to enter a new "event transition lane" scope, it is no longer
possible to render any more loading states for the current transition
lane. That's when we invoke `onDefaultTransitionIndicator` for any roots
that have new indicator lanes.
5) When we commit, we remove the finished lanes from `indicatorLanes`
and once that reaches zero again, then we can clean up the default
indicator. This approach means that you can start multiple different
transitions while an indicator is still going but it won't stop/restart
each time. Instead, it'll wait until all are done before stopping.
Follow ups:
- [x] Default updates are currently not enough to cancel because those
aren't flush in the same microtask. That's unfortunate. #33186
- [x] Handle async actions before the setState. Since these don't
necessarily have a root this is tricky. #33190
- [x] Disable for `useDeferredValue`. ~Since it also goes through
`markRootUpdated` and schedules a Transition lane it'll get a default
indicator even though it probably shouldn't have one.~ EDIT: Turns out
this just works because it doesn't go through `markRootUpdated` when
work is left behind.
- [x] Implement built-in DOM version by default. #33162
When we're entangled with an async action lane we use that lane instead
of the currentEventTransitionLane. Conversely, if we start a new async
action lane we reuse the currentEventTransitionLane.
So they're basically supposed to be in sync but they're not if you
resolve the async action and then schedule new stuff in the same event.
Then you end up with two transitions in the same event with different
lanes.
By stashing it like this we fix that but it also gives us an opportunity
to check just the currentEventTransitionLane to see if this event
scheduled any regular Transition updates or Async Transitions.
This keeps track of the transition lane allocated for this event. I want
to be able to use the current one within sync work flushing to know
which lane needs its loading indicator cleared.
It's also a bit weird that transition work scheduled inside sync updates
in the same event aren't entangled with other transitions in that event
when `flushSync` is.
Therefore this moves it to reset after flushing.
It should have no impact. Just splitting it out into a separate PR for
an abundance of caution.
The only thing this might affect would be if the React internals throws
and it doesn't reset after. But really it doesn't really have to reset
and they're all entangled anyway.
When we get the source location for "View source for this element" we
should be using the enclosing function of the callsite of the child. So
that we don't just point to some random line within the component.
This is similar to the technique in #33136.
This technique is now really better than the fake throw technique, when
available. So I now favor the owner technique. The only problem it's
only available in DEV and only if it has a child that's owned (and not
filtered).
We could implement this same technique for the error that's thrown in
the fake throwing solution. However, we really shouldn't need that at
all because for client components we should be able to call
`inspect(fn)` at least in Chrome which is even better.
Enabled in experimental channel.
We know this is critical semantics to enforce at the HTML level since if
you don't then you can't add explicit boundaries after the fact.
However, this might have to go in a major release to allow for
upgrading.
## Summary
Our builds generate files with a `.mjs` file extension. These are
currently filtered out by `ReactFlightWebpackPlugin` so I am updating it
to support this file extension.
This fixes https://github.com/facebook/react/issues/33155
## How did you test this change?
I built the plugin with this change and used `yalc` to test it in my
project. I confirmed the expected files now show up in
`react-client-manifest.json`
React Compiler's program traversal logic is pretty lengthy and complex
as we've added a lot of features piecemeal. `compileProgram` is 300+
lines long and has confusing control flow (defining helpers inline,
invoking visitors, mutating-asts-while-iterating, mutating global
`ALREADY_COMPILED` state).
- Moved more stuff to `ProgramContext`
- Separated `compileProgram` into a bunch of helpers
Tested by syncing this stack to a Meta codebase and observing no
compilation output changes (D74487851, P1806855669, P1806855379)
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/33147).
* #33149
* #33148
* __->__ #33147
Stacked on #33150.
We use `noop` functions in a lot of places as place holders. I don't
think there's any real optimizations we get from having separate
instances. This moves them to use a common instance in `shared/noop`.
New take on #29716
## Summary
Template literals consisting entirely of constant values will be inlined
to a string literal, effectively replacing the backticks with a double
quote.
This is done primarily to make the resulting instruction a string
literal, so it can be processed further in constant propatation. So this
is now correctly simplified to `true`:
```js
`` === "" // now true
`a${1}` === "a1" // now true
```
If a template string literal can only partially be comptime-evaluated,
it is not that useful for dead code elimination or further constant
folding steps and thus, is left as-is in that case. Same is true if the
literal contains an array, object, symbol or function.
## How did you test this change?
See added tests.
(Almost) all pragmas are now one of the following:
- `@...TestOnly`: custom pragma for test fixtures
- `@<configName>` | `@<configName>:true`: enables with either true or a
default enabled value
- `@<configName>:<json value>`
`fragmentInstance.dispatchEvent(evt)` calls `element.dispatchEvent(evt)`
on the fragment's host parent. This mimics bubbling if the
`fragmentInstance` could receive an event itself.
If the parent is disconnected, there is a dev warning and no event is
dispatched.
## Summary
`-constant` is represented as a `UnaryExpression` node that is currently
not part of constant folding. If the operand is a constant number, the
node is folded to `constant * -1`. This also coerces `-0` to `0`,
resulting in `0 === -0` being folded to `true`.
## How did you test this change?
See attached tests
Follow up to #33136.
This clarifies in the types where the conversion happens from a CallSite
which we use to simulate getting the enclosing line/col to a
FunctionLocation which doesn't represent a CallSite but actually just
the function which only has an enclosing line/col.
This enables `focus` and `focusLast` methods on FragmentInstances to
search nested host components, depth first. Attempts focus on each child
and bails if one is successful. Previously, only the first level of host
children would attempt focus.
Now if we have an example like
```
component MenuItem() {
return (<div><a>{...}</a></div>)
}
component Menu() {
return <Fragment>{items.map(i => <MenuItem i={i} />)}</Fragment>
}
```
We can target focus on the first or last a tag, rather than checking
each wrapping div and then noop.
Stacked on #33135.
This encodes the line/column of the enclosing function as part of the
stack traces. When that information is available.
I adjusted the fake function code generation so that the beginning of
the arrow function aligns with these as much as possible.
This ensures that when the browser tries to look up the line/column of
the enclosing function, such as for getting the function name, it gets
the right one. If we can't get the enclosing line/column, then we encode
it at the beginning of the file. This is likely to get a miss in the
source map identifiers, which means that the function name gets
extracted from the runtime name instead which is better.
Another thing where this is used is the in the Performance Track.
Ideally that would be fixed by
https://issues.chromium.org/u/1/issues/415968771 but the enclosing
information is useful for other things like the function name resolution
anyway.
We can also use this for the "View source for this element" in React
DevTools.
This is first step to include more enclosing line/column in the parsed
data.
We install our own `prepareStackTrace` to collect structured callsite
data and only fall back to parsing the string if it was already
evaluated or if `prepareStackTrace` doesn't work in this environment.
We still mirror the default V8 format for encoding the function name
part. A lot of this is covered by tests already.
## Summary
When using React DevTools to highlight component updates, the highlights
would sometimes appear behind elements that use the browser's
[top-layer](https://developer.mozilla.org/en-US/docs/Glossary/Top_layer)
(such as `<dialog>` elements or components using the Popover API). This
made it difficult to see which components were updating when they were
inside or behind top-layer elements.
This PR fixes the issue by using the Popover API to ensure that
highlighting appears on top of all content, including elements in the
top-layer. The implementation maintains backward compatibility with
browsers that don't support the Popover API.
## How did you test this change?
I tested this change in the following ways:
1. Manually tested in Chrome (which supports the Popover API) with:
- Created a test application with React components inside `<dialog>`
elements and custom elements using the Popover API
- Verified that component highlighting appears above these elements when
they update
- Confirmed that highlighting displays correctly for nested components
within top-layer elements
2. Verified backward compatibility:
- Tested in browsers without Popover API support to ensure fallback
behavior works correctly
- Confirmed that no errors occur and highlighting still functions as
before
3. Ran the React DevTools test suite:
- All tests pass successfully
- No regressions were introduced
[demo-page](https://devtools-toplayer-demo.vercel.app/)
[demo-repo](https://github.com/yongsk0066/devtools-toplayer-demo)
### AS-IS
https://github.com/user-attachments/assets/dc2e1281-969f-4f61-82c3-480153916969
### TO-BE
https://github.com/user-attachments/assets/dd52ce35-816c-42f0-819b-0d5d0a8a21e5
This adds `compareDocumentPosition(otherNode)` to fragment instances.
The semantics implemented are meant to match typical element
positioning, with some fragment specifics. See the unit tests for all
expectations.
- An element preceding a fragment is `Node.DOCUMENT_POSITION_PRECEDING`
- An element after a fragment is `Node.DOCUMENT_POSITION_FOLLOWING`
- An element containing the fragment is
`Node.DOCUMENT_POSITION_PRECEDING` and
`Node.DOCUMENT_POSITION_CONTAINING`
- An element within the fragment is
`Node.DOCUMENT_POSITION_CONTAINED_BY`
- An element compared against an empty fragment will result in
`Node.DOCUMENT_POSITION_DISCONNECTED` and
`Node.DOCUMENT_POSITION_IMPLEMENTATION_SPECIFIC`
Since we assume a fragment instances target children are DOM siblings
and we want to compare the full fragment as a pseudo container, we can
compare against the first target child outside of handling the special
cases (empty fragments and contained elements).
Multiple things here:
- Improve the mean calculation for metrics so we don't report 0 when
web-vitals fail to be retrieved
- improve ui chaos monkey to use puppeteer APIs since only those trigger
INP/CLS metrics since we need emulated mouse clicks
- Add logic to navigate to a temp page after render since some
web-vitals metrics are only calculated when the page is backgrounded
- Some readability improvements
Originally I thought it was important that SSR used the same View
Transition name as the client so that the Fizz runtime could emit those
names and then the client could pick up and take over. However, I no
longer believe that approach is feasible. Instead, the names can be
generated only during that particular animation.
Therefore we can simplify the auto name assignment to not have to
consider the hydration.
Stacked on #33129. Flagged behind `enableHydrationChangeEvent`.
If you type into a controlled input before hydration and something else
rerenders like a setState in an effect, then the controlled input will
reset to whatever React thought it was. Even with event replaying that
this is stacked on, if the second render happens before event replaying
has fired in a separate task.
We don't want to flush inside the commit phase because then things like
flushSync in these events wouldn't work since they're inside the commit
stack.
This flushes all event replaying between renders by flushing it at the
end of `flushSpawned` work. We've already committed at that point and is
about to either do subsequent renders or yield to event loop for passive
effects which could have these events fired anyway. This just ensures
that they've already happened by the time subsequent renders fire. This
means that there's now a type of event that fire between sync render
passes.
This fixes a long standing issue that controlled inputs gets out of sync
with the browser state if it's changed before we hydrate.
This resolves the issue by replaying the change events (click, input and
change) if the value has changed by the time we commit the hydration.
That way you can reflect the new value in state to bring it in sync. It
does this whether controlled or uncontrolled.
The idea is that this should be ok to replay because it's similar to the
continuous events in that it doesn't replay a sequence but only reflects
the current state of the tree.
Since this is a breaking change I added it behind
`enableHydrationChangeEvent` flag.
There is still an additional issue remaining that I intend to address in
a follow up. If a `useLayoutEffect` triggers an sync rerender on
hydration (always a bad idea) then that can rerender before we have had
a chance to replay the change events. If that renders through a input
then that input will always override the browser value with the
controlled value. Which will reset it before we've had a change to
update to the new value.
Note that bailing out adds false positives for hoisted functions whose
only references are within other functions. For example, this rewrite
would be safe.
```js
// source program
function foo() {
return bar();
}
function bar() {
return 42;
}
// compiler output
let bar;
if (/* deps changed */) {
function foo() {
return bar();
}
bar = function bar() {
return 42;
}
}
```
These false positives are difficult to detect because any maybe-call of
foo before the definition of bar would be invalid.
Instead of bailing out, we should rewrite hoisted function declarations
to the following form.
```js
let bar$0;
if (/* deps changed */) {
// All references within the declaring memo block
// or before the function declaration should use
// the original identifier `bar`
function foo() {
return bar();
}
function bar() {
return 42;
}
bar$0 = bar;
}
// All references after the declaring memo block
// or after the function declaration should use
// the rewritten declaration `bar$0`
```
I noticed that we increase this in the recursive part of the algorithm.
This would mean that we'd count a key more than once if it has Server
Components inside it recursively resolving. This moves it out to where
we enter from toJSON. Which is called once per JSON entry (and therefore
once per key).
This revisits a validation I built a while ago, trying to make it more strict this time to ensure that it's high-signal.
We detect function expressions which are *known* mutable — they definitely can modify a variable defined outside of the function expression itself (modulo control flow). This uses types to look for known Store and Mutate effects only, and disregards mutations of effects. Any such function passed to a location with a Freeze effect is reported as a validation error.
This is behind a flag and disabled by default. If folks agree this makes sense to revisit, i'll test out internally and we can consider enabling by default.
ghstack-source-id: 075a731444ce95e52dbd5ea3be85c16d428927f5
Pull Request resolved: https://github.com/facebook/react/pull/33079
If a function captures a mutable value but never gets called, we don't infer a mutable range for that function. This means that we also don't alias the function with its mutable captures.
This case is tricky, because we don't generally know for sure what is a mutation and what may just be a normal function call. For example:
```js
hook useFoo() {
const x = makeObject();
return () => {
return readObject(x); // could be a mutation!
}
}
```
If we pessimistically assume that all such cases are mutations, we'd have to group lots of memo scopes together unnecessarily. However, if there is definitely a mutation:
```js
hook useFoo(createEntryForKey) {
const cache = new WeakMap();
return (key) => {
let entry = cache.get(key);
if (entry == null) {
entry = createEntryForKey(key);
cache.set(key, entry); // known mutation!
}
return entry;
}
}
```
Then we have to ensure that the function and its mutable captures alias together and end up in the same scope. However, aliasing together isn't enough if the function and operands all have empty mutable ranges (end = start + 1).
This pass finds function expressions and object methods that have an empty mutable range and known-mutable operands which also don't have a mutable range, and ensures that the function and those operands are aliased together *and* that their ranges are updated to end after the function expression. This is sufficient to ensure that a reactive scope is created for the alias set.
NOTE: The alternative is to reject these cases. If we do that we'd also want to similarly disallow cases like passing a mutable function to a hook.
ghstack-source-id: 5d8158246a320e80d8da3f0e395ac1953d8920a2
Pull Request resolved: https://github.com/facebook/react/pull/33078
Building on mofeiz's recent work to type constructors. Also, types for reanimated values which are useful in the next PR.
ghstack-source-id: 1c81e213a11337ac7e9c85a429ecf3f1d1adef66
Pull Request resolved: https://github.com/facebook/react/pull/33077
This pass didn't previously report the precise difference btw inferred/manual dependencies unless a debug flag was set. But the error message is really good (nice job mofeiz): the only catch is that in theory the inferred dep could be a temporary that can't trivially be reported to the user.
But the messages are really useful for quickly verifying why the compiler couldn't preserve memoization. So here we switch to outputting a detailed message about the discrepancy btw inferred/manual deps so long as the inferred dep root is a named variable. I also slightly adjusted the message to handle the case where there is no diagnostic, which can occur if there were no manual deps but the compiler inferred a dependency.
ghstack-source-id: 534f6f1fec0855e05e85077eba050eb2ba254ef8
Pull Request resolved: https://github.com/facebook/react/pull/33095
If a JSX attribute value is a string that contains unicode or other characters that need special escaping, we wrap the attribute value in an expression container. However, our unicode to detect this only handled the basic unicode character plane, not the "astral" plane which includes emojis.
This PR updates the regex to detect such extended characters and also use an expression container.
ghstack-source-id: 6d9c8e4dd22285077108e2fa53d66154d1b781fb
Pull Request resolved: https://github.com/facebook/react/pull/33096
Our runtime results are still bogus, but so far this tweak let's the llm
use the tools a little more intelligently.
example:
---
```js
import React from 'react';
function App() {
const [count, setCount] = React.useState(0);
const [data, setData] = React.useState([]);
React.useEffect(() => {
const processData = () => {
console.log("Processing data...");
const newData = [];
for (let i = 0; i < 1000000000; i++) {
newData.push({ id: i, value: Math.random() * count });
}
return newData;
};
const processedData = processData();
setData(processedData);
}, [count]);
return (
<div>
<p>Count: {count}</p>
<p>Data Length: {data.length}</p>
<ul>
{data.slice(0, 5).map((item) => (
<li key={item.id}>Item {item.id}: {item.value.toFixed(2)}</li>
))}
</ul>
</div>
);
};
```
why is this component slow? use the react tools to figure this out.
> I'll analyze why this component is slow using the React tools. Let's
first evaluate the performance of the original code.
>
[review-react-runtime ...]
>
> The performance measurement tool timed out, which is a strong
indication of just how severe the performance issue is in this
component. Let's now try to compile the code to see if React Compiler
can identify any issues:
>
[compile...]
>
> Now I understand the issue. Let's analyze why this component > is
extremely slow:
> Main Performance Issues:
>
> Massive Data Processing: The component is trying to create an array
with a billion (1,000,000,000) objects in the processData function. This
is an enormous amount of data that will:
>
> Consume massive amounts of memory
> Take an extremely long time to process
> Likely crash the browser
>
>
> Unnecessary Recalculation: The effect depends on [count], meaning
every time the count changes, it will reprocess this enormous dataset.
> Inefficient Data Handling: Even though only 5 items are displayed, the
component processes a billion items.
>
> Let's fix these issues:
>
[compile...]
>
> Now let's check if our modified code performs better:
>
[review-react-runtime...]
>
> Excellent! The performance has dramatically improved. Now let's check
the React documentation to make sure we're following the best practices:
>
[query-react-dev-docs...]
(hit the maximum length conversation limit because i'm on a free plan)
Since we use esbuild we need to correctly move dependencies that are
required at runtime into `dependencies` and other packages that are only
used in development in to `devDependencies`. This ensures the correct
packages are included in the build.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/33101).
* #33085
* #33084
* #33083
* #33082
* __->__ #33101
Because we now decided whether to outline in the flushing phase, when
we're writing the preamble we don't yet know if we will make that
decision so we don't know if it's safe to omit the external runtime.
However, if you are providing an external runtime it's probably a pretty
safe bet you're streaming something dynamically that's likely to need it
so we can always include it.
The main thing is that this makes it hard to test it because it affects
our tests in ways it wouldn't otherwise so we have to add a bunch of
conditions.
Stacked on #33076.
This fixes a bug where we used the "complete" status but the
DOMContentLoaded event. This checks for not "loading" instead.
We also add a new status where the boundary has been marked as complete
by the server but has not yet flushed either due to being throttled,
suspended on CSS or animating.
Stacked on #33073.
React semantics is that Suspense boundaries reveal with a throttle
(300ms). That helps avoid flashing reveals when a stream reveals many
individual steps back to back. It can also improve overall performance
by batching the layout and paint work that has to happen at each step.
Unfortunately we never implemented this for SSR streaming - only for
client navigations. This is highly noticeable on very dynamic sites with
lots of Suspense boundaries. It can look good with a client nav but feel
glitchy when you reload the page or initial load.
This fixes the Fizz runtime to be throttled and reveals batched into a
single paint at a time. We do this by first tracking the last paint
after the complete (this will be the first paint if `rel="expect"` is
respected). Then in the `completeBoundary` operation we queue the
operation and then flush it all into a throttled batch.
Another motivation is that View Transitions need to operate as a batch
and individual steps get queued in a sequence so it's extra important to
include as much content as possible in each animated step. This will be
done in a follow up for SSR View Transitions.
Stacked on #33066 and #33068.
Currently we're passing `errorDigest` to `completeBoundary` if there is
a client side error (only CSS loading atm). This only exists because of
`completeBoundaryWithStyles`. Normally if there's a server-side error
we'd emit the `clientRenderBoundary` instruction instead. This adds
unnecessary code to the common case where all styles are in the head.
This is about to get worse with batching because client render shouldn't
be throttled but complete should be.
The first commit moves the client render logic inline into
`completeBoundaryWithStyles` so we only pay for it when styles are used.
However, the approach I went with in the second commit is to reuse the
`$RX` instruction instead (`clientRenderBoundary`). That way if you have
both it ends up being amortized. However, it does mean we have to emit
the `$RX` (along with the `$RC` helper if any
`completeBoundaryWithStyles` instruction is needed.
Stacked on #33065.
The runtime is about to be a lot more complicated so we need to start
sharing some more code.
The problem with sharing code is that we want the inline runtime to as
much as possible be isolated in its scope using only a few global
variables to refer across runtimes.
A problem with Closure Compiler is that it refuses to inline functions
if they have closures inside of them. Which makes sense because of how
VMs work it can cause memory leaks. However, in our cases this doesn't
matter and code size matters more. So we can't use many clever tricks.
So this just favors writing the source in the inline form. Then we add
an extra compiler pass to turn those global variables into local
variables in the external runtime.
We weren't treating terminal operands as eligible for memoization in PruneNonEscapingScopes, which meant that they could end up un-memoized. Terminal operands can also be compound ReactiveValues like SequenceExpressions, so part of the fix is to make sure we don't just recurse into compound values but record the full aliasing information we would for top-level instructions.
Still WIP, this needs to handle terminals other than for..of.
ghstack-source-id: 09a29230514e3bc95d1833cd4392de238fabbeda
Pull Request resolved: https://github.com/facebook/react/pull/33062
## Summary
Fix babel presets, and add a bit more context to the tool so that it is
more reliable
## How did you test this change?
Manually tested the mcp integrated with claude desktop
We normally expect the segment to exist whatever the client does while
streaming. However, when hydration errors at the root of the shell for a
whole document render, then we clear nodes from body which can include
our segments. We don't need them anymore because we switched to client
rendering.
It triggers an error accessing parent node which can safely be ignored.
This just helps avoid confusion in this scenario.
This also covers up the error in #33067. Which doesn't actually cause
any visible problems other than error logging. However, ideally we
wouldn't emit completeBoundary instructions if the boundary is inside a
cancelled fallback.
```js
function Component() {
useEffect(() => {
let hasCleanedUp = false;
document.addEventListener(..., () => hasCleanedUp ? foo() : bar());
// effect return values shouldn't be typed as frozen
return () => {
hasCleanedUp = true;
}
};
}
```
### Problem
`PruneHoistedContexts` currently strips hoisted declarations and
rewrites the first `StoreContext` reassignment to a declaration. For
example, in the following example, instruction 0 is removed while a
synthetic `DeclareContext let` is inserted before instruction 1.
```js
// source
const cb = () => x; // reference that causes x to be hoisted
let x = 4;
x = 5;
// React Compiler IR
[0] DeclareContext HoistedLet 'x'
...
[1] StoreContext reassign 'x' = 4
[2] StoreContext reassign 'x' = 5
```
Currently, we don't account for `DeclareContext let`. As a result, we're
rewriting to insert duplicate declarations.
```js
// source
const cb = () => x; // reference that causes x to be hoisted
let x;
x = 5;
// React Compiler IR
[0] DeclareContext HoistedLet 'x'
...
[1] DeclareContext Let 'x'
[2] StoreContext reassign 'x' = 5
```
### Solution
Instead of always lowering context variables to a DeclareContext
followed by a StoreContext reassign, we can keep `kind: 'Const' | 'Let'
| 'Reassign' | etc` on StoreContext.
Pros:
- retain more information in HIR, so we can codegen easily `const` and
`let` context variable declarations back
- pruning hoisted `DeclareContext` instructions is simple.
Cons:
- passes are more verbose as we need to check for both `DeclareContext`
and `StoreContext` declarations
~(note: also see alternative implementation in
https://github.com/facebook/react/pull/32745)~
### Testing
Context variables are tricky. I synced and diffed changes in a large
meta codebase and feel pretty confident about landing this. About 0.01%
of compiled files changed. Among these changes, ~25% were [direct
bugfixes](https://www.internalfb.com/phabricator/paste/view/P1800029094).
The [other
changes](https://www.internalfb.com/phabricator/paste/view/P1800028575)
were primarily due to changed (corrected) mutable ranges from
https://github.com/facebook/react/pull/33047. I tried to represent most
interesting changes in new test fixtures
`
Fixes an edge case in React Compiler's effects inference model.
Returned values should only be typed as 'frozen' if they are (1) local
and (2) not a function expression which may capture and mutate this
function's outer context. See test fixtures for details
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/33047).
* #32765
* #32747
* __->__ #33047
## Summary
Add a way for the agent to get some data on the performance of react
code
## How did you test this change?
Tested function independently and directly with claude desktop app
---------
Co-authored-by: Sebastian "Sebbie" Silbermann <sebastian.silbermann@vercel.com>
Same principle as #33029 but for Flight.
We pretty aggressively create separate rows for things in Flight (every
Server Component that's an async function create a microtask). However,
sync Server Components and just plain Host Components are not. Plus we
should ideally ideally inline more of the async ones in the same way
Fizz does.
This means that we can create rows that end up very large. Especially if
all the data is already available. We can't show the parent content
until the whole thing loads on the client.
We don't really know where Suspense boundaries are for Flight but any
Element is potentially a point that can be split.
This heuristic counts roughly how much we've serialized to block the
current chunk and once a limit is exceeded, we start deferring all
Elements. That way they get outlined into future chunks that are later
in the stream. Since they get replaced by Lazy references the parent can
potentially get unblocked.
This can help if you're trying to stream a very large document with a
client nav for example.
Adds Fragment Ref support to RN through the Fabric config, starting with
`observeUsing`/`unobserveUsing`. This is mostly a copy from the
implementation on DOM, and some of it can likely be shared in the future
but keeping it separate for now and we can refactor as we add more
features.
Added a basic test with Fabric, but testing specific methods requires so
much mocking that it doesn't seem valuable here.
I built Fabric and ran on the Catalyst app internally to test with
intersection observers end to end.
Stacked on #32736.
That way you can find the owner stack of each component that rerendered
for context.
In addition to the JSX callsite tasks that we already track, I also
added tracking of the first `setState` call before rendering.
We then run the "Update" entries in that task. That way you can find the
callsite of the first setState and therefore the "cause" of a render
starting by selecting the "Update" track.
Unfortunately this is blocked on bugs in Chrome that makes it so that
these stacks are not reliable in the Performance tab. It basically just
doesn't work.
This is a new extension that Chrome added to the existing
`console.timeStamp` similar to the extensions added to
`performance.measure`. This one should be significantly faster because
it doesn't have the extra object indirection, it doesn't return a
`PerformanceMeasure` entry and doesn't register itself with the global
system of entries.
I also use `performance.measure` in DEV for errors since we can attach
the error to the `properties` extension which doesn't exist for
`console.timeStamp`.
A downside of using this API is that there's no programmatic API for the
site itself to collect its own logs from React. Which the previous
allowed us to use the standard `performance.getEntries()` for. The
recommendation instead will be for the site to patch `console.timeStamp`
if it wants to collect measurements from React just like you're
recommended to patch `console.error` or `fetch` or whatever to collect
other instrumentation metrics.
This extension works in Chrome canary but it doesn't yet work fully in
Chrome stable. We might want to wait until it has propagated to Chrome
to stable. It should be in Chrome 136.
Follow up to #33027.
This enhances the heuristic so that we accumulate the size of the
currently written boundaries. Starting from the size of the root (minus
preamble) for the shell.
This ensures that if you have many small boundaries they don't all
continue to get inlined. For example, you can wrap each paragraph in a
document in a Suspense boundary to regain document streaming
capabilities if that's what you want.
However, one consideration is if it's worth producing a fallback at all.
Maybe if it's like `null` it's free but if it's like a whole alternative
page, then it's not. It's possible to have completely useless Suspense
boundaries such as when you nest several directly inside each other. So
this uses a limit of at least 500 bytes of the content itself for it to
be worth outlining at all. It also can't be too small because then for
example a long list of paragraphs can never be outlined.
In the fixture I straddle this limit so some paragraphs are too small to
be considered. An unfortunate effect of that is that you can end up with
some of them not being outlined which means that they appear out of
order. SuspenseList is supposed to address that but it's unfortunate.
The limit is still fairly high though so it's unlikely that by default
you'd start outlining anything within the viewport at all. I had to
reduce the `progressiveChunkSize` by an order of magnitude in my fixture
to try it out properly.
`requestFormReset` incorrectly tries to get the current dispatch queue
from the Fiber. However, the Fiber might be the workInProgress which is
an inconsistent state.
This hack just tries the other Fiber if it detects one of the known
inconsistent states but there can be more.
Really we should stash the dispatch queue somewhere stateful which is
effectively what `setState` does by binding it to the closure.
## Summary
We don't need the isArray check for this experiment, as
`fastAddProperties` already does the same. Also renaming
slowAddProperties to make it clearer we can fully remove this codepath
once fastAddProperties is fully rolled out.
## How did you test this change?
```
yarn test packages/react-native-renderer -r=xplat --variant=true
```
When we end up creating an incomplete state in the shell we end up not
flushing anything. As a hack, in this case we need to reset the
ResumableState because some of the ResumableState is still relevant
(e.g. any preloads that went into headers) but some of the
ResumableState needs to be reset since they assume that what we produced
actually flushed.
We didn't reset the instructions state but we haven't actually flushed
any of the instructions so it needs to reset.
Since the very beginning we have had the `progressiveChunkSize` option
but we never actually took advantage of it because we didn't count the
bytes that we emitted. This starts counting the bytes by taking a pass
over the added chunks each time a segment completes.
That allows us to outline a Suspense boundary to stream in late even if
it is already loaded by the time that back-pressure flow and in a
`prerender`. Meaning it gets inserted with script.
The effect can be seen in the fixture where if you have large HTML
content that can block initial paint (thanks to
[`rel="expect"`](https://github.com/facebook/react/pull/33016) but also
nested Suspense boundaries). Before this fix, the paint would be blocked
until the large content loaded. This lets us paint the fallback first in
the case that the raw bytes of the content takes a while to download.
You can set it to `Infinity` to opt-out. E.g. if you want to ensure
there's never any scripts. It's always set to `Infinity` in
`renderToHTML` and the legacy `renderToString`.
One downside is that if we might choose to outline a boundary, we need
to let its fallback complete.
We don't currently discount the size of the fallback but really just
consider them additive even though in theory the fallback itself could
also add significant size or even more than the content. It should maybe
really be considered the delta but that would require us to track the
size of the fallback separately which is tricky.
One problem with the current heuristic is that we just consider the size
of the boundary content itself down to the next boundary. If you have a
lot of small boundaries adding up, it'll never kick in. I intend to
address that in a follow up.
When effect dependencies cannot be inferred due to memoization-related
bailouts or unexpected mutable ranges (which currently often have to do
with writes to refs), fall back to traversing the effect lambda itself.
This fallback uses the same logic as PropagateScopeDependencies:
1. Collect a sidemap of loads and property loads
2. Find hoistable accesses from the control flow graph. Note that here,
we currently take into account the mutable ranges of instructions (see
`mutate-after-useeffect-granular-access` fixture)
3. Collect the set of property paths accessed by the effect
4. Merge to get the set of minimal dependencies
Inferred effect dependencies and inlined jsx (both experimental
features) rely on `InferReactivePlaces` to determine their dependencies.
Since adding type inference for phi nodes
(https://github.com/facebook/react/pull/30796), we have been incorrectly
inferring stable-typed value blocks (e.g. `props.cond ? setState1 :
setState2`) as non-reactive. This fix patches InferReactivePlaces
instead of adding a new pass since we want non-reactivity propagated
correctly
See https://github.com/rollup/plugins/issues/1425
Currently, `@babel/helper-string-parser/lib/index.js` is either emitted
as a wrapped esmodule or inline depending on the ordering of async
functions in `rollup/commonjs`. Specifically,
`@babel/types/lib/definitions/core.js` is cyclic (i.e. transitively
depends upon itself), but sometimes
`@babel/helper-string-parser/lib/index.js` is emitted before this is
realized.
A relatively straightforward patch is to wrap all modules (see
https://github.com/rollup/plugins/issues/1425#issuecomment-1465626736).
This only regresses `eslint-plugin-react-hooks` bundle size by ~1.8% and
is safer (see
https://github.com/rollup/plugins/blob/master/packages/commonjs/README.md#strictrequires)
> The default value of true will wrap all CommonJS files in functions
which are executed when they are required for the first time, preserving
NodeJS semantics. This is the safest setting and should be used if the
generated code does not work correctly with "auto". Note that
strictRequires: true can have a small impact on the size and performance
of generated code, but less so if the code is minified.
(note that we're on an earlier version of `@rollup/commonjs` which does
not default to `strictRequires: true`)
The semantics of React is that anything outside of Suspense boundaries
in a transition doesn't display until it has fully unsuspended. With SSR
streaming the intention is to preserve that.
We explicitly don't want to support the mode of document streaming
normally supported by the browser where it can paint content as tags
stream in since that leads to content popping in and thrashing in
unpredictable ways. This should instead be modeled explictly by nested
Suspense boundaries or something like SuspenseList.
After the first shell any nested Suspense boundaries are only revealed,
by script, once they're fully streamed in to the next boundary. So this
is already the case there. However, for the initial shell we have been
at the mercy of browser heuristics for how long it decides to stream
before the first paint.
Chromium now has [an API explicitly for this use
case](https://developer.mozilla.org/en-US/docs/Web/API/View_Transition_API/Using#stabilizing_page_state_to_make_cross-document_transitions_consistent)
that lets us model the semantics that we want. This is always important
but especially so with MPA View Transitions.
After this a simple document looks like this:
```html
<!DOCTYPE html>
<html>
<head>
<link rel="expect" href="#«R»" blocking="render"/>
</head>
<body>
<p>hello world</p>
<script src="bootstrap.js" id="«R»" async=""></script>
...
</body>
</html>
```
The `rel="expect"` tag indicates that we want to wait to paint until we
have streamed far enough to be able to paint the id `"«R»"` which
indicates the shell.
Ideally this `id` would be assigned to the root most HTML element in the
body. However, this is tricky in our implementation because there can be
multiple and we can render them out of order.
So instead, we assign the id to the first bootstrap script if there is
one since these are always added to the end of the shell. If there isn't
a bootstrap script then we emit an empty `<template
id="«R»"></template>` instead as a marker.
Since we currently put as much as possible in the shell if it's loaded
by the time we render, this can have some negative effects for very
large documents. We should instead apply the heuristic where very large
Suspense boundaries get outlined outside the shell even if they're
immediately available. This means that even prerenders can end up with
script tags.
We only emit the `rel="expect"` if you're rendering a whole document.
I.e. if you rendered either a `<html>` or `<head>` tag. If you're
rendering a partial document, then we don't really know where the
streaming parts are anyway and can't provide such guarantees. This does
apply whether you're streaming or not because we still want to block
rendering until the end, but in practice any serialized state that needs
hydrate should still be embedded after the completion id.
Previously the CompileSuccess event would emit first before CompileSkip,
so the lsp's codelens would incorrectly flag skipped components/hooks
(via 'use no memo') as being optimized.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/33012).
* __->__ #33012
* #33011
* #33010
Adds a new codeaction event in the compiler and handler in forgive. This
allows you to remove a dependency array when you're editing a range that
is within an autodep eligible function.
Co-authored-by: Jordan Brown <jmbrown@meta.com>
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/33000).
* #33002
* #33001
* __->__ #33000
Co-authored-by: Jordan Brown <jmbrown@meta.com>
Stacked on #32862 and #32842.
This means that Activity boundaries now act as boundaries which can have
their effects mounted independently. Just like Suspense boundaries, we
hydrate the outer content first and then start hydrating the content in
an Offscreen lane. Flowing props or interacting with the content
increases the priority just like Suspense boundaries.
This skips emitting even the comments for `<Activity mode="hidden">` so
we don't hydrate those. Instead those are deferred to a later client
render.
The implementation are just forked copies of the SuspenseComponent
branches and then carefully going through each line and tweaking it.
The main interesting bit is that, unlike Suspense, Activity boundaries
don't have fallbacks so all those branches where you might commit a
suspended tree disappears. Instead, if something suspends while
hydration, we can just leave the dehydrated content in place. However,
if something does suspend during client rendering then it should bubble
up to the parent. Therefore, we have to be careful to only
pushSuspenseHandler when hydrating. That's really the main difference.
This just uses the existing basic Activity tests but I've started work
on port all of the applicable Suspense tests in SelectiveHydration-test
and PartialHydration-test to Activity versions.
Stacked on #32851 and #32900.
This implements the equivalent Configs for ActivityInstance as we have
for SuspenseInstance. These can be implemented as comments but they
don't have to be and can be implemented differently in the renderer.
This seems like a lot duplication but it's actually ends mostly just
calling the same methods underneath and the wrappers compiles out.
This doesn't leave the Activity dehydrated yet. It just hydrates into it
immediately.
I think this was probably just copy-paste from the Suspense path.
It shouldn't matter what the previous state of an Offscreen boundary
was. What matters is that it's now hidden and therefore if it suspends,
we can just leave it as is without the tree becoming inconsistent.
Found this bug while working on Activity. There's a weird edge case when
a dehydrated Suspense boundary is a direct child of another Suspense
boundary which is hydrated but then it resuspends without forcing the
inner one to hydrate/delete.
It used to just leave that in place because hiding/unhiding didn't deal
with dehydrated fragments.
Not sure this is really worth fixing.
Summary: We landed on not including fire functions in dep arrays. They
aren't needed because all values returned from the useFire hook call
will read from the same ref. The linter will error if you include a
fired function in an explicit dep array.
Test Plan: yarn snap --watch
--
I found a bug even before the Activity hydration stuff.
If we're hydrating an Offscreen boundary in its "hidden" state it won't
have any content to hydrate so will trigger hydration errors (which are
then eaten by the Offscreen boundary itself). Leaving it not prewarmed.
This doesn't happen in the simple case because we'd be hydrating at a
higher priority than Offscreen at the root, and those are deferred to
Offscreen by not having higher priority. However, we've hydrating at the
Offscreen priority, which we do inside Suspense boundaries, then it
tries to hydrate against an empty set.
I ended up moving this to the Activity boundary in a future PR since
it's the SSR side that decided where to not render something and it only
has a concept of Activity, no Offscreen.
1dc05a5e22 (diff-d5166797ebbc5b646a49e6a06a049330ca617985d7a6edf3ad1641b43fde1ddfR1111)
Since `hidden` is a prop on arbitrary DOM elements it's a common mistake
to think that it would also work that way on `<Activity>` but it
doesn't. In fact, we even had this mistakes in our own tests.
Maybe there's an argument that we should actually just support it but we
also have more modes planned.
So this adds a warning. It should also already be covered by TypeScript.
There's really no need to even run the workflow for non-members or
collaborators for the labeling and discord notification workflows. We
can exit early.
This change adds a background color to Toggles to make them easier to
see. This is especially important when DevTools are not in focus, and
it's harder to see.
Test plan:
1. `yarn build:chrome:local`
2. Inspect components
3. Hover over "Select an Element in page to inspect it"
4. Observe background change
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
This PR adds support for displaying the names of changed hooks directly
in the Profiler tab, making it easier to identify specific updates.
A `HookChangeSummary` component has been introduced to show these hook
names, with a `displayMode` prop that toggles between `“compact”` for
tooltips and `“detailed”` for more in-depth views. This keeps tooltip
summaries concise while allowing for a full breakdown where needed.
This functionality also respects the `“Always parse hook names from
source”` setting from the Component inspector, as it uses the same
caching mechanism already in place for the Components tab. Additionally,
even without hook names parsed, the Profiler will now display hook types
(like `State`, `Callback`, etc.) based on data from `inspectedElement`.
To enable this across the DevTools, `InspectedElementContext` has been
moved higher in the component tree, allowing it to be shared between the
Profiler and Components tabs. This update allows hook name data to be
reused across tabs without duplication.
Additionally, a `getAlreadyLoadedHookNames` helper function was added to
efficiently access cached hook names, reducing the need for repeated
fetching when displaying changes.
These changes improve the ability to track specific hook updates within
the Profiler tab, making it clearer to see what’s changed.
### Before
Previously, the Profiler tab displayed only the IDs of changed hooks, as
shown below:
<img width="350" alt="Screenshot 2024-11-01 at 12 02 21_cropped"
src="https://github.com/user-attachments/assets/7a5f5f67-f1c8-4261-9ba3-1c76c9a88af3">
### After (without hook names parsed)
When hook names aren’t parsed, custom hooks and hook types are displayed
based on the inspectedElement data:
<img width="350" alt="Screenshot 2024-11-01 at 12 03 09_cropped"
src="https://github.com/user-attachments/assets/ed857a6d-e6ef-4e5b-982c-bf30c2d8a7e2">
### After (with hook names parsed)
Once hook names are fully parsed, the Profiler tab provides a complete
breakdown of specific hooks that have changed:
<img width="350" alt="Screenshot 2024-11-01 at 12 03 14_cropped"
src="https://github.com/user-attachments/assets/1ddfcc35-7474-4f4d-a084-f4e9f993a5bf">
This should resolve#21856🎉
It used to be that in `__DEV__` we wrapped this `renderWithHooks`,
`checkDidRenderIdHook` pair in calls to `setIsRendering()`. However,
that dev-only bookkeeping was removed in
https://github.com/facebook/react/pull/29206 leaving this redundant
check which runs identical code in dev and in prod.
## Test Plan
* Manually confirm both cases are the same
* GitHub CI tests
We use the Update flag to track if a View Transition had any mutations
or relayout. Unlike the other usage of it, this is just temporary state
during the commit phase.
Normally the flags gets used in the render phase and we reset it when we
rerender but in the case of "nested" updates, those trees didn't update.
We're only looking for relayouts. So we need to manually reset it before
we start using it.
We probably shouldn't abuse the Update flag for this and instead use
something like temporary state on ViewTransitionState.
This lets us write them early in the render phase.
This should be safe because even if we write them deeply, then they
still can't be wrapped by a element because then they'd no longer be in
the document scope anymore. They end up flat in the body and so when we
search the content we'll discover them.
## Summary
This fixes how we map priorities between Fabric and the React
reconciler. At the moment, we're only considering default and discrete
priorities, when there's a larger range of priorities available.
In Fabric, we'll test supporting additional priorities soon. For that
test to do something useful, we need the new priorities to be mapped to
reconciler priorities correctly, which is what this change is done.
> [!IMPORTANT]
> At the moment, this is a no-op because Fabric is only reporting
default and discrete event priorities.
## How did you test this change?
Will test e2e on React Native on top of
https://github.com/facebook/react-native/pull/50627
The changes are gated in React Native, so we'll use that feature flag to
test this.
Stacked on #32838.
We don't always type the Props of built-ins. This adds typing for most
of the built-ins.
When we did type them, we used to put it in the `ReactFiber...Component`
files but any public API like this can be implemented in other renderers
too such as Fizz. So I moved them to `shared/ReactTypes` which is where
we put other public API types (that are not already built-in to Flow).
That way Fizz can import them and assert properly when it accesses the
props.
This rule currently has a few false positives, so let's disable it for
now (just in the eslint rule, it's still enabled in the compiler) while
we iterate on it.
Uses `&` for Activity as opposed to `$` for Suspense. This will be used
to delimitate which nodes we can skip hydrating.
This isn't used on the client yet. It's just a noop on the client
because it's just an unknown comment. This just adds the SSR parts.
Activity is a client component, but you should still be able to import
it and render it from a Server Component. Same as what we do with other
types like Suspense and ViewTransition.
Even if the `enableSuspenseyImages` flag is off.
Started View Transitions already wait for Suspensey Fonts and this is
another Suspensey feature that is even more important for View
Transitions - even though we eventually want it all the time. So this
uses `<ViewTransition>` as an early opt-in for that tree into Suspensey
Images, which we can ship in a minor.
If you're doing an update inside a ViewTransition then we're eligible to
start a ViewTransition in any Transition that might suspend. Even if
that doesn't end up animating after all, we still consider it Suspensey.
We could try to suspend inside the startViewTransition but that's not
how it would work with `enableSuspenseyImages` on and we can't do that
for startGestureTransition.
Even so we still need some opt-in to trigger the Suspense fallback even
before we know whether we'll animate or not. So the simple solution is
just that `<ViewTransition>` opts in the whole subtree into Suspensey
Images in general.
In this PR I disable `enableSuspenseyImages` in experimental so that we
can instead test the path that only enables it inside `<ViewTransition>`
tree since that's the path that would next graduate to a minor.
Behind the `enableSrcObject` flag. This is revisiting a variant of what
was discussed in #11163.
Instead of supporting the [`srcObject`
property](https://developer.mozilla.org/en-US/docs/Web/API/HTMLMediaElement/srcObject)
as a separate name, this adds an overload of `src` to allow objects to
be passed. The DOM needs to add separate properties for the object forms
since you read back but it doesn't make sense for React's write-only API
to do that. Similar to how we'll like add an overload for
`popoverTarget` instead of calling it `popoverTargetElement` and how
`style` accepts an object and it's not `styleObject={{...}}`.
There are a number of reason to revisit this.
- It's just way more convenient to have this built-in and it makes
conceptual sense. We typically support declarative APIs and polyfill
them when necessary.
- RSC supports Blobs and by having it built-in you don't need a Client
Component wrapper to render it where as doing it with effects would
require more complex wrappers. By picking Blobs over base64,
client-navigations can use the more optimized binary encoding in the RSC
protocol.
- The timing aspect of coordinating it with Suspensey images and image
decoding is a bit tricky to get right because if you set it in an effect
it's too late because you've already rendered it.
- SSR gets complicated when done in user space because you have to
handle both branches. Likely with `useSyncExternalStore`.
- By having it built-in we could optimize the payloads shared between
RSC payloads embedded in the HTML and data URLs.
This does not support objects for `<source src>` nor `<img srcset>`.
Those don't really have equivalents in the DOM neither. They're mainly
for picking an option when you don't know programmatically. However, for
this use case you're really better off picking a variant before
generating the blobs.
We may support Response objects in the future too as per
https://github.com/whatwg/fetch/issues/49
When `startTime` still has its initial value of `-1.1` we must not call
`logComponentMount`. This can occur when rendering a `'next/dynamic'`
component with `{ssr: false}` in a client component, for example.
Unfortunately, I didn't manage to reproduce this scenario in a unit
test.
Safari has a bug where if you put a block element inside an inline
element and the inline element has a `view-transition-name` assigned it
finds it as duplicate names.
https://bugs.webkit.org/show_bug.cgi?id=290923
This adds a warning if we detect this scenario in dev mode.
For the case where it renders into a single block, we can model this by
making the parent either `block` or `inline-block` automatically to fix
the issue. So we do that to automatically cover simple cases like
`<a><div>...</div></a>`. This unfortunately causes layout/styling thrash
so we might want to delete it once the bug has been fixed in enough
Safari versions.
Found a bug that occurs during a specific combination of very subtle
implementation details.
It occurs sometimes (not always) when 1) a transition is scheduled
during a popstate event, and 2) as a result, a new value is passed to an
already-mounted useDeferredValue hook.
The fix is relatively straightforward, and I found it almost
immediately; it took a bit longer to figure out exactly how the scenario
occurred in production and create a test case to simulate it.
Rather than couple the test to the implementation details, I've chosen
to keep it as high-level as possible so that it doesn't break if the
details change. In the future, it might not be trigger the exact set of
internal circumstances anymore, but it could be useful for catching
similar bugs because it represents a realistic real world situation —
namely, switching tabs repeatedly in an app that uses useDeferredValue.
We've known we've wanted this for many years and most of the
implementation was already done for Suspensey CSS. This waits to commit
until images have decoded by default or up to 500ms timeout (same as
suspensey fonts).
It only applies to Transitions, Retries (Suspense), Gesture Transitions
(flag) and Idle (doesn't exist). Sync updates just commit immediately.
`<img loading="lazy" src="..." />` opts out since you explicitly want it
to load lazily in that case.
`<img onLoad={...} src="..." />` also opts out since that implies you're
ok with managing your own reveal.
In the future, we may add an opt in e.g. `<img blocking="render"
src="..." />` that opts into longer timeouts and re-suspends even sync
updates. Perhaps also triggering error boundaries on errors.
The rollout for this would have to go in a major and we may have to
relax the default timeout to not delay too much by default. However, we
can also make this part of `enableViewTransition` so that if you opt-in
by using View Transitions then those animations will suspend on images.
That we could ship in a minor.
Stacked on #32815.
To be able to differentiate mounted subtrees from updated subtrees. This
adds a yellow entry above the component subtree that mounted. This is
added both to the render phase, mutation effect phase, layout effect
phase and passive effect phase.
<img width="962" alt="Screenshot 2025-04-03 at 10 41 02 PM"
src="https://github.com/user-attachments/assets/13777347-07e8-458c-9127-8675ef08b54f"
/>
Ideally we could probably give an annotation to the component instead of
adding a whole other line which is also a color that's kind of
distracting. However, not all components are included and keeping track
of which one is the first one below is kind of annoying. Adding a marker
to all components is kind of noisy. So this is a compromise. It's only
one per depth so it won't make it too deep even on larger trees.
If this is an unmount, those are added to the mutation effect phase for
the layout unmounts and passive unmount effect phase. Since these never
have a render, they're not in the render phase.
<img width="1010" alt="Screenshot 2025-04-03 at 11 05 57 PM"
src="https://github.com/user-attachments/assets/ab39f27e-13be-4281-94fa-9391bb293fd2"
/>
For showing / hiding `<Activity>` the terminology "Reconnect" and
"Disconnect" is used instead.
This fixes two bugs with commit phase effect tracking.
I missed, or messed up the rebase for, deletion effects when a subtree
was deleted and for passive disconnects when a subtree was hidden.
The other bug is that when I started using self time
(componentEffectDuration) for color and for determining whether to
bother logging an entry, I didn't consider that the component with
effects can have children which end up resetting this duration before we
log. Which lead to most effects not having their components logged since
they almost always have children.
We don't necessarily have to push/pop but we have to store at least one
thing on the stack unfortunately. That's because we have to do the
actual log after the children to get the right end time. So might as
well use the push/pop strategy like the rest of them.
Native only. Displays the native tag for Native Host components inside a
badge, when user inspects the component.
Only displaying will be supported for now, because in order to get
native tags indexable, they should be part of the bridge operations,
which is technically a breaking change that requires significantly more
time investment.
The text will only be shown when user hovers over the badge.

Rename "Suspended" commit to "Suspended on CSS" since that's the only
reason for this particular branch. This will not hold true because with
suspended images and with view transitions those can also be the reason.
So in the future we need to add those.
Only log "Blocked" in the components track if we yield for 3ms or
longer. It's common to have like 1-2ms yield times for various reasons
going on which is not worth the noise to consider "blocking".
Rename "Blocked" to "Update" in the Blocking/Transition tracks. This is
when a setState happens and with stack traces it's where you should look
for the stack trace of the setState. So we want to indicate that this is
the "Update".
I only added the "Blocked" part if we're blocked for more than 5ms
before we can start rendering - indicating that some other track was
working at the same time and preventing us from rendering.
This can happen for example if you have duplicate names in the "old"
state. This errors the transition before the updateCallback is invoked
so we haven't yet applied mutations etc.
This runs through those phases after the error to get us back to a
consistent state.
The problem with setting both `children` or `dangerouslySetInnerHTML`
and also using a ref on a DOM node to either manually append children or
using it as a Container for `createRoot` or `createPortal` is that it's
ambiguous which children should win. Ideally you use one of the four
options to control children. Meaning that ideally you always use a leaf
container for refs like this.
Unfortunately it's very common to use a React owned thing with children
as a Container of a Portal. For example `document.body` can have both
regular React children and be used as a Portal container. This isn't
really fully supported and has some undefined behavior like relative
order isn't guaranteed but still very common.
It is extra bad if the children are a `string`/`number` or if
`dangerouslySetInnerHTML` is set. Because then when ever that reactively
updates it'll clear out any manually added DOM nodes. When this happens
isn't guaranteed. It's always happening as far as the reactivity is
concerned. See https://github.com/facebook/react/issues/31600
Therefore, we should warn for this specific pattern. This still allows
non-text children as a compromise even though that behavior is also
somewhat undefined.
Stacked on #32793.
This is meant to model the intended semantics of `addTransitionType`
better. The previous hack just consumed all transition types when any
root committed so it could steal them from other roots. Really each root
should get its own set. Really each transition lane should get its own
set.
We can't implement the full ideal semantics yet because 1) we currently
entangle transition lanes 2) we lack `AsyncContext` on the client so for
async actions we can't associate a `addTransitionType` call to a
specific `startTransition`.
This starts by modeling Transition Types to be stored on the Transition
instance. Conceptually they belong to the Transition instance of that
`startTransition` they belong to. That instance is otherwise mostly just
used for Transition Tracing but it makes sense that those would be able
to be passed the Transition Types for that specific instance.
Nested `startTransition` need to get entangled. So that this
`addTransitionType` can be associated with the `setState`:
```js
startTransition(() => {
startTransition(() => {
addTransitionType(...)
});
setState(...);
});
```
Ideally we'd probably just use the same Transition instance itself since
these are conceptually all part of one entangled one. But transition
tracing uses multiple names and start times. Unclear what we want to do
with that. So I kept separate instances but shared `types` set.
Next I collect the types added during a `startTransition` to any root
scheduled with a Transition. This should really be collected one set per
Transition lane in a `LaneMap`. In fact, the information would already
be there if Transition Tracing was always enabled because it tracks all
Transition instances per lane. For now I just keep track of one set for
all Transition lanes. Maybe we should only add it if a `setState` was
done on this root in this particular `startTransition` call rather
having already scheduled any Transition earlier.
While async transitions are entangled, we don't know if there will be a
startTransition+setState on a new root in the future. Therefore, we
collect all transition types while this is happening and if a new root
gets startTransition+setState they get added to that root.
```js
startTransition(async () => {
addTransitionType(...)
await ...;
setState(...);
});
```
Stacked on #32792.
It's tricky to associate a specific `addTransitionType` call to a
specific `startTransition` call because we don't have `AsyncContext` in
browsers yet. However, we can keep track if there are any async
transitions running at all, and if not, warn. This should cover most
cases.
This also errors when inside a React render which might be a legit way
to associate a Transition Type to a specific render (e.g. based on props
changing) but we want to be a more conservative about allowing that yet.
If we wanted to support calling it in render, we might want to set which
Transition object is currently rendering but it's still tricky if the
render has `async function` components. So it might at least be
restricted to sync components (like Hooks).
Stacked on #32788.
Normally we track `addTransitionType` globally because of the async gap
that can happen in Actions where we lack AsyncContext to associate it
with a particular Transition. This unfortunately also means it's
possible to call outside of `startTransition` which is something we want
to warn for.
We need to be able to distinguish whether `addTransitionType` is for a
regular Transition or a Gesture Transition though.
Since `startGestureTransition` is only synchronous we can track it
within that execution scope and move it to a separate set. Since we know
for sure which call owns it we can properly associate it with that
specific provider's `ScheduledGesture`.
This does not yet handle calling `addTransitionType` inside the render
phase of a gesture. That would currently still be associated with the
next Transition instead.
When different animations in a View Transition have different durations,
we shouldn't stretch them out to run the full range of swipe. Because
then they wouldn't line up the same way as when played using plain time.
This adjusts the range start/end to be what it would've been when played
by time. Except since we are playing animations in reverse, the
animation-delay is actually applied from the range end and then the
duration from there to get closer to the start.
Reverse the range if the original animation was reversed.
Interestingly, the range it takes can be adjusted by what is in the
viewport since if a long duration animation is excluded then everything
else adjusts too.
I left some todos too. We really should also handle if the original
animation has multiple iterations. Currently we only play those once.
Stacked on #32785.
This is now replaced by `startGestureTransition` added in #32785.
I also renamed the flag from `enableSwipeTransition` to
`enableGestureTransition` to correspond to the new name.
Stacked on #32783. This will replace [the `useSwipeTransition`
API](https://github.com/facebook/react/pull/32373).
Instead, of a special Hook, you can make updates to `useOptimistic`
Hooks within the `startGestureTransition` scope.
```
import {unstable_startGestureTransition as startGestureTransition} from 'react';
const cancel = startGestureTransition(timeline, () => {
setOptimistic(...);
}, options);
```
There are some downsides to this like you can't define two directions as
once and there's no "standard" direction protocol. It's instead up to
libraries to come up with their own conventions (although we can suggest
some).
The convention is still that a gesture recognizer has two props `action`
and `gesture`. The `gesture` prop is a Gesture concept which now behaves
more like an Action but 1) it can't be async 2) it shouldn't have
side-effects. For example you can't call `setState()` in it except on
`useOptimistic` since those can be reverted if needed. The `action` is
invoked with whatever side-effects you want after the gesture fulfills.
This is isomorphic and not associated with a specific renderer nor root
so it's a bit more complicated.
To implement this I unify with the `ReactSharedInternal.T` property to
contain a regular Transition or a Gesture Transition (the `gesture`
field). The benefit of this unification means that every time we
override this based on some scope like entering `flushSync` we also
override the `startGestureTransition` scope. We just have to be careful
when we read it to check the `gesture` field to know which one it is.
(E.g. I error for setState / requestFormReset.)
The other thing that's unique is the `cancel` return value to know when
to stop the gesture. That cancellation is no longer associated with any
particular Hook. It's more associated with the scope of the
`startGestureTransition`. Since the schedule of whether a particular
gesture has rendered or committed is associated with a root, we need to
somehow associate any scheduled gestures with a root.
We could track which roots we update inside the scope but instead, I
went with a model where I check all the roots and see if there's a
scheduled gesture matching the timeline. This means that you could
"retain" a gesture across roots. Meaning this wouldn't cancel until both
are cancelled:
```
const cancelA = startGestureTransition(timeline, () => {
setOptimisticOnRootA(...);
}, options);
const cancelB = startGestureTransition(timeline, () => {
setOptimisticOnRootB(...);
}, options);
```
It's more like it's a global transition than associated with the roots
that were updated.
Optimistic updates mostly just work but I now associate them with a
specific "ScheduledGesture" instance since we can only render one at a
time and so if it's not the current one, we leave it for later.
Clean up of optimistic updates is now lazy rather than when we cancel.
Allowing the cancel closure not to have to be associated with each
particular update.
This is some overdue refactoring. The two types never made sense. It
also should be defined by isomorphic since it defines how it should be
used by renderers rather than isomorphic depending on Fiber.
Clean up hidden classes to be consistent.
Fix missing name due to wrong types. I choose not to invoke the
transition tracing callbacks if there's no name since the name is
required there.
This was a template for the 19 beta. Since 19 has been stable for a
while now, we can clean this up. Any bug report for React 19 should use
the standard bug report template.
Portals and `<ViewTransition>` are tricky because they leave the React
tree. You might think of a Portal's container conceptually as also being
part of a React tree but that's not quite how they're modeled today.
They're more like their own roots. So instead, of trying to find a
conceptual place in the React tree we treat Portals as their own root.
We have two ways of tracking whether an update to a ViewTransition
boundary has occurred. Either a DOM mutation has happened within it, or
a resize of a child has caused it to potentially relayout its parent.
Normally that just follows the tree structure of React, but not when
it's a Portal.
When it's a Portal we don't know which DOM parent it might have
affected. For all we know it's at the root (and in fact, in most cases
that's where Portals go).
With this PR we mark the root as having been affected by a mutation or
resize. This means that the whole document will animate and we can't
optimize away from it. This ensures that a mutation to the root of a
Portal doesn't go unanimated with other things are animating such as its
parent.
You can regain this optimization by adding a `<ViewTransition>` boundary
directly inside the Portal itself so it owns its own animation. If that
DOM node is also absolutely positioned it doesn't leak.
Conversely this also means that a mutation inside a Portal doesn't
affect its React parent so it won't trigger its parent's animation if
this was the only thing animating. That could be unfortunate if this
container is actually inside the same React parent. However, because
this would have been an update we would've marked it for "maybe
animating" and updates can't only get their animations cancelled if the
root is cancelled, in practice this will actually animate anyway.
Accidentally broke this when migrating our test runner to use the
bundled build https://github.com/facebook/react/pull/32758
The fix is pretty simple. File watcher should listen for changes in
`packages/babel-plugin-react-compiler` instead of `cwd`, which is now
`packages/snap`.
From what we can see, `build-info.json` is a vestigal file that we were
previously including in builds but are no longer since 2022 (see
https://github.com/facebook/react/pull/23257, which removes
`build-info.json` which would have broken
scripts/release/build-release-locally-commands/add-build-info-json.js).
Since this file is no longer built, instead of looking it up we default
to the `version` that was passed in as an argument to
scripts/release/prepare-release-from-npm.js. Since `version` is what is
pulled from npm, there should only be 1 consistent version for all the
packages that are pulled. Therefore, only 1 version (eg canary) needs to
be replaced to the new stable version.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32778).
* __->__ #32778
* #32777
Currently, inferred effect dependencies are considered a
"compiler-required" feature. This means that untransformed callsites
should escalate to a build error.
`ValidateNoUntransformedReferences` iterates 'special effect' callsites
and checks that the compiler was able to successfully transform them.
Prior to this PR, this relied on checking the number of arguments passed
to this special effect.
This obviously doesn't work with `noEmit: true`, which is used for our
eslint plugin (this avoids mutating the babel program as other linters
run with the same ast). This PR adds a set of `babel.SourceLocation`s to
do best effort matching in this mode.
Typically we mark the name of things that might animate in the snapshot
phase. At the same time we track that should call startViewTransition
too. However, we don't do this for "enter" since they're only marked
later. Leading to having just an "enter" not to animate unless there's
at least another update too.
This tracks if there's a ViewTransitionComponent in the tree that
enters. Luckily we know that from the static flag so we don't have to
traverse it.
Stacked on https://github.com/facebook/react/pull/32734
In React a ViewTransition class of `"none"` doesn't just mean that it
has no class but also that it has no ViewTransition name. The default
(`null | undefined`) means that it has no specific class but should run
with the default built-in animation. This adds this as an explicit
string called `"auto"` as well.
That way you can do `<ViewTransition default="foo" enter="auto">` to
override the "foo" just for the "enter" trigger to be the default
built-in animation. Where as if you just specified `null` it would be
like not specifying enter at all which would trigger "foo".
It was always confusing that this is not a CSS class but a
view-transition-class.
The `className` sticks out a bit among its siblings `enter`, `exit`,
`update` and `share`. The idea is that the most specific definition
override is the class name that gets applied and this prop is really
just the fallback, catch-all or "any" that is applied if you didn't
specify a more specific one.
It has also since evolved not just to take a string but also a map of
Transition Type to strings.
The "class" is really the type of the value. We could add a suffix to
all of them like `defaultClass`, `enterClass`, `exitClass`,
`updateClass` and `shareClass`. However, this doesn't necessarily make
sense with the mapping of Transition Type to string. It also makes it a
bit too DOM centric. In React Native this might still be called a
"class" but it might be represented by an object definition. We might
even allow some kind of inline style form for the DOM too. Really this
is about picking which "animation" that runs which can be a string or
instance. "Animation" is too broad because there's also a concept of a
CSS Animation and these are really sets of CSS animations (group,
image-pair, old, new). It could maybe be `defaultTransition`,
`enterTransition`, etc but that seems unnecessarily repetitive and still
doesn't say anything about it being a class.
We also already have the name "default" in the map of Transition Types.
In fact you can now specify a default for default:
```
<ViewTransition default={{"navigation-back": "slide-out", "default": "fade-in"}}>
```
One thing I don't like about the name `"default"` is that it might be
common to just apply a named class that does it matching to
enter/exit/update in the CSS selectors (such as the `:only-child` rule)
instead of doing that mapping to each one using React. In that can you
end up specifying only `default={...}` a lot and then what is it the
"default" for? It's more like "all". I think it's likely that you end up
with either "default" or the specific forms instead of both at once.
Starting a View Transition is an async sequence. Since React can get a
sync update in the middle of sequence we sometimes interrupt that
sequence.
Currently, we don't actually cancel the View Transition so it can just
run as a partial. This ensures that we fully skip it when that happens,
as well as warn.
However, it's very easy to trigger this with just a setState in
useLayoutEffect right now. Therefore if we're inside the preparing
sequence of a startViewTransition, this delays work that would've
normally flushed in a microtask. ~Maybe we want to do the same for
Default work already scheduled through a scheduler Task.~ Edit: This was
already done.
`flushSync` currently will still lead to an interrupted View Transition
(with a warning). There's a tradeoff here whether we want to try our
best to preserve the guarantees of `flushSync` or favor the animation.
It's already possible to suspend at the root with `flushSync` which
means it's not always 100% guaranteed to commit anyway. We could treat
it as suspended. But let's see how much this is a problem in practice.
Currently, `babel-plugin-react-compiler` is bundled with (almost) all
external dependencies. This is because babel traversal and ast logic is
not forward-compatible. Since `babel-plugin-react-compiler` needs to be
compatible with babel pipelines across a wide semvar range, we (1) set
this package's babel dependency to an early version and (2) inline babel
libraries into our bundle.
A few other packages in `react/compiler` depend on the compiler. This PR
moves `snap`, our test fixture compiler and evaluator, to use the
bundled version of `babel-plugin-react-compiler`. This decouples the
babel version used by `snap` with the version used by
`babel-plugin-react-compiler`, which means that `snap` now can test
features from newer babel versions (see
https://github.com/facebook/react/pull/32742).
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32758).
* #32759
* __->__ #32758
https://github.com/facebook/react/pull/32529 added a dynamic flag for
this, but that breaks tests since the flags are not defined everywhere.
However, this is a static value and the flag is only for supporting
existing tests. So we can override it in the test config, and make it
static at built time instead.
This adds early logging when two ViewTransitions with the same name are
mounted at the same time. Whether they're part of a View Transition or
not.
This lets us include the owner stack of each one. I do two logs so that
you can get the stack trace of each one of the duplicates.
It currently only logs once for each name which also avoids the scenario
when you have many hits for the same name in one commit. However, we
could also possibly log a stack for each of them but seems noisy.
Currently we don't log if a SwipeTransition is the first time the pair
gets mounted which could lead to a View Transition error before we've
warned. That could be a separate improvement.
This got moved into the functional component and class component case
statements here:
0de1233fd1.
So that we could separate the error case for class components.
However, due to a faulty rebase this got restored at the top as well.
Leading to double component renders being logged.
In the other offscreen reconnect passes we don't do this in each case
statement but still once at the top. The reason this doesn't matter is
because use the PerformedWork flag and that is only set for function and
class components. Although maybe it should be set for expensive DOM
components too and then we have to remember this.
Casing was incorrect.
Tested by running locally with a PAT.
```
$ scripts/release/download-experimental-build.js --commit=2d40460cf768071d3a70b4cdc16075d23ca1ff25
Command failed: gh attestation verify artifacts_combined.zip --repo=facebook/react
Error: failed to fetch attestations from facebook/react: HTTP 404: Not Found (https://api.github.com/repos/facebook/react/attestations/sha256:23d05644f9e49e02cbb441e3932cc4366b261826e58ce222ea249a6b786f0b5f?per_page=30)
`gh attestation verify artifacts_combined.zip --repo=facebook/react` (exited with error code 1)
$ scripts/release/download-experimental-build.js --commit=2d40460cf768071d3a70b4cdc16075d23ca1ff25 --noVerify
⠼ Downloading artifacts from GitHub for commit 2d40460cf7) 5% 0.1m, estimated 1.6m
✓ Downloading artifacts from GitHub for commit 2d40460cf7) 9.5 secs
An experimental build has been downloaded!
You can download this build again by running:
scripts/download-experimental-build.js --commit=2d40460cf768071d3a70b4cdc16075d23ca1ff25
```
We now generate attestations in `process_artifacts_combined` so we can
verify the provenance of the build later in other workflows. However,
this requires `write` permissions for `id-token` and `attestations` so
PRs from forks cannot generate this attestation.
To get around this, I added a `--no-verify` flag to
scripts/release/download-experimental-build.js. This flag is only passed
in `runtime_build_and_test.yml` for the sizebot job, since 1) the
workflow runs in the `pull_request` trigger which has read-only
permissions, and 2) the downloaded artifact is only used for sizebot
calculation, and not actually used.
The flag is explicitly not passed in `runtime_commit_artifacts.yml`
since there we actually use the artifact internally. This is fine as
once a PR lands on main, it will then run the build on that new commit
and generate an attestation.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32738).
* #32739
* __->__ #32738
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
1. Having a development build for FB will be convenient for fb internal
feature development
2. Add a new checkbox to toggle new internal features added to React
Devtools.
## How did you test this change?
1. yarn test
2. set extra env variables in bash profile and build an internal version
with the new script.
3. toggle on/off the new checkbox, the value is stored in local storage
correctly.
---------
Co-authored-by: Aohua Mu <muaohua@fb.com>
Uses https://cli.github.com/manual/gh_attestation_verify to verify that
the downloaded artifact matches the attestation generated during the
build process in runtime_commit_artifacts.
Example:
On a workflow run of runtime_build_and_test.yml with no attestations:
```
$ scripts/release/download-experimental-build.js --commit=ea5f065745b777cb41cc9e54a3b29ed8c727a574
Command failed: gh attestation verify artifacts_combined.zip --repo=facebook/react
Error: failed to fetch attestations from facebook/react: HTTP 404: Not Found (https://api.github.com/repos/facebook/react/attestations/sha256:7adba0992ba477a927aad5a07f95ee2deb7d18427c84279d33fc40a3bc28ebaa?per_page=30)
`gh attestation verify artifacts_combined.zip --repo=facebook/react` (exited with error code 1)
```
On one which does:
```
$ scripts/release/download-experimental-build.js --commit=12e85d74c1c233cdc2f3228a97473a4435d50c3b
✓ Downloading artifacts from GitHub for commit 12e85d74c1) 10.5 secs
An experimental build has been downloaded!
You can download this build again by running:
scripts/download-experimental-build.js --commit=12e85d74c1c233cdc2f3228a97473a4435d50c3b
```
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32728).
* #32729
* __->__ #32728
Need this to run against target for forks to get the notification.
This job does not checkout the code in the PR, so it's safe to run from
the target.
Also fixes failing checks on PRs:
<img width="870" alt="Screenshot 2025-03-24 at 3 28 30 PM"
src="https://github.com/user-attachments/assets/add78287-6449-4e48-9376-f3b360d2607c"
/>
(Found when compiling Meta React code)
Let variable declarations and reassignments are currently rewritten to
`StoreLocal <varName>` instructions, which each translates to a new
`const varName` declaration in codegen.
```js
// Example input
function useHook() {
const getX = () => x;
let x = CONSTANT1;
if (cond) {
x += CONSTANT2;
}
return <Stringify getX={getX} />
}
// Compiled output, prior to this PR
import { c as _c } from "react/compiler-runtime";
function useHook() {
const $ = _c(1);
let t0;
if ($[0] === Symbol.for("react.memo_cache_sentinel")) {
const getX = () => x;
let x = CONSTANT1;
if (cond) {
let x = x + CONSTANT2;
x;
}
t0 = <Stringify getX={getX} />;
$[0] = t0;
} else {
t0 = $[0];
}
return t0;
}
```
This also manifests as a babel internal error when replacing the
original function declaration with the compiler output. The below
compilation output fails with `Duplicate declaration "x" (This is an
error on an internal node. Probably an internal error.)`.
```js
// example input
let x = CONSTANT1;
if (cond) {
x += CONSTANT2;
x = CONSTANT3;
}
// current output
let x = CONSTANT1;
if (playheadDragState) {
let x = x + CONSTANT2
x;
let x = CONSTANT3;
}
```
We currently have the ability to have a separate animation for a
ViewTransition that relayouts but doesn't actually have any internal
mutations. This can be useful if you want to separate just a move from
for example flashing an update.
However, we're concerned that this might be more confusion than its
worth because subtle differences in mutations can cause it to trigger
the other case. The existence of the property name might also make you
start looking for it to solve something that it's not meant for.
We already fallback to using the "update" property if it exists but
layout doesn't. So if we ever decide to add this back it would backwards
compatible. We've also shown in implementation that it can work.
This implements `getRootNode(options)` on fragment instances as the
equivalent of calling `getRootNode` on the fragment's parent host node.
The parent host instance will also be used to proxy dispatchEvent in an
upcoming PR.
Avoid failing builds when imported function specifiers conflict by using
babel's `generateUid`. Failing a build is very disruptive, as it usually
presents to developers similar to a javascript parse error.
```js
import {logRender as _logRender} from 'instrument-runtime';
const logRender = () => { /* local conflicting implementation */ }
function Component_optimized() {
_logRender(); // inserted by compiler
}
```
Currently, we fail builds (even in `panicThreshold:none` cases) when
import specifiers are detected to conflict with existing local
variables. The reason we destructively throw (instead of bailing out) is
because (1) we first generate identifier references to the conflicting
name in compiled functions, (2) replaced original functions with
compiled functions, and then (3) finally check for conflicts.
When we finally check for conflicts, it's too late to bail out.
```js
// import {logRender} from 'instrument-runtime';
const logRender = () => { /* local conflicting implementation */ }
function Component_optimized() {
logRender(); // inserted by compiler
}
```
Adds Effect.ConditionallyMutateIterator, which has the following
effects:
- capture for known array, map, and sets
- mutate for all other values
An alternative to this approach could be to add polymorphic shape
definitions
* Adds `isConstructor: boolean` to `FunctionType`. With this PR, each
typed function can either be a constructor (currently only known
globals) or non constructor. Alternatively, we prefer to encode
polymorphic types / effects (and match the closest subtype)
* Add Map and Set globals + built-ins
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32697).
* #32698
* __->__ #32697
`pull_request_target` gives access to repository secrets and permissions
for use from forks, for example to add a comment.
> Due to the dangers inherent to automatic processing of PRs, GitHub’s
standard pull_request workflow trigger by default prevents write
permissions and secrets access to the target repository. However, in
some scenarios such access is needed to properly process the PR. To this
end the pull_request_target workflow trigger was introduced.
> The reason to introduce the pull_request_target trigger was to enable
workflows to label PRs (e.g. needs review) or to comment on the PR.
(via
https://securitylab.github.com/resources/github-actions-preventing-pwn-requests/)
In this case there is no reason for us to allow this, so let's just use
the normal `pull_request` trigger which is less permissive.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32708).
* __->__ #32708
* #32709
Followup from https://github.com/facebook/react/pull/32499
Manual mode is unused and has some bugs such as revealing hidden
boundaries when manually toggling. We also want to change how manual
mode works, and do some refactors to Activity to make it easier to
support. For now we'll remove it, then add it back after the other
changes we have planned.
This works around this Safari bug.
https://bugs.webkit.org/show_bug.cgi?id=290146
This unfortunate because it may cause additional layouts if there's more
updates to the tree coming by manual mutation before it gets painted
naturally. However, we might end up wanting to read layout early anyway.
This affects the fixture because we clone the `<link>` from the `<head>`
which is itself another bug. However, it should be possible to have
`<link>` tags inserted into the new tree so this is still relevant.
Partially reverts #32686.
PR caches inherit from caches generated in `main`. If it cannot find
that cache, it will create one scoped to just that PR (and PRs that
inherit from it).
There is an edge case where cache eviction can happen in the middle of a
test run. If cache eviction removes a `main` cache, child jobs that
depend on it will start failing because of the `fail-on-cache-miss`
setting.
This PR reverts the default behavior. If this happens, the workflow will
still continue in slow mode where it will `yarn install` child jobs
instead of reusing from cache. This is slower but will at least allow
workflows to continue.
Additionally I added restore keys so that we can fallback to other
caches if present so `yarn install` doesn't need to start over from
scratch.
Updates ~all of our validations to return a Result, and then updates callers to either unwrap() if they should bailout or else just log.
ghstack-source-id: 418b5f5aa2b7dd49ca76b3f98a48a35150691d7e
Pull Request resolved: https://github.com/facebook/react/pull/32688
React uses function identity to determine whether a given JSX expression represents the same type of component and should reconcile (keep state, update props) or replace (teardown state, create a new instance). This PR adds off-by-default validation to check that developers are not dynamically creating components during render.
The check is local and intentionally conservative. We specifically look for the results of call expressions, new expressions, or function expressions that are then used directly (or aliased) as a JSX tag. This allows common sketchy but fine-in-practice cases like passing a reference to a component from a parent as props, but catches very obvious mistakes such as:
```js
function Example() {
const Component = createComponent();
return <Component />;
}
```
We could expand this to catch more cases, but this seems like a reasonable starting point. Note that I tried enabling the validation by default and the only fixtures that error are the new ones added here. I'll also test this internally. What i'm imagining is that we enable this in the linter but not the compiler.
ghstack-source-id: e7408c0a55478b40d65489703d209e8fa7205e45
Pull Request resolved: https://github.com/facebook/react/pull/32683
Since we use a centralized cache we should fail subsequent steps if the
child jobs are unable to restore the cache from the first 2 jobs.
Also fix some incorrect hashes used for the fixture tests.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32686).
* __->__ #32686
* #32685
There was a bug previously in our commit artifacts step where the
emitted REVISION hash would reference the commit on the builds branch
rather than from `main`.
Given that our internal manual sync script also does this, let's align
them both to always reference the commit from `main` instead.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32680).
* __->__ #32680
* #32679
* #32678
Defaults to warn, but since some steps require these artifacts to be
uploaded we specify an error if its not found. Some other steps like
playwright test-results are only uploaded on failure so it's okay to
ignore.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32679).
* #32680
* __->__ #32679
* #32678
> Caches have branch scope restriction in place. This means that if
caches for a specific branch are using a lot of storage quota, it may
result into more frequently used caches from default branch getting
thrashed. For example, if there are many pull requests happening on a
repo and are creating caches, these cannot be used in default branch
scope but will still occupy a lot of space till they get cleaned up by
eviction policy. But sometime we want to clean them up on a faster
cadence so as to ensure default branch is not thrashing.
https://github.com/actions/cache/blob/main/tips-and-workarounds.md#force-deletion-of-caches-overriding-default-cache-eviction-policy
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32675).
* __->__ #32675
* #32674
To avoid race conditions where multiple jobs try to write to the same
cache, we now centralize saving the cache and then reusing it in every
subsequent job.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32672).
* #32675
* #32674
* __->__ #32672
## Summary
In the recommended configuration for `eslint-plugin-react-compiler`,
i.e. `reactCompiler.configs.recommended`, the rule is typed as `string`
rather than `eslint.Linter.RuleEntry` or anything assignable thereto,
which results in the following type error if you type check your eslint
configuration:
```
Property ''react-compiler/react-compiler'' is incompatible with index signature.
Type 'string' is not assignable to type 'RuleEntry | undefined'.
```
Simply adding a const assertion fixes the error.
## How did you test this change?
I emitted declarations for the module and confirmed that the rule is now
typed as the string literal `'error'`
I'm seeing a lot of instances of
> Failed to save: Unable to reserve cache with key
runtime-and-compiler-node_modules-v5-X64-Linux-e454609794aae66da9909c77dd6efa073eceff7f44d6527611f8465e102578b4,
another job may be creating this cache.
which is adding ~20 seconds to every step. Let's try to bust the cache
following this
[comment](https://github.com/actions/cache/issues/485#issuecomment-744145040)
and see if that helps.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32671).
* #32672
* __->__ #32671
Using the github variable for the commit message replaces the variable
inline. If the commit message contains quotes or other characters that
need to be escaped, this breaks the workflow.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32668).
* #32669
* __->__ #32668
Follow up to #32656.
Remove touchAction from SwipeRecognizer. I was under the wrong
impression that this was only the touch-action applied to this
particular element, but that parents would still win but in fact this
blocks the parent from scrolling in the other direction. By specifying a
fixed direction it also blocked rage-swiping in the other direction
early on.
Disable pointer-events on view-transition so that the scroll can be hit.
This means that touches hit below the items animating above. This allows
swiping to happen again before momentum scroll has finished. Previously
they were ignored. This only works as long as the SwipeRecognizer is
itself not animating. This means you can now rage-swipe in both
directions quickly.
Alternative to facebook/react#31584 which sets
enableTreatFunctionDepsAsConditional:true` by default.
This PR changes dependency hoisting to be more conservative while trying
to preserve an optimal "happy path". We assume that a function "is
likely called" if we observe the following in the react function body.
- a direct callsite
- passed directly as a jsx attribute or child
- passed directly to a hook
- a direct return
A function is also "likely called" if it is directly called, passed to
jsx / hooks, or returned from another function that "is likely called".
Note that this approach marks the function definition site with its
hoistable properties (not its use site). I tried implementing use-site
hoisting semantics, but it felt both unpredictable (i.e. as a developer,
I can't trust that callbacks are well memoized) and not helpful (type +
null checks of a value are usually colocated with their use site)
In this fixture (copied here for easy reference), it should be safe to
use `a.value` and `b.value` as dependencies, even though these functions
are conditionally called.
```js
// inner-function/nullable-objects/assume-invoked/conditional-call-chain.tsx
function Component({a, b}) {
const logA = () => {
console.log(a.value);
};
const logB = () => {
console.log(b.value);
};
const hasLogged = useRef(false);
const log = () => {
if (!hasLogged.current) {
logA();
logB();
hasLogged.current = true;
}
};
return <Stringify log={log} shouldInvokeFns={true} />;
}
```
On the other hand, this means that we produce invalid output for code
like manually implementing `Array.map`
```js
// inner-function/nullable-objects/bug-invalid-array-map-manual.js
function useFoo({arr1, arr2}) {
const cb = e => arr2[0].value + e.value;
const y = [];
for (let i = 0; i < arr1.length; i++) {
y.push(cb(arr1[i]));
}
return y;
}
```
Reverts facebook/react#30660
I don’t feel confident in the approach. This part of code is supposed to
rely on the module bundler behaving as expected. _Maybe_ this is correct
but I need to review it closer — it was intentionally _not_ implemented
this way originally.
I’ll try to take a closer look some time this week. We don’t have to
merge this revert right now but just flagging that I don’t understand
the thinking behind the new approach and don’t have confidence in it.
Adds `getClientRects()` to fragment instances with a fixture test case.
`Element.getClientRect` returns a collection of `DOMRect`s (see example
of multiline span returning two `DOMRect` boxes).
`fragmentInstance.getClientRects` here flattens those collections into
an array of rects.
`focus()` was added in https://github.com/facebook/react/pull/32465.
Here we add `focusLast()` and `blur()`. I also extended `focus` to take
options.
`focus` will focus the first focusable element. `focusLast` will focus
the last focusable element. We could consider a `focusFirst` naming or
even the `focusWithin` used by test selector APIs as well.
`blur` will only have an effect if the current `document.activeElement`
is one of the fragment children.
I made the button a bit bigger and moved the swipe recognizer around the
whole screen. Typically these are used around the whole content without
any affordances and not as a standalone scrubber. Ideally the swipe
would be able to be inside the animating content but it can't yet due to
[this Safari bug](https://bugs.webkit.org/show_bug.cgi?id=288795).
Added back some paragraphs so that scrolling can be tested properly. It
appears it's possible to get the swipe to be a bit misaligned if you
scroll enough on iOS.
<img width="437" alt="Screenshot 2025-03-17 at 10 27 42 PM"
src="https://github.com/user-attachments/assets/589dc828-717e-420c-83dc-94ae6ad59791"
/>
This does the same thing for `measureUpdateViewTransition` that we did
for `measureNestedViewTransitions` in
e3cbaffef0.
If a boundary hasn't mutated and didn't change in size, we mark it for
cancellation. Otherwise we add names to it. The different from the
CommitViewTransition path is that the "old" names are added to the
clones so this is the first time the "new" names.
Now we also cancel any boundaries that were unchanged. So now the root
no longer animates. We still have to clone them. There are other
optimizations that can avoid cloning but once we've done all the layouts
we can still cancel the running animation and let them just be the
regular content if they didn't change. Just like the regular
fire-and-forget path.
This also fixes the measurement so that we measure clones by adjusting
their position back into the viewport.
This actually surfaces a bug in Safari that was already in #32612. It
turns out that the old names aren't picked up for some reason and so in
Safari they looked more like a cross-fade than what #32612 was supposed
to fix. However, now that bug is even more apparent because they
actually just disappear in Safari. I'm not sure what that bug is but
it's unrelated to this PR so will fix that separately.
ViewTransition uses the `useId` algorithm to auto-assign names. This
ensures that we could animate between SSR content and client content by
ensuring that the names line up.
However, I missed that we need to bump the id (materialize it) when we
do that. This is what function components do if they use one or more
`useId()`. This caused duplicate names when two ViewTransitions were
nested without any siblings since they would share name.
In light of recent third party actions being compromised, let's just
push the commit ourselves rather than use a third party action. We
already detect if changes are needed, so the step will only run if so.
I also added a `dry_run` option to the manual runs of this workflow for
testing.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32648).
* #32650
* #32649
* __->__ #32648
Follow-up to #31850. We want to build using the original commit SHA, not
the merge commit that GitHub Actions creates behind the scenes. We were
already checking out the correct commit object, but the COMMIT_SHA
artifact was still pointing to the merge commit.
This should fix the sizebot links to point to working URLs, too.
We don't have an experimental-only build of devtools, but we can at
least add these filters to the internal build.
A better way would be to use feature detection, but I'm not sure how and
this isn't a very heavily used feautre.
This implements `observeUsing(observer)` and `unobserverUsing(observer)`
on fragment instances. IntersectionObservers and ResizeObservers can be
passed to observe each host child of the fragment. This is the
equivalent to calling `observer.observe(child)` or
`observer.unobserve(child)` for each child target.
Just like the addEventListener, the observer is held on the fragment
instance and applied to any newly mounted child. So you can do things
like wrap a paginated list in a fragment and have each child
automatically observed as they commit in.
Unlike, the event listeners though, we don't `unobserve` when a child is
removed. If a removed child is currently intersecting, the observer
callback will be called when it is removed with an empty rect. This lets
you track all the currently intersecting elements by setting state from
the observer callback and either adding or removing them from your list
depending on the intersecting state. If you want to track the removal of
items offscreen, you'd have to maintain that state separately and append
intersecting data to it in the observer callback. This is what the
fixture example does.
There could be more convenient ways of managing the state of multiple
child intersections, but basic examples are able to be modeled with the
simple implementation. Let's see how the usage goes as we integrate this
with more advanced loggers and other features.
For now you can only attach one observer to an instance. This could
change based on usage but the fragments are composable and could be
stacked as one way to apply multiple observers to the same elements.
In practice, one pattern we expect to enable is more composable logging
such as
```javascript
function Feed({ items }) {
return (
<ImpressionLogger>
{items.map((item) => (
<FeedItem />
))}
</ImpressionLogger>
);
}
```
where `ImpressionLogger` would set up the IntersectionObserver using a
fragment ref with the required business logic and various components
could layer it wherever the logging is needed. Currently most callsites
use a hook form, which can require wiring up refs through the tree and
merging refs for multiple loggers.
Based off: https://github.com/facebook/react/pull/32499
While looking into `React.lazy` issues for built-ins, I noticed we
already error for `lazy` with build-ins, but we don't have any tests for
`getComponentNameFromType` using all the built-ins. This may be
something we should handle, but for now we should at least have tests.
Here's why: while writing tests, I noticed we check `type` instead of
`$$typeof` for portals:
9cdf8a99ed/packages/react-reconciler/src/ReactPortal.js (L25-L32)
This PR adds tests for all the built-ins and fixes the portal bug.
[Commit to
review](e068c167d4)
This PR separates Activity to it's own element type separate from
Offscreen. The goal is to allow us to add Activity element boundary
semantics during hydration similar to Suspense semantics, without
impacting the Offscreen behavior in suspended children.
There's two ways to find updated View Transitions.
One is the "commit/measureNestedViewTransitions" pass which is used to
find things in unchanged subtrees. This can only lead to the relayout
case since there's can't possibly be any mutations in the subtree. This
is only triggered when none of the direct siblings have any mutations at
all.
The other case is "commit/measureUpdateViewTransition" which is for a
ViewTransition that itself has mutations scheduled inside of it which
leads to the "update" case.
However, there's a case between these two cases. When a direct sibling
has a mutation but there's also a ViewTransition exactly at the same
level. In that case we can't bail out on the whole set of children so we
won't trigger the "nested" case. Previously we also didn't trigger the
"commit/measureUpdateViewTransition" case because we first checked if
that had any mutations inside of it at all. This leads to neither case
picking up this boundary.
We could check if the ViewTransition itself has any mutations inside and
if not trigger the nested path.
There's a simpler way though. Because
`commit/measureUpdateViewTransition` is actually just optimistic. The
flags are pessimistic and we don't know for sure if there will actually
be a mutation until we've traversed the tree. It can sometimes lead to
the "relayout" case. So we can just use that same path, knowing that
it'll just lead to the layout pass. Therefore it's safe to just remove
this check.
This is a nit but a Config should not have to know anything about the
internals of Fibers. Ideally it shouldn't even access them but we have
some cases where we need pointers back in like for this fragment.
The way we've typically abstracted this is using the
`ReactFiberTreeReflection` helper that's in the `react-reconciler`. Such
as in the event system.
f3c956006a/packages/react-dom-bindings/src/events/ReactDOMEventListener.js (L22-L26)
We sometimes cheat but we really should clean this up such that a
`Fiber` is actually an opaque type to the Configs and it can never dot
into it without using a helper.
So this just moves `traverseFragmentInstanceChildren` to
ReactFiberTreeReflection so that the ConfigDOM doesn't ever dot into its
fields itself. It just passes the Fiber through back into the
react-reconciler. I had to add a wrapper to read the `.child` to avoid
that being assumed too. I also noticed that FragmentInstanceType is not
actually passed through so that argument is unnecessary.
Stacked on #32599 and #32611.
This is able to reuse the code from CommitViewTransitions for "enter",
"shared" and "layout". The difference is that for "enter"/"shared" in
the "new" phase we pass in the deletions.
For "layout" of nested boundaries we just need to measure the clones at
the same time we measure the original nodes since we haven't measured
them in a previous phase in the current approach.
With these updates, things move around more like expected in the fixture
because we're now applying the appropriate pairs to trigger individual
animations instead of just the full document cross-fade.
The "update" phase is a little more complicated and is coming soon.
Stacked on #32578.
We need to apply view-transition-names to the clones that we create in
the "old" phase for the ViewTransition boundaries that should activate.
Finding pairs is a little trickier than in
ReactFiberCommitViewTransitions. Normally we collect all name
"insertions" in the `accumulateSuspenseyCommit` phase before we even
commit. Then in the snapshot do we visit all "deletions" and since we
already collected all the insertions we know immediately if the deletion
had a pair and should therefore get a "name" assigned to activate the
boundary. For ReactFiberApplyGesture we need to assign names to
"insertions" since it's in reverse but we don't already have a map of
deletions. Therefore we need to first visit all deletions.
Instead of doing that in a completely separate pass, we instead visit
deletions in the same pass to find pairs. Since this is in the same pass
we might visit insertions before deletions or vice versa depending on
document order. However, we can deal with this by applying the name to
the insertion when we find the deletion if we've already made the clones
at that point.
Applying names to pure exits, updates or nested (relayout) is a bit more
straight-forward.
Stacked on #32585 and #32605.
This adds more loops for the phases of "Apply Gesture". It doesn't
implement the interesting bit yet like adding view-transition-names and
measurements. I'll do that in a separate PR to keep reviewing easier.
The three phases of this approach is roughly:
- Clone and apply names to the "old" state.
- Inside startViewTransition: Apply names to the "new" state. Measure
both the "old" and "new" state to know whether to cancel some of them.
Delete the clones which will include all the "old" names.
- After startViewTransition: Restore "new" names back to no
view-transition-name.
Since we don't have any other Effects in these phases we have a bit more
flexibility and we can avoid extra phases that traverse the tree. I've
tried to avoid any additional passes.
An interesting consequence of this approach is that we could measure
both the "old" and "new" state before `startViewTransition`. This would
be more efficient because we wouldn't need to take View Transition
snapshots of parts of the tree that won't actually animate. However,
that would require an extra pass and force layout earlier. It would also
have different semantics from the fire-and-forget View Transitions
because we could optimize better which can be visible. It would also not
account for any late mutations. So I decided to instead let the layout
be computed by painting as usual and then measure both "old" and "new"
inside the startViewTransition instead. Then canceling anything that
doesn't animate to keep it consistent.
Unfortunately, though there's not a lot of code sharing possible in
these phases because the strategy is so different with the cloning and
because the animation is performed in reverse. The "finishedWork" Fiber
represents the "old" state and the "current" Fiber represents the "new"
state.
The most complicated phase is the cloning. I actually ended up having to
make a very different pattern from the other phases and CommitWork in
general. Because we have to clone as we go and also do other things like
apply names and finding pairs, it has more phases. I ended up with an
approach that uses three different loops. The outer one for updated
trees, one for inserted trees that don't need cloning (doesn't include
reappearing offscreen) and one for not updated trees that still need
cloning. Inside each loop it can also be in different phases which I
track with the `visitPhase` enum - this pattern is kind of new.
Additionally, we need to measure the cloned nodes after we've applied
mutations to them and we have to wait until the whole tree is inserted.
We don't have a reference to these DOM elements in the Fiber tree since
that still refers to the original ones. We need to store the cloned
elements somewhere. So I added a temporary field on the
ViewTransitionState to keep track of any clones owned by that
ViewTransition.
When we deep clone an unchanged subtree we don't have DOM element
instances. It wouldn't be quite safe to try to find them from the tree
structure. So we need to avoid the deep clones if we might need DOM
elements. Therefore we keep traversing in the case where we need to find
nested ViewTransition boundaries that are either potentially affected by
layout or a "pair".
For the other two phases the pattern there's a lot of code duplication
since it's slightly different from the commit ones but they at least
follow the same pattern. For the restore phase I was actually able to
reuse most of the code.
I don't love how much code this is.
This prepares from being able to reuse some this in ApplyGesture.
These all start with resetting a counter but it's tricky to have to
remember to do this and tricky to do from the outside of this module. So
we make an exported helper that does the resetting. Ideally it gets
inlined.
We also stop passing "current" to measureViewTransitionHostInstances.
Same thing for cancelViewTransitionHostInstances. This doesn't make
sense for "nested" which has not updated and so might not have an
alternate. Instead we pass in the old and new name if they might be
different.
Normally these are gated by the whole commitGestureOnRoot path but in
the case of an early commit these phases may need to be invoked.
Earlier. Those paths weren't gated which I noticed when I started adding
code to them.
This is the exact same code in both cases. It's just general clean up.
By unifying them it becomes less confusing to reuse these helpers in the
Apply Gesture path where the naming is reversed.
Traverse program after running compiler transform to find untransformed
references to compiler features (e.g. `inferEffectDeps`, `fire`).
Hard error to fail the babel pipeline when the compiler fails to
transform these features to give predictable runtime semantics.
Untransformed calls to functions like `fire` will throw at runtime
anyways, so let's fail the build to catch these earlier.
Note that with this fails the build *regardless of panicThreshold*
We only need the compiler built for `yarn test` in the root directory.
Rather than always cache both for every step, let's just do it where
it's needed explicitly.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32608).
* #32609
* __->__ #32608
Now that the compiler lint rule is merged into
eslint-plugin-react-hooks, we also need to update our caches so compiler
dependencies are also cached. This should fix the CI walltime regression
we are now seeing.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32603).
* #32604
* __->__ #32603
Removes `EnvironmentConfig.enableMinimalTransformsForRetry` in favor of
`run` parameters. This is a minimal difference but lets us explicitly
opt out certain compiler passes based on mode parameters, instead of
environment configurations
Retry flags don't really make sense to have in `EnvironmentConfig`
anyways as the config is user-facing API, while retrying is a compiler
implementation detail.
(per @josephsavona's feedback
https://github.com/facebook/react/pull/32164#issuecomment-2608616479)
> Re the "hacky" framing of this in the PR title: I think this is fine.
I can see having something like a compilation or output mode that we use
when running the pipeline. Rather than changing environment settings
when we re-run, various passes could take effect based on the
combination of the mode + env flags. The modes might be:
>
> * Full: transform, validate, memoize. This is the default today.
> * Transform: Along the lines of the backup mode in this PR. Only
applies transforms that do not require following the rules of React,
like `fire()`.
> * Validate: This could be used for ESLint.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32511).
* #32512
* __->__ #32511
This change fixes a coverage hole in rolling out with `gating`. Prior to
this PR, configuring `gating` causes React Compiler to bail out of
optimizing some functions.
This means that it's not entirely safe to cutover from `gating` enabled
for all users (i.e. rolled out 100%) to removing the `gating` config
altogether, as new functions may be opted into compilation when they
stop bailing out due to gating-specific logic.
This is technically slightly slower due to the additional function
indirection. An alternative approach is to recommend running a codemod
to insert `use no memo`s on currently-bailing out functions before
removing the`gating` config.
---
Tested [internally](
https://fburl.com/diff/q982ovua) by enabling on a page that previously
had a few hundred bailouts due to gating + hoisted function declarations
and (1) clicking around locally and (2) running a bunch of e2e tests
Reduce false positive bailouts by using the same
`isReferencedIdentifier` logic that the compiler also uses for
determining context variables and a function's own hoisted declarations.
Details:
Previously, we counted every babel identifier as a reference. This is
problematic because babel counts most string symbols as an identifier.
```js
print(x); // x is an identifier as expected
obj.x // x is.. also an identifier here
{x: 2} // x is also an identifier here
```
This PR adds a check for `isReferencedIdentifier`. Note that only
non-lval
references pass this check. This should be fine as we don't need to
hoist function declarations before writes to the same lvalue (which
should error in strict mode anyways)
```js
print(x); // isReferencedIdentifier(x) -> true
obj.x // isReferencedIdentifier(x) -> false
{x: 2} // isReferencedIdentifier(x) -> false
x = 2 // isReferencedIdentifier(x) -> false
```
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32596).
* __->__ #32596
* #32595
* #32594
* #32593
* #32522
* #32521
- Add `at`, `indexOf`, and `includes`
- Optimize MixedReadOnly which is currently only used by hook return
values. Hook return values are typed as Frozen, this change propagates
that to return values of aliasing function calls (such as `at`). One
potential issue is that developers may pass
`enableAssumeHooksFollowRulesOfReact:false` and set
`transitiveMixedData`, expecting their transitive mixed data to be
mutable. This is a bit of an edge case and already doesn't have clear
semantics.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32594).
* #32596
* #32595
* __->__ #32594
* #32593
* #32522
* #32521
Expand type inference to infer mixedReadOnly types for numeric and
computed property accesses.
```js
function Component({idx})
const data = useFragment(...)
// we want to type `posts` correctly as Array
const posts = data.viewers[idx].posts.slice(0, 5);
// ...
}
```
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32593).
* #32596
* #32595
* #32594
* __->__ #32593
* #32522
* #32521
## Summary
Right now, `react-compiler-healthcheck` flags `mobx` as a "known
incompatible library". But it's not precisely *MobX* that's
incompatible. It's the observer HOC that comes from `mobx-react` and
`mobx-react-lite`.
I've been working on
[mst-use-observable](https://github.com/coolsoftwaretyler/mst-use-observable),
which makes MobX-State-Tree compatible with the compiler. However,
projects that use `mobx-state-tree` and `mst-use-observable` will still
depend on `mobx` as a dependency.
And there [have been efforts in the past to write a hook for
observability](https://github.com/mobxjs/mobx/discussions/2566). So it's
possible that MobX could become compatible, so long as authors access it
with a hook, rather than the HOC.
I would like to propose updating the health check to be a little more
precise and flag the HOC dependencies, rather than MobX itself.
Thanks in advance for your consideration!
## How did you test this change?
`npx react-compiler-healthcheck` shouldn't flag on `mobx` in
dependencies, but will for `mobx-react-lite` and `mobx-react`.
Test suites, formatting, linting, all passed.
---------
Co-authored-by: lauren <poteto@users.noreply.github.com>
fix: update CONTRIBUTING.md link path
Updated the relative path to CONTRIBUTING.md from `../CONTRIBUTING.md`
to `./../../CONTRIBUTING.md` to ensure the correct file is referenced.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
This change merges the `react-compiler` rule from
`eslint-plugin-react-compiler` into the `eslint-plugin-react-hooks`
plugin. In order to do the move in a way that keeps commit history with
the moved files, but also no remove them from their origin until a
future cleanup change can be done, I did the `git mv` first, and then
recreated the files that were moved in their original places, as a
separate commit. Unfortunately GH shows the moved files as new instead
of the ones that are truly new. But in the IDE and `git blame`, commit
history is intact with the moved files.
Since this change adds new dependencies, and one of those dependencies
has a higher `engines` declaration for `node` than what the plugin
currently has, this is technically a breaking change and will have to go
out as part of a major release.
### Related Changes
- https://github.com/facebook/react/pull/32458
---------
Co-authored-by: Lauren Tan <poteto@users.noreply.github.com>
This adds a page to the DOM fixture to test Fragment Refs. The first
test case is for `addEventListener`/`removeEventListener`.
Setting `enableFragmentRefs` to `__EXPERIMENTAL__` and building is
required to run the fixture.
<img width="872" alt="Screenshot 2025-03-05 at 12 58 57 PM"
src="https://github.com/user-attachments/assets/fee498b7-fd96-4178-9e82-c46d4cb55c9b"
/>
I'm not sure what exactly is causing the flakiness in the playground e2e
tests but I suspect it's some kind of timing issue.
Let's try waiting for Monaco to be fully initialized before running
tests.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32584).
* __->__ #32584
* #32583
Extracting portions of #32416 for easier review. This PR dedupes
@babel/types to resolve to 7.26.3, for compatibility in the root
workspace where eslint-plugin-react-hooks resides.
I also needed to update @babel/preset-typescript in snap.
The compiler changes in HIR and ReactiveScopes were needed due to types
changing. Notably, Babel [added support for optional chaining
assignment](https://github.com/babel/babel/pull/15751) (currently [Stage
1](https://github.com/tc39/proposal-optional-chaining-assignment)), so
in the latest versions of @babel/types, AssignmentExpression.left can
now also be of t.OptionalMemberExpression.
Given that this is in Stage 1, the compiler probably shouldn't support
this syntax, so this PR updates HIR to bailout with a TODO if there is a
non LVal on the lhs of an Assignment Expression.
There was also a small superficial SourceLocation change needed in
`InferReactiveScopeVariables` as Babel 8 changes were [accidentally
released in
7](https://github.com/babel/babel/issues/10746#issuecomment-2699146670).
It doesn't affect our analysis so it seems fine to just update with the
new properties.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32581).
* #32582
* __->__ #32581
Co-authored-by: michael faith <michaelfaith@users.noreply.github.com>
Co-authored-by: michael faith <michaelfaith@users.noreply.github.com>
Follow up to #32540.
We do allow gestures to be cancelled early (we call skipTransition) if
the gesture stops before it has even started.
This happens in the fixture when we auto-scroll.
*This API is experimental and subject to change or removal.*
This PR is an alternative to
https://github.com/facebook/react/pull/32421 based on feedback:
https://github.com/facebook/react/pull/32421#pullrequestreview-2625382015
. The difference here is that we traverse from the Fragment's fiber at
operation time instead of keeping a set of children on the
`FragmentInstance`. We still need to handle newly added or removed child
nodes to apply event listeners and observers, so we treat those updates
as effects.
**Fragment Refs**
This PR extends React's Fragment component to accept a `ref` prop. The
Fragment's ref will attach to a custom host instance, which will provide
an Element-like API for working with the Fragment's host parent and host
children.
Here I've implemented `addEventListener`, `removeEventListener`, and
`focus` to get started but we'll be iterating on this by adding
additional APIs in future PRs. This sets up the mechanism to attach refs
and perform operations on children. The FragmentInstance is implemented
in `react-dom` here but is planned for Fabric as well.
The API works by targeting the first level of host children and proxying
Element-like APIs to allow developers to manage groups of elements or
elements that cannot be easily accessed such as from a third-party
library or deep in a tree of Functional Component wrappers.
```javascript
import {Fragment, useRef} from 'react';
const fragmentRef = useRef(null);
<Fragment ref={fragmentRef}>
<div id="A" />
<Wrapper>
<div id="B">
<div id="C" />
</div>
</Wrapper>
<div id="D" />
</Fragment>
```
In this case, calling `fragmentRef.current.addEventListener()` would
apply an event listener to `A`, `B`, and `D`. `C` is skipped because it
is nested under the first level of Host Component. If another Host
Component was appended as a sibling to `A`, `B`, or `D`, the event
listener would be applied to that element as well and any other APIs
would also affect the newly added child.
This is an implementation of the basic feature as a starting point for
feedback and further iteration.
This fixes a critical issue with moveBefore. I was told that the
disconnected -> connected case was going to be relaxed and not be an
error but apparently that is not the case.
This means that we can't use this for initial insertions. Only moves.
Unfortunately React's internals doesn't distinguish these cases. This
adds a hack that checks each nodes but this is pretty bad for
performance. We should only call this in one or the other case.
Given that we still need feature detection. Both of which means that
these calls are no longer inlined and this extra code. I wonder if it's
even worth it given that you can't even rely on it working anyway since
not all browsers have it. Kind of don't want to ship this until all
browsers have it.
Even then we'd ideally refactor React to use separate code paths for
initial insertion vs moves. Which leads to some unfortunate code
duplication.
Enabling feature detection of early DOM features in a framework is
reckless. I'm not judging other frameworks (but also a little bit).
Because if you do something like `if (moveBefore) moveBefore(a, b) else
insertBefore(a, b)` like we do and then the implementation has to change
there are still too many websites out there that it becomes impossible
to change it. It would break the web. It would instead have to change to
a different name. That's what happened with `contains` -> `includes`.
Counter to popular belief it didn't have anything to do with patching
prototypes. Therefore, ideally frameworks shouldn't start rely on it
until there's two implementations so that there's time for feedback.
That's why we didn't immediately enable this even in experimental.
However, at this point there's probably enough feature detection and it
has shipped long enough in Chrome that it's unlikely to be able to
change at this point.
We can enable it now. For now just in `@experimental` to see if we can
flush out issues with it before bringing it to stable.
Otherwise these can survive into the next View Transition and cause
havoc to that transition.
This was appearing as a flash in Safari in the fixture when going from
A->B. This triggers a View Transition and at the same time the scroll
position updates in an effect. That fires a scroll event which starts a
gesture. This shouldn't really happen and the SwipeRecognizer should
ideally ignore those but it's good to surface edge cases. That gesture
is blocked on the View Transition finishing and then immediately after
it starts a gesture View Transition. That gesture then picked up the
former Animation from the previous transition which caused issues. This
PR fixes that flash.
Currently in the `compiler` workspace, we invoke esbuild directly to
build most packages (with the exception of `snap`). This has been mostly
fine, but does not allow us to do things like generate type declaration
files.
I would like #32416 to be able to consume the merged
eslint-plugin-react-compiler from source rather than via npm, and one of
the things that has come up from my exploration in that stack using the
compiler from source is that babel-plugin-react-compiler is missing type
declarations. This is primarily because React's build process uses
rollup + rollup-plugin-typescript, which runs tsc. So the merged plugin
needs to typecheck properly in order to build. An alternative might be
to migrate to something like babel with rollup instead to simply strip
types rather than typecheck before building. The minor downside of that
approach is that we would need to manually maintain a d.ts file for
eslint-plugin-react-hooks. For now I would like to see if this PR helps
us make progress rather than go for the slightly worse alternative.
[`tsup`](https://github.com/egoist/tsup) is esbuild based so build
performance is comparable. It is slower when generating d.ts files, but
it's still much faster than rollup which we used prior to esbuild. For
now, I have turned off `dts` by default, and it is only passed when
publishing on npm.
If you want to also generate d.ts files you can run `yarn build --dts`.
```
# BEFORE: build all compiler packages (esbuild)
$ time yarn build
✨ Done in 15.61s.
yarn build 13.82s user 1.54s system 96% cpu 15.842 total
# ---
# AFTER: build all compiler packages (tsup)
$ time yarn build
✨ Done in 12.39s.
yarn build 12.58s user 1.68s system 106% cpu 13.350 total
# ---
# AFTER: build all compiler packages and type declarations (tsup)
$ time yarn build --dts
✨ Done in 30.69s.
yarn build 43.57s user 3.20s system 150% cpu 31.061 total
```
I still need to test if this unblocks #32416 but this stack can be
landed independently though as we could probably just release type
declarations on npm. No one should be using the compiler directly, but
if they really wanted to, lack of type declarations would not stop them
(cf React secret internals).
Note that I still kept esbuild as we still use it directly for forgive.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32550).
* #32551
* __->__ #32550
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
This PR fixes asserts when `passChildrenWhenCloningPersistedNodes` is
enabled for React Native and OffscreenComponent child rendering unhides
host components.
Discussions around possible fixes for the asserts seen in React Native
suggested changing the way we handle hiding/unhiding host components by
updating the fiber state with the hidden host component instead of
submitting a hidden clone Fabric and keeping the original as the current
fiber.
Implementing this fix would require holding onto the original styling of
the hidden host component. The reconciler updates the styling by adding
`display: none` to hide the contents. If the original host component was
already hidden, the renderer would lose that information and remove the
styling when showing the contents again.
To reduce the changes required to make
`passChildrenWhenCloningPersistedNodes` work, this PR falls back to the
original cloning method when OffscreenComponents are part of the
children needed to be added back. This effectively resolve the asserts
triggered by the feature in RN and improves overall performance.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
This fix was tested by enabling `passChildrenWhenCloningPersistedNodes`
in an app built with React Native that had a repro for triggering the
asserts. The asserts do not occur anymore when using the changes in this
PR.
---------
Co-authored-by: Nick <lefever@meta.com>
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
Adds changelog entries for the last two minor releases of
`eslint-plugin-react-hooks`. Fixes#31717.
I chose to not include #31208 (8382581446)
and #32115 (fd2d279984) in the changelog
as they only changed internals that do not affect consumers of the
plugin, and it doesn't seem like the changelog previously included such
changes.
Changes are sorted by importance (rather than by commit date), with the
most important changes first.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
Docs only, nothing to test.
This is used to register Server References that exist in the current
environment but also exists in the server it might call into. Such as a
remote server.
If the value comes from the remote server in the first place then this
is called automatically to ensure that you can pass a reference back to
where it came from - even if the `serverModuleMap` option is used. This
was already the case when `serverModuleMap` wasn't passed. This is how
you can pass server references back to the server. However, when we
added `serverModuleMap` that pass was skipped because we were getting
real functions instead of proxies.
For functions that wasn't yet passed from the remote server to the
current server, we can register them eagerly just like we do for
`import('/server').registerServerReference()`. You can now also do this
with `import('/client').registerServerReference()`. We could make them
shared so you only have to do this once but it might not be possible to
pass to the remote server and the remote server might not even be the
same RSC renderer. Therefore I split them. It's up to the compiler
whether it should do that or not. It has to know that any function you
might call might be able to receive it. This is currently global to a
specific RSC renderer.
Setting the animation's currentTime causes a quirk where the transition
can end up off by a bit and the end state can be slightly off the end
time.
However, I realized that we don't have to because if we just set the
direction in the `animate()` call directly the Safari bug goes away.
This is really the essence mechanism of the `useSwipeTransition`
feature.
We don't want to immediately switch to the destination state when
starting a gesture. The effects remain mounted on the current state. We
want the current state to be "live". This is important to for example
allow a video to keeping playing while starting a swipe (think
TikTok/Reels) and not stop until you've committed the action. The only
thing that can be live is the "new" state. Therefore we treat the
destination as the "old" state and perform a reverse animation from
there.
Ideally we could apply the old state to the DOM tree, take a snapshot
and then revert it back in the mutation of `startViewTransition`.
Unfortunately, the way `startViewTransition` was designed it always
paints one frame of the "old" state which would lead this to cause a
flicker.
To work around this, we need to create a clone of any View Transition
boundary that might be mutated and then render that offscreen. That way
we can render the "current" state on screen and the "destination" state
offscreen for the screenshots. Being mutated can be either due to React
doing a DOM mutation or if a child boundary resizes that causes the
parent to relayout. We don't have to do this for insertions or deletions
since they only appear on one side.
The worst case scenario is that we have to clone the whole root. That's
what this first PR implements. We clone the container and if it's not
absolutely positioned, we position it on top of the current one. If the
container is `document` or `<html>` we instead clone the `<body>` tag
since it's the only one we can insert a duplicate of. If the container
is deep in the tree we clone just that even though technically we should
probably clone the whole document in that case. We just keep the impact
smaller. Ideally though we'd never hit this case. In fact, if we clone
the document we issue a warning (always for now) since you probably
should optimize this. In the future I intend to add optimizations when
affected View Transition boundaries are absolutely positioned since they
cannot possibly relayout the parent. This would be the ideal way to use
this feature most efficiently but it still works without it.
Since we render the "old" state outside the viewport, we need to then
adjust the animation to put it back into the viewport. This is the
trickiest part to get right while still preserving any customization of
the View Transitions done using CSS. This current approach reapplies all
the animations with adjusted keyframes.
In the case of an "exit" the pseudo-element itself is positioned outside
the viewport but since we can't programmatically update the style of the
pseudo-element itself we instead adjust all the keyframes to put it back
into the viewport. If there is no animation on the group we add one.
In the case of an "update" the pseudo-element is positioned on the new
state which is already inside the viewport. However, the auto-generated
animation of the group has a starting keyframe that starts outside the
viewport. In this case we need to adjust that keyframe.
In the future I might explore a technique that inserts stylesheets
instead of mutating the animations. It might be simpler. But whatever
hacks work to maximize the compatibility is best.
This change adds more details about prior versions of the plugin's
config, to help people as they migrate from legacy to flat configs
across multiple versions of this plugin. At some point in the 6.0 or 7.0
cycle, it would probably make sense to re-consolidate this into a single
version.
Closes#32494
Summary: Correctly supports React.useEffect when React is
imported as `import * as React from 'react'`
(as well as other namespaces as specified in the config).
We added support for `onScrollEnd` in #26789 but it only works in Chrome
and Firefox. Safari still doesn't support `scrollend` and there's no
indication that they will anytime soon so this polyfills it.
While I don't particularly love our synthetic event system this tries to
stay within the realm of how our other polyfills work. This implements
all `onScrollEnd` events as a plugin.
The basic principle is to first feature detect the `onscrollend` DOM
property to see if there's native support and otherwise just use the
native event.
Then we listen to `scroll` events and set a timeout. If we don't get any
more scroll events before the timeout we fire `onScrollEnd`. Basically
debouncing it. If we're currently pressing down on touch or a mouse then
we wait until it is lifted such as if you're scrolling with a finger or
using the scrollbars on desktop but isn't currently moving.
If we do get any native events even though we're in polyfilling mode, we
use that as an indication to fire the `onScrollEnd` early.
Part of the motivation is that this becomes extra useful pair for
https://github.com/facebook/react/pull/32422. We also probably need
these events to coincide with other gesture related internals so you're
better off using our polyfill so they're synced.
I end up rebuilding for testing the view-transition fixture a lot. It
doesn't need everything that flight needs so this just adds a short hand
that's a little faster to rebuild.
---------
Co-authored-by: Hendrik Liebau <mail@hendrik-liebau.de>
Randomly noticed this when I looked at a recent [DevTools regression
test run](https://github.com/facebook/react/actions/runs/13578385011).
I don't recall why we added `continue-on-error` previously, but I
believe it was to keep all jobs in the matrix running even if one were
to fail, in order to fully identify any failures from code changes like
build or test failures.
There is now a `fail-fast` option which does this.
[`continue-on-error`](https://docs.github.com/en/actions/writing-workflows/workflow-syntax-for-github-actions#jobsjob_idcontinue-on-error)
now means:
> Prevents a workflow run from failing when a job fails. Set to true to
allow a workflow run to pass when this job fails.
so it's not correct to use it.
This change swaps which config `recommended` is aliasing. In 5.2.0, the
new flat config was introduced as `recommended-latest`, while
`recommended` still pointed at the legacy rc-based config, with a note
that in the next major version `recommended` would be updated to point
at `recommend-latest`. This change makes that swap, and make the default
`recommended` experience the flat config. To continue using the legacy
rc recommended config, please make the following change in your config
```diff
- extends: ['plugin:react-hooks/recommended']
+ extends: ['plugin:react-hooks/recommended-legacy']
```
This change also deprecates `recommended-latest` in favor of
`recommended`. `recommended-latest` will be removed in a future major
version.
The README has been updated to reflect the new usage, and to put the
flat config sections before the legacy config sections.
I also took the opportunity to change the v9 fixture to use a typescript
config, serving as a demonstration for usage as well as a way to
validate the types are correct.
BREAKING CHANGE
---------
Co-authored-by: lauren <poteto@users.noreply.github.com>
Since the compiler plugin is going to be merged into the hooks plugin,
and ultimately decomposed into several more rules, it would be good to
start creating a more traditional folder structure for the plugin. This
change just moves the rules into a `rules` folder.
Co-authored-by: lauren <poteto@users.noreply.github.com>
In preparation for the merging of the compiler plugin into this one
(#32416), this change proactively updates the plugin's `engines`
declaration to require Node versions greater than or equal to 18
BREAKING CHANGE
Co-authored-by: lauren <poteto@users.noreply.github.com>
This adds a `ReactFiberApplyGesture` which is basically intended to be a
fork of the phases in `ReactFiberCommitWork` except for the fake commit
that `useSwipeTransition` does. So far none of the phases are actually
implemented yet. This is just the scaffolding around them so I can fill
them in later.
The important bit is that we call `startViewTransition` (via the
`startGestureTransition` Config) when a gesture starts. We add a paused
animation to prevent the transition from committing (even if the
ScrollTimeline goes to 100%). This also locks the documents so that we
can't commit any other Transitions until it completes.
When the gesture completes (scroll end) then we stop the gesture View
Transition. If there's no new work scheduled we do that immediately but
if there was any new work already scheduled, then we assume that this
will potentially commit the new state. So we wait for that to finish.
This lets us lock the animation in its state instead of snapping back
and then applying the real update.
Using this technique we can't actually run a View Transition from the
current state to the actual committed state because it would snap back
to the beginning and then run the View Transition from there. Therefore
any new commit needs to skip View Transitions even if it should've
technically animated to that state. We assume that the new state is the
same as the optimistic state you already swiped to. An alternative to
this technique could be to commit the optimistic state when we cancel
and then apply any new updates o top of that. I might explore that in
the future.
Regardless it's important that the `action` associated with the swipe
schedules some work before we cancel. Otherwise it risks reverting
first. So I had to update this in the fixture.
It's getting unwieldy to list every single package to skip in these
commands when you only want to publish one, ie
eslint-plugin-react-hooks.
This adds a new `onlyPackages` and `publishVersion` option to the
publish commands to make that easier.
This doesn't change anything. It just moves some functions.
This moves the view transitions helper functions into its own file. This
is similar to how I already moved ReactFiberCommitEffects and
ReactFiberCommitHostEffects out of ReactFiberCommitWork.
This makes it a bit easier to navigate and get an overview of
ReactFiberCommitWork but another motivation is also so that I can refer
to these helpers from
[ReactFiberApplyGesture](https://github.com/facebook/react/pull/32451/files#diff-42297cf327dee8e01d83c85314b8965953b9674e7c4615ce6c430464dcc8550b).
For the `useId` algorithm we used colon `:` before and after.
https://github.com/facebook/react/pull/23360
This avoids collisions in general by using an unusual characters. It
also avoids collisions when concatenated with some other ID.
Unfortunately, `:` is not a valid character in `view-transition-name`.
This PR swaps the format from:
```
:r123:
```
To the unicode:
```
«r123»
```
Which is valid CSS selectors. This also allows them being used for
`querySelector()` which we didn't really find a legit use for but seems
ok-ish.
That way you can get a view-transition-name that you can manually
reference. E.g. to generate styles:
```js
const id = useId();
return <>
<style>{`
::view-transition-group(${id}) { ... }
::view-transition-old(${id}) { ... }
::view-transition-new(${id}) { ... }
`}</style>
<ViewTransition name={id}>...</ViewTransition>
</>;
```
## Summary
> [!NOTE]
> This only modifies types, so shouldn't have an impact at runtime.
Some time ago we moved some type definitions from React to React Native
in #26437.
This continues making progress on that so values that are created by
React Native and passed to the React renderer (in this case public
instances) are actually defined in React Native and not in React.
This will allow us to modify the definition of some of these types
without having to make changes in the React repository (in the short
term, we want to refactor PublicInstance from an object to an interface,
and then modify that interface to add all the new DOM methods).
## How did you test this change?
Manually synced `ReactNativeTypes` on top of
https://github.com/facebook/react-native/pull/49602 and verified Flow
passes.
Link headers are optionally supported for cases where you prefer to send
resource loading hints before you're ready to send the body of a
request. While many resources can be correctly preloaded from a link
header responsive images are currently not supported and end up
preloading the default src rather than the correctly sized image. Until
responsive images are supported React will not allow these images to
preload as headers and will retain them to preload as HTML.
closes: #32437
Stacked on #32412.
To effectively `useSwipeTransition` you need something to start and stop
the gesture as well as triggering an Action.
This adds an example Gesture Recognizer to the fixture. Instead of
having this built-in to React itself, instead the idea is to leave this
to various user space Component libraries. It can be done in different
ways for different use cases. It could use JS driven or native
ScrollTimeline or both.
This example uses a native scroll with scroll snapping to two edges. If
you swipe far enough to snap to the other edge, it triggers an Action at
the end.
This particular example uses a `position: sticky` to wrap the content of
the Gesture Recognizer. This means that it's inert by itself. It doesn't
scroll its content just like a plain JS recognizer using pointer events
would. This is useful because it means that scrolling doesn't affect
content before we start (the "scroll" event fires after scrolling has
already started) so we don't have to both trying to start it earlier. It
also means that scrolling doesn't affect the live content which can lead
to unexpected effects on the View Transition.
I find the inert recognizer the most useful pairing with
`useSwipeTransition` but it's not the only way to do it. E.g. you can
also have a scrollable surface that uses plain scrolling with snapping
and then just progressively enhances swiping between steps.
Stacked on #32379
Track the range offsets along the timeline where previous/current/next
is. This can also be specified as an option. This lets you model more
than three states along a timeline by clamping them and then updating
the "current" as you go.
It also allows specifying the "current" offset as something different
than what it was when the gesture started such as if it has to start
after scroll has already happened (such as what happens if you listen to
the "scroll" event).
We can only render one direction at a time with View Transitions. When
the direction changes we need to do another render in the new direction
(returning previous or next).
To determine direction we store the position we started at and anything
moving to a lower value (left/up) is "previous" direction (`false`) and
anything else is "next" (`true`) direction.
For the very first render we won't know which direction you're going
since you're still on the initial position. It's useful to start the
render to allow the view transition to take control before anything
shifts around so we start from the original position. This is not
guaranteed though if the render suspends.
For now we start the first render by guessing the direction such as if
we know that prev/next are the same as current. With the upcoming auto
start mode we can guess more accurately there before we start. We can
also add explicit APIs to `startGesture` but ideally it wouldn't matter.
Ideally we could just start after the first change in direction from the
starting point.
Upgrade compiler playground to use the newest nextjs release, which
includes react compiler transform pipeline optimizations
https://github.com/vercel/next.js/pull/75676/.
Also made a drive-by fix to avoid the error `Cannot update a component
('Router') while rendering a different component ('StoreProvider'). To
locate the bad setState() call inside 'StoreProvider', follow the stack
trace as described in https://react.dev/link/setstate-in-render`. The
bad setState came from `history.replaceState({}, '', \`#${hash}\`);`.
Prior to this, playground ran side effects in a reducer (i.e. during
render). These have now been moved an effect.
Update eslint-plugin-react-hooks to be built targetting ES5 instead. For
various reasons our internal infra relies on these files being built
already downleveled.
Test fixtures testing different compiler features (e.g. non-auto
memoization) should live in separate directories.
Remove bug-prefixed fixtures that have since been fixed
Add test evaluator export to more fixtures
Prior to this PR, our HIR represented property access with numeric
literals (e.g. `myVar[0]`) as ComputedLoads. This means that they were
subject to some deopts (most notably, not being easily dedupable /
hoistable as dependencies).
Now, `PropertyLoad`, `PropertyStore`, etc reference numeric and string
literals (although not yet string literals that aren't valid babel
identifiers). The difference between PropertyLoad and ComputedLoad is
fuzzy now (maybe we should rename these).
- PropertyLoad: property keys are string and numeric literals, only when
the string literals are valid babel identifiers
- ComputedLoad: non-valid babel identifier string literals (rare) and
other non-literal expressions
The biggest feature from this PR is that it trivially enables
array-indicing expressions as dependencies. The compiler can also
specify global and imported types for arrays (e.g. return value of
`useState`)
I'm happy to close this if it complicates more than it helps --
alternative options are to entirely rely on instruction reordering-based
approaches like ReactiveGraphIR or make dependency-specific parsing +
hoisting logic more robust.
LoweredFunction dependencies were exclusively used for dependency
extraction (in `propagateScopeDeps`). Now that we have a
`propagateScopeDepsHIR` that recursively traverses into nested
functions, we can delete `dependencies` and their associated synthetic
`LoadLocal`/`PropertyLoad` instructions.
[Internal snapshot
diff](https://www.internalfb.com/phabricator/paste/view/P1716950202) for
this change shows ~.2% of files changed. I [read through ~60 of the
changed
files](https://www.internalfb.com/phabricator/paste/view/P1733074307)
- most changes are due to better outlining (due to better DCE)
- a few changes in memo inference are due to changed ordering
```
// source
arr.map(() => contextVar.inner);
// previous instructions
$0 = LoadLocal arr
$1 = $0.map
// Below instructions are synthetic
$2 = LoadLocal contextVar
$3 = $2.inner
$4 = Function deps=$3 context=contextVar {
...
}
```
- a few changes are effectively bugfixes (see
`aliased-nested-scope-fn-expr`)
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32096).
* #32099
* #32286
* #32104
* #32098
* #32097
* __->__ #32096
- [build(eslint-plugin-react-hooks): add
ts-linting](4c0fbe73d9)
This change adds configuration to the eslint config governing
`eslint-plugin-react-hooks` to use the typescript-eslint plugin and
parser. It adds the typescript-recommended config, and configures the
team's preferred `array-type` convention.
- [refactor(eslint-plugin-react-hooks): improve
conditionals](540d0d95bc)
This change addresses several feedback items from
https://github.com/facebook/react/pull/32240
- [ci (eslint-e2e): exclude nested node_modules from
cache](a3279f46a8)
This change removes the nested fixture `node_modules` from being cached,
so that the symbolic link can be made after the build happens.
This change removes the `devEngines` declaration in the root package. It
didn't match the package.json spec and in npm 10.9.0 (released in
October), a breaking change was introduced that checks the `devEngines`
property. This causes `npm pack` calls to fail, due to the malformed
`devEngines`. Since there's already an `.nvmrc` defined in the repo, and
no strong need to enforce a specific node version for local development,
this removes the declaration altogether.
## Summary
The `flow-api-translator` from the `hermes` repo does not support flow
type spreads. It is currently not able to digest the ReactNativeTypes
file as it contains unsupported syntax. The simplest solution is to
change the type of the `TouchedViewDataAtPoint` to equivalent, yet
supported by the Flow tooling. In this case the intersection can be used
as
the `TouchedViewDataAtPoint` and `InspectorData` have no common
property.
## How did you test this change?
Run yarn flow native
This Hook will be used to drive a View Transition based on a gesture.
```js
const [value, startGesture] = useSwipeTransition(prev, current, next);
```
The `enableSwipeTransition` flag will depend on `enableViewTransition`
flag but we may decide to ship them independently. This PR doesn't do
anything interesting yet. There will be a lot more PRs to build out the
actual functionality. This is just wiring up the plumbing for the new
Hook.
This first PR is mainly concerned with how the whole starts (and stops).
The core API is the `startGesture` function (although there will be
other conveniences added in the future). You can call this to start a
gesture with a source provider. You can call this multiple times in one
event to batch multiple Hooks listening to the same provider. However,
each render can only handle one source provider at a time and so it does
one render per scheduled gesture provider.
This uses a separate `GestureLane` to drive gesture renders by marking
the Hook as having an update on that lane. Then schedule a render. These
renders should be blocking and in the same microtask as the
`startGesture` to ensure it can block the paint. So it's similar to
sync.
It may not be possible to finish it synchronously e.g. if something
suspends. If so, it just tries again later when it can like any other
render. This can also happen because it also may not be possible to
drive more than one gesture at a time like if we're limited to one View
Transition per document. So right now you can only run one gesture at a
time in practice.
These renders never commit. This means that we can't clear the
`GestureLane` the normal way. Instead, we have to clear only the root's
`pendingLanes` if we don't have any new renders scheduled. Then wait
until something else updates the Fiber after all gestures on it have
stopped before it really clears.
For Hookstate Proxies of class instances, `data.constructor.name`
returns `Proxy({})`, so use
`Object.getPrototypeOf(data).constructor.name` instead, which works
correctly from my testing.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
React DevTools immediately bricks itself if you inspect any component
that has a prop that is a Hookstate that wraps a class instance ...
because these are proxies where `data.constructor.name` returns some
un-cloneable object, but `Object.getPrototypeOf(data)` doesn't return
`Object` (it returns the prototype of the class inside).
## How did you test this change?
This part of the code has no associated tests at all.
Technically,
`packages/react-devtools-shared/src/__tests__/legacy/inspectElement-test.js`
exists, but I tried `yarn test` and these tests aren't even executed
anymore. I can't figure it out, so whatever.
If you run this code:
```js
class Class {}
const instance = new Class();
const instanceProxy = new Proxy(instance, {
get(target, key, receiver) {
if (key === 'constructor') {
return { name: new Proxy({}, {}) };
}
return Reflect.get(target, key, receiver);
},
});
```
then `instanceProxy.constructor.name` returns some proxy that cannot be
cloned, but `Object.getPrototypeOf(instanceProxy).constructor.name`
returns the correct value.
This PR fixes the devtools to use
`Object.getPrototypeOf(instanceProxy).constructor.name`.
I modified my local copy of devtools to use this method and it fixed the
bricking that I experienced.
Related #29954
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
When using React Devtools, calling `console.log('%s', null)` in userland
can cause it to throw an error:
```
TypeError: Cannot read properties of null (reading 'toString')
```
## How did you test this change?
Added a unit test.
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
See https://github.com/47ng/nuqs/issues/808.
## Summary
In React Native, public instances and internal host nodes are not
represented by the same object (ReactNativeElement & shadow nodes vs.
just DOM elements), and the only one that's required for rendering is
the shadow node. Public instances are generally only necessary when
accessed via refs or events, and that usually happens for a small amount
of components in the tree.
This implements an optimization to create the public instance on demand,
instead of eagerly creating it when creating the host node. We expect
this to improve performance by reducing the logic we do per node and the
number of object allocations.
## How did you test this change?
Manually synced the changes to React Native and run Fantom tests and
benchmarks, with the flag enabled and disabled. All tests pass in both
cases, and benchmarks show a slight but consistent performance
improvement.
## Summary
Fixes#32354.
Re-creation of #15197: adds a dev-only warning if `create == null` to
the three `use*Effect` functions:
* `useEffect`
* `useInsertionEffect`
* `useLayoutEffect`
Updates the warning to match the same text given in the
`react/exhaustive-deps` lint rule.
## How did you test this change?
I applied the changes manually within `node_modules/` on a local clone
of
https://github.com/JoshuaKGoldberg/repros/tree/react-use-effect-no-arguments.
Please pardon me for opening a PR addressing a not-accepted issue. I was
excited to get back to #15194 -> #15197 now that I have time. 🙂
---------
Co-authored-by: lauren <poteto@users.noreply.github.com>
Merges the useResourceEffect API into useEffect while keeping the
underlying implementation the same. useResourceEffect will be removed in
the next diff.
To fork between behavior we rely on a `typeof` check for the updater or
destroy function in addition to the CRUD feature flag. This does now
have to be checked every time (instead of inlined statically like before
due to them being different hooks) which will incur some non-zero amount
(possibly negligble) of overhead for every effect.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32205).
* #32206
* __->__ #32205
Small refactor to the `resource` type to narrow it to an arbitrary
object or void/null instead of the top type. This makes the overload on
useEffect simpler since the return type of create is no longer widened
to the top type when we merge their definitions.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32203).
* #32206
* #32205
* #32204
* __->__ #32203
## Summary
This PR attempts to make running the React DevTools a little friendlier
in projects that are not completely React.
At the moment, running the DevTools with `npx react-devtools` will
default to the port to use the `PORT` env variable otherwise it'll fall
back to `8097`. `PORT` is a common env variable, so we can get into this
strange situation where the a Rails server (eg Puma) is using `PORT`,
and then the React DevTools attempts to boot using the same `PORT`.
This PR introduces a dedicated env variable, `REACT_DEVTOOLS_PORT` to
assist in this scenario.
## How did you test this change?
I'm using fish shell, so I did the following, please let me know if
there's a better way:
```sh
cd packages/react-devtools
set -x PORT 1000
set -x REACT_DEVTOOLS_PORT 2000
node bin.js
```
We can see in the UI that it's listening on `2000`. Without this PR,
it'd listen on `1000`:

Follow-up for #32332. The Discord webhook seems to ignore draft PRs,
which is a good thing. But when a draft PR is then later set to "ready
for review" we do want to send another notification that should not be
filtered out.
Our internal build infra relies on a 1:1 mapping between `main` and the
2 build branches. Directly committing changes to those branches breaks
that infra.
Adds a simple workflow to leave a comment and decline the PR.
There's no real reason to have 2 jobs for sizebot. It's more of a
historical artifact from before the GH migration. Merging them should
require one less worker needing to be provisioned and some of the extra
overhead
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32333).
* __->__ #32333
* #32332
Adds a new Timing logger event to the compiler which currently only
records the walltime of running the compiler from the time the babel
plugin's Program visitor enters to the time it exits.
To enable, run the compiler with `ENABLE_REACT_COMPILER_TIMINGS=1 ...`
or `export ENABLE_REACT_COMPILER_TIMINGS=1` to set it by default.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
Improve the error message, as the value is currently an object instead
of a string, which results in it being converted to '[object Object]'.
## How did you test this change?
Already tested locally.
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
followup to
* https://github.com/facebook/react/pull/32069
* https://github.com/facebook/react/pull/32163
* https://github.com/facebook/react/pull/32224
in react-dom in Dev we validate that the tag nesting is valid. This is
motivated primarily because while browsers are tolerant to poor HTML
there are many cases that if server rendered will be hydrated in a way
that will break hydration.
With the changes to singleton scoping where the document body is now the
implicit render/hydration context for arbitrary tags at the root we need
to adjust the validation logic to allow for valid programs such as
rendering divs as a child of a Document (since this div will actually
insert into the body).
While modern DOM implementations all support getRootNode if you are
running React in a runtime which does not the fallback logic which uses
`.ownerDocument` works everywhere except when the container is a
Document itself. This change corrects this by returning the container
intsance if it is a Document type.
We have this really old (5+ years) feature for inspecting native styles
of React Native Host components.
We also have a custom Cache implementation in React DevTools, which was
forked from React at some point. We know that this should be removed,
but it spans through critical parts of the application, like fetching
and caching inspected element.
Before this PR, this was also used for caching native style and layouts
of RN Host components. This approach is out of date, and was based on
the presence of Suspense boundary around inspected element View, which
we have removed to speed up element inspection -
https://github.com/facebook/react/pull/30555.
Looks like I've introduced a regression in
https://github.com/facebook/react/pull/31956:
- Custom Cache implementation will throw thenables and suspend.
- Because of this, some descendant Suspense boundaries will not resolve
for a long time, and React will throw an error
https://react.dev/errors/482.
I've switched from a usage of this custom Cache implementation to a
naive fetching in effect and keeping the layout and style in a local
state of a Context, which will be propagated downwards. The race should
be impossible, this is guaranteed by the mechanism for queueing messages
through microtasks queue.
The only downside is the UI. If you quickly switch between 2 elements,
and one of them has native style, while the other doesn't, UI will feel
jumpy. We can address this later with a Suspense boundary, if needed.
3 years ago we partially disabled comment nodes as valid containers.
Some unflagged support was left in due to legacy APIs like
`unmountComponentAtNode` and `unstable_renderSubtreeIntoContainer` but
these were since removed in React 19. This update flags the remaining
uses of comments as containers.
follow up to https://github.com/facebook/react/pull/32163
This continues the work of making Suspense workable anywhere in a
react-dom tree. See the prior PRs for how we handle server rendering and
client rendering. In this change we update the hydration implementation
to be able to locate expected nodes. In particular this means hydration
understands now that the default hydration context is the document body
when the container is above the body.
One case that is unique to hydration is clearing Suspense boundaries.
When hydration fails or when the server instructs the client to recover
an errored boundary it's possible that the html, head, and body tags in
the initial document were written from a fallback or a different primary
content on the server and need to be replaced by the client render.
However these tags (and in the case of head, their content) won't be
inside the comment nodes that identify the bounds of the Suspense
boundary. And when client rendering you may not even render the same
singletons that were server rendered. So when server rendering a
boudnary which contributes to the preamble (the html, head, and body tag
openings plus the head contents) we emit a special marker comment just
before closing the boundary out. This marker encodes which parts of the
preamble this boundary owned. If we need to clear the suspense boundary
on the client we read this marker and use it to reset the appropriate
singleton state.
This implements `findSourceMapURL` in react-server-dom-parcel, enabling
source maps for replayed server errors on the client. It utilizes a new
endpoint in the Parcel dev server that returns the source map for a
given bundle/file. The error overlay UI has also been updated to handle
these stacks. See https://github.com/parcel-bundler/parcel/pull/10082
Also updated the fixture to the latest Parcel canary. A few APIs have
changed. We do have a higher level library wrapper now (`@parcel/rsc`
added in https://github.com/parcel-bundler/parcel/pull/10074) but I left
the fixture using the lower level APIs directly here since it is easier
to see how react-server-dom-parcel is used.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Contributing to https://github.com/facebook/react/pull/32240, this
change adds the tsconfig, tsup config, and estree type declarations that
will be needed for that plugin's typescript migration.
Hacky retry pipeline for when transforming `fire(...)` calls encounters
validation, todo, or memoization invariant bailouts. Would love feedback
on how we implement this to be extensible to other compiler
non-memoization features (e.g. inlineJSX)
Some observations:
- Compiler "front-end" passes (e.g. lower, type, effect, and mutability
inferences) should be shared for all compiler features -- memo and
otherwise
- Many passes (anything dealing with reactive scope ranges, scope blocks
/ dependencies, and optimizations such as ReactiveIR #31974) can be left
out of the retry pipeline. This PR hackily skips memoization features by
removing reactive scope creation, but we probably should restructure the
pipeline to skip these entirely on a retry
- We should maintain a canonical set of "validation flags"
Note the newly added fixtures are prefixed with `bailout-...` when the
retry fire pipeline is used. These fixture outputs contain correctly
inserted `useFire` calls and no memoization.
## Summary
When lookup `Parent`, `HostRoot` and `HostPortal` should be merged,
because when creating a `Portal`, it will also include
`containerInfo`(So we can directly use this `containerInfo` to delete
the real DOM nodes.), so there is no need to handle them separately.
## How did you test this change?
No behavior changes, all existing tests pass.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Contributing to https://github.com/facebook/react/pull/32240, this
change adds the dev dependencies needed to support the migration of the
plugin to typescript.
## Summary
Fix typo in dangerfile.js which results in an unreachable code path
which ought to be hit when there is no matching base artifact during
DangerCI automated code review.
See:
221f3002ca/dangerfile.js (L73)
Compare:
221f3002ca/dangerfile.js (L171)
And the case which should hit this code path:
221f3002ca/dangerfile.js (L160)
Given the above context, the condition `Number === Infinity` is clearly
meant to be `decimal === Infinity`, which it will be if the `catch`
statement triggers when there is no matching base artifact. Without this
fix, the primitive value `Infinity` is passed to
`percentFormatter.format(decimal)`, resulting in the string `'+∞%'`.
With this fix, the resulting string will be the intended `'New file'`.
## [Resolves issue
32278](https://github.com/facebook/react/issues/32278)
Addresses https://github.com/facebook/react/issues/32244.
### Chromium
We will use
[chrome.permissions](https://developer.chrome.com/docs/extensions/reference/api/permissions)
for checking / requesting `clipboardWrite` permission before copying
something to the clipboard.
### Firefox
We will keep `clipboardWrite` as a required permission, because there is
no reliable and working API for requesting optional permissions for
extensions that are extending browser DevTools:
- `chrome.permissions` is unavailable for devtools pages -
https://bugzilla.mozilla.org/show_bug.cgi?id=1796933
- You can't call `chrome.permissions.request` from background, because
this instruction has to be executed inside user-event callback,
basically only initiated by user.
I don't really want to come up with solutions like opening a new tab
with a button that user has to click.
When a named ViewTransition component unmounts in one place and mounts
in a different place we need to match these up so we know a pair has
been created. Since the unmounts are tracked in the snapshot phase we
need some way to track the mounts before that.
Originally the way I did that is by reusing the render phase since there
was no other phase in the commit before that. However, that's not quite
correct. Just because something is visited in render doesn't mean it'll
commit. E.g. if that tree ends up suspending or erroring. Which would
lead to a false positive on match. The unmount shouldn't animate in that
case.
(Un)fortunately we have already added a traversal before the snapshot
phase for tracking suspensey CSS. The `accumulateSuspenseyCommit` phase.
This needs to find new mounts of Suspensey CSS or if there was a
reappearing Offscreen boundary it needs to find any Suspensey CSS
already inside that tree. This is exactly the same traversal we need to
find newly appearing View Transition components. So we can just reuse
that.
I just noticed that we don't actually need to let the devtools build
finish first because the e2e tests don't use those built files. We can
decouple them to allow them to run in paralllel.
Building DevTools is currently the long pole for the runtime CI job.
Let's see if we can get the overall runtime for runtime build and test
down by speeding this one step up.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32266).
* #32267
* __->__ #32266
## Summary
`fastAddProperties` has shown some perf benefits when used for creating
props payload for new components. In this PR we'll try to use it for
diffing props for existing components.
It would be good enough if it simply doesn't regress perf. We'll be able
to delete the old `addProperties`, and make `fastAddProperties` the
default behaviour.
## How did you test this change?
```
yarn lint
yarn flow native
yarn test packages/react-native-renderer -r=xplat --variant=false
yarn test packages/react-native-renderer -r=xplat --variant=true
```
## Summary
We're adding support for `Document` instances in React Native (as
`ReactNativeDocument` instances) in
https://github.com/facebook/react-native/pull/49012 , which requires the
React Fabric renderer to handle its lifecycle.
This modifies the renderer to create those document instances and
associate them with the React root, and provides a new method for React
Native to access them given its containerTag / rootTag.
## How did you test this change?
Tested e2e in https://github.com/facebook/react-native/pull/49012
manually syncing these changes.
This is a follow up to https://github.com/facebook/react/pull/32069
In the prior change I updated Fizz to allow you to render Suspense
boundaries at any level within a react-dom application by treating the
document body as the default render scope. This change updates Fiber to
provide similar semantics. Note that this update still does not deliver
hydration so unifying the Fizz and Fiber implementations in a single App
is not possible yet.
The implementation required a rework of the getHostSibling and
getHostParent algorithms. Now most HostSingletons are invisible from a
host positioning perspective. Head is special in that it is a valid host
scope so when you have Placements inside of it, it will act as the
parent. But body, and html, will not directly participate in host
positioning.
Additionally to support flipping to a fallback html, head, and body tag
in a Suspense fallback I updated the offscreen hiding/unhide logic to
pierce through singletons when lookin for matching hidable nod
boundaries anywhere (excluding hydration)
Corresponding Parcel PR:
https://github.com/parcel-bundler/parcel/pull/10073
Parcel avoids [cascading cache
invalidation](https://philipwalton.com/articles/cascading-cache-invalidation/)
by injecting a bundle manifest containing a mapping of stable bundle ids
to hashed URLs. When using an HTML entry point, this is done (as of the
above PR) via a native import map. This means that if a bundle's hash
changes, only that bundle will be invalidated (plus the HTML itself
which typically has a short caching policy), not any other bundles that
reference it.
For RSCs, we cannot currently use native import maps because of client
side navigations, where a new HTML file is not requested. Eventually,
multiple `<script type="importmap">` elements will be supported
(https://github.com/whatwg/html/pull/10528) ([coming Chrome
133](https://chromestatus.com/feature/5121916248260608)), at which point
React could potentially inject them. In the meantime, I've added some
APIs to Parcel to polyfill this. With this change, an import map can be
sent along with a client reference, containing a mapping for any dynamic
imports and URL dependencies (e.g. images) that are referenced by the JS
bundles. On the client, the import map is extended with these new
mappings prior to executing the referenced bundles. This preserves the
caching advantages described above while supporting client navigations.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
## Summary
PR https://github.com/facebook/react/pull/31963 migrated the bundler
from Rollup to esbuild, but the `react-compiler-healthcheck` script
lacks a shebang, leading to issues with `npx` not being able to execute
it.
dc7578290f/compiler/packages/react-compiler-healthcheck/rollup.config.js (L60-L78)9eabb37338/compiler/packages/react-compiler-healthcheck/scripts/build.js (L38-L53)
## How did you test this change?
**Before**
(fail)
```shell
(main)> npx --version
10.5.0
(main)> npx react-compiler-healthcheck
/home/jeremy/.npm/_npx/67b118a83a29962c/node_modules/.bin/react-compiler-healthcheck: line 1: /bin: Is a directory
/home/jeremy/.npm/_npx/67b118a83a29962c/node_modules/.bin/react-compiler-healthcheck: line 2: syntax error near unexpected token `('
/home/jeremy/.npm/_npx/67b118a83a29962c/node_modules/.bin/react-compiler-healthcheck: line 2: ` * Copyright (c) Meta Platforms, Inc. and affiliates.'
```
**After**
```shell
(main)> npx react-compiler-healthcheck
Successfully compiled 108 out of 146 components.
StrictMode usage not found.
Found no usage of incompatible libraries.
```
I wrote this a couple summers back as an experiment to see how easily we could translate the compiler to Rust. We make extensive use of in-place mutation of the IR, and the experiment proved that this we can get reasonable ergonomics for this in Rust which was cool. We've since ended up using some of the code here for Relay, allowing Relay Compiler to parse JS files to do more fine-grained extraction of data. For React Compiler though, we plan to continue using JavaScript and explore lightweight native wrappers for things like OXC and SWC plugins. We're also working with the Hermes team to eventually compile the compiler with Static Hermes.
As Tomo always says: always bet on JavaScript.
ghstack-source-id: c5770a2efc
Pull Request resolved: https://github.com/facebook/react/pull/32219
## Summary
This fixes#30659 , the issue was how the state was preserved and needed
special cases for the forward and memo, have also added tests related to
the same.
## How did you test this change?
`yarn test packages/react-refresh/src/__tests__/ReactFresh-test.js`

<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Our [LlamaIndex](https://www.llamaindex.ai/) Product is blocked by this
bug
Fixes: https://github.com/facebook/react/issues/32137
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
- Adds support for `experimental_useEffectEvent`, now DevTools will be
able to display this hook for inspected element
- Added a use case to DevTools shell, couldn't add case, because we are
using ReactTestRenderer, which has the corresponding flag disabled.
- Forward-fix logic for handling `experimental` prefix that was added in
https://github.com/facebook/react/pull/32088.

This adds an isomorphic API to add Transition Types, which represent the
cause, to the current Transition. This is currently mainly for View
Transitions but as a concept it's broader and we might expand it to more
features and object types in the future.
```js
import { unstable_addTransitionType as addTransitionType } from 'react';
startTransition(() => {
addTransitionType('my-transition-type');
setState(...);
});
```
If multiple transitions get entangled this is additive and all
Transition Types are collected. You can also add more than one type to a
Transition (hence the `add` prefix).
Transition Types are reset after each commit. Meaning that `<Suspense>`
revealing after a `startTransition` does not get any View Transition
types associated with it.
Note that the scoping rules for this is a little "wrong" in this
implementation. Ideally it would be scoped to the nearest outer
`startTransition` and grouped with any `setState` inside of it.
Including Actions. However, since we currently don't have AsyncContext
on the client, it would be too easy to drop a Transition Type if there
were no other `setState` in the same `await` task. Multiple Transitions
are entangled together anyway right now as a result. So this just tracks
a global of all pending Transition Types for the next Transition. An
inherent tricky bit with this API is that you could update multiple
roots. In that case it should ideally be associated with each root.
Transition Tracing solves this by associating a Transition with any
updates that are later collected but this suffers from the problem
mentioned above. Therefore, I just associate Transition Types with one
root - the first one to commit. Since the View Transitions across roots
are sequential anyway it kind of makes sense that only one really is the
cause and the other one is subsequent.
Transition Types can be used to apply different animations based on what
caused the Transition. You have three different ways to choose from for
how to use them:
## CSS
It integrates with [View Transition
Types](https://www.w3.org/TR/css-view-transitions-2/#active-view-transition-pseudo-examples)
so you can match different animations based on CSS scopes:
```css
:root:active-view-transition-type(my-transition-type) {
&::view-transition-...(...) {
...
}
}
```
This is kind of a PITA to write though and if you have a CSS library
that provide View Transition Classes it's difficult to import those into
these scopes.
## Class per Type
This PR also adds an object-as-map form that can be passed to all
`className` properties:
```js
<ViewTransition className={{
'my-navigation-type': 'hello',
'default': 'world',
}}>
```
If multiple types match, then they're joined together. If no types match
then the special `"default"` entry is used instead. If any type has the
value `"none"` then that wins and the ViewTransition is disabled (not
assigned a name).
These can be combined with `enter`/`exit`/`update`/`layout`/`share`
props to match based on kind of trigger and Transition Type.
```js
<ViewTransition enter={{
'navigation-back': 'enter-right',
'navigation-forward': 'enter-left',
}}
exit={{
'navigation-back': 'exit-right',
'navigation-forward': 'exit-left',
}}>
```
## Events
In addition, you can also observe the types in the View Transition Event
callbacks as the second argument. That way you can pick different
imperative Animations based on the cause.
```js
<ViewTransition onUpdate={(inst, types) => {
if (types.includes('navigation-back')) {
...
} else if (types.includes('navigation-forward')) {
...
} else {
...
}
}}>
```
## Future
In the future we might expose types to `useEffect` for more general
purpose usage. This would also allow non-View Transition based
Animations such as existing libraries to use this same feature to
coordinate the same concept.
We might also allow richer objects to be passed along here. Only the
strings would apply to View Transitions but the imperative code and
effects could do something else with them.
Typed errors is not a feature that Flight currently supports. However,
for presentation purposes, serializing a custom error name is something
we could support today.
With this PR, we're now transporting custom error names through the
server-client boundary, so that they are available in the client e.g.
for console replaying. One example where this can be useful is when you
want to print debug information while leveraging the fact that
`console.warn` displays the error stack, including handling of hiding
and source mapping stack frames. In this case you may want to show
`Warning: ...` or `Debug: ...` instead of `Error: ...`.
In prod mode, we still transport an obfuscated error that uses the
default `Error` name, to not leak any sensitive information from the
server to the client. This also means that you must not rely on the
error name to discriminate errors, e.g. when handling them in an error
boundary.
rollup doesn't inline cjs requires (although it can with an external
plugin), so requiring package.json was causing issues internally at Meta
since that file doesn't exist there.
We could teach our build scripts to do so but given that the eslint meta
field is optional anyways I opted to just hardcode the name and omit the
version.
Suspense is meant to be composable but there has been a lonstanding
limitation with using Suspense above the `<body>` tag of an HTML
document due to peculiarities of how HTML is parsed. For instance if you
used Suspense to render an entire HTML document and had a fallback that
might flush an alternate Document the comment nodes which describe this
boundary scope won't be where they need to be in the DOM for client
React to properly hydrate them. This is somewhat a problem of our own
making in that we have a concept of a Preamble and we leave the closing
body and html tags behind until streaming has completed which produces a
valid HTML document that also matches the DOM structure that would be
parsed from it. However Preambles as a concept are too important to
features like Float to imagine moving away from this model and so we can
either choose to just accept that you cannot use Suspense anywhere
except inside the `<body>` or we can build special support for Suspense
into react-dom that has a coherent semantic with how HTML documents are
written and parsed.
This change implements Suspense support for react-dom/server by
correctly serializing boundaries during rendering, prerendering, and
resumgin on the server. It does not yet support Suspense everywhere on
the client but this will arrive in a subsequent change. In practice
Suspense cannot be used above the `<body>` tag today so this is not a
breaking change since no programs in the wild could be using this
feature anyway.
React's streaming rendering of HTML doesn't lend itself to replacing the
contents of the documentElement, head, or body of a Document. These are
already special cased in fiber as HostSingletons and similarly for Fizz
the values we render for these tags must never be updated by the Fizz
runtime once written. To accomplish these we redefine the Preamble as
the tags that represent these three singletons plus the contents of the
document.head. If you use Suspense above any part of the Preamble then
nothing will be written to the destination until the boundary is no
longer pending. If the boundary completes then the preamble from within
that boudnary will be output. If the boundary postpones or errors then
the preamble from the fallback will be used instead.
Additionally, by default anything that is not part of the preamble is
implicitly in body scope. This leads to the somewhat counterintuitive
consequence that the comment nodes we use to mark the borders of a
Suspense boundary in Fizz can appear INSIDE the preamble that was
rendered within it.
```typescript
render((
<Suspense>
<html lang="en">
<body>
<div>hello world</div>
</body>
</html>
</Suspense>
))
```
will produce an HTML document like this
```html
<!DOCTYPE html>
<html lang="en">
<head></head>
<body>
<!--$--> <-- this is the comment Node representing the outermost Suspense
<div>hello world</div>
<$--/$-->
</body>
</html>
```
Later when I update Fiber to support Suspense anywhere hydration will
similarly start implicitly in the document body when the root is part of
the preamble (the document or one of it's singletons).
For now we just reject all calls of impure functions, and the validation
is off by default. Going forward we can make this more precise and only
reject impure functions called during render.
Note that I was intentionally imprecise in the return type of these
functions in order to avoid changing output of existing code. We lie to
the compiler and say that Date.now, performance.now, and Math.random
return unknown mutable objects rather than primitives. Once the
validation is complete and vetted we can switch this to be more precise.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
I've noticed that the value stored under `is_core_team` gets
stringified, so some PRs may be mislabelled as coming from the core
team.
I've checked this on my fork and saw stringified `null` returned by the
`is_core_team`, and this PR explicitly checks for the correct value.
Feel free to close this PR if you want to go with another approach.
## How did you test this change?
Checked this change on my fork with and without listing myself in the
maintainers file.
Adds a new `MAINTAINERS` file which contains github usernames of core
team members. This file serves as documentation for core team membership
and is also used to automatically label PRs from core.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/32100).
* #32101
* __->__ #32100
Alternative to #32071. As a follow up to #31993, the `platform` target
was incorrectly being set to `browser` since it was the default argument
for the build script. This corrects it to `node` and `cjs` which I think
should resolve node 20 issues.
We don't always consistently use "tags" in commit messages, so let's use
the filepaths modified in the PR instead to determine which channel to
send notifications to.
Since we've started experimenting with it, I've started seeing a spike
in errors:
```
Unsupported hook in the react-debug-tools package: Missing method in Dispatcher: useResourceEffect
```
Adding missing hook to the `Dispatcher` that is proxied by React
DevTools.
I can't really add an example that will use it to our RDT testing shell,
because it uses experimental builds of `react`, which don't have this
hook. I've tested it manually by rebuilding artifacts with
`enableUseResourceEffectHook` flag enabled.

The DOM fixture hasn't worked on local builds since the UMD support was
removed in https://github.com/facebook/react/pull/28735
Here we update the fixture to set the local experimental builds to
window. Some of the pages are still broken, such as hydration. But these
bugs exist on other versions as well and can be cleaned up separately.
## Summary
This pull request addresses an issue where the copy functionality was
not working in Firefox. The root cause was the absence of the
'clipboardWrite' permission in the manifest. To ensure consistency
across all supported browsers, the 'clipboardWrite' permission has been
added to the manifests for Chrome, Edge, and Firefox extensions.
Closes#31422
## How did you test this change?
I ran the modified extension in all browsers (MacOS) and verified that
the copy functionality works in each.
https://github.com/user-attachments/assets/a41ff14b-3d65-409c-ac7f-1ccd72fa944a
The forking for `shared/ReactFeatureFlags` doesn't work in the console
patches. Since they're already forked, we can import the internal
ReactFeatureFlags files directly.
Would have caught this in testing a PR sync, but the PR syncs are broken
right now.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
This pull request resolves an issue where consecutive profiling sessions
would cause Dev Tools to freeze due to an infinite loop of state
updates. The problem occurs when the startProfiling function triggers a
call to [`selectCommitIndex(0)` in
SnapshotSelector](b3a95caf61/packages/react-devtools-shared/src/devtools/views/Profiler/SnapshotSelector.js (L77-L85))
as previous profiling data is available, which causes a re-render. Then,
[ProfilerContextProvider calls
`selectCommitIndex(null)`](b3a95caf61/packages/react-devtools-shared/src/devtools/views/Profiler/ProfilerContext.js (L231-L241))
to clear the view while profiling is in progress, leading to another
re-render and creating an infinite loop. This behavior was prevented by
clearing the existing profiling data before starting a new session.
Closes#31977Closes#31679
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
I ran the Dev Tools locally following [the contributing
guideline](b3a95caf61/packages/react-devtools/CONTRIBUTING.md).
I observed the freeze at the start of the second profiling session.
Then, I modified the code to clear the store when starting a new session
and ran the Dev Tools again. This time, no freeze was observed.
Before:
https://github.com/user-attachments/assets/9d790f84-f6d0-4951-8202-e599cf8d225b
After:
https://github.com/user-attachments/assets/af097019-0b8f-49dd-8afc-0f6cd72af787
## Summary
This change fixes a gap in the plugin's support of eslint v9. In one
place that it's using the `SourceCode` api, it's correctly considering
v9's api. But in the other place where `SourceCode` is used, it's only
using the legacy api, which was removed in v9.
This adds five props to `<ViewTransition>` that adds a specific
`view-transition-class` when React wants to animate it based on the
heuristic that triggers.
```js
<ViewTransition
enter="slide-from-left"
exit="slide-to-right"
layout="slide"
update="none"
share="cross-fade"
>
```
- `enter`: The <ViewTransition> or its parent Component is mounted and
there's no other <ViewTransition> with the same name being deleted.
- `exit`: The <ViewTransition> or its parent Component is unmounted and
there's no other <ViewTransition> with the same name being deleted.
- `layout`: There are no updates to the content inside this
<ViewTransition> boundary itself but the boundary has resized or moved
due to other changes to siblings.
- `share`: This <ViewTransition> is being mounted and another
<ViewTransition> instance with the same name is being unmounted
elsewhere.
- `update`: The content of <ViewTransition> has changed either due to
DOM mutations or because an inner child <ViewTransition> has resized.
The existing `className` is the baseline and the others are added to it
to combine.
This is convenient to distinguish things like `enter` / `exit` but that
can already be expressed as CSS. The other cases can't be expressed as
purely CSS.
`"none"` is a special value that deactivates the view transition name
under that condition.
The most important feature of this is that you can now limit View
Transitions to only tigger when a particular DOM node is affected, not
when just any child updates, by opt-ing out a subtree. This is safer
when added to shared parent.
```js
<ViewTransition>
<div>
<ViewTransition className="none">
{children}
</ViewTransition>
</div>
</ViewTransition>
```
This can't be fully expressed using neither just CSS nor the imperative
refs API since we need some way to have already removed the
`view-transition-name` when this happens. When you think about the
implementation details it might seem a bit strange that you specify the
`class` to `none` to remove the `name` but it's really about picking
which animation should happen for that case default (`undefined`), a
specific one (class) or none (`"none"`).
This adds five events to `<ViewTransition>` that triggers when React
wants to animate it.
- `onEnter`: The `<ViewTransition>` or its parent Component is mounted
and there's no other `<ViewTransition>` with the same name being
deleted.
- `onExit`: The `<ViewTransition>` or its parent Component is unmounted
and there's no other `<ViewTransition>` with the same name being
deleted.
- `onLayout`: There are no updates to the content inside this
`<ViewTransition>` boundary itself but the boundary has resized or moved
due to other changes to siblings.
- `onShare`: This `<ViewTransition>` is being mounted and another
`<ViewTransition>` instance with the same name is being unmounted
elsewhere.
- `onUpdate`: The content of `<ViewTransition>` has changed either due
to DOM mutations or because an inner child `<ViewTransition>` has
resized.
Only one of these events is fired per Transition. If you want to cover
all updates you have to listen to `onLayout`, `onShare` and `onUpdate`.
We could potentially do something like fire `onUpdate` if `onLayout` or
`onShare` isn't specified but it's a little sketchy to have behavior
based on if someone is listening since it limits adding wrappers that
may or may not need it.
Each takes a `ViewTransitionInstance` as an argument so you don't need a
ref to animate it.
```js
<ViewTransition onEnter={inst => inst.new.animate(keyframes, options)}>
```
The timing of this event is after the View Transition's `ready` state
which means that's too late to do any changes to the View Transition's
snapshots but now both the new and old pseudo-elements are ready to
animate.
The order of `onExit` is parent first, where as the others are child
first. This mimics effect mount/unmount.
I implement this by adding to a queue in the commit phase and then call
it while we're finishing up the commit. This is after layout effects but
before passive effects since passive effects fire after the animation is
`finished`.
This adds refs to View Transition that can resolve to an instance of:
```js
type ViewTransitionRef = {
name: string,
group: Animatable,
imagePair: Animatable,
old: Animatable,
new: Animatable,
}
```
Animatable is a type that has `animate(keyframes, options)` and
`getAnimations()` on it. It's the interface that exists on Element that
lets you start animations on it. These ones are like that but for the
four pseudo-elements created by the view transition.
If a name changes, then a new ref is created. That way if you hold onto
a ref during an exit animation spawned by the name change, you can keep
calling functions on it. It will keep referring to the old name rather
than the new name.
This allows imperative control over the animations instead of using CSS
for this.
```js
const viewTransition = ref.current;
const groupAnimation = viewTransition.group.animate(keyframes, options);
const imagePairAnimation = viewTransition.imagePair.animate(keyframes, options);
const oldAnimation = viewTransition.old.animate(keyframes, options);
const newAnimation = viewTransition.new.animate(keyframes, options);
```
The downside of using this API is that it doesn't work with SSR so for
SSR rendered animations they'll fallback to the CSS. You could use this
for progressive enhancement though.
Note: In this PR the ref only controls one DOM node child but there can
be more than one DOM node in the ViewTransition fragment and they are
just left to their defaults. We could try something like making the
`animate()` function apply to multiple children but that could lead to
some weird consequences and the return value would be difficult to
merge. We could try to maintain an array of Animatable that updates with
how ever many things are currently animating but that makes the API more
complicated to use for the simple case. Conceptually this should be like
a fragment so we would ideally combine the multiple children into a
single isolate if we could. Maybe one day the same name could be applied
to multiple children to create a single isolate. For now I think I'll
just leave it like this and you're really expect to just use it with one
DOM node. If you have more than one they just get the default animations
from CSS.
Using this is a little tricky due timing. In this fixture I just use a
layout effect plus rAF to get into the right timing after the
startViewTransition is ready. In the future I'll add an event that fires
when View Transitions heuristics fire with the right timing.
Stacked on https://github.com/facebook/react/pull/31956. See [commit on
top](ecb8df4175).
Use `initialScrollOffset` prop for `FixedSizeList` from `react-window`.
This happens when user selects an element in built-in Elements panel in
DevTools, and then opens Components panel from React DevTools - elements
will be synced and corresponding React Element will be pre-selected, we
just have to scroll to its position now.
Stacked on https://github.com/facebook/react/pull/31892, see commit on
top.
For some reason, there were 2 fields different fields for essentially
same thing: `selectedElementID` and `inspectedElementID`. Basically, the
change is:
```
selectedElementID -> inspectedElementID
selectedElementIndex -> inspectedElementIndex
```
I have a theory that it was due to previously used async approach around
element inspection, and the whole `InspectedElementView` was wrapped in
`Suspense`.
Related: https://github.com/facebook/react/pull/31342
This fixes RDT behaviour when some DOM element was pre-selected in
built-in browser's Elements panel, and then Components panel of React
DevTools was opened for the first time. With this change, React DevTools
will correctly display the initial state of the Components Tree with the
corresponding React Element (if possible) pre-selected.
Previously, we would only subscribe listener when `TreeContext` is
mounted, but this only happens when user opens one of React DevTools
panels for the first time. With this change, we keep state inside
`Store`, which is created when Browser DevTools are opened. Later,
`TreeContext` will use it for initial state value.
Planned next changes:
1. Merge `inspectedElementID` and `selectedElementID`, I have no idea
why we need both.
2. Fix issue with `AutoSizer` rendering a blank container.
In this PR:
1. Removed unused code in `Tree.js`
2. Removed logic for pre-selecting first element in the tree by default.
This is a bit clowny, because it steals focus and resets scroll, when
user attempts to expand / collapse some subtree.
3. Updated comments around
1c381c588a.
To expand on 3-rd point, for someone who might be reading this in the
future:
We can't guarantee focus of RDT browser extension panels, because they
are hosted in an `iframe`. Attempting to fire any events won't have any
result, user action with the corresponding `iframe` is required in order
for this `iframe` to obtain focus.
The only reason why built-in Elements panel in Chrome works correctly is
because it is supported natively somewhere in Chrome / Chrome DevTools.
Also, when you select an element on the application page, Chrome will
make sure that Elements panel opened, which technically guarantees focus
inside DevTools window and Elements panel subview.
As of today, we can't navigate user to third-party extensions panels,
there is no API for this, hence no ability to guarantee focused RDT
panels.
Feature was added in https://github.com/facebook/react/pull/31577, lets
enable it by default. Note: for gradual rollout with React Native, we
will continue to emit different event, requires some changes on React
Native side to support this.
I have plans to make this feature to be accessible via browser context
menu, which has really limited API. In order to minimize potential
divergence, lets make this the default state for the feature.
- Adds @compilationMode(all|infer|syntax|annotation) and
@panicMode(none) directives. This is now shared with our test infra
- Playground still defaults to `infer` mode while tests default to `all`
mode
- See added fixture tests
I had forgotten that our default error reporting threshold was `none`
due to the fact that build pipelines should not throw errors. This
resets it back to throwing on all errors which mostly is the same as the
eslint plugin.
Closes#32014.
## Summary
Callers for this method has been removed in
65bda54232,
so these methods no longer need to be conditionally exported and the
feature flag can be removed.
## How did you test this change?
Flow fabric/native
Fonts flickering in while loading can be disturbing to any transition
but especially View Transitions. Even if they don't cause layout thrash
- the paint thrash is bad enough. We might add Suspensey fonts to all
Transitions in the future but it's especially a no-brainer for View
Transitions.
We need to apply mutations to the DOM first to know whether that will
trigger new fonts to load. For general Suspensey fonts, we'd have to
revert the commit by applying mutations in reverse to return to the
previous state. For View Transitions, since a snapshot is already
frozen, we can freeze the screen while we're waiting for the font at no
extra cost. It does mean that the page isn't responsive during this time
but we should only block this for a short period anyway.
The timeout needs to be short enough that it doesn't cause too much of
an issue when it's a new load and slow, yet long enough that you have a
chance to load it. Otherwise we wait for no reason. The assumption here
is that you likely have either cached the font or preloaded it earlier -
or you're on an extremely fast connection. This case is for optimizing
the high end experience.
Before:
https://github.com/user-attachments/assets/e0acfffe-fa49-40d6-82c3-5b08760175fb
After:
https://github.com/user-attachments/assets/615a03d3-9d6b-4eb1-8bd5-182c4c37a628
Note that since the Navigation is blocked on the font now the browser
spinner shows up while the font is loading.
This allows mutations and scrolling in the layout phase to be counted
towards the mutation. This would maybe not be the case for gestures but
it is useful for fire-and-forget.
This also avoids the issue that if you resolve navigation in
useLayoutEffect that it ends up dead locked.
It also means that useLayoutEffect does not observe the scroll
restoration and in fact, the scroll restoration would win over any
manual scrolling in layout effects. For better or worse, this is more in
line with how things worked before and how it works in popstate. So it's
less of a breaking change. This does mean that we can't unify the after
mutation phase with the layout phase though.
To do this we need split out flushSpawnedWork from the flushLayoutEffect
call.
Spawned work from setState inside the layout phase is done outside and
not counted towards the transition. They're sync updates and so are not
eligible for their own View Transitions. It's also tricky to support
this since it's unclear what things like exits in that update would
mean. This work will still be able to mutate the live DOM but it's just
not eligible to trigger new transitions or adjust the target of those.
One difference between popstate is that this spawned work is after
scroll restoration. So any scrolling spawned from a second pass would
now win over scroll restoration.
Another consequence of this change is that you can't safely animate
pseudo elements in useLayoutEffect. We'll introduce a better event for
that anyway.
This adds navigation support to the View Transition fixture using both
`history.pushState/popstate` and the Navigation API models.
Because `popstate` does scroll restoration synchronously at the end of
the event, but `startViewTransition` cannot start synchronously, it
would observe the "old" state as after applying scroll restoration. This
leads to weird artifacts. So we intentionally do not support View
Transitions in `popstate`. If it suspends anyway for some other reason,
then scroll restoration is broken anyway and then it is supported. We
don't have to do anything here because this is already how things worked
because the sync `popstate` special case already included the sync lane
which opts it out of View Transitions.
For the Navigation API, scroll restoration can be blocked. The best way
to do this is to resolve the Navigation API promise after React has
applied its mutation. We can detect if there's currently any pending
navigation and wait to resolve the `startViewTransition` until it
finishes and any scroll restoration has been applied.
https://github.com/user-attachments/assets/f53b3282-6315-4513-b3d6-b8981d66964e
There is a subtle thing here. If we read the viewport metrics before
scroll restoration has been applied, then we might assume something is
or isn't going to be within the viewport incorrectly. This is evident on
the "Slide In from Left" example. When we're going forward to that page
we shift the scroll position such that it's going to appear in the
viewport. If we did this before applying scroll restoration, it would
not animate because it wasn't in the viewport then. Therefore, we need
to run the after mutation phase after scroll restoration.
A consequence of this is that you have to resolve Navigation in
`useInsertionEffect` as otherwise it leads to a deadlock (which
eventually gets broken by `startViewTransition`'s timeout of 10
seconds). Another consequence is that now `useLayoutEffect` observes the
restored state. However, I think what we'll likely do is move the layout
phase to before the after mutation phase which also ensures that
auto-scrolling inside `useLayoutEffect` are considered in the viewport
measurements as well.
Stacked on #31975.
View Transitions cannot handle interruptions in that if you start a new
one before the previous one has finished, it just stops and then
restarts. It doesn't seamlessly transition into the new transition.
This is generally considered a bad thing but I actually think it's quite
good for fire-and-forget animations (gestures is another story). There
are too many examples of bad animations in fast interactions because the
scenario wasn't predicted. Like overlapping toasts or stacked layers
that look bad. The only case interrupts tend to work well is when you do
a strict reversal of an animation like returning to the page you just
left or exiting a modal just being opened. However, we're limited by the
platform even in that regard.
I think one reason interruptions have traditionally been seen as good is
because it's hard if you have a synchronous framework to not interrupt
since your application state has already moved on. We don't have that
limitation since we can suspend commits. We can do all the work to
prepare for the next commit by rendering while the animation is going
but then delay the commit until the previous one finishes.
Another technical limitation earlier animation libraries suffered from
is only have the option to either interrupt or sequence animations since
it's modeling just one change set. Like showing one toast at a time.
That's bad. We don't have that limitation because we can interrupt a
previously suspended commit and start working on a new one instead.
That's what we do for suspended transitions in general. The net effect
is that we batch the commits.
Therefore if you get multiple toasts flying in fast, they can animate as
a batch in together all at once instead of overlapping slightly or being
staggered. Interruptions (often) bad. Staggered animations bad. Batched
animations good.
This PR stashes the currently active View Transition with an expando on
the container that's animating (currently always document). This is
similar to what we do with event handlers etc. We reason we do this with
an expando is that if you have multiple Reacts on the same page they
need to wait for each other. However, one of those might also be the SSR
runtime. So this lets us wait for the SSR runtime's animations to finish
before starting client ones. This could really be a more generic name
since this should ideally be shared across frameworks. It's kind of
strange that this property doesn't already exist in the DOM given that
there can only be one. It would be useful to be able to coordinate this
across libraries.
Stacked on #31975.
We're going to recommend that the primary way you style a View
Transition is using a View Transition Class (and/or Type). These are
only available in the View Transitions v2 spec. When they're not
available it's better to fallback to just not animating instead of
animating with the wrong styling rules applied.
This is already widely supported in Chrome and Safari 18.2. Safari 18.2
usage is still somewhat low but it's rolling out quickly as we speak.
A way to detect this is by just passing the object form to
`startViewTransition` which throws if it's an earlier version. The
object form is required for `types` but luckily classes rolled out at
the same time. Therefore we're only indirectly detecting class support.
This means that in practice Safari 18.0 and 18.1 won't animate. We could
try to only apply the feature detection if you're actually using classes
or types, but that would create an unfortunate ecosystem burden to try
to support names. It also leads to flaky effects when only some
animations work. Better to just disable them all.
Firefox has yet to ship anything. We'll have to look out for how the
feature detection happens there and if they roll things out in different
order but if you ship late, you deal with web compat as the ball lies.
Stacked on #31975.
This is the primary way we recommend styling your View Transitions since
it allows for reusable styling such as a CSS library specializing in
View Transitions in a way that's composable and without naming
conflicts. E.g.
```js
<ViewTransition className="enter-slide-in exit-fade-out update-cross-fade">
```
This doesn't change the HTML `class` attribute. It's not a CSS class.
Instead it assign the `view-transition-class` style prop of the
underlying DOM node while it's transitioning.
You can also just use `<div style={{viewTransitionClass: ...}}>` on the
DOM node but it's convenient to control the Transition completely from
the outside and conceptually we're transitioning the whole fragment. You
can even make Transition components that just wraps existing components.
`<RevealTransition><Component /></RevealTransition>` this way.
Since you can also have multiple wrappers for different circumstances it
allows React's heuristics to use different classes for different
scenarios. We'll likely add more options like configuring different
classes for different `types` or scenarios that can't be described by
CSS alone.
## CSS Modules
```js
import transitions from './transitions.module.css';
<ViewTransition className={transitions.bounceIn}>...</ViewTransition>
```
CSS Modules works well with this strategy because you can have globally
unique namespaces and define your transitions in the CSS modules as a
library that you can import. [As seen in the fixture
here.](8b91b37bb8 (diff-b4d9854171ffdac4d2c01be92a5eff4f8e9e761e6af953094f99ca243b054a85R11))
I did notice an unfortunate bug in how CSS Modules (at least in Webpack)
generates class names. Sometimes the `+` character is used in the hash
of the class name which is not valid for `view-transition-class` and so
it breaks. I had to rename my class names until the hash yielded
something different to work around it. Ideally that bug gets fixed soon.
## className, rly?
`className` isn't exactly the most loved property name, however, I'm
using `className` here too for consistency. Even though in this case
there's no direct equivalent DOM property name. The CSS property is
named `viewTransitionClass`, but the "viewTransition" prefix is implied
by the Component it is on in this case. For most people the fact that
this is actually a different namespace than other CSS classes doesn't
matter. You'll most just use a CSS library anyway and conceptually
you're just assigning classes the same way as `className` on a DOM node.
But if we ever rename the `class` prop then we can do that for this one
as well.
This will provide the opt-in for using [View
Transitions](https://developer.mozilla.org/en-US/docs/Web/API/View_Transition_API)
in React.
View Transitions only trigger for async updates like `startTransition`,
`useDeferredValue`, Actions or `<Suspense>` revealing from fallback to
content. Synchronous updates provide an opt-out but also guarantee that
they commit immediately which View Transitions can't.
There's no need to opt-in to View Transitions at the "cause" side like
event handlers or actions. They don't know what UI will change and
whether that has an animated transition described.
Conceptually the `<ViewTransition>` component is like a DOM fragment
that transitions its children in its own isolate/snapshot. The API works
by wrapping a DOM node or inner component:
```js
import {ViewTransition} from 'react';
<ViewTransition><Component /></ViewTransition>
```
The default is `name="auto"` which will automatically assign a
`view-transition-name` to the inner DOM node. That way you can add a
View Transition to a Component without controlling its DOM nodes styling
otherwise.
A difference between this and the browser's built-in
`view-transition-name: auto` is that switching the DOM nodes within the
`<ViewTransition>` component preserves the same name so this example
cross-fades between the DOM nodes instead of causing an exit and enter:
```js
<ViewTransition>{condition ? <ComponentA /> : <ComponentB />}</ViewTransition>
```
This becomes especially useful with `<Suspense>` as this example
cross-fades between Skeleton and Content:
```js
<ViewTransition>
<Suspense fallback={<Skeleton />}>
<Content />
</Suspense>
</ViewTransition>
```
Where as this example triggers an exit of the Skeleton and an enter of
the Content:
```js
<Suspense fallback={<ViewTransition><Skeleton /></ViewTransition>}>
<ViewTransition><Content /></ViewTransition>
</Suspense>
```
Managing instances and keys becomes extra important.
You can also specify an explicit `name` property for example for
animating the same conceptual item from one page onto another. However,
best practices is to property namespace these since they can easily
collide. It's also useful to add an `id` to it if available.
```js
<ViewTransition name="my-shared-view">
```
The model in general is the same as plain `view-transition-name` except
React manages a set of heuristics for when to apply it. A problem with
the naive View Transitions model is that it overly opts in every
boundary that *might* transition into transitioning. This is leads to
unfortunate effects like things floating around when unrelated updates
happen. This leads the whole document to animate which means that
nothing is clickable in the meantime. It makes it not useful for smaller
and more local transitions. Best practice is to add
`view-transition-name` only right before you're about to need to animate
the thing. This is tricky to manage globally on complex apps and is not
compositional. Instead we let React manage when a `<ViewTransition>`
"activates" and add/remove the `view-transition-name`. This is also when
React calls `startViewTransition` behind the scenes while it mutates the
DOM.
I've come up with a number of heuristics that I think will make a lot
easier to coordinate this. The principle is that only if something that
updates that particular boundary do we activate it. I hope that one day
maybe browsers will have something like these built-in and we can remove
our implementation.
A `<ViewTransition>` only activates if:
- If a mounted Component renders a `<ViewTransition>` within it outside
the first DOM node, and it is within the viewport, then that
ViewTransition activates as an "enter" animation. This avoids inner
"enter" animations trigger when the parent mounts.
- If an unmounted Component had a `<ViewTransition>` within it outside
the first DOM node, and it was within the viewport, then that
ViewTransition activates as an "exit" animation. This avoids inner
"exit" animations triggering when the parent unmounts.
- If an explicitly named `<ViewTransition name="...">` is deep within an
unmounted tree and one with the same name appears in a mounted tree at
the same time, then both are activated as a pair, but only if they're
both in the viewport. This avoids these triggering "enter" or "exit"
animations when going between parents that don't have a pair.
- If an already mounted `<ViewTransition>` is visible and a DOM
mutation, that might affect how it's painted, happens within its
children but outside any nested `<ViewTransition>`. This allows it to
"cross-fade" between its updates.
- If an already mounted `<ViewTransition>` resizes or moves as the
result of direct DOM nodes siblings changing or moving around. This
allows insertion, deletion and reorders into a list to animate all
children. It is only within one DOM node though, to avoid unrelated
changes in the parent to trigger this. If an item is outside the
viewport before and after, then it's skipped to avoid things flying
across the screen.
- If a `<ViewTransition>` boundary changes size, due to a DOM mutation
within it, then the parent activates (or the root document if there are
no more parents). This ensures that the container can cross-fade to
avoid abrupt relayout. This can be avoided by using absolutely
positioned children. When this can avoid bubbling to the root document,
whatever is not animating is still responsive to clicks during the
transition.
Conceptually each DOM node has its own default that activates the parent
`<ViewTransition>` or no transition if the parent is the root. That
means that if you add a DOM node like `<div><ViewTransition><Component
/></ViewTransition></div>` this won't trigger an "enter" animation since
it was the div that was added, not the ViewTransition. Instead, it might
cause a cross-fade of the parent ViewTransition or no transition if it
had no parent. This ensures that only explicit boundaries perform coarse
animations instead of every single node which is really the benefit of
the View Transitions model. This ends up working out well for simple
cases like switching between two pages immediately while transitioning
one floating item that appears on both pages. Because only the floating
item transitions by default.
Note that it's possible to add manual `view-transition-name` with CSS or
`style={{ viewTransitionName: 'auto' }}` that always transitions as long
as something else has a `<ViewTransition>` that activates. For example a
`<ViewTransition>` can wrap a whole page for a cross-fade but inside of
it an explicit name can be added to something to ensure it animates as a
move when something relates else changes its layout. Instead of just
cross-fading it along with the Page which would be the default.
There's more PRs coming with some optimizations, fixes and expanded
APIs. This first PR explores the above core heuristic.
---------
Co-authored-by: Sebastian "Sebbie" Silbermann <silbermann.sebastian@gmail.com>
The public API has been deleted a long time ago so this should be unused
unless it's used by hacks. It should be replaced with an
effect/lifecycle that manually tracks this if you need it.
The problem with this API is how the timing implemented because it
requires Placement/Hydration flags to be cleared too early. In fact,
that's why we also have a separate PlacementDEV flag that works
differently.
https://github.com/facebook/react/blob/main/packages/react-reconciler/src/ReactFiberCommitWork.js#L2157-L2165
We should be able to remove this code now.
The playground's compilation mode is currently set to 'all' along with
reporting all errors.
This tends to be misleading since people usually expect a 1:1 match
between how the playground works with what the compiler does in their
codebase, eg https://github.com/reactwg/react-compiler/discussions/51.
This is a follow up to #31930 and a prerequisite for #31975.
With View Transitions, the commit phase becomes async which means that
other work can sneak in between. We need to be resilient to that.
This PR first refactors the flushMutationEffects and flushLayoutEffects
to use module scope variables to track its arguments so we can defer
them. It shares these with how we were already doing it for
flushPendingEffects.
We also track how far along the commit phase we are so we know what we
have left to flush.
Then callers of flushPassiveEffects become flushPendingEffects. That
helper synchronously flushes any remaining phases we've yet to commit.
That ensure that things are at least consistent if that happens.
Finally, when we are using a scheduled task, we don't do any work. This
ensures that we're not flushing any work too early if we could've
deferred it. This still ensures that we always do flush it before
starting any new work on any root so new roots observe the committed
state.
There are some unfortunate effects that could happen from allowing
things to flush eagerly. Such as if a flushSync sneaks in before
startViewTransition, it'll skip the animation. If it's during a
suspensey font it'll start the transition before the font has loaded
which might be better than breaking flushSync. It'll also potentially
flush passive effects inside the startViewTransition which should
typically be ok.
Refs are basically just fancy Layout Effects. These are conceptually the
same thing and are always visited together so they don't need to be
different flags.
Whenever we disappear/reappear Offscreen content we need to do both Refs
and Layout Effects.
This is just indicating which phase needs to be visited and these are
always the same phase.
This migrates the compiler's bundler to esbuild instead of rollup.
Unlike React, our bundling use cases are far simpler since the majority
of our packages are meant to be run on node. Rollup was adding
considerable build time overhead whereas esbuild remains fast and has
all the functionality we need out of the box.
### Before
```
time yarn workspaces run build
yarn workspaces v1.22.22
> babel-plugin-react-compiler
yarn run v1.22.22
$ rimraf dist && rollup --config --bundleConfigAsCjs
src/index.ts → dist/index.js...
(!) Circular dependencies
# ...
created dist/index.js in 15.5s
✨ Done in 16.45s.
> eslint-plugin-react-compiler
yarn run v1.22.22
$ rimraf dist && rollup --config --bundleConfigAsCjs
src/index.ts → dist/index.js...
(!) Circular dependencies
# ...
created dist/index.js in 9.1s
✨ Done in 10.11s.
> make-read-only-util
yarn run v1.22.22
warning package.json: No license field
$ tsc
✨ Done in 1.81s.
> react-compiler-healthcheck
yarn run v1.22.22
$ rimraf dist && rollup --config --bundleConfigAsCjs
src/index.ts → dist/index.js...
(!) Circular dependencies
# ...
created dist/index.js in 8.7s
✨ Done in 10.43s.
> react-compiler-runtime
yarn run v1.22.22
$ rimraf dist && rollup --config --bundleConfigAsCjs
src/index.ts → dist/index.js...
(!) src/index.ts (1:0): Module level directives cause errors when bundled, "use no memo" in "src/index.ts" was ignored.
# ...
created dist/index.js in 1.1s
✨ Done in 1.82s.
> snap
yarn run v1.22.22
$ rimraf dist && concurrently -n snap,runtime "tsc --build" "yarn --silent workspace react-compiler-runtime build --silent"
$ rimraf dist && rollup --config --bundleConfigAsCjs --silent
[runtime] yarn --silent workspace react-compiler-runtime build --silent exited with code 0
[snap] tsc --build exited with code 0
✨ Done in 5.73s.
✨ Done in 47.30s.
yarn workspaces run build 75.92s user 5.48s system 170% cpu 47.821 total
```
### After
```
time yarn workspaces run build
yarn workspaces v1.22.22
> babel-plugin-react-compiler
yarn run v1.22.22
$ rimraf dist && scripts/build.js
✨ Done in 1.02s.
> eslint-plugin-react-compiler
yarn run v1.22.22
$ rimraf dist && scripts/build.js
✨ Done in 0.93s.
> make-read-only-util
yarn run v1.22.22
warning package.json: No license field
$ rimraf dist && scripts/build.js
✨ Done in 0.89s.
> react-compiler-healthcheck
yarn run v1.22.22
$ rimraf dist && scripts/build.js
✨ Done in 0.58s.
> react-compiler-runtime
yarn run v1.22.22
$ rimraf dist && scripts/build.js
✨ Done in 0.48s.
> snap
yarn run v1.22.22
$ rimraf dist && concurrently -n snap,runtime "tsc --build" "yarn --silent workspace react-compiler-runtime build"
$ rimraf dist && scripts/build.js
[runtime] yarn --silent workspace react-compiler-runtime build exited with code 0
[snap] tsc --build exited with code 0
✨ Done in 4.69s.
✨ Done in 9.46s.
yarn workspaces run build 9.70s user 0.99s system 103% cpu 10.329 total
```
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31963).
* #31964
* __->__ #31963
* #31962
This is behind an unusual flag (enableCreateEventHandleAPI) that doesn't
serve a special return value. I'll be collecting other flags from this
phase too.
We can just use the global flag and reset it before the next mutation
phase. Unlike focusedInstanceHandle this doesn't leak any memory in the
meantime.
We're currently visiting the snapshot phase for every `Update` flag even
though we rarely have to do anything in the Snapshot phase.
The only flags that seem to use these wider visits is
`enableCreateEventHandleAPI` and `enableUseEffectEventHook` but really
neither of those should do that neither. They should schedule explicit
Snapshot phases if needed.
This tracks commit phase errors and marks the component that errored as
red. These also get the errors attached to the entry.
<img width="1505" alt="Screenshot 2024-12-20 at 2 40 14 PM"
src="https://github.com/user-attachments/assets/cac3ead7-a024-4e33-ab27-2e95293c4299"
/>
In the render phase I just mark the Error Boundary that caught the
error. We don't have access to the actual error since it's locked behind
closures in the update queue. We could probably expose that someway.
<img width="949" alt="Screenshot 2024-12-20 at 1 49 05 PM"
src="https://github.com/user-attachments/assets/3032455d-d9f2-462b-9c07-7be23663ecd3"
/>
Follow ups:
Since the Error Boundary doesn't commit its attempted render, we don't
log those. If we did then maybe we should just mark the errored
component like I do for the commit phase. We could potentially walk the
list of errors and log the captured fibers and just log their entries as
children.
We could also potentially walk the uncommitted Fiber tree by stashing it
somewhere or even getting it from the alternate. This could be done on
Suspense boundaries too to track failed hydrations.
---------
Co-authored-by: Ricky <rickhanlonii@gmail.com>
A common source of performance problems is due to cascading renders from
calling `setState` in `useLayoutEffect` or `useEffect`. This marks the
entry from the update to when we start the render as red and `"Cascade"`
to highlight this.
<img width="964" alt="Screenshot 2024-12-19 at 10 54 59 PM"
src="https://github.com/user-attachments/assets/2bfa91e6-1dc1-4b7f-a659-50aaf2a97e83"
/>
In addition to this case, there's another case where you call `setState`
multiple times in the same event causing multiple renders. This might be
due to multiple `flushSync`, or spawned a microtasks from a
`useLayoutEffect`. In theory it could also be from a microtask scheduled
after the first `setState`. This one we can only detect if it's from an
event that has a `window.event` since otherwise it's hard to know if
we're still in the same event.
<img width="1210" alt="Screenshot 2024-12-19 at 11 38 44 PM"
src="https://github.com/user-attachments/assets/ee188bc4-8ebb-4e95-b5a5-4d724856c27d"
/>
I decided against making a ping in a microtask considered a cascade.
Because that should ideally be using the Suspense Optimization and so
wouldn't be considered multi-pass.
<img width="1284" alt="Screenshot 2024-12-19 at 11 07 30 PM"
src="https://github.com/user-attachments/assets/2d173750-a475-41a0-b6cf-679d15c4ca97"
/>
We might consider making the whole render phase and maybe commit phase
red but that should maybe reserved for actual errors. The "Blocked"
phase really represents the `setState` and so will have the stack trace
of the first update.
This flag first moves the `shouldYield()` logic into React itself. We
need this for `postTask` compatibility anyway since this logic is no
longer a concern of the scheduler. This means that there can also be no
global `requestPaint()` that asks for painting earlier. So this is best
rolled out with `enableAlwaysYieldScheduler` (and ideally
`enableYieldingBeforePassive`) instead of `enableRequestPaint`.
Once in React we can change the yield timing heuristics. This uses the
previous 5ms for Idle work to keep everything responsive while doing
background work. However, for Transitions and Retries we have seen that
same thread animations (like loading states animating, or constant
animations like cool Three.js stuff) can take CPU time away from the
Transition that causes moving into new content to slow down. Therefore
we only yield every 25ms.
The purpose of this yield is not to avoid the overhead of yielding,
which is very low, but rather to intentionally block any frequently
occurring other main thread work like animations from starving our work.
If we could we could just tell everyone else to throttle their stuff for
ideal scheduling but that's not quite realistic. In other words, the
purpose of this is to reduce the frame rate of animations to 30 fps and
we achieve this by not yielding. We still do yield to allow the
animations to not just stall. This seems like a good balance.
The 5ms of Idle is because we don't really need to yield less often
since the overhead is low. We keep it low to allow 120 fps animations to
run if necessary and our work may not be the only work within a frame so
we need to yield early enough to leave enough time left.
Similarly we choose 25ms rather than say 35ms to ensure that we push
long enough to guarantee to half the frame rate but low enough that
there's plenty of time left for a rAF to power each animation every
other frame. It's also low enough that if something else interrupts the
work like a new interaction, we can still be responsive to that within
50ms or so. We also need to yield in case there's I/O work that needs to
get bounced through the main thread.
This flag is currently off everywhere since we have so many other
scheduling flags but that means there's some urgency to roll those out
fully so we can test this one. There's also some tests to update since
this doesn't go through the Mock scheduler anymore for yields.
We currently have a failing test for React DevTools against React 17.
This started failing in https://github.com/facebook/react/pull/30899,
where we changed logic for error tracking and started relying on
`onPostCommitFiberRoot` hook.
Looking at https://github.com/facebook/react/pull/21183,
`onPostCommitFiberRoot` was shipped in 18, which means that any console
errors / warnings emitted in passive effects won't be recorded by React
DevTools for React < 18.
Followup to #31725
This implements `prepareDestinationForModule` in the Parcel Flight
client. On the Parcel side, the `<Resources>` component now only inserts
`<link>` elements for stylesheets (along with a bootstrap script when
needed), and React is responsible for inserting scripts. This ensures
that components that are conditionally dynamic imported during render
are also preloaded.
CSS must be added to the RSC tree using `<Resources>` to avoid FOUC.
This must be manually rendered in both the top-level page, and in any
component that is dynamic imported. It would be nice if there was a way
for React to automatically insert CSS as well, but unfortunately
`prepareDestinationForModule` only knows about client components and not
CSS for server components. Perhaps there could be a way we could
annotate components at code splitting boundaries with the resources they
need? More thoughts in this thread:
https://github.com/facebook/react/pull/31725#discussion_r1884867607
This is similar to #31876 but for Server Components.
It marks them as errored and puts the error message in the Summary
properties.
<img width="1511" alt="Screenshot 2024-12-20 at 5 05 35 PM"
src="https://github.com/user-attachments/assets/92f11e42-0e23-41c7-bfd4-09effb25e024"
/>
This only looks at the current chunk for rejections. That means that
there might still be promises deeper that rejected but it's only the
immediate return value of the Server Component that's considered a
rejection of the component itself.
Currently you need to do one of either:
1. Install React DevTools
2. Install React Refresh
3. Add Profiler component
To opt in to component level profiling.
It was a bit confusing that some of the fixtures was doing 2 which made
them work while other was depending on if you had DevTools.
Really React Refresh shouldn't really opt you in I think.
Traverse the compiled functions to ensure there are no lingering fires
and that all
fire calls are inside an effect lambda.
Also corrects the import to import from the compiler runtime instead
--
This is the diff with the meaningful changes. The approach is:
1. Collect fire callees and remove fire() calls, create a new binding
for the useFire result
2. Update LoadLocals for captured callees to point to the useFire result
3. Update function context to reference useFire results
4. Insert useFire calls after getting to the component scope
This approach aims to minimize the amount of new bindings we introduce
for the function expressions
to minimize bookkeeping for dependency arrays. We keep all of the
LoadLocals leading up to function
calls as they are and insert new instructions to load the originally
captured function, call useFire,
and store the result in a new promoted temporary. The lvalues that
referenced the original callee are
changed to point to the new useFire result.
This is the minimal diff to implement the expected behavior (up to
importing the useFire call, next diff)
and further stacked diffs implement error handling. The rules for fire
are:
1. If you use fire for a callee in the effect once you must use it for
every time you call it in that effect
2. You can only use fire in a useEffect lambda/functions defined inside
the useEffect lambda
There is still more work to do here, like updating the effect dependency
array and handling object methods
--
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31796).
* #31811
* #31798
* #31797
* __->__ #31796
We report a false positive for the combination of a ref-accessing
function placed inside an array which is they type-cast. Here we teach
ref validation about type casts. I also tried other variants like
`return ref as const` but those already worked.
Closes#31864
https://github.com/facebook/react/pull/31785 turned on
`enableYieldingBeforePassive` for the internal test renderer builds. We
have some failing tests on the RN side blocking the sync so lets turn
these off for now.
We already have handling and retry logic for in-flight workflows in
`downloadArtifactsFromGitHub`, so there's no need to exit early if we
find a workflow for a given commit but it hasn't finished yet.
We support streaming `multipart/form-data` in Node.js using Busboy since
that's kind of the idiomatic ecosystem way for handling these stream
there. There's not really anything idiomatic like that for Edge that's
universal yet.
This adds a version that's basically just
`AsyncIterable.from(formData)`. It could also be a `ReadableStream` of
those entries since those are also `AsyncIterable`.
I imagine that in the future we might add one from a binary
`ReadableStream` that does the parsing built-in.
#31787 introduces an experimental scheduler flag:
`enableAlwaysYieldScheduler`, which is turned off for www. There wasn't
a SchedulerFeatureFlags fork for native-fb, so the experimental change
was enabled in the Scheduler-dev build there which causes test failures
and is blocking the sync.
#31805 introduces another scheduler flag `enableRequestPaint`, which is
set as a `__VARIANT__` on www. I've set this to `true` here to preserve
the existing behavior. We can follow up with dynamic flags for native-fb
after unblocking the sync.
This updates the CI workflow for the runtime build and tests to use the
HEAD commit of the PR branch rather than the Fake News merge commit that
the `@actions/checkout` action bafflingly defaults to.
Testing against the merge commit never made sense to me as a behavior
because as soon as someone updates upstream, it's out of date anyway.
It should just match the exact commit that the developer pushed, and the
once that appears in the GitHub UI.
This is a follow up to #31752.
This keeps track in the commit phase whether this subtree was hydrated.
If it was, then we mark those components in the Components track as
green. Just like the phase itself is marked as green.
If the boundary client rendered we instead mark it as "errored" and its
children given the plain primary render color (blue). I also collect the
hydration error for this case so we can include its message in the
details view. (Unfortunately this doesn't support newlines atm.)
Most of the time this happens in separate commits for each boundary but
it is possible to force a client render in the same pass as a hydration.
Such as if an update flows into a boundary that has been put into
fallback state after it was initially attempted.
<img width="1487" alt="Screenshot 2024-12-18 at 12 06 54 AM"
src="https://github.com/user-attachments/assets/74c57291-4d11-414c-9751-3dac3285a89a"
/>
We might have already resolved models that are not pending and so are
not rejected by aborting the stream. When those later get parsed they
might discover new chunks which end up as pending. These should be
errored since they will never be able to resolve later.
This avoids infinitely hanging the stream.
This same fix needs to be ported to ReactFlightClient that has the same
issue.
Adds a test that shows using <StrictMode /> anywhere outside of the root
node will not fire strict effects.
This works:
```js
root.render(
<StrictMode>
<App>
<Children />
</App>
</StrictMode>
);
```
This does not fire strict effects on mount:
```js
root.render(
<App>
<StrictMode>
<Children />
</StrictMode>
</App>
);
```
Before calling `emitTimingChunk` inside of `forwardDebugInfo`, we must
not increment `request.pendingChunks`, as this is already done inside of
the `emitTimingChunk` function.
I don't have a unit test for this, but manually verified that this fixes
the hanging responses in https://github.com/vercel/next.js/pull/73804.
In https://github.com/facebook/react/pull/30967 and
https://github.com/facebook/react/pull/30983 I added logging of the just
rendered components and the effects. However this didn't consider the
special Offscreen passes. So this adds the same thing to those passes.
Log component effect timings for disconnected/reconnected offscreen
subtrees. This includes initial mount of a Suspense boundary.
Log component render timings for reconnected and already offscreen
offscreen subtrees.
This treats workInProgressRoot work and rootWithPendingPassiveEffects
the same way. Basically as long as there's some work on the root, yield
the current task. Including passive effects. This means that passive
effects are now a continuation instead of a separate callback. This can
mean they're earlier or later than before. Later for Idle in case
there's other non-React work. Earlier for same Default if there's other
Default priority work.
This makes sense since increasing priority of the passive effects beyond
Idle doesn't really make sense for an Idle render.
However, for any given render at same priority it's more important to
complete this work than start something new.
Since we special case continuations to always yield to the browser, this
has the same effect as #31784 without implementing `requestPaint`. At
least assuming nothing else calls `requestPaint`.
<img width="587" alt="Screenshot 2024-12-14 at 5 37 37 PM"
src="https://github.com/user-attachments/assets/8641b172-8842-4191-8bf0-50cbe263a30c"
/>
As an alternative to #31784.
We should really just always yield each virtual task to a native task.
So that it's 1:1 with native tasks. This affects when microtasks within
each task happens. This brings us closer to native `postTask` semantics
which makes it more seamless to just use that when available.
This still doesn't yield when a task expires to protect against
starvation.
This flag controls the strict mode double invoke render/lifecycles/etc
behavior in Strict Mode.
The only place this flag is off is the test renderers, which it should
be on for.
If we can land this, we can follow up to remove the flag.
Add shape / type for global Object.keys. This is useful because
- it has an Effect.Read (not an Effect.Capture) as it cannot alias its
argument.
- Object.keys return an array
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31583).
* __->__ #31583
* #31582
We previously didn't track context variables in the hoistable values
sidemap of `propagateScopeDependencies`. This was overly conservative as
we *do* track the mutable range of context variables, and it is safe to
hoist accesses to context variables after their last direct / aliased
maybe-assignment.
```js
function Component({value}) {
// start of mutable range for `x`
let x = DEFAULT;
const setX = () => x = value;
const aliasedSet = maybeAlias(setX);
maybeCall(aliasedSet);
// end of mutable range for `x`
// here, we should be able to take x (and property reads
// off of x) as dependencies
return <Jsx value={x} />
}
```
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31582).
* #31583
* __->__ #31582
Compiler playground now runs the entire program through
`babel-plugin-react-compiler` instead of a custom pipeline which
previously duplicated function inference logic from `Program.ts`. In
addition, the playground output reflects the tranformed file (instead of
a "virtual file" of manually concatenated functions).
This helps with the following:
- Reduce potential discrepencies between playground and babel plugin
behavior. See attached fixture output for an example where we previously
diverged.
- Let playground users see compiler-inserted imports (e.g. `_c` or
`useFire`)
This also helps us repurpose playground into a more general tool for
compiler-users instead of just for compiler engineers.
- imports and other functions are preserved.
We differentiate between imports and globals in many cases (e.g.
`inferEffectDeps`), so it may be misleading to omit imports in printed
output
- playground now shows other program-changing behavior like position of
outlined functions and hoisted declarations
- emitted compiled functions do not need synthetic names
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31774).
* #31809
* __->__ #31774
Stacked on #31737.
<img width="987" alt="Screenshot 2024-12-11 at 8 41 15 PM"
src="https://github.com/user-attachments/assets/438379a9-0138-4d02-a53a-419402839558"
/>
When mixing environments (like "use cache" or third party RSC) it's
useful to color and badge those components differently to differentiate.
I'm not putting them in separate tracks because when they do actually
execute, like cache misses or third party RSCs, they behave like they're
part of the same tree.
Stacked on #31736.
<img width="1223" alt="Screenshot 2024-12-11 at 8 21 12 PM"
src="https://github.com/user-attachments/assets/a7cbc04b-c831-476b-aa2f-baddec9461c9"
/>
This emits a placeholder when we're deduping a component. This starts
when the parent's self time ends, where we would've started rendering
this component if it wasn't already started. The end time is when the
actual render ends since the parent is also blocked by it.
Stacked on #31735.
This ensures that Server Components Track comes first. Since it's
typically rendered first on the server for initial load and then flows
into scheduler and client components work. Also puts it closer to the
Network and further away from "Main" JS.
<img width="769" alt="Screenshot 2024-12-11 at 5 31 41 PM"
src="https://github.com/user-attachments/assets/7198db0f-075e-4a78-8ea4-3bfbf06727cb"
/>
Same trick as in #31615.
We introduced the `unstable_useContextWithBailout` API to run compiler
based experiments. This API was designed to be an experiment proxy for
alternative approaches which would be heavier to implement. The
experiment turned out to be inconclusive. Since most of our performance
critical usage is already optimized, we weren't able to find a clear win
with this approach.
Since we don't have further plans for this API, let's clean it up.
Stacked on https://github.com/facebook/react/pull/31729
<img width="1436" alt="Screenshot 2024-12-11 at 3 36 41 PM"
src="https://github.com/user-attachments/assets/0a201913-0076-4bbf-be18-8f1df6c58313"
/>
The Server Components visualization is currently a tree flame graph
where parent spans the child. This makes it equivalent to the Client
Components visualization.
However, since Server Components can be async and therefore parallel, we
need to do something when two children are executed in parallel. This PR
bumps parallel children into a separate track and then within that track
if that child has more children it can grow within that track.
I currently just cut off more than 10 parallel tracks.
Synchronous Server Components are still in sequence but it's unlikely
because even a simple microtasky Async Component is still parallel.
<img width="959" alt="Screenshot 2024-12-11 at 4 31 17 PM"
src="https://github.com/user-attachments/assets/5ad6a7f8-7fa0-46dc-af51-78caf9849176"
/>
I think this is probably not a very useful visualization for Server
Components but we can try it out.
I'm also going to try a different visualization where parent-child
relationship is horizontal and parallel vertical instead, but it might
not be possible to make that line up in this tool. It makes it a little
harder to see how much different components (including their children)
impact the overall tree. If that's the only visualization it's also
confusing why it's different dimensions than the Client Component
version.
When implementing passive effects we did a pretty massive oversight.
While the passive effect is scheduled into its own scheduler task, the
scheduler doesn't always yield to the browser if it has time left. That
means that if you have a fast commit phase, it might try to squeeze in
the passive effects in the same frame but those then might end being
very heavy.
We had `requestPaint()` for this but that was only implemented for the
`isInputPending` experiment. It wasn't thought we needed it for the
regular scheduler because it yields "every frame" anyway - but it
doesn't yield every task. While the `isInputPending` experiment showed
that it wasn't actually any significant impact, and it was better to
keep shorter yield time anyway. Which is why we deleted the code.
Whatever small win it did see in some cases might have been actually due
to this issue rather than anything to do with `isInputPending` at all.
As you can see in https://github.com/facebook/react/pull/31782 we do
have this implemented in the mock scheduler and a lot of behavior that
we assert assumes that this works.
So this just implements yielding after `requestPaint` is called.
Before:
<img width="1023" alt="Screenshot 2024-12-14 at 3 40 24 PM"
src="https://github.com/user-attachments/assets/d60f4bb2-c8f8-4f91-a402-9ac25b278450"
/>
After:
<img width="1108" alt="Screenshot 2024-12-14 at 3 41 25 PM"
src="https://github.com/user-attachments/assets/170cdb90-a049-436f-9501-be3fb9bc04ca"
/>
Notice how in after the native task is split into two. It might not
always actually paint and the native scheduler might make the same
mistake and think it has enough time left but it's at least less likely
to.
We do have another way to do this. When we yield a continuation we also
yield to the native browser. This is to enable the Suspense Optimization
(currently disabled) to work. We could do the same for passive effects
and, in fact, I have a branch that does but because that requires a lot
more tests to be fixed it's a lot more invasive of a change. The nice
thing about this approach is that this is not even running in tests at
all and the tests we do have assert that this is the behavior already. 😬
This highlights the render phase as the tertiary color (green) when
we're render a hydration lane or offscreen lane.
I call the "Render" phase "Hydrated" instead in this case. For the
offscreen case we don't currently have a differentiation between
hydrated or activity. I just called that "Prepared". Even for the
hydration case where there's no discovered client rendered boundaries
it's more like it's preparing for an interaction rather than blocking
one. Where as for the other lanes the hydration might block something.
<img width="1173" alt="Screenshot 2024-12-12 at 11 23 14 PM"
src="https://github.com/user-attachments/assets/49ab1508-840f-4188-a085-18fe94b14187"
/>
In a follow up I'd like to color the components in the Components tree
green if they were hydrated but not the ones that was actually client
rendered e.g. due to a mismatch or forced client rendering so you can
tell the difference. Unfortunately, the current signals we have for this
get reset earlier in the commit phase than when we log these.
Another thing is that a failed hydration should probably be colored red
even though it ends up committing successfully. I.e. a recoverable
error.
Related to #31752.
When hydrating, we have two different ways of handling a Suspense
boundary that the server has already given up on and decided to client
render. If we have already hydrated the parent and then later this
happens, then we'll use the retry lane like any ping. If we discover
that it was already in client-render mode when we discover the Suspense
boundary for the first time, then schedule a default lane to let us
first finish the current render and then upgrade the priority to sync to
try to client render this boundary as soon as possible since we're
holding back content.
We used to use the `DefaultHydrationLane` for this but this is not
really a Hydration. It's actually a client render. If we get any other
updates flowing in from above at the same time we might as well do them
in the same pass instead of two passes. So this should be considered
more like any update.
This also means that visually the client render pass now gets painted as
a render instead of a hydration.
This show the flow of a shell being hydrated at the default priority,
then a Suspense boundary being discovered and hydrated at Idle and then
an inner boundary being discovered as client rendered which gets
upgraded to default.
<img width="1363" alt="Screenshot 2024-12-14 at 12 13 57 AM"
src="https://github.com/user-attachments/assets/a141133e-4856-4f38-a11f-f26bd00b6245"
/>
We're seeing errors when testing useResourceEffect in SSR and it turns
out we're missing the noop dispatcher function on Fizz.
I tested a local build with this change and it resolved the late
mutation errors in the e2e tests.
## Summary
This PR improves the Trace Updates feature by letting developers see
component names directly on the update overlay. Before this change, the
overlay only highlighted updated regions, leaving it unclear which
components were involved. With this update, you can now match visual
updates to their corresponding components, making it much easier to
debug rendering performance.
### New Feature: Show component names while highlighting
When the new **"Show component names while highlighting"** setting is
enabled, the update overlay display the names of affected components
above the rectangles, along with the update count. This gives immediate
context about what’s rendering and why. The preference is stored in
local storage and synced with the backend, so it’s remembered across
sessions.
### Improvements to Drawing Logic
The drawing logic has been updated to make the overlay sharper and
easier to read. Overlay now respect device pixel ratios, so they look
great on high-DPI screens. Outlines have also been made crisper, which
makes it easier to spot exactly where updates are happening.
> [!NOTE]
> **Grouping Logic and Limitations**
> Updates are grouped by their screen position `(left, top coordinates)`
to combine overlapping or nearby regions into a single group. Groups are
sorted by the highest update count within each group, making the most
frequently updated components stand out.
> Overlapping labels may still occur when multiple updates involve
components that overlap but are not in the exact same position. This is
intentional, as the logic aims to maintain a straightforward mapping
between update regions and component names without introducing
unnecessary complexity.
### Testing
This PR also adds tests for the new `groupAndSortNodes` utility, which
handles the logic for grouping and sorting updates. The tests ensure the
behavior is reliable across different scenarios.
## Before & After
https://github.com/user-attachments/assets/6ea0fe3e-9354-44fa-95f3-9a867554f74chttps://github.com/user-attachments/assets/32af4d98-92a5-47dd-a732-f05c2293e41b
---------
Co-authored-by: Ruslan Lesiutin <rdlesyutin@gmail.com>
When scheduling the initial root and when using
`unstable_scheduleHydration` we should use the Hydration Lanes rather
than the raw update lane. This ensures that we're always hydrating using
a Hydration Lane or the Offscreen Lane rather than other lanes getting
some random hydration in it.
This fixes an issue where updating a root while it is still hydrating
causes it to trigger client rendering when it could just hydrate and
then apply the update on top of that.
It also fixes a potential performance issue where
`unstable_scheduleHydration` gets batched with an update that then ends
up forcing an update of a boundary that requires it to rewind to do the
hydration lane anyway. Might as well just start with the hydration
without the update applied first.
I added a kill switch (`enableHydrationLaneScheduling`) just in case but
seems very safe given that using `unstable_scheduleHydration` at all is
very rare and updating the root before the shell hydrates is extremely
rare (and used to trigger a recoverable error).
Follow up to #31725.
I diffed against the Turbopack one to find any unexpected discrepancies.
Some parts are forked enough that it's hard to diff but I think I got
most of it.
We're still publishing RCs and creating canary version strings using the
RC naming convention. Setting the `canaryChannelLabel` back to canary
fixes the version names and tags after the 19 stable release.
<img width="966" alt="Screenshot 2024-12-10 at 10 49 19 PM"
src="https://github.com/user-attachments/assets/27a21bdf-86b9-4203-893b-89523e698138">
This emits a tree view visualization of the timing information for each
Server Component provided in the RSC payload.
The unique thing about this visualization is that the end time of each
Server Component spans the end of the last child. Now what is
conceptually a blocking child is kind of undefined in RSC. E.g. if
you're not using a Promise on the client, or if it is wrapped in
Suspense, is it really blocking the parent?
Here I reconstruct parent-child relationship by which chunks reference
other chunks. A child can belong to more than one parent like when we
dedupe the result of a Server Component.
Then I wait until the whole RSC payload has streamed in, and then I
traverse the tree collecting the end time from children as I go and emit
the `performance.measure()` calls on the way up.
There's more work for this visualization in follow ups but this is the
basics. For example, since the Server Component time span includes async
work it's possible for siblings to execute their span in parallel (Foo
and Bar in the screenshot are parallel siblings). To deal with this we
need to spawn parallel work into separate tracks. Each one can be deep
due to large trees. This can makes this type of visualization unwieldy
when you have a lot of parallelism. Therefore I also plan another
flatter Timeline visualization in a follow up.
This adds a new `react-server-dom-parcel-package`, which is an RSC
integration for the Parcel bundler. It is mostly copied from the
existing webpack/turbopack integrations, with some changes to utilize
Parcel runtime APIs for loading and executing bundles/modules.
See https://github.com/parcel-bundler/parcel/pull/10043 for the Parcel
side of this, which includes the plugin needed to generate client and
server references. https://github.com/parcel-bundler/rsc-examples also
includes examples of various ways to use RSCs with Parcel.
Differences from other integrations:
* Client and server modules are all part of the same graph, and we use
Parcel's
[environments](https://parceljs.org/plugin-system/transformer/#the-environment)
to distinguish them. The server is the Parcel build entry point, and it
imports and renders server components in route handlers. When a `"use
client"` directive is seen, the environment changes and Parcel creates a
new client bundle for the page, combining all client modules together.
CSS from both client and server components are also combined
automatically.
* There is no separate manifest file that needs to be passed around by
the user. A [Runtime](https://parceljs.org/plugin-system/runtime/)
plugin injects client and server references as needed into the relevant
bundles, and registers server action ids using `react-server-dom-parcel`
automatically.
* A special `<Resources>` component is also generated by Parcel to
render the `<script>` and `<link rel="stylesheet">` elements needed for
a page, using the relevant info from the bundle graph.
Note: I've already published a 0.0.x version of this package to npm for
testing purposes but happy to add whoever needs access to it as well.
### Questions
* How to test this in the React repo. I'll have integration tests in
Parcel, but setting up all the different mocks and environments to
simulate that here seems challenging. I could try to copy how
Webpack/Turbopack do it but it's a bit different.
* Where to put TypeScript types. Right now I have some ambient types in
my [example
repo](https://github.com/parcel-bundler/rsc-examples/blob/main/types.d.ts)
but it would be nice for users not to copy and paste these. Can I
include them in the package or do they need to maintained separately in
definitelytyped? I would really prefer not to have to maintain code in
three different repos ideally.
---------
Co-authored-by: Sebastian Markbage <sebastian@calyptus.eu>
# Summary
I'm working to get the main `react-native` package parsable by modern
Flow tooling (both `flow-bundler`, `flow-api-translator`).
This diff trivially removes some redundant Flow comment syntax in
`ReactNativeTypes.js`, which fixes parsing under these newer tools.
## How did you test this change?
Files were pasted into `react-native-github` under fbsource, where Flow
validates ✅.
Stacked on #31715.
This adds profiling data for Server Components to the RSC stream (but
doesn't yet use it for anything). This is on behind
`enableProfilerTimer` which is on for Dev and Profiling builds. However,
for now there's no Profiling build of Flight so in practice only in DEV.
It's gated on `enableComponentPerformanceTrack` which is experimental
only for now.
We first emit a timeOrigin in the beginning of the stream. This provides
us a relative time to emit timestamps against for cross environment
transfer so that we can log it in terms of absolute times. Using this as
a separate field allows the actual relative timestamps to be a bit more
compact representation and preserves floating point precision.
We emit a timestamp before emitting a Server Component which represents
the start time of the Server Component. The end time is either when the
next Server Component starts or when we finish the task.
We omit the end time for simple tasks that are outlined without Server
Components.
By encoding this as part of the debugInfo stream, this information can
be forwarded between Server to Server RSC.
When supporting ref as prop in
https://github.com/facebook/react/pull/31558, I missed fixing the
optimization to pass a spread-props-only props object in without an
additional object copy. In the case that we have only a ref along with a
spread, we cannot return only the spread object. This results in
dropping the ref.
In this example
```javascript
<Foo ref={ref} {...props} />
```
The bugged output is:
```javascript
{
// ...
props: props
}
```
With this change we now get the correct output:
```javascript
{
// ...
props: {ref: ref, ...props}
}
```
We added an experimental `prerender` API to flight. This change exposes
this API in stable channels prefixed as `unstable_prerender`. We have
high confidence this API should exist but because we have not yet
settled on how to handle resuming/replaying of RSC streams we may need
to change the API contract to suit future needs. This release will allow
us to get more usage out of the existing implemented functionality
without requiring you to use experimental builds which will open up
greater adoption and opportunity for feedback.
the `prerender` implementation is documented in the `react-server`
package. As with all RSC APIs implemented in bundler specific binding
packages these aren't intended to be called by end users but instead be
used by frameworks implementing React Server Components.
Previously `prerender` was exposed unprefixed and only in the
experimental channel. This PR renames the export across all channels to
`unstable_prerender` so users of this previously unprefixed api will
need to update to the unstable form. This isn't a breaking change
because it was only exposed in the experimental channel which does not
follow semver. The reason we don't expose it under both names is that
users may feature detect the unprefixed form and then when we finally do
ship it as unprefixed we may change the function signature and break
this code. Changing the name now is much safer.
We shouldn't call onError/onPostpone when we halt a stream because that
node didn't error yet. Its digest would also get lost.
We also have a lot of error branches now for thenables and streams. This
unifies them under erroredTask. I'm not yet unifying the cases that
don't allocate a task for the error when those are outlined.
The need for this was removed in
https://github.com/facebook/react/pull/30831
Since the new DevTools version has been released for a while and we
expect people to more or less auto-update. Future versions of React
don't need this.
Once we remove the remaining uses of `getInstanceFromNode` e.g. in the
deprecated internal `findDOMNode`/`findNodeHandle` and the event system,
we can completely remove the tagging of DOM nodes.
This clarifies a few things by ensuring that there is always at least
one required field. This can be used to refine the object to one of the
specific types. However, it's probably just a matter of time until we
make this tagged unions instead. E.g. it would be nice to rename the
`name` field `ReactComponentInfo` to `type` and tag it with the React
Element symbol because then it's just the same as a React Element.
I also extract a time field. The idea is that this will advance (or
rewind) the time to the new timestamp and then anything below would be
defined as happening within that time stamp. E.g. to model the start and
end for a server component you'd do something like:
```
[
{time: 123},
{name: 'Component', ... },
{time: 124},
]
```
The reason this needs to be in the `ReactDebugInfo` is so that timing
information from one environment gets transferred into the next
environment. It lets you take a Promise from one world and transfer it
into another world and its timing information is preserved without
everything else being preserved.
I've gone back and forth on if this should be part of each other Info
object like `ReactComponentInfo` but since those can be deduped and can
change formats (e.g. this should really just be a React Element) it's
better to store this separately.
The time format is relative to a `timeOrigin` which is the current
environment's `timeOrigin`. When it's serialized between environments
this needs to be considered.
Emitting these timings is not yet implemented in this PR.
---------
Co-authored-by: eps1lon <sebastian.silbermann@vercel.com>
This is just moving some code into a helper.
We have a bunch of special cases for the return value slot of a Server
Component that's different from just rendering that inside an object.
This was getting a little tricky to reason about inline with the rest of
rendering.
Hints and Console logs are side-effects and don't belong to any
particular value. They're `void`. Therefore they don't need a row ID.
In the current parsing scheme it's ok to omit the id. It just becomes
`0` which is the initial value which is then unused for these row types.
So it looks like:
```
:HP[...]
:W[...]
0:{...}
```
We could patch the parsing to encode the tag in the ID so it's more like
the ID is the target of the side-effect.
```
H:P[...]
W:[...]
0:{...}
```
Or move the tagging to the beginning like it used to be.
But this seems simple enough for now.
To avoid GC pressure and accidentally hanging onto old trees Suspense
boundary retries are now implemented in the commit phase. I used the
Callback flag which was previously only used to schedule callbacks for
Class components. This isn't quite semantically equivalent but it's
unused and seemingly compatible.
When streaming SSR while hydrating React will wait for Suspense
boundaries to be revealed by the SSR stream before attempting to hydrate
them. The rationale here is that the Server render is likely further
ahead of whatever the client would produce so waiting to let the server
stream in the UI is preferable to retrying on the client and possibly
delaying how quickly the primary content becomes available. However If
the connection closes early (user hits stop for instance) or there is a
server error which prevents additional HTML from being delivered to the
client this can put React into a broken state where the boundary never
resolves nor errors and the hydration never retries that boundary
freezing it in it's fallback state.
Once the document has fully loaded we know there is not way any
additional Suspense boundaries can arrive. This update changes react-dom
on the client to schedule client renders for any unfinished Suspense
boundaries upon document loading.
The technique for client rendering a fallback is pretty straight
forward. When hydrating a Suspense boundary if the Document is in
'complete' readyState we interpret pending boundaries as fallback
boundaries. If the readyState is not 'complete' we register an event to
retry the boundary when the DOMContentLoaded event fires.
To test this I needed JSDOM to model readyState. We previously had a
temporary implementation of readyState for SSR streaming but I ended up
implementing this as a mock of JSDOM that implements a fake readyState
that is mutable. It starts off in 'loading' readyState and you can
advance it by mutating document.readyState. You can also reset it to
'loading'. It fires events when changing states.
This seems like the least invasive way to get closer-to-real-browser
behavior in a way that won't require remembering this subtle detail
every time you create a test that asserts Suspense resolution order.
Any LoadGlobal in the "infer deps" position can safely use an empty dep
array. Globals have no reactive deps!
I just keep messing up sapling. This is the revised version of #31662
Reverts facebook/react#31629
`@babel/plugin-proposal-private-methods` is not compatible with
`@babel/traverse` versions < 7.25 (see
https://github.com/babel/babel/issues/16851). Internally we have
partners that use a less modern babel version, and we expect this to be
an issue for older codebases in OSS as well.
Adds `target: 'donotuse_meta_internal'`, which inserts useMemoCache
imports directly from `react`. Note that this is only valid for Meta
bundles, as others do not [re-export the `c`
function](5b0ef217ef/packages/react/index.fb.js (L68-L70)).
```js
// target=donotuse_meta_internal
import {c as _c} from 'react';
// target=19
import {c as _c} from 'react/compiler-runtime';
// target=17,18
import {c as _c} from 'react-compiler-runtime';
```
Meta is a bit special in that react runtime and compiler are guaranteed
to be up-to-date and compatible. It also has its own bundling and module
resolution logic, which makes importing from `react/compiler-runtime`
tricky.
I'm also fine with implementing the alternative which adds an internal
stub for `react-compiler-runtime` and
[bundles](5b0ef217ef/scripts/rollup/bundles.js (L120))
the runtime for internal builds.
## Overview
Changes the error message to say "Server Functions" instead of "Server
Actions" since this error can fire in cases like:
```
<button onClick={serverFunction} />
```
Which is calling a server function, not a server action.
Adds a way to configure how we insert deps for experimental purposes.
```
[
{
module: 'react',
imported: 'useEffect',
numRequiredArgs: 1,
},
{
module: 'MyExperimentalEffectHooks',
imported: 'useExperimentalEffect',
numRequiredArgs: 2,
},
]
```
would insert dependencies for calls of `useEffect` imported from `react`
if they have 1 argument and calls of useExperimentalEffect` from
`MyExperimentalEffectHooks` if they have 2 arguments. The pushed dep
array is appended to the arg list.
We didn't originally support holes within array patterns, so DCE was
only able to prune unused items from the end of an array pattern. Now
that we support holes we can replace any unused item with a hole, and
then just prune the items to the last identifier/spread entry.
Note: this was motivated by finding useState where either the state or
setState go unused — both are strong indications that you're violating
the rules in some way. By DCE-ing the unused portions of the useState
destructuring we can easily check if you're ignoring either value.
closes#31603
This is a redo of that PR not using ghstack
A long standing issue for React has been that if you reorder stateful
nodes, they may lose their state and reload. The thing moving loses its
state. There's no way to solve this in general where two stateful nodes
swap.
The [`moveBefore()`
proposal](https://chromestatus.com/feature/5135990159835136?gate=5177450351558656)
has now moved to
[intent-to-ship](https://groups.google.com/a/chromium.org/g/blink-dev/c/YE_xLH6MkRs/m/_7CD0NYMAAAJ).
This function is kind of like `insertBefore` but preserves state.
There's [a demo here](https://state-preserving-atomic-move.glitch.me/).
Ideally we'd port this demo to a fixture so we can try it.
Currently this flag is always off - even in experimental. That's because
this is still behind a Chrome flag so it's a little early to turn it on
even in experimental. So you need a custom build. It's on in RN but only
because it doesn't apply there which makes it easier to tell that it's
safe to ship once it's on everywhere else.
The other reason it's still off is because there's currently a semantic
breaking change. `moveBefore()` errors if both nodes are disconnected.
That happens if we're inside a completely disconnected React root.
That's not usually how you should use React because it means effects
can't read layout etc. However, it is currently supported. To handle
this we'd have to try/catch the `moveBefore` to handle this case but we
hope this semantic will change before it ships. Before we turn this on
in experimental we either have to wait for the implementation to not
error in the disconnected-disconnected case in Chrome or we'd have to
add try/catch.
This is a hack that ensures that all four lanes as visible whether you
have any tracks in them or not, and that they're in the priority order
within the Scheduler track group. We do want to show all even if they're
not used because it shows what options you're missing out on.
<img width="1035" alt="Screenshot 2024-11-22 at 12 38 30 PM"
src="https://github.com/user-attachments/assets/f30ab0b9-af5e-48ed-b042-138444352575">
In Chrome, the order of tracks within a group are determined by the
earliest start time. We add fake markers at start time zero in that
order eagerly. Ideally we could do this only once but because calls that
aren't recorded aren't considered for ordering purposes, we need to keep
adding these over and over again in case recording has just started. We
can't tell when recording starts.
Currently performance.mark() are in first insertion order but
performance.measure() are in the reverse order. I'm not sure that's
intentional. We can always add the 0 time slot even if it's in the past.
That's still considered for ordering purposes as long as the measurement
is recorded at the time we call it.
This is for researching/prototyping, not a feature we are releasing
imminently.
Putting up an early version of inferring effect dependencies to get
feedback on the approach. We do not plan to ship this as-is, and may not
start by going after direct `useEffect` calls. Until we make that
decision, the heuristic I use to detect when to insert effect deps will
suffice for testing.
The approach is simple: when we see a useEffect call with no dep array
we insert the deps inferred for the lambda passed in. If the first
argument is not a lambda then we do not do anything.
This diff is the easy part. I think the harder part will be ensuring
that we can infer the deps even when we have to bail out of memoization.
We have no other features that *must* run regardless of rules of react
violations. Does anyone foresee any issues using the compiler passes to
infer reactive deps when there may be violations?
I have a few questions:
1. Will there ever be more than one instruction in a block containing a
useEffect? if no, I can get rid of the`addedInstrs` variable that I use
to make sure I insert the effect deps array temp creation at the right
spot.
2. Are there any cases for resolving the first argument beyond just
looking at the lvalue's identifier id that I'll need to take into
account? e.g., do I need to recursively resolve certain bindings?
---------
Co-authored-by: Mofei Zhang <feifei0@meta.com>
This ensures that we mark the time from ping until we render as
"Blocked".
We intentionally don't want to show the event time even if it's
something like "load" because it draws attention away from interactions
etc.
<img width="577" alt="Screenshot 2024-11-21 at 7 22 39 PM"
src="https://github.com/user-attachments/assets/70cca2e8-bd5e-489f-98f0-b4dfee5940af">
This avoid re-emitting the yellow "Event" log when we ping inside the
original event. Instead of treating events as repeated when we get
repeated updates, we treat them as repeated if we've ever logged out
this event before.
Additionally, in the case the prerender sibling flag is on we need to
ensure that if a render gets interrupted when it has been suspended we
treat that as "Prewarm" instead of "Interrupted Render".
Before:
<img width="539" alt="Screenshot 2024-11-19 at 2 39 44 PM"
src="https://github.com/user-attachments/assets/190ca50c-5168-40d8-a6fd-6b9a583af1f0">
After:
<img width="1004" alt="Screenshot 2024-11-21 at 4 53 16 PM"
src="https://github.com/user-attachments/assets/0c441ada-1ed1-412c-8935-aaf040c25dfe">
Fixes a bug with the experimental `useResourceEffect` hook where we
would compare the wrong deps when there happened to be another kind of
effect preceding the ResourceEffect. To do this correctly we need to add
a pointer to the ResourceEffect's identity on the update.
I also unified the previously separate push effect impls for resource
effects since they are always pushed together as a unit.
Stacked on #31552. Must be tested with `enableSiblingPrerendering` off
since the `use()` optimization is not on there yet.
This adds a span to the Components track when we yield in the middle of
the event loop. In this scenario, the "Render" span continues through
out the Scheduler track. So you can see that the Component itself might
not take a long time but yielding inside of it might.
This lets you see if something was blocking the React render loop while
yielding. If we're blocked 1ms or longer we log that as "Blocked".
If we're yielding due to suspending in the middle of the work loop we
log this as "Suspended".
<img width="837" alt="Screenshot 2024-11-16 at 1 15 14 PM"
src="https://github.com/user-attachments/assets/45a858ea-17e6-416c-af1a-78c126e033f3">
If the render doesn't commit because it restarts due to some other
prewarming or because some non-`use()` suspends, it doesn't have from
context components.
<img width="971" alt="Screenshot 2024-11-16 at 1 13 55 PM"
src="https://github.com/user-attachments/assets/a67724f8-702e-4e7d-9499-9ffc09541a61">
The `useActionState` path doesn't work yet because the `use()`
optimization doesn't work there for some reason. But the idea is that it
should mark the time that the component is blocked as Action instead of
Suspended.
When we suspend the render with delay, we won't do any more work until
we get some kind of another update/ping. It's because conceptually
something is suspended and then will update later. We need to highlight
this period to show why it's not doing any work. We fill the empty space
with "Suspended". This stops whenever the same lane group starts
rendering again. Clamped by the preceeding start time/event time/update
time.
<img width="902" alt="Screenshot 2024-11-15 at 1 01 29 PM"
src="https://github.com/user-attachments/assets/acf9dc9a-8fc3-4367-a8b0-d19f9c9eac73">
Ideally we would instead start the next render and suspend the work loop
at all places we suspend. In that mode this will instead show up as a
very long "Render" with a "Suspended" period instead highlighted in the
Components track as one component is suspended. We'll soon have that for
`use()` but not all updates so this covers the rest.
One issue with `useActionState` is that it is implemented as suspending
at the point of the `useActionState` which means that the period of the
Action shows up as a suspended render instead of as an Action which
happens for raw actions. This is not really how you conceptually think
about it so we need some special case for `useActionState`. In the
screenshot above, the first "Suspended" is actually awaiting an Action
and the second "Suspended" is awaiting the data from it.
```
=> Found "hermes-parser@0.25.1"
info Reasons this module exists
- "_project_#prettier-plugin-hermes-parser" depends on it
- Hoisted from "_project_#prettier-plugin-hermes-parser#hermes-parser"
- Hoisted from "_project_#eslint-plugin-react-compiler#hermes-parser"
- Hoisted from "_project_#snap#hermes-parser"
- Hoisted from "_project_#snap#babel-plugin-syntax-hermes-parser#hermes-parser"
- Hoisted from "_project_#eslint-plugin-react-compiler#hermes-eslint#hermes-parser"
info Disk size without dependencies: "1.49MB"
info Disk size with unique dependencies: "1.82MB"
info Disk size with transitive dependencies: "1.82MB"
info Number of shared dependencies: 1
✨ Done in 0.81s.
```
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31586).
* __->__ #31586
* #31585
```
=> Found "react@0.0.0-experimental-4beb1fd8-20241118"
info Reasons this module exists
- "_project_#babel-plugin-react-compiler" depends on it
- Hoisted from "_project_#babel-plugin-react-compiler#react"
- Hoisted from "_project_#snap#react"
info Disk size without dependencies: "252KB"
info Disk size with unique dependencies: "252KB"
info Disk size with transitive dependencies: "252KB"
info Number of shared dependencies: 0
✨ Done in 0.60s.
```
```
=> Found "react-dom@0.0.0-experimental-4beb1fd8-20241118"
info Reasons this module exists
- "_project_#babel-plugin-react-compiler" depends on it
- Hoisted from "_project_#babel-plugin-react-compiler#react-dom"
- Hoisted from "_project_#snap#react-dom"
info Disk size without dependencies: "8.04MB"
info Disk size with unique dependencies: "8.17MB"
info Disk size with transitive dependencies: "8.17MB"
info Number of shared dependencies: 1
✨ Done in 0.56s.
```
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31585).
* #31586
* __->__ #31585
Our e2e setup with monaco is kinda brittle since it relies on the dom.
It seems like longish text gets truncated so let's just simpify all
these test cases.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31573).
* __->__ #31573
* #31572
Since `enableRefAsProp` shipped everywhere, the ReactElement
implementation on prod puts refs on both `element.ref` and
`element.props.ref`. Here we let the `ref` case fall through so its now
available on props, matching the JSX runtime.
This PR introduces a new experimental hook `useResourceEffect`, which is
something that we're doing some very early initial tests on.
This may likely not pan out and will be removed or modified if so.
Please do not rely on it as it will break.
This lets us track separately if something was suspended on an Action
using useActionState rather than suspended on Data.
This approach feels quite bloated and it seems like we'd eventually
might want to read more information about the Promise that suspended and
the context it suspended in. As a more general reason for suspending.
The way useActionState works in combination with the prewarming is quite
unfortunate because 1) it renders blocking to update the isPending flag
whether you use it or not 2) it prewarms and suspends the useActionState
3) then it does another third render to get back into the useActionState
position again.
Now that we rely on function context exclusively, let's clean up
`HIRFunction.context` after DCE. This PR is in preparation of #31204,
which would otherwise have unnecessary declarations (of context values
that become entirely DCE'd)
'
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31202).
* __->__ #31202
* #31203
* #31201
* #31200
* #31521
`JSXMemberExpression` is currently the only instruction (that I know of)
that directly references identifier lvalues without a corresponding
`LoadLocal`.
This has some side effects:
- deadcode elimination and constant propagation now reach
JSXMemberExpressions
- we can delete `LoweredFunction.dependencies` without dangling
references (previously, the only reference to JSXMemberExpression
objects in HIR was in function dependencies)
- JSXMemberExpression now is consistent with all other instructions
(e.g. has a rvalue-producing LoadLocal)
'
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31201).
* #31202
* #31203
* __->__ #31201
* #31200
* #31521
Recursively visit inner function instructions to extract dependencies
instead of using `LoweredFunction.dependencies` directly.
This is currently gated by enableFunctionDependencyRewrite, which needs
to be removed before we delete `LoweredFunction.dependencies` altogether
(#31204).
Some nice side effects
- optional-chaining deps for inner functions
- full DCE and outlining for inner functions (see #31202)
- fewer extraneous instructions (see #31204)
-
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31200).
* #31202
* #31203
* #31201
* __->__ #31200
* #31521
We were previously filtering out `ref.current` dependencies in
propagateScopeDependencies:checkValidDependency`. This is incorrect.
Instead, we now always take a dependency on ref values (the outer box)
as they may be reactive. Pruning is done in
pruneNonReactiveDependencies.
This PR includes a small patch to `collectReactiveIdentifier`. Prior to
this, we conservatively assumed that pruned scopes always produced
reactive declarations. This assumption fixed a bug with non-reactivity,
but some of these declarations are `useRef` calls. Now we have special
handling for this case
```js
// This often produces a pruned scope
React.useRef(1);
```
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31521).
* #31202
* #31203
* #31201
* #31200
* __->__ #31521
This includes:
- `Interrupted Render`: Interrupted Renders (setState or ping at higher
priority)
- `Prewarm`: Suspended Renders outside a Suspense boundary
(RootSuspendedWithDelay/RootSuspendedAtTheShell)
- `Errored Render`: Render that errored somewhere in the tree (Fatal or
Not) (which may or may not be retried and then complete)
- `Teared Render`: Due to useSyncExternalStore not matching (which will
do another sync attempt)
Suspended Commit:
<img width="893" alt="Screenshot 2024-11-14 at 11 47 40 PM"
src="https://github.com/user-attachments/assets/b25a6a8b-a5e9-4d66-b325-57aef4bf9dad">
Errored with a second recovery attempt that also errors:
<img width="976" alt="Screenshot 2024-11-15 at 12 09 06 AM"
src="https://github.com/user-attachments/assets/9ce52cbb-b587-4f1e-8b67-e51d9073ae5b">
## Summary
This fixes a typo in the error that gets reported when Float errors
while hoisting a style tag that does not contain both `precedence` and
`href`. There was a typo in _conflict_ and the last part of the sentence
doesn't make sense. I assume it wasn't needed since the message already
suggests moving the style tag to the head manually.
It's useful to quickly see where new events are kicking off new
rendering. This uses the new "warning" color (yellow) to do that. This
is to help distinguish it from the purple (secondary color) which is
used for the commit phase which is more of a follow up and it's often
that you have several rerenders within one event which makes it hard to
tell a part where it starts and event otherwise.
For the span marking between previous render within the same event and
the next setState, I use secondary-light (light purple) since it's kind
of still part of the same sequence at that point. It's usually a spawned
render (e.g. setState in useEffect or microtask) but it can also be
sequential flushSync.
I was bothered by that the event name is the only thing that's lower
case so I prefixed it with `Event: ` like the JS traces are.
<img width="1499" alt="Screenshot 2024-11-13 at 7 15 45 PM"
src="https://github.com/user-attachments/assets/0c81c810-6b5d-4fc7-9bc0-d15b53844ade">
It might be a little confusing why our track starts earlier than the JS
one below in the "Main Thread" flamegraph which looks the same. That's
because ours is the start of the event time which is when the click
happens where as the Main Thread one is when the JS event loop gets
around to processing the event.
When you schedule a microtask from render or effect and then call
setState (or ping) from there, the "event" is the event that React
scheduled (which will be a postMessage). The event time of this new
render will be before the last render finished.
We usually clamp these but in this scenario the update doesn't happen
while a render is happening. Causing overlapping events.
Before:
<img width="1229" alt="Screenshot 2024-11-12 at 11 01 30 PM"
src="https://github.com/user-attachments/assets/9652cf3b-b358-453c-b295-1239cbb15952">
Therefore when we finalize a render we need to store the end of the last
render so when we a new update comes in later with an event time earlier
than that, we know to clamp it.
There's also a special case here where when we enter the
`RootDidNotComplete` or `RootSuspendedWithDelay` case we neither leave
the root as in progress nor commit it. Those needs to finalize too.
Really this should be modeled as a suspended track that we haven't added
yet. That's the gap between "Blocked" and "message" below.
After:
<img width="1471" alt="Screenshot 2024-11-13 at 12 31 34 AM"
src="https://github.com/user-attachments/assets/b24f994e-9055-4b10-ad29-ad9b36302ffc">
I also fixed an issue where we may log the same event name multiple
times if we're rendering more than once in the same event. In this case
I just leave a blank trace between the last commit and the next update.
I also adding ignoring of the "message" event at all in these cases when
the event is from React's scheduling itself.
Fixes a bug.
We're supposed to not log "Waiting for Paint" if the passive effect
phase was forced since we weren't really waiting until the paint.
Instead we just log an empty string when we force it to still ensure
continuity.
We should always log the passive phase. This check was in the wrong
place.
In order to make use of the compiler in stable releases (eg React 19 RC,
canary), we need to export the compiler runtime in the stable channel as
well.
## Summary
`@rollup/plugin-typescript` emits a warning while building, hinting that
`outputToFilesystem` defaults to true.
Although "noEmit" is set to `true` for the tsconfig, rollup writes a
`dist/.tsbuildinfo`. That file is then also shipped inside the npm
module and doesn't offer any benefit for library consumers. Setting this
option to false results in the file not being written and thus omitted
from the npm module.
## How did you test this change?
`dist/.tsbuildinfo` is not emitted any more.
Previously we were showing Components inside each lane track but that
meant that as soon as you expanded a lane you couldn't see the other
line so you couldn't get an overview over how well things were
scheduled.
This instead moves all the Components into a single top-level track and
renames the previous one to a "Scheduler" track group.
<img width="1352" alt="Screenshot 2024-11-12 at 8 26 05 PM"
src="https://github.com/user-attachments/assets/590bc6d3-3540-4ee4-b474-5d733b8d8d8d">
That way you can get an overview over what React is working on first and
then right below see which Component is being worked on.
Ideally the "Scheduler" track would be always expanded since each Track
is always just a single row. Now you have to expand each lane to see the
labels but then you're wasting a lot of vertical real estate. There's
currently no option to create this with the Chrome performance.measure
extensions.
<img width="1277" alt="Screenshot 2024-11-12 at 8 26 16 PM"
src="https://github.com/user-attachments/assets/4fc39e35-10ec-4452-ad32-c1c2e6b5e1a8">
In preparation for the next RC, I set this feature flag to true
everywhere. I did not delete the feature flag yet, in case there are yet
more bugs to be discovered.
I also didn't remove the dynamic feature flag from the Meta builds; I'll
let the Meta folks handle that.
Our CI workflows generally cache `**/node_modules` (note the glob, it
caches all transitive node_module directories) to speed up startup for
new jobs that don't change any dependencies. However it seems like one
of our caches got into a weird state (not sure how it happened) where
the `build` directory (used in various other scripts as the directory
for compiled React packages) would contain a `node_modules` directory as
well. This made sizebot size change messages very big since it would try
to compare every single file in `build/node_modules`.
The fix is to ensure we always clean the `build` directory before doing
anything with it. We can also delete that one problematic cache but this
PR is a little more resilient to other weird behavior with that
directory.
This provides less context but skips a lot of noise.
Previously we were including parent components to provide context about
what is rendering but this turns out to be:
1) Very expensive due to the overhead of `performance.measure()` while
profiling.
2) Unactionable noise in the profile that hurt more than it added in
real apps with large trees.
This approach instead just add performance.measure calls for each
component that was marked as PerformedWork (which was used for this
purpose by React Profiler) or had any Effects.
Not everything gets marked with PerformedWork though. E.g. DOM nodes do
not but they can have significant render times since creating them takes
time. We might consider including them if a self-time threshold is met.
Because there is little to no context about the component anymore it
becomes really essential to get a feature from Chrome DevTools that can
link to something with more context like React DevTools.
This reverts commit d3bf32a95806b6d583ef041b8d83781cd686cfd8 which was
part of #30983
When you have very deep trees this trick can cause the top levels to
skew way too much from the real numbers. Creating unbalanced trees.
The bug should have been fixed in Chrome Canary now so that entries
added later are sorted to go first which should've addressed this issue.
## Summary
We have been getting unhandled `TypeError: Cannot convert object to
primitive value` errors in development that only occur when using
devtools. I tracked it down to `console.error()` calls coming from
Apollo Client where one of the arguments is an object without a
prototype (created with `Object.create(null)`). This causes
`formatConsoleArgumentsToSingleString()` in React's devtools to error as
the function does not defend against `String()` throwing an error.
My attempted fix is to introduce a `safeToString` function (naming
suggestions appreciated) which expects `String()` to throw on certain
object and in that case falls back to returning `[object Object]`, which
is what `String({})` would return.
## How did you test this change?
Added a new unit test.
This readme documents React Server Components from `react-server`
package enough to get an implementer started. It's not comprehensive but
it's a beginning point and crucially adds documentation for the
`prerender` API for Flight.
We've previously failed to land this change due to some internal apps
seeing infinite render loops due to external store state updates during
render. It turns out that since the `renderWasConcurrent` var was moved
into the do block, the sync render triggered from the external store
check was stuck with a `RootSuspended` `exitStatus`. So this is not
unique to sibling prerendering but more generally related to how we
handle update to a sync external store during render.
We've tested this build against local repros which now render without
crashes. We will try to add a unit test to cover the scenario as well.
---------
Co-authored-by: Andrew Clark <git@andrewclark.io>
Co-authored-by: Rick Hanlon <rickhanlonii@fb.com>
## Summary
I'm working to get the main `react-native` package parsable by modern
Flow tooling (both `flow-bundler`, `flow-api-translator`), and one
blocker is legacy `module.exports` syntax. This diff updates files which
are [synced to
`react-native`](https://github.com/facebook/react-native/tree/main/packages/react-native/Libraries/Renderer/shims)
from this repo.
## How did you test this change?
Files were pasted into `react-native-github` under fbsource, where Flow
validates ✅.
Previously, we bailed out on outlining jsx that had children that were
not part of the outlined jsx.
Now, we add support for children by treating as attributes.
Previously, we would skip outlining jsx expressions that had duplicate
jsx attributes as we would not rename them causing incorrect
compilation.
In this PR, we add outlining support for duplicate jsx attributes by
renaming them.
Previously, we'd directly store the original attributes from the jsx
expressions. But this isn't enough as we want to rename duplicate
attributes.
This PR refactors the prop collection logic to store both the original
and new names for jsx attributes in the newly outlined jsx expression.
For now, both the new and old names are the same. In the future, they
will be different when we add support for outlining expressions with
duplicate attribute names.
Backs out the 2 related commits:
-
f8f6e1a21a
-
6c0f37f94b
Since I only realized when syncing that we need the version of `react`
and the legacy renderer to match.
While I investigate if there's anything we can do to work around that
while preserving the legacy renderer, this unblocks the sync.
Recursively collect identifier / property loads and optional chains from
inner functions. This PR is in preparation for #31200
Previously, we only did this in `collectHoistablePropertyLoads` to
understand hoistable property loads from inner functions.
1. collectTemporariesSidemap
2. collectOptionalChainSidemap
3. collectHoistablePropertyLoads
- ^ this recursively calls `collectTemporariesSidemap`,
`collectOptionalChainSidemap`, and `collectOptionalChainSidemap` on
inner functions
4. collectDependencies
Now, we have
1. collectTemporariesSidemap
- recursively record identifiers in inner functions. Note that we track
all temporaries in the same map as `IdentifierIds` are currently unique
across functions
2. collectOptionalChainSidemap
- recursively records optional chain sidemaps in inner functions
3. collectHoistablePropertyLoads
- (unchanged, except to remove recursive collection of temporaries)
4. collectDependencies
- unchanged: to be modified to recursively collect dependencies in next
PR
'
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31346).
* #31202
* #31203
* #31201
* #31200
* __->__ #31346
* #31199
`enablePropagateScopeDepsHIR` is now used extensively in Meta. This has
been tested for over two weeks in our e2e tests and production.
The rest of this stack deletes `LoweredFunction.dependencies`, which the
non-hir version of `PropagateScopeDeps` depends on. To avoid a more
forked HIR (non-hir with dependencies and hir with no dependencies),
let's go ahead and clean up the non-hir version of
PropagateScopeDepsHIR.
Note that all fixture changes in this PR were previously reviewed when
they were copied to `propagate-scope-deps-hir-fork`. Will clean up /
merge these duplicate fixtures in a later PR
'
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31199).
* #31202
* #31203
* #31201
* #31200
* #31346
* __->__ #31199
All dependencies and declarations of a reactive scope can be reordered
to scope start/end. i.e. generated code does not depend on conditional
short-circuiting logic as dependencies are inferred to have no side
effects.
Sorting these by name helps us get higher signal compilation snapshot
diffs when upgrading the compiler and testing PRs
Move environment config parsing for `inlineJsxTransform`,
`lowerContextAccess`, and some dev-only options out of snap (test
fixture). These should now be available for playground via
`@inlineJsxTransform` and `lowerContextAccess`.
Other small change:
Changed zod fields from `nullish()` -> `nullable().default(null)`.
[`nullish`](https://zod.dev/?id=nullish) fields accept `null |
undefined` and default to `undefined`. We don't distinguish between null
and undefined for any of these options, so let's only accept null +
default to null. This also makes EnvironmentConfig in the playground
more accurate. Previously, some fields just didn't show up as
`prettyFormat({field: undefined})` does not print `field`.
We were bailing out on complex computed-key syntax (prior to #31344) as
we assumed that this caused bugs (due to inferring computed key rvalues
to have `freeze` effects).
This fixture shows that this bailout is unrelated to the underlying bug
`PropertyPathRegistry` is responsible for uniqueing identifier and
property paths. This is necessary for the hoistability CFG merging logic
which takes unions and intersections of these nodes to determine a basic
block's hoistable reads, as a function of its neighbors. We also depend
on this to merge optional chained and non-optional chained property
paths
This fixes a small bug in #31066 in which we create a new registry for
nested functions. Now, we use the same registry for a component / hook
and all its inner functions
'
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31345).
* #31204
* #31202
* #31203
* #31201
* #31200
* #31346
* #31199
* #31431
* __->__ #31345
* #31197
We don't actually want the source mapped version of `.stack` from errors
because that would cause us to not be able to associate it with a source
map in the UIs that need it. The strategy in browsers is more correct
where the display is responsible for source maps.
That's why we disable any custom `prepareStackTrace` like the ones added
by `source-map`. We reset it to `undefined`.
However, when running node with `--enable-source-maps` the default for
`prepareStackTrace` which is a V8 feature (but may exist elsewhere too
like Bun) is a source mapped version of the stack. In those environments
we need to reset it to a default implementation that doesn't apply
source maps.
We already did this in Flight using the `ReactFlightStackConfigV8.js`
config. However, we need this more generally in the
`shared/ReactComponentStackFrame` implementation.
We could always set it to the default implementation instead of
`undefined` but that's unnecessary code in browser builds and it might
lead to slightly different results. For safety and code size, this PR
does it with a fork instead.
All builds specific to `node` or `edge` (or `markup` which is a server
feature) gets the default implementation where as everything else (e.g.
browsers) get `undefined` since it's expected that this is not source
mapped. We don't have to do anything about the equivalent in React
DevTools since React DevTools doesn't run on the server.
JSX inlining is a prod-only optimization. We want to enforce this while
maintaining the same compiler output in DEV and PROD.
Here we add a conditional to the transform that only replaces JSX with
object literals outside of DEV. Then a later build step can handle DCE
based on the value of `__DEV__`
## Summary
While fixing ref lifecycles in hidden subtrees in
https://github.com/facebook/react/pull/31379, @rickhanlonii noticed that
we could also add more unit tests for other types of tags to prevent
future regressions during code refactors.
This PR adds more unit tests in the same vein as those added in
https://github.com/facebook/react/pull/31379.
## How did you test this change?
Verified unit tests pass:
```
$ yarn
$ yarn test ReactFreshIntegration-test.js
```
Reverts facebook/react#31403 to reenable lazy context propagation
The disabling was to produce a build that could help track down whether
this flag is causing a possibly related bug in transitions but we don't
intend to disable it just fix forward once we figure out what the
problem is
disables lazy context propagation in oss to help determine if it is
causing bugs in startTransition. Will reenable after cutting a canary
release with this flag disabled
When we serialize debug info we should never error even though we don't
currently support everything being serialized. Since it's non-essential
dev information.
We already handle errors in the replacer but not when errors happen in
the JSON algorithm itself - such as cyclic errors.
We should ideally support cyclic objects but regardless we should
gracefully handle the errors.
## Summary
We're seeing certain situations in React Native development where ref
callbacks in `<Activity mode="hidden">` are sometimes invoked exactly
once with `null` without ever being called with a "current" value.
This violates the contract for refs because refs are expected to always
attach before detach (and to always eventually detach after attach).
This is *particularly* bad for refs that return cleanup functions,
because refs that return cleanup functions expect to never be invoked
with `null`. This bug causes such refs to be invoked with `null`
(because since `safelyAttachRef` was never called, `safelyDetachRef`
thinks the ref does not return a cleanup function and invokes it with
`null`).
This fix makes use of `offscreenSubtreeWasHidden` in
`commitDeletionEffectsOnFiber`, similar to how
ec52a5698e
did this for `commitDeletionEffectsOnFiber`.
## How did you test this change?
We were able to isolate the repro steps to isolate the React Native
experimental changes. However, the repro steps depend on Fast Refresh.
```
function callbackRef(current) {
// Called once with `current` as null, upon triggering Fast Refresh.
}
<Activity mode="hidden">
<View ref={callbackRef} />;
</Activity>
```
Ideally, we would have a unit test that verifies this behavior without
Fast Refresh. (We have evidence that this bug occurs without Fast
Refresh in real product implementations. However, we have not
successfully deduced the root cause, yet.)
This PR currently includes a unit test that reproduces the Fast Refresh
scenario, which is also demonstrated in this CodeSandbox:
https://codesandbox.io/p/sandbox/hungry-darkness-33wxy7
Verified unit tests pass:
```
$ yarn
$ yarn test
# Run with `-r=www-classic` for `enableScopeAPI` tests.
$ yarn test -r=www-classic
```
Verified on the internal React Native development branch that the bug no
longer repros.
---------
Co-authored-by: Rick Hanlon <rickhanlonii@fb.com>
When resolving import specifiers from the react namespace (`import
{imported as local} from 'react'`), we were previously only checking if
the `imported` identifier was a hook if we didn't already have its
definition in the global registry. We also need to check if `local` is a
hook in the case of aliasing since there may be hook-like APIs in react
that don't start with `use` (eg they are experimental or unstable).
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31384).
* #31385
* __->__ #31384
* #31383
This PR loosens the restriction on the types of computed properties we
can handle.
Previously, we would disallow anything that is not an identifier because
non-identifiers could be mutating. But member expressions are not
mutating so we can treat them similar to identifiers.
This reverts commit 6c4bbc7832.
It looked like the bug we found on the original land was related to
broken product code. But through landing #31268 we found additional bugs
internally. Since disabling the feature flag does not fix the bugs, we
have to revert again to unblock the sync. We can continue to debug with
our internal build.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
The recent blog post and
[documentation](https://react.dev/learn/react-compiler#using-react-compiler-with-react-17-or-18)
say that `react-compiler-runtime` supports React 17, yet it currently
requires React 18 or 19 as a peer dependency, making it unusable for
installing on a project still using React 17.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
Manually installing the package on a React 17 codebase.
---------
Co-authored-by: lauren <poteto@users.noreply.github.com>
When parsing stacks from third parties they may include invalid url
characters. So we need to encode them. Since these are expected to be
urls though we use just encodeURI instead of encodeURIComponent.
Normally we filter out stack frames with missing `filename` because they
can be noisy and not ignore listed. However, it's up to the
filterStackFrame function to determine whether to do it. This lets us
match `<anonymous>` stack frames in V8 parsing (they don't have line
numbers).
When a React Server Consumer Manifest does not include an entry for a
client reference ID, we must not try to look up the export name (or
`'*'`) for the client reference. Otherwise this will fail with
`TypeError: Cannot read properties of undefined (reading '...')` instead
of the custom error we intended to throw.
## Summary
This fixes a minor nit I have about the `react-compiler-runtime` package
in that the published code is minified. I assume most consumers will
minify their own bundles so there's no real advantage to minifying it as
part of the build.
For my purposes it makes it more difficult to read the code, use
`patch-package` (if needed), or diff two versions without referencing
the source code on github or mapping it back to original source using
the source maps.
## How did you test this change?
I ran the build locally and looked at the result but did not run the
code. It's a lot more readable except for the commonjs
compatibility-related stuff that Rollup inserts.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
Currently, `react-hooks/rules-of-hooks` does not support `do/while`
loops - I've also reported this in
https://github.com/facebook/react/issues/28713.
This PR takes a stab at adding support for `do/while` by following the
same logic we already have for detecting `while` loops.
After this PR, any hooks called inside a `do/while` loop will be
considered invalid.
We're also adding some unit tests to confirm that the behavior is
working as expected.
Fixes#28713.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
I've added unit tests that cover the case and verified that they pass by
running:
```
yarn test packages/eslint-plugin-react-hooks/__tests__/ESLintRulesOfHooks-test.js --watch
```
I've also verified that the rest of the tests continue to pass by
running:
```
yarn test
```
and
```
yarn test --prod
```
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Since the Babel plugin is bundled into a single file (except for
`@babel/types`
45804af18d/compiler/packages/babel-plugin-react-compiler/rollup.config.js (L18))
we can move these deps to `devDependencies`.
Main motivation is e.g. not installing ancient version of
`pretty-format` (asked in https://github.com/facebook/react/issues/29062
without getting a reason, but if consumers can just skip the deps
entirely that's even better).
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
I tested by installing the plugin into an empty project, deleting
everything in `node_modules` _except_ for `babel-plugin-react-compiler`
and doing `require('babel-plugin-react-compiler')`. It still worked
fine, so it should work in other cases as well 😀
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
In order to adopt react 19's ref-as-prop model, Flow needs to eliminate
all the places where they are treated differently.
`React.AbstractComponent` is the worst example of this, and we need to
eliminate it.
This PR eliminates them from the react repo, and only keeps the one that
has 1 argument of props.
## How did you test this change?
yarn flow
When we added `renderToReadableStream` we added the `allReady` helper to
make it easier to do SSG rendering but it's kind of awkward to wire up
that way. Since we're also discouraging `renderToString` in React 19 the
cliff is kind of awkward. ([As noted by
Docusaurus.](https://github.com/facebook/react/pull/24752#issuecomment-2178309299))
The idea of the `react-dom/static` `prerender` API was that this would
be the replacement for SSG rendering. Awkwardly this entry point
actually already exists in stable but it has only `undefined` exports.
Since then we've also added other useful heuristics into the `prerender`
branch that makes this really the favored and easiest to use API for the
prerender (SSG/ISR) use case.
`prerender` is also used for Partial Prerendering but that part is still
experimental.
However, we can expose only the `prerender` API on `react-dom/static`
without it returning the `postponeState`. Instead the stream is on
`prelude`. The naming is a bit awkward if you don't consider resuming
but it's the same thing.
It's really just `renderToReadable` stream with automatic `allReady` and
better heuristics for prerendering.
Stacked on #31299.
We already have an option for resolving Client References to other
Client References when consuming an RSC payload on the server.
This lets you resolve Server References on the consuming side when the
environment where you're consuming the RSC payload also has access to
those Server References. Basically they becomes like Client References
for this consumer but for another consumer they wouldn't be.
I happened to notice some jobs on main get canceled if another PR landed
before the prior commit on main had finished running CI. This is not
great for difftrain because the commit artifacts job relies on the CI
jobs on main finishing before it triggers. This would lead to commits
being skipped on DiffTrain which is not great for provenance since we
want it to be a 1:1 sync.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31296).
* #31297
* __->__ #31296
InlineJSXTransform wasn't traversing into function expressions or object
methods, so any JSX inside such functions wouldn't have gotten inlined.
This PR updates to traverse nested functions to transform all JSX within
a hook or component.
Note that this still doesn't transform JSX outside of components or
hooks, ie in standalone render helpers.
This was previously blocked because the playground was a part of the
compiler's yarn workspace and there was some funky hoisting going on.
Now that we are decoupled we can upgrade to Next 15, which hopefully
should improve build times.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31291).
* #31293
* #31292
* __->__ #31291
It turns out npm sets the latest tag by default so simply removing it
didn't change the previous behavior.
The `latest` tag is typically used for stable release versions, and
other tags for unstable versions such as prereleases. Since the compiler
is still in prerelease, let's set the latest tag only for
non-experimental releases to help signal which version is the safest to
try out.
---
[//]: # (BEGIN SAPLING FOOTER)
Stack created with [Sapling](https://sapling-scm.com). Best reviewed
with [ReviewStack](https://reviewstack.dev/facebook/react/pull/31288).
* #31289
* __->__ #31288
Currently, the react compiler can not compile within callbacks which can
potentially cause over rendering. Consider this example:
```jsx
function Component(countries, onDelete) {
const name = useFoo();
return countries.map(() => {
return (
<Foo>
<Bar name={name}/>
<Baz onclick={onDelete} />
</Foo>
);
});
}
```
In this case, there's no memoization of the nested jsx elements. But
instead if we were to manually refactor the nested jsx into separate
component like this:
```jsx
function Component(countries, onDelete) {
const name = useFoo();
return countries.map(() => {
return <Temp name={name} onDelete={onDelete} />;
});
}
function Temp({ name, onDelete }) {
return (
<Foo>
<Bar name={name} />
<Baz onclick={onDelete} />
</Foo>
);
}
```
The compiler can now optimise both these components:
```jsx
function Component(countries, onDelete) {
const $ = _c(4);
const name = useFoo();
let t0;
if ($[0] !== name || $[1] !== onDelete || $[2] !== countries) {
t0 = countries.map(() => <Temp name={name} onDelete={onDelete} />);
$[0] = name;
$[1] = onDelete;
$[2] = countries;
$[3] = t0;
} else {
t0 = $[3];
}
return t0;
}
function Temp(t0) {
const $ = _c(7);
const { name, onDelete } = t0;
let t1;
if ($[0] !== name) {
t1 = <Bar name={name} />;
$[0] = name;
$[1] = t1;
} else {
t1 = $[1];
}
let t2;
if ($[2] !== onDelete) {
t2 = <Baz onclick={onDelete} />;
$[2] = onDelete;
$[3] = t2;
} else {
t2 = $[3];
}
let t3;
if ($[4] !== t1 || $[5] !== t2) {
t3 = (
<Foo>
{t1}
{t2}
</Foo>
);
$[4] = t1;
$[5] = t2;
$[6] = t3;
} else {
t3 = $[6];
}
return t3;
}
```
Now, when `countries` is updated by adding one single value, only the
newly added value is re-rendered and not the entire list. Rather than
having to do this manually, this PR teaches the react compiler to do
this transformation.
This PR adds a new pass (`OutlineJsx`) to capture nested jsx statements
and outline them in a separate component. This newly outlined component
can then by memoized by the compiler, giving us more fine grained
rendering.
Adds tests for Compiler integration.
This includes:
- Tests against Compiler from source.
- Versioned (18.2 - <19) tests against Compiler from npm.
For tests against React 18.2, I had to download `react-compiler-runtime`
from npm and put it to `react/compiler-runtime.js`.
## Summary
The React Native Renderer exports a
`__SECRET_INTERNALS_DO_NOT_USE_OR_YOU_WILL_BE_FIRED` property with a
single method that has no remaining call sites:
`computeComponentStackForErrorReporting`
This PR cleans up this unused export.
## How did you test this change?
```
$ yarn
$ yarn flow fabric
$ yarn test
```
This was gated behind `enableOwnerStacks` since they share some code
paths but it's really part of `enableServerComponentLogs`.
This just includes the server-side regular stack on Error/replayed logs
but doesn't use console.createTask and doesn't include owner stacks.
Follows https://github.com/facebook/react/pull/31238
___
This is a partial re-land of
https://github.com/facebook/react/pull/31056. We saw breakages surface
after the original land and had to revert. Now that they've been fixed,
let's try this again. This time we'll split up the commits to give us
more control of testing and rollout internally.
Original PR: https://github.com/facebook/react/pull/31056
Original Commit:
4c71025d8d
Revert PR: https://github.com/facebook/react/pull/31080
Commit description:
> When a synchronous update suspends, and we prerender the siblings, the
prerendering should be non-blocking so that we can immediately restart
once the data arrives.
>
> This happens automatically when there's a Suspense boundary, because
we immediately commit the boundary and then proceed to a Retry render,
which are always concurrent. When there's not a Suspense boundary, there
is no Retry, so we need to take care to switch from the synchronous work
loop to the concurrent one, to enable time slicing.
Co-authored-by: Andrew Clark <git@andrewclark.io>
In #31140 we switched over the uMC polyfill to use memo instead of state
since memo would FastRefresh properly. However this busted devtools'
badging of compiled components; this PR fixes it.
TODO: tests
Co-authored-by: Ruslan Lesiutin <rdlesyutin@gmail.com>
---------
Co-authored-by: Ruslan Lesiutin <rdlesyutin@gmail.com>
Fixes tests against React 18 after
https://github.com/facebook/react/pull/31154:
- Set `supportsTimeline` to true for `Store`.
- Execute `store.profilerStore.startProfiling` after `legacyRender`
import, because this is where `react-dom` is imported and renderer is
registered. We don't yet propagate `isProfiling` flag to newly
registered renderers, when profiling already started see:
d5bba18b5d/packages/react-devtools-shared/src/hook.js (L203-L204)
Summary:
With the previous PR we no longer need to mark identifiers as reactive in contexts where we don't have places. We already deleted most uses of markReactiveId; the last case was to track identifiers through loadlocals etc -- but we already use a disjoint alias map that accounts for loadlocals when setting reactivity.
ghstack-source-id: 69ce0a78b0
Pull Request resolved: https://github.com/facebook/react/pull/31178
Summary:
The official guidance for useRef notes an exception to the rule that refs cannot be accessed during render: to avoid recreating the ref's contents, you can test that the ref is uninitialized and then initialize it using an if statement:
```
if (ref.current == null) {
ref.current = SomeExpensiveOperation()
}
```
The compiler didn't recognize this exception, however, leading to code that obeyed all the official guidance for refs being rejected by the compiler. This PR fixes that, by extending the ref validation machinery with an awareness of guard operations that allow lazy initialization. We now understand `== null` and similar operations, when applied to a ref and consumed by an if terminal, as marking the consequent of the if as a block in which the ref can be safely written to. In order to do so we need to create a notion of ref ids, which link different usages of the same ref via both the ref and the ref value.
ghstack-source-id: d2729274f351e1eb0268f28f629fa4c2568ebc4d
Pull Request resolved: https://github.com/facebook/react/pull/31188
Bumps [micromatch](https://github.com/micromatch/micromatch) from 4.0.5
to 4.0.8.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a
href="https://github.com/micromatch/micromatch/releases">micromatch's
releases</a>.</em></p>
<blockquote>
<h2>4.0.8</h2>
<p>Ultimate release that fixes both CVE-2024-4067 and CVE-2024-4068. We
consider the issues low-priority, so even if you see automated scanners
saying otherwise, don't be scared.</p>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/micromatch/micromatch/blob/master/CHANGELOG.md">micromatch's
changelog</a>.</em></p>
<blockquote>
<h2>[4.0.8] - 2024-08-22</h2>
<ul>
<li>backported CVE-2024-4067 fix (from v4.0.6) over to 4.x branch</li>
</ul>
<h2>[4.0.7] - 2024-05-22</h2>
<ul>
<li>this is basically v4.0.5, with some README updates</li>
<li><strong>it is vulnerable to CVE-2024-4067</strong></li>
<li>Updated braces to v3.0.3 to avoid CVE-2024-4068</li>
<li>does NOT break API compatibility</li>
</ul>
<h2>[4.0.6] - 2024-05-21</h2>
<ul>
<li>Added <code>hasBraces</code> to check if a pattern contains
braces.</li>
<li>Fixes CVE-2024-4067</li>
<li><strong>BREAKS API COMPATIBILITY</strong></li>
<li>Should be labeled as a major release, but it's not.</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="8bd704ec0d"><code>8bd704e</code></a>
4.0.8</li>
<li><a
href="a0e68416a4"><code>a0e6841</code></a>
run verb to generate README documentation</li>
<li><a
href="4ec288484f"><code>4ec2884</code></a>
Merge branch 'v4' into hauserkristof-feature/v4.0.8</li>
<li><a
href="03aa805217"><code>03aa805</code></a>
Merge pull request <a
href="https://redirect.github.com/micromatch/micromatch/issues/266">#266</a>
from hauserkristof/feature/v4.0.8</li>
<li><a
href="814f5f70ef"><code>814f5f7</code></a>
lint</li>
<li><a
href="67fcce6a10"><code>67fcce6</code></a>
fix: CHANGELOG about braces & CVE-2024-4068, v4.0.5</li>
<li><a
href="113f2e3fa7"><code>113f2e3</code></a>
fix: CVE numbers in CHANGELOG</li>
<li><a
href="d9dbd9a266"><code>d9dbd9a</code></a>
feat: updated CHANGELOG</li>
<li><a
href="2ab13157f4"><code>2ab1315</code></a>
fix: use actions/setup-node@v4</li>
<li><a
href="1406ea38f3"><code>1406ea3</code></a>
feat: rework test to work on macos with node 10,12 and 14</li>
<li>Additional commits viewable in <a
href="https://github.com/micromatch/micromatch/compare/4.0.5...4.0.8">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps [json5](https://github.com/json5/json5) from 2.2.1 to 2.2.3.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a
href="https://github.com/json5/json5/releases">json5's
releases</a>.</em></p>
<blockquote>
<h2>v2.2.3</h2>
<ul>
<li>Fix: json5@2.2.3 is now the 'latest' release according to npm
instead of v1.0.2. (<a
href="https://redirect.github.com/json5/json5/issues/299">#299</a>)</li>
</ul>
<h2>v2.2.2</h2>
<ul>
<li>Fix: Properties with the name <code>__proto__</code> are added to
objects and arrays.
(<a href="https://redirect.github.com/json5/json5/issues/199">#199</a>)
This also fixes a prototype pollution vulnerability reported by
Jonathan Gregson! (<a
href="https://redirect.github.com/json5/json5/issues/295">#295</a>).</li>
</ul>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/json5/json5/blob/main/CHANGELOG.md">json5's
changelog</a>.</em></p>
<blockquote>
<h3>v2.2.3 [<a
href="https://github.com/json5/json5/tree/v2.2.3">code</a>, <a
href="https://github.com/json5/json5/compare/v2.2.2...v2.2.3">diff</a>]</h3>
<ul>
<li>Fix: json5@2.2.3 is now the 'latest' release according to npm
instead of
v1.0.2. (<a
href="https://redirect.github.com/json5/json5/issues/299">#299</a>)</li>
</ul>
<h3>v2.2.2 [<a
href="https://github.com/json5/json5/tree/v2.2.2">code</a>, <a
href="https://github.com/json5/json5/compare/v2.2.1...v2.2.2">diff</a>]</h3>
<ul>
<li>Fix: Properties with the name <code>__proto__</code> are added to
objects and arrays.
(<a href="https://redirect.github.com/json5/json5/issues/199">#199</a>)
This also fixes a prototype pollution vulnerability reported by
Jonathan Gregson! (<a
href="https://redirect.github.com/json5/json5/issues/295">#295</a>).</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="c3a7524277"><code>c3a7524</code></a>
2.2.3</li>
<li><a
href="94fd06d82e"><code>94fd06d</code></a>
docs: update CHANGELOG for v2.2.3</li>
<li><a
href="3b8cebf0c4"><code>3b8cebf</code></a>
docs(security): use GitHub security advisories</li>
<li><a
href="f0fd9e194d"><code>f0fd9e1</code></a>
docs: publish a security policy</li>
<li><a
href="6a91a05fff"><code>6a91a05</code></a>
docs(template): bug -> bug report</li>
<li><a
href="14f8cb186e"><code>14f8cb1</code></a>
2.2.2</li>
<li><a
href="10cc7ca916"><code>10cc7ca</code></a>
docs: update CHANGELOG for v2.2.2</li>
<li><a
href="7774c10979"><code>7774c10</code></a>
fix: add <strong>proto</strong> to objects and arrays</li>
<li><a
href="edde30abd8"><code>edde30a</code></a>
Readme: slight tweak to intro</li>
<li><a
href="97286f8bd5"><code>97286f8</code></a>
Improve example in readme</li>
<li>Additional commits viewable in <a
href="https://github.com/json5/json5/compare/v2.2.1...v2.2.3">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Summary:
The fact that phis are identifiers rather than places is unfortunate in a few cases. In some later analyses, we might wish to know whether a phi is reactive, but we don't have an easy way to do that currently.
Most of the changes here is just replacing phi.id with phi.place.identifier and such. Interesting bits are EnterSSA (several functions now take places rather than identifiers, and InferReactivePlaces now needs to mark places as reactive explicitly.
ghstack-source-id: 5f4fb396cd86b421008c37832a5735ac40f8806e
Pull Request resolved: https://github.com/facebook/react/pull/31171
When aborting we emit chunks for each pending task. However there was a
bug where a thenable could also reject before we could flush and we end
up with an extra chunk throwing off the pendingChunks bookeeping. When a
task is retried we skip it if is is not in PENDING status because we
understand it was completed some other way. We need to replciate this
for the reject pathway on serialized thenables since aborting if
effectively completing all pending tasks and not something we need to
continue to do once the thenable rejects later.
We can't make a special getter to mark the boundary of deep
serialization (which can be used for lazy loading in the future) when
the parent object is a special object that we parse with
getOutlinedModel. Such as Map/Set and JSX.
This marks the objects that are direct children of those as not possible
to limit.
I don't love this solution since ideally it would maybe be more local to
the serialization of a specific object.
It also means that very deep trees of only Map/Set never get cut off.
Maybe we should instead override the `get()` and enumeration methods on
these instead somehow.
It's important to have it be a getter though because that's the
mechanism that lets us lazy-load more depth in the future.
renderModelDesctructive can sometimes be called direclty on Date values.
When this happens we don't first call toJSON on the Date value so we
need to explicitly handle the case where where the rendered value is a
Date instance as well. This change updates renderModelDesctructive to
account for sometimes receiving Date instances directly.
Stacked on https://github.com/facebook/react/pull/31132. See last
commit.
There are 2 issues:
1. We've been recording timeline events, even if Timeline Profiler was
not supported by the Host. We've been doing this for React Native, for
example, which would significantly regress perf of recording a profiling
session, but we were not even using this data.
2. Currently, we are generating component stack for every state update
event. This is extremely expensive, and we should not be doing this.
We can't currently fix the second one, because we would still need to
generate all these stacks, and this would still take quite a lot of
time. As of right now, we can't generate a component stack lazily
without relying on the fact that reference to the Fiber is not stale.
With `enableOwnerStacks` we could populate component stacks in some
collection, which would be cached at the Backend, and then returned only
once Frontend asks for it. This approach also eliminates the need for
keeping a reference to a Fiber.
Stacked on https://github.com/facebook/react/pull/31131. See last
commit.
This is a clean-up and a pre-requisite for next changes:
1. `ReloadAndProfileConfig` is now split into boolean value and settings
object. This is mainly because I will add one more setting soon, and
also because settings might be persisted for a longer time than the flag
which signals if the Backend was reloaded for profiling. Ideally, this
settings should probably be moved to the global Hook object, same as we
did for console patching.
2. Host is now responsible for reseting the cached values, Backend will
execute provided `onReloadAndProfileFlagsReset` callback.
Based on https://github.com/facebook/react/pull/31049, credits to
@EdmondChuiHW.
What is happening here:
1. Once Agent is destroyed, unsubscribe own listeners and bridge
listeners.
2. [Browser extension only] Once Agent is destroyed, unsubscribe
listeners from BackendManager.
3. [Browser extension only] I've discovered that `backendManager.js`
content script can get injected multiple times by the browser. When
Frontend is initializing, it will create Store first, and then execute a
content script for bootstraping backend manager. If Frontend was
destroyed somewhere between these 2 steps, Backend won't be notified,
because it is not initialized yet, so it will not unsubscribe listeners
correctly. We might end up duplicating listeners, and the next time
Frontend is launched, it will report an issues "Cannot add / remove node
...", because same operations are emitted twice.
To reproduce 3 you can do the following:
1. Click reload-to-profile
2. Right after when both app and Chrome DevTools panel are reloaded,
close Chrome DevTools.
3. Open Chrome DevTools again, open Profiler panel and observe "Cannot
add / remove node ..." error in the UI.
We can't wait for a response from Backend, because it might take some
time to actually finish profiling.
We should keep a flag on the frontend side, so user can quickly see the
feedback in the UI.
Updates the compiler to always import from `react-compiler-runtime` by
default. The runtime then decides whether to use the official or
userspace implementation of useMemoCache.
In order to support using the compiler on versions of React prior to 19,
we need the ability to statically import `c` (aka useMemoCache) or
fallback to a polyfill supplied by `react-compiler-runtime` (note: this
is a separate npm package, not to be confused with
`react/compiler-runtime`, which is currently a part of react).
To do this we first need to re-export `useMemoCache` under the top level
React namespace again, which is additive and thus non-breaking. Doing so
allows `react-compiler-runtime` to statically either re-export
`React.__COMPILER_RUNTIME.c` or supply a polyfill, without the need for
a dynamic import which is finicky to support due to returning a promise.
In later PRs I will remove `react/compiler-runtime` and update the
compiler to emit imports to `react-compiler-runtime` instead.
When we added support for Reanimated, we didn't distinguish between true
globals (i.e. identifiers with no static resolutions), module types, and
imports #29188. For the past 3-4 months, Reanimated imports were not
being matched to the correct hook / function shape we match globals and
module imports against two different registries.
This PR fixes our support for Reanimated library functions imported
under `react-native-reanimated`. See test fixtures for details
Stack from [ghstack](https://github.com/ezyang/ghstack) (oldest at
bottom):
* __->__ #31066
* #31032
Prior to this PR, we consider all of a nested function's accessed paths
as 'hoistable' (to the basic block in which the function was defined).
Now, we traverse nested functions and find all paths hoistable to their
*entry block*.
Note that this only replaces the *hoisting* part of function
declarations, not dependencies. This realistically only affects optional
chains within functions, which always get truncated to its inner
non-optional path (see
[todo-infer-function-uncond-optionals-hoisted.tsx](576f3c0aa8/compiler/packages/babel-plugin-react-compiler/src/__tests__/fixtures/compiler/propagate-scope-deps-hir-fork/reduce-reactive-deps/todo-infer-function-uncond-optionals-hoisted.tsx))
See newly added test fixtures for details
Update: Note that toggling `enableTreatFunctionDepsAsConditional` makes
a non-trivial impact on granularity of inferred deps (i.e. we find that
function declarations uniquely identify some paths as hoistable).
Snapshot comparison of internal code shows ~2.5% of files get worse
dependencies ([internal
link](https://www.internalfb.com/phabricator/paste/view/P1625792186))
Stack from [ghstack](https://github.com/ezyang/ghstack) (oldest at
bottom):
* #31066
* __->__ #31032
Prior to this PR, we check whether the property load source (e.g. the
evaluation of `<base>` in `<base>.property`) is mutable + scoped to
determine whether the property load itself is eligible for hoisting.
This changes to check the base identifier of the load.
- This is needed for the next PR #31066. We want to evaluate whether the
base identifier is mutable within the context of the *outermost
function*. This is because all LoadLocals and PropertyLoads within a
nested function declaration have mutable-ranges within the context of
the function, but the base identifier is a context variable.
- A side effect is that we no longer infer loads from props / other
function arguments as mutable in edge cases (e.g. props escaping out of
try-blocks or being assigned to context variables)
Adds HIR version of `PropagateScopeDeps` to handle optional chaining.
Internally, this improves memoization on ~4% of compiled files (internal links: [1](https://www.internalfb.com/intern/paste/P1610406497/))
Summarizing the changes in this PR.
1. `CollectOptionalChainDependencies` recursively traverses optional blocks down to the base. From the base, we build up a set of `baseIdentifier.propertyA?.propertyB` mappings.
The tricky bit here is that optional blocks sometimes reference other optional blocks that are *not* part of the same chain e.g. a(c?.d)?.d. See code + comments in `traverseOptionalBlock` for how we avoid concatenating unrelated blocks.
2. Adding optional chains into non-null object calculation.
(Note that marking `a?.b` as 'non-null' means that `a?.b.c` is safe to evaluate, *not* `(a?.b).c`. Happy to rename this / reword comments accordingly if there's a better term)
This pass is split into two stages. (1) collecting non-null objects by block and (2) propagating non-null objects across blocks. The only significant change here was to (2). We add an extra reduce step `X=Reduce(Union(X, Intersect(X_neighbors)))` to merge optional and non-optional nodes (e.g. nonNulls=`{a, a?.b}` reduces to `{a, a.b}`)
3. Adding optional chains into dependency calculation.
This was the trickiest. We need to take the "maximal" property chain as a dependency. Prior to this PR, we avoided taking subpaths e.g. `a.b` of `a.b.c` as dependencies by only visiting non-PropertyLoad/LoadLocal instructions. This effectively only recorded the property-path at site-of-use.
Unfortunately, this *quite* doesn't work for optional chains for a few reasons:
- We would need to skip relevant `StoreLocal`/`Branch terminal` instructions (but only those within optional blocks that have been successfully read).
- Given an optional chain, either (1) only a subpath or (2) the entire path can be represented as a PropertyLoad. We cannot directly add the last hoistable optional-block as a dependency as MethodCalls are an edge case e.g. given a?.b.c(), we should depend on `a?.b`, not `a?.b.c`
This means that we add its dependency at either the innermost unhoistable optional-block or when encountering it within its phi-join.
4. Handle optional chains in DeriveMinimalDependenciesHIR.
This was also a bit tricky to formulate. Ideally, we would avoid a 2^3 case join (cond | uncond cfg, optional | not optional load, access | dependency). This PR attempts to simplify by building two trees
1. First add each hoistable path into a tree containing `Optional | NonOptional` nodes.
2. Then add each dependency into another tree containing `Optional | NonOptional`, `Access | Dependency` nodes, truncating the dependency at the earliest non-hoistable node (i.e. non-matching pair when walking the hoistable tree)
ghstack-source-id: a2170f2628
Pull Request resolved: https://github.com/facebook/react/pull/31037
## Summary
Creates a new `HostInstance` type for React Native, to more accurately
capture the intent most developers have when using the `NativeMethods`
type or `React.ElementRef<HostComponent<T>>`.
Since `React.ElementRef<HostComponent<T>>` is typed as
`React.AbstractComponent<T, NativeMethods>`, that means
`React.ElementRef<HostComponent<T>>` is equivalent to `NativeMethods`
which is equivalent to `HostInstance`.
## How did you test this change?
```
$ yarn
$ yarn flow fabric
```
Allow aborting encoding arguments to a Server Action if a Promise
doesn't resolve. That way at least part of the arguments can be used on
the receiving side. This leaves it unresolved in the stream rather than
encoding an error.
This should error on the receiving side when the stream closes but it
doesn't right now in the Edge/Browser versions because closing happens
immediately before we've had a chance to call `.then()` so the Chunks
are still in pending state. This is an existing bug also in
FlightClient.
We're seeing issues with this feature internally including bugs with
sibling prerendering and errors that are difficult for developers to
action on. We'll turn off the feature for the time being until we can
improve the stability and ergonomics.
This PR does two things:
- Turn off `enableInfiniteLoopDetection` everywhere while leaving it as
a variant on www so we can do further experimentation.
- Revert https://github.com/facebook/react/pull/31061 which was a
temporary change for debugging. This brings the feature back to
baseline.
Fixes https://github.com/facebook/react/issues/31100.
There are 2 things:
1. In https://github.com/facebook/react/pull/30987, we've introduced a
breaking change: importing `react-devtools-core` is no longer enough for
installing React DevTools global Hook. You need to call `initialize`, in
which you may provide initial settings. I am not adding settings here,
because it is not implemented, and there are no plans for supporting
this.
2. Calling `installHook` is not necessary inside `standalone.js`,
because this script is running inside Electron wrapper (which is just a
UI, not the app that we are debugging). We will loose the ability to use
React DevTools on this React application, but I guess thats fine.
This allows us to show props in React DevTools when inspecting a Server
Component.
I currently drastically limit the object depth that's serialized since
this is very implicit and you can have heavy objects on the server.
We previously was using the general outlineModel to outline
ReactComponentInfo but we weren't consistently using it everywhere which
could cause some bugs with the parsing when it got deduped on the
client. It also lead to the weird feature detect of `isReactComponent`.
It also meant that this serialization was using the plain serialization
instead of `renderConsoleValue` which means we couldn't safely serialize
arbitrary debug info that isn't serializable there.
So the main change here is to call `outlineComponentInfo` and have that
always write every "Server Component" instance as outlined and in a way
that lets its props be serialized using `renderConsoleValue`.
<img width="1150" alt="Screenshot 2024-10-01 at 1 25 05 AM"
src="https://github.com/user-attachments/assets/f6e7811d-51a3-46b9-bbe0-1b8276849ed4">
The idea is that the RSC protocol is a superset of Structured Clone.
#25687 One exception that we left out was serializing Error objects as
values. We serialize "throws" or "rejections" as Error (regardless of
their type) but not Error values.
This fixes that by serializing `Error` objects. We don't include digest
in this case since we don't call `onError` and it's not really expected
that you'd log it on the server with some way to look it up.
In general this is not super useful outside throws. Especially since we
hide their values in prod. However, there is one case where it is quite
useful. When you replay console logs in DEV you might often log an Error
object within the scope of a Server Component. E.g. the default RSC
error handling just console.error and error object.
Before this would just be an empty object due to our lax console log
serialization:
<img width="1355" alt="Screenshot 2024-09-30 at 2 24 03 PM"
src="https://github.com/user-attachments/assets/694b3fd3-f95f-4863-9321-bcea3f5c5db4">
After:
<img width="1348" alt="Screenshot 2024-09-30 at 2 36 48 PM"
src="https://github.com/user-attachments/assets/834b129d-220d-43a2-a2f4-2eb06921747d">
TODO for a follow up: Flight Reply direction. This direction doesn't
actually serialize thrown errors because they always reject the
serialization.
Rename for clarity:
- `CollectHoistablePropertyLoads:Tree` -> `CollectHoistablePropertyLoads:PropertyPathRegistry`
- `getPropertyLoadNode` -> `getOrCreateProperty`
- `getOrCreateRoot` -> `getOrCreateIdentifier`
- `PropertyLoadNode` -> `PropertyPathNode`
Refactor to CFG joining logic for `CollectHoistablePropertyLoads`. We now write to the same set of inferredNonNullObjects when traversing from entry and exit blocks. This is more correct, as non-nulls inferred from a forward traversal should be included when computing the backward traversal (and vice versa). This fix is needed by an edge case in #31036
Added invariant into fixed-point iteration to terminate (instead of infinite looping).
ghstack-source-id: 1e8eb2d566b649ede93de9a9c13dad09b96416a5
Pull Request resolved: https://github.com/facebook/react/pull/31036
Fix edge case in which we incorrectly returned a cached exception instead of trying to rerender with new props.
ghstack-source-id: 843fb85df4a2ae7a88f296104fb16b5f9a34c76e
Pull Request resolved: https://github.com/facebook/react/pull/31082
Found when writing #31037, summary copied from comments:
This is an extreme edge case and not code we'd expect any reasonable developer to write. In most cases e.g. `(a?.b != null ? a.b : DEFAULT)`, we do want to take a dependency on `a?.b`.
I found this trying to come up with edge cases that break the current dependency + CFG merging logic. I think it makes sense to error on the side of correctness. After all, we still take `a` as a dependency if users write `a != null ? a.b : DEFAULT`, and the same fix (understanding the `<hoistable> != null` test expression) works for both. Can be convinced otherwise though!
ghstack-source-id: cc06afda59f7681e228495f5e35a596c20f875f5
Pull Request resolved: https://github.com/facebook/react/pull/31035
Since removing ExitSSA, Identifier and IdentifierId should mean the same thing
ghstack-source-id: 076cacbe8360e716b0555088043502823f9ee72e
Pull Request resolved: https://github.com/facebook/react/pull/31034
Followup from #30894.
This adds a new flagged mode `enablePropagateScopeDepsInHIR: "enabled_with_optimizations"`, under which we infer more hoistable loads:
- it's always safe to evaluate loads from `props` (i.e. first parameter of a `component`)
- destructuring sources are safe to evaluate loads from (e.g. given `{x} = obj`, we infer that it's safe to evaluate obj.y)
- computed load sources are safe to evaluate loads from (e.g. given `arr[0]`, we can infer that it's safe to evaluate arr.length)
ghstack-source-id: 32f3bb72e9f85922825579bd785d636f4ccf724d
Pull Request resolved: https://github.com/facebook/react/pull/31033
Followup from #30894 , not sure how these got missed. Note that this PR just copies the fixtures without adding `@enablePropagateDepsInHIR`. #31032 follows and actually enables the HIR-version of propagateScopeDeps to run. I split this out into two PRs to make snapshot differences easier to review, but also happy to merge
Fixtures found from locally setting snap test runner to default to `enablePropagateDepsInHIR: 'enabled_baseline'` and forking fixtures files with different output.
ghstack-source-id: 7d7cf41aa923d83ad49f89079171b0411923ce6b
Pull Request resolved: https://github.com/facebook/react/pull/31030
Discovered yesterday while was publishing a new release.
NPM `10.x.x` changed the text for 404 errors, so this check was failing.
Instead of handling 404 as a signal, I think its better to just parse
the whole list of versions and check if the new one is already there.
Currently the playground is setup as a linked workspace for the
compiler which complicates our yarn workspace setup and means that snap
can sometimes pull in a different version of react than was otherwise
specified.
There's no real reason to have these workspaces combined so let's split
them up.
ghstack-source-id: 56ab064b2f
Pull Request resolved: https://github.com/facebook/react/pull/31081
In a recent update we make Flight start working immediately rather than
waitin for a new task. This commit updates fizz to have similar
mechanics. We start the render in the currently running task but we do
so in a microtask to avoid reentrancy. This aligns Fizz with Flight.
ref: https://github.com/facebook/react/pull/30961
This has been broken since the migration to GitHub actions.
Previously, we've been using `buildId` as an identifier from CircleCI.
I've decided to use a commit hash as an identifier, because I don't know
if there is a better option, and
`scripts/release/download_build_artifacts.js` allows us to download them
for a specific commit.
Seems like we can specify a wildcard dependency name to ignore all
dependencies from being updated. As I understand it dependabot will
still run monthly but no PRs will be generated.
ghstack-source-id: 64b76bd532663cdc4db10ba6299e791b5908d5b1
Pull Request resolved: https://github.com/facebook/react/pull/31074
Bumps [ws](https://github.com/websockets/ws) from 6.2.2 to 6.2.3.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a
href="https://github.com/websockets/ws/releases">ws's
releases</a>.</em></p>
<blockquote>
<h2>6.2.3</h2>
<h1>Bug fixes</h1>
<ul>
<li>Backported e55e5106 to the 6.x release line (eeb76d31).</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="d87f3b6d3a"><code>d87f3b6</code></a>
[dist] 6.2.3</li>
<li><a
href="eeb76d313e"><code>eeb76d3</code></a>
[security] Fix crash when the Upgrade header cannot be read (<a
href="https://redirect.github.com/websockets/ws/issues/2231">#2231</a>)</li>
<li>See full diff in <a
href="https://github.com/websockets/ws/compare/6.2.2...6.2.3">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
You can trigger a rebase of this PR by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
> **Note**
> Automatic rebases have been disabled on this pull request as it has
been open for over 30 days.
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
In preparation to support reload-to-profile in Fusebox (#31021), we need
a way to check capability of different backends, e.g. web vs React
Native.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
* Default, e.g. existing web impl = no-op
* Custom impl: is called
React DevTools no longer operates with just Fibers, it now builds its
own Shadow Tree, which represents the tree on the Host (Fabric on
Native, DOM on Web).
We have to keep track of public instances for a select-to-inspect
feature. We've recently changed this logic in
https://github.com/facebook/react/pull/30831, and looks like we've been
incorrectly getting a public instance for Fabric case.
Not only this, turns out that all `getInspectorData...` APIs are
returning Fibers, and not public instances. I have to expose it, so that
React DevTools can correctly identify the element, which was selected.
Changes for React Native are in
[D63421463](https://www.internalfb.com/diff/D63421463)
When a synchronous update suspends, and we prerender the siblings, the
prerendering should be non-blocking so that we can immediately restart
once the data arrives.
This happens automatically when there's a Suspense boundary, because we
immediately commit the boundary and then proceed to a Retry render,
which are always concurrent. When there's not a Suspense boundary, there
is no Retry, so we need to take care to switch from the synchronous work
loop to the concurrent one, to enable time slicing.
Over time the behavior of these two paths has converged to be
essentially the same. So this merges them back into one function. This
should save some code size and also make it harder for the behavior to
accidentally diverge. (For the same reason, rolling out this change
might expose some areas where we had already accidentally diverged.)
We're seeing the limit hit in some tests after enabling sibling
prerendering. Let's bump the limit so we can run more tests and gather
more signal on the changes. When we understand the scope of the problem
we can determine whether we need to change how the updates are counted
in prerenders and/or fix specific areas of product code.
Stacked on https://github.com/facebook/react/pull/31009.
1. Instead of keeping `showInlineWarningsAndErrors` in `Settings`
context (which was removed in
https://github.com/facebook/react/pull/30610), `Store` will now have a
boolean flag, which controls if the UI should be displaying information
about errors and warnings.
2. The errors and warnings counters in the Tree view are now counting
only unique errors. This makes more sense, because it is part of the
Elements Tree view, so ideally it should be showing number of components
with errors and number of components of warnings. Consider this example:
2.1. Warning for element `A` was emitted once and warning for element
`B` was emitted twice.
2.2. With previous implementation, we would show `3 ⚠️`, because in
total there were 3 warnings in total. If user tries to iterate through
these, it will only take 2 steps to do the full cycle, because there are
only 2 elements with warnings (with one having same warning, which was
emitted twice).
2.3 With current implementation, we would show `2 ⚠️`. Inspecting the
element with doubled warning will still show the warning counter (2)
before the warning message.
With these changes, the feature correctly works.
https://fburl.com/a7fw92m4
This is a follow-up from #30528 to not only handle props (the critical
change), but also the owner ~and stack~ of a referenced element.
~Handling stacks here is rather academic because the Flight Server
currently does not deduplicate owner stacks. And if they are really
identical, we should probably just dedupe the whole element.~ EDIT:
Removed from the PR.
Handling owner objects on the other hand is an actual requirement as
reported in https://github.com/vercel/next.js/issues/69545. This problem
only affects the stable release channel, as the absence of owner stacks
allows for the specific kind of shared owner deduping as demonstrated in
the unit test.
I messed up the yml syntax and also realized that our script doesn't
currently handle renames or deletes, so I fixed that
ghstack-source-id: 7d481a951a
Pull Request resolved: https://github.com/facebook/react/pull/31028
Sometimes it is useful to bypass the revision check when we need to make
changes to the runtime_commit_artifacts script. The `force` input can be
passed via the GitHub UI for manual runs of the workflow.
ghstack-source-id: cf9e32c01a
Pull Request resolved: https://github.com/facebook/react/pull/31027
The trailing / was being omitted, so instead of moving the cjs
directory itself, it would move only its contents instead. This broke
some internal path assumptions.
Additionally, updates the step to create the react-dom directory prior
to moving.
ghstack-source-id: b6eedb0c88cd3aa3a786a3d3d280ede5ee81a063
Pull Request resolved: https://github.com/facebook/react/pull/31026
A slight behavior change here too is that I now mark the start of the
commit phase before the BeforeMutationEffect phase. This affects
`<Profiler>` too.
The named sequences are as follows:
Render -> Suspended or Throttled -> Commit -> Waiting for Paint ->
Remaining Effects
The Suspended phase is only logged if we delay the Commit due to CSS /
images.
The Throttled phase is only logged if we delay the commit due to the
Suspense throttling timer.
<img width="1246" alt="Screenshot 2024-09-20 at 9 14 23 PM"
src="https://github.com/user-attachments/assets/8d01f444-bb85-472b-9b42-6157d92c81b4">
I don't yet log render phases that don't complete. I think I also need
to special case renders that or don't commit after being suspended.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Profiling fails sometimes because `onProfilingStatus` is called
repeatedly on some occasions, e.g. multiple calls to
`getProfilingStatus`.
Subsequent calls should be a no-op if the profiling status hasn't
changed.
Reported via #30661#28838.
> [!TIP]
> Hide whitespace changes on this PR
<img width="328" alt="screenshot showing the UI controls for hiding
whitespace changes on GitHub"
src="https://github.com/user-attachments/assets/036385cf-2610-4e69-a717-17c05d7ef047">
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
Tested as part of Fusebox implementation of reload-to-profile.
https://github.com/facebook/react/pull/31021?#discussion_r1770589753
This tracks the current window.event.timeStamp the first time we
setState or call startTransition. For either the blocking track or
transition track. We can use this to show how long we were blocked by
other events or overhead from when the user interacted until we got
called into React.
Then we track the time we start awaiting a Promise returned from
startTransition. We can use this track how long we waited on an Action
to complete before setState was called.
Then finally we track when setState was called so we can track how long
we were blocked by other word before we could actually start rendering.
For a Transition this might be blocked by Blocking React render work.
We only log these once a subsequent render actually happened. If no
render was actually scheduled, then we don't log these. E.g. if an
isomorphic Action doesn't call startTransition there's no render so we
don't log it.
We only log the first event/update/transition even if multiple are
batched into it later. If multiple Actions are entangled they're all
treated as one until an update happens. If no update happens and all
entangled actions finish, we clear the transition so that the next time
a new sequence starts we can log it.
We also clamp these (start the track later) if they were scheduled
within a render/commit. Since we share a single track we don't want to
create overlapping tracks.
The purpose of this is not to show every event/action that happens but
to show a prelude to how long we were blocked before a render started.
So you can follow the first event to commit.
<img width="674" alt="Screenshot 2024-09-20 at 1 59 58 AM"
src="https://github.com/user-attachments/assets/151ba9e8-6b3c-4fa1-9f8d-e3602745eeb7">
I still need to add the rendering/suspended phases to the timeline which
why this screenshot has a gap.
<img width="993" alt="Screenshot 2024-09-20 at 12 50 27 AM"
src="https://github.com/user-attachments/assets/155b6675-b78a-4a22-a32b-212c15051074">
In this case it's a Form Action which started a render into the form
which then suspended on the action. The action then caused a refresh,
which interrupts with its own update that's blocked before rendering.
Suspended roots like this is interesting because we could in theory
start working on a different root in the meantime which makes this
timeline less linear.
When aborting we currently don't produce a componentStack when aborting
the shell. This is likely just an oversight and this change updates this
behavior to be consistent with what we do when there is a boundary
## Overview
Adds a lint rule to prevent optional chaining to catch issues like
https://github.com/facebook/react/pull/30982 until we support optional
chaining without a bundle impact.
Based on https://github.com/facebook/react/pull/30995 ([rendered
diff](https://github.com/jackpope/react/compare/inline-jsx-2...jackpope:react:inline-jsx-3?expand=1))
____
Some apps still use `react.element` symbols. Not only do we want to test
there but we also want to be able to upgrade those sites to
`react.transitional.element` without blocking on the compiler (we can
change the symbol feature flag and compiler config at the same time).
The compiler runtime uses `react.transitional.element`, so the snap
fixture will fail if we change the default here. However I confirmed
that commenting out the fixture entrypoint and running snap with
`react.element` will update the fixture symbols as expected.
If JSX receives a props spread without additional attributes (besides
`ref` and `key`), we can pass the spread object as a property directly
to avoid the extra object copy.
```
<Test {...propsToSpread} />
// {props: propsToSpread}
<Test {...propsToSpread} a="z" />
// {props: {...propsToSpread, a: "z"}}
```
Stacked on https://github.com/facebook/react/pull/30986.
Previously, we would call `installHook` at a top level of the JavaScript
module. Because of this, having `require` statement for
`react-devtools-core` package was enough to initialize the React
DevTools global hook on the `window`.
Now, the Hook can actually receive an argument - initial user settings
for console patching. We expose this as a function `initialize`, which
can be used by third parties (including React Native) to provide the
persisted settings.
The README was also updated to reflect the changes.
## Summary
Builds `react-dom` for React Native so that it also populates the
`builds/facebook-fbsource` branch.
**NOTE:** For Meta employees, D61354219 is the internal integration.
## How did you test this change?
```
$ yarn build
…
$ ls build/facebook-react-native/react-dom/cjs
ReactDOM-dev.js ReactDOM-prod.js ReactDOM-profiling.js
```
Rewrite `containerInfo?.ownerDocument?.defaultView ?? window` to instead
use a ternary.
This changes the compilation output (see [bundle changes from
#30951](d65fb06955)).
```js
// compilation of containerInfo?.ownerDocument?.defaultView ?? window
var $jscomp$optchain$tmpm1756096108$1, $jscomp$nullish$tmp0;
containerInfo =
null !=
($jscomp$nullish$tmp0 =
null == containerInfo
? void 0
: null ==
($jscomp$optchain$tmpm1756096108$1 = containerInfo.ownerDocument)
? void 0
: $jscomp$optchain$tmpm1756096108$1.defaultView)
? $jscomp$nullish$tmp0
: window;
// compilation of ternary expression
containerInfo =
null != containerInfo &&
null != containerInfo.ownerDocument &&
null != containerInfo.ownerDocument.defaultView
? containerInfo.ownerDocument.defaultView
: window;
```
This also reduces the number of no-op bundle syncs for Meta. Note that
Closure compiler's `jscomp$optchain$tmp<HASH>` identifiers change when
we rebuild (likely due to version number changes). See
[workflow](https://github.com/facebook/react/actions/runs/10891164281/job/30221518374)
for a PR that was synced despite making no changes to the runtime.
Stacked on https://github.com/facebook/react/pull/30636. See [this
commit](20cec76c44).
This has been only used for React Native and will be replaced by another
approach (initialization via `installHook` call) in the next PR.
Stacked on https://github.com/facebook/react/pull/30610 and whats under
it. See [last
commit](248ddba186).
Now, we are using
[`chrome.storage`](https://developer.chrome.com/docs/extensions/reference/api/storage)
to persist settings for the browser extension across different sessions.
Once settings are updated from the UI, the `Store` will emit
`settingsUpdated` event, and we are going to persist them via
`chrome.storage.local.set` in `main/index.js`.
When hook is being injected, we are going to pass a `Promise`, which is
going to be resolved after the settings are read from the storage via
`chrome.storage.local.get` in `hookSettingsInjector.js`.
Stacked on https://github.com/facebook/react/pull/30597 and whats under
it. See [this
commit](59b4efa723).
With this change, the initial values for console patching settings are
propagated from hook (which is the source of truth now, because of
https://github.com/facebook/react/pull/30596) to the UI. Instead of
reading from `localStorage` the frontend is now requesting it from the
hook. This happens when settings modal is rendered, and wrapped in a
transition. Also, this is happening even if settings modal is not opened
yet, so we have enough time to fetch this data without displaying loader
or similar UI.
Stacked on https://github.com/facebook/react/pull/30596. See [this
commit](4ba5e784bb).
Moving `formatWithStyles` and `formatConsoleArguments` to its own
modules, so that we can finally have a single implementation for these
and stop inlining them in RDT global hook object.
Stacked on https://github.com/facebook/react/pull/30566 and whats under
it. See [this
commit](374fd737e4).
It is mostly copying code from one place to another and updating tests.
With these changes, for every console method that we patch, there is
going to be a single applied patch:
- For `error`, `warn`, and `trace` we are patching when hook is
installed. This guarantees that component stacks are going to be
appended even if browser DevTools are not opened. We pay some price for
it, though: if user has browser DevTools closed and if at this point
some warning or error is emitted (logged), the next time user opens
browser DevTools, they are going to see `hook.js` as the source frame.
Unfortunately, ignore listing from source maps is not applied
retroactively, and I don't know if its a bug or just a design
limitations. Once browser DevTools are opened, source maps will be
loaded and ignore listing will be applied for all emitted logs in the
future.
- For `log`, `info`, `group`, `groupCollapsed` we are only patching when
React notifies React DevTools about running in StrictMode. We unpatch
the methods right after it.
Right now we are patching console 2 times: when hook is installed
(before page is loaded) and when backend is connected. Because of this,
even if user had `appendComponentStack` setting enabled, all emitted
error and warning logs are not going to have component stacks appended.
They also won't have component stacks appended retroactively when user
opens browser DevTools (this is when frontend is initialized and
connects to backend).
This behavior adds potential race conditions with LogBox in React
Native, and also unpredictable to the user, because in order to get
component stacks logged you have to open browser DevTools, but by the
time you do it, error or warning log was already emitted.
To solve this, we are going to only patch console in the hook object,
because it is guaranteed to load even before React. Settings are going
to be synchronized with the hook via Bridge, and React DevTools Backend
Host (React Native or browser extension shell) will be responsible for
persisting these settings across the session, this is going to be
implemented in a separate PR.
This adds an `InlineJsxTransform` optimization pass, toggled by the
`enableInlineJsxTransform` flag. When enabled, JSX will be transformed
into React Element object literals, preventing runtime overhead during
element creation.
TODO:
- [ ] Add conditionals to make transform PROD-only
- [ ] Make the React element symbol configurable so this works with
runtimes that support `react.element` or `react.transitional.element`
- [ ] Look into additional optimization to pass props spread through
directly if none of the properties are mutated
Stacked on #30981. Same as #30967 but for effects.
This logs a tree of components using `performance.measure()`.
In addition to the previous render phase this logs one tree for each
commit phase:
- Mutation Phase
- Layout Effect
- Passive Unmounts
- Passive Mounts
I currently skip the Before Mutation phase since the snapshots are so
unusual it's not worth creating trees for those.
The mechanism is that I reuse the timings we track for
`enableProfilerCommitHooks`. I track first and last effect timestamp
within each component subtree. Then on the way up do we log the entry.
This means that we don't include overhead to find our way down to a
component and that we don't need to add any additional overhead by
reading timestamps.
To ensure that the entries get ordered correctly we need to ensure that
the start time of each parent is slightly before the inner one.
This code is weird. It reads back the transition that it just set from
the shared internals. It's almost like it expects it to be a getter or
something.
This avoids that and makes it consistent with what ReactFiberHooks
already does.
Stacked on #30979.
The problem with the previous approach is that it recursively walked the
tree up to propagate the resulting time from recording a layout effect.
Instead, we keep a running count of the effect duration on the module
scope. Then we reset it when entering a nested Profiler and then we add
its elapsed count when we exit the Profiler.
This also fixes a bug where we weren't previously including unmount
times for some detached trees since they couldn't bubble up to find the
profiler.
Summary:
1. Minor refactor to provide a stable API for calling the compiler from the playground
2. Allows spaces in pass names without breaking the appearance of the playground by replacing spaces with in pass tabs
ghstack-source-id: 12a43ad86c16c0e21f3e6b4086d531cdefd893eb
Pull Request resolved: https://github.com/facebook/react/pull/30988
Compiler bailout diagnostics should now highlight only the first line of
the source location span.
(Resubmission of #30423 which was reverted due to invalid column
number.)
Summary:
Introduces a new binding kind for functions that allows them to be hoisted. Also has the result of causing all nested function declarations to be outputted as function declarations, not as let bindings.
ghstack-source-id: fa40d4909fb3d30c23691e36510ebb3c3cc41053
Pull Request resolved: https://github.com/facebook/react/pull/30922
Summary:
This brings the behavior of ref mutation within hook callbacks into alignment with the behavior of global mutations--that is, we allow all hooks to take callbacks that may mutate a ref. This is potentially unsafe if the hook eagerly calls its callback, but the alternative is excessively limiting (and inconsistent with other enforcement).
This also bans *directly* passing a ref.current value to a hook, which was previously allowed.
ghstack-source-id: e66ce7123e
Pull Request resolved: https://github.com/facebook/react/pull/30917
Summary:
This change expands our handling of refs to build an understanding of nested refs within objects and functions that may return refs. It builds a special-purpose type system within the ref analysis that gives a very lightweight structural type to objects and array expressions (merging the types of all their members), and then propagating those types throughout the analysis (e.g., if `ref` has type `Ref`, then `{ x: ref }` and `[ref]` have type `Structural(value=Ref)` and `{x: ref}.anything` and `[ref][anything]` have type `Ref`).
This allows us to support structures that contain refs, and functions that operate over them, being created and passed around during rendering without at runtime accessing a ref value.
The analysis here uses a fixpoint to allow types to be fully propagated through the system, and we defend against diverging by widening the type of a variable if it could grow infinitely: so, in something like
```
let x = ref;
while (condition) {
x = [x]
}
```
we end up giving `x` the type `Structural(value=Ref)`.
ghstack-source-id: afb0b0cb01
Pull Request resolved: https://github.com/facebook/react/pull/30902
## Summary
When a view config can not be found, it currently errors with
`TypeError: Cannot read property 'bubblingEventTypes' of null`. Instead
invariant at the correct location and prevent further processing of the
null viewConfig to improve the error logged.
## How did you test this change?
Build and run RN playground app referencing an invalid native view
through `requireNativeComponent`.
This fixes printing Error objects in Chrome DevTools.
I've observed that Chrome DevTools is not source mapping and linkifying
URLs, when was running this on larger apps. Chrome DevTools talks to V8
via Chrome DevTools protocol, every object has a corresponding
[`RemoteObject`](https://chromedevtools.github.io/devtools-protocol/tot/Runtime/#type-RemoteObject).
When Chrome DevTools sees that Error object is printed in the console,
it will try to prettify it. `description` field of the corresponding
`RemoteObject` for the `Error` JavaScript object is a combination of
`Error` `name`, `message`, `stack` fields. This is not just a raw
`stack` field, so our prefix for this field just doesn't work. [V8 is
actually filtering out first line of the `stack` field, it only keeps
the stack frames as a string, and then this gets prefixed by `name` and
`message` fields, if they are
available](https://source.chromium.org/chromium/chromium/src/+/main:v8/src/inspector/value-mirror.cc;l=252-311;drc=bdc48d1b1312cc40c00282efb1c9c5f41dcdca9a?fbclid=IwZXh0bgNhZW0CMTEAAR1tMm5YC4jqowObad1qXFT98X4RO76CMkCGNSxZ8rVsg6k2RrdvkVFL0i4_aem_e2fRrqotKdkYIeWlJnk0RA).
As an illustration, this:
```
const fakeError = new Error('');
fakeError.name = 'Stack';
fakeError.stack = 'Error Stack:' + stack;
```
will be formatted by `V8` as this `RemoteObject`:
```
{
...
description: 'Stack: ...',
...
}
```
Notice that there is no `Error` prefix, that was previously added.
Because of this, [Chrome DevTools won't even try to symbolicate the
stack](ee4729d2cc/front_end/panels/console/ErrorStackParser.ts (L33-L35)),
because it doesn't have such prefix.
Stacked on #30960 and #30966. Behind the enableComponentPerformanceTrack
flag.
This is the first step of performance logging. This logs the start and
end time of a component render in the passive effect phase. We use the
data we're already tracking on components when the Profiler component or
DevTools is active in the Profiling or Dev builds. By backdating this
after committing we avoid adding more overhead in the hot path. By only
logging things that actually committed, we avoid the costly unwinding of
an interrupted render which was hard to maintain in earlier versions.
We already have the start time but we don't have the end time. That's
because `actualStartTime + actualDuration` isn't enough since
`actualDuration` counts the actual CPU time excluding yields and
suspending in the render.
Instead, we infer the end time to be the start time of the next sibling
or the complete time of the whole root if there are no more siblings. We
need to pass this down the passive effect tree. This will mean that any
overhead and yields are attributed to this component's span. In a follow
up, we'll need to start logging these yields to make it clear that this
is not part of the component's self-time.
In follow ups, I'll do the same for commit phases. We'll also need to
log more information about the phases in the top track. We'll also need
to filter out more components from the trees that we don't need to
highlight like the internal Offscreen components. It also needs polish
on colors etc.
Currently, I place the components into separate tracks depending on
which lane currently committed. That way you can see what was blocking
Transitions or Suspense etc. One problem that I've hit with the new
performance.measure extensions is that these tracks show up in the order
they're used which is not the order of priority that we use. Even when
you add fake markers they have to actually be within the performance run
since otherwise the calls are noops so it's not enough to do that once.
However, I think this visualization is actually not good because these
trees end up so large that you can't see any other lanes once you expand
one. Therefore, I think in a follow up I'll actually instead switch to a
model where Components is a single track regardless of lane since we
don't currently have overlap anyway. Then the description about what is
actually rendering can be separate lanes.
<img width="1512" alt="Screenshot 2024-09-15 at 10 55 55 PM"
src="https://github.com/user-attachments/assets/5ca3fa74-97ce-40c7-97f7-80c1dd7d6470">
<img width="1512" alt="Screenshot 2024-09-15 at 10 56 27 PM"
src="https://github.com/user-attachments/assets/557ad65b-4190-465f-843c-0bc6cbb9326d">
We used to queue a separate third passive phase to invoke onPostCommit
but this is unnecessary. We can just treat it as a plain passive effect.
This means it is interleaved with other passive effects but we only need
to know the duration of the things below us which is already done at
this point.
I also extracted the user space call to onPostCommit into
ReactCommitEffects. Same as onCommit. It's now covered by
runWithFiberInDEV and catches.
This flag will be used to gate a new timeline profiler that's integrate
with the Performance Tab and the new performance.measure extensions in
Chrome.
It replaces the existing DevTools feature so this disables
enableSchedulingProfiler when it is enabled since they can interplay in
weird ways potentially.
This means that experimental React now disable scheduling profiler and
enables this new approach.
In a past update we made render and prerender have different work
scheduling behavior because these methods are meant to be used in
differeent environments with different performance tradeoffs in mind.
For instance to prioritize streaming we want to allow as much IO to
complete before triggering a round of work because we want to flush as
few intermediate UI states. With Prerendering there will never be any
intermediate UI states so we can more aggressively render tasks as they
complete.
One thing we've found is that even during render we should ideally kick
off work immediately. This update normalizes the intitial work for
render and prerender to start in a microtask. Choosing microtask over
sync is somewhat arbitrary but there really isn't a reason to make them
different between render/prerender so for now we'll unify them and keep
it as a microtask for now.
This change also updates pinging behavior. If the request is still in
the initial task that spawned it then pings will schedule on the
microtask queue. This allows immediately available async APIs to resolve
right away. The concern with doing this for normal pings is that it
might crowd out IO events but since this is the initial task there would
be IO to already be scheduled.
Nit: I don't trust flags in hot code. While it can take somewhat longer
to compile two functions and JIT them. After that they don't need to
check branches. Also makes it clearer the purpose.
When the environment name changes for a chunk we issue a new debug chunk
which updates the environment name. This chunk was not beign included in
the pendingChunks count so the count was off when flushing
In #26624, the ability to mark a client reference module as `async` in
the React client manifest was removed because it was not utilized by
Webpack, neither in `ReactFlightWebpackPlugin` nor in Next.js. However,
some bundlers and frameworks are sophisticated enough to properly handle
and identify async ESM modules (e.g., client component modules with
top-level `await`), most notably Turbopack in Next.js. Therefore, we
need to consider the `async` flag in the client manifest when resolving
the client reference metadata on the server. The SSR manifest cannot
override this flag, meaning that if a module is async, it must remain
async in all client environments.
x-ref: https://github.com/vercel/next.js/pull/70022
Insertion effects do not unmount when a subtree is removed while
offscreen.
Current behavior for an insertion effect is if the component goes
- *visible -> removed:* calls insertion effect cleanup
- *visible -> offscreen -> removed:* insertion effect cleanup is never
called
This makes it so we always call insertion effect cleanup when removing
the component.
Likely also fixes https://github.com/facebook/react/issues/26670
---------
Co-authored-by: Rick Hanlon <rickhanlonii@fb.com>
Summary:
This PR performs a major refactor of InferReferenceEffects to separate out the work on marking places with Effects from inferring FunctionEffects. The behavior should be identical after this change (see [internal sync](https://www.internalfb.com/intern/everpaste/?handle=GN74VxscnUaztTYDAL8q0CRWBIxibsIXAAAB)) but the FunctionEffect logic should be easier to work with.
These analyses are unfortunately still deeply linked--the FunctionEffect analysis needs to reason about the "current" value kind for each point in the program, while the InferReferenceEffects algorithm performs global updates on the state of the program (e.g. freezing). In the future, it might be possible to make these entirely separate passes if we store the ValueKind directly on places.
For the most part, the logic of reference effects and function effects can be cleanly separated: for each instruction and terminal, we visit its places and infer their effects, and then we visit its places and infer any function effects that they cause. The biggest wrinkle here is that when a transitive function freeze operation occurs, it has to happen *after* inferring the function effects on the place, because otherwise we may convert a value from Context to Frozen, which will cause the ContextualMutation function effect to be converted to a ReactMutation effect too early. This can be observed in a case like this:
```
export default component C() {
foo(() => {
const p = {};
return () => {
p['a'] = 1
};
});
}
```
Here when the outer function returns the inner function, it freezes the inner function which transitively freezes `p`. But before that freeze happens, we need to replay the ContextualMutation on the inner function to determine that the value is mutable in the outer context. If we froze `p` first, we would instead convert the ContextualMutation to a ReactMutation and error.
To handle this, InferReferenceEffects now delays the exection of the freezeValue action until after it's called the helper functions that generate function effects. So the order of operations on a given place is now
set effect --> generate function effects --> transitively freeze dependencies, if applicable
ghstack-source-id: 21cb50c140
Pull Request resolved: https://github.com/facebook/react/pull/30920
At some point this trick was added to initialize the value first to NaN
and then replace them with zeros and negative ones.
This is to address the issue noted in
https://github.com/facebook/react/issues/14365 where these hidden
classes can be initialized to SMIs at first and then deopt when we
realize they're actually doubles.
However, this fix has been long broken and has deopted the profiling
build for years because closure compiler optimizes out the first write.
I'm not sure because I haven't A/B-tested this in the JIT yet but I
think we can use negative zero and -1.1 as the initial values instead
since they're not simple integers. Negative zero `===` zero (but not
Object.is) so is the same as far as our code is concerned. The negative
value is just `< 0` comparisons.
Resubmission of #30079 -- core logic unchanged, but needed to rebase past #30573
### Quick background
#### Temporaries
The compiler currently treats temporaries and named variables (e.g. `x`) differently in this pass.
- named variables may be reassigned (in fact, since we're running after LeaveSSA, a single named identifier's IdentifierId may map to multiple `Identifier` instances -- each with its own scope and mutable range)
- temporaries are replaced with their represented expressions during codegen. This is correct (mostly correct, see #29878) as we're careful to always lower the correct evaluation semantics. However, since we rewrite reactive scopes entirely (to if/else blocks), we need to track temporaries that a scope produces in `ReactiveScope.declarations` and later promote them to named variables.
In the same example, $4, $5, and $6 need to be promoted: $2 ->`t0`, $5 ->`t1`, and $6 ->`t2`.
```js
[1] $2 = LoadGlobal(global) foo
[2] $3 = LoadLocal bar$1
scope 0:
[3] $4 = Call $2(<unknown> $3)
scope 1:
[4] $5 = Object { }
scope 2:
[5] $6 = Object { a: $4, b: $5 }
[6] $8 = StoreLocal Const x$7 = $6
```
#### Dependencies
`ReactiveScope.dependencies` records the set of (read-only) values that a reactive scope is dependent on. This is currently limited to just variables (named variables from source and promoted temporaries) and property-loads.
All dependencies we record need to be hoistable -- i.e. reordered to just before the ReactiveScope begins. Not all PropertyLoads are hoistable.
In this example, we should not evaluate `obj.a.b` without before creating x and checking `objIsNull`.
```js
// reduce-reactive-deps/no-uncond.js
function useFoo({ obj, objIsNull }) {
const x = [];
if (isFalse(objIsNull)) {
x.push(obj.a.b);
}
return x;
}
```
While other memoization strategies with different constraints exist, the current compiler requires that `ReactiveScope.dependencies` be re-orderable to the beginning of the reactive scope. But.. `PropertyLoad`s from null values will throw `TypeError`. This means that evaluating hoisted dependencies should throw if and only if the source program throws. (It is also a bug if source throws and compiler output does not throw. See https://github.com/facebook/react-forget/pull/2709)
---
### Rough high level overview
1. Pass 1
Walk over instructions to gather every temporary used outside of its defining scope (same as ReactiveFunction version). These determine the sidemaps we produce, as temporaries used outside of their declaring scopes get promoted to named variables later (and are not considered hoistable rvals).
2. Pass 2 (collectTemporariesSidemap)
Walk over instructions to generate a sidemap of temporary identifier -> named variable and property path (e.g. `$3 -> {obj: props, path: ["a", "b"]}`)
2. Pass 2 (collectHoistablePropertyLoads)
a. Build a sidemap of block -> accessed variables and properties (e.g. `bb0 -> [ {obj: props, path: ["a", "b"]} ]`)
b. Propagate "non-nullness" i.e. variables and properties for which we can safely evaluate `PropertyLoad`.
A basic block can unconditionally read from identifier X if any of the following applies:
- the block itself reads from identifier X
- all predecessors of the block read from identifier X
- all successors of the block read from identifier X
4. Pass 3: (collectDependencies)
Walks over instructions again to record dependencies and declarations, using the previously produced sidemaps. We do not record any control-flow here
5. Merge every scope's recorded dependencies with the set of hoistable PropertyLoads
Tested by syncing internally and (1) checking compilation output differences ([internal link](https://www.internalfb.com/intern/everpaste/?handle=GPCfUBt_HCoy_S4EAJDVFJyJJMR0bsIXAAAB)), running internally e2e tests ([internal link](https://fburl.com/sandcastle/cs5mlkxq))
---
### Followups:
1. Rewrite function expression deps
This change produces much more optimal output as the compiler now uses the function CFG to understand which variables / paths are assumed to be non-null. However, it may exacerbate [this function-expr hoisting bug](https://github.com/facebook/react/blob/main/compiler/packages/babel-plugin-react-compiler/src/__tests__/fixtures/compiler/bug-invalid-hoisting-functionexpr.tsx). A short term fix here is to simply call some form of `collectNonNullObjects` on every function expression to find hoistable variable / paths. In the longer term, we should refactor out `FunctionExpression.deps`.
2. Enable optional paths
(a) don't count optional load temporaries as dependencies (e.g. `collectOptionalLoadRValues(...)`).
(b) record optional paths in both collectHoistablePropertyLoads and dependency collection
ghstack-source-id: 2507f6ea751dce09ad1dccd353ae6fc7cf411582
Pull Request resolved: https://github.com/facebook/react/pull/30894
- flip `enablePropagateDepsInHIR` to off by default
- fork fixtures which produce compilation differences in #30894 to separate directory `propagate-scope-deps-hir-fork`, to be cleaned up when we remove this flag
ghstack-source-id: 7d5b8dc29788a65c272c846af9877b09fbf2cd60
Pull Request resolved: https://github.com/facebook/react/pull/30949
Adds evaluator support for a few compiler test fixtures
ghstack-source-id: 202654992a9876cea59885b54a338c908e369ddb
Pull Request resolved: https://github.com/facebook/react/pull/30948
This means that the owner of a Component rendered on the remote server
becomes the Component on this server.
Ideally we'd support this for the Client side too. In particular Fiber
but currently ReactComponentInfo's owner is typed as only supporting
other ReactComponentInfo and it's a bigger lift to support that.
This is only in the same experimental exports as `resume`. Useful with
Postpone/Halt.
We already have `prerender()` to create a partial tree with postponed
state. We also have `resume()` to dynamically resume such a tree.
This lets you do a new prerender by resuming an already existing
postponed state. Basically creating a chain of preludes. The next
prelude would include the scripts to patch up the document.
This mostly just works since both prerender and resume are already
implemented using the same code so we just enable both at the root. I'm
sure we'll find some edge cases since this wasn't considered when it was
first written but so far I've only found an unrelated existing bug with
`keyPath` fixed here.
The current state is that `rendererInterface`, which contains all the
backend logic, like generating component stack or attaching errors to
fibers, or traversing the Fiber tree, ..., is only mounted after the
Frontend is created.
For browser extension, this means that we don't patch console or track
errors and warnings before Chrome DevTools is opened.
With these changes, `rendererInterface` is created right after
`renderer` is injected from React via global hook object (e. g.
`__REACT_DEVTOOLS_GLOBAL_HOOK__.inject(...)`.
Because of the current implementation, in case of multiple Reacts on the
page, all of them will patch the console independently. This will be
fixed in one of the next PRs, where I am moving console patching to the
global Hook.
This change of course makes `hook.js` script bigger, but I think it is a
reasonable trade-off for better DevX. We later can add more heuristics
to optimize the performance (if necessary) of `rendererInterface` for
cases when Frontend was connected late and Backend is attempting to
flush out too many recorded operations.
This essentially reverts https://github.com/facebook/react/pull/26563.
When a component suspends and is replaced by a fallback, we should start
prerendering the fallback immediately, even before any new data is
received. During the retry, we can enter prerender mode directly if
we're sure that no new data was received since we last attempted to
render the boundary.
To do this, when completing the fallback, we leave behind a pending
retry lane on the Suspense boundary. Previously we only did this once a
promise resolved, but by assigning a lane during the complete phase, we
will know that there's speculative work to be done.
Then, upon committing the fallback, we mark the retry lane as suspended
— but only if nothing was pinged or updated in the meantime. That allows
us to immediately enter prerender mode (i.e. render without skipping any
siblings) when performing the retry.
We added enough fields to need a constructor instead of inline object in
V8.
We didn't update the resumeRequest path though so it wasn't using the
constructor and had a different hidden class.
Both for browser extension, and for React Native (as part of
`react-devtools-core`) `Store` is initialized before the Backend (and
`Agent` as a part of it):
bac33d1f82/packages/react-devtools-extensions/src/main/index.js (L111-L113)
Any messages that we send from `Store`'s constructor are ignored,
because there is nothing on the other end yet. With these changes,
`Agent` will send `backendInitialized` message to `Store`, after which
`getBackendVersion` and other events will be sent.
Note that `isBackendStorageAPISupported` and `isSynchronousXHRSupported`
are still sent from `Agent`'s constructor, because we don't explicitly
ask for it from `Store`, but these are used.
This the pre-requisite for fetching settings and unsupported renderers
reliably from the Frontend.
This is important if the lazy is at the root of the chunk. I don't have
a unit test for it but @gnoff has a repro.
It also shouldn't unwrap the last value since that's the one we're
referencing.
This was already done correctly by @unstubbable in waitForReference so
this just aligns with that.
If something suspends in the shell — i.e. we won't replace the suspended
content with a fallback — we might as well prerender the siblings during
the current render pass, instead of spawning a separate prerender pass.
This is implemented by setting the "is prerendering" flag to true
whenever we suspend in the shell. But only if we haven't already skipped
over some siblings, because if so, then we need to schedule a separate
prerender pass regardless.
Alternative to #30868. The goal is to ensure that the types coming out of moduleTypeProvider are valid wrt to hook typing. If something is named like a hook, then it must be typed as a hook (or don't type it).
ghstack-source-id: 3e8b5a0a7010d0c484bbb417fb258e76bf4e32bc
Pull Request resolved: https://github.com/facebook/react/pull/30888
Make `onErrorOrWarning` and `getComponentStack` part of
`rendererInterface`. By doing this, they will be available from the
global hook `rendererInterfaces` Map. This makes them available to be
used by Hook, which soon will be the only one who is doing console
patching.
This is also a pre-requisite for removing `registerRenderer`:
d160aa0fbb/packages/react-devtools-shared/src/backend/console.js (L113-L121)
This adds owner stacks to replayed Server Component logs in environments
that don't support native console.createTask.
<img width="521" alt="Screenshot 2024-09-09 at 8 55 21 PM"
src="https://github.com/user-attachments/assets/261cfaee-ea65-4044-abf0-c41abf358fea">
It also tracks the logs in the global componentInfoToComponentLogsMap
which lets us associate those logs with Server Components when they
later commit into the fiber tree.
<img width="1280" alt="Screenshot 2024-09-09 at 9 31 16 PM"
src="https://github.com/user-attachments/assets/436312a6-f9f4-4add-8129-0fb9b9eb18ee">
I tried to create unit tests for this since it's now wired up
end-to-end. Unfortunately, the complicated testing set up for Flight
requires a complex set of resetting modules which are incompatible with
the complicated test setup in getVersionedRenderImplementation for
DevTools tests.
This reverts #19603.
Before:
<img width="724" alt="Screenshot 2024-08-28 at 12 07 29 AM"
src="https://github.com/user-attachments/assets/0613088f-c013-4f1c-92c3-fbdae8c1f109">
After:
<img width="771" alt="Screenshot 2024-08-28 at 12 08 13 AM"
src="https://github.com/user-attachments/assets/eef21bee-d11f-4f0a-9147-053a163f720f">
Consensus seems to be that while the purple on is a bit clearer and
easier to read. The purple is not on brand so it doesn't look like
React. It looks ugly. It's distracting (too eye catching). Taking away
attention from other tabs in an unfair way.
It also gets worse with more tabs added. We plan on both adding another
tab and panes inside other tabs (elements/sources) soon. Each needs to
be marked somehow as part of React but spelling it out is too long.
Putting inside a second tab means two clicks and takes away real-estate
from our extension and doesn't solve the problem with extension panes in
other tabs. We also plan on adding multiple different tracks to the
Performance tab which also needs a name other than just React and
spelling out React as a prefix is too long. The Emoji is too
distracting. So it seems best to uniformly apply the symbol - albeit it
might just look like a dot to many.
Dark mode looks close to on brand:
<img width="1089" alt="Screenshot 2024-08-28 at 12 32 50 AM"
src="https://github.com/user-attachments/assets/7175a540-4241-4c26-9e4d-4d367873af57">
Any time we're creating a stack trace we should have a
react-stack-bottom-frame so we know what to filter out.
This is the same thing we already do for createFakeJSXCallStackInDEV but
we should do that when replaying logs too.
The console instrumentation should not know about things like Fibers.
Only the renderer bindings should know about that stuff. We can improve
the layering by just moving all that stuff behind a `getComponentStack`
helper that gets injected by the renderer.
This sets us up for the Flight renderer #30906 to have its own
implementation of this function.
Stacked on #30899.
This adds another map to store Server Components logs. When they're
replayed with an owner we can associate them with a DevToolsInstance.
The replaying should happen before they can mount in Fiber so they'll
always have all logs when they mount. There can be more than one
Instance associated with any particular ReactComponentInfo. It can also
be unmounted and restored later.
One thing that's interesting about these is that when a Server Component
tree refreshes a new set of ReactComponentInfo will update through the
tree and the VirtualInstances will update with new instances. This means
that the old errors/warnings are no longer associated with the
VirtualInstance. I.e. it's not continually appended like updates do for
Fiber backed instances. On the client we dedupe errors/warnings for the
life time of the page. On the server that doesn't work well because it
would mean that when you refresh the page, you miss out on warnings so
we dedupe them per request instead. If we just appended on refresh it
would keep adding them.
If ever add a deduping mechanism that spans longer than a request, we
might need to do more of a merge when these updates.
Nothing actually adds logs to this map yet. That will need an
integration with Flight in a follow up.
Stacked on #30906.
Injects the Flight Client into the DevTools hook if it `supportsFlight`.
This only injects in DEV. We could inject it in prod too but so far the
only feature this exposes is only available in DEV anyway. I also only
call `injectIntoDevTools` in the browser builds since we don't really
support DevTools on the server anyway.
The main purpose of this for now is so that DevTools can track the
Server Component owner of replayed logs. This lets us add owner stacks
where `console.createTask` is not natively supported (like Firefox). It
also lets us associate the log with the Server Component in the
Component tree #30905.
This represents a virtual renderer that connects to the Flight Client.
It's virtual in the sense that the actual rendering has already happened
on the server. The Flight Client parses the result. Most of the result
then end up in objects that render into another renderer and that's how
we see most Server Components in DevTools. As part of the client's tree.
However, some things are side-effects that don't really connect to any
particular client renderer. For example preloads() and logs. For those
we need to treat the Flight Client as if it was its own renderer just
like a Fiber renderer or even legacy renderer. We really could support
Fizz and Flight Server as DevTools targets too for example to connect it
to the backend but there's just not much demand for that.
This will initially only be used to track the owners of replayed console
logs but could be expanded to more. For example to send controls to
start profiling on the server. It could also be expanded to build an RSC
payload inspector that is automatically connected.
We can simplify this tracking by not having a separate pending set of
logs and the logs tracked per instance and instead we just track the
logs per Fiber. This avoids the need to move it back into the pending
set after unmounts in case a Fiber is reparented.
The main motivation for this is to unify with an upcoming tracking of
logs for Server Components. For those it doesn't make sense to move them
into a per instance set and because the same Server Component - and its
logs - may appear more than once. So no particular instance should steal
it.
The second part of this change is that instead of looking up the
instance from fiber, which requires the fiberToFiberInstanceMap, we
instead look up if a component has any new logs when we traverse it in
the commit phase. After all for a component to have had a log it must
have updated. This is a similar technique to #30897. This technique also
works for Server Components without having to maintain a one to many
relationship from ComponentInfo to VirtualInstance. So it unifies them.
Normally this look up would be fast since the `fiberToComponentsLogs`
set would be empty and so doesn't add any significant weight to the
commit phase. If there's a ton of logs on many different components then
it's not great since it would slow down the commit phase but that's not
what we expect to see so in typical usage, this is better.
There is an unfortunate consequence though which is that
`console.warn/error` in passive effects (i.e. `useEffect`) wouldn't be
picked up because currently we traverse the logs in
`handleCommitFiberRoot` which is too early. If we moved that to
`handlePostCommitFiberRoot` this wouldn't be a problem. In the meantime,
I just detect this and do a brute force flush by walking all mounted
instances if there's a `console.warn/error` inside a passive effect.
If we ever add "owners" to event handlers that are triggered outside the
render/commit phases (like `<div onClick={...}>`) and we want to
associate error/warnings in those, we'd need a different technique to
ensure those get flushed in time.
## Summary
This PR bumps Flow all the way to the latest 0.245.2.
Most of the suppressions comes from Flow v0.239.0's change to include
undefined in the return of `Array.pop`.
I also enabled `react.custom_jsx_typing=true` and added custom jsx
typing to match the old behavior that `React.createElement` is
effectively any typed. This is necessary since various builtin
components like `React.Fragment` is actually symbol in the React repo
instead of `React.AbstractComponent<...>`. It can be made more accurate
by customizing the `React$CustomJSXFactory` type, but I will leave it to
the React team to decide.
## How did you test this change?
`yarn flow` for all the renderers
Stacked on #30896.
The problem with the `getUpdatersList` function is that it iterates over
Fibers and then looks up each of those Fibers in the
fiberToFiberInstanceMap which we ideally could get rid of.
However, every time an updater comes into play for a commit it must mean
that something below the updater itself updated and so the updater will
also be cloned which means we'll pass it on the way down when traversing
the tree in the commit.
When we do this traversal, we can just look if the Fiber is in the
updater set and if so add it to the updater list as we go.
When Context change tracking was added to support modern Context it
relied on the "memoizedValue" to read the current value. This only works
in React 18+ when it was added to support Lazy Context Propagation.
However, the backend stored the old value the same way it used to work
for legacy Context in a global map. This was unnecessary since we *also*
have the old value on the previous Fiber.
This removes all the costly tracking of previous values for every Fiber
that uses Contexts slowing down profiling. Instead, we just compare the
Contexts from
The downside is that this no longer supports detecting changes due to
legacy Context because it doesn't have a similar "previous" value.
However, legacy Context has long been deprecated and is completely
removed in 19. So I don't think it's worth supporting since you have to
be on an old version *and* actually use legacy Context *and* trying to
profile something that updates it. Which btw, updating legacy contexts
only worked at all from 16 something when we made updates work. So it
was unusual even in the slight gap where you could and before you had
migrated to modern Context introduced in 16.3.
Ideally we shouldn't use the `.alternate` to access previous state
because ideally Fibers shouldn't have alternates.
The only case it's ok to use it is when it is used to identity the
stateful part of a component's identity. In a non-alternate Fiber model
there would instead be another object that represents instance but in
the current model it's modeled by the pair.
It's not ok is to get the previous state of the tree since that would
not live on the stateful part.
We don't generally need this though because we have the previous state
on instance.data before updating it, or passed from above.
While looking at the Context tracking implementation for other reasons I
noticed this bug.
Originally it wasn't allowed to have conditional `useContext(context)`
(although we did because it's technically possible). With `use(context)`
it is officially allowed to be conditional as long as it is within a
Hook/Component and not within a try/catch.
This means that this loop comparing previous and next contexts need to
consider that the Context objects might not line up and so it's possibly
comparing apples to oranges. We already bailed if one was longer than
the other.
If the order of contexts changes later in the component that means
something else must have already changed earlier so the reason for the
rerender isn't the context so we can just return false in that case.
Fixes the bug that @alexmckenley and @mofeiZ found where setState-in-render can reset useMemoCache and cause an infinite loop. The bug was that renderWithHooksAgain() was not resetting hook state when rerendering (so useMemo values were preserved) but was resetting the updateQueue. This meant that the entire memo cache was cleared on a setState-in-render.
The fix here is to call a new helper function to clear the update queue. It nulls out other properties, but for memoCache it just sets the index back to zero.
ghstack-source-id: fc0947ce219334117075df6a4e33b39975af2bc4
Pull Request resolved: https://github.com/facebook/react/pull/30889
Reactive scopes in HIR has been stable for over 3 months now and is the future direction of react compiler, removing this flag to reduce implementation forks.
ghstack-source-id: 65cdf63cf7
Pull Request resolved: https://github.com/facebook/react/pull/30891
Stacked on #30881.
Move `runWithFiberInDEV` from the recursive part of the commit phase and
instead wrap each call into user space. These should really map 1:1 with
where we're using `try/catch` since that's where we're calling into user
space.
The goal of this is to avoid the extra stack frames added by
`enableOwnerStacks` in the recursive parts to avoid stack overflow. This
way we only have a couple of extra at the end of the stack instead of a
couple of extra at every depth of the tree.
This is mostly just moves and same code extracted into utility
functions.
This is to help clarify what needs to be wrapped in try/catch and
runWithFiberInDEV. I'll do the runWithFiberInDEV changes in a follow up.
This leaves ReactCommitWork mostly to do matching on the tag and the
recursive loops.
First, this basically reverts
1f3892ef8c
to use a Map/Set to track what is forced to suspend/error again instead
of flags on the Instance. The difference is that now the key in the
Fiber itself instead of the ID. Critically this avoids the
fiberToFiberInstance map to look up whether or not a Fiber should be
forced to suspend when asked by the renderer.
This also allows us to force suspend/error on filtered instances. It's a
bit unclear what should happen when you try to Suspend or Error a child
but its parent boundary is filtered. It was also inconsistent between
Suspense and Error due to how they were implemented.
I think conceptually you're trying to simulate what would happen if that
Component errored or suspended so it would be misleading if we triggered
a different boundary than would happen in real life. So I think we
should trigger the nearest unfiltered Fiber, not the nearest Instance.
The consequence of this however is that if this instance was filtered,
there's no way to undo it without refreshing or removing the filter.
This is an edge case though since it's unusual you'd filter these in the
first place.
It used to be that Suspense walked the store in the frontend and Error
walked the Fibers in the backend. They also did this somewhat eagerly.
This simplifies and unifies the model by passing the id of what you
clicked in the frontend and then we walk the Fiber tree from there in
the backend to lazily find the boundary. However I also eagerly walk the
tree at first to find whether we have any Suspense or Error boundary
parents at all so we can hide the buttons if not.
This also implements it to work with VirtualInstances using #30865. I
find the nearest Fiber Instance downwards filtered or otherwise. Then
from its parent we find the nearest Error or Suspense boundary. That's
because VirtualInstance will always have their inner Fiber as an
Instance but they might not have their parent since it might be
filtered. Which would potentially cause us to skip over a filtered
parent Suspense boundary.
When we filter Fiber Instances where have no way to recover our position
in the Fiber tree. The extreme form of this is if you filter out all the
Fibers and keep only Server Components.
This affects operations that are performed against fibers such as
collecting Host Instances for highlighting or emulating
suspending/erroring.
Conceptually we don't need to add this into the DevToolsInstance tree
because we only need to get to some Fibers from a VirtualInstance. A
Virtual Instance can contain more than one conceptual child Fiber. It
would be easier if we didn't include them in the tree on one hand
because we could just traverse the tree and assume it looks like the one
on the frontend. But it's also tricky to manage the lifetime. So I went
with a special FilteredFiberInstance node in the tree.
Currently I only add it if its parent would've been a VirtualInstance
since we don't need it in any other cases. If the parent was another
FiberInstance it already has a Fiber.
There might be need for always tracking all Instances whether they're
filtered or not or just moving filtering to the frontend but for now I'm
keeping the general architecture as is.
At Meta we have a pattern of using tagged template literals for features that are compiled away:
```
// Relay:
graphql`...graphql text...`
```
In many cases these tags produce a primitive value, and we can get even more optimal output if we can tell the compiler about these types. The new moduleTypeProvider gives us the ability to declare such types, this PR extends the compiler to use this type information for TaggedTemplateExpression values.
ghstack-source-id: 3cd6511b7f
Pull Request resolved: https://github.com/facebook/react/pull/30869
Adds the concept of a "prerender". These special renders are spawned
whenever something suspends (and we're not already prerendering).
The purpose is to move speculative rendering work into a separate phase
that does not block the UI from updating. For example, during a
transition, if something suspends, we should not speculatively prerender
siblings that will be replaced by a fallback in the UI until *after* the
fallback has been shown to the user.
### Based on
- #30761
- #30759
---
`use` has an optimization where in some cases it can suspend the work
loop during the render phase until the data has resolved, rather than
unwind the stack and lose context. However, the current implementation
is not compatible with sibling prerendering. So I've temporarily
disabled it until the sibling prerendering has been refactored. We will
add it back in a later step.
This lets us get from a HostInstance to the nearest DevToolsInstance
without relying on `findFiberByHostInstance` and
`fiberToDevToolsInstanceMap`. We already did the equivalent of this for
Resources in HostHoistables.
One issue before was that we'd ideally get away from the
`fiberToDevToolsInstanceMap` map in general since we should ideally not
treat Fibers as stateful but they could be replaced by something else
stateful in principle.
This PR also addresses Virtual Instances. Now you can select a DOM node
and have it select a Virtual Instance if that's the nearest parent since
the parent doesn't have to be a Fiber anymore.
However, the other reason for this change is that I'd like to get rid of
the need for the `findFiberByHostInstance` from being injected. A
renderer should not need to store a reference back from its instance to
a Fiber. Without the Synthetic Event system this wouldn't be needed by
the renderer so we should be able to remove it. We also don't really
need it since we have all the information by just walking the commit to
collect the nodes if we just maintain our own Map.
There's one subtle nuance that the different renderers do. Typically a
HostInstance is the same thing as a PublicInstance in React but
technically in Fabric they're not the same. So we need to translate
between PublicInstance and HostInstance. I just hardcoded the Fabric
implementation of this since it's the only known one that does this but
could feature detect other ones too if necessary. On one hand it's more
resilient to refactors to not rely on injected helpers and on hand it
doesn't follow changes to things like this.
For the conflict resolution I added in #30494 I had to make that
specific to DOM so we can move the DOM traversal to the backend instead
of the injected helper.
This lets us track what a Component might suspend on from DevTools. We
could already collect this by replaying a component's Hooks but that
would be expensive to collect from a whole tree.
The thenables themselves might contain useful information but mainly
we'd want access to the `_debugInfo` on the thenables which might
contain additional information from the server.
19bd26beb6/packages/shared/ReactTypes.js (L114)
In a follow up we should really do something similar in Flight to
transfer `use()` on the debugInfo of that Server Component.
This lets us highlight Server Components.
However, there is a problem with this because if the actual nearest
Fiber is filtered, there's no FiberInstance and so we might skip past it
and maybe never find a child while walking the whole tree. This is very
common in the case where you have just Server Components and Host
Components which are filtered by default.
Note how the DOM nodes that are just plain host instances without client
component wrappers are not highlighted here:
<img width="1102" alt="Screenshot 2024-08-30 at 4 33 55 PM"
src="https://github.com/user-attachments/assets/c9a7b91e-5faf-4c60-99a8-1195539ff8b5">
Fixing that needs a separate refactor though and related to several
other features that already have a similar issue without
VirtualInstances like Suspense/Error Boundaries (triggering
suspense/error on a filtered Suspense/ErrorBoundary doesn't work
correctly). So this first PR just adds the feature for the common case
where there's at least some Fibers.
Stacked on #30842.
This adds a filter to be able to exclude Components from a certain
environment. Default to Client or Server.
The available options are computed into a dropdown based on the names
that are currently used on the page (or an option that were previously
used). In addition to the hardcoded "Client". Meaning that if you have
Server Components on the page you see "Server" or "Client" as possible
options but it can be anything if there are multiple RSC environments on
the page.
"Client" in this case means Function and Class Components in Fiber -
excluding built-ins.
If a Server Component has two environments (primary and secondary) then
both have to be filtered to exclude it.
We don't show the option at all if there are no Server Components used
in the page to avoid confusing existing users that are just using Client
Components and wouldn't know the difference between Server vs Client.
<img width="815" alt="Screenshot 2024-08-30 at 12 56 42 AM"
src="https://github.com/user-attachments/assets/e06b225a-e85d-4cdc-8707-d4630fede19e">
To recap. This only affects DEV and RSC. It patches console on the
server in DEV (similar to how React DevTools already does and what we
did for the double logging). Then replays those logs with a `[Server]`
badge on the client so you don't need a server terminal open.
This has been on for over 6 months now in our experimental channel and
we've had a lot of coverage in Next.js due to various experimental flags
like taint and ppr.
It's non-invasive in that even if something throws we just serialize
that as an unknown value.
The main feedback we've gotten was:
- The serialization depth wasn't deep enough which I addressed in #30294
and haven't really had any issues since. This could still be an issue or
the inverse that you serialize too many logs that are also too deep.
This is not so much an issue with intentional logging and things like
accidental errors don't typically have unbounded arguments (e.g. React
errors are always string arguments). The ideal would be some way to
retain objects and then load them on-demand but that needs more
plumbing. Which can be later.
- The other was that double logging on the server is annoying if the
same terminal does both the RSC render and SSR render which was
addressed in #30207. It is now off by default in node/edge-builds of the
client, on by default in browser builds. With the `replayConsole` option
to either opt-in or out.
We've reached a good spot now I think.
These are better with `enableOwnerStacks` but that's a separate track
and not needed.
The only thing to document here, other than maybe that we're doing it,
is the `replayConsole` option but that's part of the RSC renderers that
themselves are not documented so nowhere to document it.
Related - https://github.com/facebook/react/pull/30407.
This is experimental-only and FB-only hook. Without these changes,
inspecting an element that is using this hook will throw an error,
because this hook is missing in Dispatcher implementation from React
DevTools, which overrides the original one to build the hook tree.

One nice thing from it is that in case of any potential regressions
related to this experiment, we can quickly triage which implementation
of `useContext` is used by inspecting an element in React DevTools.
Ideally, I should've added some component that is using this hook to
`react-devtools-shell`, so it can be manually tested, but I can't do it
without rewriting the infra for it. This is because this hook is only
available from fb-www builds, and not experimental.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
When debugging applications that are experiencing runaway re-rendering,
it is helpful to profile them in the React Developer Tools.
Unfortunately there is a size limit on the captured profile which can
make them impossible to inspect or save. The limitations I have found
are in `postMessage` for the Chrome extension and in the `ws` websocket
server for the standalone app.
Profiling an app that produces a large profile artifact will simply show
that no profiling data was captured and output an error in the console,
here shown for the standalone app:
```text
standalone.js:92 [React DevTools] Error with websocket connection i {target: H, type: 'error', message: 'Max payload size exceeded', error: RangeError: Max payload size exceeded
at e.exports.haveLength (/Users/rune/.npm/_npx/8ea6ac5c50…}error: RangeError: Max payload size exceeded
```
This change simply increases the max payload of the websocket server in
the standalone app so that larger profiles may be captured and
inspected.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
I verified that I could capture and inspect profiling data that
previously exceeded the default limitation for a particular app
Support filtering Virtual Instances with existing filters.
Server Components are considered "Functions".
In a follow up I'll a new filter for "Environment" which will let you
filter by Client vs Server (and more).
This appends a (filtered) virtual instance path at the end of the fiber
path. If a virtual instance is selected inside the fiber.
The main part of the path is still just the fiber path since that's the
semantically stateful part. Then we just tack on a few virtual path
frames at the end if we're currently selecting a specific Server
Component within the nearest Fiber.
I also took the opportunity to fix a bug which caused selections inside
Suspense boundaries to not be tracked.
Firefox [finally supports
`ExecutionWorld.MAIN`](https://bugzilla.mozilla.org/show_bug.cgi?id=1736575)
in content scripts, which means we can migrate the browser extension to
Manifest V3.
This PR also removes a bunch of no longer required explicit branching
for Firefox case, when we are using Manifest V3-only APIs.
We are also removing XMLHttpRequest injection, which is no longer needed
and restricted in Manifest V3. The new standardized approach (same as in
Chromium) doesn't violate CSP rules, which means that extension can
finally be used for apps running in production mode.
To prevent any difference in behavior, we check that the optionality of the inferred deps exactly matches the optionality of the manual dependencies. This required a fix, I was incorrectly inferring optionality of manual deps (they're only optional if OptionalTerminal.optional is true) - for nested cases of mixed optional/non-optional.
ghstack-source-id: afd49e89cc
Pull Request resolved: https://github.com/facebook/react/pull/30840
Per title. This gives us much more granular memoization when the source used optional member expressions. Note that we only infer optional deps when the source used optionals: we don't (yet) infer optional dependencies from conditionals.
ghstack-source-id: 104d0b712d
Pull Request resolved: https://github.com/facebook/react/pull/30838
Handles an additional case as part of testing combinations of the same path being accessed in different places with different segments as optional/unconditional.
ghstack-source-id: ace777fcbb
Pull Request resolved: https://github.com/facebook/react/pull/30836
Updates PropagateScopeDeps and DeriveMinimalDeps to understand optional dependency paths (`a?.b`). There a few key pieces to this:
In PropagateScopeDeps we jump through some hoops to work around the awkward structure of nested OptionalExpressions. This is much easier in HIR form, but I managed to get this pretty close and i think it will be landable with further cleanup. A good chunk of this is avoiding prematurely registering a value as a dependency - there are a bunch of indirections in the ReactiveFunction structure:
```
t0 = OptionalExpression
SequenceExpression
t0 = Sequence
...
LoadLocal t0
```
Where if at any point we call `visitOperand()` we'll prematurely register a dependency instead of declareProperty(). The other bit is that optionals can be optional=false for nested member expressions where not all the parts are actually optional (`foo.bar?.bar.call()`). And of course, parts of an optional chain can still be conditional even when optional=true (for example the `x` in `foo.bar?.[x]?.baz`). Not all of this is tested yet so there are likely bugs still.
The other bit is DeriveMinimalDeps, which is thankfully easier. We add OptionalAccess and OptionalDep and update the merge and reducing logic for these cases. There is probably still more to update though, for things like merging subtrees. There are a lot of ternaries that assume a result can be exactly one of two states (conditional/unconditional, dependency/access) and these assumptions don't hold anymore. I'd like to refactor to dependency/access separate from conditional/optional/unconditional. Also, the reducing logic isn't quite right: once a child is optional we keep inferring all the parents as optional too, losing some precision. I need to adjust the reducing logic to let children decide whether their path token is optional or not.
ghstack-source-id: 207842ac64
Pull Request resolved: https://github.com/facebook/react/pull/30819
If the inferred deps are more precise (non-optional) than the manual deps (optional) it should pass validation.
The other direction also seems like it would be fine - inferring optional deps when the original was non-optional - but for now let's keep the "at least as precise" rule.
ghstack-source-id: 9f7a99ee5f
Pull Request resolved: https://github.com/facebook/react/pull/30816
Branch terminals didn't have a fallthrough because they correspond to an outer terminal (optional, logical, etc) that has the "real" fallthrough. But understanding how branch terminals correspond to these outer terminals requires knowing the branch fallthrough. For example, `foo?.bar?.baz` creates terminals along the lines of:
```
bb0:
optional fallthrough=bb4
bb1:
optional fallthrough=bb3
bb2:
...
branch ... (fallthrough=bb3)
...
bb3:
...
branch ... (fallthrough=bb4)
...
bb4:
...
```
Without a fallthrough on `branch` terminals, it's unclear that the optional from bb0 has its branch node in bb3. With the fallthroughs, we can see look for a branch with the same fallthrough as the outer optional terminal to match them up.
ghstack-source-id: d48c623289
Pull Request resolved: https://github.com/facebook/react/pull/30814
Adds an `optional: boolean` property to each token in a DependencyPath, currently always set to false. Also updates the equality and printing logic for paths to account for this field.
Subsequent PRs will update our logic to determine which manual dependencies were optional, then we can start inferring optional deps as well.
ghstack-source-id: 66c2da2cfa
Pull Request resolved: https://github.com/facebook/react/pull/30813
Previously the path of a ReactiveScopeDependency was `Array<string>`. We need to track whether each property access is optional or not, so as a first step we change this to `Array<{property: string}>`, making space for an additional property in a subsequent PR.
ghstack-source-id: c5d38d72f6
Pull Request resolved: https://github.com/facebook/react/pull/30812
AnalyzeFunctions was reusing the `ReactiveScopeDependency` type since it happened to have a convenient shape, but we need to change this type to represent optionality. We now use a locally defined type instead.
ghstack-source-id: e305c6ede4
Pull Request resolved: https://github.com/facebook/react/pull/30811
Summary:
This addresses the issue of the compiler being overly restrictive about refs escaping into object expressions. Rather than erroring whenever a ref flows into an object, we will now treat the object itself as a ref, and apply the same escape rules to it. Whenever we look up a property from a ref value, we now don't know whether that value is itself a ref or a ref value, so we assume it's both.
The same logic applies to ref-accessing functions--if such a function is stored in an object, we'll propagate that property to the object itself and any properties looked up from it.
ghstack-source-id: 5c6fcb895d4a1658ce9dddec286aad3a57a4c9f1
Pull Request resolved: https://github.com/facebook/react/pull/30821
Summary:
We currently can return a ref from a hook but not an object containing a ref.
ghstack-source-id: 8b1de4991eb2731b7f758e685ba62d9f07d584b2
Pull Request resolved: https://github.com/facebook/react/pull/30820
If we see the "Maximum call stack size exceeded" error we know we've hit
stack overflow. We can recover from this by spawning a new task and
trying again. Effectively a zero-cost trampoline in the normal case. The
new task will have a clean stack. If you have a lot of siblings at the
same depth that hits the limit you can end up hitting this once for each
sibling but within that new sibling you're unlikely to hit this again.
So it's not too expensive.
If it errors again in the retryTask pass, the other error handling takes
over which causes this to be able to still not infinitely stall. E.g.
when the component itself throws an error like this.
It's still better to increase the stack limit for performance if you
have a really deep tree but it doesn't really hurt to be able to recover
since it's zero cost when it doesn't happen.
We could do the same thing for Flight. Those trees don't tend to be as
deep but could happen.
This loops over the remainingReconcilingChildren to find existing
FiberInstances that match the updated Fiber. This is the same thing we
already do for virtual instances. This avoids the need for a
`fiberToFiberInstanceMap`.
This loop is fast but there is a downside when the children set is very
large and gets reordered with keys since we might have to loop over the
set multiple times to get to the instances in the bottom. If that
becomes a problem we can optimize it the same way ReactChildFiber does
which is to create a temporary Map only when the children don't line up
properly. That way everything except the first pass can use the Map but
there's no need to create it eagerly.
Now that we have the loop we don't need the previousSibling field so we
can save some memory there.
These don't have their own time since they don't take up any time to
render but they show up in the tree for context. However they never
render themselves. Their base tree time is the base time of their
children. This way they take up the same space as their combined
children in the Profiler tree. (Instead of leaving a blank line which
they did before this PR.)
The frontend doesn't track the difference between a virtual instance and
a Fiber that didn't render this update. This might be a bit confusing as
to why it didn't render. I add the word "client" to make it a bit
clearer and works for both. We should probably have different verbiage
here based on it is a Server Component or something else.
<img width="1103" alt="Screenshot 2024-08-26 at 5 00 47 PM"
src="https://github.com/user-attachments/assets/87b811d4-7024-466a-845d-542493ed3ca2">
I also took the opportunity to remove idToTreeBaseDurationMap and
idToRootMap maps. Cloning the Map isn't really all that super fast
anyway and it means we have to maintain the map continuously as we
render. Instead, we can track it on the instances and then walk the
instances to create a snapshot when starting to profile. This isn't as
fast but really fast too and requires less bookkeeping while rendering
instead which is more sensitive than that one snapshot in the beginning.
## Summary
suspenseCallback feature has proved to be useful for FB Web. Let's look
at enabling the feature for the React Native build.
## How did you test this change?
Will sync the react changes with a React Native build and will verify
that performance logging is correctly notified of suspense promises
during the suspense callback.
We don't have the source location of Server Components on the client
because we don't want to eagerly do the throw trick for all Server
Components just in case. Unfortunately Node.js doesn't expose V8's API
to get a source location of a function.
We do have the owner stacks of the JSX that created it though and at
some point we'll also show that location in DevTools.
However, the realization is that if a Server Component is the owner of
any child. The owner stack of that child will have the owner component's
source location as its bottom stack frame.
The technique I'm implementing here is to track whenever a child mounts
we already have its owner. We track the first discovered owned child's
stack on the owner. Then when we ask for a Source location of the owner
do we parse that stack and extract the location of the bottom frame.
This doesn't give us a location necessarily in the top of the function
but somewhere in the function.
In this case the first owned child is the Container:
<img width="1107" alt="Screenshot 2024-08-22 at 10 24 42 PM"
src="https://github.com/user-attachments/assets/95f32850-24a5-4151-8ce6-b7b89db68aee">
<img width="648" alt="Screenshot 2024-08-22 at 10 24 20 PM"
src="https://github.com/user-attachments/assets/4bcba033-866f-4684-9beb-de09d189deff">
We can even use this technique for Fibers too. Currently I use this as a
fallback in case the error technique didn't work. This covers a case
where nothing errors but you still render a child. This case is actually
quite common:
```
function Foo() {
return <Bar />;
}
```
However, for Fibers we could really just use the `inspect(function)`
technique which works for all cases. At least in Chrome.
Unfortunately, this technique doesn't work if a Component doesn't create
any new JSX but just renders its children. It also currently doesn't
work if the child is filtered since I only look up the owner if an
instance is not filtered. This means that the container in the fixture
can't view source by default since the host component is filtered:
```
export default function Container({children}) {
return <div>{children}</div>;
}
```
<img width="1107" alt="Screenshot 2024-08-22 at 10 24 35 PM"
src="https://github.com/user-attachments/assets/c3f8f9c5-5add-4d35-9290-3a5079e82adc">
I noticed that there is a delay due to the inspection being split into
one part that gets the attribute and another eval that does the
inspection. This is a bit hacky and uses temporary global names that are
leaky. The timeout was presumably to ensure that the first step had
fully propagated but it's slow. As we've learned, it can be throttled,
and it isn't a guarantee either way.
Instead, we can just consolidate these into a single operation that
by-passes the bridge and goes straight to the renderer interface from
the eval.
I did the same for the viewElementSource helper even though that's not
currently in use since #28471 but I think we probably should return to
that technique when it's available since it's more reliable than the
throw - at least in Chrome. I'm not sure about the status of React
Native here. In Firefox, inspecting a function with source maps doesn't
seem to work. It doesn't jump to original code.
This allows us to handle common operations such as `useFragment(...).edges.nodes ?? []` where we have a `Phi(MixedReadonly, Array)`. The underlying pattern remains general-purpose and not Relay-specific, and any API that returns transitively "mixed" data (primitives, arrays, plain objects) can benefit from the same type refinement.
ghstack-source-id: 5128310894
Pull Request resolved: https://github.com/facebook/react/pull/30797
Redo of an earlier (pre-OSS) PR to infer types of phi nodes. There are a few pieces to this:
1. Update InferTypes to infer the type of `phi.id.type`, not the unused `phi.type`.
2. Update the algorithm to verify that all the phi types are actually equal, not just have the same kind.
3. Handle circular types by removing the cycle.
However, that reveals another issue: InferMutableRanges currently infers the results of `Store` effects _after_ its fixpoint loop. That was fine when a Store could never occur on a phi (since they wouldn't have a type to get a function signature from). Now though, we can have Store effects occur on phis, and we need to ensure that this correctly updates the mutable range of the phi operands - recursively. See new test that fails without the fixpoint loop.
ghstack-source-id: 2e1b02844d
Pull Request resolved: https://github.com/facebook/react/pull/30796
This is a complex case: we not only need phi type inference but also need to be able infer the union of `MixedReadonly | Array`.
ghstack-source-id: 935088910d
Pull Request resolved: https://github.com/facebook/react/pull/30793
This is a refactor of the fix in #27505.
When a transition update is scheduled by a popstate event, (i.e. a back/
forward navigation) we attempt to render it synchronously even though
it's a transition, since it's likely the previous page's data is cached.
In #27505, I changed the implementation so that it only "upgrades" the
priority of the transition for a single attempt. If the attempt
suspends, say because the data is not cached after all, from then on it
should be treated as a normal transition.
But it turns out #27505 did not work as intended, because it relied on
marking the root with pending synchronous work (root.pendingLanes),
which was never cleared until the popstate update completed.
The test scenarios I wrote accidentally worked for a different reason
related to suspending the work loop, which I'm currently in the middle
of refactoring.
This reverts commit b34b750729.
This hack doesn't play well internally so I'm reverting this for now
(but keeping the compilationMode override). I'll audit the locations we
report later and try to make them more accurate so we won't need this
workaround.
ghstack-source-id: b6be29c11d
Pull Request resolved: https://github.com/facebook/react/pull/30792
Currently you can jump to definition of a function by right clicking
through the context menu. However, it's pretty difficult to discover.
This makes the functions clickable to jump to definition - like links.
This uses the same styling as we do for links (which are btw only
clickable if they're not editable). Including cursor: pointer.
I added a background on hover which follows the same pattern as the
owners list.
I also dropped the ƒ prefix when displaying functions. This is a cute
short cut and there's precedence in how Chrome prints functions in the
console *if* the function's toString would've had a function prefix like
if it was a function declaration or expression. It does not do this for
arrow functions or object methods.
Elsewhere in the JS ecosystem this isn't really used anywhere. It
invites more questions than it answers.
The parenthesis and curlies are enough. There's no ambiguity here since
strings have quotations. It looks better with just its object method
form. Keeping it simple seems best. To my eyes this flows better because
I'm used to looking at function syntax but not weird "f"s.
Before:
<img width="433" alt="Screenshot 2024-08-20 at 11 55 09 PM"
src="https://github.com/user-attachments/assets/9dd50da6-598f-4291-9e24-1cdc7200dc9e">
After:
<img width="388" alt="Screenshot 2024-08-20 at 11 46 01 PM"
src="https://github.com/user-attachments/assets/dd988e14-412e-4deb-8c8c-26a54be8331f">
After (Hover):
<img width="389" alt="Screenshot 2024-08-20 at 11 46 31 PM"
src="https://github.com/user-attachments/assets/6fb4ebed-5dc1-448a-8e4d-b6d4f3903329">
Stacked on #30758 and #30755.
This is copy paste from #30755 into the ESM package. We use the
`webpack-sources` package for the source map utility but it's not
actually dependent on Webpack itself. Could probably inline it in the
build.
We don't a full Identifier object for the return type, we can just store the type.
ghstack-source-id: 4594d64ce3900ced3e461945697926489898318e
Pull Request resolved: https://github.com/facebook/react/pull/30790
Rename this field so we can use it for the actual return type.
ghstack-source-id: 118d7dcfbbcc40911bf6d13f14e70053e436738d
Pull Request resolved: https://github.com/facebook/react/pull/30789
Uses the returnIdentifier added in the previous PR to provide a stable identifier for which we can infer a return type for functions, then wires up the equations in InferTypes to infer the type.
ghstack-source-id: 22c0a9ea096daa5f72821fca2a5ff5b199f65c8b
Pull Request resolved: https://github.com/facebook/react/pull/30785
This gives us a place to store type information, used in follow-up PRs.
ghstack-source-id: ee0bfa253f63c30ccaac083b9f1f72b76617f19c
Pull Request resolved: https://github.com/facebook/react/pull/30784
If you have a function expression which _captures_ a mutable value (but does not mutate it), and that function is invoked during render, we infer the invocation as a mutation of the captured value. But in some circumstances we can prove that the captured value cannot have been mutated, and could in theory avoid inferring a mutation.
ghstack-source-id: 47664e48ce8c51a6edf4d714d1acd1ec4781df80
Pull Request resolved: https://github.com/facebook/react/pull/30783
Adds a new Environment config option which allows specifying a function that is called to resolve types of imported modules. The function is passed the name of the imported module (the RHS of the import stmt) and can return a TypeConfig, which is a recursive type of the following form:
* Object of valid identifier keys (or "*" for wildcard) and values that are TypeConfigs
* Function with various properties, whose return type is a TypeConfig
* or a reference to a builtin type using one of a small list (currently Ref, Array, MixedReadonly, Primitive)
Rather than have to eagerly supply all known types (most of which may not be used) when creating the config, this function can do so lazily. During InferTypes we call `getGlobalDeclaration()` to resolve global types. Originally this was just for known react modules, but if the new config option is passed we also call it to see if it can resolve a type. For `import {name} from 'module'` syntax, we first resolve the module type and then call `getPropertyType(moduleType, 'name')` to attempt to retrieve the property of the module (the module would obviously have to be typed as an object type for this to have a chance of yielding a result). If the module type is returned as null, or the property doesn't exist, we fall through to the original checking of whether the name was hook-like.
TODO:
* testing
* cache the results of modules so we don't have to re-parse/install their types on each LoadGlobal of the same module
* decide what to do if the module types are invalid. probably better to fatal rather than bail out, since this would indicate an invalid configuration.
ghstack-source-id: bfdbf67e3d
Pull Request resolved: https://github.com/facebook/react/pull/30771
The fixture from the previous PR was getting inconsistent behavior because of the following:
1. Create an object in a useMemo
2. Create a callback in a useCallback, where the callback captures the object from (1) into a local object, then passes that local object into a logging method. We have to assume the logging method could modify the local object, and transitively, the object from (1).
3. Call the callback during render.
4. Pass the callback to JSX.
We correctly infer that the object from (1) is captured and modified in (2). However, in (4) we transitively freeze the callback. When transitively freezing functions we were previously doing two things: updating our internal abstract model of the program values to reflect the values as being frozen *and* also updating function operands to change their effects to freeze.
As the case above demonstrates, that can clobber over information about real potential mutability. The potential fix here is to only walk our abstract value model to mark values as frozen, but _not_ override operand effects. Conceptually, this is a forward data flow propagation — but walking backward to update effects is pushing information backwards in the algorithm. An alternative would be to mark that data was propagated backwards, and trigger another loop over the CFG to propagate information forward again given the updated effects. But the fix in this PR is more correct.
ghstack-source-id: c05e716f37
Pull Request resolved: https://github.com/facebook/react/pull/30766
This fixture bails out on ValidatePreserveExistingMemo but would ideally memoize since the original memoization is safe. It's trivial to make it pass by commenting out the commented line (`LogEvent.log(() => object)`). I would expect the compiler to infer this as possible mutation of `logData`, since `object` captures a reference to `logData`. But somehow `logData` is getting memoized successfully, but we still infer the callback, `setCurrentIndex`, as having a mutable range that extends to the `setCurrentIndex()` call after the useCallback.
ghstack-source-id: 4f82e34510
Pull Request resolved: https://github.com/facebook/react/pull/30764
DevTools shouldn't use react-is since that's versioned to one version of
React. We don't need to since we use all the symbols from
shared/ReactSymbols anyway and have a fork of typeOf that can cover
both.
Now JSX of old React versions show up with proper JSX formatting when
inspecting.
These are only needed internally so I'm opting to just do it in the
commit artifacts job instead of amending the build config.
ghstack-source-id: 6a5382b028
Pull Request resolved: https://github.com/facebook/react/pull/30775
Similar to https://github.com/facebook/react/pull/30768 we want to
schedule work during prerendering in microtasks both for the root task
and pings. We continue to schedule flushes as Tasks to allow as much
work to be batched up as possible.
The unbundled form is just a way to show case a prototype for how an
unbundled version of RSC can work. It's not really intended for every
bundler combination to provide such a configuration.
There's no configuration of Turbopack that supports this mode atm and
possibly never will be since it's more of an integrated server/client
experience.
This removes the unbundled form and node register/loaders from the
turbopack build.
Follow up to #30741.
This is just for the reference Webpack implementation.
If there is a source map associated with a Node ESM loader, we generate
new source map entries for every `registerServerReference` call.
To avoid messing too much with it, this doesn't rewrite the original
mappings. It just reads them while finding each of the exports in the
original mappings. We need to read all since whatever we append at the
end is relative. Then we just generate new appended entries at the end.
For the location I picked the location of the local name identifier.
Since that's the name of the function and that gives us a source map
name index. It means it jumps to the name rather than the beginning of
the function declaration. It could be made more clever like finding a
local function definition if it is reexported. We could also point to
the line/column of the function declaration rather than the identifier
but point to the name index of the identifier name.
Now jumping to definition works in the fixture.
<img width="574" alt="Screenshot 2024-08-20 at 2 49 07 PM"
src="https://github.com/user-attachments/assets/7710f0e6-2cee-4aad-8d4c-ae985f8289eb">
Unfortunately this technique doesn't seem to work in Firefox nor Safari.
They don't apply the source map for jumping to the definition.
In https://github.com/facebook/react/pull/29491 I updated the work
scheduler for Flight to use microtasks to perform work when something
pings. This is useful but it does have some downsides in terms of our
ability to do task prioritization. Additionally the initial work is not
instantiated using a microtask which is inconsistent with how pings
work.
In this change I update the scheduling logic to use microtasks
consistently for prerenders and use regular tasks for renders both for
the initial work and pings.
Shortcut for the common case where only a single flag is checked. Same
as `gate(flags => flags.enableFeatureFlag)`.
Normally I don't care about these types of conveniences but I'm about to
add a lot more inline flag checks these all over our tests and it gets
noisy. This helps a bit.
When we introduced prerendering for flight we modeled an abort of a
flight prerender as having unfinished rows. This is similar to how
postpone was already implemented when you postponed from "within" a
prerender using React.unstable_postpone. However when aborting with a
postponed instance every boundary would be eagerly marked for client
rendering which is more akin to prerendering and then resuming with an
aborted signal.
The insight with the flight work was that it's not so much the postpone
that describes the intended semantics but the abort combined with a
prerender. So like in flight when you abort a prerender and enableHalt
is enabled boundaries and the shell won't error for any reason. Fizz
will still call onPostpone and onError according to the abort reason but
the consuemr of the prerender should expect to resume it before trying
to use it.
When aborting a prerender we should leave references unfulfilled, not
share a common unfullfilled reference. functionally today this doesn't
matter because we don't have resuming but the semantic is that the row
was not available when the abort happened and in a resume the row should
fill in. But by pointing each task to a common unfulfilled chunk we lose
the ability for these references to resolves to distinct values on
resume.
When aborting with a postpone value boundaries are put into client
rendered mode even during prerenders. This doesn't follow the postpoen
semantics of the rest of fizz where during a prerender a postpone is
tracked and it will leave holes in tracked postpone state that can be
resumed. This change updates this behavior to match the postpones
semantics between aborts and imperative postpones.
Noticed this from #30707. This was vestigial from from circleci and now
that we're on GH actions I think we should be able to remove this option
altogether.
ghstack-source-id: 78e8b0243b
Pull Request resolved: https://github.com/facebook/react/pull/30753
stacked on: #30731
We've refined the model of halting a prerender. Now when you abort
during a prerender we simply omit the rows that would complete the
flight render. This is analagous to prerendering in Fizz where you must
resume the prerender to actually result in errors propagating in the
postponed holes. We don't have a resume yet for flight and it's not
entirely clear how that will work however the key insight here is that
deciding whether the never resolving rows are an error or not should
really be done on the consuming side rather than in the producer.
This PR also reintroduces the logs for the abort error/postpone when
prerendering which will give you some indication that something wasn't
finished when the prerender was aborted.
Stacked on #30731.
When logging a Promise we emit it as an infinite promise instead of
blocking the replay on it.
This models that as a halted row instead. No need for this special case.
I unflag the receiving side since now it's used to replace a feature
that's already unflagged so it's used.
When printing these in DevTools they show up as the name of the
constructor so then you pass a Promise to the client it logs as "Chunk"
which is confusing.
Ideally we'd probably just name this Promise but 1) there's a slight
difference in the .then method atm 2) it's a bit tricky to name a
variable and get it from the global in the same scope. Closure compiler
doesn't let us just name a function because it removes it and just uses
the variable name.
using infinitely suspending promises isn't right because this will parse
as a promise which is only appropriate if the value we're halting at is
a promise. Instead we need to have a special marker type that says this
reference will never resolve. Additionally flight client needs to not
error any halted references when the stream closes because they will
otherwise appear as an error
addresses:
https://github.com/facebook/react/pull/30705#discussion_r1720479974
Per comments on the new validation pass, this disallows creating JSX (expression/fragment) within a try statement. Developers sometimes use this pattern thinking that they can catch errors during the rendering of the element, without realizing that rendering is lazy. The validation allows us to teach developers about the error boundary pattern.
ghstack-source-id: 0bc722aeaed426ddd40e075c008f0ff2576e0c33
Pull Request resolved: https://github.com/facebook/react/pull/30725
This uses a similar technique to what we use to generate fake stack
frames for server components. This generates an eval:ed wrapper function
around the Server Reference proxy we create on the client. This wrapper
function gets the original `name` of the action on the server and I also
add a source map if `findSourceMapURL` is defined that points back to
the source of the server function.
For `"use server"` on the server, there's no new API. It just uses the
callsite of `registerServerReference()` on the Server. We can infer the
function name from the actual function on the server and we already have
the `findSourceMapURL` on the client receiving it.
For `"use server"` imported from the client, there's two new options
added to `createServerReference()` (in addition to the optional
[`encodeFormAction`](#27563)). These are only used in DEV mode. The
[`findSourceMapURL`](#29708) option is the same one added in #29708. We
need to pass this these references aren't created in the context of any
specific request but globally. The other weird thing about this case is
that this is actually a case where the compiled environment is the
client so any source maps are the same as for the client layer, so the
environment name here is just `"Client"`.
```diff
createServerReference(
id: string,
callServer: CallServerCallback,
encodeFormAction?: EncodeFormActionCallback,
+ findSourceMapURL?: FindSourceMapURLCallback, // DEV-only
+ functionName?: string, // DEV-only
)
```
The key is that we use the location of the
`registerServerReference()`/`createServerReference()` call as the
location of the function. A compiler can either emit those at the same
locations as the original functions or use source maps to have those
segments refer to the original location of the function (or in the case
of a re-export the original location of the re-export is also a fine
approximate). The compiled output must call these directly without a
wrapper function because the wrapper adds a stack frame. I decided
against complicated and fragile dev-only options to skip n number of
frames that would just end up in prod code. The implementation just
skips one frame - our own. Otherwise it'll just point all source mapping
to the wrapper.
We don't have a `"use server"` imported from the client implementation
in the reference implementation/fixture so it's a bit tricky to test
that. In the case of CJS on the server, we just use a runtime instead of
compiler so it's tricky to source map those appropriately. We can
implement it for ESM on the server which is the main thing we're testing
in the fixture. It's easier in a real implementation where all the
compilation is just one pass. It's a little tricky since we have to
parse and append to other source maps but I'd like to do that as a
follow up. Or maybe that's just an exercise for the reader.
You can right click an action and click "Go to Definition".
<img width="1323" alt="Screenshot 2024-08-17 at 6 04 27 PM"
src="https://github.com/user-attachments/assets/94d379b3-8871-4671-a20d-cbf9cfbc2c6e">
For now they simply don't point to the right place but you can still
jump to the right file in the fixture:
<img width="1512" alt="Screenshot 2024-08-17 at 5 58 40 PM"
src="https://github.com/user-attachments/assets/1ea5d665-e25a-44ca-9515-481dd3c5c2fe">
In Firefox/Safari given that the location doesn't exist in the source
map yet, the browser refuses to open the file. Where as Chrome does
nearest (last) line.
It is possible to throw after aborting during a render and we were not
properly tracking this. We use an AbortSigil to mark whether a rendering
task needs to abort but the throw interrupts that and we end up handling
an error on the error pathway instead.
This change reworks the abort-while-rendering support to be robust to
throws after calling abort
Addresses a todo from a while back. We now validate environment options when parsing the plugin options, which means we can stop re-parsing/validating in later phases.
ghstack-source-id: b19806e843e1254716705b33dcf86afb7223f6c7
Pull Request resolved: https://github.com/facebook/react/pull/30726
This enables finding Server Components on the owner path. Server
Components aren't stateful so there's not actually one specific owner
that it necessarily matches. So it can't be a global look up. E.g. the
same Server Component can be rendered in two places or even nested
inside each other.
Therefore we need to find an appropriate instance using a heuristic. We
can do that by traversing the parent path since the owner is likely also
a parent. Not always but almost always.
To simplify things we can also do the same for Fibers. That brings us
one step closer to being able to get rid of the global
fiberToFiberInstance map since we can just use the shadow tree to find
this information.
This does mean that we can't find owners that aren't parents which is
usually ok. However, there is a test case that's interesting where you
have a React ART tree inside a DOM tree. In that case the owners
actually span multiple renderers and roots so the owner is not on the
parent stack. Usually this is fine since you'd just care about the
owners within React ART but ideally we'd support this. However, I think
that really the fix to this is that the React ART tree itself should
actually show up inside the DOM tree in DevTools and in the virtual
shadow tree because that's conceptually where it belongs. That would
then solve this particular issue. We'd just need some way to associate
the root with a DOM parent when it gets mounted.
This was a pet peeve where our playground could only compile top level
FunctionDeclarations. Just synthesize a fake identifier if it doesn't
have one.
ghstack-source-id: 882483c79c
Pull Request resolved: https://github.com/facebook/react/pull/30729
This PR updates the eslint plugin to report unused opt out directives.
One of the downsides of the opt out directive is that it opts the
component/hook out of compilation forever, even if the underlying issue
was fixed in product code or fixed in the compiler.
ghstack-source-id: 81deb5c11b
Pull Request resolved: https://github.com/facebook/react/pull/30721
This PR updates the babel plugin to continue the compilation pipeline as
normal on components/hooks that have been opted out using a directive.
Instead, we no longer emit the compiled function when the directive is
present.
Previously, we would skip over the entire pipeline. By continuing to
enter the pipeline, we'll be able to detect if there are unused
directives.
The end result is:
- (no change) 'use forget' will always opt into compilation
- (new) 'use no forget' will opt out of compilation but continue to log
errors without throwing them. This means that a Program containing
multiple functions (some of which are opted out) will continue to
compile correctly
ghstack-source-id: 5bd85df2f8
Pull Request resolved: https://github.com/facebook/react/pull/30720
enableHalt turns on a mode for flight prerenders where aborts are
treated like infinitely stalled outcomes while still completing the
prerender. For regular tasks we simply serialize the slot as a promise
that never settles. For ReadableStream, Blob, and Async Iterators we
just never advance the serialization so they remain unfinished when
consumed on the client.
When enableHalt is turned on aborts of prerenders will halt rather than
error. The abort reason is forwarded to the upstream produces of the
aforementioned async iterators, blobs, and ReadableStreams. In the
future if we expose a signal that you can consume from within a render
to cancel additional work the abort reason will also be forwarded there
Summary:
The change earlier in this stack makes it less safe to have ref enforcement disabled. This diff enables it by default.
ghstack-source-id: d3ab5f1b28b7aed0f0d6d69547bb638a1e326b66
Pull Request resolved: https://github.com/facebook/react/pull/30716
Summary:
We previously were excessively strict about preventing functions that access refs from being returned--doing so is potentially valid for hooks, because the return value may only be used in an event or effect.
ghstack-source-id: cfa8bb1b54e8eb365f2de50d051bd09e09162d7b
Pull Request resolved: https://github.com/facebook/react/pull/30724
Summary:
Since we want to make ref-in-render errors enabled by default, we should position those errors at the location of the read. Not only will this be a better experience, but it also aligns the behavior of Forget and Flow.
This PR also cleans up the resulting error messages to not emit implementation details about place values.
ghstack-source-id: 1d1131706867a6fc88efddd631c4d16d2181e592
Pull Request resolved: https://github.com/facebook/react/pull/30723
Test Plan:
Documents that useCallback calls interfere with it being ok for refs to escape as part of functions into jsx
ghstack-source-id: a5df427981ca32406fb2325e583b64bbe26b1cdd
Pull Request resolved: https://github.com/facebook/react/pull/30714
Summary:
Refs, as stable values that the rules of react around mutability do not apply to, currently are treated as having mutable ranges, and through aliasing, this can extend the mutable range for other values and disrupt good memoization for those values. This PR excludes refs and their .current values from having mutable ranges.
Note that this is unsafe if ref access is allowed in render: if a mutable value is assigned to ref.current and then ref.current is mutated later, we won't realize that the original mutable value's range extends.
ghstack-source-id: e8f36ac25e2c9aadb0bf13bd8142e4593ee9f984
Pull Request resolved: https://github.com/facebook/react/pull/30713
## Summary
Flow will eventually remove the specific `React.Element` type. For most
of the code, it can be replaced with `React.MixedElement` or
`React.Node`.
When specific react elements are required, it needs to be replaced with
either `React$Element` which will trigger a `internal-type` lint error
that can be disabled project-wide, or use
`ExactReactElement_DEPRECATED`.
Fortunately in this case, this one can be replaced with just
`React.MixedElement`.
## How did you test this change?
`flow`
Prerendering in flight is similar to prerendering in Fizz. Instead of
receiving a result (the stream) immediately a promise is returned which
resolves to the stream when the prerender is complete. The promise will
reject if the flight render fatally errors otherwise it will resolve
when the render is completed or is aborted.
Test Plan:
Builds support for a.x++ and friends. Similar to a.x += y, emits it as an assignment expression.
ghstack-source-id: 8f3979913aad561cdba70464c3cc5f0ee95887b5
Pull Request resolved: https://github.com/facebook/react/pull/30697
Summary:
It doesn't seem as though this invariant was necessary
ghstack-source-id: b27e76525911d5cfc1991b5cfdb7b2074c039e21
Pull Request resolved: https://github.com/facebook/react/pull/30699
Supports showing the key in DevTools on the Server Component that the
key was applied to. We can also use this to reconcile to preserve
instance equality when they're reordered.
One thing that's a bit weird about this is that if you provide an
explicit key on a Server Component that alone doesn't have any
semantics. It's because we pass the key down and let the nearest child
inherit the key or get prefixed by the key.
So you might see the same key as a prefix on the child of the Server
Component too which might be a bit confusing. We could remove the prefix
from children but that might also be a bit confusing if they collide.
The div in this case doesn't have a key explicitly specified. It gets it
from the Server Component parent.
<img width="1107" alt="Screenshot 2024-08-14 at 10 06 36 PM"
src="https://github.com/user-attachments/assets/cfc517cc-e737-44c3-a1be-050049267ee2">
Overall keys get a bit confusing when you apply filter. Especially since
it's so common to actually apply the key on a Host Instance. So you
often don't see the key.
Per discussion today, adds validation against calling setState "during" passive effects. Basically, it's fine to _schedule_ setState to be called (via a timeout, listener, etc) but generally not recommended to call setState during the effect since that will trigger a cascading render.
This validation is off by default, i'm putting this up for discussion and to experiment with it internally.
ghstack-source-id: 5f385ddab59561ec3939ae5ece265dfee4f2cb56
Pull Request resolved: https://github.com/facebook/react/pull/30685
This commit updates the file locations and bulid configurations for
flight in preparation for new static entrypoints. This follows a
structure similar to Fizz which has a unified build but exports methods
from different top level entrypoints. This PR doesn't actually add the
new top level entrypoints however, that will arrive in a later update.
During local development it's common to add or remove code which may
change the cache size between renders. Add a failing test to show that
currently (without the compiled fast refresh check) this issues a
warning and reuses the cache which may have stale values.
ghstack-source-id: efdcb017ba3bdadd88b1f8bb5523b1a9f6217eb5
Pull Request resolved: https://github.com/facebook/react/pull/30662
Summary:
UseTransition is a builtin hook that returns a stable value, like useState. This PR represents that in Forget, and marks the startTransition function as stable.
ghstack-source-id: 0e76a64f2d0c86a4eb55c620922b4698250bb5c3
Pull Request resolved: https://github.com/facebook/react/pull/30681
Summary:
In theory, as I understand it, the result of a useRef will never change between renders, because we'll always provide the same ref value consistently. That means that memoization that depends on a ref value will never re-compute, so I think we could not infer it as a dependency in Forget. This diff, however, doesn't do that: it instead allows the validatePreserveExistingMemoizationGuarantees analysis to admit mismatches between explicit dependencies and implicit ones when the implicit dependency is a ref that doesn't exist in source.
ghstack-source-id: 685d859d1eed5d1e19dbbbfadc75be3875ddb6ea
Pull Request resolved: https://github.com/facebook/react/pull/30679
This adds VirtualInstances to the tree. Each Fiber has a list of its
parent Server Components in `_debugInfo`. The algorithm is that when we
enter a set of fibers, we actually traverse level 0 of all the
`_debugInfo` in each fiber. Then level 1 of each `_debugInfo` and so on.
It would be simpler if `_debugInfo` only contained Server Component
since then we could just look at the index in the array but it actually
contains other data as well which leads to multiple passes but we don't
expect it to have a lot of levels before hitting a reified fiber.
Finally when we hit the end a traverse the fiber itself.
This lets us match consecutive `ReactComponentInfo` that are all the
same at the same level. This creates a single VirtualInstance for each
sequence. This lets the same Server Component instance that's a parent
to multiple children appear as a single Instance instead of one per
Fiber.
Since a Server Component's result can be rendered in more than one place
there's not a 1:1 mapping though. If it is in different parents or if
the sequence is interrupted, then it gets split into two different
instances with the same `ReactComponentInfo` data.
The real interesting case is what happens during updates because this
algorithm means that a Fiber can become reparented during an update to
end up in a different VirtualInstance. The ideal would maybe be that the
frontend could deal with this reparenting but instead I basically just
unmount the previous instance (and its children) and mount a new
instance which leads to some interesting scenarios. This is inline with
the strategy I was intending to pursue anyway where instances are
reconciled against the previous children of the same parent instead of
the `fiberToFiberInstance` map - which would let us get rid of that map.
In that case the model is resilient to Fiber being in more than one
place at a time.
However this unmount/remount does mean that we can lose selection when
this happens. We could maybe do something like using the tracked path
like I did for component filters. Ideally it's a weird edge case though
because you'd typically not have it. The main case that it happens now
is for reorders of list of server components. In that case basically all
the children move between server components while the server components
themselves stay in place. We should really include the key in server
components so that we can reconcile them using the key to handle
reorders which would solve the common case anyway.
I convert the name to the `Env(Name)` pattern which allows the
Environment Name to be used as a badge.
<img width="1105" alt="Screenshot 2024-08-13 at 9 55 29 PM"
src="https://github.com/user-attachments/assets/323c20ba-b655-4ee8-84fa-8233f55d2999">
(Screenshot is with #30667. I haven't tried it with the alternative
fix.)
---------
Co-authored-by: Ruslan Lesiutin <rdlesyutin@gmail.com>
Alternative to https://github.com/facebook/react/pull/30667.
Basically wrap every section in a `div` with the same class, and only
apply `border-bottom` for every instance, except for the last child. We
are paying some cost by having more divs, but thats more explicit.
When synchronously aborting in a non-async Function Component if you
throw after aborting the task would error rather than abort because
React never observed the AbortSignal.
Using a sigil to throw after aborting during render isn't effective b/c
the user code itself could throw so insteead we just read the request
status. This is ok b/c we don't expect any tasks to still be pending
after the currently running task finishes.
However I found one instance where that wasn't true related to
serializing thenables which I've fixed so we may find other cases. If we
do, though it's almost certainly a bug in our task bookkeeping so we
should just fix it if it comes up.
I also updated `abort` to not set the status to ABORTING unless the
status was OPEN. we don't want to ever leave CLOSED or CLOSING status
When I implemented the ability to abort synchronoulsy in flight I made
it possible for erroring async server components to cause an unhandled
rejection error. In the current implementation if you abort during the
synchronous phase of a Function Component and then throw an error in the
synchronous phase React will not attach any promise handlers because it
short circuits the thenable treatment and throws an AbortSigil instead.
This change updates the rendering logic to ignore the rejecting
component.
There was a comment that it's not safe to walk the unmounted fiber tree
which I'm not sure is correct or not but we need to walk the instance
tree to be able to clean up virtual instances anyway. We already walk
the instance tree to clean up "remaining instances".
This is also simpler because we don't need to special case Suspense
boundaries. We simply clean up whatever branch we had before.
The ultimate goal is to also walk the instance tree for updates so we
don't need a fiber to instance map.
## Summary
As promised on https://github.com/facebook/react/pull/29627, this
creates a unit test for the `findNodeHandle` error that prevents
developers from calling it within render methods.
## How did you test this change?
```
$ yarn test ReactFabric-test.internal.js
```
Summary:
As title. Better support for flow typing, bugfixes, etc fixes these
ghstack-source-id: 6326653ce42b33b6c1c76a494434d133382ca80a
Pull Request resolved: https://github.com/facebook/react/pull/30591
Summary:
Builds support for macros that are invoked as methods rather than just function calls or jsx.
We now record macros as a schema that represents arbitrary member expressions including wildcards (so we can support, e.g., myMacro.*.foo.bar). When examining PropertyLoads in the macro memoization stage, we build up a map of partially-satisfied macro patterns until we determine that the pattern has been fully satisfied, at which point we treat the result of the PropertyLoad as a macro value.
ghstack-source-id: d78d9ba7041968c861ffa110fb7882b339a0e257
Pull Request resolved: https://github.com/facebook/react/pull/30589
> [!NOTE]
> The `latest` tag is published by default if no tag is specified, which
> is what we had done since the first release of the compiler
In my last PR to auto publish compiler releases I had added the
experimental tag to be used in publishing. However because we had
already previously published to the latest tag (which is non-removable)
this means that the `latest` tag is pinned to an old version. That makes
untagged installs of the compiler default to that old version instead of
whatever is the latest.
This changes the behavior back to what it was before. Since we are still
in the experimental release of the compiler anyway it seems fine to use
the latest tag. When we reach stable, we can update this to only push to
latest for stable releases.
ghstack-source-id: 1809481b45
Pull Request resolved: https://github.com/facebook/react/pull/30666
Stacked on #30625 and #30657.
This ensures that we only create instances during the commit
reconciliation and that we don't create unnecessary instances for things
that are filtered or not mounted. This ensures that we also can rely on
the reconciliation to do all the clean up. Now everything is created and
deleted as a pair in the same pass.
Previously we were including unfiltered components in the owner stack
which probably doesn't make sense since you're intending to filter them
everywhere presumably. However, it also means that those links were
broken since you can't link into owners that don't exist in the parent
tree.
The main complication is the component filters. It relied on not
unmounting the old instances. I had to update some tests that asserted
on ids that are now shifted.
For warnings/errors tracking I now restore them back into the pending
set when they unmount. Basically it puts them back into their
"pre-commit" state. That way when they remount they’re still there.
For restoring the current selection I use the tracked path mechanism
instead of relying on the id being unchanged. This is better anyway
because if you filter out the currently selected item it's better to
select the nearest match instead of just losing the selection.
Same principle as #30555. We shouldn't be throttling the UI to make it
feel less snappy. Instead, we should use back-pressure to handle it.
Normally the browser handles it automatically with frame aligned events.
E.g. if the thread can't keep up with sync updates it doesn't send each
event but the next one. E.g. pointermove or resize.
However, it is possible that we end up queuing too many events if the
frontend can't keep up but the solution to this is the same as mentioned
in #30555. I.e. to track the last message and only send after we get a
response.
I still keep the throttle to persist the selection since that affects
the disk usage and doesn't have direct UX effects.
The main motivation for this change though is that lodash throttle
doesn't rely on timers but Date.now which makes it incompatible with
most jest helpers which means I can't write tests against these
functions properly.
This no longer uses the handleCommitFiberUnmount hook to track unmounts.
Instead, we can just unmount the DevToolsInstances that we didn't reuse.
This doesn't account for cleaning up instances that were unnecessarily
created when they weren't in the tree. I have a separate follow up for
that.
This also removes the queuing of untracking. This was added in #21523
but I don't believe it has been needed for a while because the mentioned
flushPendingErrorsAndWarningsAfterDelay hasn't called untrackFiberID for
a while so the race condition doesn't exist. It's hard to tell though
because from the issues there weren't really any repros submitted.
We made block types explicit a long time ago, this comment is super stale
ghstack-source-id: 810a34bb4c14a3f4541003db23ffb7ad91aecc8c
Pull Request resolved: https://github.com/facebook/react/pull/30633
This is the beginning of a refactor of the DevTools Fiber backend. The
new approach is basically that we listen to each commit from Fiber and
traverse the tree - building up a filtered shadow tree. Then we send
diffs based on that tree and perform our own operations against that
instead of using Fibers as the source of truth.
Fiber diffs Elements -> Fibers. The backend diffs Fibers ->
DevToolsInstances as a side-effect it sends deltas to the front end.
This makes the algorithm resilient to a different Fiber implementation
that doesn't use pairs of Fibers (alternates) but instead stateless new
clones each time. In that world we can't treat Fibers as instances. They
can hold onto instances but they're not necessarily 1:1 themselves.
The same thing also applies to Server Components that don't have their
own instances.
The algorithm is more or less the same as React's reconciliation in
ReactChildFiber itself. However, we do a mutable update of the tree as
we go. We also cheat a bit here in the first version in that we still
have fiberToFiberInstance map and alternate which makes reorders easier.
Further down we could do the reorders by adding the previous set to a
temporary map like ChildFiber does but only if they're not already in
order.
This first bit is just about making sure that we produce correct trees.
We have fairly good test coverage already of that already.
In the next few follow ups I'll start simplifying the rest of the logic
by taking advantage of the new tree.
Previously the compiler would add an import for the specified context
callee even if the context access was not lowered, leading to unused
imports.
This PR tracks if lowering has happened and adds the import only when
necessary.
ghstack-source-id: 6ad794da41116e1034783b6c4a58fbfe7790343e
Pull Request resolved: https://github.com/facebook/react/pull/30628
If a value is specified for the LowerContextAccess environment config,
we rewrite the callee from 'useContext' to the specificed value.
This will allow us run an experiment internally.
ghstack-source-id: 00e161b988c8f8a1cf96efff8095f050cb534cc1
Pull Request resolved: https://github.com/facebook/react/pull/30612
*This is only for internal profiling, not intended to ship.*
This pass is intended to be used with https://github.com/facebook/react/pull/30407.
This pass synthesizes selector functions by collecting immediately
destructured context acesses. We bailout for other types of context
access.
This pass lowers context access to use a selector function by passing
the synthesized selector function as the second argument.
ghstack-source-id: 92d0f6ff2f
Pull Request resolved: https://github.com/facebook/react/pull/30548
This PR updates to use SSA form through the entire compilation pipeline. This means that in both HIR form and ReactiveFunction form, `Identifier` instances map 1:1 to `IdentifierId` values. If two identifiers have the same IdentifierId, they are the same instance. What this means is that all our passes can use this more precise information to determine if two particular identifiers are not just the same variable, but the same SSA "version" of that variable.
However, some parts of our analysis really care about program variables as opposed to SSA versions, and were relying on LeaveSSA to reset identifiers such that all Identifier instances for a particular program variable would have the same IdentifierId (though not necessarily the same Identifier instance). With LeaveSSA removed, those analysis passes can now use DeclarationId instead to uniquely identify a program variable.
Note that this PR surfaces some opportunties to improve edge-cases around reassigned values being declared/reassigned/depended-upon across multiple scopes. Several passes could/should use IdentifierId to more precisely identify exactly which values are accessed - for example, a scope that reassigns `x` but doesn't use `x` prior to reassignment doesn't have to take a dependency on `x`. But today we take a dependnecy.
My approach for these cases was to add a "TODO LeaveSSA" comment with notes and the name of the fixture demonstrating the difference, but to intentionally preserve the existing behavior (generally, switching to use DeclarationId when IdentifierId would have been more precise).
Beyond updating passes to use DeclarationId instead of Identifier/IdentifierId, the other change here is to extract out the remaining necessary bits of LeaveSSA into a new pass that rewrites InstructionKind (const/let/reassign/etc) based on whether a value is actually const or has reassignments and should be let.
ghstack-source-id: 69afdaee5fadf3fdc98ce97549da805f288218b4
Pull Request resolved: https://github.com/facebook/react/pull/30573
Adds `Identifier.declarationId` and the new `DeclarationId` (simulated) opaque type. DeclarationId allows uniquely identifying a variable in the original source, ie regardless of reassignments. This allows us to stay in SSA form throughout compilation (see next diff) while still being able to distinguish SSA versions (via IdentifierId) and non-SSA versions (DeclarationId).
ghstack-source-id: f2547a58aa7b30cea29fcfe23d5cb45583858a4e
Pull Request resolved: https://github.com/facebook/react/pull/30569
Publishes the compiler packages on the same schedule as the React ones.
For now the manual script can only build from `main` but in the future
we can add support for building specific commits
ghstack-source-id: 66676c578b795b90bf3c5715be8900438868b6ee
Pull Request resolved: https://github.com/facebook/react/pull/30615
Updates the release script to publish tags as well as take a `--ci`
option
Test plan:
```
$ yarn npm:publish --debug --frfr
yarn run v1.22.22
$ node scripts/release/publish --debug --frfr
ℹ Preparing to publish (for real) [debug=true]
ℹ Building packages
✔ Successfully built babel-plugin-react-compiler
✔ Successfully built eslint-plugin-react-compiler
✔ Successfully built react-compiler-healthcheck
NPM 2-factor auth code: ******
✔ Wrote package.json for babel-plugin-react-compiler@0.0.0-experimental-10cf18a-20240806
========== babel-plugin-react-compiler ==========
⠧ Publishing babel-plugin-react-compiler@0.0.0-experimental-10cf18a-20240806 to npm
+ babel-plugin-react-compiler@0.0.0-experimental-10cf18a-20240806
✔ Successfully published babel-plugin-react-compiler to npm
ℹ dry-run: npm dist-tag add babel-plugin-react-compiler@0.0.0-experimental-10cf18a-20240806 experimental --otp=******
✔ Successfully pushed dist-tag experimental for babel-plugin-react-compiler to npm
✔ Wrote package.json for eslint-plugin-react-compiler@0.0.0-experimental-532f76b-20240806
========== eslint-plugin-react-compiler ==========
⠹ Publishing eslint-plugin-react-compiler@0.0.0-experimental-532f76b-20240806 to npm
+ eslint-plugin-react-compiler@0.0.0-experimental-532f76b-20240806
✔ Successfully published eslint-plugin-react-compiler to npm
ℹ dry-run: npm dist-tag add eslint-plugin-react-compiler@0.0.0-experimental-532f76b-20240806 experimental --otp=******
✔ Successfully pushed dist-tag experimental for eslint-plugin-react-compiler to npm
✔ Wrote package.json for react-compiler-healthcheck@0.0.0-experimental-48a8743-20240806
========== react-compiler-healthcheck ==========
⠙ Publishing react-compiler-healthcheck@0.0.0-experimental-48a8743-20240806 to npm
+ react-compiler-healthcheck@0.0.0-experimental-48a8743-20240806
✔ Successfully published react-compiler-healthcheck to npm
ℹ dry-run: npm dist-tag add react-compiler-healthcheck@0.0.0-experimental-48a8743-20240806 experimental --otp=******
✔ Successfully pushed dist-tag experimental for react-compiler-healthcheck to npm
✅ All done
✨ Done in 50.64s.
```
ghstack-source-id: 405cc001c2ab2adaad2bfe4f11fdb7fd28d7e2d1
Pull Request resolved: https://github.com/facebook/react/pull/30614
I originally added this prior to the compiler being OSS'd as a "just in
case" feature to panic cancel if something went wrong. Now that the
compiler is already launched this is unnecessary.
ghstack-source-id: dd17dc8a331657ce23c0cbc012ba967cfc3b9542
Pull Request resolved: https://github.com/facebook/react/pull/30613
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
In the shared_lint,
for the first Prettier job, use `${{ runner.arch }}-${{ runner.os
}}-modules-${{ hashFiles('yarn.lock') }}` as the cache key.
For the following jobs, use `${{ runner.arch }}-${{ runner.os
}}-modules-${{ hashFiles('**/yarn.lock') }}` as the cache key.
Some of the jobs do not hit the cache if the hash does not match.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
I run [act](https://github.com/nektos/act) locally to test it.
Update createTemporaryPlace to use makeTemporary and also rename
makeTemporary to makeTemporaryIdentifier to make it less ambiguous.
ghstack-source-id: b5955d3d667064f2ccf7e633ab63df2269dc56fa
Pull Request resolved: https://github.com/facebook/react/pull/30585
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Just fixing some copy-paste typos.
## How did you test this change?
Untested.
Follow up from #30584.
You can already select a singleton or hoistable (that's not a resource)
in the browser elements panel and it'll select the corresponding node in
the RDT Components panel. That works because it uses the same mechanism
as event dispatching and those need to be able to receive events.
However, you can't select a resource. Because that's conceptually one to
many.
This keeps track of which fiber is acquiring which resource so we can
find all the corresponding instances.
E.g. now you can select the `<link rel="stylesheet">` in the Flight
fixture in the Element panel and then the component that rendered it in
the Components panel will be selected.
If we had a concept multi-selection we could potentially select all of
them. This similar to how a Server Component can be rendered in more
than one place and if we want to select all matching ones. It's kind of
weird though and both cases are edge cases.
Notably imperative preloads do have elements that don't have any
corresponding component but that's ok. So they'll just select `<head>`.
Maybe in dev we could track the owners of those.
Summary:
Fixes issue documented by #30435. We change the pipeline order so that outlining comes after tracking macro operands, and any function that is referenced in a macro will now not be outlined.
ghstack-source-id: f731ad65c8b84db3fc5f3a2ff3a6986112765963
Pull Request resolved: https://github.com/facebook/react/pull/30587
This is just for clarity at first.
Before:
- mountFiberRecursively accepts a set of children and flag that says
whether to just do one
- updateFiberRecursively accepts a fiber and loops over its children
- unmountFiberChildrenRecursively accepts a fiber and loops over its
children
After:
- mountFiberRecursively accepts a Fiber and calls
mountChildrenRecursively
- updateFiberRecursively accepts a Fiber and calls
updateChildrenRecursively
- unmountFiberRecursively accepts a Fiber and calls
unmountChildrenRecursively
- mountChildrenRecursively accepts a set of children and loops over each
one
- updateChildrenRecursively accepts a set of children and loops over
each one
- unmountChildrenRecursively accepts a set of children and loops over
each one
So now there's one place where things happens for the single item and
one place where we do the loop.
Basically the new Float types needs to be supported. Resources are a bit
special because they're a DOM specific type but we can expect any other
implementation using resources to provide and instance on this field if
needed.
There's a slightly related case for the reverse lookup. You can already
select a singleton or hoistable (that's not a resource) in the browser
elements panel and it'll select the corresponding node in the RDT
Components panel. That works because it uses the same mechanism as event
dispatching and those need to be able to receive events.
However, you can't select a resource. Because that's conceptually one to
many. We could in principle just search the tree for the first one or
keep a map of currently mounted resources and just pick the first fiber
that created it. So that you can select a resource and see what created
it. Particularly useful when there's only one Fiber which is most of the
time.
---------
Co-authored-by: Ruslan Lesiutin <rdlesyutin@gmail.com>
*This is only for internal profiling, not intended to ship.*
ghstack-source-id: e48998b7be4272199c8a6ff9cc2ec0975add5030
Pull Request resolved: https://github.com/facebook/react/pull/30547
In the future, we can use this to identify useContext calls.
ghstack-source-id: 01d7b0941ccd09f65346eb5431aa53fe361ce5ed
Pull Request resolved: https://github.com/facebook/react/pull/30546
This is a useful utility function similar to the existing
`makeInstructionId` and `makeIdentifierId` functions.
This PR moves it outside the HIRBuilder so we can use this in passes
that don't have access to the builder instance.
ghstack-source-id: 1ac0839e6cb417aedcdf8cdd159af7069af7172a
Pull Request resolved: https://github.com/facebook/react/pull/30545
Rather than storing the entire babel node, store only the required
information which is the node type.
This will be useful for when we synthesize new functions that don't have
a corresponding babel node.
ghstack-source-id: 9098cbdbc4b1e9a6e7dafa2e7645f6f4854e1eac
Pull Request resolved: https://github.com/facebook/react/pull/30544
ghstack failed to land #30552 properly, resubmitting
Developers sometimes use `useMemo()` as a way to conditionally execute code, including conditionally calling setState. However, the compiler may remove existing useMemo calls if they are not necessary, which _should_ always be a safe optimization. If the useMemo has side effects (eg sets state), then this isn't safe.
This PR improves ValidateNoSetStateInRender to disallow any setState in useMemo (even if it's conditional), expanding on the previous check for unconditional setState in render. Note that the approach uses the StartMemoize/FinishMemoize instructions added in DropManualMemo to know whether a particular setState call is within a useMemo or not. This means enabling the validation in DropManualMemo when the setState validation is enabled, but that's fine since that validation is on everywhere by default (_except_ for in fixtures, which we have a todo for)
ghstack-source-id: 65bb3289c3
Pull Request resolved: https://github.com/facebook/react/pull/30583
Adding `__IS_NATIVE__` global, which will be used for forking backend
implementation. Will only be set to `true` for `react-devtools-core`
package, which is used by `react-native`.
Ideally, we should name it `react-devtools-native`, and keep
`react-devtools-core` as host-agnostic.
With this change, the next release of `react-devtools-core` should
append component stack as Error object, not as string, and should add
`(<anonymous>)` suffix to component stack frames.
Persistent renderers used the `Update` effect flag to check if a subtree
needs to be cloned. In some cases, that causes extra renders, such as
when a layout effect is triggered which only has an effect on the JS
side, but doesn't update the host components.
It's been a bit tricky to find the right places where this needs to be
set and I'm not 100% sure I got all the cases even though the tests
passed.
[`react-window` disables `pointerEvents` while scrolling meaning you
can't click anything while
scrolling.](https://github.com/bvaughn/react-window/issues/128).
This means that the first click when you stop the scroll with inertial
scrolling doesn't get registered. This is suuuper annoying. This might
make sense when you click to stop on a more intentional UI but it
doesn't makes sense in a list like this because we eagerly click things
even on mousedown.
This PR just override that to re-enable pointer events.
Supposedly this is done for performance but that might be outdated
knowledge. I haven't observed any difference so far.
If we discover that it's a perf problem, there's another technique we
can use where we call `ownerDocument.elementFromPoint(e.pageX, e.pageY)`
and then dispatch the event against that element. But let's try the
simplest approach first?
There's two problems. The biggest one is that it turns out that Chrome
is throttling looping timers that we're using both while polling and for
batching bridge traffic. This means that bridge traffic a lot of the
time just slows down to 1 second at a time. No wonder it feels sluggish.
The only solution is to not use timers for this.
Even when it doesn't like in Firefox the batching into 100ms still feels
too sluggish.
The fix I use is to batch using a microtask instead so we can still
batch multiple commands sent in a single event but we never artificially
slow down an interaction.
I don't think we've reevaluated this for a long time since this was in
the initial commit of DevTools to this repo. If it causes other issues
we can follow up on those.
We really shouldn't use timers for debouncing and such. In fact, React
itself recommends against it because we have a better technique with
scheduling in Concurrent Mode. The correct way to implement this in the
bridge is using a form of back-pressure where we don't keep sending
messages until we get a message back and only send the last one that
matters. E.g. when moving the cursor over a the elements tab we
shouldn't let the backend one-by-one move the DOM node to each one we
have ever passed. We should just move to the last one we're currently
hovering over. But this can't be done at the bridge layer since it
doesn't know if it's a last-one-wins or imperative operation where each
one needs to be sent. It needs to be done higher. I'm not currently
seeing any perf problems with this new approach but I'm curious on React
Native or some thing. RN might need the back-pressure approach. That can
be a follow up if we ever find a test case.
Finally, the other problem is that we use a Suspense boundary around the
Element Inspection. Suspense boundaries are for things that are expected
to take a long time to load. This shows a loading state immediately. To
avoid flashing when it ends up being fast, React throttles the reveal to
200ms. This means that we take a minimum of 200ms to show the props. The
way to show fast async data in React is using a Transition (either using
startTransition or useDeferredValue). This lets the old value remaining
in place while we're loading the next one.
We already implement this using `inspectedElementID` which is the async
one. It would be more idiomatic to implement this with useDeferredValue
rather than the reducer we have now but same principle. We were just
using the wrong ID in a few places so when it synchronously updated they
suspended. So I just made them use the inspectedElementID instead.
Then I can simply remove the Suspense boundary. Now the selection
updates in the tree view synchronously and the sidebar lags a frame or
two but it feels instant. It doesn't flash to white between which is
key.
Summary:
This diff extends the existing work on validating against locals being reassigned after render, by propagating the reassignment "effect" into the lvalues of instructions when the rvalue operands include values known to cause reassignments. In particular, this "closes the loop" for function definitions and function calls: a function that returns a function that reassigns will be considered to also perform reassignments, but previous to this we didn't consider the result of a `Call` of a function that reassigns to itself be a value that reassigns.
This causes a number of new bailouts in test cases, all of which appear to me to be legit.
ghstack-source-id: 770bf02d079ea2480be243a49caa6f69573d8092
Pull Request resolved: https://github.com/facebook/react/pull/30540
When aborting with a postpone value in Fizz if any tasks are still
pending in the root while prerendering the prerender will fatally error.
This is different from postponing imperatively in a root task and really
the semantics should be the same. This change updates React to treat an
abort with a postpone value as a postponed root rather than a fatal
error.
This just tracks the `.parent` field properly and uses DevToolsInstances
in more places that used to use IDs or Fibers.
I also use this new parent path when looking up a DevToolsInstance from
a DOM node. This should ideally be simple because the `.parent` field
represents only the unfiltered parents and include any virtual parents.
So we should be able to just get one from nearest Fiber that has one.
However, because we don't currently always clean up the map of
DevToolsInstances (e.g. updateComponentFilters doesn't recursively clean
out everything) it can leave matches hanging that shouldn't be there. So
we need to run the shouldFilterFiber filter to ignore those.
Another interesting implication is that without a FiberInstance we don't
have a way to get to a VirtualInstance from a HostComponent. Which means
that even filtered Fibers need to have a FiberInstance if they have a
VirtualInstance parent. Even if we don't actually mount them into the
front-end.
There's a special case that happens when we replay logs on the client
because this doesn't happen within the context of any particular
rendered component. So we need to reimplement things that would normally
be handled by a full client like Fiber.
The implementation of `getOwnerStackByComponentInfoInDev` is the
simplest version since it doesn't have any client components in it so I
move it to `shared/`. It's only used by Flight but both `react-server/`
and `react-client/` packages. The ReactComponentInfo type is also more
generic than just Flight anyway.
In a follow up I still need to implement this in React DevTools when
native tasks are not available so that it appends it to the console.
While debugging #30536 I happened to notice that the bug only reproduced
when there was interleaving scopes, and observed that an unpruned scope
nested inside of a pruned one was not being visited by
CollectPromotableTemporaries, which keeps track of which identifiers
should be promoted later. Therefore when actually promoting temporaries
we were skipping over the identifiers in children of pruned scopes
ghstack-source-id: d805f62f22
Pull Request resolved: https://github.com/facebook/react/pull/30537
Stacked on #30494 and #30491.
This is setting us up to be able to track Server Components. This is now
split into a FiberInstance (Client Component) and a VirtualInstance
(Server Component). We're not actually creating any VirtualInstances yet
though this is just the data structures.
Server Components and potentially other compiled away or runtime
optimized away (e.g. calling through a function without creating an
intermediate Fiber) don't have a stateful instance. They just represent
the latest data. It's kind of like a React Element.
However, in the DevTools UI we need them to be stateful partly just so
that you can select and refer to them separately. E.g. the same Server
Component output rendered into different slots on the client should
still have two different representations in the DevTools. Also if the
same child Fibers update in place because the Server Component refreshed
we shouldn't lose the selection if you've selected a Server Component.
I'll implement this by creating Virtual Instances that only exist for
the purpose of the DevTools UI and so it'll be implemented in the
DevTools.
We could just make a Map from `id` to `Fiber | ReactComponentInfo` but
that requires a branching without a consistent hidden class. We also
need some more states on there. We also have some other Maps that tracks
extra states like that of component stacks, errors and warnings.
Constantly resizing and adding/removing from a Map isn't exactly fast.
It's faster to have a single Map with an object in it than one Map per
object. However, having extra fields that are usually just `null` can
instead mean more memory gets used. Since only a very small fraction of
instances will have errors/warnings or having initialized its component
stack, it made sense to store that in a separate Map that is usually
just empty.
However, with the addition of particularly the `parent` field and the
ability to do a fast hidden-class safe branching on the `kind` field I
think it's probably worth actually allocating an extra first class
object per Instance to store DevTools state into. That's why I converted
from just storing `Fiber` -> `id` to storing `Fiber` ->
`DevToolsInstance` which then keeps the warnings/errors/componentStack
as extra fields that are usually `null`. That is a lot of objects though
since it's one per Fiber pair basically.
We use static dependency injection. We shouldn't use this dynamic
dependency injection we do for DevTools internals. There's also meta
programming like spreading and stuff that isn't needed.
This moves the config from `injectIntoDevTools` to the FiberConfig so it
can be statically resolved.
Closure Compiler has some trouble generating optimal code for this
anyway so ideally we'd refactor this further but at least this is better
and saves a few bytes and avoids some code paths (when minified).
Stacked on #30491.
When going from DOM Node to select a component or highlight a component
we find the nearest mounted ancestor. However, when multiple renderers
are nested there can be multiple ancestors. The original fix#24665 did
this by taking the inner renderer if it was an exact match but if it
wasn't it just took the first renderer.
Instead, we can track the inner most node we've found so far. Then get
the ID from that node (which will be fast since it's now a perfect
match). This is a better match.
However, the main reason I'm doing this is because the old mechanism
leaked the `Fiber` type outside the `RendererInterface` which is
supposed to abstract all of that. With the new algorithm this doesn't
leak.
I've tested this with a new build against the repro in the old issue
#24539 and it seems to work.
The invalid GraphQL in these fixtures somehow causes an unhandled
promise rejection error when running `yarn prettier-all`. This fixes
that issue by making the GraphQL valid.
With GitHub issue templates this workflow is not truly necessary and
can deny other workflows from running due to a limited amount of CI
workers in the pool.
I propose deleting this workflow and relying on issue templates instead.
ghstack-source-id: a798621f36
Pull Request resolved: https://github.com/facebook/react/pull/30518
Stacked on #30490.
This is in the same spirit but to clarify the difference between what is
React Native vs part of any generic Host. We used to use "Native" to
mean three different concepts. Now "Native" just means React Native.
E.g. from the frontend's perspective the Host can be
Highlighted/Inspected. However, that in turn can then be implemented as
either direct DOM manipulation or commands to React Native. So frontend
-> backend is "Host" but backend -> React Native is "Native" while
backend -> DOM is "Web".
Rename NativeElementsPanel to BuiltinElementsPanel. This isn't a React
Native panel but one part of the surrounding DevTools. We refer to Host
more as the thing running React itself. I.e. where the backend lives.
The runtime you're inspecting. The DevTools itself needs a third term.
So I went with "Builtin".
This is not used by DevTools since it has its own implementation of it.
This function is getting removed since `findDOMNode` is getting removed
so we shouldn't keep around extra bytes unnecessarily.
There is also `findHostInstancesForRefresh` which should really be
implemented on the `react-refresh` side. Not using an injection but
that's a heavier lift and only affects `__DEV__`.
Several CI workflows depend on the runtime_build_and_test.yml workflow
to complete before it can successfully download the build artifact.
However it is possible to encounter a race condition where the build
hasn't completed when the new workflow is started.
This PR adds a simple polling mechanism that waits up to 10 minutes for
the build for that revision to complete.
ghstack-source-id: 6a954638a800fbea8081e6fba35ee4b4437731c5
Pull Request resolved: https://github.com/facebook/react/pull/30515
Added instructions on the new workflow. Let's keep this short around for
now as it may be used again due to muscle memory and emit a helpful
message instead.
ghstack-source-id: 3f840a3d4319309d31cefeae028f97d280b0c09a
Pull Request resolved: https://github.com/facebook/react/pull/30510
This can be restored back to being a boolean instead of an enum
ghstack-source-id: aca58fb7ea386ee489dd895e028f1aa2fc507193
Pull Request resolved: https://github.com/facebook/react/pull/30508
Unforks these scripts now that we are fully migrated to GH.
ghstack-source-id: e1e15452f2d2e178a5b56203ebd0b42151e6a9ba
Pull Request resolved: https://github.com/facebook/react/pull/30506
There is currently a mismatch in how the persistent mode JS API and the
Fabric native code interpret `completeRoot`.
This is a short-lived experiment to see the effect of moving the Fabric
`completeRoot` call from `finalizeContainerChildren` to
`replaceContainerChildren` which in some cases does not get called.
actions/cache has a default timeout of 10 minutes. Occasionally the
cache service download gets stuck and it waits this amount of time
before proceeding like it was a cache miss.
10 minutes is way too long so let's shorten this to a minute.
ghstack-source-id: 95dee31bd9
Pull Request resolved: https://github.com/facebook/react/pull/30512
Currently if you abort a Fizz render during rendering the render will
not complete correctly because there are inconsistencies with task
counting. This change updates the abort implementation to allow you to
abort from within a render itself. We already landed a similar change
for Flight in #29764
We need a GitHub token to download artifacts from GitHub so
unfortunately codesandboxci will need to revert to the slower process
of building from source for now until it's possible to pass secrets to
codesandboxci.
ghstack-source-id: edab979084
Pull Request resolved: https://github.com/facebook/react/pull/30511
I need to start clarifying where things are really actually Fibers and
where they're not since I'm adding Server Components as a separate type
of component instance which is not backed by a Fiber.
Nothing in the front end should really know anything about what kind of
renderer implementation we're inspecting and indeed it's already not
always a "Fiber" in the legacy renderer.
We typically refer to this as a "Component Instance" but the front end
currently refers to it as an Element as it historically grew from the
browser DevTools Elements tab.
I also moved the renderer.js implementation into the `backend/fiber`
folder. These are at the same level as `backend/legacy`. This clarifies
that anything outside of this folder ideally shouldn't refer to a
"Fiber".
console.js and profilingHooks.js unfortunately use Fibers a lot which
needs further refactoring. The profiler frontend also uses the term
alot.
Second try, seems like you need to explicitly pass secrets to reusable
workflows.
ghstack-source-id: 05ffdae13474dba64119182bf72c15d07f83efd2
Pull Request resolved: https://github.com/facebook/react/pull/30504
When a Fizz render is closing but not yet closed it's possible that
pinged tasks can spawn more work. The point of the closing state is to
allow time to start piping/reading the underlying stream but
semantically the render is finished at that point so work should no
longer happen.
During params parsing for this script, it previously would call out to
CircleCI for a build ID, but this is no longer needed.
ghstack-source-id: 9c70824498
Pull Request resolved: https://github.com/facebook/react/pull/30499
Turns out I had configured the reusable workflow with the wrong `on`
command.
Also removes the workflow_dispatch config from the nightly workflow as
that was not meant to be triggered manually.
ghstack-source-id: 426d07279d
Pull Request resolved: https://github.com/facebook/react/pull/30498
Migrates the last 2 remaining circleci jobs to GH actions. The behavior
of these workflows have been kept the same.
Overview:
- Reusable workflow `runtime_prereleases.yml` added
- Nightly workflow on cron triggers the reusable workflow with the
current HEAD sha
- Manual workflow which can be triggered from the github UI with a
`prerelease_commit_sha` which triggers the reusable workflow
ghstack-source-id: 84ef33c732
Pull Request resolved: https://github.com/facebook/react/pull/30495
When prerendering it can be convenient to abort the prerender while
rendering. However if any Suspense fallbacks have not yet rendered
before the abort happens the fallback itself will error and cause the
nearest parent Suspense boundary to render a fallback instead.
Prerenders are by definition not time critical so the prioritization of
children over fallbacks which makes sense for render isn't similarly
motivated for prerender. Given this, this change updates fallback
rendering during a prerender to attempt the fallback before attempting
children.
Updates this script to download from GH actions instead, to prepare for
moving the cron jobs over to GH actions.
ghstack-source-id: 9bba9f2721e42b508d7fac6604be72906dedd836
Pull Request resolved: https://github.com/facebook/react/pull/30485
Extracts out the code to download builds from GH into its own module so
that it can be reused later.
ghstack-source-id: 26687db971d06339d099d1d5075825efb82cf6b8
Pull Request resolved: https://github.com/facebook/react/pull/30484
**This API is not intended to ship. This is a temporary unstable hook
for internal performance profiling.**
This PR exposes `unstable_useContextWithBailout`, which takes a compare
function in addition to Context. The comparison function is run to
determine if Context propagation and render should bail out earlier.
`unstable_useContextWithBailout` returns the full Context value, same as
`useContext`.
We can profile this API against `useContext` to better measure the cost
of Context value updates and gather more data around propagation and
render performance.
The bailout logic and test cases are based on
https://github.com/facebook/react/pull/20646
Additionally, this implementation allows multiple values to be compared
in one hook by returning a tuple to avoid requiring additional Context
consumer hooks.
Now that we've fully migrated the PR CI workflow (build_and_test) to GH,
we can fully delete the workflow altogether. This will break
https://react-builds.vercel.app/ unfortunately but I'll wait for
acdlite to come back from vacation and work with him to fix it.
The remaining jobs in circleci are for publishing prereleases of React
to npm. I'll work on migrating those next.
ghstack-source-id: 05f346829f
Pull Request resolved: https://github.com/facebook/react/pull/30480
Promotes v2 to the primary workflow file so that we don't double write
to the protected branches.
Note: this may break DiffTrain temporarily, I will fix forward if so
ghstack-source-id: f6505a72f2
Pull Request resolved: https://github.com/facebook/react/pull/30477
Adds back the missing steps with a few tweaks to where previously some
`github` context value was referenced, I changed it to read from the
triggering workflow_run (ie the build on `main`) instead.
ghstack-source-id: 4b0fa135f0
Pull Request resolved: https://github.com/facebook/react/pull/30476
In https://github.com/facebook/react/pull/23316 we fixed a bug where
onload events were missed if they happened too early. This update adds
support for srcset to retrigger the load event. Firefox unfortunately
does not trigger a load even when you assign srcset so this won't work
in every browser when you use srcset without src however it does close a
gap in chrome at least
Unfortunately creating a workflow that depends on another worfklow run
requires it to first be merged into main, so I can't really test porting
this without landing it first.
To do this safely, I've left the original job intact for DiffTrain and
added a forked file. This fork only currently downloads the artifact
from the HEAD commit in GH actions; I've removed the steps that push to
the protected branches for now while I test to see if this works as
expected.
This workflow needs to depend on the runtime_build_and_test workflow
being complete because otherwise it will fail since the artifacts
haven't been built yet.
ghstack-source-id: 0f9cebc525
Pull Request resolved: https://github.com/facebook/react/pull/30472
More or less a straight copy from the circleci config. I spotted some
inefficiencies but will fix those later to make reviewing this easier.
ghstack-source-id: cb3456c602
Pull Request resolved: https://github.com/facebook/react/pull/30406
This was only used for build_and_test which has since been migrated to
gh actions and is now therefore unused. Looks like I missed this during
the previous cleanup.
ghstack-source-id: 278443951e
Pull Request resolved: https://github.com/facebook/react/pull/30467
To handle more cases, always append the synthetic outlined function as a
new child of the module rather than make assumptions about the original
function. This should handle whatever case where the original function
expression may be a child of a variety of parents
ghstack-source-id: 8581edb8be
Pull Request resolved: https://github.com/facebook/react/pull/30466
Addresses follow up feedback from #30446. Since the outlined function is
guaranteed to have a module-scoped unique identifier name, we can
simplify the insertion logic for the outlined function to always emit a
function declaration rather than switch based on the original function
type. This is fine because the outlined function is synthetic anyway.
ghstack-source-id: 0a4d1f7b0a
Pull Request resolved: https://github.com/facebook/react/pull/30464
If a function expression that mutates a global is passed as a prop,
we don't throw an error as we assume it's not called in render.
But if this function expression is captured in an object and passed down
as prop, we throw an error.
ghstack-source-id: 74cacee09f565550007b2e01fa8877ad64ccfbe9
Pull Request resolved: https://github.com/facebook/react/pull/30456
This is a major nit but this avoids an extra stack frame when we're
replaying logs.
Normally the `printToConsole` frame doesn't show up because it'd be
ignore listed.
<img width="421" alt="Screenshot 2024-07-25 at 11 49 39 AM"
src="https://github.com/user-attachments/assets/81334c2f-e19e-476a-871e-c4db9dee294e">
When you expand to show ignore listed frames a ton of other frames show
up.
<img width="516" alt="Screenshot 2024-07-25 at 11 49 47 AM"
src="https://github.com/user-attachments/assets/2ab8bdfb-464c-408d-9176-ee2fabc114b6">
The annoying thing about this frame is that it's at the top of the stack
where as typically framework stuff ends up at the bottom and something
you can ignore. The user space stack comes first.
With this fix there's no longer any `printToConsole` frame.
<img width="590" alt="Screenshot 2024-07-25 at 12 09 09 PM"
src="https://github.com/user-attachments/assets/b8365d53-31f3-43df-abce-172d608d3c9c">
Am I wiling to eat the added complexity and slightly slower performance
for this nit? Definitely.
Following https://github.com/facebook/react/pull/30436
Concurrent by default strategy has been unshipped. Here we clean up the
`allowConcurrentByDefault` path and related logic/tests.
For now, this keeps the `concurrentUpdatesByDefaultOverride` argument in
`createContainer` and `createHydrationContainer` and ignores the value
to prevent more breaking changes to `react-reconciler` in the RC stage.
This enables configuring the name of the requested environment.
When we currently use createTask, we start with a `"use server"`
annotation. This option basically configures that string.
I now also deal with the case when switching environments along the
owner path. If you go from `"Third Party"` to `"Server"` to `"Client"`,
it'll have a task named `"use third party"` at the root, then `"use
server"` and then finally `"use client"`.
We don't really have the concept of a Server Component making a request
during render to then create another Server Component. Really the inner
one should conceptually have the first one as its owner in that case. So
currently the inner one will always have a null owner. We could somehow
connect them in this server-to-server case.
We don't currently have a way to configure the `"use client"` option but
I figured maybe that could be inferred by the server environment that
the Flight Client is executed within.
Note: We did talk before about annotating each stack frame with the
environment. You can effectively do that manually when parsing
`rsc://React/{environment}/` from `captureOwnerStack`. However, we can't
do that natively. At least not without deeper integration. Because it's
the source map that's responsible for the actual function name of each
stack frame - not what we give it at runtime. So for the native stacks,
the task showing the change in environment is more practical.
This way you can use the environment to know where to look for the
source map in case you have multiple server environments.
This becomes part of the public protocol since it's part of what you'll
parse out of the `rsc://React/` prefixed URLs inside of
`captureOwnerStack`.
This lets you customize the filter, for example allowing node_modules or
filter out additional functions that you don't want to include when
sending the stack to the client.
Notably this doesn't filter out Server Components out of the parent
stack. Those are just like a view of the tree by name. Not virtual stack
frames.
https://github.com/facebook/react/pull/30422 broke existing build
shortcuts.
Revert the usage of `names` (`_`) and `type` args.
`yarn build-for-devtools` / `yarn build-for-devtools-dev` / `yarn
build-for-devtools-prod` should all work again.
Moved the bundleType documentation into description so they can be fuzzy
matched. But a build like `yarn build --type FB_WWW_PROD` still works
when matched exactly.
There's probably a better way to document the positional `names` arg in
the `--help` command, but didn't see it when browsing the yargs docs so
let's just fix the existing builds for now.
Now:
```
% yarn build --help
yarn run v1.22.19
$ node ./scripts/rollup/build-all-release-channels.js --help
Options:
--help Show help [boolean]
--version Show version number [boolean]
--releaseChannel, -r Build the given release channel. [string] [choices: "experimental", "stable"]
--index, -i Worker id. [number]
--total, -t Total number of workers. [number]
--ci Run tests in CI [choices: "circleci", "github"]
--type Build the given bundle type. (NODE_ES2015,ESM_DEV,ESM_PROD,NODE_DEV,NODE_PROD,NODE_PROFILING,BUN_DEV,BUN_PROD,FB_WWW_DEV,FB_WWW_PROD,FB_WWW_PROFILING,RN_OSS_DE
V,RN_OSS_PROD,RN_OSS_PROFILING,RN_FB_DEV,RN_FB_PROD,RN_FB_PROFILING,BROWSER_SCRIPT) [string]
--pretty Force pretty output. [boolean]
--sync-fbsource Include to sync build to fbsource. [string]
--sync-www Include to sync build to www. [string]
--unsafe-partial Do not clean ./build first.
```
When a model references a deduped object of a blocked element that has
subsequently been turned into a lazy element, we need to wait for the
lazy element's chunk to resolve before resolving the reference.
Without the fix, the new test failed with the following runtime error:
```
TypeError: Cannot read properties of undefined (reading 'children')
1003 | let value = chunk.value;
1004 | for (let i = 1; i < path.length; i++) {
> 1005 | value = value[path[i]];
| ^
1006 | }
1007 | const chunkValue = map(response, value);
1008 | if (__DEV__ && chunk._debugInfo) {
at getOutlinedModel (packages/react-client/src/ReactFlightClient.js:1005:26)
```
The bug was uncovered after updating React in Next.js in
https://github.com/vercel/next.js/pull/66711.
Previously we would insert new (Arrow)FunctionExpressions as a sibling
of the original function. However this would break in the outlining case
as it would cause the original function expression's parent to become a
SequenceExpression, breaking a bunch of assumptions in the babel plugin.
To get around this, we synthesize a new VariableDeclaration to contain
the newly inserted function expression and therefore insert it as a true
sibling to the original function.
Yeah, it's kinda gross
ghstack-source-id: df13e3b439962b95af4bbd82ef4302624668faf7
Pull Request resolved: https://github.com/facebook/react/pull/30446
I discovered this compiler crash while trying to do an internal sync of
the compiler. Any kind of outlining appears to crash the babel plugin
when the component is a function expression.
ghstack-source-id: 4f717674af91d4d4b730e64cbd7a144b9faab13e
Pull Request resolved: https://github.com/facebook/react/pull/30443
We still filter them before passing from server to client in Flight
Server but when presenting a native stack, we don't need to filter them.
That's left to ignore listing in the presentation.
The stacks are pretty clean regardless thanks to the bottom stack
frames.
We can also unify the owner stack formatters into one shared module
since Fizz/Flight/Fiber all do the same thing. DevTools currently does
the same thing but is forked so it can support multiple versions.
Concurrent by default has been unshipped! Let's clean it up.
Here we remove `forceConcurrentByDefaultForTesting`, which allows us to
run tests against both concurrent strategies. In the next PR, we'll
remove the actual concurrent by default code path.
Addresses discussion at https://github.com/facebook/react/pull/30399#discussion_r1684693021. Once we've constructed scopes it's invalid to use identifier mutable ranges. The only places we can do this which i can find are ValidateMemoizedEffectDeps (which is already flawed and disabled by default) and ValidatePreservedManualMemoization. I added a todo to the former, and fixed up the latter.
The idea of the fix is that for StartMemo dependencies, if they needed to be memoized (identifier.scope != null) then that scope should exist and should have already completed. If they didn't need a scope or can't have one created (eg their range spans a hook), then their scope would be pruned. So if the scope is set, not pruned, and not completed, then it's an error.
For declarations (FinishMemo) the existing logic applies unchanged.
ghstack-source-id: af5bfd88553de3e30621695f9d139c4dc5efb997
Pull Request resolved: https://github.com/facebook/react/pull/30428
Later passes may rely on HIR invariants such as blocks being in RPO or instructions having unique, ascending InstructionIds. However, BuildReactiveScopeTerminalsHIR doesn't currently gurantee this.
This PR updates that pass to first restore RPO, fixup predecessors (the previous logic tried to do this but failed on unreachable blocks, where `markPredecessors()` handles that case), and renumber instructions. Then it walks instructions and scopes to update identifier and scope ranges given the new instruction ids.
ghstack-source-id: 2a99df02ac9d125b202cae369e2dc4dccefb0625
Pull Request resolved: https://github.com/facebook/react/pull/30399
Once we create scopes, we should prefer to use the block structure to identify active scope ranges rather than the scope range. They _should_ always be in sync, but ultimately the block structure determine the active range (ie the id of the 'scope' terminal and the terminal's fallthrough block).
ghstack-source-id: 730b6d1cfaf0eb689d71057c78a48045ac4fb11c
Pull Request resolved: https://github.com/facebook/react/pull/30398
Doing some debugging I noticed that a few of the newer terminals kinds weren't printing the instruction id.
ghstack-source-id: e0e4c96aeefdfe09d3be1527fd7103b4e506eb8e
Pull Request resolved: https://github.com/facebook/react/pull/30397
Stacked on #30427.
Most hooks and such are called inside renders which already have these
on the stack but life-cycles that call out on them are useful to cut off
too.
Typically we don't create JSX in here so they wouldn't be part of owner
stacks anyway but they can be apart of plain stacks such as the ones
prefixes to console logs or printed by error dialogs.
This lets us cut off any React internals below. This should really be
possible using just ignore listing too ideally.
At this point we should maybe just build a Babel plugin that lets us
annotate a function to need to have this name.
The current stack is available in the native UI but that's hidden by
default so you don't see the actual current component on the stack.
This is unlike the native async stacks UI where they're all together.
So we prefix the stack with the current stack first.
<img width="279" alt="Screenshot 2024-07-22 at 10 05 13 PM"
src="https://github.com/user-attachments/assets/8f568fda-6493-416d-a0be-661caf44d808">
---------
Co-authored-by: Ruslan Lesiutin <rdlesyutin@gmail.com>
babel-plugin-idx enforces that its 2nd argument is an arrow function, so
outlining needs to skip over lambdas that are args to idx. This PR adds
a small repro highlighting the issue.
ghstack-source-id: b4627ec552056f33090e2f7bc0536a6006d79d18
Pull Request resolved: https://github.com/facebook/react/pull/30435
To surface any potential conflicts with this plugin, let's install it
into snap so we can surface any runtime errors after compilation
ghstack-source-id: 545eee6fb7f6401e919422581cf64070da581d50
Pull Request resolved: https://github.com/facebook/react/pull/30434
This ensures that we can keep overriding what runtime to use by
resetting modules while still using the automatic JSX plugin. This is
like the "inline requires" transform but just for JSX.
I got sick of trying to figure out workarounds to hide the extra stack
frame that appears due to the wrappers.
Improve command documentation and make it easier to build specific
bundle types
**Before**
```
% yarn build --help
yarn run v1.22.19
$ node ./scripts/rollup/build-all-release-channels.js --help
Options:
--help Show help [boolean]
--version Show version number [boolean]
--releaseChannel, -r Build the given release channel. [string] [choices: "experimental", "stable"]
--index, -i Worker id. [number]
--total, -t Total number of workers. [number]
--ci Run tests in CI [choices: "circleci", "github"]
✨ Done in 0.69s.
```
**After**
```
% yarn build --help
yarn run v1.22.19
$ node ./scripts/rollup/build-all-release-channels.js --help
Options:
--help Show help [boolean]
--version Show version number [boolean]
--releaseChannel, -r Build the given release channel. [string] [choices: "experimental", "stable"]
--index, -i Worker id. [number]
--total, -t Total number of workers. [number]
--bundle Build the given bundle type.
[choices: "NODE_ES2015", "ESM_DEV", "ESM_PROD", "NODE_DEV", "NODE_PROD", "NODE_PROFILING", "BUN_DEV", "BUN_PROD", "FB_WWW_DEV", "FB_WWW_PROD",
"FB_WWW_PROFILING", "RN_OSS_DEV", "RN_OSS_PROD", "RN_OSS_PROFILING", "RN_FB_DEV", "RN_FB_PROD", "RN_FB_PROFILING", "BROWSER_SCRIPT"]
--ci Run tests in CI [choices: "circleci", "github"]
--names Build for matched bundle names. Example: "react-test,index.js". [array]
--pretty Force pretty output. [boolean]
--sync-fbsource Include to sync build to fbsource. [string]
--sync-www Include to sync build to www. [string]
--unsafe-partial Do not clean ./build first. [boolean]
✨ Done in 0.61s.
```
Changes
- Use yargs to document existing options: `pretty`, `sync-fbsource`,
`sync-www`, `unsafe-partial`.
- Move `_` arg to `names` option for consistency with other options and
discoverability through yargs help
- Add `bundle` option in place of `argv.type` that allows choices of any
BundleType to be passed in directly.
This will allow us to parse new flow syntax since the `flow` parser is
no longer updated.
I had to exclude some files and have them fall back to `flow` parser
since they contain invalid graphql syntax that makes the plugin crash.
Stacked on #30410.
If we've parsed another RSC stream on the server from a different RSC
server, while using `findSourceMapURL`, the Flight Client ends up adding
a `rsc://React/` prefix and a numeric suffix to the URL. It's a virtual
file that represents the virtual eval:ed frame in that environment.
If we then see that same stack again, we'd serialize a virtual frame to
another virtual. Meaning `findSourceMapURL` on the client would see the
virtual frame of the intermediate server and it would have to strip it
to figure out what source map to use.
This PR strips it in the Server if we see a virtual frame. At each new
client it always refers to the original stack.
We don't have to do this. We could leave it to each `findSourceMapURL`
implementation and `captureOwnerStack` parser to recursively strip each
layer. It could maybe be useful to have the environment name in the
virtual frame to know which server to look for the source map in.
Stacked on #30410.
Use "owner stacks" as the appended component stack if it is available on
the Fiber. This will only be available if the enableOwnerStacks flag is
on. Otherwise it fallback to parent stacks. In prod, there's no owner so
it's never added there.
I was going back and forth on whether to inject essentially
`captureOwnerStack` as part of the DevTools hooks or replicate the
implementation but decided to replicate the implementation.
The DevTools needs all the same information from internals to implement
owner views elsewhere in the UI anyway so we're not saving anything in
terms of the scope of internals. Additionally, we really need this
information for non-current components as well like "rendered by" views
of the currently selected component.
It can also be useful if we need to change the format after the fact
like we did for parent stacks in:
https://github.com/facebook/react/pull/30289
Injecting the implementation would lock us into specifics both in terms
of what the core needs to provide and what the DevTools can use.
The implementation depends on the technique used in #30369 which tags
frames to strip out with `react-stack-bottom-frame`. That's how the
implementation knows how to materialize the error if it hasn't already.
Firefox:
<img width="487" alt="Screenshot 2024-07-21 at 11 33 37 PM"
src="https://github.com/user-attachments/assets/d3539b53-4578-4fdd-af25-25698b2bcc7d">
Follow up: One thing about this view is that it doesn't include the
current actual synchronous stack. When I used to append these I would
include both the real current stack and the owner stack. That's because
the owner stack doesn't include the name of the currently executing
component. I'll probably inject the current stack too in addition to the
owner stack. This is similar to how native Async Stacks are basically
just appended onto the current stack rather than its own.
Stacked on #30401.
Previously we were transferring the original V8 stack trace string to
the client and then parsing it there. However, really the server is the
one that knows what format it is and it should be able to vary by server
environment.
We also don't use the raw string anymore (at least not in
enableOwnerStacks). We always create the native Error stacks.
The string also made it unclear which environment it is and it was
tempting to just use it as is.
Instead I parse it on the server and make it a structured stack in the
transfer format. It also makes it clear that it needs to be formatted in
the current environment before presented.
Stacked on https://github.com/facebook/react/pull/30400 and
https://github.com/facebook/react/pull/30369
Previously we were using fake evals to recreate a stack for console
replaying and thrown errors. However, for owner stacks we just used the
raw string that came from the server.
This means that the format of the owner stack could include different
formats. Like Spidermonkey format for the client components and V8 for
the server components. This means that this stack can't be parsed
natively by the browser like when printing them as error like in
https://github.com/facebook/react/pull/30289. Additionally, since
there's no source file registered with that name and no source mapping
url, it can't be source mapped.
Before:
<img width="1329" alt="before-firefox"
src="https://github.com/user-attachments/assets/cbe03f9c-96ac-48fb-b58f-f3a224a774f4">
Instead, we need to create a fake stack like we do for the other things.
That way when it's printed as an Error it gets source mapped. It also
means that the format is consistently in the native format of the
current browser.
After:
<img width="753" alt="after-firefox"
src="https://github.com/user-attachments/assets/b436f1f5-ca37-4203-b29f-df9828c9fad3">
So this is nice because you can just take the result from
`captureOwnerStack()` and append it to an `Error` stack and print it
natively. E.g. this is what React DevTools will do.
If you want to parse and present it yourself though it's a bit awkward
though. The `captureOwnerStack()` API now includes a bunch of
`rsc://React/` URLs. These don't really have any direct connection to
the source map. Only the browser knows this connection from the eval.
You basically have to strip the prefix and then manually pass the
remainder to your own `findSourceMapURL`.
Another awkward part is that since Safari doesn't support eval sourceURL
exposed into `error.stack` - it means that `captureOwnerStack()` get an
empty location for server components since the fake eval doesn't work
there. That's not a big deal since these stacks are already broken even
for client modules for many because the `eval-source-map` strategy in
Webpack doesn't work in Safari for this same reason.
A lot of this refactoring is just clarifying that there's three kind of
ReactComponentInfo fields:
- `stack` - The raw stack as described on the original server.
- `debugStack` - The Error object containing the stack as represented in
the current client as fake evals.
- `debugTask` - The same thing as `debugStack` but described in terms of
a native `console.createTask`.
Ideally we wouldn't need to filter out React internals and it'd just be
covered by ignore listing by any downstream tool. E.g. a framework using
captureOwnerStack could have its own ignore listing. Printed owner
stacks would get browser source map ignore-listing. React DevTools could
have its own ignore list for internals. However, it's nice to be able to
provide nice owner stacks without a bunch of noise by default.
Especially on the server since they have to be serialized.
We currently call each function that calls into user space and track its
stack frame. However, this needs code for checking each one and doesn't
let us work across bundles.
Instead, we can name each of these frame something predictable by giving
the function a name.
Unfortunately, it's a common practice to rename functions or inline them
in compilers. Even if we didn't, others downstream from us or a dev-mode
minifier could. I use this `.bind()` trick to avoid minifying these
functions and ensure they get a unique name added to them in all
browsers. It's not 100% fool proof since a smart enough compiler could
also discover that the `this` value is not used and strip out the
function and then inline it but nobody does this yet at least.
This lets us find the bottom stack easily from stack traces just by
looking for the name.
The download job for sizebot requires both modules from the root repo
but also has a nested yarn lockfile in scripts/release. Calculate the
hash for the cache using both lockfiles.
ghstack-source-id: fc1703b547ab906ee244cfa3540414a6df8c660e
Pull Request resolved: https://github.com/facebook/react/pull/30393
Updates the prettier config to format all `.ts` and `.tsx` files in the
repo using the existing defaults and removing overrides.
The first commit in this PR contains the config changes, the second is
just the result of running `yarn prettier-all`.
Now that the job is migrated to GH, we can remove this from circleci.
Note that sizebot still comments on this PR.
ghstack-source-id: 337661e3b00d3d3686a539bf0877d8526b0f15b9
Pull Request resolved: https://github.com/facebook/react/pull/30387
Wires up sizebot in gh actions. I also fixed sizebot incorrectly
reporting that ReactAllWarnings was deleted.
ghstack-source-id: d3b1bb2088651409e8656c66f1eb28ab534a0604
Pull Request resolved: https://github.com/facebook/react/pull/30380
Updates the forked script to download build artifacts from GitHub. Note
that this PR just adds the script, it does not add it to GH actions yet.
ghstack-source-id: 08b0d2f93a88d55386e43a7d1bf88a67a117e899
Pull Request resolved: https://github.com/facebook/react/pull/30376
This PR just copies the original file without any modifications for
easier review.
The original script makes assumptions about CircleCI that are difficult
to untangle. So let's fork this file temporarily for GitHub actions.
Later on we will remove the original and rename this fork back to the
original naming.
ghstack-source-id: 0ce078538e76349d9ecb69ffc1c352e24390c426
Pull Request resolved: https://github.com/facebook/react/pull/30374
Adds an _ prefix to temporary build parts from parallelization to allow
easier merging in later passes.
ghstack-source-id: 714da85972e138d389224f67601dc7aaa6676e11
Pull Request resolved: https://github.com/facebook/react/pull/30385
Build artifacts are uniquely associated to a single workflow run, so
appending the sha was unnecessary. I originally included it to make it
easier to download later but this turns out to be unneeded.
Drops the sha suffix to make downloading the artifact in a separate
script / workflow more straightforward.
ghstack-source-id: 36ac4df4c3
Pull Request resolved: https://github.com/facebook/react/pull/30364
Addresses a follow-up from the previous PR. Destructured function params are currently not eagerly promoted to temporaries: we wait until PromotedUsedTemporaries. But params _always_ have to be named, so we can promote when constructing HIR.
ghstack-source-id: a6f665762ebcb7b06b118fcaf7515b8021645eae
Pull Request resolved: https://github.com/facebook/react/pull/30332
Implements general-purpose function outlining. Specifically, anonymous function expressions which have no dependencies/context variables are extracted into named top-level functions. The original function expression is replaced with a `LoadGlobal` of the generated name.
Note that the architecture is designed to allow very general purpose forms of outlining, though we currently are very conservative in what we outline. Specifically, the outlining allows annotating functions with an optional ReactiveFunctionType, which if set will cause the outlined function to get compiled as that type. So we could for example outline a helper hook or helper component, set the type, and then have the hook/component get memoized as well. For now though we just outline with no type set, and generate the function as-is without running it through compilation.
ghstack-source-id: 2a7da6c8e85c3f8becb22d3869d9b6200f7db126
Pull Request resolved: https://github.com/facebook/react/pull/30331
Refactors Program.ts to first traverse the `Program` node and build up a queue of functions to visit, then iterate that queue and compile the functions. This doesn't change behavior, but allows the next diff to add additional items to the queue during compilation (for function outlining).
ghstack-source-id: 858527c30ccc26b3aa6fe75a4746fce0820b316f
Pull Request resolved: https://github.com/facebook/react/pull/30330
Fixture demonstrating a case where we can "outline" a function expression.
ghstack-source-id: 836471518f0ff14d16f7b7bbf2e8900660896e97
Pull Request resolved: https://github.com/facebook/react/pull/30329
Stores the Babel `Scope` object for the current function on the Environment, allowing access later for generating new globally unique names. The idea is to expose a small subset of the capabilities of the Scope API via Environment, so that the rest of the compiler remains decoupled from Babel. Ideally we'd use our own Scope implementation too, but we can punt on that for now since the parts we're using (global id generation) seem pretty reliable.
ghstack-source-id: 37f7113b11fe980688dae423883cf6b8890e77be
Pull Request resolved: https://github.com/facebook/react/pull/30328
Now that these run in GH, we can remove these jobs from the circleci
build_and_test workflow to speed up the remaining jobs left in circleci
since this was the long pole.
I have left the definition of these jobs in tact however, as they are
used for devtools_regression_tests which has yet to be migrated to GH.
ghstack-source-id: 6f4ed3efa2
Pull Request resolved: https://github.com/facebook/react/pull/30352
The tests for the build currently take about 3.5 minutes and is at the
moment the long pole for the whole workflow. By sharding we can make
this workflow faster and save about a minute or so in overall wall time.
ghstack-source-id: c23df7b6d7
Pull Request resolved: https://github.com/facebook/react/pull/30349
Safari has a behavior (bug) where when you consturct an Image in
javascript if you set srcset before properties for `sizes` the brwoser
will download the largest image size because it starts to load before
you communicate the sizes information.
https://x.com/OliverJAsh/status/1812408504444989588?t=CVHPqBaUiF5-6DBPGERTDA
There are likely other combinations or property order assignment that
can cause problems such as setting crossorigin after assigning src or
srcset. Conceptually we should withold the src and srcSet from the Image
instance until last so all relevant other properties can be assigned
before actually initiating any network activity.
This is an unforunate amount of code for what is realistically a bug in
Browsers but it should allow us to avoid weird regressions depending on
prop object order.
I didn't change the preload prop order because I don't believe preload
links have the same issue (they are not fetched as eagerly I believe).
One nice benefit of this change though is the img case can move higher
in the switch which is likely optimal given it's a relatively common
tag. Previously it was as low as it was because it was part of the void
element set so it couldn't be elevated without elevating less common
tags
---------
Co-authored-by: Jan Kassens <jan@kassens.net>
I'm experimenting with a new pass that sometimes creates scopes with early returns earlier in the pipeline, but there are a few passes that assume that can't happen. This PR is updating those passes just to be more resilient to help unblock experimentation.
ghstack-source-id: a9e348181ddad1a1e936ef023b5d5ee44aaf3d8c
Pull Request resolved: https://github.com/facebook/react/pull/30333
We have an experimental mode where we generate scopes for simple phi values, even if they aren't subsequently mutated. This mode was incorrectly generating scope ranges, leaving the start at 0 which is invalid. The fix is to allow non-zero identifier ranges to overwrite the scope start (rather than taking the min) if the scope start is still zero.
ghstack-source-id: ecbb04c96ed4de62f781e48cda46309c42aa07e0
Pull Request resolved: https://github.com/facebook/react/pull/30321
---
Adding an experimental / donotuse flag for small Meta internal usecase
ghstack-source-id: 908ef1e150c9fef1347616c9c4dc6bf3316900b0
Pull Request resolved: https://github.com/facebook/react/pull/30342
---
The current version of `@babel/generator` used by playground has some bugs (see https://github.com/babel/babel/issues/10966)
```js
// Try pasting this into playground
function useFoo(a, b) {
return (a ?? b) == c;
}
// Current playground output
function useFoo(a, b) {
return a ?? b == c;
}
```
We previously locked babel library versions to be compatible with the oldest Meta internal usages. Now that both compiler and eslint plugins are bundled with rollup, this shouldn't be necessary.
ghstack-source-id: fa20d676b526d279817d1488f117262aa0869622
Pull Request resolved: https://github.com/facebook/react/pull/30341
---
* panicThreshold: `all_errors` -> `none`
* inject an error logger through compiler config (instead of using exceptions)
We currently report at most one lint warning per file, this lets us exhaustively report all available ones (see new
test fixture for example)
ghstack-source-id: 5299315574d11929efc39ee8f6033e3035d1e378
Pull Request resolved: https://github.com/facebook/react/pull/30336
## Summary
This PR fixes the `fastAddProperties` function. Now it nullifies a prop
if it was defined in one of the items of a style array, but then set to
`undefined` or `null` in one of the subsequent items. E.g. `style:
[{top: 0}, {top: undefined}]` should evaluate to `{top: null}`. Also
added a test case for that.
## How did you test this change?
```
yarn test packages/react-native-renderer -r=xplat --variant=false
yarn test packages/react-native-renderer -r=xplat --variant=true
yarn flow native
```
Unfortunately, Firefox doesn't include the name of a function in stack
traces if you set it as either `.name` or `.displayName` at runtime.
Only if you include it declarative.
We also can't include it into a named function expression because not
all possible names are expressible declaratively. E.g. spaces or
punctuations.
However, we can express any name if it's an object property and since
object properties now give their name declarative to the function
defined inside of them, we can declaratively express any name this way.
The interstital characters in our link header tracking are not
contributing to the remaining capacity calculation so when a lot of
inditidual links are present in the link header it can allow an
overflowing link header to be included. This change corrects the math so
it properly prevents overflow.
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
A proposed fix for the bug described in
https://github.com/facebook/react/issues/25967
## How did you test this change?
See the issue linked above, test scenario included in the code sandbox:
https://codesandbox.io/s/fervent-ives-0vm9es?file=/src/App.jsx
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
Stacked on #30308.
This is now a noop module so we can stop applying the transform of
console.error using the Babel plugin in the mainline builds. I'm keeping
the transform for RN/WWW for now although it might be nice if the
transform moved into those systems as it gets synced instead of keeping
it upstream.
In jest tests we're already not running the forks for RN/WWW so we don't
need it at all there.
React transpiles some of its own `console.error` calls into a helper
that appends component stacks to those calls. However, this doesn't
cover user space `console.error` calls - which includes React helpers
that React has moved into third parties like createClass and prop-types.
The idea is that any user space component can add a warning just like
React can which is why React DevTools adds them too if they don't
already exist. Having them appended in both places is tricky because now
you have to know whether to remove them from React's logs.
Similarly it's often common for server-side frameworks to forget to
cover the `console.error` logs from other sources since React DevTools
isn't active there. However, it's also annoying to get component stacks
clogging the terminal - depending on where the log came from.
In the future `console.createTask()` will cover this use case natively
and when available we don't append them at all.
The new strategy relies on either:
- React DevTools existing to add them to React logs as well as third
parties.
- `console.createTask` being supported and surfaced.
- A third party framework showing the component stack either in an Error
Dialog or appended to terminal output.
For a third party to be able to implement this they need to be able to
get the component stack. To get the component stack from within a
`console.error` call you need to use the `React.captureOwnerStack()`
helper which is only available in `enableOwnerStacks` flag. However,
it's possible to polyfill with parent stacks using internals as a stop
gap. There's a question of whether React 19 should just go out with
`enableOwnerStacks` to expose this but regardless I think it's best it
doesn't include component stacks from the runtime for consistency.
In practice it's not really a regression though because typically either
of the other options exists and error dialogs don't implement
`console.error` overrides anyway yet. SSR terminals might miss them but
they'd only have them in DEV warnings to begin with an a subset of React
warnings. Typically those are either going to happen on the client
anyway or replayed.
Our tests are written to assert that component stacks work in various
scenarios all over the place. To ensure that this keeps working I
implement a "polyfill" that is similar to that expected a server
framework might do - in `assertConsoleErrorDev` and `toErrorDev`.
This PR doesn't yet change www or RN since they have their own forks of
consoleWithStackDev for now.
Merges most workflows into a single workflow, which should make the
"Checks" tab easier to visualize sincee it will all be graphed in a
single interface. There should be no change in behavior, this is a
mechanical change.
ghstack-source-id: a5241a2420
Pull Request resolved: https://github.com/facebook/react/pull/30324
Quick change to standardize on a single timezone across all workflows
and to use the same version of node (18.20.1).
Also updates .nvmrc
ghstack-source-id: e1d43006ec
Pull Request resolved: https://github.com/facebook/react/pull/30323
In www, the experimental versions get a .modern.js or .classic.js prefix
and get copied into the same folder. In RN, they don't seem to have
.modern.js and .classic.js versions so they end up getting the same
name.
sebmarkbage's theory is that what happens is that they then override
the file that was already there. So depending on if experimental or
stable build finishes first you get a different version at the end.
It doesn't make sense to use `__EXPERIMENTAL__` for flags in native-fb
since there's no modern/classic split there. So that flag should just be
hardcoded to true or false and then it doesn't matter which one finishes
first.
We don't support experimental builds in OSS RN neither so the same thing
could happen with
[`enableOwnerStacks`](5dcf3ca8d4/packages/shared/forks/ReactFeatureFlags.native-oss.js (L60)).
You can see that the build errors in the previous PR but passes after
these flag changes.
ghstack-source-id: d10f37bcea
Pull Request resolved: https://github.com/facebook/react/pull/30322
I noticed that the www-modern builds pick up the `.experimental.js`
entry points but these flags that are associated with these exports are
not enabled in www, so it gets the wrong builds.
This file is just a clone over the stable `ReactServer.js` one. We
should probably do the reexport pattern instead.
The full stack is the current execution stack (`new Error().stack`) +
the current owner stack (`React.captureOwnerStack()`).
The idea with the top frame was that when we append it to console.error
we'd include both since otherwise the true reason would be obscured
behind the little `>` to expand. So we'd just put both stack front and
center. By adding this into getCurrentStack it was easy to use the same
filtering. I never implemented in Fizz or Flight though.
However, with the public API `React.captureOwnerStack()` it's not
necessary to include the current stack since you already have it and
you'd have filtering capabilities in user space too.
Since I'm removing the component stacks from React itself we no longer
need this. It's expected that maybe RDT or framework polyfill would
include this same technique though.
While the goal is to remove legacy context completely, I think we can
already land the removal of legacy context for function components. I
didn't even know this feature existed until reading the code recently.
The win is just a couple of property lookups on function renders, but it
trims down the API already as the full removal will likely still take a
bit more time.
www: Starting with enabled test renderer and a feature flag for
production rollout.
RN: Not enabled, will follow up on this.
This avoids potential differences between Git versions.
Having a guarantee unique hash isn't neccessary as it's just
informational and we have the date in the version string as well.
This code is getting deleted in #30313 anyway but it should've been
gated all along.
This code exists to basically manually transpile console.error to
consoleWithStackDev because the transpiler doesn't work on `.apply` or
`.bind` or the dynamic look up. We only apply the transform in DEV so we
should've only done this in DEV.
Otherwise these logs get silenced in prod.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
Now that HostContext determination for Fabric is a DEV-only behavior, we
can move the HostContext determination to resolve from the ViewConfig
for a given type. Doing this will allow arbitrary types to register
themselves as potential parents of raw text string children. This is the
first of two diffs for react as we'll:
1. Add the new property to the ViewConfig types
2. Update React Native to include the `supportsRawText` property for
`RCTText`, `RCTVirtualText`, `AndroidTextInput`, etc.
3. Switch the behavior of react to read from the ViewConfig rather than
a static list of types.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
- yarn test
- yarn test --prod
- Pulled change into react-native, added `supportsRawText` props to
RCTText, RCTVirtualText, etc. ViewConfigs and confirmed everything type
checks.
I'm pretty sure this is completely unnecessary even in www and RN
because it's only useful if you use the mock scheduler which typically
only we do in our own tests. But all our tests pass so unless www/RN
does something with it, I don't think this is used.
Also remove unnecessary `__DEV__` check. If it gets pulled in prod, we'd
want to know about it.
Object literals should be faster at least on React Native with Hermes as
the JS engine.
It might also be interesting to confirm the old comments in this file
from years ago are even still valid. Creating an object from a literal
should be a simpler operation.
It's a bit unfortunate that this introduces a bunch of copied code, but
since we rearely update the fields on fibers, this seems like an okay
tradeoff for a hot code path. An alternative would be some sort of macro
system, but that doesn't seem worth the extra complexity.
We're removing this wrapper from the mainline but RN is still using
component stacks to filter out warnings.
This is unfortunate since it'll be hard to keep track of the interplay
with these, DevTools and how you're supposed to implement error dialogs
in userspace.
Currently we're printing parent stacks at the end of DOM nesting even
with owner stacks enabled. That's because the context of parent tree is
relevant for determining why two things are nested. It might not be
sufficient to see the owner stack alone.
I'm trying to get rid of parent stacks and rely on more of the plain
owner stacks or ideally console.createTask. These are generally better
anyway since the exact line for creating the JSX is available. It also
lets you find a parent stack frame that is most relevant e.g. if it's
hidden inside internals.
For DOM nesting there's really only two stacks that are relevant. The
creation of the parent and the creation of the child. Sometimes they're
close enough to be the same thing. Such as for parents that can't have
text children or when the ancestor is the direct parent created at the
same place (same owner).
Sometimes they're far apart. In this case I add a second console.error
within the context of the ancestor. That way the second stack trace can
be used to read the stack trace for where it was created.
To preserve some parent context I now print the parent stack in a diff
view format using the logic from hydration diffs. This includes some
siblings and props for context.
<img width="756" alt="Screenshot 2024-07-10 at 12 21 38 AM"
src="https://github.com/facebook/react/assets/63648/0843133d-cc7a-4ecc-91c0-f46ae8e99f20">
Text Nodes:
<img width="749" alt="Screenshot 2024-07-10 at 12 37 40 AM"
src="https://github.com/facebook/react/assets/63648/ee377d82-54ee-450a-99d1-fcc3ef290d59">
---------
Co-authored-by: tjallingt <tjallingt@gmail.com>
For environments that still have legacy contexts available, this adds a
warning to make the remaining call sites easier to locate and encourage
upgrades.
This marker can then be emitted as a getter. When this object gets
accessed we use a special error to let the user know what is going on.
<img width="1350" alt="Screenshot 2024-07-08 at 10 13 46 PM"
src="https://github.com/facebook/react/assets/63648/e3eb698f-e02d-4394-a051-ba9ac3236480">
When you click the `...`:
<img width="1357" alt="Screenshot 2024-07-08 at 10 13 56 PM"
src="https://github.com/facebook/react/assets/63648/4b8ce1cf-d762-49a4-97b9-aeeb1aa8722c">
I also increased the object limit in console logs. It was arbitrarily
set very low before.
These limits are per message. So if you have a loop of many logs it can
quickly add up a lot of strain on the server memory and the client. This
is trying to find some tradeoff. Unfortunately we don't really do much
deduping in these logs so with cyclic objects it ends up maximizing the
limit and then siblings aren't logged.
Ideally we should be able to lazy load them but that requires a lot of
plumbing to wire up so if we can avoid it we should try to. If we want
to that though one idea is to use the getter to do a sync XHR to load
more data but the server needs to retain the objects in memory for an
unknown amount of time. The client could maybe send a signal to retain
them until a weakref clean up but even then it kind of needs a heartbeat
to let the server know the client is still alive. That's a lot of
complexity. There's probably more we can do to optimize deduping and
other parts of the protocol to make it possible to have even higher
limits.
Only for parent stacks. This ensures that we can use the regular
mechanism for appending stack traces. E.g. you can polyfill it.
This is mainly so that I can later remove the automatic appending.
Component stacks have a similar problem to the problem with keyPath
where we had to move it down and set it late right before recursing.
Currently we work around that by popping exactly one off when something
suspends. That doesn't work with the new server stacks being added which
are more than one. It also meant that we kept having add a single frame
that could be popped when there shouldn't need to be one.
Unlike keyPath component stacks has this weird property that once
something throws we might need the stack that was attempted for errors
or the previous stack if we're going to retry and just recreate it.
I've tried a few different approaches and I didn't like either but this
is the one that seems least problematic.
I first split out renderNodeDestructive into a retryNode helper. During
retries only retryNode is called. When we first discover a node, we pass
through renderNodeDestructive.
Instead of add a component stack frame deep inside renderNodeDestructive
after we've already refined a node, we now add it before in
renderNodeDestructive. That way it's only added once before being
attempted. This is similar to how Fiber works where in ChildFiber we
match the node once to create the instance and then later do we attempt
to actually render it and it's only the second part that's ever retried.
This unfortunately means that we now have to refine the node down to
element/lazy/thenables twice. To avoid refining the type too I move that
to be done lazily.
We already added this for other thrown errors, not just console.errors.
There's a production form of this. We just missed adding this context.
Mainly the best context is the line number though which comes from owner
stacks.
Before:
<img width="844" alt="Screenshot 2024-07-04 at 3 20 34 PM"
src="https://github.com/facebook/react/assets/63648/0fd8a53f-538a-4429-a4cf-c22f85a09aa8">
After:
<img width="845" alt="Screenshot 2024-07-05 at 6 08 28 PM"
src="https://github.com/facebook/react/assets/63648/7b9da13a-fa97-4581-9899-06de6fface65">
Firefox:
<img width="1338" alt="Screenshot 2024-07-05 at 6 09 50 PM"
src="https://github.com/facebook/react/assets/63648/f2eb9f2a-2251-408f-86d0-b081279ba378">
The first log doesn't get a stack because it's logged before DevTools
boots up and connects which is unfortunate.
The second log already has a stack printed by React (this is on stable)
it gets replaced by our object now.
The third and following logs don't have a stack and get one appended.
I only turn the stack into an error object if it matches what we would
emit from DevTools anyway. Otherwise we assume it's not React. Since I
had to change the format slightly to make this work, I first normalize
the stack slightly before doing a comparison since it won't be 1:1.
This was missed in the mount dev dispatcher. It was only in the rerender
dispatcher which means that it was only logged during the rerender.
Since DevTools can hide logs during rerenders, this hid the warning in
StrictMode.
This is the same change as in #30289 but for the main runtime - e.g.
parent stacks in errorInfo.componentStack, appended stacks to
console.error coming from React itself and when we add virtual frames to
owner stacks.
Since we don't add location information these frames look weird to some
stack parsers - such as the native one. This is an existing issue when
you want to use some off-the-shelf parsers to parse production component
stacks for example.
While we won't add Error objects to logs ourselves necessarily, some
third party could want to do the same thing we do in DevTools and so we
should provide the same capability to just take this trace and print it
using an Error object.
Stacked on #30197.
This is similar to #30182 and #21610 in Fizz.
Track the current owner/stack/task on the task. This tracks it for
attribution when serializing child properties.
This lets us provide the right owner and createTask when we
console.error from inside Flight itself. This also affects the way we
print those logs on the client since we need the owner and stack. Now
console.errors that originate on the server gets the right stack on the
client:
<img width="760" alt="Screenshot 2024-07-03 at 6 03 13 PM"
src="https://github.com/facebook/react/assets/63648/913300f8-f364-4e66-a19d-362e8d776c64">
Unfortunately, because we don't track the stack we never pop it so it'll
keep tracking for serializing sibling properties. We rely on "children"
typically being the last property in the common case anyway. However,
this can lead to wrong attribution in some cases where the invalid
property is a next property (without a wrapping element) and there's a
previous element that doesn't. E.g. `<ClientComponent title={<div />}
invalid={nonSerializable} />` would use the div as the attribution
instead of ClientComponent.
I also wrap all of our own console.error, onError and onPostpone in the
context of the parent component. It's annoying to have to remember to do
this though.
We could always wrap the whole rendering in such as context but it would
add more overhead since this rarely actually happens. It might make
sense to track the whole current task instead to lower the overhead.
That's what we do in Fizz. We'd still have to remember to restore the
debug task though. I realize now Fizz doesn't do that neither so the
debug task isn't wrapping the console.errors that Fizz itself logs.
There's something off about that Flight and Fizz implementations don't
perfectly align.
Wire up owner stacks in Flight to the shared internals. This exposes it
to `captureOwnerStack()`.
In this case we install it permanently as we only allow one RSC renderer
which then supports async contexts. Same thing we do for owner.
This also ends up adding it to errors logged by React through
`consoleWithStackDev`. The plan is to eventually remove that but this is
inline with what we do in Fizz and Fiber already.
However, at the same time we've instrumented the console so we need to
strip them back out before sending to the client. This lets the client
control whether to add the stack back in or allowing
`console.createTask` to control it.
This is another reason we shouldn't append them from React but for now
we hack it by removing them after the fact.
Defaults to true in browser builds, otherwise defaults to false. The
assumption is that the server logs will already contain a log from the
original Flight server.
We currently always replay console logs but this leads to duplicates on
the server by default when you use SSR, because the Flight Client on the
server replays the logs. This can be nice since those logs gets badged.
It can also be nice if they're running in separate servers but when
they're logging to the same stream it's annoying. Which is really the
typical set up so we should just make that the default but leave it
configurable.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Fix how devtools handles URLs. It
- cannot handle relative source map URLs `//# sourceMappingURL=x.map`
- cannot recognize Windows style URLs
## How did you test this change?
works on my side
Use the same normalizeCodeLocInfo that we use everywhere else.
We should actually test the component stack itself. Not just that it
exists. This was causing false passes.
However, the logic was also wrong before because it wouldn't always
strip out the last line so wouldn't accurately normalize it. Leading to
false failures as well.
It can be efficient to accept raw string chunks to pass through a stream
instead of encoding them into a binary copy first.
Previously our Flight parsers didn't accept receiving string chunks.
That's partly because we sometimes need to encode binary chunks anyway
so string only transport isn't enough but some chunks can be strings.
This adds a partial ability for chunks to be received as strings.
However, accepting strings comes with some downsides. E.g. if the
strings are split up we need to buffer it which compromises the perf for
the common case. If the chunk represents binary data, then we'd need to
encode it back into a typed array which would require a TextEncoder
dependency in the parser. If the string chunk represents a byte length
encoded string we don't know how many unicode characters to read without
measuring them in terms of binary - also requiring a TextEncoder.
This PR is mainly intended for use for pass-through within the same
memory. We can simplify the implementation by assuming that any string
chunk is passed as the original chunk. This requires that the server
stream config doesn't arbitrarily concatenate strings (e.g. large
strings should not be concatenated which is probably a good heuristic
anyway). It also means that this is not suitable to be used with for
example receiving string chunks on the client by passing them through
SSR hydration data - except if the encoding that way was only used with
chunks that were already encoded as strings by Flight.
Web streams mostly just work on binary data anyway so they can't use
this.
In Node.js streams we concatenate precomputed and small strings into
larger buffers. It might make sense to do that using string ropes
instead. However, in the meantime we can at least pass large strings
that are outside our buffer view size as raw strings. There's no benefit
to us eagerly encoding those.
Also, let Node accept string chunks as long as they're following our
expected constraints. This lets us test the mixed protocol using
pass-throughs. This can also be useful when the RSC server is in the
same environment as the SSR server as they don't have to go from strings
to typed arrays back to strings.
Now we can also use this in the pass-through used in renderToMarkup.
This lets us avoid the dependency on TextDecoder/TextEncoder in that
package.
The issue reported in #30172 was fixed with #29823. The PR also added
the test [`should resolve deduped objects that are themselves
blocked`](6d2a97a711/packages/react-server-dom-webpack/src/__tests__/ReactFlightDOMBrowser-test.js (L348-L393)),
which tests a similar scenario. However, the existing test would have
also succeeded before applying the changes from #29823. Therefore, I
believe it makes sense to add an additional test `should resolve deduped
objects in nested children of blocked models`, which does not succeed
without #29823, to prevent regressions.
Stacked on #30170.
This lets us track Server Component parent stacks in Fizz which also
lets us track the correct owner stack for lazy.
In Fiber we're careful not to make any DEV only fibers but since the
ReactFizzComponentStack data structures just exist for debug meta data
anyway we can just expand on that.
Stacked on #30132.
This way we can get parent and owner stacks from the error.
This forces us to confront multiple errors and whether or not a Flight
error that ends up being unobservable needs to really reject the render.
This implements stashing of Flight errors with a digest and only errors
if they end up erroring the Fizz render too. At this point they'll have
parent stacks so we can surface those.
When we added component stacks to Fizz in prod it severely slowed down
common cases where you intentionally are throwing error for purposes of
client rendering. Our parent component stack generation is very slow
since call components with fake errors to generate them.
Therefore we disabled them in prod but included them in prerenders.
https://github.com/facebook/react/pull/27850
However, we still kept generating data structures for them and the code
still exists there for the prerenders. We could stop generating the data
structures which are not completely free but also not crazy bad.
What we can do instead is just lazily generate the component stacks.
This is in fact what plain stacks do anyway. This doesn't work as well
in Fiber because the data structures are live but on the server they're
immutable so it's fine to do it later as well.
That way you can choose to not read this getter for intentionally thrown
errors - after inspecting the Error object - yet still get component
stacks in prod for other errors.
Summary: Compiler pass tabs are bolded when their contents have changed from previous passes; but currently the HIR and JS tabs are unbolded. Conceptually they should be, if HIR is "changed" from the source code and JS is "changed" from the last IR phase.
In addition, the "show diff" option doesn't make a ton of sense for tabs that either aren't part of the pipeline (EnvironmentConfig) or (maybe more controversially, but imo) passes where the IR representation has changed since the last pass (BuildReactiveFunctions). This diff drops the button from those tabs.
ghstack-source-id: 1d67e2f371a8c75792f7f6450f52ecbf79720c00
Pull Request resolved: https://github.com/facebook/react/pull/30151
Summary: The playground currently has limited support for Flow files--it tries to parse them if the // flow sigil is on the fist line, but this is often not the case for files one would like to inspect in practice. more importantly, component syntax isn't supported even then, because it depends on the Hermes parser.
This diff improves the state of flow support in the playground to make it more useful: when we see `flow` anywhere in the file, we'll assume it's a flow file, parse it with the Hermes parser, and disable typescript-specific features of Monaco editor.
ghstack-source-id: b99b1568d7de602dd70d8cf1d8110d62530cf43b
Pull Request resolved: https://github.com/facebook/react/pull/30150
Stacked on #30142.
This tracks owners and their stacks in DEV in Fizz. We use the
ComponentStackNode as the data structure to track this information -
effectively like ReactComponentInfo (Server) or Fiber (Client). They're
the instance.
I then port them same logic from ReactFiberComponentStack,
ReactFiberOwnerStack and ReactFiberCallUserSpace to Fizz equivalents.
This gets us both owner stacks from `captureOwnerStack()`, as well as
appended to console.errors logged by Fizz, while rendering and in
onError.
Summary: In change-detection mode, we previously were spreading the contents of the computation block into the result twice. Other babel passes that cause in-place mutations of the AST would then be causing action at a distance and breaking the overall transform result. This pr creates clones of the nodes instead, so that mutations aren't reflected in both places where the block is used.
ghstack-source-id: b78def8d8d1b8f9978df0a231f64fdeda786a3a3
Pull Request resolved: https://github.com/facebook/react/pull/30148
We use this to encode the binary length of a large string without
escaping it. This is really kind of optional though. This lets a Server
that can't encode strings but just pass them along able to emit RSC -
albeit a less optimal format.
The only build we have that does that today is react-html but the FB
version of Flight had a similar constraint.
It's still possible to support binary data as long as
byteLengthOfBinaryChunk is implemented which doesn't require a text
encoder. Many streams (including Node streams) support binary OR string
chunks.
Even though the whole package is private right now. Once we publish it,
it'll likely be just the experimental channel first before upgrading to
stable.
This means it gets excluded from the built packages.
Stacked on top of #30121.
This is the same thing we do for `renderToReadableStream` so that you
don't have to manually inject it into the stream.
The only reason we didn't for `renderToString` / `renderToStaticMarkup`
was to preserve legacy behavior but since this is a new API we can
change that.
If you're rendering a partial it doesn't matter. This is likely what
you'd do for RSS feeds. The question is if you can reliably rely on the
doctype being used while rendering e-mails since many clients are so
quirky. However, if you're careful it also doesn't hurt so it seems best
to include it.
Follow up to #30105.
This supports `renderToMarkup` in a non-RSC environment (not the
`react-server` condition).
This is just a Fizz renderer but it errors at runtime when you use
state, effects or event handlers that would require hydration - like the
RSC version would. (Except RSC can give early errors too.)
To do this I have to move the `react-html` builds to a new `markup`
dimension out of the `dom-legacy` dimension so that we can configure
this differently from `renderToString`/`renderToStaticMarkup`.
Eventually that dimension can go away though if deprecated. That also
helps us avoid dynamic configuration and we can just compile in the
right configuration so the split helps anyway.
One consideration is that if a compiler strips out useEffects or inlines
initial state from useState, then it would not get called an the error
wouldn't happen. Therefore to preserve semantics, a compiler would need
to inject some call that can check the current renderer and whether it
should throw.
There is an argument that it could be useful to not error for these
because it's possible to write components that works with SSR but are
just optionally hydrated. However, there's also an argument that doing
that silently is too easy to lead to mistakes and it's better to error -
especially for the e-mail use case where you can't take it back but you
can replay a queue that had failures. There are other ways to
conditionally branch components intentionally. Besides if you want it to
be silent you can still use renderToString (or better yet
renderToReadableStream).
The primary mechanism is the RSC environment and the client-environment
is really the secondary one that's only there to support legacy
environments. So this also ensures parity with the primary environment.
This is all behind the `enableOwnerStacks` flag.
This is a follow up to #29088. In that I moved type validation into the
renderer since that's the one that knows what types are allowed.
However, I only removed it from `React.createElement` and not the JSX
which was an oversight.
However, I also noticed that for invalid types we don't have the right
stack trace for throws because we're not yet inside the JSX element that
itself is invalid. We should use its stack for the stack trace. That's
the reason it's enough to just use the throw now because we can get a
good stack trace from the owner stack. This is fixed by creating a fake
Throw Fiber that gets assigned the right stack.
Additionally, I noticed that for certain invalid types like the most
common one `undefined` we error in Flight so a missing import in RSC
leads to a generic error. Instead of erroring on the Flight side we
should just let anything that's not a Server Component through to the
client and then let the Client renderer determine whether it's a valid
type or not. Since we now have owner stacks through the server too, this
will still be able to provide a good stack trace on the client that
points to the server in that case.
<img width="571" alt="Screenshot 2024-06-25 at 6 46 35 PM"
src="https://github.com/facebook/react/assets/63648/6812c24f-e274-4e09-b4de-21deda9ea1d4">
To get the best stack you have to expand the little icon and the regular
stack is noisy [due to this Chrome
bug](https://issues.chromium.org/issues/345248263) which makes it a
little harder to find but once that's fixed it might be easier.
Name of the package is tbd (straw: `react-html`). It's a new package
separate from `react-dom` though and can be used as a standalone package
- e.g. also from a React Native app.
```js
import {renderToMarkup} from '...';
const html = await renderToMarkup(<Component />);
```
The idea is that this is a helper for rendering HTML that is not
intended to be hydrated. It's primarily intended to support a subset of
HTML that can be used as embedding and not served as HTML documents from
HTTP. For example as e-mails or in RSS/Atom feeds or other
distributions. It's a successor to `renderToStaticMarkup`.
A few differences:
- This doesn't support "Client Components". It can only use the Server
Components subset. No useEffect, no useState etc. since it will never be
hydrated. Use of those are errors.
- You also can't pass Client References so you can't use components
marked with `"use client"`.
- Unlike `renderToStaticMarkup` this does support async so you can
suspend and use data from these components.
- Unlike `renderToReadableStream` this does not support streaming or
Suspense boundaries and any error rejects the promise. Since there's no
feasible way to "client render" or patch up the document.
- Form Actions are not supported since in an embedded environment
there's no place to post back to across versions. You can render plain
forms with fixed URLs though.
- You can't use any resource preloading like `preload()` from
`react-dom`.
## Implementation
This first version in this PR only supports Server Components since
that's the thing that doesn't have an existing API. Might add a Client
Components version later that errors.
We don't want to maintain a completely separate implementation for this
use case so this uses the `dom-legacy` build dimension to wire up a
build that encapsulates a Flight Server -> Flight Client -> Fizz stream
to render Server Components that then get SSR:ed.
There's no problem to use a Flight Client in a Server Component
environment since it's already supported for Server-to-Server. Both of
these use a bundler config that just errors for Client References though
since we don't need any bundling integration and this is just a
standalone package.
Running Fizz in a Server Component environment is a problem though
because it depends on "react" and it needs the client version.
Therefore, for this build we embed the client version of "react" shared
internals into the build. It doesn't need anything to be able to use
those APIs since you can't call the client APIs anyway.
One unfortunate thing though is that since Flight currently needs to go
to binary and back, we need TextEncoder/TextDecoder to be available but
this shouldn't really be necessary. Also since we use the legacy stream
config, large strings that use byteLengthOfChunk errors atm. This needs
to be fixed before shipping. I'm not sure what would be the best
layering though that isn't unnecessarily burdensome to maintain. Maybe
some kind of pass-through protocol that would also be useful in general
- e.g. when Fizz and Flight are in the same process.
---------
Co-authored-by: Sebastian Silbermann <silbermann.sebastian@gmail.com>
Bumps [ws](https://github.com/websockets/ws) from 7.2.1 to 7.5.10.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a
href="https://github.com/websockets/ws/releases">ws's
releases</a>.</em></p>
<blockquote>
<h2>7.5.10</h2>
<h1>Bug fixes</h1>
<ul>
<li>Backported e55e5106 to the 7.x release line (22c28763).</li>
</ul>
<h2>7.5.9</h2>
<h1>Bug fixes</h1>
<ul>
<li>Backported bc8bd34e to the 7.x release line (0435e6e1).</li>
</ul>
<h2>7.5.8</h2>
<h1>Bug fixes</h1>
<ul>
<li>Backported 0fdcc0af to the 7.x release line (2758ed35).</li>
<li>Backported d68ba9e1 to the 7.x release line (dc1781bc).</li>
</ul>
<h2>7.5.7</h2>
<h1>Bug fixes</h1>
<ul>
<li>Backported 6946f5fe to the 7.x release line (1f72e2e1).</li>
</ul>
<h2>7.5.6</h2>
<h1>Bug fixes</h1>
<ul>
<li>Backported b8186dd1 to the 7.x release line (73dec34b).</li>
<li>Backported ed2b8039 to the 7.x release line (22a26afb).</li>
</ul>
<h2>7.5.5</h2>
<h1>Bug fixes</h1>
<ul>
<li>Backported ec9377ca to the 7.x release line (0e274acd).</li>
</ul>
<h2>7.5.4</h2>
<h1>Bug fixes</h1>
<ul>
<li>Backported 6a72da3e to the 7.x release line (76087fbf).</li>
<li>Backported 869c9892 to the 7.x release line (27997933).</li>
</ul>
<h2>7.5.3</h2>
<h1>Bug fixes</h1>
<ul>
<li>The <code>WebSocketServer</code> constructor now throws an error if
more than one of the
<code>noServer</code>, <code>server</code>, and <code>port</code>
options are specefied (66e58d27).</li>
<li>Fixed a bug where a <code>'close'</code> event was emitted by a
<code>WebSocketServer</code> before
the internal HTTP/S server was actually closed (5a587304).</li>
<li>Fixed a bug that allowed WebSocket connections to be established
after
<code>WebSocketServer.prototype.close()</code> was called
(772236a1).</li>
</ul>
<h2>7.5.2</h2>
<h1>Bug fixes</h1>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="d962d70649"><code>d962d70</code></a>
[dist] 7.5.10</li>
<li><a
href="22c2876323"><code>22c2876</code></a>
[security] Fix crash when the Upgrade header cannot be read (<a
href="https://redirect.github.com/websockets/ws/issues/2231">#2231</a>)</li>
<li><a
href="8a78f87706"><code>8a78f87</code></a>
[dist] 7.5.9</li>
<li><a
href="0435e6e12b"><code>0435e6e</code></a>
[security] Fix same host check for ws+unix: redirects</li>
<li><a
href="4271f07cfc"><code>4271f07</code></a>
[dist] 7.5.8</li>
<li><a
href="dc1781bc31"><code>dc1781b</code></a>
[security] Drop sensitive headers when following insecure redirects</li>
<li><a
href="2758ed3550"><code>2758ed3</code></a>
[fix] Abort the handshake if the Upgrade header is invalid</li>
<li><a
href="a370613fab"><code>a370613</code></a>
[dist] 7.5.7</li>
<li><a
href="1f72e2e14f"><code>1f72e2e</code></a>
[security] Drop sensitive headers when following redirects (<a
href="https://redirect.github.com/websockets/ws/issues/2013">#2013</a>)</li>
<li><a
href="8ecd890800"><code>8ecd890</code></a>
[dist] 7.5.6</li>
<li>Additional commits viewable in <a
href="https://github.com/websockets/ws/compare/7.2.1...7.5.10">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Adds a pass which validates that local variables are not reassigned by functions which may be called after render. This is a straightforward forward data-flow analysis, where we:
1. Build up a mapping of context variables in the outer component/hook
2. Find ObjectMethod/FunctionExpressions which may reassign those context variables
3. Propagate aliases of those functions via StoreLocal/LoadLocal
4. Disallow passing those functions with a Freeze effect. This includes JSX arguments, hook arguments, hook return types, etc.
Conceptually, a function that reassigns a local is inherently mutable. Frozen functions must be side-effect free, so these two categories are incompatible and we can use the freeze effect to find all instances of where such functions are disallowed rather than special-casing eg hook calls and JSX.
ghstack-source-id: c2b22e3d62a1ab490a6a2150e28b934b9dc8676b
Pull Request resolved: https://github.com/facebook/react/pull/30107
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
`Cannot access .then on server` is not an ideal message when you try to
await or do promise chain to the properties of client reference. The
below example will let `.then` get accessed by native code while
handling the promise chain but the access is not clearly visible in user
code.
```
import('./client-module').then((mod) => mod.Component)
```
This PR chnage the error message of module reference proxy '.then'
property to show more kinds of usage, then it can be pretty clearly for
helping users to avoid the bad usage
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
Unit test
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
When we replay logs we badge them with e.g. `[Server]`. That way it's
easy to identify that the source of the log actually happened on the
Server (RSC). However, when we threw an error we didn't have any such
thing. The error was rethrown on the client and then handled just like
any other client error.
This transfers the `environmentName` in DEV to our restored Error
"sub-class" (conceptually) along with `digest`. That way you can read
`error.environmentName` to print this in your own UI.
I also updated our default for `onCaughtError` (and `onError` in Fizz)
to use the `printToConsole` helper that the Flight Client uses to log it
with the badge format. So by default you get the same experience as
console.error for caught errors:
<img width="810" alt="Screenshot 2024-06-10 at 9 25 12 PM"
src="https://github.com/facebook/react/assets/63648/8490fedc-09f6-4286-9332-fbe6b0faa2d3">
<img width="815" alt="Screenshot 2024-06-10 at 9 39 30 PM"
src="https://github.com/facebook/react/assets/63648/bdcfc554-504a-4b1d-82bf-b717e74975ac">
Unfortunately I can't do the same thing for `onUncaughtError` nor
`onRecoverableError` because they use `reportError` which doesn't have
custom formatting (unless we also prevented default on window.onerror).
However maybe that's ok because 1) you should always have an error
boundary 2) it's not likely that an RSC error can actually recover
because it's not going to be rendered again so shouldn't really happen
outside some parent conditionally rendering maybe.
The other problem with this approach is that the default is no longer
trivial - so reimplementing the default in user space is trickier and
ideally we shouldn't expose our default to be called.
The explicit mock override in this test was causing it to always run as
native-oss instead of also as xplat. This moves the test to use `//
@gate persistent` instead to run it in all persistent configs.
Currently, the `hookKind` for `useInsertionEffect` is set to
`useLayoutEffect`. This pull request fixes it by adding a new `hookKind`
for `useInsertionEffect`.
Bumps [ws](https://github.com/websockets/ws) from 8.13.0 to 8.17.1.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a
href="https://github.com/websockets/ws/releases">ws's
releases</a>.</em></p>
<blockquote>
<h2>8.17.1</h2>
<h1>Bug fixes</h1>
<ul>
<li>Fixed a DoS vulnerability (<a
href="https://redirect.github.com/websockets/ws/issues/2231">#2231</a>).</li>
</ul>
<p>A request with a number of headers exceeding
the[<code>server.maxHeadersCount</code>][]
threshold could be used to crash a ws server.</p>
<pre lang="js"><code>const http = require('http');
const WebSocket = require('ws');
<p>const wss = new WebSocket.Server({ port: 0 }, function () {
const chars =
"!#$%&'*+-.0123456789abcdefghijklmnopqrstuvwxyz^_`|~".split('');
const headers = {};
let count = 0;</p>
<p>for (let i = 0; i < chars.length; i++) {
if (count === 2000) break;</p>
<pre><code>for (let j = 0; j &lt; chars.length; j++) {
const key = chars[i] + chars[j];
headers[key] = 'x';
if (++count === 2000) break;
}
</code></pre>
<p>}</p>
<p>headers.Connection = 'Upgrade';
headers.Upgrade = 'websocket';
headers['Sec-WebSocket-Key'] = 'dGhlIHNhbXBsZSBub25jZQ==';
headers['Sec-WebSocket-Version'] = '13';</p>
<p>const request = http.request({
headers: headers,
host: '127.0.0.1',
port: wss.address().port
});</p>
<p>request.end();
});
</code></pre></p>
<p>The vulnerability was reported by <a
href="https://github.com/rrlapointe">Ryan LaPointe</a> in <a
href="https://redirect.github.com/websockets/ws/issues/2230">websockets/ws#2230</a>.</p>
<p>In vulnerable versions of ws, the issue can be mitigated in the
following ways:</p>
<ol>
<li>Reduce the maximum allowed length of the request headers using the
[<code>--max-http-header-size=size</code>][] and/or the
[<code>maxHeaderSize</code>][] options so
that no more headers than the <code>server.maxHeadersCount</code> limit
can be sent.</li>
</ol>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="3c56601092"><code>3c56601</code></a>
[dist] 8.17.1</li>
<li><a
href="e55e5106f1"><code>e55e510</code></a>
[security] Fix crash when the Upgrade header cannot be read (<a
href="https://redirect.github.com/websockets/ws/issues/2231">#2231</a>)</li>
<li><a
href="6a00029edd"><code>6a00029</code></a>
[test] Increase code coverage</li>
<li><a
href="ddfe4a804d"><code>ddfe4a8</code></a>
[perf] Reduce the amount of <code>crypto.randomFillSync()</code>
calls</li>
<li><a
href="b73b11828d"><code>b73b118</code></a>
[dist] 8.17.0</li>
<li><a
href="29694a5905"><code>29694a5</code></a>
[test] Use the <code>highWaterMark</code> variable</li>
<li><a
href="934c9d6b93"><code>934c9d6</code></a>
[ci] Test on node 22</li>
<li><a
href="1817bac06e"><code>1817bac</code></a>
[ci] Do not test on node 21</li>
<li><a
href="96c9b3dedd"><code>96c9b3d</code></a>
[major] Flip the default value of <code>allowSynchronousEvents</code>
(<a
href="https://redirect.github.com/websockets/ws/issues/2221">#2221</a>)</li>
<li><a
href="e5f32c7e1e"><code>e5f32c7</code></a>
[fix] Emit at most one event per event loop iteration (<a
href="https://redirect.github.com/websockets/ws/issues/2218">#2218</a>)</li>
<li>Additional commits viewable in <a
href="https://github.com/websockets/ws/compare/8.13.0...8.17.1">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
## Summary
When DevTools frontend and backend are connected, we patch console in 2
places:
- `patch()`, when renderer is attached to:
- listen to any errors / warnings emitted
- append component stack if requested by the user
- `patchForStrictMode()`, when React notifies about that the next
invocation is about to happed during StrictMode
`patchForStrictMode()` will always be at the top of the patch stack,
because it is called at runtime when React notifies React DevTools,
because of this, `patch()` may receive already modified arguments (with
stylings for dimming), we should attempt to restore the original
arguments
## How did you test this change?
Look at yellow warnings on the element view:
| Before | After |
| --- | --- |
| 
| 
|
Double checked by syncing internally and verifying the # of `visitInstruction` calls with unique `InstructionId`s.
This is a bit of an awkward pattern though. A cleaner alternative might be to override `visitValue` and store its results in a sidemap (instead of returning)
ghstack-source-id: f6797d7652
Pull Request resolved: https://github.com/facebook/react/pull/30077
Adds Array.prototype methods that return primitives or other arrays -- naive type inference can be really helpful in reducing mutable ranges -> achieving higher quality memoization.
Also copies Array.prototype methods to our mixed read-only JSON-like object shape.
(Inspired after going through some suboptimal internal compilation outputs.)
ghstack-source-id: 0bfad11180
Pull Request resolved: https://github.com/facebook/react/pull/30075
Our previous logic for aligning scopes to block scopes constructs a tree of block and scope nodes. We ensured that blocks always mapped to the same node as their fallthroughs. e.g.
```js
// source
a();
if (...) {
b();
}
c();
// HIR
bb0:
a()
if test=... consequent=bb1 fallthrough=bb2
bb1:
b()
goto bb2
bb2:
c()
// AlignReactiveScopesToBlockScopesHIR nodes
Root node (maps to both bb0 and bb2)
|- bb1
|- ...
```
There are two issues with the existing implementation:
1. Only scopes that overlap with the beginning of a block are aligned correctly. This is because the traversal does not store information about the block-fallthrough pair for scopes that begin *within* the block-fallthrough range.
```
\# This case gets handled correctly
┌──────────────┐
│ │
block start block end
scope start scope end
│ │
└───────────────┘
\# But not this one!
┌──────────────┐
│ │
block start block end
scope start scope end
│ │
└───────────────┘
```
2. Only scopes that are directly used by a block is considered. See the `align-scopes-nested-block-structure` fixture for details.
ghstack-source-id: 327dec5019
Pull Request resolved: https://github.com/facebook/react/pull/29891
ghstack-source-id: 04b1526c85
Pull Request resolved: https://github.com/facebook/react/pull/29878
The AlignReactiveScope bug should be simplest to fix, but it's also caught by an invariant assertion. I think a fix could be either keeping track of "active" block-fallthrough pairs (`retainWhere(pair => pair.range.end > current.instr[0].id)`) or following the approach in `assertValidBlockNesting`.
I'm tempted to pull the value-block aligning logic out into its own pass (using the current `node` tree traversal), then align to non-value blocks with the `assertValidBlockNesting` approach. Happy to hear feedback on this though!
The other two are likely bigger issues, as they're not caught by static invariants.
Update:
- removed bug-phi-reference-effect as it's been patched by @josephsavona
- added bug-array-concat-should-capture
## Summary
Sometimes `constructor` happens to be the name of an unrelated property,
or we may be dealing with a `Proxy` that intercepts every read. Verify
the constructor is a function before using its name, and reset the name
anyway if it turns out not to be serializable.
Fixes some cases of the devtools crashing and becoming inoperable upon
attempting to inspect components whose props are Hookstate `State`s.
## How did you test this change?
Installed a patched version of the extension and confirmed that it
solves the problem.
---------
Co-authored-by: Ruslan Lesiutin <rdlesyutin@gmail.com>
With this, we can set a `debugger` breakpoint and we'll break into the
source code when running tests with snap. Without this, we'd break into
the transpiled js code.
When converting value blocks from HIR to ReactiveFunction, we have to drop StoreLocal assignments that represent the assignment of the phi, since ReactiveFunction supports compound expressions. These StoreLocals are only present to represent the conditional assignment of the value itself - but it's also possible for the expression to have contained an assignment expression. Before, in trying to strip the first category of StoreLocal we also accidentally stripped the second category. Now we check that the assignment is for a temporary, and don't strip otherwise.
ghstack-source-id: e7759c963bbc1bbff2d3230534b049199e3262ad
Pull Request resolved: https://github.com/facebook/react/pull/30067
## Summary
There is a race condition in the way we poll if React is on the page and
when we actually clear this polling instance. When user navigates to a
different page, we will debounce a callback for 500ms, which will:
1. Cleanup previous React polling instance
2. Start a new React polling instance
Since the cleanup logic is debounced, there is a small chance that by
the time we are going to clean up this polling instance, it will be
`eval`-ed on the page, that is using React. For example, when user is
navigating from the page which doesn't have React running, to a page
that has React running.
Next, we incorrectly will try to mount React DevTools panels twice,
which will result into conflicts in the Store, and the error will be
shown to the user
## How did you test this change?
Since this is a race condition, it is hard to reproduce consistently,
but you can try this flow:
1. Open a page that is using React, open browser DevTools and React
DevTools components panel
2. Open a page that is NOT using React, like google.com, wait ~5 seconds
until you see `"Looks like this page doesn't have React, or it hasn't
been loaded yet"` message in RDT panel
3. Open a page that is using React, observe the error `"Uncaught Error:
Cannot add node "1" because a node with that id is already in the
Store."`
Couldn't been able to reproduce this with these changes.
- Made each workflow's name consistent
- Rename each workflow file with consistent naming scheme
- Promote flow-ci-ghaction to flow-ci
ghstack-source-id: 490b643dcd
Pull Request resolved: https://github.com/facebook/react/pull/30037
Copies the existing circleci workflow for checking the inlined Fizz
runtime into GitHub actions. I didn't remove the circleci job for now
just to check for parity.
ghstack-source-id: 09480b1a20
Pull Request resolved: https://github.com/facebook/react/pull/30035
This PR adds parallelism similar to our existing circleci setup for
running yarn tests with the various test params. It does this by
sharding tests into `$SHARD_COUNT` number of groups, then spawning a job
for each of them and using jest's built in `--shard` option.
Effectively this means that the job will spawn an additional (where `n`
is the number of test params)
`n * $SHARD_COUNT` number of jobs to run tests in parallel
for a total of `n + (n * $SHARD_COUNT)` jobs. This does mean the
GitHub UI at the bottom of each PR gets longer and unfortunately it's
not sorted in any way as far as I can tell. But if something goes wrong
it should still be easy to find out what the problem is.
The PR also changes the `ci` argument for jest-cli to be an enum instead
so the tests use all available workers in GitHub actions. This will have
to live around for a bit until we can fully migrate off of circleci.
ghstack-source-id: 08f2d16353
Pull Request resolved: https://github.com/facebook/react/pull/30033
Copies the existing circleci workflow for yarn test into GitHub
actions. I didn't remove the circleci job for now just to check for
parity.
Opted to keep the same hardcoded list of params rather than use GitHub's
matrix permutations since this was intentional in the circleci config.
ghstack-source-id: b77a091254
Pull Request resolved: https://github.com/facebook/react/pull/30032
Adds a fixture based on internal case where our current output is quite a bit more verbose than the original memoization. See the comment in the fixture for more about the heuristic we can apply.
ghstack-source-id: e637a38140
Pull Request resolved: https://github.com/facebook/react/pull/29998
Note: due to a bad rebase i included #29883 here. Both were stamped so i'm not gonna bother splitting it back up aain.
This PR includes two changes:
* First, allow `LoadLocal` to be reordered if a) the load occurs after the last write to a variable and b) the LoadLocal lvalue is used exactly once
* Uses a more optimal reordering for statement blocks, while keeping the existing approach for expression blocks.
In #29863 I tried to find a clean way to share code for emitting instructions between value blocks and regular blocks. The catch is that value blocks have special meaning for their final instruction — that's the value of the block — so reordering can't change the last instruction. However, in finding a clean way to share code for these two categories of code, i also inadvertently reduced the effectiveness of the optimization.
This PR updates to use different strategies for these two kinds of blocks: value blocks use the code from #29863 where we first emit all non-reorderable instructions in their original order, then try to emit reorderable values. The reason this is suboptimal, though, is that we want to move instructions closer to their dependencies so that they can invalidate (merge) together. Emitting the reorderable values last prevents this.
So for normal blocks, we now emit terminal operands first. This will invariably cause some of the non-reorderable instructions to be emitted, but it will intersperse reoderable instructions in between, right after their dependencies. This maximizes our ability to merge scopes.
I think the complexity cost of two strategies is worth the benefit, as evidenced by the reduced memo slots in the fixtures.
ghstack-source-id: ad3e516fa4
Pull Request resolved: https://github.com/facebook/react/pull/29882
Copies the existing circleci workflow for yarn flags into GitHub
actions. I didn't remove the circleci job for now just to check for
parity.
ghstack-source-id: 003f2a4796
Pull Request resolved: https://github.com/facebook/react/pull/30029
The existing flow-ci script makes some assumptions about running inside
of circleci for parallelization. This PR forks the script with very smal
ll tweaks to allow for a short name to be passed in as an argument.
These short names are discovered in a new GH job and then each one is
passed as an argument for parallelization
ghstack-source-id: dc85486388f74088c22b386b77b45996ef753f1a
Pull Request resolved: https://github.com/facebook/react/pull/30026
Copies the existing circleci workflow for flow into GitHub actions. I
didn't remove the circleci job for now just to check for parity.
ghstack-source-id: 59104902e48a2b520ea2971d99c061c74b03a1a0
Pull Request resolved: https://github.com/facebook/react/pull/30025
Copies the existing circleci workflow for linting into GitHub actions. I
didn't remove the circleci for now just to check for parity.
ghstack-source-id: a3754dcc3b
Pull Request resolved: https://github.com/facebook/react/pull/30023
Merges the existing config to the root one so we can have a single
configuration file. I've tried to keep the compiler config as much as
possible in this PR so that no formatting changes occur.
ghstack-source-id: 8bbfc9f269
Pull Request resolved: https://github.com/facebook/react/pull/30021
This PR extends the previous logic added in #29141 to also account for
other kinds of non-ascii characters such as `\n`. Because these control
characters are individual special characters (and not 2 characters `\`
and `n`) we match based on unicode which was already being checked for
non-Latin characters.
This allows control characters to continue to be compiled equivalently
to its original source if it was provided in a JsxExpressionContainer.
However note that this PR does not convert JSX attributes that are
StringLiterals to JsxExpressionContainer, to preserve the original
source code as it was written.
Alternatively we could always emit a JsxExpressionContainer if it was
used in the source and not try to down level it to some other node
kind. But since we already do this I opted to keep this behavior.
Partially addresses #29648.
ghstack-source-id: ecc61c9f0bece90d18623b3c570fea05fbcd811a
Pull Request resolved: https://github.com/facebook/react/pull/29997
Need to tighten up this a bit.
react-dom isomorphic currently depends on react-reconciler which is
mostly DCE but it's pulled in which makes it hard to make other bundling
changes.
ReactFlightServer can have a hard dependency on the module that imports
its internals since even if other internals are aliased it still always
needs the server one.
Now that the compiler directory has its own prettier config, we can
remove the prettierignore entry for compiler/ so it still runs in your
editor if you open the root directory
ghstack-source-id: 5e3bd597cf2f11a9931f084eb909ffd81ebdca81
Pull Request resolved: https://github.com/facebook/react/pull/29993
## Summary
Fix bundle type filtering logic to correctly handle array input in
argv.type and use some with includes for accurate filtering. This
addresses a TypeError encountered during yarn build-for-devtools-prod
and yarn build-for-devtools-dev commands.
## Motivation
The current implementation of the `shouldSkipBundle` function in
`scripts/rollup/build.js` has two issues:
1. **Incorrect array handling in
`parseRequestedNames`([#29613](https://github.com/facebook/react/issues/29613)):**
The function incorrectly wraps the `argv.type` value in an additional
array when it's already an array. This leads to a `TypeError:
names[i].split is not a function` when `parseRequestedNames` attempts to
split the nested array, as seen in this error message:
```
C:\Users\Administrator\Documents\새 폴더\react\scripts\rollup\build.js:76
let splitNames = names[i].split(',');
^
TypeError: names[i].split is not a function
```
This PR fixes this by correctly handling both string and array inputs in
`argv.type`:
```diff
- const requestedBundleTypes = argv.type
- ? parseRequestedNames([argv.type], 'uppercase')
+ const argvType = Array.isArray(argv.type) ? argv.type : [argv.type];
+ const requestedBundleTypes = argv.type
+ ? parseRequestedNames(argvType, 'uppercase')
```
2. **Inaccurate filtering logic in
`shouldSkipBundle`([#29614](https://github.com/facebook/react/issues/29614)):**
The function uses `Array.prototype.every` with `indexOf` to check if
**all** requested bundle types are missing in the current bundle type.
However, when multiple bundle types are requested (e.g., `['NODE',
'NODE_DEV']`), the function should skip a bundle only if **none** of the
requested types are present. The current implementation incorrectly
allows bundles that match any of the requested types.
To illustrate, consider the following example output:
```
requestedBundleTypes [ 'NODE', 'NODE_DEV' ]
bundleType NODE_DEV
isAskingForDifferentType false
requestedBundleTypes [ 'NODE', 'NODE_DEV' ]
bundleType NODE_PROD
isAskingForDifferentType false // Incorrect behavior
```
In this case, even though the bundle type is `NODE_PROD` and doesn't
include `NODE_DEV`, the bundle is not skipped due to the incorrect
logic.
This PR fixes this by replacing `every` with `some` and using `includes`
for a more accurate check:
```diff
- const isAskingForDifferentType = requestedBundleTypes.every(
- requestedType => bundleType.indexOf(requestedType) === -1
- );
+ const isAskingForDifferentType = requestedBundleTypes.some(
+ requestedType => !bundleType.includes(requestedType)
+ );
```
This ensures that the bundle is skipped only if **none** of the
requested types are found in the `bundleType`.
This PR addresses both of these issues to ensure correct bundle type
filtering in various build scenarios.
## How did you test this change?
1. **Verification of `requestedBundleTypes` usage in
`shouldSkipBundle`:**
* I manually tested the following scenarios:
* `yarn build`: Verified that `requestedBundleTypes` remains an empty
array, as expected.
* `yarn build-for-devtools`: Confirmed that `requestedBundleTypes` is
correctly set to `['NODE']`, as in the original implementation.
* `yarn build-for-devtools-dev`: This previously failed due to the
error. After the fix, I confirmed that `requestedBundleTypes` is now
correctly passed as `['NODE', 'NODE_DEV']`.
2. **Debugging of filtering logic in `shouldSkipBundle`:**
* I added the following logging statements to the `shouldSkipBundle`
function to observe its behavior during the build process:
```javascript
console.log('requestedBundleTypes', requestedBundleTypes);
console.log('bundleType', bundleType);
console.log('isAskingForDifferentType', isAskingForDifferentType);
```
* By analyzing the log output, I confirmed that the filtering logic now
correctly identifies when a bundle should be skipped based on the
requested types. This allowed me to verify that the fix enables building
specific target bundles as intended.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
I have fixed an issue where the display of the HIR diff in the React
Compiler Playground was incorrect. The HIR diff is supposed to show the
pre-change state as the source, but currently, it is showing
EnvironmentConfig as the pre-change state. This PR corrects this by
setting the pre-change state to source instead of EnvironmentConfig.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
before:

after:

Somehow missed this while working on
https://github.com/facebook/react/pull/29869.
With these changes, manual inspection of the
`react_devtools_backend_compact.js` doesn't have any occurences of
`__IS_FIREFOX__` flag.
Only with the enableOwnerStacks flag (which is not on in www).
This is a new DEV-only API to be able to implement what we do for
console.error in user space.
This API does not actually include the current stack that you'd get from
`new Error().stack`. That you'd have to add yourself.
This adds the ability to have conditional development exports because we
plan on eventually having separate ESM builds that use the "development"
or "production" export conditions.
NOTE: This removes the export of `act` from `react` in prod (as opposed
to a function that throws) - inline with what we do with other
conditional exports.
## Summary
This is the pre-requisite for
https://github.com/facebook/react/pull/29231.
Current implementation of profiling hooks is only using
`performance.mark` and then makes `performance.clearMarks` call right
after it to free the memory. We've been relying on this assumption in
the tests that every mark is cleared by the time we check something.
https://github.com/facebook/react/pull/29231 adds `performance.measure`
calls and the `start` mark is not cleared until the corresponding `stop`
one is registered, and then they are cleared together.
## How did you test this change?
To test against React from source:
```
yarn test --build --project=devtools -r=experimental --ci
```
To test against React 18:
```
./scripts/circleci/download_devtools_regression_build.js 18.0 --replaceBuild
node ./scripts/jest/jest-cli.js --build --project devtools --release-channel=experimental --reactVersion 18.0 --ci
```
If a component uses the `useRef` hook directly then we type it's return
value as a ref. But if it's wrapped in a custom hook then we lose out on
this type information as the compiler doesn't look at the hook
definition. This has resulted in some false positives in our analysis
like the ones reported in #29160 and #29196.
This PR will treat objects named as `ref` or if their names end with the
substring `Ref`, and contain a property named `current`, as React refs.
```
const ref = useMyRef();
const myRef = useMyRef2();
useEffect(() => {
ref.current = ...;
myRef.current = ...;
})
```
In the above example, `ref` and `myRef` will be treated as React refs.
Updated version of #29758 removing `useFormState` since that was the
previous name for `useActionState`.
---------
Co-authored-by: Hieu Do <hieudn.uh@gmail.com>
Stacked on https://github.com/facebook/react/pull/29869.
## Summary
When using ANSI escape sequences, we construct a message in the
following way: `console.<method>('\x1b...%s\x1b[0m',
userspaceArgument1?, userspaceArgument2?, userspaceArgument3?, ...)`.
This won't dim all arguments, if user had something like `console.log(1,
2, 3)`, we would only apply it to `1`, since this is the first
arguments, so we need to:
- inline everything whats possible into a single string, while
preserving console substitutions defined by the user
- omit css and object substitutions, since we can't really inline them
and will delegate in to the environment
## How did you test this change?
Added some tests, manually inspected that it works well for web and
native cases.
Adds fixtures for `macro.namespace(...)` style invocations which we use internally in some cases instead of just `macro(...)`. I tried every example i could think of that could possibly break it (including basing one off of another fixture where we hit an invariant related due to a temporary being emitted for a method call), and they all worked. I just had to fix an existing bug where we early return in some cases instead of continuing, which is a holdover from when this pass was originally written as a ReactiveFunction visitor.
ghstack-source-id: c01f45b3ef6f42b6d1f1ff0508aea258000e0fce
Pull Request resolved: https://github.com/facebook/react/pull/29899
## Summary
Removes the usage of `consoleManagedByDevToolsDuringStrictMode` flag
from React DevTools backend, this is the only place in RDT where this
flag was used. The only remaining part is
[`ReactFiberDevToolsHook`](6708115937/packages/react-reconciler/src/ReactFiberDevToolsHook.js (L203)),
so React renderers can start notifying DevTools when `render` runs in a
Strict Mode.
> TL;DR: it is broken, and we already incorrectly apply dimming, when
RDT frontend is not opened. Fixing in the next few changes, see next
steps.
Before explaining why I am removing this, some context is required. The
way RDT works is slightly different, based on the fact if RDT frontend
and RDT backend are actually connected:
1. For browser extension case, the Backend is a script, which is
injected by the extension when page is loaded and before React is
loaded. RDT Frontend is loaded together with the RDT panel in browser
DevTools, so ONLY when user actually opens the RDT panel.
2. For native case, RDT backend is shipped together with `react-native`
for DEV bundles. It is always injected before React is loaded. RDT
frontend is loaded only when user starts a standalone RDT app via `npx
react-devtools` or by opening React Native DevTools and then selecting
React DevTools panel.
When Frontend is not connected to the Backend, the only thing we have is
the `__REACT_DEVTOOLS_GLOBAL_HOOK__` — this thing inlines some APIs in
itself, so that it can work similarly when RDT Frontend is not even
opened. This is especially important for console logs, since they are
cached and stored, then later displayed to the user once the Console
panel is opened, but from RDT side, you want to modify these console
logs when they are emitted.
In order to do so, we [inline the console patching logic into the
hook](3ac551e855/packages/react-devtools-shared/src/hook.js (L222-L319)).
This implementation doesn't use the
`consoleManagedByDevToolsDuringStrictMode`. This means that if we enable
`consoleManagedByDevToolsDuringStrictMode` for Native right now, users
would see broken dimming in LogBox / Metro logs when RDT Frontend is not
opened.
Next steps:
1. Align this console patching implementation with the one in `hook.js`.
2. Make LogBox compatible with console stylings: both css and ASCII
escape symbols.
3. Ship new version of RDT with these changes.
4. Remove `consoleManagedByDevToolsDuringStrictMode` from
`ReactFiberDevToolsHook`, so this is rolled out for all renderers.
This adds few changes:
1. We are going to ship source maps only for 2 artifacts:
`installHook.js` and `react_devtools_backend_compact.js`, because it is
only these modules that can patch console and be visible to the user via
stack traces in console. We need to ship source maps to be able to use
`ignoreList` feature in source maps, so we can actually hide these from
stack traces.
| Before | After |
|--------|--------|
| 
| 
|
2. The `"sources"` field in source map will have relative urls listed,
instead of absolute with `webpack://` protocol. This will move the
sources to the `React Developer Tools` frame in `Sources` panel, instead
of `webpack://`.
| Before | After |
|--------|--------|
| 
| 
|
> [!NOTE]
> I still have 1 unresolved issue with shipping source maps in extension
build, and it is related to Firefox, which can't find them in the
extension bundle and returns 404, even though urls are relative and I
can actually open them via unique address like
`moz-extension://<extension-id>/build/intallHook.js.map` ¯\\\_(ツ)\_/¯
## Summary
Configures the React Native open source feature flags in preparation for
React Native 0.75, which will be upgraded to React 19.
## How did you test this change?
```
$ yarn test
$ yarn flow fabric
```
Adds a pass just after DCE to reorder safely reorderable instructions (jsx, primitives, globals) closer to where they are used, to allow other optimization passes to be more effective. Notably, the reordering allows scope merging to be more effective, since that pass relies on two scopes not having intervening instructions — in many cases we can now reorder such instructions out of the way and unlock merging, as demonstrated in the changed fixtures.
The algorithm itself is described in the docblock.
note: This is a cleaned up version of #29579 that is ready for review.
ghstack-source-id: c54a806cad
Pull Request resolved: https://github.com/facebook/react/pull/29863
Updates our scope merging pass to allow more types of instructions to intervene btw scopes. This includes all the non-allocating kinds of nodes that are considered reorderable in #29863. It's already safe to merge scopes with these instructions — we only merge if the lvalue is not used past the next scope. Additionally, without changing this pass reordering isn't very effective, since we would reorder to add these types of intervening instructions and then not be able to merge scopes.
Sequencing this first helps to see the win just from reordering alone.
ghstack-source-id: 79263576d8
Pull Request resolved: https://github.com/facebook/react/pull/29881
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
In the Fabric renderer in React Native, we only use the HostContext to
issue soft errors in __DEV__ bundles when attempting to add a raw text
child to a node that may not support them. Moving the logic to set this
context to __DEV__ bundles only unblocks more expensive methods for
resolving whether a parent context supports raw text children, like
resolving this information from `getViewConfigForType`.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
yarn test (--prod)
sanitize javascript: urls for <object> tags
React 19 added sanitization for `javascript:` URLs for `href` properties
on various tags. This PR also adds that sanitization for `<object>` tags
as well that Firefox otherwise executes.
Summary: The change detection mode was unavailable in the playground because the pragma was not a boolean. This fixes that by special casing it in pragma parsing, similar to validateNoCapitalizedCalls
ghstack-source-id: 4a8c17d21ab8b7936ca61c9dd1f7fdf8322614c9
Pull Request resolved: https://github.com/facebook/react/pull/29889
### Summary
Similarly to what has been done on the `react-native` repo in
https://github.com/facebook/react-native/pull/43851, this PR adds a
`react.code-workspace` workspace file when using VSCode.
This disables the built-in TypeScript Language Service for `.js`, `.ts`,
and `.json` files, recommends extensions, enables `formatOnSave`,
excludes certain files in search, and configures Flow language support.
### Motivation
This is a DevX benefit for **React contributors** using open source VS
Code. Without this, it takes quite a long time to set up the environment
in vscode to work well.
For me the following two points took around an hour each to figure out,
but for others it may take even more (screenshots can be found below):
* Search with "files to include" was searching in ignored files
(compiled/generated)
* Configure language validation and prettier both in "packages" that use
flow and in the "compiler" folder that uses typescript.
### Recommended extensions
NOTE: The recommended extensions list is currently minimal — happy to
extend this now or in future, but let's aim to keep these conservative
at the moment.
* Flow — language support
* EditorConfig — formatting based on `.editorconfig`, all file types
* Prettier — formatting for JS* files
* ESLint — linter for JS* files
### Why `react.code-workspace`?
`.code-workspace` files have slight extra behaviours over a `.vscode/`
directory:
* Allows user to opt-in or skip.
* Allows double-click launching from file managers.
* Allows base folder (and any subfolders in future) to be opened with
local file tree scope (useful in fbsource!)
* (Minor point) Single config file over multiple files.
https://code.visualstudio.com/docs/editor/workspaces
### Test plan
Against a new un-configured copy of Visual Studio Code Insiders.
**Without workspace config**
❌ .js files raise errors by default (built-in TypeScript language
service)
❌ When using the Flow VS Code extension, the wrong version (global) of
Flow is used.
<img width="978" alt="Screenshot 2024-06-10 at 16 03 59"
src="https://github.com/facebook/react/assets/5188459/17e19ba4-bac2-48ea-9b35-6b4b6242bcc1">
❌ Searching in excluded files when the "include" field is specified
<img width="502" alt="Screenshot 2024-06-10 at 15 41 24"
src="https://github.com/facebook/react/assets/5188459/00248755-7905-41bc-b303-498ddba82108">
**With workspace config**
✅ Built-in TypeScript Language Service is disabled for .js files, but
still enabled for .ts[x] files

✅ Flow language support is configured correctly against flow version in
package.json
<img width="993" alt="Screenshot 2024-06-10 at 16 03 44"
src="https://github.com/facebook/react/assets/5188459/b54e143c-a013-4e73-8995-3af7b5a03e36">
✅ Does not search in excluded files when the "include" field is
specified
<img width="555" alt="Screenshot 2024-06-10 at 15 39 18"
src="https://github.com/facebook/react/assets/5188459/dd3e5344-84fb-4b5d-8689-4c8bd28168e0">
✅ Workspace config is suggested when folder is opened in VS Code

✅ Dialog is shown on workspace launch with recommended VS Code
extensions
<img width="580" alt="Screenshot 2024-06-10 at 15 40 52"
src="https://github.com/facebook/react/assets/5188459/c6406fb6-92a0-47f1-8497-4ffe899bb6a9">
Our passes aren't sequenced such that we could observe this bug, but this retains the proper terminal kind for pruned-scopes in mapTerminalSuccessors.
ghstack-source-id: 1a03b40e45649bbef7d6db968fb2dbd6261a246a
Pull Request resolved: https://github.com/facebook/react/pull/29884
Summary: Minor change inspired by #29863: the BuildHIR pass ensures that Binary and UnaryOperator nodes only use a limited set of the operators that babel's operator types represent, which that pr relies on for safe reorderability, but the type of those HIR nodes admits the other operators. For example, even though you can't build an HIR UnaryOperator with `delete` as the operator, it is a valid HIR node--and if we made a mistaken change that let you build such a node, it would be unsafe to reorder.
This pr makes the typing of operators stricter to prevent that.
ghstack-source-id: 9bf3b1a37eae3f14c0e9fb42bb3ece522b317d98
Pull Request resolved: https://github.com/facebook/react/pull/29880
The export maps for react packages have to choose an order of
preference. Many runtimes use multiple conditions, for instance when
building for edge webpack also uses the browser condition which makes
sense given most edge runtimes have a web-standards based set of APIs.
However React is building the browser builds primarily for actual
browsers and sometimes have builds intended for servers that might be
browser compat. This change updates the order of conditions to
preference specific named runtimes > node > generic edge runtimes >
browser > default
Fixes a bug found by mofeiZ in #29878. When we merge queued states, if the new state does not introduce changes relative to the queued state we should use the queued state, not the new state.
ghstack-source-id: c59f69de15
Pull Request resolved: https://github.com/facebook/react/pull/29879
That way we get owner stacks (native or otherwise) for `console.error`
or `console.warn` inside of them.
Since the `reportError` is also called within this context, we also get
them for errors thrown within event listeners. You'll also be able to
observe this in in the `error` event. Similar to how `onUncaughtError`
is in the scope of the instance that errored - even though
`onUncaughtError` doesn't kick in for event listeners.
Chrome (from console.createTask):
<img width="306" alt="Screenshot 2024-06-12 at 2 08 19 PM"
src="https://github.com/facebook/react/assets/63648/34cd9d57-0df4-44df-a470-e89a5dd1b07d">
<img width="302" alt="Screenshot 2024-06-12 at 2 03 32 PM"
src="https://github.com/facebook/react/assets/63648/678117b1-e03a-47d4-9989-8350212c8135">
Firefox (from React DevTools):
<img width="493" alt="Screenshot 2024-06-12 at 2 05 01 PM"
src="https://github.com/facebook/react/assets/63648/94ca224d-354a-4ec8-a886-5740bcb418e5">
(This is the parent stack since React DevTools doesn't just yet print
owner stack.)
(Firefox doesn't print the component stack for uncaught since we don't
add component stacks for "error" events from React DevTools - just
console.error. Perhaps an oversight.)
If we didn't have the synthetic event system this would kind of just
work natively in Chrome because we have this task active when we attach
the event listeners to the DOM node and async stacks just follow along
that way. In fact, if you attach a manual listener in useEffect you get
this same effect. It's just because we use event delegation that this
doesn't work.
However, if we did get rid of the synthetic event system we'd likely
still want to add a wrapper on the DOM node to set our internal current
owner so that the non-native part of the system still can observe the
active instance. That wouldn't work with manually attached listeners
though.
Bumps [braces](https://github.com/micromatch/braces) from 3.0.2 to
3.0.3.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="74b2db2938"><code>74b2db2</code></a>
3.0.3</li>
<li><a
href="88f1429a0f"><code>88f1429</code></a>
update eslint. lint, fix unit tests.</li>
<li><a
href="415d660c30"><code>415d660</code></a>
Snyk js braces 6838727 (<a
href="https://redirect.github.com/micromatch/braces/issues/40">#40</a>)</li>
<li><a
href="190510f79d"><code>190510f</code></a>
fix tests, skip 1 test in test/braces.expand</li>
<li><a
href="716eb9f12d"><code>716eb9f</code></a>
readme bump</li>
<li><a
href="a5851e57f4"><code>a5851e5</code></a>
Merge pull request <a
href="https://redirect.github.com/micromatch/braces/issues/37">#37</a>
from coderaiser/fix/vulnerability</li>
<li><a
href="2092bd1fb1"><code>2092bd1</code></a>
feature: braces: add maxSymbols (<a
href="https://github.com/micromatch/braces/issues/">https://github.com/micromatch/braces/issues/</a>...</li>
<li><a
href="9f5b4cf473"><code>9f5b4cf</code></a>
fix: vulnerability (<a
href="https://security.snyk.io/vuln/SNYK-JS-BRACES-6838727">https://security.snyk.io/vuln/SNYK-JS-BRACES-6838727</a>)</li>
<li><a
href="98414f9f1f"><code>98414f9</code></a>
remove funding file</li>
<li><a
href="665ab5d561"><code>665ab5d</code></a>
update keepEscaping doc (<a
href="https://redirect.github.com/micromatch/braces/issues/27">#27</a>)</li>
<li>Additional commits viewable in <a
href="https://github.com/micromatch/braces/compare/3.0.2...3.0.3">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
This lets the environment name vary within a request by the context a
component, log or error being executed in.
A potentially different API would be something like
`setEnvironmentName()` but we'd have to extend the `ReadableStream` or
something to do that like we do for `.allReady`. As a function though it
has some expansion possibilities, e.g. we could potentially also pass
some information to it for context about what is being asked for.
If it changes before completing a task, we also emit the change so that
we have the debug info for what the environment was before entering a
component and what it was after completing it.
Stacked on #29807.
This lets the nearest Suspense/Error Boundary handle it even if that
boundary is defined by the model itself.
It also ensures that when we have an error during serialization of
properties, those can be associated with the nearest JSX element and
since we have a stack/owner for that element we can use it to point to
the source code of that line. We can't track the source of any nested
arbitrary objects deeper inside since objects don’t track their stacks
but close enough. Ideally we have the property path but we don’t have
that right now. We have a partial in the message itself.
<img width="813" alt="Screenshot 2024-06-09 at 10 08 27 PM"
src="https://github.com/facebook/react/assets/63648/917fbe0c-053c-4204-93db-d68a66e3e874">
Note: The component name (Counter) is lost in the first message because
we don't print it in the Task. We use `"use client"` instead because we
expect the next stack frame to have the name. We also don't include it
in the actual error message because the Server doesn't know the
component name yet. Ideally Client References should be able to have a
name. If the nearest is a Host Component then we do use the name though.
However, it's not actually inside that Component that the error happens
it's in App and that points to the right line number.
An interesting case is that if something that's actually going to be
consumed by the props to a Suspense/Error Boundary or the Client
Component that wraps them fails, then it can't be handled by the
boundary. However, a counter intuitive case might be when that's on the
`children` props. E.g.
`<ErrorBoundary>{clientReferenceOrInvalidSerialization}</ErrorBoundary>`.
This value can be inspected by the boundary so it's not safe to pass it
so if it's errored it is not caught.
## Implementation
The first insight is that this is best solved on the Client rather than
in the Server because that way it also covers Client References that end
up erroring.
The key insight is that while we don't have a true stack when using
`JSON.parse` and therefore no begin/complete we can still infer these
phases for Elements because the first child of an Element is always
`'$'` which is also a leaf. In depth first that's our begin phase. When
the Element itself completes, we have the complete phase. Anything in
between is within the Element.
Using this idea I was able to refactor the blocking tracking mechanism
to stash the blocked information on `initializingHandler` and then on
the way up do we let whatever is nearest handle it - whether that's an
Element or the root Chunk. It's kind of like an Algebraic Effect.
cc @unstubbable This is something you might want to deep dive into to
find more edge cases. I'm sure I've missed something.
---------
Co-authored-by: eps1lon <sebastian.silbermann@vercel.com>
Stacked on #29807.
Conceptually the error's owner/task should ideally be captured when the
Error constructor is called but neither `console.createTask` does this,
nor do we override `Error` to capture our `owner`. So instead, we use
the nearest parent as the owner/task of the error. This is usually the
same thing when it's thrown from the same async component but not if you
await a promise started from a different component/task.
Before this stack the "owner" and "task" of a Lazy that errors was the
nearest Fiber but if the thing erroring is a Server Component, we need
to get that as the owner from the inner most part of debugInfo.
To get the Task for that Server Component, we need to expose it on the
ReactComponentInfo object. Unfortunately that makes the object not
serializable so we need to special case this to exclude it from
serialization. It gets restored again on the client.
Before (Shell):
<img width="813" alt="Screenshot 2024-06-06 at 5 16 20 PM"
src="https://github.com/facebook/react/assets/63648/7da2d4c9-539b-494e-ba63-1abdc58ff13c">
After (App):
<img width="811" alt="Screenshot 2024-06-08 at 12 29 23 AM"
src="https://github.com/facebook/react/assets/63648/dbf40bd7-c24d-4200-81a6-5018bef55f6d">
Summary: We now expect that candidate components that have Flow or TS type annotations on their first parameters have annotations that are potentially objects--this lets us reject compiling functions that explicitly take e.g. `number` as a parameter.
ghstack-source-id: e2c23348265b7ef651232b962ed7be7f6fed1930
Pull Request resolved: https://github.com/facebook/react/pull/29866
Summary: We can tighten our criteria for what is a component by requiring that a component or hook contain JSX or hook calls directly within its body, excluding nested functions . Currently, if we see them within the body anywhere -- including nested functions -- we treat it as a component if the other requirements are met. This change makes this stricter.
We also now expect components (but not necessarily hooks) to have return statements, and those returns must be potential React nodes (we can reject functions that return function or object literals, for example).
ghstack-source-id: 4507cc3955216c564bf257c0b81bfb551ae6ae55
Pull Request resolved: https://github.com/facebook/react/pull/29865
Summary: Projects which have heavily adopted Flow component syntax may wish to enable the compiler only for components and hooks that use the syntax, rather than trying to guess which functions are components and hooks. This provides that option.
ghstack-source-id: 579ac9f0fa01d8cdb6a0b8f9923906a0b37662f3
Pull Request resolved: https://github.com/facebook/react/pull/29864
Stacked on #29804.
Transferring of debugInfo was added in #28286. It represents the parent
stack between the current Fiber and into the next Fiber we're about to
create. I.e. Server Components in between. ~I don't love passing
DEV-only fields as arguments anyway since I don't trust closure to
remove unused arguments that way.~ EDIT: Actually it seems like closure
handled that just fine before which is why this is no change in prod.
Instead, I track it on the module scope. Notably with DON'T use
try/finally because if something throws we want to observe what it was
at the time we threw. Like the pattern we use many other places.
Now we can use this when we create the Throw Fiber to associate the
Server Components that were part of the parent stack before this error
threw. There by giving us the correct parent stacks at the location that
threw.
This lets us rethrow it in the conceptual place of the child.
There's currently a problem when we suspend or throw in the child fiber
reconciliation phase. This work is done by the parent component, so if
it suspends or errors it is as if that component errored or suspended.
However, conceptually it's like a child suspended or errored.
In theory any thing can throw but it is really mainly due to either
`React.lazy` (both in the element.type position and node position),
`Thenable`s or the `Thenable`s that make up `AsyncIterable`s.
Mainly this happens because a Server Component that errors turns into a
`React.lazy`. In practice this means that if you have a Server Component
as the direct child of an Error Boundary. Errors inside of it won't be
caught.
We used to have the same problem with Thenables and Suspense but because
it's now always nested inside an inner Offscreen boundary that shields
it by being one level nested. However, when we have raw Offscreen
(Activity) boundaries they should also be able to catch the suspense if
it's in a hidden state so the problem returns. This fixes it for thrown
promises but it doesn't fix it for SuspenseException. I'm not sure this
is even the right strategy for Suspense though. It kind of relies on the
node never actually mounting/committing.
It's conceptually a little tricky because the current component can
inspect the children and make decisions based on them. Such as
SuspenseList.
The other thing that this PR tries to address is that it sets the
foundation for dealing with error reporting for Server Components that
errored. If something client side errors it'll be a stack like Server
(DebugInfo) -> Fiber -> Fiber -> Server -> (DebugInfo) -> Fiber.
However, all error reporting relies on it eventually terminating into a
Fiber that is responsible for the error. To avoid having to fork too
much it would be nice if I could create a Fiber to associate with the
error so that even a Server component error in this case ultimately
terminates in a Fiber.
We know from Fiber that inline objects with more than 16 properties in
V8 turn into dictionaries instead of optimized objects. The trick is to
use a constructor instead of an inline object literal. I don't actually
know if that's still the case or not. I haven't benchmarked/tested the
output. Better safe than sorry.
It's unfortunate that this can have a negative effect for Hermes and JSC
but it's not as bad as it is for V8 because they don't deopt into
dictionaries. The time to construct these objects isn't a concern - the
time to access them frequently is.
We have to beware the Task objects in Fizz. Those are currently on 16
fields exactly so we shouldn't add anymore ideally.
We should ideally have a lint rule against object literals with more
than 16 fields on them. It might not help since sometimes the fields are
conditional.
To keep consistent with the rest of the React repo, let's remove this
because editor settings are personal. Additionally this wasn't in the
root directory so it wasn't being applied anyway.
ghstack-source-id: 3a2e2993d6
Pull Request resolved: https://github.com/facebook/react/pull/29861
Bumps [braces](https://github.com/micromatch/braces) from 3.0.2 to
3.0.3.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="74b2db2938"><code>74b2db2</code></a>
3.0.3</li>
<li><a
href="88f1429a0f"><code>88f1429</code></a>
update eslint. lint, fix unit tests.</li>
<li><a
href="415d660c30"><code>415d660</code></a>
Snyk js braces 6838727 (<a
href="https://redirect.github.com/micromatch/braces/issues/40">#40</a>)</li>
<li><a
href="190510f79d"><code>190510f</code></a>
fix tests, skip 1 test in test/braces.expand</li>
<li><a
href="716eb9f12d"><code>716eb9f</code></a>
readme bump</li>
<li><a
href="a5851e57f4"><code>a5851e5</code></a>
Merge pull request <a
href="https://redirect.github.com/micromatch/braces/issues/37">#37</a>
from coderaiser/fix/vulnerability</li>
<li><a
href="2092bd1fb1"><code>2092bd1</code></a>
feature: braces: add maxSymbols (<a
href="https://github.com/micromatch/braces/issues/">https://github.com/micromatch/braces/issues/</a>...</li>
<li><a
href="9f5b4cf473"><code>9f5b4cf</code></a>
fix: vulnerability (<a
href="https://security.snyk.io/vuln/SNYK-JS-BRACES-6838727">https://security.snyk.io/vuln/SNYK-JS-BRACES-6838727</a>)</li>
<li><a
href="98414f9f1f"><code>98414f9</code></a>
remove funding file</li>
<li><a
href="665ab5d561"><code>665ab5d</code></a>
update keepEscaping doc (<a
href="https://redirect.github.com/micromatch/braces/issues/27">#27</a>)</li>
<li>Additional commits viewable in <a
href="https://github.com/micromatch/braces/compare/3.0.2...3.0.3">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps [braces](https://github.com/micromatch/braces) from 3.0.2 to
3.0.3.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="74b2db2938"><code>74b2db2</code></a>
3.0.3</li>
<li><a
href="88f1429a0f"><code>88f1429</code></a>
update eslint. lint, fix unit tests.</li>
<li><a
href="415d660c30"><code>415d660</code></a>
Snyk js braces 6838727 (<a
href="https://redirect.github.com/micromatch/braces/issues/40">#40</a>)</li>
<li><a
href="190510f79d"><code>190510f</code></a>
fix tests, skip 1 test in test/braces.expand</li>
<li><a
href="716eb9f12d"><code>716eb9f</code></a>
readme bump</li>
<li><a
href="a5851e57f4"><code>a5851e5</code></a>
Merge pull request <a
href="https://redirect.github.com/micromatch/braces/issues/37">#37</a>
from coderaiser/fix/vulnerability</li>
<li><a
href="2092bd1fb1"><code>2092bd1</code></a>
feature: braces: add maxSymbols (<a
href="https://github.com/micromatch/braces/issues/">https://github.com/micromatch/braces/issues/</a>...</li>
<li><a
href="9f5b4cf473"><code>9f5b4cf</code></a>
fix: vulnerability (<a
href="https://security.snyk.io/vuln/SNYK-JS-BRACES-6838727">https://security.snyk.io/vuln/SNYK-JS-BRACES-6838727</a>)</li>
<li><a
href="98414f9f1f"><code>98414f9</code></a>
remove funding file</li>
<li><a
href="665ab5d561"><code>665ab5d</code></a>
update keepEscaping doc (<a
href="https://redirect.github.com/micromatch/braces/issues/27">#27</a>)</li>
<li>Additional commits viewable in <a
href="https://github.com/micromatch/braces/compare/3.0.2...3.0.3">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps [braces](https://github.com/micromatch/braces) from 3.0.2 to
3.0.3.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="74b2db2938"><code>74b2db2</code></a>
3.0.3</li>
<li><a
href="88f1429a0f"><code>88f1429</code></a>
update eslint. lint, fix unit tests.</li>
<li><a
href="415d660c30"><code>415d660</code></a>
Snyk js braces 6838727 (<a
href="https://redirect.github.com/micromatch/braces/issues/40">#40</a>)</li>
<li><a
href="190510f79d"><code>190510f</code></a>
fix tests, skip 1 test in test/braces.expand</li>
<li><a
href="716eb9f12d"><code>716eb9f</code></a>
readme bump</li>
<li><a
href="a5851e57f4"><code>a5851e5</code></a>
Merge pull request <a
href="https://redirect.github.com/micromatch/braces/issues/37">#37</a>
from coderaiser/fix/vulnerability</li>
<li><a
href="2092bd1fb1"><code>2092bd1</code></a>
feature: braces: add maxSymbols (<a
href="https://github.com/micromatch/braces/issues/">https://github.com/micromatch/braces/issues/</a>...</li>
<li><a
href="9f5b4cf473"><code>9f5b4cf</code></a>
fix: vulnerability (<a
href="https://security.snyk.io/vuln/SNYK-JS-BRACES-6838727">https://security.snyk.io/vuln/SNYK-JS-BRACES-6838727</a>)</li>
<li><a
href="98414f9f1f"><code>98414f9</code></a>
remove funding file</li>
<li><a
href="665ab5d561"><code>665ab5d</code></a>
update keepEscaping doc (<a
href="https://redirect.github.com/micromatch/braces/issues/27">#27</a>)</li>
<li>Additional commits viewable in <a
href="https://github.com/micromatch/braces/compare/3.0.2...3.0.3">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Per title, implements an HIR-based version of FlattenScopesWithHooksOrUse as part of our push to use HIR everywhere. This is the last pass to migrate before PropagateScopeDeps, which is blocking the fix for `bug.invalid-hoisting-functionexpr`, ie where we can infer incorrect dependencies for function expressions if the dependencies are accessed conditionally.
ghstack-source-id: 05c6e26b3b7a3b1c3e106a37053f88ac3c72caf5
Pull Request resolved: https://github.com/facebook/react/pull/29840
Pre the title, this implements an HIR-based version of FlattenReactiveLoops. Another step on the way to HIR-everywhere.
ghstack-source-id: e1d166352df6b0725e4c4915a19445437916251f
Pull Request resolved: https://github.com/facebook/react/pull/29838
Adds the HIR equivalent of a pruned-scope, allowing us to start porting the scope-pruning passes to operate on HIR.
ghstack-source-id: dbbdc43219123467acc1a531d8276e8b9cc91e14
Pull Request resolved: https://github.com/facebook/react/pull/29837
The ci step for the playground already installs playwright browsers so
this step was unnecessary. It also doesn't work internally for our sync
scripts
ghstack-source-id: d6e7615637
Pull Request resolved: https://github.com/facebook/react/pull/29841
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
The parsePluginOptions seemed to be duplicated within
[BabelPlugin.ts](f5af92d2c4/compiler/packages/babel-plugin-react-compiler/src/Babel/BabelPlugin.ts (L32))
and
[Program.ts](f5af92d2c4/compiler/packages/babel-plugin-react-compiler/src/Entrypoint/Program.ts (L220)).
Since the options already parsed in BabelPlugin.ts should have been
passed to compileProgram, in this PR we deleted parsePluginOptions in
compileProgram and used the options passed as arguments as they are.
I've done that.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
<img width="516" alt="image"
src="https://github.com/facebook/react/assets/87469023/2a70c6ea-0330-42a2-adff-48ae3e905790">
Basically make `console.error` and `console.warn` behave like normal -
when a component stack isn't appended. I need this because I need to be
able to print rich logs with the component stack option and to be able
to disable instrumentation completely in `console.createTask`
environments that don't need it.
Currently we can't print logs with richer objects because they're
toString:ed first. In practice, pretty much all arguments we log are
already toString:ed so it's not necessary anyway. Some might be like a
number. So it would only be a problem if some environment can't handle
proper consoles but then it's up to that environment to toString it
before logging.
The `Warning: ` prefix is historic and is both noisy and confusing. It's
mostly unnecessary since the UI surrounding `console.error` and
`console.warn` tend to have visual treatment around it anyway. However,
it's actively misleading when `console.error` gets prefixed with a
Warning that we consider an error level. There's an argument to be made
that some of our `console.error` don't make the bar for an error but
then the argument is to downgrade each of those to `console.warn` - not
to brand all our actual error logging with `Warning: `.
Apparently something needs to change in React Native before landing this
because it depends on the prefix somehow which probably doesn't make
sense already.
## Overview
Updates `eslint-plugin-jest` and enables the recommended rules with some
turned off that are unhelpful.
The main motivations is:
a) we have a few duplicated tests, which this found an I deleted
b) making sure we don't accidentally commit skipped tests
Adds a shape type for component props, which has one defined property: "ref". This means that if the ref property exists, we can type usage of `props.ref` (or via destructuring) the same as the result of `useRef()` and infer downstream usage similarly.
ghstack-source-id: 76cd07c5dfeea2a4aafe141912663b097308fd73
Pull Request resolved: https://github.com/facebook/react/pull/29834
## Overview
The clever trick in https://github.com/facebook/react/pull/29799 turns
out to not work because signedsource includes the generated hash in the
header. Reverts back to checking git diff, filtering out the REVISION
file and `@generated` headers.
There are two cases where it's legit/intended to remove scopes, and we can inline the scope rather than reify a "pruned" scope:
* Scopes that contain a single instruction with a hook call. The fact that we create a scope in this case at all is just an artifact of it being simpler to do this and remove the scope later rather than try to avoid creating it in the first place. So for these scopes, we can just inline them.
* Scopes that are provably non-escaping. Removing the scope is an optimization, not a case of us having to prune away something that should be there. So again, its fine to inline in this case.
I found this from syncing the stack internally and looking at differences in compiled output. The latter case was most common but the first case is just an obvious improvement.
ghstack-source-id: 80610ddafad65eb837d0037e2692dd74bc548088
Pull Request resolved: https://github.com/facebook/react/pull/29820
Adds additional information to the CompileSuccess LoggerEvent:
* `prunedMemoBlocks` is the number of reactive scopes that were pruned for some reason.
* `prunedMemoValues` is the number of unique _values_ produced by those scopes.
Both numbers exclude blocks that are just a hook call - ie although we create and prune a scope for eg `useState()`, that's just an artifact of the sequencing of our pipeline. So what this metric is counting is cases of _other_ values that go unmemoized. See the new fixture, which takes advantage of improvements in the snap runner to optionally emit the logger events in the .expect.md file if you include the "logger" pragma in a fixture.
ghstack-source-id: c2015bb5565746d07427587526b71e23685279c2
Pull Request resolved: https://github.com/facebook/react/pull/29810
Mostly addresses the issue with non-reactive pruned scopes. Before, values from pruned scopes would not be memoized, but could still be depended upon by downstream scopes. However, those downstream scopes would assume the value could never change. This could allow the developer to observe two different versions of a value - the freshly created one (if observed outside a scope) or a cached one (if observed inside, or through) a scope which used the value but didn't depend on it.
The fix here is to consider the outputs of pruned reactive scopes as reactive. Note that this is a partial fix because of things like control variables — the full solution would be to mark these values as reactive, and then re-run InferReactivePlaces. We can do this once we've fully converted our pipeline to use HIR everywhere. For now, this should fix most issues in practice because PruneNonReactiveDependencies already does basic alias tracking (see new fixture).
ghstack-source-id: 364430bbeca4cfca2fbf9df4d92b2e61b3352311
Pull Request resolved: https://github.com/facebook/react/pull/29790
There's a category of bug currently where pruned reactive scopes whose outputs are non-reactive can have their code end up inlining into another scope, moving the location of the instruction. Any value that had a scope assigned has to have its order of evaluation preserved, despite the fact that it got pruned, so naively we could just force every pruned scope to have its declarations promoted to named variables.
However, that ends up assigning names to _tons_ of scope declarations that don't really need to be promoted. For example, a scope with just a hook call ends up with:
```
const x = useFoo();
=>
scope {
$t0 = Call read useFoo$ (...);
}
$t1 = StoreLocal 'x' = read $t0;
```
Where t0 doesn't need to be promoted since it's used immediately to assign to another value which is a non-temporary.
So the idea of this PR is that we can track outputs of pruned scopes which are directly referenced from inside a later scope. This fixes one of the two cases of the above pattern. We'll also likely have to consider values from pruned scopes as always reactive, i'll do that in the next PR.
ghstack-source-id: b37fb9a7cb1430b7c35ec5946269ce5a886a486a
Pull Request resolved: https://github.com/facebook/react/pull/29789
There are a few places where we want to check whether a value actually got memoized, and we currently have to infer this based on values that "should" have a scope and whether a corresponding scope actually exists. This PR adds a new ReactiveStatement variant to model a reactive scope block that was pruned for some reason, and updates all the passes that prune scopes to instead produce this new variant.
ghstack-source-id: aea6dab469acb1f20058b85cb6f9aafab5d167cd
Pull Request resolved: https://github.com/facebook/react/pull/29781
## Overview
Reverts https://github.com/facebook/react/pull/26616 and implements the
suggested way instead.
This change in #26616 broken the internal sync command, which now
results in duplicated `@generated` headers. It also makes it harder to
detect changes during the diff train sync. Instead, we will check for
changes, and if there are changes sign the files and commit them to the
sync branch.
## Strategy
The new sync strategy accounts for the generated headers during the
sync:
- **Revert Version**: Revert the version strings
- **Revert @generated**: Re-sign the files (will be the same hash as
before if unchanged)
- **Check**: Check if there are changes **if not, skip**
- **Re-apply Version**: Now add back the new version string
- **Re-sign @generated**: And re-generate the headers
Then commit to branch. This ensures that if there are no changes, we'll
skip.
---------
Co-authored-by: Timothy Yung <yungsters@gmail.com>
## Summary
See #29737
## How did you test this change?
As the feature requires module support and the test runner does
currently not support running tests as modules, I could only test it via
playground.
The goal is to improve speed of the development by inlining and DCE
unused branches.
We have the ability to preserve some variable names and pretty print in
the production version so might as well do the same with DEV.
When we made stylesheets suspend even during high priority updates we
exposed a bug in the loading tracking of stylesheets that are loaded as
part of the preamble. This allowed these stylesheets to put suspense
boundaries into fallback mode more often than expected because cases
where a stylesheet was server rendered could now cause a fallback to
trigger which was never intended to happen.
This fix updates resource construction to evaluate whether the instance
exists in the DOM prior to construction and if so marks the resource as
loaded and inserted.
One ambiguity that needed to be solved still is how to tell whether a
stylesheet rendered as part of a late Suspense boundary reveal is
already loaded. I updated the instruction to clear out the loading
promise after successfully loading. This is useful because later if we
encounter this same resource again we can avoid the microtask if it is
already loaded. It also means that we can concretely understand that if
a stylesheet is in the DOM without this marker then it must have loaded
(or errored) already.
This PR makes it so we always emit a const VariableDeclaration for
compiled functions in gating mode. If the original declaration's parent
was an ExportDefaultDeclaration we'll also append a new
ExportDefaultDeclaration pointing to the new identifier. This allows
code that adds optional properties to the function declaration to still
work in gating mode
ghstack-source-id: 5705479135baa268eeb3c85bfbf1883964e84916
Pull Request resolved: https://github.com/facebook/react/pull/29806
When gating is enabled, any function declaration properties that were
previously set (typically `Function.displayName`) would cause a crash
after compilation as the original identifier is no longer present.
ghstack-source-id: beb7e258561ea598d306fa67706d34a8788d9322
Pull Request resolved: https://github.com/facebook/react/pull/29802
This refactors key warning to happen inline after we've matched a Fiber.
I didn't want to do that originally because it was riskier. But it turns
out to be straightforward enough.
This lets us use that Fiber as the source of the warning which matters
to DevTools because then DevTools can associate it with the right
component after it mounts.
We can also associate the duplicate key warning with this Fiber. That
way we'll get the callsite with the duplicate key on the stack and can
associate this warning with the child that had the duplicate.
I kept the forked DevTools tests because the warning now is counted on
the Child instead of the Parent (18 behavior).
However, this won't be released in 19.0.0 so I only test this in
whatever the next version is.
Doesn't seem worth it to have a test for just the 19.0.0 behavior.
Fixes false positives where we currently disallow mutations of refs from callbacks passed to JSX, if the ref is also passed to jsx. We consider these to be mutations of "frozen" values, but refs are explicitly allowed to have interior mutability. The fix is to always allow (at leat within InferReferenceEffects) for refs to be mutated. This means we completely rely on ValidateNoRefAccessInRender to validate ref access and stop reporting false positives.
ghstack-source-id: 1a30609f5f
Pull Request resolved: https://github.com/facebook/react/pull/29733
Stacked on #29491
Previously if you aborted during a render the currently rendering task
would itself be aborted which will cause the entire model to be replaced
by the aborted error rather than just the slot currently being rendered.
This change updates the abort logic to mark currently rendering tasks as
aborted but allowing the current render to emit a partially serialized
model with an error reference in place of the current model.
The intent is to support aborting from rendering synchronously, in
microtasks (after an await or in a .then) and in lazy initializers. We
don't specifically support aborting from things like proxies that might
be triggered during serialization of props
## Summary
The test started to fail after
https://github.com/facebook/react/pull/29088.
Fork the test and the expected store state for:
- React 18.x, to represent the previous behavior
- React >= 19, to represent the current RDT behavior, where error can't
be connected to the fiber, because it was not yet mounted and shared
with DevTools.
Ideally, DevTools should start keeping track of such fibers, but also
distinguish them from some that haven't mounted due to Suspense or error
boundaries.
We don't always have the NODE_ENV set, so additionally check for the
__DEV__ global if it has one set.
ghstack-source-id: 3719a4710a5fb1b4abf511f469c815917b7dfdf4
Pull Request resolved: https://github.com/facebook/react/pull/29785
Stacked on #29551
Flight pings much more often than Fizz because async function components
will always take at least a microtask to resolve . Rather than
scheduling this work as a new macrotask Flight now schedules pings in a
microtask. This allows more microtasks to ping before actually doing a
work flush but doesn't force the vm to spin up a new task which is quite
common give n the nature of Server Components
While most builds of Flight and Fizz schedule work in new tasks some do
execute work synchronously. While this is necessary for legacy APIs like
renderToString for modern APIs there really isn't a great reason to do
this synchronously.
We could schedule works as microtasks but we actually want to yield so
the runtime can run events and other things that will unblock additional
work before starting the next work loop.
This change updates all non-legacy uses to be async using the best
availalble macrotask scheduler.
Browser now uses postMessage
Bun uses setTimeout because while it also supports setImmediate the
scheduling is not as eager as the same API in node
the FB build also uses setTimeout
This change required a number of changes to tests which were utilizing
the sync nature of work in the Browser builds to avoid having to manage
timers and tasks. I added a patch to install MessageChannel which is
required by the browser builds and made this patched version integrate
with the Scheduler mock. This way we can effectively use `act` to flush
flight and fizz work similar to how we do this on the client.
Summary
The dispatch function from useReducer is stable, so it is also non-reactive.
the related PR: #29665
the related comment: #29674 (comment)
I am not sure if the location of the new test file is appropriate😅.
How did you test this change?
Added the specific test compiler/packages/babel-plugin-react-compiler/src/__tests__/fixtures/compiler/useReducer-returned-dispatcher-is-non-reactive.expect.md.
## Summary
There was an attempt to upgrade `ip` to 2.0.1 to mitigate CVE in
https://github.com/facebook/react/pull/29725#issuecomment-2150389616,
but there actually another one CVE in version `2.0.1`. Instead, migrate
to `internal-ip`, which similarly small package that we can use
Note: not upgrading to version 7+, because they are pure ESM.
## How did you test this change?
Validated that standalone version of RDT works and connects to the app.
## Summary
We currently do deep diffing for object props, and also use custom
differs, if they are defined, for props with custom attribute config.
The idea is to simply do a `===` comparison instead of all that work. We
will do less computation on the JS side, but send more data to native.
The hypothesis is that this change should be neutral in terms of
performance. If that's the case, we'll be able to get rid of custom
differs, and be one step closer to deleting view configs.
This PR adds the `enableShallowPropDiffing` feature flag to support this
experiment.
## How did you test this change?
With `enableShallowPropDiffing` hardcoded to `true`:
```
yarn test packages/react-native-renderer
```
This fails on the following test cases:
- should use the diff attribute
- should do deep diffs of Objects by default
- should skip deeply-nested changed functions
Which makes sense with this change. These test cases should be deleted
if the experiment is shipped.
This lets us ensure that we use the original V8 format and it lets us
skip source mapping. Source mapping every call can be expensive since we
do it eagerly for server components even if an error doesn't happen.
In the case of an error being thrown we don't actually always do this in
practice because if a try/catch before us touches it or if something in
onError touches it (which the default console.error does), it has
already been initialized. So we have to be resilient to thrown errors
having other formats.
These are not as perf sensitive since something actually threw but if
you want better perf in these cases, you can simply do something like
`onError(error) { console.error(error.message) }` instead.
The server has to be aware whether it's looking up original or compiled
output. I currently use the file:// check to determine if it's referring
to a source mapped file or compiled file in the fixture. A bundled app
can more easily check if it's a bundle or not.
Normally we take the renderClientElement path but this is an internal
fast path.
No tests because we don't run tests with console.createTask (which is
not easy since we test component stacks).
Ideally this would be covered by types but since the types don't
consider flags and DEV it doesn't really help.
## Overview
We didn't have any tests that ran in persistent mode with the xplat
feature flags (for either variant).
As a result, invalid test gating like in
https://github.com/facebook/react/pull/29664 were not caught.
This PR adds test flavors for `ReactFeatureFlag-native-fb.js` in both
variants.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Remove `startTransition` and `useActionState` from `react-server`
condition of react, as they should only stay in client bundle.
This will reduce the server bundle of react itself.
Found this while tracing where the `process.emit` was called.
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
Following the instructions in the compiler/docs/DEVELOPMENT_GUIDE.md, we are stuck on the command `yarn snap --watch` because it calls readTestFilter even though the filter option is not enabled.
Use some clever git diffing to ignore lines that only change the
`@generated` header. We can't do this for the version string because the
version string can be embedded in lines with other changes, but this
header is always on one line.
This information is available in the regular stack but since that's
hidden behind an expando and our appended stack to logs is not hidden,
it hides the most important frames like the name of the current
component.
This is closer to what happens to the native stack.
We only include stacks if they're within a ReactFiberCallUserSpace call
frame. This should be most that have a current fiber but this is
critical to filtering out most React frames if the regular node_modules
filter doesn't work.
Most React warnings fire during the rendering phase and not inside a
user space function but some do like hooks warnings and setState in
render. This feature is more important if we port this to React DevTools
appending stacks to all logs where it's likely to originate from inside
a component and you want the line within that component to immediately
part of the visible stack.
One thing that kind sucks is that we don't have a reliable way to
exclude React internal stack frames. We filter node_modules but it might
not match. For other cases I try hard to only track the stack frame at
the root of React (e.g. immediately inside createElement) until the
ReactFiberCallUserSpace so we don't need the filtering to work. In this
case it's hard to achieve the same thing though. This is easier in RDT
because we have the start/end line and parsing of stack traces so we can
use that to exclude internals but that's a lot of code/complexity for
shipping within the library.
For example in Safari:
<img width="590" alt="Screenshot 2024-05-31 at 6 15 27 PM"
src="https://github.com/facebook/react/assets/63648/2820c8c0-8a03-42e9-8678-8348f66b051a">
Ideally warnOnUseFormStateInDev and useFormState wouldn't be included
since they're React internals. Before this change, the Counter.js line
also wasn't included though which points to exactly where the error is
within the user code.
(Note Server Components have V8 formatted lines and Client Components
have JSC formatted lines.)
RC releases are a special kind of prerelease build because unlike
canaries we shouldn't publish new RCs from any commit on `main`, only
when we intentionally bump the RC number. But they are still prerelases
— like canary and experimental releases, they should use exact version
numbers in their dependencies (no ^).
We only need to generate these builds during the RC phase, i.e. when the
canary channel label is set to "rc".
Example of resulting package.json output:
```json
{
"name": "react-dom",
"version": "19.0.0-rc.0",
"dependencies": {
"scheduler": "0.25.0-rc.0"
},
"peerDependencies": {
"react": "19.0.0-rc.0"
}
}
```
https://react-builds.vercel.app/prs/29736/files/oss-stable-rc/react-dom/package.json
Based on
- #29694
---
If an action in the useActionState queue errors, we shouldn't run any
subsequent actions. The contract of useActionState is that the actions
run in sequence, and that one action can assume that all previous
actions have completed successfully.
For example, in a shopping cart UI, you might dispatch an "Add to cart"
action followed by a "Checkout" action. If the "Add to cart" action
errors, the "Checkout" action should not run.
An implication of this change is that once useActionState falls into an
error state, the only way to recover is to reset the component tree,
i.e. by unmounting and remounting. The way to customize the error
handling behavior is to wrap the action body in a try/catch.
Mini-refactor of useActionState to only wrap the action in a transition
context if the dispatch is called during a transition. Conceptually, the
action starts as soon as the dispatch is called, even if the action is
queued until earlier ones finish.
We will also warn if an async action is dispatched outside of a
transition, since that is almost certainly a mistake. Ideally we would
automatically upgrade these to a transition, but we don't have a great
way to tell if the action is async until after it's already run.
Host Components can exist as four semantic types
1. regular Components (Vanilla obv)
2. singleton Components
2. hoistable components
3. resources
Each of these component types have their own rules related to mounting
and reconciliation however they are not direclty modeled as their own
unique fiber type. This is partly for code size but also because
reconciling the inner type of these components would be in a very hot
path in fiber creation and reconciliation and it's just not practical to
do this logic check here.
Right now we have three Fiber types used to implement these 4 concepts
but we probably need to reconsider the model and think of Host
Components as a single fiber type with an inner implementation. Once we
do this we can regularize things like transitioning between a resource
and a regular component or a singleton and a hoistable instance. The
cases where these transitions happen today aren't particularly common
but they can be observed and currently the handling of these transitions
is incomplete at best and buggy at worst. The most egregious case is the
link type. This can be a regular component (stylesheet without
precedence) a hoistable component (non stylesheet link tags) or a
resource (stylesheet with a precedence) and if you have a single jsx
slot that tries to reconcile transitions between these types it just
doesn't work well.
This commit adds an error for when a Hoistable goes from Instance to
Resource. Currently this is only possible for `<link>` elements going to
and from stylesheets with precedence. Hopefully we'll be able to remove
this error and implement as an inner type before we encounter new
categories for the Hoistable types
detecting type shifting to and from regular components is harder to do
efficiently because we don't want to reevaluate the type on every update
for host components which is currently not required and would add
overhead to a very hot path
singletons can't really type shift in their one practical implementation
(DOM) so they are only a problem in theroy not practice
Requires https://github.com/facebook/react/pull/29706
The strategy here is to:
- Checkout the builds/facebook-www branch
- Read the current sync'd VERSION
- Checkout out main and sync new build
- sed/{new version string}/{old version string}
- Run git status, skip sync if clean
- Otherwise, sed/{old version string}/{new version string} and push
commit
This means that:
- We're using the real version strings from the builds
- We are checking the last commit on the branch for the real last
version
- We're skipping any commits that won't result in changes
- ???
- Profit!
This lets you click a stack frame on the client and see the Server
source code inline.
<img width="871" alt="Screenshot 2024-06-01 at 11 44 24 PM"
src="https://github.com/facebook/react/assets/63648/581281ce-0dce-40c0-a084-4a6d53ba1682">
<img width="840" alt="Screenshot 2024-06-01 at 11 43 37 PM"
src="https://github.com/facebook/react/assets/63648/00dc77af-07c1-4389-9ae0-cf1f45199efb">
We could do some logic on the server that sends a source map url for
every stack frame in the RSC payload. That would make the client
potentially config free. However regardless we need the config to
describe what url scheme to use since that’s not built in to the bundler
config. In practice you likely have a common pattern for your source
maps so no need to send data over and over when we can just have a
simple function configured on the client.
The server must return a source map, even if the file is not actually
compiled since the fake file is still compiled.
The source mapping strategy can be one of two models depending on if the
server’s stack traces (`new Error().stack`) are source mapped back to
the original (`—enable-source-maps`) or represents the location in
compiled code (like in the browser).
If it represents the location in compiled code it’s actually easier. You
just serve the source map generated for that file by the tooling.
If it is already source mapped it has to generate a source map where
everything points to the same location (as if not compiled) ideally with
a segment per logical ast node.
Eslint rules should never throw, so if we fail to parse with Babel or
Hermes, we should just ignore the error. This should fix issues such as
trying to run the eslint rule on non tsx|ts|jsx|js files, Hermes parser
not supporting certain JS syntax, etc.
I didn't add a test for this as our eslint-rule-tester config uses
hermes-eslint parser, so it wasn't possible to add a top level await as
it would crash hermes-eslint before our rule was triggered. Similarly I
couldn't add a test for non-JS files as it would not be parseable by
hermes-eslint.
Fixes#29107
ghstack-source-id: 60afcdb89ab4a8d2e4697cc50c5490803e7cbeac
Pull Request resolved: https://github.com/facebook/react/pull/29631
When a component suspends with `use`, we switch to the "re-render"
dispatcher during the subsequent render attempt, so that we can reuse
the work from the initial attempt. However, once we run out of hooks
from the previous attempt, we should switch back to the regular "update"
dispatcher.
This is conceptually the same fix as the one introduced in
https://github.com/facebook/react/pull/26232. That fix only accounted
for initial mount, but the useTransition regression test added in
f82973302b3f490ec120c3b102e8c3792452dfc9 illustrates that we need to
handle updates, too.
The issue affects more than just useTransition but because most of the
behavior between the "re-render" and "update" dispatchers is the same
it's hard to contrive other scenarios in a test, which is probably why
it took so long for someone to notice.
Closes#28923 and #29209
---------
Co-authored-by: eps1lon <sebastian.silbermann@vercel.com>
Summary: Using the change detection code to debug codebases that violate the rules of react is a lot easier when we have a source location corresponding to the value that has changed inappropriately. I didn't see an easy way to track that information in the existing data structures at the point of codegen, so this PR adds locations to identifiers and reactive scopes (the location of a reactive scope is the range of the locations of its included identifiers).
I'm interested if there's a better way to do this that I missed!
ghstack-source-id: aed5f7edda
Pull Request resolved: https://github.com/facebook/react/pull/29658
Summary: This PR expands the analysis from the previous in the stack in order to also capture when a value can incorrectly change within a single render, rather than just changing between two renders. In the case where dependencies have changed and so a new value is being computed, we now compute the value twice and compare the results. This would, for example, catch when we call Math.random() in render.
The generated code is a little convoluted, because we don't want to have to traverse the generated code and substitute variable names with new ones. Instead, we save the initial value to the cache as normal, then run the computation block again and compare the resulting values to the cached ones. Then, to make sure that the cached values are identical to the computed ones, we reassign the cached values into the output variables.
ghstack-source-id: d0f11a4cb2
Pull Request resolved: https://github.com/facebook/react/pull/29657
Summary: jmbrown215 recently had an observation that the arguments to useState/useRef are only used when a component renders for the first time, and never afterwards. We can skip more computation that we previously could, with reactive blocks that previously recomputed values when inputs changed now only ever computing them on the first render.
ghstack-source-id: 5d044ef787
Pull Request resolved: https://github.com/facebook/react/pull/29653
Summary: The essential assumption of the compiler is that if the inputs to a computation have not changed, then the output should not change either--computation that the compiler optimizes is idempotent.
This is, of course, known to be false in practice, because this property rests on requirements (the Rules of React) that are loosely enforced at best. When rolling out the compiler to a codebase that might have rules of react violations, how should developers debug any issues that arise?
This diff attempts one approach to that: when the option is set, rather than simply skipping computation when dependencies haven't changed, we will *still perform the computation*, but will then use a runtime function to compare the original value and the resultant value. The runtime function can be customized, but the idea is that it will perform a structural equality check on the values, and if the values aren't structurally equal, we can report an error, including information about what file and what variable was to blame.
This assists in debugging by narrowing down what specific computation is responsible for a difference in behavior between the uncompiled code and the program after compilation.
ghstack-source-id: 50dad3dacf
Pull Request resolved: https://github.com/facebook/react/pull/29656
Summary: This adds a debugging mode to the compiler that simply adds a `|| true` to the guard on all memoization blocks, which results in the generated code never using memoized values and always recomputing them. This is designed as a validation tool for the compiler's correctness--every program *should* behave exactly the same with this option enabled as it would with it disabled, and so any difference in behavior should be investigated as either a compiler bug or a pipeline issue.
(We add `|| true` rather than dropping the conditional block entirely because we still want to exercise the guard tests, in case the guards themselves are the source of an error, like reading a property from undefined in a guard.)
ghstack-source-id: 955a47ec16
Pull Request resolved: https://github.com/facebook/react/pull/29655
Summary: This adds a compiler option to not drop existing manual memoization and leaving useMemo/useCallback in the generated source. Why do we need this, given that we also have options to validate or ensure that existing memoization is preserved? It's because later diffs on this stack are designed to alter the behavior of the memoization that the compiler emits, in order to detect rules of react violations and debug issues. We don't want to change the behavior of user-level memoization, however, since doing so would be altering the semantics of the user's program in an unacceptable way.
ghstack-source-id: 89dccdec9ccb4306b16e849e9fa2170bb5dd021f
Pull Request resolved: https://github.com/facebook/react/pull/29654
This lets any element created from the server, to bottom out with a
client "owner" which is the creator of the Flight request. This could be
a Server Action being invoked or a router.
This is similar to how a client element bottoms out in the creator of
the root element without an owner. E.g. where the root app element was
created.
Without this, we inherit the task of whatever is currently executing
when we're parsing which can be misleading.
Before:
<img width="507" alt="Screenshot 2024-05-30 at 12 06 57 PM"
src="https://github.com/facebook/react/assets/63648/e234db7e-67f7-404c-958a-5c5500ffdf1f">
After:
<img width="555" alt="Screenshot 2024-05-30 at 4 59 04 PM"
src="https://github.com/facebook/react/assets/63648/8ba6acb4-2ffd-49d4-bd44-08228ad4200e">
The before/after doesn't show much of a difference here but that's just
because our Flight parsing loop is an async, which maybe it shouldn't be
because it can be unnecessarily deep, and it creates a hidden line for
every loop. That's what the `Promise.then` is. If the element is lazily
initialized it's worse because we can end up in an unrelated render task
as the owner - although that's its own problem.
We're getting a ton of issues filed using the blank template, for
example these airline support tickets:
https://github.com/facebook/react/issues/29678
I think someone somewhere is linking to our issues with pre-filled
content. This fixes it by forcing a template to be used.
When defining a displayName on forwardRef/memo we forward that name to
the inner function.
We used to use displayName for this but in #29206 I switched this to use
`"name"`. That's because V8 doesn't use displayName, it only uses the
overridden name in stack traces. This is the only thing covered by our
tests for component stacks.
However, I realized that Safari only uses displayName and not the name.
So this sets both.
## Summary
In https://github.com/facebook/react/pull/29088, the validation logic
for `React.Children` inspected whether `mappedChild` — the return value
of the map callback — has a valid `key`. However, this deviates from
existing behavior which only warns if the original `child` is missing a
required `key`.
This fixes false positive `key` validation warnings when using
`React.Children`, by validating the original `child` instead of
`mappedChild`.
This is a more general fix that expands upon my previous fix in
https://github.com/facebook/react/pull/29662.
## How did you test this change?
```
$ yarn test ReactChildren-test.js
```
Follow up to https://github.com/facebook/react/pull/29632.
It's possible for `eval` to throw such as if we're in a CSP environment.
This is non-essential debug information. We can still proceed to create
a fake stack entry. It'll still have the right name. It just won't have
the right line/col number nor source url/source map. It might also be
ignored listed since it's inside Flight.
We have three kinds of stacks that we send in the RSC protocol:
- The stack trace where a replayed `console.log` was called on the
server.
- The JSX callsite that created a Server Component which then later
called another component.
- The JSX callsite that created a Host or Client Component.
These stack frames disappear in native stacks on the client since
they're executed on the server. This evals a fake file which only has
one call in it on the same line/column as the server. Then we call
through these fake modules to "replay" the callstack. We then replay the
`console.log` within this stack, or call `console.createTask` in this
stack to recreate the stack.
The main concern with this approach is the performance. It adds
significant cost to create all these eval:ed functions but it should
eventually balance out.
This doesn't yet apply source maps to these. With source maps it'll be
able to show the server source code when clicking the links.
I don't love how these appear.
- Because we haven't yet initialized the client module we don't have the
name of the client component we're about to render yet which leads to
the `<...>` task name.
- The `(async)` suffix Chrome adds is still a problem.
- The VMxxxx prefix is used to disambiguate which is noisy. Might be
helped by source maps.
- The continuation of the async stacks end up rooted somewhere in the
bootstrapping of the app. This might be ok when the bootstrapping ends
up ignore listed but it's kind of a problem that you can't clear the
async stack.
<img width="927" alt="Screenshot 2024-05-28 at 11 58 56 PM"
src="https://github.com/facebook/react/assets/63648/1c9d32ce-e671-47c8-9d18-9fab3bffabd0">
<img width="431" alt="Screenshot 2024-05-28 at 11 58 07 PM"
src="https://github.com/facebook/react/assets/63648/52f57518-bbed-400e-952d-6650835ac6b6">
<img width="327" alt="Screenshot 2024-05-28 at 11 58 31 PM"
src="https://github.com/facebook/react/assets/63648/d311a639-79a1-457f-9a46-4f3298d07e65">
<img width="817" alt="Screenshot 2024-05-28 at 11 59 12 PM"
src="https://github.com/facebook/react/assets/63648/3aefd356-acf4-4daa-bdbf-b8c8345f6d4b">
Partially reverts https://github.com/facebook/react/pull/28593.
While rolling out RDT 5.2.0, I've observed some issues on React Native
side: hooks inspection for some complex hook trees, like in
AnimatedView, were broken. After some debugging, I've noticed a
difference between what is in frame's source.
The difference is in the top-most frame, where with V8 it will correctly
pick up the `Type` as `Proxy` in `hookStack`, but for Hermes it will be
`Object`. This means that for React Native this top most frame is
skipped, since sources are identical.
Here I am reverting back to the previous logic, where we check each
frame if its a part of the wrapper, but also updated `isReactWrapper`
function to have an explicit case for `useFormStatus` support.
## Summary
https://github.com/facebook/react/pull/29088 introduced a regression
triggering this warning when rendering flattened positional children:
> Each child in a list should have a unique "key" prop.
The specific scenario that triggers this is when rendering multiple
positional children (which do not require unique `key` props) after
flattening them with one of the `React.Children` utilities (e.g.
`React.Children.toArray`).
The refactored logic in `React.Children` incorrectly drops the
`element._store.validated` property in `__DEV__`. This diff fixes the
bug and introduces a unit test to prevent future regressions.
## How did you test this change?
```
$ yarn test ReactChildren-test.js
```
## Summary
This PR add tests for `ReactNativeAttributePayloadFabric.js`.
It introduces `ReactNativeAttributePayloadFabric-test.internal.js`,
which is a copy-paste of `ReactNativeAttributePayload-test.internal.js`.
On top of that, there is a bunch of new test cases for the
`ReactNativeAttributePayloadFabric.create` function.
## How did you test this change?
```
yarn test packages/react-native-renderer
```
## Summary
Resolves#29622
## How did you test this change?
I verified the implementation using the test.
Note:
This PR was done without waiting for approval in #29622, so feel free to
just close it.
We were missing a check that ObjectMethods are not getters or setters. In our experience this is pretty rare within React components and hooks themselves, so let's start with a todo.
Closes#29586
ghstack-source-id: 03c6cce9a9
Pull Request resolved: https://github.com/facebook/react/pull/29592
Fixes https://x.com/raibima/status/1794395807216738792
The issue is that if you pass a global-modifying function as prop to JSX, we currently report that it's invalid to modify a global during rendering. The problem is that we don't really know when/if the child component will actually call that function prop. It would be against the rules to call the function during render, but it's totally fine to call it during an event handler or from a useEffect.
Since we don't know at the call-site how the child will use the function, we should allow such calls. In the future we could improve this in a few ways:
* For all functions that modify globals, codegen an assertion or warning into the function that fires if it's called "during render". We'd have to precisely define what "during render" is, but this would at least help developers catch this dynamically.
* Use the type system to distinguish "event/effect" and "render" functions to help developers avoid accidentally mutating globals during render.
ghstack-source-id: 4aba4e6d21
Pull Request resolved: https://github.com/facebook/react/pull/29591
- Moves the file as it needs to be in root git directory
- Removes now unreachable commits due to repo merge
- Add run prettier commit c998bb1ed4 to ignored revs
ghstack-source-id: d9dfa7099fbc7782fbce600af4caafd405c196cb
Pull Request resolved: https://github.com/facebook/react/pull/29630
This was missed in https://github.com/facebook/react/pull/29038 when
unifying the "owner" abstractions, causing `findNodeHandle` to warn even
outside of `render()` invocations.
user's pipeline
When the user app has a babel.config file that is missing the compiler,
strange things happen as babel does some strange merging of options from
the user's config and in various callsites like in our eslint rule and
healthcheck script. To minimize odd behavior, we default to not reading
the user's babel.config
Fixes#29135
ghstack-source-id: d6fdc43c5c
Pull Request resolved: https://github.com/facebook/react/pull/29211
After this is merged, I'll add it to .git-blame-ignore-revs. I can't do
it now as the hash will change after ghstack lands this stack.
ghstack-source-id: 054ca869b7
Pull Request resolved: https://github.com/facebook/react/pull/29214
This didn't actually fail before but I'm just adding an extra check.
Currently Client References are always "function" proxies so they never
fall into this branch. However, we do in theory support objects as
client references too depending on environment. We have checks
elsewhere. So this just makes that consistent.
When I added new builtin types for jsx and functions, i forget to add a shape definition. This meant that attempting to accesss a property or method on these types would cause an internal error with an unresolved shape. That wasn't obvious because we rarely call methods on these types.
I confirmed that the new fixtures here fail without the fix.
ghstack-source-id: aa8f8d75a3
Pull Request resolved: https://github.com/facebook/react/pull/29624
We currently don't report an error if the code attempts to reassign a const. Our thinking has been that we're not trying to catch all possible mistakes you could make in JavaScript — that's what ESLint, TypeScript, and Flow are for — and that we want to focus on React errors. However, accidentally reassigning a const is easy to catch and doesn't get in the way of other analysis so let's implement it.
Note that React Compiler's ESLint plugin won't report these errors by default, but they will show up in playground.
Fixes#29598
ghstack-source-id: a0af8b9a486d74a8991413322efddc3e3028c755
Pull Request resolved: https://github.com/facebook/react/pull/29619
Fixes the behavior of actions that are queued by useActionState to use
the action function that was current at the time it was dispatched, not
at the time it eventually executes.
The conceptual model is that the action is immediately dispatched, as if
it were sent to a remote server/worker. It's the remote worker that
maintains the queue, not the client.
This is another property of actions makes them more like event handlers
than like reducers.
`disableDOMTestUtils` and the FB build `ReactTestUtilsFB` allowed us to
finish migrating internal callsites off of ReactTestUtils. Now that
usage is cleaned up, we can remove the flag, build artifact, and test
coverage for the deprecated utility methods.
Throw an error during module initialization if the version of the
"react-dom" package does not match the version of "react".
We used to be more relaxed about this, because the "react" package
changed so infrequently. However, we now have many more features that
rely on an internal protocol between the two packages, including Hooks,
Float, and the compiler runtime. So it's important that both packages
are versioned in lockstep.
Before this change, a version mismatch would often result in a cryptic
internal error with no indication of the root cause.
Instead, we will now compare the versions during module initialization
and immediately throw an error to catch mistakes as early as possible
and provide a clear error message.
Stacked on #29206 and #29221.
This disables appending owner stacks to console when
`console.createTask` is available in the environment. Instead we rely on
native "async" stacks that end up looking like this with source maps and
ignore list enabled.
<img width="673" alt="Screenshot 2024-05-22 at 4 00 27 PM"
src="https://github.com/facebook/react/assets/63648/5313ed53-b298-4386-8f76-8eb85bdfbbc7">
Unfortunately Chrome requires a string name for each async stack and,
worse, a suffix of `(async)` is automatically added which is very
confusing since it seems like it might be an async component or
something which it is not.
In this case it's not so bad because it's nice to refer to the host
component which otherwise doesn't have a stack frame since it's
internal. However, if there were more owners here there would also be a
`<Counter> (async)` which ends up being kind of duplicative.
If the Chrome DevTools is not open from the start of the app, then
`console.createTask` is disabled and so you lose the stack for those
errors (or those parents if the devtools is opened later). Unlike our
appended ones that are always added. That's unfortunate and likely to be
a bit of a DX issue but it's also nice that it saves on perf in DEV mode
for those cases. Framework dialogs can still surface the stack since we
also track it in user space in parallel.
This currently doesn't track Server Components yet. We need a more
clever hack for that part in a follow up.
I think I probably need to also add something to React DevTools to
disable its stacks for this case too. Since it looks for stacks in the
console.error and adds a stack otherwise. Since we don't add them
anymore from the runtime, the DevTools adds them instead.
Stacked on #29044.
To work with `console.createTask(...).run(...)` we need to be able to
run a function in the scope of the task.
The main concern with this, other than general performance, is that it
might add more stack frames on very deep stacks that hit the stack
limit. Such as with the commit phase where we recursively go down the
tree. These callbacks aren't really necessary in the recursive part but
only in the shallow invocation of the commit phase for each tag. So we
could refactor the commit phase so that only the shallow part at each
level is covered this way.
This one should be fully behind the `enableOwnerStacks` flag.
Instead of printing the parent Component stack all the way to the root,
this now prints the owner stack of every JSX callsite. It also includes
intermediate callsites between the Component and the JSX call so it has
potentially more frames. Mainly it provides the line number of the JSX
callsite. In terms of the number of components is a subset of the parent
component stack so it's less information in that regard. This is usually
better since it's more focused on components that might affect the
output but if it's contextual based on rendering it's still good to have
parent stack. Therefore, I still use the parent stack when printing DOM
nesting warnings but I plan on switching that format to a diff view
format instead (Next.js already reformats the parent stack like this).
__Follow ups__
- Server Components show up in the owner stack for client logs but logs
done by Server Components don't yet get their owner stack printed as
they're replayed. They're also not yet printed in the server logs of the
RSC server.
- Server Component stack frames are formatted as the server and added to
the end but this might be a different format than the browser. E.g. if
server is running V8 and browser is running JSC or vice versa. Ideally
we can reformat them in terms of the client formatting.
- This doesn't yet update Fizz or DevTools. Those will be follow ups.
Fizz still prints parent stacks in the server side logs. The stacks
added to user space `console.error` calls by DevTools still get the
parent stacks instead.
- It also doesn't yet expose these to user space so there's no way to
get them inside `onCaughtError` for example or inside a custom
`console.error` override.
- In another follow up I'll use `console.createTask` instead and
completely remove these stacks if it's available.
Updates Environment#getGlobalDeclaration() to only resolve "globals" if they are a true global or an import from react/react-dom. We still keep the logic to resolve hook-like names as custom hooks. Notably, this means that a local `Array` reference won't get confused with our Array global declaration, a local `useState` (or import from something other than React) won't get confused as `React.useState()`, etc.
I tried to write a proper fixture test to test that we react to changes to a custom setState setter function, but I think there may be an issue with snap and how it handles re-renders from effects. I think the tests are good here but open to feedback if we want to go down the rabbit hole of figuring out a proper snap test for this.
ghstack-source-id: 5e9a8f6e0d23659c72a9d041e8d394b83d6e526d
Pull Request resolved: https://github.com/facebook/react/pull/29190
No-op refactor to make Environment#getGlobalDeclaration() take a NonLocalBinding instead of just a name. The idea is that in subsequent PRs we can use information about the binding to resolve a type more accurately. For example, we can resolve `Array` differently if its an import or local and not the global Array. Similar for resolving local `useState` differently than the one from React.
ghstack-source-id: c8063e6fb8acdd347a56477d6b06238dd54979b1
Pull Request resolved: https://github.com/facebook/react/pull/29189
We currently use `LoadGlobal` and `StoreGlobal` to represent any read (or write) of a variable defined outside the component or hook that is being compiled. This is mostly fine, but for a lot of things we want to do going forward (resolving types across modules, for example) it helps to understand the actual source of a variable.
This PR is an incremental step in that direction. We continue to use LoadGlobal/StoreGlobal, but LoadGlobal now has a `binding:NonLocalBinding` instead of just the name of the global. The NonLocalBinding type tells us whether it was an import (and which kind, the source module name etc), a module-local binding, or a true global. By keeping the LoadGlobal/StoreGlobal instructions, most code that deals with "anything not declared locally" doesn't have to care about the difference. However, code that _does_ want to know the source of the value can figure it out.
ghstack-source-id: e701d4ebc0fb5681a0197198ac2c2a03b3e8aae9
Pull Request resolved: https://github.com/facebook/react/pull/29188
Note: Despite the similar-sounding description, this fix is unrelated to
the issue where updates that occur after an `await` in an async action
must also be wrapped in their own `startTransition`, due to the absence
of an AsyncContext mechanism in browsers today.
---
Discovered a flaw in the current implementation of the isomorphic
startTransition implementation (React.startTransition), related to async
actions. It only creates an async scope if something calls setState
within the synchronous part of the action (i.e. before the first
`await`). I had thought this was fine because if there's no update
during this part, then there's nothing that needs to be entangled. I
didn't think this through, though — if there are multiple async updates
interleaved throughout the rest of the action, we need the async scope
to have already been created so that _those_ are batched together.
An even easier way to observe this is to schedule an optimistic update
after an `await` — the optimistic update should not be reverted until
the async action is complete.
To implement, during the reconciler's module initialization, we compose
its startTransition implementation with any previous reconciler's
startTransition that was already initialized. Then, the isomorphic
startTransition is the composition of every
reconciler's startTransition.
```js
function startTransition(fn) {
return startTransitionDOM(() => {
return startTransitionART(() => {
return startTransitionThreeFiber(() => {
// and so on...
return fn();
});
});
});
}
```
This is basically how flushSync is implemented, too.
Previously Suspensey recursion would only trigger if the
ShouldSuspendCommit flag was true. However there is a dependence on the
Visibility flag embedded in this logic because these flags share a bit.
To make it clear that the semantics of Suspensey resources require
considering both flags I've added it to the condition even though this
extra or-ing is a noop when the bit is shared
This is necessary to simplify the component stack handling to make way
for owner stacks. It also solves some hacks that we used to have but
don't quite make sense. It also solves the problem where things like key
warnings get silenced in RSC because they get deduped. It also surfaces
areas where we were missing key warnings to begin with.
Almost every type of warning is issued from the renderer. React Elements
are really not anything special themselves. They're just lazily invoked
functions and its really the renderer that determines there semantics.
We have three types of warnings that previously fired in
JSX/createElement:
- Fragment props validation.
- Type validation.
- Key warning.
It's nice to be able to do some validation in the JSX/createElement
because it has a more specific stack frame at the callsite. However,
that's the case for every type of component and validation. That's the
whole point of enableOwnerStacks. It's also not sufficient to do it in
JSX/createElement so we also have validation in the renderers too. So
this validation is really just an eager validation but also happens
again later.
The problem with these is that we don't really know what types are valid
until we get to the renderer. Additionally, by placing it in the
isomorphic code it becomes harder to do deduping of warnings in a way
that makes sense for that renderer. It also means we can't reuse logic
for managing stacks etc.
Fragment props validation really should just be part of the renderer
like any other component type. This also matters once we add Fragment
refs and other fragment features. So I moved this into Fiber. However,
since some Fragments don't have Fibers, I do the validation in
ChildFiber instead of beginWork where it would normally happen.
For `type` validation we already do validation when rendering. By
leaving it to the renderer we don't have to hard code an extra list.
This list also varies by context. E.g. class components aren't allowed
in RSC but client references are but we don't have an isomorphic way to
identify client references because they're defined by the host config so
the current logic is flawed anyway. I kept the early validation for now
without the `enableOwnerStacks` since it does provide a nicer stack
frame but with that flag on it'll be handled with nice stacks anyway. I
normalized some of the errors to ensure tests pass.
For `key` validation it's the same principle. The mechanism for the
heuristic is still the same - if it passes statically through a parent
JSX/createElement call then it's considered validated. We already did
print the error later from the renderer so this also disables the early
log in the `enableOwnerStacks` flag.
I also added logging to Fizz so that key warnings can print in SSR logs.
Flight is a bit more complex. For elements that end up on the client we
just pass the `validated` flag along to the client and let the client
renderer print the error once rendered. For server components we log the
error from Flight with the server component as the owner on the stack
which will allow us to print the right stack for context. The factoring
of this is a little tricky because we only want to warn if it's in an
array parent but we want to log the error later to get the right debug
info.
Fiber/Fizz has a similar factoring problem that causes us to create a
fake Fiber for the owner which means the logs won't be associated with
the right place in DevTools.
Repro of a case where we should ideally merge consecutive scopes, but where intermediate temporaries prevent the scopes from merging.
We'd need to reorder instructions in order to merge these.
ghstack-source-id: 4f05672604eeb547fc6c26ef99db6572843ac646
Pull Request resolved: https://github.com/facebook/react/pull/29197
In MergeReactiveScopesThatInvalidateTogether when deciding which scopes were eligible for mergin at all, we looked specifically at the instructions whose lvalue produces the declaration. So if a scope declaration was `t0`, we'd love for the instruction where `t0` was the lvalue and look at the instruction type to decide if it is eligible for merging.
Here, we use the inferred type instead (now that the inferred types support the same set of types of instructions we looked at before). This allows us to find more cases where scopes can be merged.
ghstack-source-id: 0e3e05f24ea0ac6e3c43046bc3e114f906747a04
Pull Request resolved: https://github.com/facebook/react/pull/29157
Improves merging of consecutive scopes so that we now merge two scopes if the dependencies of the second scope are a subset of the previous scope's output *and* that dependency has a type that will always produce a new value (array, object, jsx, function) if it is re-evaluated.
To make this easier, we extend the set of builtin types to include ones for function expressions and JSX and to infer these types in InferTypes. This allows using the already inferred types in MergeReactiveScopesThatInvalidateTogether.
ghstack-source-id: e9119fc4e02b3665848113d71fdff0c5bac3348a
Pull Request resolved: https://github.com/facebook/react/pull/29156
React Compiler attempts to merge consecutive reactive scopes in order to reduce overhead. The basic idea is that if two consecutive scopes would always invalidate together then we should merge them. It gets more complicated, though, because values produced by the earlier scope may not always invalidate when their inputs do. For example, a scope that produces `fn(x)` may not invalidate on all changes to `x` if the function is `Math.max(x, 10)` (changing x from 8 to 9 won't change the output).
Previously we were conservative and only merged if either:
* the two scopes had the same dependencies
* the second scope's deps exactly matched the previous scope's outputs.
You can see this in the new fixture, where the second `<button>` gets its own scope, which happens because the preceding scope has an extra output that isn't a dep of the `<button>`'s scope.
ghstack-source-id: d869c8d4df5aa4105bbdae01b5dd7f106145b351
Pull Request resolved: https://github.com/facebook/react/pull/29155
This lets us expose the component stack to the error reporting that
happens here as `console.error` patching. Now if you just call
`console.error` in the error handlers it'll get the component stack
added to the end by React DevTools.
However, unfortunately this happens a little too late so the Fiber will
be disconnected with its `.return` pointer set to null already. So it'll
be too late to extract a parent component stack from but you can at
least get the stack from source to error boundary. To work around this I
manually add the parent component stack in our default handlers when
owner stacks are off. We could potentially fix this but you can also
just include it yourself if you're calling `console.error` and it's not
a problem for owner stacks.
This is not a problem for owner stacks because we'll still have those
and so for those just calling `console.error` just works. However, the
main feature is that by letting React add them, we can switch to using
native error stacks when available.
We previously had two slightly different concepts for "current fiber".
There's the "owner" which is set inside of class components in prod if
string refs are enabled, and sometimes inside function components in DEV
but not other contexts.
Then we have the "current fiber" which is only set in DEV for various
warnings but is enabled in a bunch of contexts.
This unifies them into a single "current fiber".
The concept of string refs shouldn't really exist so this should really
be a DEV only concept. In the meantime, this sets the current fiber
inside class render only in prod, however, in DEV it's now enabled in
more contexts which can affect the string refs. That was already the
case that a string ref in a Function component was only connecting to
the owner in prod. Any string ref associated with any non-class won't
work regardless so that's not an issue. The practical change here is
that an element with a string ref created inside a life-cycle associated
with a class will work in DEV but not in prod. Since we need the current
fiber to be available in more contexts in DEV for the debugging
purposes. That wouldn't affect any old code since it would have a broken
ref anyway. New code shouldn't use string refs anyway.
The other implication is that "owner" doesn't necessarily mean
"rendering" since we need the "owner" to track other debug information
like stacks - in other contexts like useEffect, life cycles, etc.
Internally we have a separate `isRendering` flag that actually means
we're rendering but even that is a very overloaded concept. So anything
that uses "owner" to imply rendering might be wrong with this change.
This is a first step to a larger refactor for tracking current rendering
information.
---------
Co-authored-by: Sebastian Silbermann <silbermann.sebastian@gmail.com>
## Summary
We ran React compiler against part of our codebase and collected
compiler errors. One of the more common non-actionable errors is caused
by usage of the `!` TypeScript non-null assertion operation:
```
(BuildHIR::lowerExpression) Handle TSNonNullExpression expressions
```
It seems like React Compiler _should_ be able to support this by just
ignoring the syntax and using the underlying expression. I'm sure a lot
of our non-null assertion usage should not exist and I understand if
React Compiler does not want to support this syntax. It wasn't obvious
to me if this omission was intentional or if there are future plans to
use `TSNonNullExpression` as part of the compiler's analysis. If there
are no future plans it seems like just ignoring it should be fine.
## How did you test this change?
```sh
❯ yarn snap --filter
yarn run v1.17.3
$ yarn workspace babel-plugin-react-compiler run snap --filter
$ node ../snap/dist/main.js --filter
PASS non-null-assertion
1 Tests, 1 Passed, 0 Failed
```
In #29201 a fix was made to ensure we don't "forget" about some
listeners when handling cyclic chunks.
In #29204 another fix was made for a special case when the chunk already
has listeners before it first resolves.
This implements the followup fix for Flight Reply which was originally
missed in #29204
Co-authored-by: Janka Uryga <lolzatu2@gmail.com>
Updates Suspensey instances and resources to preload even during urgent
updates and to potentially suspend.
The current implementation is unchanged for transitions but for sync
updates if there is a suspense boundary above the resource/instance it
will be rendered in fallback mode instead.
Note: This behavior is not what we want for images once we make them
suspense enabled. We will need to have forked behavior here to
distinguish between stylesheets which should never commit when not
loaded and images which should commit after a small delay
When using the playground you typically want to see what it outputs, so
let's make the JS tab expanded by default.
ghstack-source-id: 721bc4c381c50db008058b31e1f976e92eab8548
Pull Request resolved: https://github.com/facebook/react/pull/29203
Follow up to https://github.com/facebook/react/pull/29201. If a chunk
had listeners attached already (e.g. because `.then` was called on the
chunk returned from `createFromReadableStream`),
`wakeChunkIfInitialized` would overwrite any listeners added during
chunk initialization. This caused cyclic [path
references](https://github.com/facebook/react/pull/28996) within that
chunk to never resolve. Fixed by merging the two arrays of listeners.
Explicitly waits for the build to finish since the playground requires
them to run
ghstack-source-id: 0bd7d5272d7fa09dc3a140b82a962dc4a3ae585b
Pull Request resolved: https://github.com/facebook/react/pull/29180
Fixes#29200
The cyclic state might have added listeners that will still need to be
invoked. This happens if we have a cyclic reference AND end up blocked.
We have already cleared these before entering the parsing when we enter
the CYCLIC state so we they already have the right type. If listeners
are added during this phase they should carry over to the blocked state.
---------
Co-authored-by: Hendrik Liebau <mail@hendrik-liebau.de>
## Summary
```js
assertConsoleErrorDev([
['Hello', {withoutStack: true}]
])
```
now errors with a helpful diff message if the message mismatched. See
first commit for previous behavior.
## How did you test this change?
- `yarn test --watch
packages/internal-test-utils/__tests__/ReactInternalTestUtils-test.js`
## Summary
Enables the `disableStringRefs` and `enableRefAsProp` feature flags for
React Native (Meta).
## How did you test this change?
```
$ yarn test
$ yarn flow fabric
```
## Summary
Closes#29130
## How did you test this change?
Run the healthcheck in the compiler playground and the nodejs.org repo
for the next config with a `.mjs` extension. Sanity with Vite React
template.
Signed-off-by: abizek <abishekilango@protonmail.com>
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
In the playground, it's hard to see at a glance what compiler passes are
involved in introducing changes.
This PR bolds every pass that introduces a change.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
Before:
<img width="1728" alt="image"
src="https://github.com/facebook/react/assets/5144292/803ca786-0726-4456-b0db-520dc90a6771">
After:
<img width="1728" alt="image"
src="https://github.com/facebook/react/assets/5144292/38885644-00e9-4065-9c44-db533000d13a">
## Summary
- While rolling out RDT 5.2.0 on Fusebox, we've discovered that context
menus don't work well with this environment. The reason for it is the
context menu state implementation - in a global context we define a map
of registered context menus, basically what is shown at the moment (see
deleted Contexts.js file). These maps are not invalidated on each
re-initialization of DevTools frontend, since the bundle
(react-devtools-fusebox module) is not reloaded, and this results into
RDT throwing an error that some context menu was already registered.
- We should not keep such data in a global state, since there is no
guarantee that this will be invalidated with each re-initialization of
DevTools (like with browser extension, for example).
- The new implementation is based on a `ContextMenuContainer` component,
which will add all required `contextmenu` event listeners to the
anchor-element. This component will also receive a list of `items` that
will be displayed in the shown context menu.
- The `ContextMenuContainer` component is also using
`useImperativeHandle` hook to extend the instance of the component, so
context menus can be managed imperatively via `ref`:
`contextMenu.current?.hide()`, for example.
- **Changed**: The option for copying value to clipboard is now hidden
for functions. The reasons for it are:
- It is broken in the current implementation, because we call
`JSON.stringify` on the value, see
`packages/react-devtools-shared/src/backend/utils.js`.
- I don't see any reasonable value in doing this for the user, since `Go
to definition` option is available and you can inspect the real code and
then copy it.
- We already filter out fields from objects, if their value is a
function, because the whole object is passed to `JSON.stringify`.
## How did you test this change?
### Works with element props and hooks:
- All context menu items work reliably for props items
- All context menu items work reliably or hooks items
https://github.com/facebook/react/assets/28902667/5e2d58b0-92fa-4624-ad1e-2bbd7f12678f
### Works with timeline profiler:
- All context menu items work reliably: copying, zooming, ...
- Context menu automatically closes on the scroll event
https://github.com/facebook/react/assets/28902667/de744cd0-372a-402a-9fa0-743857048d24
### Works with Fusebox:
- Produces no errors
- Copy to clipboard context menu item works reliably
https://github.com/facebook/react/assets/28902667/0288f5bf-0d44-435c-8842-6b57bc8a7a24
Bumps [rustix](https://github.com/bytecodealliance/rustix) from 0.37.22
to 0.37.27.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="b38dc51262"><code>b38dc51</code></a>
chore: Release rustix version 0.37.27</li>
<li><a
href="a2d9c8ee1a"><code>a2d9c8e</code></a>
Fix p{read,write}v{,v2}'s encoding of the offset argument on Linux. (<a
href="https://redirect.github.com/bytecodealliance/rustix/issues/896">#896</a>)
(#...</li>
<li><a
href="dce2777622"><code>dce2777</code></a>
chore: Release rustix version 0.37.26</li>
<li><a
href="06dbe83c60"><code>06dbe83</code></a>
Fix <code>sendmsg_unix</code>'s address encoding. (<a
href="https://redirect.github.com/bytecodealliance/rustix/issues/885">#885</a>)
(<a
href="https://redirect.github.com/bytecodealliance/rustix/issues/886">#886</a>)</li>
<li><a
href="00b84d6aac"><code>00b84d6</code></a>
chore: Release rustix version 0.37.25</li>
<li><a
href="cad15a7076"><code>cad15a7</code></a>
Fixes for <code>Dir</code> on macOS, FreeBSD, and WASI.</li>
<li><a
href="df3c3a192c"><code>df3c3a1</code></a>
Merge pull request from GHSA-c827-hfw6-qwvm</li>
<li><a
href="b78aeff1a2"><code>b78aeff</code></a>
chore: Release rustix version 0.37.24</li>
<li><a
href="c0c3f01d7c"><code>c0c3f01</code></a>
Add GNU/Hurd support (<a
href="https://redirect.github.com/bytecodealliance/rustix/issues/852">#852</a>)</li>
<li><a
href="f416b6b27b"><code>f416b6b</code></a>
Fix the <code>test_ttyname_ok</code> test when /dev/stdin is
inaccessable. (<a
href="https://redirect.github.com/bytecodealliance/rustix/issues/821">#821</a>)</li>
<li>Additional commits viewable in <a
href="https://github.com/bytecodealliance/rustix/compare/v0.37.22...v0.37.27">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps [postcss](https://github.com/postcss/postcss) from 8.4.24 to
8.4.31.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a
href="https://github.com/postcss/postcss/releases">postcss's
releases</a>.</em></p>
<blockquote>
<h2>8.4.31</h2>
<ul>
<li>Fixed <code>\r</code> parsing to fix CVE-2023-44270.</li>
</ul>
<h2>8.4.30</h2>
<ul>
<li>Improved source map performance (by <a
href="https://github.com/romainmenke"><code>@romainmenke</code></a>).</li>
</ul>
<h2>8.4.29</h2>
<ul>
<li>Fixed <code>Node#source.offset</code> (by <a
href="https://github.com/idoros"><code>@idoros</code></a>).</li>
<li>Fixed docs (by <a
href="https://github.com/coliff"><code>@coliff</code></a>).</li>
</ul>
<h2>8.4.28</h2>
<ul>
<li>Fixed <code>Root.source.end</code> for better source map (by <a
href="https://github.com/romainmenke"><code>@romainmenke</code></a>).</li>
<li>Fixed <code>Result.root</code> types when <code>process()</code> has
no parser.</li>
</ul>
<h2>8.4.27</h2>
<ul>
<li>Fixed <code>Container</code> clone methods types.</li>
</ul>
<h2>8.4.26</h2>
<ul>
<li>Fixed clone methods types.</li>
</ul>
<h2>8.4.25</h2>
<ul>
<li>Improve stringify performance (by <a
href="https://github.com/romainmenke"><code>@romainmenke</code></a>).</li>
<li>Fixed docs (by <a
href="https://github.com/vikaskaliramna07"><code>@vikaskaliramna07</code></a>).</li>
</ul>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/postcss/postcss/blob/main/CHANGELOG.md">postcss's
changelog</a>.</em></p>
<blockquote>
<h2>8.4.31</h2>
<ul>
<li>Fixed <code>\r</code> parsing to fix CVE-2023-44270.</li>
</ul>
<h2>8.4.30</h2>
<ul>
<li>Improved source map performance (by Romain Menke).</li>
</ul>
<h2>8.4.29</h2>
<ul>
<li>Fixed <code>Node#source.offset</code> (by Ido Rosenthal).</li>
<li>Fixed docs (by Christian Oliff).</li>
</ul>
<h2>8.4.28</h2>
<ul>
<li>Fixed <code>Root.source.end</code> for better source map (by Romain
Menke).</li>
<li>Fixed <code>Result.root</code> types when <code>process()</code> has
no parser.</li>
</ul>
<h2>8.4.27</h2>
<ul>
<li>Fixed <code>Container</code> clone methods types.</li>
</ul>
<h2>8.4.26</h2>
<ul>
<li>Fixed clone methods types.</li>
</ul>
<h2>8.4.25</h2>
<ul>
<li>Improve stringify performance (by Romain Menke).</li>
<li>Fixed docs (by <a
href="https://github.com/vikaskaliramna07"><code>@vikaskaliramna07</code></a>).</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="90208de880"><code>90208de</code></a>
Release 8.4.31 version</li>
<li><a
href="58cc860b4c"><code>58cc860</code></a>
Fix carrier return parsing</li>
<li><a
href="4fff8e4cdc"><code>4fff8e4</code></a>
Improve pnpm test output</li>
<li><a
href="cd43ed1232"><code>cd43ed1</code></a>
Update dependencies</li>
<li><a
href="caa916bdcb"><code>caa916b</code></a>
Update dependencies</li>
<li><a
href="8972f76923"><code>8972f76</code></a>
Typo</li>
<li><a
href="11a5286f78"><code>11a5286</code></a>
Typo</li>
<li><a
href="45c5501777"><code>45c5501</code></a>
Release 8.4.30 version</li>
<li><a
href="bc3c341f58"><code>bc3c341</code></a>
Update linter</li>
<li><a
href="b2be58a2eb"><code>b2be58a</code></a>
Merge pull request <a
href="https://redirect.github.com/postcss/postcss/issues/1881">#1881</a>
from romainmenke/improve-sourcemap-performance--phil...</li>
<li>Additional commits viewable in <a
href="https://github.com/postcss/postcss/compare/8.4.24...8.4.31">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
By default, React Compiler will skip compilation if it cannot preserve existing memoization. Ie, if the code has an existing `useMemo()` or `useCallback()` and the compiler cannot determine that it is safe to keep that memoization — or do even better — then we'll leave the code alone. The actual compilation doesn't use any hints from existing memo calls, this is purely to check and avoid regressing any specific memoization that developers may have already applied.
However, we were accidentally reporting some false-positive _validation_ errors due to the StartMemoize and FinishMemoize instructions that we emit to track where the memoization was in the source code. This is now fixed.
Fixes#29131Fixes#29132
ghstack-source-id: 9f6b8dbc5074ccc96e6073cf11c4920b5375faf6
Pull Request resolved: https://github.com/facebook/react/pull/29154
Improves ValidateNoRefAccessInRender (still disabled by default) to properly ignore ref access within effects. This includes allowing ref access within functions that are only transitively called from an effect.
While I was here I also added some extra test fixtures for allowing global mutation in effects.
ghstack-source-id: fb6352a1788b7bdbebb40d5b844b711ef87d6771
Pull Request resolved: https://github.com/facebook/react/pull/29151
As a fellow beginner to React, I didn't even know React runs on top of
Node when I started.
So, some beginners might get confused about what is Node and how to find
details about it or how to download it.
So, I thought to add a hyperlink to Node replacing the word Node in the
README.md file. I think this might be a valuable contribution.
- Januda
## Summary
The "Good First Issues" header in the README was missing a hyperlink
where the other similar headlines had one.
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
N/A
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
Makes running the script a little more ergonomic by prompting for OTP
upfront.
ghstack-source-id: e9967bfde1ab01ff9417a848154743ae1926318d
Pull Request resolved: https://github.com/facebook/react/pull/29149
Babel doesn't seem to properly preserve escaping of HTML entities when emitting JSX text children, so this commit works around the issue by emitting a JsxExpressionContainer for JSX children that contain ">", "<", or "&" characters.
Closes#29100
ghstack-source-id: 2d0622397cc067c6336f3635073e07daef854084
Pull Request resolved: https://github.com/facebook/react/pull/29143
## Summary
Every tab wraps the text around but there is no way to resize it. It was
also hard to use the source map tab. It doesn't occupy the full height
nor is the tab resizable. So I made all the tabs resizable.
> Also,
> * make the source map tab occupy full height
> * make it a teeny tiny bit easier to work with the compiler playground
(especially source map)
## How did you test this change?
https://github.com/facebook/react/assets/91976421/cdec30e8-cadb-4958-8786-31c54ea83bd6
Signed-off-by: abizek <abishekilango@protonmail.com>
Adds a GitHub issue template form so we can automatically categorize
issues and get more information upfront. I mostly referenced the
DevTools bug report template and made some tweaks.
ghstack-source-id: 5bfc728a625f367932fc21263e82681079d3ac65
Pull Request resolved: https://github.com/facebook/react/pull/29140
Workaround for a bug in older versions of Babel, where strings with unicode are incorrectly escaped when emitted as JSX attributes, causing double-escaping by later processing.
Closes#29120Closes#29124
ghstack-source-id: 065440d4fb97e164beb8a8f15f252f372a59c5a0
Pull Request resolved: https://github.com/facebook/react/pull/29141
Now that the compiler is public, the `*` version was grabbing the latest
version of the compiler off of npm and was resolving to my very first
push to npm (an empty package containing only a single package.json).
This was breaking the playground as it would attempt to load the
compiler but then crash the babel pipeline due to the node module not
being found.
ghstack-source-id: 695fd9caac
Pull Request resolved: https://github.com/facebook/react/pull/29122
@jbonta nerd-sniped me into making this optimization during conference
prep, posting this as a PR now that keynote is over.
Consider these two cases:
```javascript
export default function MyApp1({ count }) {
const cb = () => count;
return <div onclick={cb}>Hello World</div>;
}
export default function MyApp2({ count }) {
return <div onclick={() => count}>Hello World</div>;
}
```
Previously, the former would create two reactive scopes (one for `cb`,
one for the div) while the latter would only have a single scope for the
`div` and its inline callback. The reason we created separate scopes
before is that there's a `StoreLocal 'cb' = t0` instruction in-between,
and i had conservatively implemented the merging pass to not allow
intervening StoreLocal instructions.
The observation is that intervening StoreLocals are fine _if_ the
assigned variable's last usage is the next scope. We already have a
check that the intervening lvalues are last-used at/before the next
scope, so it's trivial to extend this to support StoreLocal.
Note that we already don't merge scopes if there are intervening
terminals, so we don't have to worry about things like conditional
StoreLocal, conditional access of the resulting value, etc.
/cc @poteto
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
Seems like the README of the package was outdated.
## How did you test this change?
Tried this configuration in a project of mine.
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Use `filename` instead of `context.filename` in eslint compiler.
The problem is that in `react-native` + `typescript` project the context
may not have `filename`:
<img width="384" alt="image"
src="https://github.com/facebook/react/assets/22820318/e5d184fa-5ac9-4512-96b9-644baa3d5f25">
And eslint will crash with:
```bash
TypeError: Error while loading rule 'react-compiler/react-compiler': Cannot read properties of undefined (reading 'endsWith')
```
But in fact we already derive `filename` variable earlier so we can
simply reuse the variable (I guess).
## How did you test this change?
- add `eslint` plugin to RN project;
- run eslint
Uses https for the npm registry so the publishing script isn't rejected.
Fixes:
```
Beginning October 4, 2021, all connections to the npm registry - including for package installation - must use TLS 1.2 or higher. You are currently using plaintext http to connect. Please visit the GitHub blog for more information: https://github.blog/2021-08-23-npm-registry-deprecating-tls-1-0-tls-1-1/
```
ghstack-source-id: b247d044ea48f3007cf8bd13445fb7ece0f5b02f
Pull Request resolved: https://github.com/facebook/react/pull/29087
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
This PR fixes a typo in `./compiler/docs/DESIGN_GOALS.md`.
I believe `plugion` should be `plugin`.
## How did you test this change?
Rendered the markdown to html.
This script needs to run from `main` since it commits version bumps for
packages, and those need to point to publicly available hashes. So,
throw an error if we're not already on main.
ghstack-source-id: ce0168e826
Pull Request resolved: https://github.com/facebook/react/pull/29083
- Specify a registry for npm publish because otherwise it tries to use
the yarn registry
- `packages` option actually works
This _should_ work now (note last line of output), will test it once we
land this since i want to publish a new version of the eslint plugin
with some important fixes.
```
npm notice
npm notice 📦 eslint-plugin-react-compiler@0.0.0-experimental-53bb89e-20240515
npm notice === Tarball Contents ===
npm notice 827B README.md
npm notice 2.1MB dist/index.js
npm notice 1.0kB package.json
npm notice === Tarball Details ===
npm notice name: eslint-plugin-react-compiler
npm notice version: 0.0.0-experimental-53bb89e-20240515
npm notice filename: eslint-plugin-react-compiler-0.0.0-experimental-53bb89e-20240515.tgz
npm notice package size: 300.9 kB
npm notice unpacked size: 2.1 MB
npm notice shasum: cb99823f3a483c74f470085cac177bd020f7a85a
npm notice integrity: sha512-L3HV9qja1dnCl[...]IaRSZJ3P/v6yQ==
npm notice total files: 3
npm notice
npm notice Publishing to http://registry.npmjs.org/ with tag latest and default access (dry-run)
```
ghstack-source-id: 63067ef772
Pull Request resolved: https://github.com/facebook/react/pull/29082
Previously we would attempt to parse code in the eslint plugin with the
HermesParser first as it can handle some TS syntax. However, this was
leading to a mis-parse of React hook calls with type params (eg,
`useRef<null>()` as a BinaryExpression rather than a CallExpression with
a type param. This triggered our validation that Hooks should not be
used as normal values.
To fix this, we now try to parse with the babel parser (with TS support)
for filenames that end with ts/tsx, and fallback to HermesParser for
regular JS files.
ghstack-source-id: 5b7231031c
Pull Request resolved: https://github.com/facebook/react/pull/29081
Previously, we only checked for StrictMode by searching for
`<StrictMode>` but we should also check for the namespaced version,
`<React.StrictMode>`.
Fixes https://github.com/facebook/react/issues/29075
Fixes the top-level ESLint and Prettier configs to ignore the compiler.
For now the compiler has its own prettier and linting setup with
different versions/configs.
## Summary
The main field is missing, this fixes it.
Fixes#29068.
## How did you test this change?
Manually patched the package and tried it in my codebase.
This updates the Canary label from "beta" to "rc".
We will publish an actual RC (e.g. 19.0.0-rc.0) too; this only changes
the label in the canary releases.
The [`files` field](https://docs.npmjs.com/cli/v10/commands/npm-publish#files-included-in-package)
controls what files get included in the published package.
This PR specifies the `files` field on our publishable packages to only
include the `dist` directory, since we don't need to ship any types or
sourcemaps with 3 of them.
react-compiler-runtime is a runtime package which has sourcemaps, so we
also include the `src` directory in the published package.
Also fixes an invalid version range for the react peer dependency in
react-compiler-runtime, tested that it works via https://semver.npmjs.com/
ghstack-source-id: 12b36c203fc9fd8d72a1995fb3fba2312de4aa51
Pull Request resolved: https://github.com/facebook/react-forget/pull/2965
## Summary
Enables the `enableUnifiedSyncLane` feature flag for React Native
(Meta).
## How did you test this change?
```
$ yarn test
$ yarn flow fabric
```
`forget_napi` doesn't exist and given we're not currently working on the Rust compiler, I'm not sure we need to keep this around until we know that we do want to invest into this area again.
Don't really have time to implement the react-compiler/healthcheck
version of this script, so for now i propose we just publish this as
react-compiler-healthcheck
the command for running this would be
```
$ npx react-compiler-healthcheck --src 'whatever/**/*.*'
```
ghstack-source-id: e2c443a912
Pull Request resolved: https://github.com/facebook/react-forget/pull/2956
runReactBabelPluginReactCompiler brings in fbt which is unnecessary for
OSS so I removed it.
Also makes it so healthckeck is installed as an executable
ghstack-source-id: ec6c76f8be
Pull Request resolved: https://github.com/facebook/react-forget/pull/2955
We found this issue through enabling the compiler on the React Conf app.
`babel-preset-expo` automatically adds the `react-native-animated`
plugin to apps that use the preset. This means that Expo apps sometimes
omit the react-native-animated plugin from their config, which was
failing our existing check. This PR copies the same detection that Expo
does for adding reanimated as a fallback
ghstack-source-id: 46f7aec0bc
Pull Request resolved: https://github.com/facebook/react-forget/pull/2953
This errors on the client normally but in the case the `type` is a
function - i.e. a Server Component - it wouldn't be transferred to error
on the client so you end up with a worse error message. So this just
implements the same check as ChildFiber.
## Summary
The experiment has shown no significant performance changes. This PR
removes it.
## How did you test this change?
```
yarn flow native
yarn lint
```
Stacked on #28997.
We can use the technique of referencing an object by its row + property
name path for temporary references - like we do for deduping. That way
we don't need to generate an ID for temporary references. Instead, they
can just be an opaque marker in the slot and it has the implicit ID of
the row + path.
Then we can stash all objects, even the ones that are actually available
to read on the server, as temporary references. Without adding anything
to the payload since the IDs are implicit. If the same object is
returned to the client, it can be referenced by reference instead of
serializing it back to the client. This also helps preserve object
identity.
We assume that the objects are immutable when they pass the boundary.
I'm not sure if this is worth it but with this mechanism, if you return
the `FormData` payload from a `useActionState` it doesn't have to be
serialized on the way back to the client. This is a common pattern for
having access to the last submission as "default value" to the form
fields. However you can still control it by replacing it with another
object if you want. In MPA mode, the temporary references are not
configured and so it needs to be serialized in that case. That's
required anyway for hydration purposes.
I'm not sure if people will actually use this in practice though or if
FormData will always be destructured into some other object like with a
library that turns it into typed data, and back. If so, the object
identity is lost.
Uses the same technique as in #28996 to encode references to already
emitted objects. This now means that Reply can support cyclic objects
too for parity.
Instead of forcing an object to be outlined to be able to refer to it
later we can refer to it by the property path inside another parent
object.
E.g. this encodes such a reference as `'$123:props:children:foo:bar'`.
That way we don't have to preemptively outline object and we can dedupe
after the first time we've found it.
There's no cost on the client if it's not used because we're not storing
any additional information preemptively.
This works mainly because we only have simple JSON objects from the root
reference. Complex objects like Map, FormData etc. are stored as their
entries array in the look up and not the complex object. Other complex
objects like TypedArrays or imports don't have deeply nested objects in
them that can be referenced.
This solves the problem that we only dedupe after the third instance.
This dedupes at the second instance. It also solves the problem where
all nested objects inside deduped instances also are outlined.
The property paths can get pretty large. This is why a test on payload
size increased. We could potentially outline the reference itself at the
first dupe. That way we get a shorter ID to refer to in the third
instance.
Adds supports for hot module reloading (HMR) by resetting the cache if a hash of the source file changes. This is enabled via a compiler flag, but also enabled automatically via the babel plugin when NODE_ENV=development.
ghstack-source-id: 5cd1ad5c89
Pull Request resolved: https://github.com/facebook/react-forget/pull/2951
Before this change, `useFormStatus` is only activated if a form is
submitted by an action function (either `<form action={actionFn}>` or
`<button formAction={actionFn}>`).
After this change, `useFormStatus` will also be activated if you call
`startTransition(actionFn)` inside a submit event handler that is
`preventDefault`-ed.
This is the last missing piece for implementing a custom `action` prop
that is progressively enhanced using `onSubmit` while maintaining the
same behavior as built-in form actions.
Here's the basic recipe for implementing a progressively-enhanced form
action. This would typically be implemented in your UI component
library, not regular application code:
```js
import {requestFormReset} from 'react-dom';
// To implement progressive enhancement, pass both a form action *and* a
// submit event handler. The action is used for submissions that happen
// before hydration, and the submit handler is used for submissions that
// happen after.
<form
action={action}
onSubmit={(event) => {
// After hydration, we upgrade the form with additional client-
// only behavior.
event.preventDefault();
// Manually dispatch the action.
startTransition(async () => {
// (Optional) Reset any uncontrolled inputs once the action is
// complete, like built-in form actions do.
requestFormReset(event.target);
// ...Do extra action-y stuff in here, like setting a custom
// optimistic state...
// Call the user-provided action
const formData = new FormData(event.target);
await action(formData);
});
}}
/>
```
This is the first step to experimenting with a new type of stack traces
behind the `enableOwnerStacks` flag - in DEV only.
The idea is to generate stacks that are more like if the JSX was a
direct call even though it's actually a lazy call. Not only can you see
which exact JSX call line number generated the erroring component but if
that's inside an abstraction function, which function called that
function and if it's a component, which component generated that
component. For this to make sense it really need to be the "owner" stack
rather than the parent stack like we do for other component stacks. On
one hand it has more precise information but on the other hand it also
loses context. For most types of problems the owner stack is the most
useful though since it tells you which component rendered this
component.
The problem with the platform in its current state is that there's two
ways to deal with stacks:
1) `new Error().stack`
2) `console.createTask()`
The nice thing about `new Error().stack` is that we can extract the
frames and piece them together in whatever way we want. That is great
for constructing custom UIs like error dialogs. Unfortunately, we can't
take custom stacks and set them in the native UIs like Chrome DevTools.
The nice thing about `console.createTask()` is that the resulting stacks
are natively integrated into the Chrome DevTools in the console and the
breakpoint debugger. They also automatically follow source mapping and
ignoreLists. The downside is that there's no way to extract the async
stack outside the native UI itself so this information cannot be used
for custom UIs like errors dialogs. It also means we can't collect this
on the server and then pass it to the client for server components.
The solution here is that we use both techniques and collect both an
`Error` object and a `Task` object for every JSX call.
The main concern about this approach is the performance so that's the
main thing to test. It's certainly too slow for production but it might
also be too slow even for DEV.
This first PR doesn't actually use the stacks yet. It just collects them
as the first step. The next step is to start utilizing this information
in error printing etc.
For RSC we pass the stack along across over the wire. This can be
concatenated on the client following the owner path to create an owner
stack leading back into the server. We'll later use this information to
restore fake frames on the client for native integration. Since this
information quickly gets pretty heavy if we include all frames, we strip
out the top frame. We also strip out everything below the functions that
call into user space in the Flight runtime. To do this we need to figure
out the frames that represents calling out into user space. The
resulting stack is typically just the one frame inside the owner
component's JSX callsite. I also eagerly strip out things we expect to
be ignoreList:ed anyway - such as `node_modules` and Node.js internals.
## Summary
This brings:
- jest* up from 29.4.2 -> 29.7.0
- jsdom up from 20.0.0 -> 22.1.0
While the latest version of jest-dom-environment still wants
`jsdom@^20.0.0`, it can safely use at least up to `jsdom@22.1.0`. See
https://github.com/jestjs/jest/pull/13825#issuecomment-1564015010 for
details.
Upgrading to latest versions lets us improve some WheelEvent tests and
will make it possible to test a much simpler FormData construction
approach (see #29018)
## How did you test this change?
Ran `yarn test` and `yarn test --prod` successfully
Facebook: merge react index.classic.fb and index.modern.fb
These export the same.
NOTE: The 2 builds are still different based on flags and other forked
files.
## Summary
This PR makes some fixes to the `fastAddProperties` function:
- Use `if (!attributeConfig)` instead of `if (attributeConfig ===
undefined)` to account for `null`.
- If a prop has an Object `attributeConfig` with a `diff` function
defined on it, treat it as an atomic value to keep the semantics of
`diffProperties`.
## How did you test this change?
Build and run RNTester app.
This is the same change as #28780 but for the Flight Reply receiver.
While it's not possible to create an "async module" reference in this
case - resolving a server reference can still be async if loading it
requires loading chunks like in a new server instance.
Since extracting a typed array from a Blob is async, that's also a case
where a dependency can be async.
This follows the same principle as in #28611.
We cannot serialize Blobs of a form data into HTML because you can't
initialize a file input to some value. However the serialization of
state in an Action can contain blobs. In this case we do error but
outside the try/catch that recovers to error to client replaying instead
of MPA mode. This errors earlier to ensure that this works.
Testing this is a bit annoying because JSDOM doesn't have any of the
Blob methods but the Blob needs to be compatible with FormData and the
FormData needs to be compatible with `<form>` nodes in these tests. So I
polyfilled those in JSDOM with some hacks.
A possible future enhancement would be to encode these blobs in a base64
mode instead and have some way to receive them on the server. It's just
a matter of layering this. I think the RSC layer's `FORM_DATA`
implementation can pass some flag to encode as base64 and then have
decodeAction include some way to parse them. That way this case would
work in MPA mode too.
Based on #28893.
For other streams we encode each chunk as a separate form field which is
a bit bloated. Especially for binary chunks since they also have an
indirection. We need some way to encode the chunks as separate anyway.
This way the streaming using busboy actually allows each chunk to stream
in over the network one at a time.
For binary streams the actual chunking is not important. The chunks can
be split and recombined in whatever size chunk makes sense.
Since we buffer the entire content anyway we can combine the chunks to
be consecutive. This PR does that with binary streams and also combine
them into a single Blob. That way there's no extra overhead when passing
through a binary stream.
Ideally, we'd be able to just use the stream from that one Blob but
Node.js doesn't return byob streams from Blob. Additionally, we don't
actually stream the content of Blobs due to the layering with busboy
atm. We could do that for binary streams in particular by replacing the
File layering with a stream and resolving each chunk as it comes in.
That could be a follow up.
If we stop buffering in the future, this set up still allows us to split
them and send other form fields in between while blocked since the
protocol is still the same.
Follow-up to https://github.com/facebook/react/pull/28813.
RDT is using `typeOf` from `react-is` to determine the element display
name, I've forked an implementation of this method, but will be using
legacy element symbol.
## Summary
Exposes the APIs needed by React Native DevTools (Fusebox) to implement
the "view element source" and "view attribute source" features.
## How did you test this change?
1. `yarn build` in `react-devtools-fusebox`
2. Copy artifacts to rn-chrome-devtools-frontend
3. Write some additional glue code to implement
`viewElementSourceFunction` in our CDT fork.
4. Test the feature manually.
https://github.com/facebook/react/assets/2246565/12667018-100a-4b3f-957a-06c07f2af41a
We need this in the root to run the steps. It should merge cleanly with the React repo as there is no file name overlap.
Next step is to update the paths to make it work again.
## Summary
This PR introduces Fabric-only version of
`ReactNativeAttributesPayload`. It is a copy-paste of
`ReactNativeAttributesPayload.js`, and is called
`ReactNativeAttributesPayloadFabric.js`.
The idea behind this change is that certain optimizations in prop
diffing may actually be a regression on the old architecture. For
example, removing custom diffing may result in larger updateProps
payloads. Which is, I guess, fine with JSI, but might be a problem with
the bridge.
## How did you test this change?
There should be no runtime effect of this change.
The eslint rule seems to false positive on this typescript syntax, but
strangely the compiler does not
ghstack-source-id: 19baa24ff7addd83f59e2b03fdb180af169a2794
Pull Request resolved: https://github.com/facebook/react-forget/pull/2913
Make it clearer how to address this error by allowlisting globals that
are known to be safe
ghstack-source-id: e7fa6464ebb561a7a1366ff70430842007c6552e
Pull Request resolved: https://github.com/facebook/react-forget/pull/2909
During the demo I might show an example of fixing a
CannotPreserveMemoization error. But I don't want to make that
reportable by default, so this PR allows configuration like so
```js
module.exports = {
root: true,
plugins: [
'eslint-plugin-react-compiler',
],
rules: {
'react-compiler/react-compiler': [
'error', {
reportableLevels: new Set([
'InvalidJs',
'InvalidReact',
'CannotPreserveMemoization'
])
}
]
}
}
```
ghstack-source-id: 984c6d3cb7e19c8fea2bb88108dd26335c031573
Pull Request resolved: https://github.com/facebook/react-forget/pull/2936
We control what gets reported via another function anyway so it's better
to raise everything at the compiler config level. This lets us configure
what level of diagnostic is reportable later
ghstack-source-id: 996d3cbb8d8f3e1bbe943210b8d633420e0f3f3b
Pull Request resolved: https://github.com/facebook/react-forget/pull/2935
This file is intended to test that the test will skip if it was already compiled.
This updates the import to remove the no longer used name `unstable_useMemoCache`.
- Updated all directly defined dependencies to the latest React 19 Beta
- `package.json`: used `resolutions` to force React 19 for `react-is` transitive dependency
- `package.json`: postinstall script to patch fbt for the React 19 element Symbol
- Match on the message in Snap to exclude a React 19 warning that `act` should be imported from `react` instead (from inside `@testing-library/react`)
- Some updated snapshots, I think due to now recovering behavior of `useMemoCache`, please review.
In a next step, we can do the following. I excluded it since it from here as it made the PR unreviewable on GitHub.
- Snapshots now use `react/compiler-runtime` as in prod, so the different default in Snap is no longer needed.
## Summary
Sets up dynamic feature flags for `disableStringRefs`, `enableFastJSX`,
and `enableRefAsProp` in React Native (at Meta).
## How did you test this change?
```
$ yarn test
$ yarn flow fabric
```
In order to integrate the `react-reconciler` build created in #28880
with third party libraries, we need to have matching
`react-reconciler/constants` to go with it.
Same as #28847 but in the other direction.
Like other promises, this doesn't actually stream in the outgoing
direction. It buffers until the stream is done. This is mainly due to
our protocol remains compatible with Safari's lack of outgoing streams
until recently.
However, the stream chunks are encoded as separate fields and so does
support the busboy streaming on the receiving side.
We currently don't test FormData / File dependent features in CI because
we use an old Node.js version in CI. We should probably upgrade to 18
since that's really the minimum version that supports all the features
out of the box.
JSDOM is not a faithful/compatible implementation of these APIs. The
recommended way to use Flight together with FormData/Blob/File in older
Node.js versions, is to polyfill using the `undici` library.
However, even in these versions the Blob implementation isn't quite
faithful so the Reply client needs a slight tweak for multi-byte typed
arrays.
Stacked on #28798.
Add another AsyncLocalStorage to the FlightServerConfig. This context
tracks data on a per component level. Currently the only thing we track
is the owner in DEV.
AsyncLocalStorage around each component comes with a performance cost so
we only do it DEV. It's not generally a particularly safe operation
because you can't necessarily associate side-effects with a component
based on execution scope. It can be a lazy initializer or cache():ed
code etc. We also don't support string refs anymore for a reason.
However, it's good enough for optional dev only information like the
owner.
Bundle config: inline internal hook wrapper
Instead of reading this wrapper from 2 files for "start" and "end" and
then string modifying the templates, just inline them like the other
wrappers in this file.
## Summary
Enables the inspected element context menu in React Native DevTools
(Fusebox).
## How did you test this change?
1. `yarn build` in `react-devtools-fusebox`
2. Copy artifacts to rn-chrome-devtools-frontend
3. Manually test the context menu
https://github.com/facebook/react/assets/2246565/b35cc20f-8d67-43b0-b863-7731e10fffac
NOTE: The serialised values sometimes expose React internals (e.g. Hook
data structures instead of just the values), but that seems to be a
problem equally on web, so I'm going for native<->web parity here.
## Summary
The `react-devtools-fusebox` private package is used in the React Native
DevTools (Fusebox) frontend by checking build artifacts into RN's
[fork]([`facebookexperimental/rn-chrome-devtools-frontend`](https://github.com/facebookexperimental/rn-chrome-devtools-frontend))
of the Chrome DevTools (CDT) repo - see
https://github.com/facebookexperimental/rn-chrome-devtools-frontend/pull/22.
Currently, the CDT fork also includes a [manually written TypeScript
definition
file](1d5f8d5209/front_end/third_party/react-devtools/package/frontend.d.ts)
which describes `react-devtools-fusebox`'s API. This PR moves that file
into the React repo, next to the implementation of
`react-devtools-fusebox`, so we can update it atomically with changes to
the package.
As this is the first bit of TypeScript in this repo, the PR adds minimal
support for formatting `.d.ts` files with Prettier. It also opts out
`react-devtools-fusebox/dist/` from linting/formatting as a drive-by
fix.
For now, we'll just maintain the `.d.ts` file manually, but we could
consider leveraging
[`flow-api-translator`](https://www.npmjs.com/package/flow-api-translator)
to auto-generate it in the future.
## How did you test this change?
Build `react-devtools-fusebox`, observe that `dist/frontend.d.ts`
exists.
Following #28768, add a path to testing Fast JSX on www.
We want to measure the impact of Fast JSX and enable a path to testing
before string refs are completely removed in www (which is a work in
progress).
Without `disableStringRefs`, we need to copy any object with a `ref` key
so we can pass it through `coerceStringRef()` and copy it into the
object. This de-opt path is what is gated behind
`enableFastJSXWithStringRefs`.
The additional checks should have no perf impact in OSS as the flags
remain true there and the build output is not changed. For www, I've
benchmarked the addition of the boolean checks with values cached at
module scope. There is no significant change observed from our
benchmarks and any latency will apply to test and control branches
evenly. This added experiment complexity is temporary. We should be able
to clean it up, along with the flag checks for `enableRefAsProp` and
`disableStringRefs` shortly.
## Summary
This PR introduces a faster version of the `addProperties` function.
This new function is basically the `diffProperties` with `prevProps` set
to `null`, propagated constants, and all the unreachable code paths
collapsed.
## How did you test this change?
I've tested this change with [the benchmark
app](https://github.com/react-native-community/RNNewArchitectureApp/tree/new-architecture-benchmarks)
and got ~4.4% improvement in the view creation time.
When a React PR is opened CI will report large size changes. But for
critical packages like react-dom it reports always. In React 19 we moved
the build for react-dom the client reconciler from react-dom to
react-dom/client
This change adds react-dom-client artifacts for stable and oss channels
since that is originally what was being tracked. But since
react-dom/client always imports react-dom I left the original react-dom
packages as critical as well. They are small but it would be good to
keep an eye on them
To make a first time setup of the compiler truly config-less, default to
not compiling node_modules unless a user provided `sources` (advanced
option) is provided
ghstack-source-id: b0798052404d772ce6ee471e577699d4b0871d56
Pull Request resolved: https://github.com/facebook/react-forget/pull/2919
This uses the compiler runtime from `react/compiler-runtime` by default unless `compilerRuntime` is specifified in the Babel options which then imports the runtime from there. The `useMemoCache` hook is now named `c` in accordance with 4508873393
Unfortunately, I couldn't figure out how to import `react@beta` which already has that import as various react verstions were conflicting. If someone can figure this out it'd be fantastic. As a result, I had to update the default for the test runner to default the `compilerRuntime` option to `react` to preserve the previous behavior to import from `react`. Once upgraded to React 19, we should be able to remove that override.
Treat MethodCalls similar to general CallExpressions and mark them
as escaping in PruneNonEscapingScopes pass.
ghstack-source-id: 3c81bdb17f58fbeef8be24e7cb363172d1867217
Pull Request resolved: https://github.com/facebook/react-forget/pull/2925
Add a configurable list of known incompatible libraries.
Check all package.jsons for any uses of known incompatible libraries and
warn if found.
ghstack-source-id: 7329e3792b57458e681780cba3140a14a9b1a60d
Pull Request resolved: https://github.com/facebook/react-forget/pull/2923
Enables the Reanimated flag automatically if we find reanimated in the
user's list of plugins
ghstack-source-id: 20e83374612362a30d6c8cc7a903d9320e8cc23a
Pull Request resolved: https://github.com/facebook/react-forget/pull/2915
## Summary
I'm looking at cleaning up some unnecessary manual property flattening
in React Native and wanted to verify this behaviour is working as
expected, where properties from nested objects will always overwrite
properties from the base object.
## How did you test this change?
Unit tests
As discussed earlier, let's disable this validation pass by default for
oss since it still has many false positives
ghstack-source-id: fa3c21dde7cc4c3e4bb91dfa707e64bc7a9e088b
Pull Request resolved: https://github.com/facebook/react-forget/pull/2908
Rebasing and landing https://github.com/facebook/react/pull/28798
This PR was approved already but held back to give time for the sync.
Rebased and landing here without pushing to seb's remote to avoid
possibility of lost updates
---------
Co-authored-by: Sebastian Markbage <sebastian@calyptus.eu>
It turns out we already made refs writable in #25696, which has been in
canary for over a year. The approach in that PR also has the benefit of
being slightly more perf sensitive because it still uses a shared object
until the fiber is mounted. So let's just go back to that.
Add new reconciler methods since last breaking change to the README
based on usage and comments.
---------
Co-authored-by: Josh Story <josh.c.story@gmail.com>
This PR reorganizes the `react-dom` entrypoint to only pull in code that
is environment agnostic. Previously if you required anything from this
entrypoint in any environment the entire client reconciler was loaded.
In a prior release we added a server rendering stub which you could
alias in server environments to omit this unecessary code. After landing
this change this entrypoint should not load any environment specific
code.
While a few APIs are truly client (browser) only such as createRoot and
hydrateRoot many of the APIs you import from this package are only
useful in the browser but could concievably be imported in shared code
(components running in Fizz or shared components as part of an RSC app).
To avoid making these require opting into the client bundle we are
keeping them in the `react-dom` entrypoint and changing their
implementation so that in environments where they are not particularly
useful they do something benign and expected.
#### Removed APIs
The following APIs are being removed in the next major. Largely they
have all been deprecated already and are part of legacy rendering modes
where concurrent features of React are not available
* `render`
* `hydrate`
* `findDOMNode`
* `unmountComponentAtNode`
* `unstable_createEventHandle`
* `unstable_renderSubtreeIntoContainer`
* `unstable_runWithPrioirty`
#### moved Client APIs
These APIs were available on both `react-dom` (with a warning) and
`react-dom/client`. After this change they are only available on
`react-dom/client`
* `createRoot`
* `hydrateRoot`
#### retained APIs
These APIs still exist on the `react-dom` entrypoint but have normalized
behavior depending on which renderers are currently in scope
* `flushSync`: will execute the function (if provided) inside the
flushSync implemention of FlightServer, Fizz, and Fiber DOM renderers.
* `unstable_batchedUpdates`: This is a noop in concurrent mode because
it is now the only supported behavior because there is no legacy
rendering mode
* `createPortal`: This just produces an object. It can be called from
anywhere but since you will probably not have a handle on a DOM node to
pass to it it will likely warn in environments other than the browser
* preloading APIS such as `preload`: These methods will execute the
preload across all renderers currently in scope. Since we resolve the
Request object on the server using AsyncLocalStorage or the current
function stack in practice only one renderer should act upon the
preload.
In addition to these changes the server rendering stub now just rexports
everything from `react-dom`. In a future minor we will add a warning
when using the stub and in the next major we will remove the stub
altogether
This was probably a leftover from a previous time, but since this error
message throws when the dependency list is not an array literal, and not
just when its a rest spread, this PR updates the message to match.
ghstack-source-id: 28f2338212e56a67d3d477cea5abb6e9f3826488
Pull Request resolved: https://github.com/facebook/react-forget/pull/2902
This removes the automatic patching of the global `fetch` function in
Server Components environments to dedupe requests using `React.cache`, a
behavior that some RSC framework maintainers have objected to.
We may revisit this decision in the future, but for now it's not worth
the controversy.
Frameworks that have already shipped this behavior, like Next.js, can
reimplement it in userspace.
I considered keeping the implementation in the codebase and disabling it
by setting `enableFetchInstrumentation` to `false` everywhere, but since
that also disables the tests, it doesn't seem worth it because without
test coverage the behavior is likely to drift regardless. We can just
revert this PR later if desired.
Used this test scenario to clarify how callback refs work when detached
based on the availability of a cleanup function to update documentation
in https://github.com/reactjs/react.dev/pull/6770
Checking it in for additional test coverage and test-based documentation
It's not useful to output count of all failures,
as it's not actionable for the developer.
We'll still capture all failures in case we want
to add a rage option to this script.
ghstack-source-id: 4d5a1dd6a9616e6fd5e1166bb97fa047829b9273
Pull Request resolved: https://github.com/facebook/react-forget/pull/2889
Run the compiler on the globbed soruces.
The logger is used to capture the success and
failure compilation cases at the component level.
(If we were to compile the entire file directly,
we wouldn't get this granularity)
For now, we just log the number of success and
failures. In the future, we can provide a better
report building on this.
ghstack-source-id: 6d2d918190b6ed5d42b795491bbce29a950b9741
Pull Request resolved: https://github.com/facebook/react-forget/pull/2888
Exporting the hermes parser breaks the playground
as the hermes parser can not work in the browser.
No one is using this directly anyway -- snap and
others bundle hermes parser on their own, so,
let's remove it.
ghstack-source-id: d448c346eb137f8ba6ada4ad113e41a90b29baff
Pull Request resolved: https://github.com/facebook/react-forget/pull/2890
Use yargs to parse input of glob expression
matching the path of src files to compile.
ghstack-source-id: 6a35e958428cd08ef5c96e0014e072d3faf04064
Pull Request resolved: https://github.com/facebook/react-forget/pull/2886
This package will be used to check for violations
of the rules of react and other heuristics to
determine the health of a codebase.
The health of a codebase gives an expectation of
how easy it will be onboard on to the compiler.
ghstack-source-id: b52fc4e44f704e0544f15066d8905825a256dc4a
Pull Request resolved: https://github.com/facebook/react-forget/pull/2884
Stacked on #28849, #28854, #28853. Behind a flag.
If you're following along from the side-lines. This is probably not what
you think it is.
It's NOT a way to get updates to a component over time. The
AsyncIterable works like an Iterable already works in React which is how
an Array works. I.e. it's a list of children - not the value of a child
over time.
It also doesn't actually render one component at a time. The way it
works is more like awaiting the entire list to become an array and then
it shows up. Before that it suspends the parent.
To actually get these to display one at a time, you have to opt-in with
`<SuspenseList>` to describe how they should appear. That's really the
interesting part and that not implemented yet.
Additionally, since these are effectively Async Functions and uncached
promises, they're not actually fully "supported" on the client yet for
the same reason rendering plain Promises and Async Functions aren't.
They warn. It's only really useful when paired with RSC that produces
instrumented versions of these. Ideally we'd published instrumented
helpers to help with map/filter style operations that yield new
instrumented AsyncIterables.
The way the implementation works basically just relies on unwrapThenable
and otherwise works like a plain Iterator.
There is one quirk with these that are different than just promises. We
ask for a new iterator each time we rerender. This means that upon retry
we kick off another iteration which itself might kick off new requests
that block iterating further. To solve this and make it actually
efficient enough to use on the client we'd need to stash something like
a buffer of the previous iteration and maybe iterator on the iterable so
that we can continue where we left off or synchronously iterate if we've
seen it before. Similar to our `.value` convention on Promises.
In Fizz, I had to do a special case because when we render an iterator
child we don't actually rerender the parent again like we do in Fiber.
However, it's more efficient to just continue on where we left off by
reusing the entries from the thenable state from before in that case.
We have changed the shape (and the runtime) of React Elements. To help
avoid precompiled or inlined JSX having subtle breakages or deopting
hidden classes, I renamed the symbol so that we can early error if
private implementation details are used or mismatching versions are
used.
Why "transitional"? Well, because this is not the last time we'll change
the shape. This is just a stepping stone to removing the `ref` field on
the elements in the next version so we'll likely have to do it again.
Stacked on #28853 and #28854.
React supports rendering `Iterable` and will soon support
`AsyncIterable`. As long as it's multi-shot since during an update we
may have to rerender with new inputs an loop over the iterable again.
Therefore the `Iterator` and `AsyncIterator` types are not supported
directly as a child of React - and really it shouldn't pass between
Hooks or components neither for this reason. For parity, that's also the
case when used in Server Components.
However, there is a special case when the component rendered itself is a
generator function. While it returns as a child an `Iterator`, the React
Element itself can act as an `Iterable` because we can re-evaluate the
function to create a new generator whenever we need to.
It's also very convenient to use generator functions over constructing
an `AsyncIterable`. So this is a proposal to special case the
`Generator`/`AsyncGenerator` returned by a (Async) Generator Function.
In Flight this means that when we render a Server Component we can
serialize this value as an `Iterable`/`AsyncIterable` since that's
effectively what rendering it on the server reduces down to. That way if
Fiber can receive the result in any position.
For SuspenseList this would also need another special case because the
children of SuspenseList represent "rows".
`<SuspenseList><Component /></SuspenseList>` currently is a single "row"
even if the component renders multiple children or is an iterator. This
is currently different if Component is a Server Component because it'll
reduce down to an array/AsyncIterable and therefore be treated as one
row per its child. This is different from `<SuspenseList><Component
/><Component /></SuspenseList>` since that has a wrapper array and so
this is always two rows.
It probably makes sense to special case a single-element child in
`SuspenseList` to represent a component that generates rows. That way
you can use an `AsyncGeneratorFunction` to do this.
For [`AsyncIterable`](https://github.com/facebook/react/pull/28847) we
encode `AsyncIterator` as a separate tag.
Previously we encoded `Iterator` as just an Array. This adds a special
encoding for this. Technically this is a breaking change.
This is kind of an edge case that you'd care about the difference but it
becomes more important to treat these correctly for the warnings here
#28853.
This doesn't change production behavior. We always render Iterables to
our best effort in prod even if they're Iterators.
But this does change the DEV warnings which indicates which are valid
patterns to use.
It's a footgun to use an Iterator as a prop when you pass between
components because if an intermediate component rerenders without its
parent, React won't be able to iterate it again to reconcile and any
mappers won't be able to re-apply. This is actually typically not a
problem when passed only to React host components but as a pattern it's
a problem for composability.
We used to warn only for Generators - i.e. Iterators returned from
Generator functions. This adds a warning for Iterators created by other
means too (e.g. Flight or the native Iterator utils). The heuristic is
to check whether the Iterator is the same as the Iterable because that
means it's not possible to get new iterators out of it. This case used
to just yield non-sense like empty sets in DEV but not in prod.
However, a new realization is that when the Component itself is a
Generator Function, it's not actually a problem. That's because the
React Element itself works as an Iterable since we can ask for new
generators by calling the function again. So this adds a special case to
allow the Generator returned from a Generator Function's direct child.
The principle is “don’t pass iterators around” but in this case there is
no iterator floating around because it’s between React and the JS VM.
Also see #28849 for context on AsyncIterables.
Related to this, but Hooks should ideally be banned in these for the
same reason they're banned in Async Functions.
This disables symbol renaming in production builds. The original
variable and function names are preserved. All other forms of
compression applied by Closure (dead code elimination, inlining, etc)
are unchanged — the final program is identical to what we were producing
before, just in a more readable form.
The motivation is to make it easier to debug React issues that only
occur in production — the same reason we decided to start shipping
sourcemaps in #28827 and #28827.
However, because most apps run their own minification step on their npm
dependencies, it's not necessary for us to minify the symbols before
publishing — it'll be handled the app, if desired.
This is the same strategy Meta has used to ship React for years. The
React build itself has unminified symbols, but they get minified as part
of Meta's regular build pipeline.
Even if an app does not minify their npm dependencies, gzip covers most
of the cost of symbol renaming anyway.
This saves us from having to ship sourcemaps, which means even apps that
don't have sourcemaps configured will be able to debug the React build
as easily as they would any other npm dependency.
Adds an experimental feature flag to the implementation of useMemoCache,
the internal cache used by the React Compiler (Forget).
When enabled, instead of treating the cache as copy-on-write, like we do
with fibers, we share the same cache instance across all render
attempts, even if the component is interrupted before it commits.
If an update is interrupted, either because it suspended or because of
another update, we can reuse the memoized computations from the previous
attempt. We can do this because the React Compiler performs atomic
writes to the memo cache, i.e. it will not record the inputs to a
memoization without also recording its output.
This gives us a form of "resuming" within components and hooks.
This only works when updating a component that already mounted. It has
no impact during initial render, because the memo cache is stored on the
fiber, and since we have not implemented resuming for fibers, it's
always a fresh memo cache, anyway.
However, this alone is pretty useful — it happens whenever you update
the UI with fresh data after a mutation/action, which is extremely
common in a Suspense-driven (e.g. RSC or Relay) app.
So the impact of this feature is faster data mutations/actions (when the
React Compiler is used).
Meta uses various tools built on top of the "react-reconciler" package
but that package needs to match the version of the "react" package.
This means that it should be synced at the same time. However, more than
that the feature flags between the "react" package and the
"react-reconciler" package needs to line up. Since FB has custom feature
flags, it can't use the OSS version of react-reconciler.
In #26446 we started publishing non-minified versions of our production
build artifacts, along with source maps, for easier debugging of React
when running in production mode.
The way it's currently set up is that these builds are generated
*before* Closure compiler has run. Which means it's missing many of the
optimizations that are in the final build, like dead code elimination.
This PR changes the build process to run Closure on the non-minified
production builds, too, by moving the sourcemap generation to later in
the pipeline.
The non-minified builds will still preserve the original symbol names,
and we'll use Prettier to add back whitespace. This is the exact same
approach we've been using for years to generate production builds for
Meta.
The idea is that the only difference between the minified and non-
minified builds is whitespace and symbol mangling. The semantic
structure of the program should be identical.
To implement this, I disabled symbol mangling when running Closure
compiler. Then, in a later step, the symbols are mangled by Terser. This
is when the source maps are generated.
Stacked on #28872
renderToStaticNodeStream was not originally deprecated when
renderToNodeStream was deprecated because it did not yet have a clear
analog in the modern streaming implementation for SSR. In React 19 we
have already removed renderToNodeStream. This change removes
renderToStaticNodeStream as well because you can replicate it's
semantics using renderToPipeableStream with onAllReady or
renderToReadableStream with await stream.allready.
This commit adds warnings indicating that `renderToStaticNodeStream`
will be removed in an upcoming React release. This API has been legacy,
is not widely used (renderToStaticMarkup is more common) and has
semantically eqiuvalent implementations with renderToReadableStream and
renderToPipeableStream.
stacked on #28870
inline script children have been encoded as HTML for a while now but
this can easily break script parsing so practically if you were
rendering inline scripts you were using dangerouslySetInnerHTML. This is
not great because now there is no escaping at all so you have to be even
more careful. While care should always be taken when rendering untrusted
script content driving users to use dangerous APIs is not the right
approach and in this PR the escaping functionality used for
bootstrapScripts and importMaps is being extended to any inline script.
the approach is to escape 's' or 'S" with the appropriate unicode code
point if it is inside a <script or </script sequence. This has the nice
benefit of minimally escaping the text for readability while still
preserving full js parsing capabilities. As articulated when we
introduced this escaping for prior use cases this is only safe because
we are escaping the entire script content. It would be unsafe if we were
not escaping the entirety of the script because we would no longer be
able to ensure there are no earlier or later <script sequences that put
the parser in unexpected states.
style text content has historically been escaped as HTML which is
non-sensical and often leads users to using dangerouslySetInnerHTML as a
matter of course. While rendering untrusted style rules is a security
risk React doesn't really provide any special protection here and
forcing users to use a completely unescaped API is if anything worse. So
this PR updates the style escaping rules for Fizz to only escape the
text content to ensure the tag scope cannot be closed early. This is
accomplished by encoding "s" and "S" as hexadecimal unicode
representation "\73 " and "\53 " respectively when found within a
sequence like </style>. We have to be careful to support casing here
just like with the script closing tag regex for bootstrap scripts.
## Summary
The Forget codename needs to be hidden from the UI to avoid confusion.
Going forward, we'll be referring to this set of features as part of the
larger React compiler. We'll be describing the primary feature that
we've built so far as auto-memoization, and this badge helps devs see
which components have been automatically memoized by the compiler.
## How did you test this change?
- force Forget badge on with and without the presence of other badges
- confirm colors/UI in light and dark modes
- force badges on for `ElementBadges`, `InspectableElementBadges`,
`IndexableElementBadges`
- Running yarn start in packages/react-devtools-shell
[demo
video](https://github.com/facebook/react/assets/973058/fa829018-7644-4425-8395-c5cd84691f3c)
For fbsource we've historically used a separate repo for imports due to
internal limitations in Diff Train. Those have been lifted so we can now
commit this branch here and then we can import from this repo (and get
rid of the other repo)
Previously, the `refs` property of a class component instance was
read-only by user code — only React could write to it, and until/unless
a string ref was used, it pointed to a shared empty object that was
frozen in dev to prevent userspace mutations.
Because string refs are deprecated, we want users to be able to codemod
all their string refs to callback refs. The safest way to do this is to
output a callback ref that assigns to `this.refs`.
So to support this, we need to make `this.refs` writable by userspace.
## Summary
This PR adds early return to the `diff` function. We don't need to go
through all the entries of `nextProps`, process and deep-diff the values
if `nextProps` is the same object as `prevProps`. Roughly 6% of all
`diffProperties` calls can be skipped.
## How did you test this change?
RNTester.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
## Summary
This pull request converts the CircleCI workflows to GitHub actions
workflows. [Github Actions
Importer](https://github.com/github/gh-actions-importer) was used to
convert the workflows initially, then I edited them manually to correct
errors in translation.
**Issues**
1. facebook/react/devtools_regression_tests
The scripts that this workflow calls need to be modified.
## How did you test this change?
I tested these changes in a forked repo. You can [view the logs of this
workflow in my fork](https://github.com/robandpdx/react/actions).
https://fburl.com/workplace/f6mz6tmw
In React 19 React will finally stop publishing UMD builds. This is
motivated primarily by the lack of use of UMD format and the added
complexity of maintaining build infra for these releases. Additionally
with ESM becoming more prevalent in browsers and services like esm.sh
which can host React as an ESM module there are other options for doing
script tag based react loading.
This PR removes all the UMD build configs and forks.
There are some fixtures that still have references to UMD builds however
many of them already do not work (for instance they are using legacy
features like ReactDOM.render) and rather than block the removal on
these fixtures being brought up to date we'll just move forward and fix
or removes fixtures as necessary in the future.
Fixes issue where if the first letter of the expected string appeared
anywhere in actual message, the assertion would pass, leading to false
negatives. We should check the entire expected string.
---------
Co-authored-by: Ricky <rickhanlonii@gmail.com>
This wasn't clearly articulated and tested why the code structure is
like this but I think the logic is correct - or at least consistent with
the weird semantics.
We place this top-level fragment check inside the recursion so that you
can resolve how many every Lazy or Usable wrappers you want and it still
preserves the same semantics if they weren't there (which they might not
be as a matter of a race condition).
However, we don't actually recurse with the top-level fragment
unwrapping itself because nesting a bunch of keyless fragments isn't the
same as a single fragment/element.
So that when we end up referring to it in more places, it's only one.
We don't do this same pattern for regular `Symbol.iterator` because we
also support the string `"@@iterator"` for backwards compatibility.
This adds support in Flight for serializing four kinds of streams:
- `ReadableStream` with objects as a model. This is a single shot
iterator so you can read it only once. It can contain any value
including Server Components. Chunks are encoded as is so if you send in
10 typed arrays, you get the same typed arrays out on the other side.
- Binary `ReadableStream` with `type: 'bytes'` option. This supports the
BYOB protocol. In this mode, the receiving side just gets `Uint8Array`s
and they can be split across any single byte boundary into arbitrary
chunks.
- `AsyncIterable` where the `AsyncIterator` function is different than
the `AsyncIterable` itself. In this case we assume that this might be a
multi-shot iterable and so we buffer its value and you can iterate it
multiple times on the other side. We support the `return` value as a
value in the single completion slot, but you can't pass values in
`next()`. If you want single-shot, return the AsyncIterator instead.
- `AsyncIterator`. These gets serialized as a single-shot as it's just
an iterator.
`AsyncIterable`/`AsyncIterator` yield Promises that are instrumented
with our `.status`/`.value` convention so that they can be synchronously
looped over if available. They are also lazily parsed upon read.
We can't do this with `ReadableStream` because we use the native
implementation of `ReadableStream` which owns the promises.
The format is a leading row that indicates which type of stream it is.
Then a new row with the same ID is emitted for every chunk. Followed by
either an error or close row.
`AsyncIterable`s can also be returned as children of Server Components
and then they're conceptually the same as fragment arrays/iterables.
They can't actually be used as children in Fizz/Fiber but there's a
separate plan for that. Only `AsyncIterable` not `AsyncIterator` will be
valid as children - just like sync `Iterable` is already supported but
single-shot `Iterator` is not. Notably, neither of these streams
represent updates over time to a value. They represent multiple values
in a list.
When the server stream is aborted we also close the underlying stream.
However, closing a stream on the client, doesn't close the underlying
stream.
A couple of possible follow ups I'm not planning on doing right now:
- [ ] Free memory by releasing the buffer if an Iterator has been
exhausted. Single shots could be optimized further to release individual
items as you go.
- [ ] We could clean up the underlying stream if the only pending data
that's still flowing is from streams and all the streams have cleaned
up. It's not very reliable though. It's better to do cancellation for
the whole stream - e.g. at the framework level.
- [ ] Implement smarter Binary Stream chunk handling. Currently we wait
until we've received a whole row for binary chunks and copy them into
consecutive memory. We need this to preserve semantics when passing
typed arrays. However, for binary streams we don't need that. We can
just send whatever pieces we have so far.
Per team discussion, this upgrades the `initialValue` argument for
`useDeferredValue` from experimental to canary.
- Original implementation PR:
https://github.com/facebook/react/pull/27500
- API documentation PR: https://github.com/reactjs/react.dev/pull/6747
I left it disabled at Meta for now in case there's old code somewhere
that is still passing an `options` object as the second argument.
This allows the plugin to be configured to run on an allowlist, rather
than compiling all files helping with an incremental rollout plan.
The sources option takes both an array of path strings or a function
to be flexible.
For now I've left this be optional but we can make it required.
ghstack-source-id: 282a33dc8d08d47f699894692e0fcc813dff5b77
Pull Request resolved: https://github.com/facebook/react-forget/pull/2855
No need to commit this in the repo, but keeping this locally helps with
building the feedback repo.
ghstack-source-id: 28f08992b1ab856567a5338af07e12ac820a7298
Pull Request resolved: https://github.com/facebook/react-forget/pull/2854
With the enableBinaryFlight flag on we should encode typed arrays and
blobs in the Reply direction too for parity.
It's already possible to pass Blobs inside FormData but you should be
able to pass them inside objects too.
We encode typed arrays as blobs and then unwrap them automatically to
the right typed array type.
Unlike the other protocol, I encode the type as a reference tag instead
of row tag. Therefore I need to rename the tags to avoid conflicts with
other tags in references. We are running out of characters though.
This hasn't been updated in a long time, and it getting really large.
You can view the authors locally via the git history with:
``
git shortlog -se | perl -spe 's/^\s+\d+\s+//'
``
## Overview
There's currently a bug in RN now that we no longer re-throw errors. The
`showErrorDialog` function in React Native only logs the errors as soft
errors, and never a fatal. RN was depending on the global handler for
the fatal error handling and logging.
Instead of fixing this in `ReactFiberErrorDialog`, we can implement the
new root options in RN to handle caught/uncaught/recoverable in the
respective functions, and delete ReactFiberErrorDialog. I'll follow up
with a RN PR to implement these options and fix the error handling.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
The ReadableStreamController for [direct
streams](https://bun.sh/docs/api/streams#direct-readablestream) in Bun
supports a flush() method to flush all buffered items to its underlying
sink.
Without manually calling flush(), all buffered items are only flushed to
the underlying sink when the stream is closed. This behavior causes the
shell rendered against Suspense boundaries never to be flushed to the
underlying sink.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
A lot of changes to the test runner will need to be made in order to
support the Bun runtime. A separate test was manually run in order to
ensure that the changes made are correct.
The test works by sanity-checking that the shell rendered against
Suspense boundaries are emitted first in the stream.
This test was written and run on Bun v1.1.3.
```ts
import { Suspense } from "react";
import { renderToReadableStream } from "react-dom/server";
if (!import.meta.resolveSync("react-dom/server").endsWith("server.bun.js")) {
throw new Error("react-dom/server is not the correct version:\n " + import.meta.resolveSync("react-dom/server"));
}
const A = async () => {
await new Promise(resolve => setImmediate(resolve));
return <div>hi</div>;
};
const B = async () => {
return (
<Suspense fallback={<div>loading</div>}>
<A />
</Suspense>
);
};
const stream = await renderToReadableStream(<B />);
let text = "";
let count = 0;
for await (const chunk of stream) {
text += new TextDecoder().decode(chunk);
count++;
}
if (
text !==
`<!--$?--><template id="B:0"></template><div>loading</div><!--/$--><div hidden id="S:0"><div>hi</div></div><script>$RC=function(b,c,e){c=document.getElementById(c);c.parentNode.removeChild(c);var a=document.getElementById(b);if(a){b=a.previousSibling;if(e)b.data="$!",a.setAttribute("data-dgst",e);else{e=b.parentNode;a=b.nextSibling;var f=0;do{if(a&&8===a.nodeType){var d=a.data;if("/$"===d)if(0===f)break;else f--;else"$"!==d&&"$?"!==d&&"$!"!==d||f++}d=a.nextSibling;e.removeChild(a);a=d}while(a);for(;c.firstChild;)e.insertBefore(c.firstChild,a);b.data="$"}b._reactRetry&&b._reactRetry()}};$RC("B:0","S:0")</script>`
) {
throw new Error("unexpected output");
}
if (count !== 2) {
throw new Error("expected 2 chunks from react ssr stream");
}
```
The compiler has an optimisation where it transforms a simple arrow
function with only a return statement to a implicit arrow function.
In the case, there's a directive in this simple arrow function, the
directive gets dropped.
Instead of dropping the directive, the compiler should perform this
optimisation only if there are no directives.
ghstack-source-id: 514cd2440025986a2d6d950694a7339d779b09f2
Pull Request resolved: https://github.com/facebook/react-forget/pull/2848
The useMemoCache polyfill doesn't have access to the fiber, and it
simply uses state, which does not work with the existing devtools
badge for the compiler.
With this PR, devtools will look on the very first hook's state for the
memo cache sentinel and display the Forget badge if present.
The polyfill will add this sentinel to it's state (the cache array).
The flight-browser fixtures doesn't make sense. It also uses UMD builds
which are being removed so we'd have to make it use esm.sh or something
and really it just won't work because it needs to be built by webpack to
not error. We could potentially shim the webpack globals but really the
right thing is to publish the esm version of react-server and use esm.sh
to load a browser only esm demo of react-server. This change removes the
flight-browser fixture
Support propagating theme from Chrome DevTools frontend, the field is
optional.
Next step, which is out of scope of this project and general improvement
for React DevTools: teach RDT to listen to theme changes and if the
theme preference is set to `auto` in settings, update the theme
accordingly with the browser devtools.
To make the polyfill work well with devtools, we add this sentinel.
Devtools will look for this sentinel before adding the Forget badge.
ghstack-source-id: d246040f67da48fa46f818753c8bf26dff56f390
Pull Request resolved: https://github.com/facebook/react-forget/pull/2847
## Summary
Stacked on https://github.com/facebook/react/pull/28552. Review only the
[last commit at the
top](c69952f1bf).
These changes add new package `react-devtools-fusebox`, which is the
entrypoint for the RDT Frontend, which will be used in Chrome DevTools
panel. The main differences from other frontend shells (extension,
standalone) are:
1. This package builds scripts in ESM format, this is required by Chrome
DevTools, see webpack config:
c69952f1bf/packages/react-devtools-fusebox/webpack.config.frontend.js (L50-L52)
2. The build includes styles in a separate `.css` file, which is
required for Chrome DevTools: styles are loaded lazily once panel is
mounted.
## Summary
RDT backend will now expose method `connectWithCustomMessagingProtocol`,
which will be similar to the classic `connectToDevTools` one, but with
few differences:
1. It delegates the communication management between frontend and
backend to the owner (whos injecting RDT backend). Unlike the
`connectToDevTools`, which is relying on websocket connection and
receives host and port as an arguments.
2. It returns a callback, which can be used for unsubscribing the
current backend instance from the global DevTools hook.
This is a prerequisite for any non-browser RDT integration, which is not
designed to be based on websocket.
Hoistables should never flush before the preamble however there is a
surprisingly easy way to trigger this to happen by suspending in the
shell of the app. This change modifies the flushing behavior to not emit
any hoistables before the preamble has written. It accomplishes this by
aborting the flush early if there are any pending root tasks remaining.
It's unfortunate we need this extra condition but it's essential that we
don't emit anything before the preamble and at the moment I don't see a
way to do that without introducing a new condition.
There is a test that began to fail with this update. It turns out that
in node the root can be blocked during a resume even for a component
inside a Suspense boundary if that boundary was part of the prerender.
This means that with the current heuristic in this PR boundaries cannot
be flushed during resume until the root is unblocked. This is not ideal
but this is already how Edge works because the root blocks the stream in
that case. This just makes Node deopt in a similar way to edge. We
should improve this but we ought to do so in a way that works for edge
too and it needs to be more comprehensive.
## Overview
**Internal React repo tests only**
Depends on https://github.com/facebook/react/pull/28710
Adds three new assertions:
- `assertConsoleLogDev`
- `assertConsoleWarnDev`
- `assertConsoleErrorDev`
These will replace this pattern:
```js
await expect(async () => {
await expect(async () => {
await act(() => {
root.render(<Fail />)
});
}).toThrow();
}).toWarnDev('Warning');
```
With this:
```js
await expect(async () => {
await act(() => {
root.render(<Fail />)
});
}).toThrow();
assertConsoleWarnDev('Warning');
```
It works similar to our other `assertLog` matchers which clear the log
and assert on it, failing the tests if the log is not asserted before
the test ends.
## Diffs
There are a few improvements I also added including better log diffs and
more logging.
When there's a failure, the output will look something like:
<img width="655" alt="Screenshot 2024-04-03 at 11 50 08 AM"
src="https://github.com/facebook/react/assets/2440089/0c4bf1b2-5f63-4204-8af3-09e0c2d752ad">
Check out the test suite for snapshots of all the failures we may log.
Based on:
- #28808
- #28804
---
This adds a React DOM method called requestFormReset that schedules a
form reset to occur when the current transition completes.
Internally, it's the same method that's called automatically whenever a
form action is submitted. It only affects uncontrolled form inputs. See
https://github.com/facebook/react/pull/28804 for details.
The reason for the public API is so UI libraries can implement their own
action-based APIs and maintain the form-resetting behavior, something
like this:
```js
function onSubmit(event) {
// Disable default form submission behavior
event.preventDefault();
const form = event.target;
startTransition(async () => {
// Request the form to reset once the action
// has completed
requestFormReset(form);
// Call the user-provided action prop
await action(new FormData(form));
})
}
```
Based on:
- #28804
---
This sets adds a new ReactDOM export called requestFormReset, including
setting up the export and creating a method on the internal ReactDOM
dispatcher. It does not yet add any implementation.
Doing this in its own commit for review purposes.
The API itself will be explained in the next PR.
This updates the behavior of form actions to automatically reset the
form's uncontrolled inputs after the action finishes.
This is a frequent feature request for people using actions and it
aligns the behavior of client-side form submissions more closely with
MPA form submissions.
It has no impact on controlled form inputs. It's the same as if you
called `form.reset()` manually, except React handles the timing of when
the reset happens, which is tricky/impossible to get exactly right in
userspace.
The reset shouldn't happen until the UI has updated with the result of
the action. So, resetting inside the action is too early.
Resetting in `useEffect` is better, but it's later than ideal because
any effects that run before it will observe the state of the form before
it's been reset.
It needs to happen in the mutation phase of the transition. More
specifically, after all the DOM mutations caused by the transition have
been applied. That way the `defaultValue` of the inputs are updated
before the values are reset. The idea is that the `defaultValue`
represents the current, canonical value sent by the server.
Note: this change has no effect on form submissions that aren't
triggered by an action.
`<noscript>` scopes should be considered inert from the perspective of
Fizz since we assume they'll only be used in rare and adverse
circumstances. When we added preload support for img tags we did not
include the noscript scope check in the opt-out for preloading. This
change adds it in
fixes: #27910
Fixes a tiny inconsistency with compiler options where one was all
uppercase and one all lowercase by normalizing to lowercase regardless
of the casing of the user's config.
ghstack-source-id: fe60a3259de89a1b3fdd7475950e16e96cc57f6b
Pull Request resolved: https://github.com/facebook/react-forget/pull/2832
It was never clear to me what the difference between Wipe and Reset was.
Let's just get rid of one and reset to something more useful instead of
fibonacci.
ghstack-source-id: 4f88a1c1da2d0fd9e1f26e4859c12db0fc961af2
Pull Request resolved: https://github.com/facebook/react-forget/pull/2837
This compresses more efficiently than the base64 encoding we were
previously using, which makes sharing URLs a little less unwieldy and
takes up less space in local storage. Using
some real code as an example, lz-string compresses to 8040 bytes,
whereas the original base64 encoding we were using compresses to 16504
bytes
ghstack-source-id: b8f1089889b94b07d6f419606b798ffddb8863ba
Pull Request resolved: https://github.com/facebook/react-forget/pull/2834
These test don't `assertLog` or `waitFor` so we don't need to
`Scheduler.log`. Ideally we would, but since they're fuzzers it's a bit
difficult to know what the expected log is from the helper.
Since this doesn't regress current test behavior, we can improve them
after this to unblock https://github.com/facebook/react/pull/28737
We want to warn if we detect that an app is using an outdated JSX
transform. We can't just warn if `createElement` is called because we
still support `createElement` when it's called manually. We only want to
warn if `createElement` is output by the compiler.
The heuristic is to check for a `__self` prop, which is an optional,
internal prop that older transforms used to pass to `createElement` for
better debugging in development mode.
If `__self` is present, we `console.warn` once with advice to upgrade to
the modern JSX transform. Subsequent elements will not warn.
There's a special case we have to account for: when a static "key" prop
is defined _after_ a spread, the modern JSX transform outputs
`createElement` instead of `jsx`. (This is because with `jsx`, a spread
key always takes precedence over a static key, regardless of the order,
whereas `createElement` respects the order.) To avoid a false positive
warning, we skip the warning whenever a `key` prop is present.
Fixes a bug that happens when an error occurs during hydration, React
switches to client rendering, and then the client render suspends. It
works correctly if there's a Suspense boundary on the stack, but not if
it happens in the shell of the app.
Prior to this fix, the app would crash with an "Unknown root exit
status" error.
I left a TODO comment for how we might refactor this code to be less
confusing in the future.
Fix for an issue introduced in #28473 where cloneElement() with a string
ref fails due to lack of an owner. We should use the current owner in
this case.
---------
Co-authored-by: Rick Hanlon <rickhanlonii@fb.com>
Previously if the external runtime was enabled Fizz tests would use it
exclusively. However now that this flag is enabled for OSS and Meta
builds this means we were no longer testing the inline script runtime.
This changes the test flags to produce some runs where we test the
inline script runtime and others where we test the external runtime
the external runtime will be tested if the flag is enabled and
* Meta Builds: variant is true
* OSS Builds: experiemental is true
this gives us decent coverage. long term we should probably bring
variant to OSS builds since we will eventually want to test both modes
even when the external runtime is stable.
When packaging we want to infer that a bundle exists for a
`react-server` file even if it isn't explicitly configured. This is
useful in particular for the react-server entrypoints that error on
import that were recently added to `react-dom`
This change also cleans up a wayward comment left behind in a prior PR
Follow up to #28783 and #28786.
Since we've changed the implementations of these we can rename them to
something a bit more descriptive while we're at it, since anyone
depending on them will need to upgrade their code anyway.
"react" with no condition:
`__CLIENT_INTERNALS_DO_NOT_USE_OR_WARN_USERS_THEY_CANNOT_UPGRADE`
"react" with "react-server" condition:
`__SERVER_INTERNALS_DO_NOT_USE_OR_WARN_USERS_THEY_CANNOT_UPGRADE`
"react-dom":
`__DOM_INTERNALS_DO_NOT_USE_OR_WARN_USERS_THEY_CANNOT_UPGRADE`
We have a different set of dispatchers that Flight uses. This also
includes the `jsx-runtime` which must also be aliased to use the right
version.
To ensure the right versions are used together we rename the export of
the SharedInternals from 'react' and alias it in relevant bundles.
This is similar to #28771 but for isomorphic. We need a make over for
these dispatchers anyway so this is the first step. Also helps flush out
some internals usage that will break anyway.
It flattens the inner mutable objects onto the ReactSharedInternals.
`react-server` precludes loading code that expects to be run in a client
context. This includes react-dom/client react-dom/server
react-dom/unstable_testing react-dom/profiling and react-dom/static
This update makes importing any of these client only entrypoints an
error
Treat async (boolean prop) consistently with Float. Previously float
checked if `props.async === true` (or not true) but the rest of
react-dom considers anything truthy that isn't a function or symbol as
`true`. This PR normalizes the Float behavior.
Stacked on #28751
Historically explicit hydration scheduling used the reconciler's update
priority to schedule the hydration. There was a lingering todo to switch
to using event priority in the absence of an explicit update priority.
This change updates the hydration priority by referring to the event
priority if no update priority is set
Stacked on #28771
ReactDOMCurrentDispatcher has longer property names for various methods.
These methods are only ever called internally and don't need to be
represented with as many characters. This change shortens the names and
aligns them with the hint codes we use in Flight. This alignment is
passive since not all dispatcher methods will exist as flight
instructions but where they can line up it seems reasonable to make them
do so
Stacked on #28751
ReactDOMSharedInternals uses properties of considerable length to model
mutuable state. These properties are not mangled during minification and
contribute a not insigificant amount to the uncompressed bundle size and
to a lesser degree compressed bundle size.
This change rewrites the DOMInternals in a way that shortens property
names so we can have smaller builds.
It also treats the entire object as a mutable container rather than
having different mutable sub objects.
The same treatment should be given to ReactSharedInternals
We used to assume that outlined models are emitted before the reference
(which was true before Blobs). However, it still wasn't safe to assume
that all the data will be available because an "import" (client
reference) can be async and therefore if it's directly a child of an
outlined model, it won't be able to update in place.
This is a similar problem as the one hit by @unstubbable in #28669 with
elements, but a little different since these don't follow the same way
of wrapping.
I don't love the structuring of this code which now needs to pass a
first class mapper instead of just being known code. It also shares the
host path which is just an identity function. It wouldn't necessarily
pass my own review but I don't have a better one for now. I'd really
prefer if this was done at a "row" level but that ends up creating even
more code.
Add test for Blob in FormData and async modules in Maps.
We landed a flag to disable test utils in many builds but we need to
fork the entrypoint to make it work with tests properly. This also
removes test-utils implementations from builds that do not support it.
Currently in OSS builds the only thing in test-utils is a reexport of
`act`
## Summary
1. RDT browser extension's content scripts will now ship source maps
(without source in prod, to save some bundle size).
2. `installHook` content script will be ignore listed via `ignoreList`
field in the corresponding source map.
3. Previously, source map for backend file used `x_google_ignoreList`
naming, now `ignoreList`.
## How did you test this change?
1. `ignoreList-test.js`
2. Tested manually that I don't see `installHook` in stack traces when
`console.error` is called.
This PR moves `flushSync` out of the reconciler. there is still an
internal implementation that is used when these semantics are needed for
React methods such as `unmount` on roots.
This new isomorphic `flushSync` is only used in builds that no longer
support legacy mode.
Additionally all the internal uses of flushSync in the reconciler have
been replaced with more direct methods. There is a new
`updateContainerSync` method which updates a container but forces it to
the Sync lane and flushes passive effects if necessary. This combined
with flushSyncWork can be used to replace flushSync for all instances of
internal usage.
We still maintain the original flushSync implementation as
`flushSyncFromReconciler` because it will be used as the flushSync
implementation for FB builds. This is because it has special legacy mode
handling that the new isomorphic implementation does not need to
consider. It will be removed from production OSS builds by closure
though
Currently updatePriority is tracked in the reconciler. `flushSync` is
going to be implemented reconciler agnostic soon and we need to move the
tracking of this state to the renderer and out of reconciler. This
change implements new renderer bin dings for getCurrentUpdatePriority
and setCurrentUpdatePriority.
I was originally going to have the getter also do the event priority
defaulting using window.event so we eliminate getCur rentEventPriority
but this makes all the callsites where we store the true current
updatePriority on the stack harder to work with so for now they remain
separate.
I also moved runWithPriority to the renderer since it really belongs
whereever the state is being managed and it is only currently exposed in
the DOM renderer.
Additionally the current update priority is not stored on
ReactDOMSharedInternals. While not particularly meaningful in this
change it opens the door to implementing `flushSync` outside of the
reconciler
Follow up to #28768.
The modern JSX runtime (`jsx`) does not need to check if each prop is a
direct property with `hasOwnProperty` because the compiler always passes
a plain object.
I'll leave the check in the old JSX runtime (`createElement`) since that
one can be called manually with any kind of object, and if there were
old user code that relied on this for some reason, it would be using
that runtime.
CannotPreserveMemoization
We do need to fix the error location to point to the "callsite" rather
than the definition of the useMemo callback, but that aside, even if the
error message were perfect, it's not meant to be actionable to the user.
So let's change the severity to CannotPreserveMemoization. This
preserves the validation, but the eslint plugin won't report it.
ghstack-source-id: 722c88922884de05e89030a7b001bd93e0a2a114
Pull Request resolved: https://github.com/facebook/react-forget/pull/2825
This adds a new category of error where the compiler cannot preserve
memoization exactly how as it was originally authored. We're adding a
new category here because it's not an actionable error, and allows us to
more specifically control whether it's reportable or not.
ghstack-source-id: 9693cd42ca64b980248c6202091bdd4c827e1cd4
Pull Request resolved: https://github.com/facebook/react-forget/pull/2824
We currently support FormData for Replies mainly for Form Actions. This
supports it in the other direction too which lets you return it from an
action as the response. Mainly for parity.
We don't really recommend that you just pass the original form data back
because the action is supposed to be able to clear fields and such but
you could potentially at least use this as the format and could clear
some fields.
We could potentially optimize this with a temporary reference if the
same object was passed to a reply in case you use it as a round trip to
avoid serializing it back again. That way the action has the ability to
override it to clear fields but if it doesn't you get back the same as
you sent.
#28755 adds support for Blobs when the `enableBinaryFlight` is enabled
which allows them to be used inside FormData too.
(Unless "key" is spread onto the element.)
Historically, the JSX runtime clones the props object that is passed in.
We've done this for two reasons.
One reason is that there are certain prop names that are reserved by
React, like `key` and (before React 19) `ref`. These are not actual
props and are not observable by the target component; React uses them
internally but removes them from the props object before passing them to
userspace.
The second reason is that the classic JSX runtime, `createElement`, is
both a compiler target _and_ a public API that can be called manually.
Therefore, we can't assume that the props object that is passed into
`createElement` won't be mutated by userspace code after it is passed
in.
However, the new JSX runtime, `jsx`, is not a public API — it's solely a
compiler target, and the compiler _will_ always pass a fresh, inline
object. So the only reason to clone the props is if a reserved prop name
is used.
In React 19, `ref` is no longer a reserved prop name, and `key` will
only appear in the props object if it is spread onto the element.
(Because if `key` is statically defined, the compiler will pass it as a
separate argument to the `jsx` function.) So the only remaining reason
to clone the props object is if `key` is spread onto the element, which
is a rare case, and also triggers a warning in development.
In a future release, we will not remove a spread key from the props
object. (But we'll still warn.) We'll always pass the object straight
through.
The expected impact is much faster JSX element creation, which in many
apps is a significant slice of the overall runtime cost of rendering.
`delete` causes an object (in V8, and maybe other engines) to deopt to a
dictionary instead of a class. Instead of `assign` + `delete`, manually
iterate over all the properties, like the JSX runtime does.
To avoid copying the object twice I moved the `ref` prop removal to come
before handling default props. If we already cloned the props to remove
`ref`, then we can skip cloning again to handle default props.
We currently support Blobs when passing from Client to Server so this
adds it in the other direction for parity - when `enableFlightBinary` is
enabled.
We intentionally only support the `Blob` type to pass-through, not
subtype `File`. That's because passing additional meta data like
filename might be an accidental leak. You can still pass a `File`
through but it'll appear as a `Blob` on the other side. It's also not
possible to create a faithful File subclass in all environments without
it actually being backed by a file.
This implementation isn't great but at least it works. It creates a few
indirections. This is because we need to be able to asynchronously emit
the buffers but we have to "block" the parent object from resolving
while it's loading.
Ideally, we should be able to create the Blob on the client early and
then stream in it lazily. Because the Blob API doesn't guarantee that
the data is available synchronously. Unfortunately, the native APIs
doesn't have this. We could implement custom versions of all the data
read APIs but then the blobs still wouldn't work with native APIs. So we
just have to wait until Blob accepts a stream in the constructor.
We should be able to stream each chunk early in the protocol though even
though we can't unblock the parent until they've all loaded. I didn't do
this yet mostly because of code structure and I'm lazy.
This implements the concept of a DEV-only "owner" for Server Components.
The owner concept isn't really super useful. We barely use it anymore,
but we do have it as a concept in DevTools in a couple of cases so this
adds it for parity. However, this is mainly interesting because it could
be used to wire up future owner-based stacks.
I do this by outlining the DebugInfo for a Server Component
(ReactComponentInfo). Then I just rely on Flight deduping to refer to
that. I refer to the same thing by referential equality so that we can
associate a Server Component parent in DebugInfo with an owner.
If you suspend and replay a Server Component, we have to restore the
same owner. To do that, I did a little ugly hack and stashed it on the
thenable state object. Felt unnecessarily complicated to add a stateful
wrapper for this one dev-only case.
The owner could really be anything since it could be coming from a
different implementation. Because this is the first time we have an
owner other than Fiber, I have to fix up a bunch of places that assumes
Fiber. I mainly did the `typeof owner.tag === 'number'` to assume it's a
Fiber for now.
This also doesn't actually add it to DevTools / RN Inspector yet. I just
ignore them there for now.
Because Server Components can be async the owner isn't tracked after an
await. We need per-component AsyncLocalStorage for that. This can be
done in a follow up.
Based on:
- #28464
---
This moves the entire string ref implementation out Fiber and into the
JSX runtime. The string is converted to a callback ref during element
creation. This is a subtle change in behavior, because it will have
already been converted to a callback ref if you access element.prop.ref
or element.ref. But this is only for Meta, because string refs are
disabled entirely in open source. And if it leads to an issue in
practice, the solution is to switch to a different ref type, which Meta
is going to do regardless.
First attempt at making the linter work with advanced TypeScript syntax
Falls back to the babel parser for some advanced syntax like string template
syntax.
This is pretty hacky as it doesn't take in any parsing options that are
configured for the outer ESLint parser, not sure how that could be handled.
In prod, the `_owner` field is only used for string refs so if we have
string refs disabled, we don't need this field. In fact, that's one of
the big benefits of deprecating them.
This removes defaultProps support for all component types except for
classes. We've chosen to continue supporting defaultProps for classes
because lots of older code relies on it, and unlike function components,
(which can use default params), there's no straightforward alternative.
By implication, it also removes support for setting defaultProps on
`React.lazy` wrapper. So this will not work:
```js
const MyClassComponent = React.lazy(() => import('./MyClassComponent'));
// MyClassComponent is not actually a class; it's a lazy wrapper. So
// defaultProps does not work.
MyClassComponent.defaultProps = { foo: 'bar' };
```
However, if you set the default props on the class itself, then it's
fine.
For classes, this change also moves where defaultProps are resolved.
Previously, defaultProps were resolved by the JSX runtime. This change
is only observable if you introspect a JSX element, which is relatively
rare but does happen.
In other words, previously `<ClassWithDefaultProp />.props.aDefaultProp`
would resolve to the default prop value, but now it does not.
Follows #28695
Now that the action has run successfully in debug mode
([logs](https://github.com/facebook/react/actions/runs/8532177618/job/23372921455#step:2:35)),
let's enable it to persist changes.
Also changes the number of operations per run from the default of 30 to
100 since we have a large backlog of issues and PRs to work through.
Finally adds enhancement label as exempt from stale.
We basically have four kinds of recoverable errors:
- Hydration mismatches.
- Server errored but client didn't.
- Hydration render errored but client render didn't (in Root or Suspense
boundary).
- Concurrent render errored but synchronous render didn't.
For the first three we log an additional error that the root or Suspense
boundary didn't error. This provides some context about what happened.
However, the problem is that for hydration mismatches that's unnecessary
extra context that is confusing. We also don't log any additional
context for concurrent render errors that could recover. This used to be
the only recoverable error so it didn't need extra context but now we
need to distinguish them. When we log these to `reportError` it's
confusing to just see the error because you didn't see anything error on
the page. It's also hard to group them together as one.
In this PR, I remove the unnecessary context for hydration mismatches.
For hydration and concurrent errors, I now wrap them in an error that
describes that what happened but then use the new `cause` field to link
the original error so we can keep that as the cause. The error that
happened was that hydration client rendered or you deopted to sync
render, the cause of that error is some other error.
For server errors, we control the Error object so I already had added
some context to that error object's message. Since we hide the message
in prod, it's nice not to have the raw message in DEV neither. We could
potentially split these into two errors for parity though.
Follow up to #28684.
V8 includes the message in the stack and printed errors include just the
stack property which is assumed to contain the message. Without this,
the prefix doesn't get printed in the console.
<img width="578" alt="Screenshot 2024-04-03 at 6 32 04 PM"
src="https://github.com/facebook/react/assets/63648/d98a2db4-6ebc-4805-b669-59f449dfd21f">
A possible alternative would be to use a nested error with a `cause`
like #28736 but that would need some more involved serializing since
this prefix is coming from the server. Perhaps as a separate attribute.
Moving this to `internal-test-utils` so I can add helpers in the next PR
for:
- assertLogDev
- assertWarnDev
- assertErrorDev
Which will be exported from `internal-test-utils`. This isn't strictly
necessary, but it makes the factoring nicer, so internal-test-until
doesn't need to depend on `scripts/jest`.
Cleanup enableUseRefAccessWarning flag
I don't think this flag has a path forward in the current
implementation. The detection by stack trace is too brittle to detect
the lazy initialization pattern reliably (see e.g. some internal tests
that expect the warning because they use lazy intialization, but a
slightly different pattern then the expected pattern.
I think a new version of this could be to fully ban ref access during
render with an alternative API for the exceptional cases that today
require ref access during render.
Remove @providesModule remnants
Removes `@providesModule` from the generated RN modules and CI
validation that no `@providesModule` is added which should no longer be
needed as this has been the case for years now.
When a ref is passed to a class component, the class instance is
attached to the ref's current property automatically. This different
from function components, where you have to do something extra to attach
a ref to an instance, like passing the ref to `useImperativeHandle`.
Existing class component code is written with the assumption that a ref
will not be passed through as a prop. For example, class components that
act as indirections often spread `this.props` onto a child component. To
maintain this expectation, we should remove the ref from the props
object ("consume" it) before passing it to lifecycle methods. Without
this change, much existing code will break because the ref will attach
to the inner component instead of the outer one.
This is not an issue for function components because we used to warn if
you passed a ref to a function component. Instead, you had to use
`forwardRef`, which also implements this "consuming" behavior.
There are a few places in the reconciler where we modify the fiber's
internal props object before passing it to userspace. The trickiest one
is class components, because the props object gets exposed in many
different places, including as a property on the class instance.
This was already accounted for when we added support for setting default
props on a lazy wrapper (i.e. `React.lazy` that resolves to a class
component).
In all of these same places, we will also need to remove the ref prop
when `enableRefAsProp` is on.
Closes#28602
---------
Co-authored-by: Jan Kassens <jan@kassens.net>
Only the FB entry point has legacy mode now so we can move the remaining
code in there.
Also enable disableLegacyMode in modern www builds since it doesn't
expose those entry points.
Now dependent on #28709.
---------
Co-authored-by: Josh Story <story@hey.com>
Saves some bytes and ensures that we're actually disabling it.
Turns out this flag wasn't disabling React Native/Fabric, React Noop and
React ART legacy modes so those are updated too.
Should be rebased on #28681.
This PR relands #28672 on top of the flag removal and the test
demonstrating a breakage in Suspense for legacy mode.
React has deprecated module pattern Function Components for many years
at this point. Supporting this pattern required React to have a concept
of an indeterminate component so that when a component first renders it
can turn into either a ClassComponent or a FunctionComponent depending
on what it returns. While this feature was deprecated and put behind a
flag it is still in stable. This change remvoes the flag, removes the
warnings, and removes the concept of IndeterminateComponent from the
React codebase.
While removing IndeterminateComponent type Seb and I discovered that we
needed a concept of IncompleteFunctionComponent to support Suspense in
legacy mode. This new work tag is only needed as long as legacy mode is
around and ideally any code that considers this tag will be excludable
from OSS builds once we land extra gates using `disableLegacyMode` flag.
Pulling this out of #28657.
This runs react-art in concurrent mode if disableLegacyMode is true.
Effectively this means that the OSS version will be in concurrent mode
and the `.modern.js` version for Meta will be in concurrent mode, once
the flag flips for modern, but the `.classic.js` version for Meta will
be in legacy mode.
Updates flowing in from above flush synchronously so that they commit as
a unit. This also ensures that refs are resolved before the parent life
cycles. setStates deep in the tree will now be batched using "discrete"
priority but should still happen same task.
Implements support for use:
* Teaches InferReactivePlaces to treat use() result as reactive
* Teaches FlattenScopesWithHooks to also flatten scopes with use()
Handles both `use()` and `React.use()`.
This adds rollup to the runtime and adds a new plugin to add the license banner
+ inject the `"use no memo"` directive. We need to inject it there as rollup
currently strips out unknown directives during bundling.
For now this configures rollup to strip out comments in DEV builds and
whitespace. Unfortunately there's no easy way to do this in just terser alone or
other minifiers/manglers, so I had to add prettier as well to re-format the
minified code. This does make the build a little bit slower:
``` before: yarn build 118.96s user 12.38s system 185% cpu 1:10.81 total after:
yarn build 121.55s user 12.90s system 183% cpu 1:13.17 total ```
Eventually I would like to have a similar setup to React's rollup config where
we can have DEV and prod builds. After the repo merge we could probably share or
reuse bits of React's rollup config.
In React DOM, in general, we don't differentiate between `null` and
`undefined` because we expect to target DOM APIs. When we're setting a
property on a Custom Element, in the new heuristic, the goal is to allow
passing whatever data type instead of normalizing it. Switching between
`undefined` and `null` as an explicit value should therefore be
respected.
However, in this mode if `undefined` is used for the initial value, we
don't actually set the property at all. If passing `null` we will now
initialize it to the value `null`. Meaning `undefined` kind of
represents the default.
### Removing Properties
There is a pretty complex edge case which is what should happen when a
prop used to exist but was removed from the props object. This doesn't
have any kind of defined semantics. It really should mean - return to
"default". Because in the declarative world it means the same as if it
was just created - i.e. we can't just leave it as it was.
The closest might be `delete object.property` but that's not really the
intended way that properties on custom elements / classes are supposed
to operate. Additionally, for a property to even hit our heuristic it
must pass the `in` test and must exist to being with so the default must
have a value.
Since the point of these properties is to contain any kind of type,
there isn't really a conceptual default value. E.g. a numeric default
value might be zero `0` while a default string might be empty `""` and
default object might `null`. Additionally, the conceptual default can
really be initialized to anything. There's also varied precedence in the
ecosystem here and really no consensus. Anything we pick would be kind
of wrong, so we used to just pick `null`.
_The safest way to consume a Custom Element is to always pass the same
set of props._
JS does have a concept of a "default value" though and that is described
as the value `undefined`. That's why default argument / object property
initializers are initialized if the value is `undefined`.
The problem with using `undefined` as value is that [you shouldn't
actually ever set the value of a class property to
`undefined`](https://twitter.com/sebmarkbage/status/1774082540296388752).
A property should always be initialized to some value. It can't be left
missing and shouldn't be initialized to the value `undefined` for hidden
class optimizations. If we just mutate it to be `undefined` it would be
potentially bad for perf and shouldn't really be the value after
removing property - it should be returned to default.
Every property should really have a setter to be useful since it is what
is used to trigger reactivity when it changes. Sometimes you can just
use the properties passively when something else happens but most of the
time it should be a setter but to reach parity with DOM it should really
be always so that the active value can be normalized.
Those setters can have default argument initializers to represent what
the default value should be. Therefore Custom Element properties should
be used like this:
```js
class CustomElement extends HTMLElement {
_textLabel = '';
_price = 0;
_items = null;
constructor() {
super();
}
set textLabel(value = '') {
this._textLabel = value;
}
get textLabel() {
return this._textLabel;
}
set price(value = 0) {
this._price = value;
}
get price() {
return this._price;
}
set items(value = null) {
this._items = value;
}
get items() {
return this._items;
}
}
```
The default initializer can be used to initialize a value back to its
original default when `undefined` is passed to it. Therefore, we pass
`undefined`, not because we expect that to be the value of a property
but because that's the value that represents "return to default".
This fixes#28203 but not really for the reason specified in the issue.
We don't expect you to actually store the `undefined` value but to use a
setter to set the property to something else that represents the
default. When we initialize the element the first time, we won't set
anything if it's the value `undefined` so we assume that the property
initializers running in the constructor is going to set the same default
value as if we set the property to `undefined`.
cc @josepharhar
This PR makes all packages share the same typescript version and updates us to
latest versions of typescript, ts-node, typescript-eslint/eslint-plugin and
typescript-eslint/parser.
I also noticed that the tsconfig we were extending (node18-strictest) was
deprecated, so I switched us over to one that's more up to date.
Also had to make a couple of small changes to the playground so that continues
to build correctly.
Previously, we would drop directives inside a component or hook but this is
problematic with reanimated which uses `'worklet'` to mark components from
compilation.
This PR adds a directive to HIRFunction and ReactiveFunction and codegens the
directive add the end. No processing is done on the directives themselves.
Babel seems to store the directives on a BlockStatement, rather than on the
Function but I've stored it on the Function types because we only support
compiling functions and the spec defines directives as occuring in the initial
statement list of a function: > A Directive Prologue is the longest sequence of
ExpressionStatements > occurring as the initial StatementListItems or
ModuleItems of a > FunctionBody, a ScriptBody, or a ModuleBody and where each >
ExpressionStatement in the sequence consists entirely of a > StringLiteral token
followed by a semicolon.
This PR was the result of a long chain of ~yak-shaving~ debugging kicked off as
a result of fixing up invariants. Where this started was that i noticed some
cases of loops where the first instance we saw of a reactive scope was after its
starting instruction. Eg instruction N would have an operand with scope
Start:End, where Start was _before_ N. One of the cases involved a phi with a
backedge. Then i noticed that we assign scopes differently for phis with and
without backedges:
```
[1] let x0 = init;
[2] if (x0 < limit) {
[3] x1 += increment;
}
x2 = phi(x0, x1);
[4] x2;
```
The phi isn't mutated _or_ reassigned after its creation, so we don't assign a
mutable range to the phi or any of its operands. We also don't create a scope
for `x`.
But change the `if` to a `while` and now the phi moves - now there's a backedge:
```
[1] let x0 = init;
[2] while (x0 < limit) {
x2 = phi(x0, x2); // now this is "mutated" later!!!
[3] x2 += increment;
}
[4] x2;
```
What was happening here is that x2 has a mutable range which is "after" the phi
instruction, so it would appear that the phi was actually being mutated later.
Ie, this was treated equivalently to the original "if" version, but with a
mutation:
```
let x = [];
if (cond) {
x = {};
}
mutate(x); // later mutation of the phi
```
But these latter two cases are different! We only need to (should) create a
mutable range for a phi _if its value is actually mutated_. If it's just being
reassigned, well then it shouldn't matter if there are back edges or not.
So this PR implements that intuition: only create a mutable range for a phi if
it is actually _mutated_ later, ie don't assign a mutable range if it is only
_reassigned_ later. Concretely in InferMutableRanges:
* InferMutableLifetimes no longer has to initialize a range for phis during the
first pass (inferMutableRangesForStores=false). We wait to see if the phi is
mutated during the main fixpoint iteration of InferMutableRanges
* The main fixpoint iteration in InferMutableRanges already aliases phi operands
if the phi is later mutated, which will extend the end of the mutable range of
all the operands accordingly.
* Finally, InferMutableLifetimes's second run
(inferMutableRangesForStores=true), we ensure that any phis mutated later have a
valid mutable range, specifically setting the `start` of the range since the
fixpoint only updates the `end` value.
## Summary
This repo uses [Stalebot](https://github.com/probot/stale) to manage
stale Issues and PRs. Stalebot hasn't been maintained for a couple of
years and is officially archived. The number of open Issues and PRs has
increased rapidly since early 2022. Some of this looks like issues with
Stalebot reliability where labels were not applied or close actions were
not taken even when meeting the criteria in the config.
In order to make it easier for maintainers to spend time on current
Issues and PRs, let's upgrade to the Github Stale Action. For now this
PR applies the same config to the new action but we can iterate on it as
needed. The goal is to clean up abandoned and no-longer-relevant
submissions, not to close Issues that describe active bugs or feedback.
## How did you test this change?
Added `debug-only: 'true'` to this PR so we can run the action and
review the logs before allowing the action to run on schedule. We may
see a large amount of label changes and close actions on the first run
as the action clears out previously ignored stale submissions.
Alternative to #28620.
Instead of emitting lazy references to not-yet-emitted models in the
Flight Server, this fixes the observed issue in
https://github.com/unstubbable/ai-rsc-test/pull/1 by adjusting the lazy
model resolution in the Flight Client to update stale blocked root
models, before assigning them as chunk values. In addition, the element
props are not outlined anymore in the Flight Server to avoid having to
also handle their staleness in blocked elements.
fixes#28595
Make it more clear that these flags aren't used in RN OSS.
- Rename
`packages/shared/forks/ReactFeatureFlags.test-renderer.native.js` to
`packages/shared/forks/ReactFeatureFlags.test-renderer.native-fb.js`
- Remove RN OSS build cases consuming the feature flags since there is
no RN OSS RTR build.
Followups to https://github.com/facebook/react/pull/28680
One of these test don't need to use `console.log`.
The others are specifically testing `console.log` behavior, so I added a
comment.
Don't need to track it separately on the captured value anymore.
Shouldn't be in the types.
I used a getter for the warning instead because Proxies are kind of
heavy weight options for this kind of warning. We typically use getters.
We previously only included the component stack.
Cleaned up the fields in Fizz server that wasn't using consistent hidden
classes in dev vs prod.
Added a prefix to errors serialized from server rendering. It can be a
bit confusing to see where this error came from otherwise since it
didn't come from elsewhere on the client. It's really kind of confusing
with other recoverable errors that happen on the client too.
When an error boundary catches an error during hydration it'll try to
render the error state which will then try to hydrate that state,
causing hydration warnings.
When an error happens inside a Suspense boundary during hydration, we
instead let the boundary catch it and restart a client render from
there. However, when it's in the root we instead let it fail the root
and do the sync recovery pass. This didn't consider that we might hit an
error boundary first so this just skips the error boundary in that case.
We should probably instead let the root do a concurrent client render in
this same pass instead to unify with Suspense boundaries.
## Summary
Fixes a type validation error introduced in newer versions of Node.js
when calling `Module.prototype._compile` in our unit tests. (I tried but
have yet to pinpoint the precise change in Node.js that introduced this
vaildation.)
The specific error that currently occurs when running unit tests with
Node.js v18.16.1:
```
TypeError: The "mod" argument must be an instance of Module. Received an instance of Object
80 |
81 | if (useServer) {
> 82 | originalCompile.apply(this, arguments);
| ^
83 |
84 | const moduleId: string = (url.pathToFileURL(filename).href: any);
85 |
```
This fixes the type validation error by mocking modules using `new
Module()` instead of plain objects.
## How did you test this change?
Ran the unit tests successfully:
```
$ node --version
v18.16.1
$ yarn test
```
## Summary
Makes a few changes to align React Native feature flags for open source
and internal test renderer configurations.
* Enable `enableSchedulingProfiler` for profiling builds.
* Align `ReactFeatureFlags.test-renderer.native.js` (with
`ReactFeatureFlags.native-fb.js`).
* Enable `enableUseMemoCacheHook`.
* Enable `enableFizzExternalRuntime`.
* Disable `alwaysThrottleRetries`.
## How did you test this change?
Ran the following successfully:
```
$ yarn test
$ yarn flow native
$ yarn flow fabric
```
We've rolled out this flag internally on WWW. This PR removed flag
`enableCustomElementPropertySupport`
Test plan:
-- `yarn test`
Co-authored-by: Ricky Hanlon <rickhanlonii@gmail.com>
Remove module pattern function component support (flag only)
> This is a redo of #27742, but only including the flag removal,
excluding further simplifications.
The module pattern
```
function MyComponent() {
return {
render() {
return this.state.foo
}
}
}
```
has been deprecated for approximately 5 years now. This PR removes
support for this pattern.
This breaks internal tests, so must be something in the refactor. Since
it's the top commit let's revert and split into two PRs, one that
removes the flag and one that does the refactor, so we can find the bug.
The module pattern
```
function MyComponent() {
return {
render() {
return this.state.foo
}
}
}
```
has been deprecated for approximately 5 years now. This PR removes
support for this pattern. It also simplifies a number of code paths in
particular related to the concept of `IndeterminateComponent` types.
This PR adds support for `media` option to `ReactDOM.preload()`, which
is needed when images differ between screen sizes (for example mobile vs
desktop)
Removes the digest property from errorInfo passed to onRecoverableError
when handling an error propagated from the server. Previously we warned
in Dev but still provided the digest on the errorInfo object. This
change removes digest from error info but continues to warn if it is
accessed. The reason for retaining the warning is the version with the
warning was not released as stable but we will include this deprecated
removal in our next major so we should communicate this change at
runtime.
We didn't recover after all.
Currently we might log a recoverable error in the recovery pass. E.g.
the SSR server had an error. Then the client component fails to render
which errors again. This ends up double logging.
So if we fail to actually complete a fully successful commit, we ignore
any recoverable errors because we'll get real errors logged.
It's possible that this might cover up some other error that happened at
the same time.
A dependency D from either an instruction or scope is poisoned if there may be a
(non-linear) jump instruction between it and the start of its immediate parent
scope. Poisoned dependencies are added as conditional dependencies to their
parent scope.
(done: reduce false positives in scopes that begin after return/throw) (done:
fix bugs in recording and joining exhaustive conditional deps) (done: flesh out
commit message, clean up PR, add more fixtures)
--- \## Bug details:
Take a simple example: ```js target: { instrA; if (...) { instrB;
break target; } else { instrC; } instrD; // ... } instrE; // ... ```
This diagram shows how we represent this program in the reactive IR. - Blocks
are represented as a list of nodes. - Green nodes show instructions and value
blocks (simplified as a single instruction). - Pink nodes show terminals, which
transfer control to a subtree of nodes. <img width="450" alt="image"
src="https://github.com/facebook/react-forget/assets/34200447/930789f2-39cd-4ea8-b12a-530042807b46">
Prior to this PR, PropagateReactiveScopeDeps was incorrect because it assumed
that a block's instructions are evaluated unconditionally (which is how HIR
basic blocks work). E.g. if a reactive scope enclosed `block 1`, we assume that
`instrA` and `instrD` both will evaluate unconditionally.
This failed to account for `jump` instructions like break, continue, return, and
throw. This may result in invalid hoisting of PropertyLoads (i.e. Forget output
may throw when source does not throw). Note that other terminals (e.g. if and
loops) are not affected as they are self contained subtrees that evaluate
sequentially.
With the changes in this PR, we mark `block 1` as poisoned upon encountering the
`break` instruction. While `block 1` is active and poisoned, it will determine
how visited dependencies are added.
Here, added solid lines show unconditional dependencies, dashed lines show
conditionally accessed dependencies: - dependencies from `instrB, instrC` are
conditional because they are within conditional subtrees - dependencies from
`instrD` are conditional because it is within a poisoned block within its parent
scope.
<img width="450" alt="image"
src="https://github.com/facebook/react-forget/assets/34200447/81980f68-7e65-4bd7-ba94-3f0c26550e5c">
--- Recapping an offline discussion with @josephsavona: this pass would really
benefit from operating on HIR. The minimal work needed for this pass to run on
HIR is to rewrite and reorder `AlignReactiveScopesToBlockScopes` to operate on
HIR.
The following diagram shows what HIR blocks look like for the same code.
Evaluating hoistable PropertyLoad dependencies for a scope enclosing
`instr{A-D}` is much simpler: just evaluate whether the PropertyLoad evaluates
for every path between `bb0` and `bb4`. <img width="250" alt="image"
src="https://github.com/facebook/react-forget/assets/34200447/44b38939-defb-4b29-878d-4445ec6ccc06">
---
conditionals
This change is needed for #2752. To minimize renaming `error.fixture` ->
`fixture` files, I'm reordering this PR to earlier in the stack.
Prior to the fix in #2752, we only expected unconditional accesses within
`depsInCurrentConditional`, which records instructions directly within a
conditional block (not including nested conditional blocks).
RFC: we can either retain break/continue target ids (instead of pruning them in
`buildReactiveFunction`) or re-implement the same logic in `propagateScopeDeps`
(ignore implicit breaks; match unlabeled break / continues to their closest loop
/ while parent terminal).
If we go ahead with this approach, I'll clean up this PR (add relevant types and
comments)
The reanimated babel plugin specifically looks for args to their hooks that are
callbacks, then it workletizes the body of that callback so it can run on the
main thread.
But, forget extracts that callback into a temporary variable and then replaces
the previously inlined callback as an identifier, so that breaks reanimated's
babel plugin. so what happens is some of the previously workletized functions no
longer do after forget runs, which throws a runtime error about a non-worklet
function running on the main thread.
Reanimated expects this: ``` const animatedGProps = useAnimatedProp(function ()
{ ... }) ```
But forget does this: ``` const t0 =function () { ... } const animatedGProps =
useAnimatedProp(t0) ```
With the type definitions, Forget no longer assumes the args to reanimated APIs
escape so Forget does not memoize and they stay as is.
In the next major `findDOMNode` is being removed. This PR removes the
API from the react-dom entrypoints for OSS builds and re-exposes the
implementation as part of internals.
`findDOMNode` is being retained for Meta builds and so all tests that
currently use it will continue to do so by accessing it from internals.
Once the replacement API ships in an upcoming minor any tests that were
using this API incidentally can be updated to use the new API and any
tests asserting `findDOMNode`'s behavior directly can stick around until
we remove it entirely (once Meta has moved away from it)
Stacked on #28606
renderToNodeStream has been deprecated since React 18 with a warning
indicating users should upgrade to renderToPipeableStream. This change
removes renderToNodeStream
Stacked on #28627.
This makes error logging configurable using these
`createRoot`/`hydrateRoot` options:
```
onUncaughtError(error: mixed, errorInfo: {componentStack?: ?string}) => void
onCaughtError(error: mixed, errorInfo: {componentStack?: ?string, errorBoundary?: ?React.Component<any, any>}) => void
onRecoverableError(error: mixed, errorInfo: {digest?: ?string, componentStack?: ?string}) => void
```
We already have the `onRecoverableError` option since before.
Overriding these can be used to implement custom error dialogs (with
access to the `componentStack`).
It can also be used to silence caught errors when testing an error
boundary or if you prefer not getting logs for caught errors that you've
already handled in an error boundary.
I currently expose the error boundary instance but I think we should
probably remove that since it doesn't make sense for non-class error
boundaries and isn't very useful anyway. It's also unclear what it
should do when an error is rethrown from one boundary to another.
Since these are public APIs now we can implement the
ReactFiberErrorDialog forks using these options at the roots of the
builds. So I unforked those files and instead passed a custom option for
the native and www builds.
To do this I had to fork the ReactDOMLegacy file into ReactDOMRootFB
which is a duplication but that will go away as soon as the FB fork is
the only legacy root.
## Overview
This has landed, so we can remove the flag
## Changelog
This change blocks using javascript URLs such as:
```html
<a href="javascript:notfine">p0wned</a>
```
We previously announced dropping support for this via a warning:
> A future version of React will block javascript: URLs as a security
precaution. Use event handlers instead if you can. If you need to
generate unsafe HTML try using dangerouslySetInnerHTML instead.
Stacked on top of #28498 for test fixes.
### Don't Rethrow
When we started React it was 1:1 setState calls a series of renders and
if they error, it errors where the setState was called. Simple. However,
then batching came and the error actually got thrown somewhere else.
With concurrent mode, it's not even possible to get setState itself to
throw anymore.
In fact, all APIs that can rethrow out of React are executed either at
the root of the scheduler or inside a DOM event handler.
If you throw inside a React.startTransition callback that's sync, then
that will bubble out of the startTransition but if you throw inside an
async callback or a useTransition we now need to handle it at the hook
site. So in 19 we need to make all React.startTransition swallow the
error (and report them to reportError).
The only one remaining that can throw is flushSync but it doesn't really
make sense for it to throw at the callsite neither because batching.
Just because something rendered in this flush doesn't mean it was
rendered due to what was just scheduled and doesn't mean that it should
abort any of the remaining code afterwards. setState is fire and forget.
It's send an instruction elsewhere, it's not part of the current
imperative code.
Error boundaries never rethrow. Since you should really always have
error boundaries, most of the time, it wouldn't rethrow anyway.
Rethrowing also actually currently drops errors on the floor since we
can only rethrow the first error, so to avoid that we'd need to call
reportError anyway. This happens in RN events.
The other issue with rethrowing is that it logs an extra console.error.
Since we're not sure that user code will actually log it anywhere we
still log it too just like we do with errors inside error boundaries
which leads all of these to log twice.
The goal of this PR is to never rethrow out of React instead, errors
outside of error boundaries get logged to reportError. Event system
errors too.
### Breaking Changes
The main thing this affects is testing where you want to inspect the
errors thrown. To make it easier to port, if you're inside `act` we
track the error into act in an aggregate error and then rethrow it at
the root of `act`. Unlike before though, if you flush synchronously
inside of act it'll still continue until the end of act before
rethrowing.
I expect most user code breakages would be to migrate from `flushSync`
to `act` if you assert on throwing.
However, in the React repo we also have `internalAct` and the
`waitForThrow` helpers. Since these have to use public production
implementations we track these using the global onerror or process
uncaughtException. Unlike regular act, includes both event handler
errors and onRecoverableError by default too. Not just render/commit
errors. So I had to account for that in our tests.
We restore logging an extra log for uncaught errors after the main log
with the component stack in it. We use `console.warn`. This is not yet
ignorable if you preventDefault to the main error event. To avoid
confusion if you don't end up logging the error to console I just added
`An error occurred`.
### Polyfill
All browsers we support really supports `reportError` but not all test
and server environments do, so I implemented a polyfill for browser and
node in `shared/reportGlobalError`. I don't love that this is included
in all builds and gets duplicated into isomorphic even though it's not
actually needed in production. Maybe in the future we can require a
polyfill for this.
### Follow Ups
In a follow up, I'll make caught vs uncaught error handling be
configurable too.
---------
Co-authored-by: Ricky Hanlon <rickhanlonii@gmail.com>
If false, this ignores text comparison checks during hydration at the
risk of privacy safety.
Since React 18 we recreate the DOM starting from the nearest Suspense
boundary if any of the text content mismatches. This ensures that if we
have nodes that otherwise line up correctly such as if they're the same
type of Component but in a different order, then we don't accidentally
transfer state or attributes to the wrong one.
If we didn't do this e.g. attributes like image src might not line up
with the text. E.g. you might show the wrong profile picture with the
wrong name. However, the main reason we do this is because it's a
security/privacy concern if state from the original node can transfer to
the other one. For example if you start typing into a text field to
reply to a story but then it turns out that the hydration was in a
different order, you might submit that text into a different story than
you intended. Similarly, if you've already clicked an item and that gets
replayed using Action replaying or is synchronously force hydrated -
that click might end up applying to a different item in the list than
you intended. E.g. liking the wrong photo.
Unfortunately a common case where this happens is when Google Translate
is applied to a page. It'll always cause mismatches and recreate the
tree. Most of the time this wouldn't be visible to users because it'd
just recreate to the same thing and then translate again. It can affect
metrics that trace when this hydration happened though.
Meta can use this flag to decide if they favor this perf metric over the
risk to user privacy.
This is similar to the old enableClientRenderFallbackOnTextMismatch flag
except this flag doesn't patch up the text when there's a mismatch.
Because we don't have the patching anymore. The assumption is that it is
safe to ignore the safety concern because we assume it's a match and
therefore favoring not patching it will lead to better perf.
Stacked on #28502.
This builds on the mechanism in #28502 by adding a diff of everything
we've collected so far to the thrown error or logged error.
This isn't actually a longest common subsequence diff. This means that
there are certain cases that can appear confusing such as a node being
added/removed when it really would've appeared later in the list. In
fact once a node mismatches, we abort rendering so we don't have the
context of what would've been rendered. It's not quite right to use the
result of the recovery render because it can use client-only code paths
using useSyncExternalStore which would yield false differences. That's
why diffing the HTML isn't quite right.
I also present abstract components in the stack, these are presented
with the client props and no diff since we don't have the props that
were on the server. The lack of difference might be confusing but it's
useful for context.
The main thing that's data new here is that we're adding some siblings
and props for context.
Examples in the [snapshot
commit](e14532fd8d).
Stacked on #28476.
We used to `console.error` for every mismatch we found, up until the
error we threw for the hydration mismatch.
This changes it so that we build up a set of diffs up until we either
throw or complete hydrating the root/suspense boundary. If we throw, we
append the diff to the error message which gets passed to
onRecoverableError (which by default is also logged to console). If we
complete, we append it to a `console.error`.
Since we early abort when something throws, it effectively means that we
can only collect multiple diffs if there were preceding non-throwing
mismatches - i.e. only properties mismatched but tag name matched.
There can still be multiple logs if multiple siblings Suspense
boundaries all error hydrating but then they're separate errors
entirely.
We still log an extra line about something erroring but I think the goal
should be that it leads to a single recoverable or console.error.
This doesn't yet actually print the diff as part of this message. That's
in a follow up PR.
Stacked on #28458.
This doesn't actually really change the messages yet, it's just a
refactor.
Hydration warnings can be presented either as HTML or React JSX format.
If presented as HTML it makes more sense to make that a DOM specific
concept, however, I think it's actually better to present it in terms of
React JSX.
Most of the time the errors aren't going to be something messing with
them at the HTML/HTTP layer. It's because the JS code does something
different. Most of the time you're working in just React. People don't
necessarily even know what the HTML form of it looks like. So this takes
the approach that the warnings are presented in React JSX in their rich
object form.
Therefore, I'm moving the approach to yield diff data to the reconciler
but it's the reconciler that's actually printing all the warnings.
Based on
- https://github.com/facebook/react/pull/28497
- https://github.com/facebook/react/pull/28419
Reusing the disableLegacyMode flag, we set ReactTestRenderer to always
render with concurrent root where legacy APIs are no longer available.
If disableLegacyMode is false, we continue to allow the
unstable_isConcurrent option determine the root type.
Also checking a global `IS_REACT_NATIVE_TEST_ENVIRONMENT` so we can
maintain the existing behavior for RN until we remove legacy root
support there.
Based on
- https://github.com/facebook/react/pull/28419
## Summary
The shallow renderer was extracted from the repo years ago and published
by enzyme: https://github.com/enzymejs/react-shallow-renderer
We no longer need to reexport under the react-test-renderer namespace.
People can import `react-shallow-renderer` as needed
## How did you test this change?
- Observe shallow.js in react-test-renderer package from standard build
- Run build with changes on this branch
- Observe no more shallow.js export in build output
## Summary
Based on
- https://github.com/facebook/react/pull/27903
This PR
- Silence warning in React tests
- Turn on flag
We want to finish cleaning up internal RTR usage, but let's prioritize
the deprecation process. We do this by silencing the internal warning
for now.
## How did you test this change?
`yarn build`
`yarn test ReactHooksInspectionIntegration -b`
While Meta is still using legacy mode and we can't remove completely,
Meta is not using legacy hydration so we should be able to remove that.
This is just the first step. Once removed, we can vastly simplify the
DOMConfig for hydration.
This will have to be rebased when tests are upgraded.
## Overview
The error messages that say:
> ReactDOM.hydrate is no longer supported in React 18
Don't make sense in the React 19 release. Instead, they should say:
> ReactDOM.hydrate was removed in React 19.
For legacy mode, they should say:
> ReactDOM.hydrate has not been supported since React 18.
Our current validation fails to detect some invalid cases of mutable ranges —
namely, ranges that are fully or partially uninitialized, with start or
start+end still set to zero.
This PR fixes these cases, starting by validating that the ranges for _all_
reactive scopes are valid: start >= 1, and end <= (last instr id + 1). This
exposed the invalid cases, which are also fixed here:
* During AnalyzeFunctions, we need to reset identifier ranges and scopes when
exiting an inner function. This has to happen *after* the effects have been
translated to the function deps/context operands, in order for
InferRefenceEffects to continue working on the outer function. Previously I did
this at the start of InferReactiveScopeVariables, but that's insufficient bc the
incorrect ranges could also influence InferMutableRanges. AnalyzeFunctions is
the point at which we compute the ranges for identifiers in the inner function,
so it's the most ideal place to clean those up so they don't influence the outer
function.
* In InferMutableLifetimes, we need to ensure that context variable identifiers
end up with a mutable range starting where they are declared, and ending with
their last assignment. We now track declarations and extend their mutable range
to account for each reassignment.
This bumps the canary versions to v19 to communicate that the next
release will be a major. Once this lands, we can start merging breaking
changes into `main`.
## Summary
After realizing that this feature flag is entangled with
`alwaysThrottleRetries`, we're going to undo
https://github.com/facebook/react/pull/28550
## How did you test this change?
```
$ yarn test
$ yarn flow dom-browser
$ yarn flow dom-fb
$ yarn flow fabric
```
Fixes the repro added in 947832009997bf9149e88e583c46cc39f6a6136c - previously
when computing mutable ranges of phis, we didn't check that all operands had
been visited. This meant that a backedge could allow a phi's mutable range to
start at 0. Then in PropagateScopeDeps, we might see reject dependencies of a
scope since they appeared to start after a scope — only because the scope's
start was incorrectly too early.
The fix here is to initially set phi.id mutable ranges based on only on operands
that are already visited. Then, during/after the fixpoint iteration of
InferMutableRanges, we start account for all operands since we know they've been
visited at least once and have a real range.
# Overview
Adds a test to show the combination of the new throttling behavior and
not pre-rendering siblings results in pushing out content that could
have rendered much faster.
- Without the new throttling, the sibling content would render in 30ms.
- Without removing pre-rendering, the sibling content would render in
0ms.
- With both, the sibling content takes 600ms.
## Example
https://github.com/facebook/react/assets/2440089/abd62dc4-93f9-4b7b-a5aa-b795827c1a3a
## Overview
Adds a test to show the cause of an infinite loop in Relay related to
[these effects in
Relay](448aa67d2a/packages/react-relay/relay-hooks/useLazyLoadQueryNode.js (L77-L104))
and `useModernStrictMode`. The bug is related to effect behavior when
committing trees that re-suspend after initial mount.
With `useModernStrictEffect`, when you:
- initial mount
- update
- suspend (to fallbacks)
- resolve
- re-commit
We fire strict effects during the second mount, like it's a new tree.
This creates weird cases, where if there was an update while we
suspended, we'll first fire only the effects that changed dependencies,
and then fire strict effects.
Creating a test to demonstrate the behavior to see if it's a bug.
While investigating https://github.com/facebook/react/issues/28285 I
found a possible bug in handling Suspense and mismatches. As the tests
show, if the first sibling in a boundary suspends, and the second has a
mismatch, we will NOT show a fallback. If the first sibling is a
mismatch, and the second sibling suspends, we WILL show a fallback.
[Here's a stackbliz showing the behavior on
Canary](https://stackblitz.com/edit/stackblitz-starters-bh3snf?file=src%2Fstyle.css,public%2Findex.html,src%2Findex.tsx).
This breakage was introduced by:
https://github.com/facebook/react/pull/26380. Before this PR, we would
not show a fallback in either case. That PR makes it so that we don't
pre-render siblings of suspended trees, so presumably, whatever
detection we had to avoid fallbacks on mismatches, requires knowing
there's a mismatch in the tree when we suspend.
Updates InferReactiveScopeVariables to first prune scopes attached during
AnalyzeFunctions. This ensures that after this pass the only scopes that exist
on identifiers in the outer program are those that the pass explicitly inferred,
and not accidentally leftover.
We share identifiers between outer functions and inner function expressions,
which means that scopes inferred during AnalyzeFunctions can be retained on
Identifiers in the outer function. If InferReactiveScopeVariables doesn't happen
to visit an identifier we currently retain that scope information and use it
when constructing scopes, even if there doesn't technically need to be a scope
for that value.
Fixed in the next PR.
What happens here is that the phi node for `i` has its mutable range set to
start at 0, because it has a back edge and we haven't initialized the mutable
ranges of all its operands yet when we iterate the operands and set range.start
= min(start of operand starts).
Then the corresponding scope has its range set to start at 0 too. When
PropagateScopeDeps runs it sees that `b` is from instruction 1, which is after
the start of the scope (0), so it thinks `b` isn't a valid dependency.
The fix is in InferMutableRanges, where we need to make sure that phis ignore
their operand's ranges until those ranges are initialized.
Correct eslint-plugin-react-compiler dependencies
- The eslint plugin doesn't actually depend on the babel plugin as it compiles
in the dependencies. - `zod` and `zod-validation-error` were missing, but
required to run the plugin. - Update to the `hermes-parser` dependency just to
keep it updated.
Our logic to detect hoisting relies on Babel's `isReferencedIdentifier()` to
determine whether a reference to an identifier is a reference or a declaration.
The idea is that we want to find references to variables that may be hoistable,
before the declaration — the definition of hoisting. But due to the bug in
isReferencedIdentifier, we skipped over reassignments of hoisted variables. The
hack here checks if an identifier is a direct child of an AssignmentExpression,
ensuring we visit reassignments.
Adds examples for closures that reassign hoisted let bindings. We currently
compile these as context variables without hoisting, so we hit an invariant in
InferReferenceEffects when the variable is referenced before being declared.
## Overview
_Depends on https://github.com/facebook/react/pull/28514_
This PR adds a new React hook called `useActionState` to replace and
improve the ReactDOM `useFormState` hook.
## Motivation
This hook intends to fix some of the confusion and limitations of the
`useFormState` hook.
The `useFormState` hook is only exported from the `ReactDOM` package and
implies that it is used only for the state of `<form>` actions, similar
to `useFormStatus` (which is only for `<form>` element status). This
leads to understandable confusion about why `useFormState` does not
provide a `pending` state value like `useFormStatus` does.
The key insight is that the `useFormState` hook does not actually return
the state of any particular form at all. Instead, it returns the state
of the _action_ passed to the hook, wrapping it and returning a
trackable action to add to a form, and returning the last returned value
of the action given. In fact, `useFormState` doesn't need to be used in
a `<form>` at all.
Thus, adding a `pending` value to `useFormState` as-is would thus be
confusing because it would only return the pending state of the _action_
given, not the `<form>` the action is passed to. Even if we wanted to
tie them together, the returned `action` can be passed to multiple
forms, creating confusing and conflicting pending states during multiple
form submissions.
Additionally, since the action is not related to any particular
`<form>`, the hook can be used in any renderer - not only `react-dom`.
For example, React Native could use the hook to wrap an action, pass it
to a component that will unwrap it, and return the form result state and
pending state. It's renderer agnostic.
To fix these issues, this PR:
- Renames `useFormState` to `useActionState`
- Adds a `pending` state to the returned tuple
- Moves the hook to the `'react'` package
## Reference
The `useFormState` hook allows you to track the pending state and return
value of a function (called an "action"). The function passed can be a
plain JavaScript client function, or a bound server action to a
reference on the server. It accepts an optional `initialState` value
used for the initial render, and an optional `permalink` argument for
renderer specific pre-hydration handling (such as a URL to support
progressive hydration in `react-dom`).
Type:
```ts
function useActionState<State>(
action: (state: Awaited<State>) => State | Promise<State>,
initialState: Awaited<State>,
permalink?: string,
): [state: Awaited<State>, dispatch: () => void, boolean];
```
The hook returns a tuple with:
- `state`: the last state the action returned
- `dispatch`: the method to call to dispatch the wrapped action
- `pending`: the pending state of the action and any state updates
contained
Notably, state updates inside of the action dispatched are wrapped in a
transition to keep the page responsive while the action is completing
and the UI is updated based on the result.
## Usage
The `useActionState` hook can be used similar to `useFormState`:
```js
import { useActionState } from "react"; // not react-dom
function Form({ formAction }) {
const [state, action, isPending] = useActionState(formAction);
return (
<form action={action}>
<input type="email" name="email" disabled={isPending} />
<button type="submit" disabled={isPending}>
Submit
</button>
{state.errorMessage && <p>{state.errorMessage}</p>}
</form>
);
}
```
But it doesn't need to be used with a `<form/>` (neither did
`useFormState`, hence the confusion):
```js
import { useActionState, useRef } from "react";
function Form({ someAction }) {
const ref = useRef(null);
const [state, action, isPending] = useActionState(someAction);
async function handleSubmit() {
// See caveats below
await action({ email: ref.current.value });
}
return (
<div>
<input ref={ref} type="email" name="email" disabled={isPending} />
<button onClick={handleSubmit} disabled={isPending}>
Submit
</button>
{state.errorMessage && <p>{state.errorMessage}</p>}
</div>
);
}
```
## Benefits
One of the benefits of using this hook is the automatic tracking of the
return value and pending states of the wrapped function. For example,
the above example could be accomplished via:
```js
import { useActionState, useRef } from "react";
function Form({ someAction }) {
const ref = useRef(null);
const [state, setState] = useState(null);
const [isPending, setIsPending] = useTransition();
function handleSubmit() {
startTransition(async () => {
const response = await someAction({ email: ref.current.value });
setState(response);
});
}
return (
<div>
<input ref={ref} type="email" name="email" disabled={isPending} />
<button onClick={handleSubmit} disabled={isPending}>
Submit
</button>
{state.errorMessage && <p>{state.errorMessage}</p>}
</div>
);
}
```
However, this hook adds more benefits when used with render specific
elements like react-dom `<form>` elements and Server Action. With
`<form>` elements, React will automatically support replay actions on
the form if it is submitted before hydration has completed, providing a
form of partial progressive enhancement: enhancement for when javascript
is enabled but not ready.
Additionally, with the `permalink` argument and Server Actions,
frameworks can provide full progressive enhancement support, submitting
the form to the URL provided along with the FormData from the form. On
submission, the Server Action will be called during the MPA navigation,
similar to any raw HTML app, server rendered, and the result returned to
the client without any JavaScript on the client.
## Caveats
There are a few Caveats to this new hook:
**Additional state update**: Since we cannot know whether you use the
pending state value returned by the hook, the hook will always set the
`isPending` state at the beginning of the first chained action,
resulting in an additional state update similar to `useTransition`. In
the future a type-aware compiler could optimize this for when the
pending state is not accessed.
**Pending state is for the action, not the handler**: The difference is
subtle but important, the pending state begins when the return action is
dispatched and will revert back after all actions and transitions have
settled. The mechanism for this under the hook is the same as
useOptimisitic.
Concretely, what this means is that the pending state of
`useActionState` will not represent any actions or sync work performed
before dispatching the action returned by `useActionState`. Hopefully
this is obvious based on the name and shape of the API, but there may be
some temporary confusion.
As an example, let's take the above example and await another action
inside of it:
```js
import { useActionState, useRef } from "react";
function Form({ someAction, someOtherAction }) {
const ref = useRef(null);
const [state, action, isPending] = useActionState(someAction);
async function handleSubmit() {
await someOtherAction();
// The pending state does not start until this call.
await action({ email: ref.current.value });
}
return (
<div>
<input ref={ref} type="email" name="email" disabled={isPending} />
<button onClick={handleSubmit} disabled={isPending}>
Submit
</button>
{state.errorMessage && <p>{state.errorMessage}</p>}
</div>
);
}
```
Since the pending state is related to the action, and not the handler or
form it's attached to, the pending state only changes when the action is
dispatched. To solve, there are two options.
First (recommended): place the other function call inside of the action
passed to `useActionState`:
```js
import { useActionState, useRef } from "react";
function Form({ someAction, someOtherAction }) {
const ref = useRef(null);
const [state, action, isPending] = useActionState(async (data) => {
// Pending state is true already.
await someOtherAction();
return someAction(data);
});
async function handleSubmit() {
// The pending state starts at this call.
await action({ email: ref.current.value });
}
return (
<div>
<input ref={ref} type="email" name="email" disabled={isPending} />
<button onClick={handleSubmit} disabled={isPending}>
Submit
</button>
{state.errorMessage && <p>{state.errorMessage}</p>}
</div>
);
}
```
For greater control, you can also wrap both in a transition and use the
`isPending` state of the transition:
```js
import { useActionState, useTransition, useRef } from "react";
function Form({ someAction, someOtherAction }) {
const ref = useRef(null);
// isPending is used from the transition wrapping both action calls.
const [isPending, startTransition] = useTransition();
// isPending not used from the individual action.
const [state, action] = useActionState(someAction);
async function handleSubmit() {
startTransition(async () => {
// The transition pending state has begun.
await someOtherAction();
await action({ email: ref.current.value });
});
}
return (
<div>
<input ref={ref} type="email" name="email" disabled={isPending} />
<button onClick={handleSubmit} disabled={isPending}>
Submit
</button>
{state.errorMessage && <p>{state.errorMessage}</p>}
</div>
);
}
```
A similar technique using `useOptimistic` is preferred over using
`useTransition` directly, and is left as an exercise to the reader.
## Thanks
Thanks to @ryanflorence @mjackson @wesbos
(https://github.com/facebook/react/issues/27980#issuecomment-1960685940)
and [Allan
Lasser](https://allanlasser.com/posts/2024-01-26-avoid-using-reacts-useformstatus)
for their feedback and suggestions on `useFormStatus` hook.
The `__NEXT_MAJOR__` value in the RN flags doesn't make sense because:
a) The flags are for the next RN major, since it only impacts the
renderers
b) The flags are off, so they're not currently in the next major, they
need enabled
c) the flag script didn't support it
This PR adds two aliases to the RN file:
- `__TODO_NEXT_RN_MAJOR__`: flags that need enabled before the next RN
major.
- `__NEXT_RN_MAJOR__`: flags that have been enabled since the last RN
major.
These values will need to be manually kept up to date when we cut a RN
version, but once RN switches to the canary build and aligns all the
flags, this entire file can be deleted.
## Script screen
Notably, I added a TODO value and a legend that prints at the end of the
script:
<img width="1078" alt="Screenshot 2024-03-18 at 8 11 27 PM"
src="https://github.com/facebook/react/assets/2440089/14da9066-f77d-437f-8188-830a31a843c5">
Updates the RN flag flow types to work like www does, so we can use the
`.native-fb-dynamic.js` file as the type/shim for the dynamically
imported file.
`let` bindings of context variables are lowered to a DeclareContext +
StoreContext, which breaks codegen for `for` loops which expect that all
statements of the init block will lower to variable declarations. The two
instructions produce a variable declaration and a reassignment.
If we have a switch with only a default case, then that code will be executed
unconditionally. PropagateScopeDeps can take advantage of this to record
dependencies in these cases as unconditional, which avoids the issue seen in the
previous PR.
This a follow up to #28564. It's alternative to #28609 which takes
#28610 into account.
It used to be possible to return JSX from an action with
`useActionState`.
```js
async function action(errors, payload) {
"use server";
try {
...
} catch (x) {
return <div>Error message</div>;
}
}
```
```js
const [errors, formAction] = useActionState(action);
return <div>{errors}</div>;
```
Returning JSX from an action is itself not anything problematic. It's
that it also has to return the previous state to the action reducer
again that's the problem. When this happens we accidentally could
serialize an Element back to the server.
I fixed this in #28564 so it's now blocked if you don't have a temporary
reference set.
However, you can't have that for the progressive enhancement case. The
reply is eagerly encoded as part of the SSR render. Typically you
wouldn't have these in the initial state so the common case is that they
show up after the first POST back that yields an error and it's only in
the no-JS case where this happens so it's hard to discover.
As noted in #28609 there's a security implication with allowing elements
to be sent across this kind of payload, so we can't just make it work.
When an error happens during SSR our general policy is to try to recover
on the client instead. After all, SSR is mainly a perf optimization in
React terms and it's not primarily intended for a no JS solution.
This PR takes the approach that if we fail to generate the progressive
enhancement payload. I.e. if the serialization of previous state /
closures throw. Then we fallback to the replaying semantics just client
actions instead which will succeed.
The effect of this is that this pattern mostly just works:
- First render in the typical case doesn't have any JSX in it so it just
renders a progressive enhanced form.
- If JS fails to hydrate or you click early we do a form POST. If that
hits an error and it tries to render it using JSX, then the new page
will render successfully - however this time with a Replaying form
instead.
- If you try to submit the form again it'll have to be using JS.
Meaning if you use JSX as the error return value of form state and you
make a first attempt that fails, then no JS won't work because either
the first or second attempt has to hydrate.
We have ideas for potentially optimizing away serializing unused
arguments like if you don't actually use previous state which would also
solve it but it wouldn't cover all cases such as if it was deeply nested
in complex state.
Another approach that I considered was to poison the prev state if you
passed an element back but let it through to the action but if you try
to render the poisoned value, it wouldn't work. The downside of this is
when to error. Because in the progressive enhancement case it wouldn't
error early but when you actually try to invoke it at which point it
would be too late to fallback to client replaying. It would probably
have to always error even on the client which is unfortunate since this
mostly just works as long as it hydrates.
---
Thanks to @josephsavona for finding this bug. This is another example of why we
really want hir-everywhere.
Forget output currently nullthrows because we believe `obj.a` is run
unconditionally in source (missing the break/returns out of this scope)
I haven't debugged to understand exactly why this pattern fails, but there are a
few instances of this internally. It's especially weird because
```javascript
// @enableAssumeHooksFollowRulesOfReact
@enableTransitivelyFreezeFunctionExpressions
function Component(props) {
const [_state, setState] = useState();
const a = () => {
return b();
};
const b = () => {
return (
<>
<div onClick={() => onClick(true)} />
<div onClick={() => onClick(false)} /> // <---- only repros if there's a second
call!
</>
);
};
const onClick = (value) => {
setState(value);
};
return <div>{a()}</div>;
}
```
Here, if `b()` only had one nested function expression that called `onClick` it
would work. Also, if we disable `@enableTransitivelyFreezeFunctionExpressions`
then it works.
But the combination of multiple calls plus that mode causes "context variables
are always mutable". I'm guessing we're freezing `onClick` twice and the second
time reports an error since it calls `setState`.
We don't have a `DestructureContext` equivalent of `StoreContext`, so variables
that are declared via destructuring and later reassigned trigger the invariant
that all mentions of a variable must be consistently local or context. The next
PR adds a todo for this case.
We inadvertently think the type annotation on the function expression param is
an identifier and create a LoadLocal for it, which fails. This happens to trip
up on the InferReferenceEffects initialization check, which we had assumed would
only fire for invalid hoisting cases (hence the specific error message).
When PruneMaybeThrows removes maybe-throw terminals, it's possible that the
block in question reassigned a value s.t. it appears as a later phi operand.
That phi has to be rewritten to reflect the updated predecessor block.
Here we track these rewrites (transitively) and rewrite phi operands
accordingly.
As mentioned in #28609 there's a potential security risk if you allow a
passed value to the server to spoof Elements because it allows a hacker
to POST cross origin. This is only an issue if your framework allows
this which it shouldn't but it seems like we should provide an extra
layer of security here.
```js
function action(errors, payload) {
try {
...
} catch (x) {
return [newError].concat(errors);
}
}
```
```js
const [errors, formAction] = useActionState(action);
return <div>{errors}</div>;
```
This would allow you to construct a payload where the previous "errors"
set includes something like `<script src="danger.js" />`.
We could block only elements from being received but it could
potentially be a risk with creating other React types like Context too.
We use symbols as a way to securely brand these.
Most JS don't use this kind of branding with symbols like we do. They're
generally properties which we don't support anyway. However in theory
someone else could be using them like we do. So in an abundance of
carefulness I just ban all symbols from being passed (except by
temporary reference) - not just ours.
This means that the format isn't fully symmetric even beyond just React
Nodes.
#28611 allows code that includes symbols/elements to continue working
but may have to bail out to replaying instead of no JS sometimes.
However, you still can't access the symbols inside the server - they're
by reference only.
Since it was first implemented renderToStaticNodeStream never correctly
set the renderer state to mark the output as static markup which means
it was functionally the same as renderToNodeStream. This change fixes
this oversight. While we are removing renderToNodeStream in a future
version we never did deprecate the static version of this API because it
has no immediate analog in the modern APIs.
- Make all test cases in ReactLazy use RTR with concurrent root
- Except, two cases with "legacy mode" specified in description. These
are moved to a separate description block where the disableLegacyMode
flag is turned off to allow RTR to use legacy root after
https://github.com/facebook/react/pull/28498
Found when running the compiler on a large swath of internal code.
PruneMaybeThrows rewrites terminals, but the logic to update subsequent phis was
incorrectly dropping phis rather than rewriting them. Fixed in the next PR.
---
Reusing optionalMemberExpression nodes recently led to a bug when compiling
Forget playground.
```js
// the two a?.b's here should be different nodes!
if (a?.b !== $[0]) {
// ...
$[0] = a?.b;
}
```
Forget playground uses `babel-plugin-react-forget` and `next/babel`. Reusing the
same node in two positions in the AST lead to invalid mutations:
- the first `a?.b` is visited and transpiled to `a === void 0 ? ...`, which (1)
inserts nodes between the original node and its parent and (2) mutates `a?.b` in
place to a non-optional call
- the second `a?.b` in source gets updated to `a.b` and does not get visited
again
```js
// Source in `EditorImpl.tsx`
compilerOutput.kind === "err" ? compilerOutput.error.details : []
// Forget transformed:
if ($[2] !== compilerOutput.kind || $[3] !== compilerOutput.error?.details) {
t4 = compilerOutput.kind === "err" ? compilerOutput.error.details : [];
$[2] = compilerOutput.kind;
// this is good!
$[3] = compilerOutput.error?.details;
$[4] = t4;
} else {
t4 = $[4];
}
// After next/babel
if ($[2] !== compilerOutput.kind || $[3] !== ((_compilerOutput$error =
compilerOutput.error) === null || _compilerOutput$error === void 0 ? void 0 :
_compilerOutput$error.details)) {
t4 = compilerOutput.kind === "err" ? compilerOutput.error.details : [];
$[2] = compilerOutput.kind;
// Oh no!!
$[3] = _compilerOutput$error.details;
$[4] = t4;
} else {
t4 = $[4];
}
```
---
This should make it easier to grep through error diagnostics to understand state
of the codebase:
- no matching dependences -> likely that source is ignoring eslint failures
- differences in ref.current access -> non-backwards compatible refs
- subpath -> should be fixable in the compiler (unless source is ignore eslint
failures)
---
Previously (in #2663), we check that inferred dependencies exactly match source
dependencies. As @validatePreserveExistingMemoizationGuarantees checks that
Forget output does not invalidate *any more* than source, we now allow more
specific inferred dependencies when neither the inferred dep or matching source
dependency reads into a ref (based on `.current` access).
See added comments for more details
If a global error event is dispatched during a test, Jest reports that
test as a failure.
Our `@gate` pragma feature should account for this — if the gate
condition is false, and the global error event is dispatched, then the
test should be reported as a success.
The solution is to install an error event handler right before invoking
the test function. Because we install our own handler, Jest will not
report the test as a failure if a global error event is dispatched; it's
conceptually as if we wrapped the whole test event in a try-catch.
I need to do more debugging to figure out exactly why the example earlier fails
— but whatever it is, it's clearly a matter of the fbt plugin relying on some
specifics of source locations.
Here we just detect multiple instances of `<fbt:enum>` within a given `<fbt>`
tag and throw a todo.
<img width="553" alt="Screenshot 2024-03-19 at 4 41 15 PM"
src="https://github.com/facebook/react-forget/assets/6425824/e87ee704-6c67-4e10-824b-71e97e7e19f5">
Slightly improves source locations for JSX elements so that the opening and
closing tag have distinct locations that match up with source. The identifier
itself within the closing tag still has the wrong location, but at least this is
an improvement.
Doesn't fix the fbt thing but it was worth a try.
Fbt enums appear to rely on source locations and something that we're doing
(maybe destructuring?) isn't preserving locations such that the fbt plugin
breaks.
Bumps [es5-ext](https://github.com/medikoo/es5-ext) from 0.10.53 to
0.10.63.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a
href="https://github.com/medikoo/es5-ext/releases">es5-ext's
releases</a>.</em></p>
<blockquote>
<h2>0.10.63 (2024-02-23)</h2>
<h3>Bug Fixes</h3>
<ul>
<li>Do not rely on problematic regex (<a
href="3551cdd7b2">3551cdd</a>),
addresses <a
href="https://redirect.github.com/medikoo/es5-ext/issues/201">#201</a></li>
<li>Support ES2015+ function definitions in
<code>function#toStringTokens()</code> (<a
href="a52e957366">a52e957</a>),
addresses <a
href="https://redirect.github.com/medikoo/es5-ext/issues/021">#021</a></li>
<li>Ensure postinstall script does not crash on Windows, fixes <a
href="https://redirect.github.com/medikoo/es5-ext/issues/181">#181</a>
(<a
href="bf8ed799d5">bf8ed79</a>)</li>
</ul>
<h3>Maintenance Improvements</h3>
<ul>
<li>Simplify the manifest message (<a
href="7855319f41">7855319</a>)</li>
</ul>
<hr />
<p><a
href="https://github.com/medikoo/es5-ext/compare/v0.10.62...v0.10.63">Comparison
since last release</a></p>
<h2>0.10.62 (2022-08-02)</h2>
<h3>Maintenance Improvements</h3>
<ul>
<li><strong>Manifest improvements:</strong>
<ul>
<li>(<a
href="https://redirect.github.com/medikoo/es5-ext/issues/190">#190</a>)
(<a
href="b8dc53fa43">b8dc53f</a>)</li>
<li>(<a
href="c51d552c03">c51d552</a>)</li>
</ul>
</li>
</ul>
<hr />
<p><a
href="https://github.com/medikoo/es5-ext/compare/v0.10.61...v0.10.62">Comparison
since last release</a></p>
<h2>0.10.61 (2022-04-20)</h2>
<h3>Bug Fixes</h3>
<ul>
<li>Ensure postinstall script does not error (<a
href="a0be4fdacd">a0be4fd</a>)</li>
</ul>
<h3>Maintenance Improvements</h3>
<ul>
<li>Bump dependencies (<a
href="d7e0a612b7">d7e0a61</a>)</li>
</ul>
<hr />
<p><a
href="https://github.com/medikoo/es5-ext/compare/v0.10.60...v0.10.61">Comparison
since last release</a></p>
<h2>0.10.60 (2022-04-07)</h2>
<h3>Maintenance Improvements</h3>
<ul>
<li>Improve <code>postinstall</code> script configuration (<a
href="ab6b121f0c">ab6b121</a>)</li>
</ul>
<hr />
<p><a
href="https://github.com/medikoo/es5-ext/compare/v0.10.59...v0.10.60">Comparison
since last release</a></p>
<h2>0.10.59 (2022-03-17)</h2>
<h3>Maintenance Improvements</h3>
<ul>
<li>Improve manifest wording (<a
href="https://redirect.github.com/medikoo/es5-ext/issues/122">#122</a>)
(<a
href="eb7ae59966">eb7ae59</a>)</li>
<li>Update data in manifest (<a
href="3d2935ac6f">3d2935a</a>)</li>
</ul>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/medikoo/es5-ext/blob/main/CHANGELOG.md">es5-ext's
changelog</a>.</em></p>
<blockquote>
<h3><a
href="https://github.com/medikoo/es5-ext/compare/v0.10.62...v0.10.63">0.10.63</a>
(2024-02-23)</h3>
<h3>Bug Fixes</h3>
<ul>
<li>Do not rely on problematic regex (<a
href="3551cdd7b2">3551cdd</a>),
addresses <a
href="https://redirect.github.com/medikoo/es5-ext/issues/201">#201</a></li>
<li>Support ES2015+ function definitions in
<code>function#toStringTokens()</code> (<a
href="a52e957366">a52e957</a>),
addresses <a
href="https://redirect.github.com/medikoo/es5-ext/issues/021">#021</a></li>
<li>Ensure postinstall script does not crash on Windows, fixes <a
href="https://redirect.github.com/medikoo/es5-ext/issues/181">#181</a>
(<a
href="bf8ed799d5">bf8ed79</a>)</li>
</ul>
<h3>Maintenance Improvements</h3>
<ul>
<li>Simplify the manifest message (<a
href="7855319f41">7855319</a>)</li>
</ul>
<h3><a
href="https://github.com/medikoo/es5-ext/compare/v0.10.61...v0.10.62">0.10.62</a>
(2022-08-02)</h3>
<h3>Maintenance Improvements</h3>
<ul>
<li><strong>Manifest improvements:</strong>
<ul>
<li>(<a
href="https://redirect.github.com/medikoo/es5-ext/issues/190">#190</a>)
(<a
href="b8dc53fa43">b8dc53f</a>)</li>
<li>(<a
href="c51d552c03">c51d552</a>)</li>
</ul>
</li>
</ul>
<h3><a
href="https://github.com/medikoo/es5-ext/compare/v0.10.60...v0.10.61">0.10.61</a>
(2022-04-20)</h3>
<h3>Bug Fixes</h3>
<ul>
<li>Ensure postinstall script does not error (<a
href="a0be4fdacd">a0be4fd</a>)</li>
</ul>
<h3>Maintenance Improvements</h3>
<ul>
<li>Bump dependencies (<a
href="d7e0a612b7">d7e0a61</a>)</li>
</ul>
<h3><a
href="https://github.com/medikoo/es5-ext/compare/v0.10.59...v0.10.60">0.10.60</a>
(2022-04-07)</h3>
<h3>Maintenance Improvements</h3>
<ul>
<li>Improve <code>postinstall</code> script configuration (<a
href="ab6b121f0c">ab6b121</a>)</li>
</ul>
<h3><a
href="https://github.com/medikoo/es5-ext/compare/v0.10.58...v0.10.59">0.10.59</a>
(2022-03-17)</h3>
<h3>Maintenance Improvements</h3>
<ul>
<li>Improve manifest wording (<a
href="https://redirect.github.com/medikoo/es5-ext/issues/122">#122</a>)
(<a
href="eb7ae59966">eb7ae59</a>)</li>
<li>Update data in manifest (<a
href="3d2935ac6f">3d2935a</a>)</li>
</ul>
<h3><a
href="https://github.com/medikoo/es5-ext/compare/v0.10.57...v0.10.58">0.10.58</a>
(2022-03-11)</h3>
<h3>Maintenance Improvements</h3>
<ul>
<li>Improve "call for peace" manifest (<a
href="3beace4b3d">3beace4</a>)</li>
</ul>
<h3><a
href="https://github.com/medikoo/es5-ext/compare/v0.10.56...v0.10.57">0.10.57</a>
(2022-03-08)</h3>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="de4e03c477"><code>de4e03c</code></a>
chore: Release v0.10.63</li>
<li><a
href="3fd53b755e"><code>3fd53b7</code></a>
chore: Upgrade<code> lint-staged</code> to v13</li>
<li><a
href="bf8ed799d5"><code>bf8ed79</code></a>
chore: Ensure postinstall script does not crash on Windows</li>
<li><a
href="2cbbb0717b"><code>2cbbb07</code></a>
chore: Bump dependencies</li>
<li><a
href="22d0416ea1"><code>22d0416</code></a>
chore: Bump LICENSE year</li>
<li><a
href="a52e957366"><code>a52e957</code></a>
fix: Support ES2015+ function definitions in
<code>function#toStringTokens()</code></li>
<li><a
href="3551cdd7b2"><code>3551cdd</code></a>
fix: Do not rely on problematic regex</li>
<li><a
href="7855319f41"><code>7855319</code></a>
chore: Simplify the manifest message</li>
<li><a
href="78e041fe78"><code>78e041f</code></a>
chore: Release v0.10.62</li>
<li><a
href="c51d552c03"><code>c51d552</code></a>
chore: Improve manifest</li>
<li>Additional commits viewable in <a
href="https://github.com/medikoo/es5-ext/compare/v0.10.53...v0.10.63">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Fbt violates the JSX spec by using a lowercase function as a tagname, even
though lowercase names are reserved for builtins. Here we detect cases where
there is an `<fbt>` tag where `fbt` is a local identifier and throw a todo.
Also apply content hash for experimental files
In #28582 I missed that experimental files have a copy of this build
function setting the version strings.
Currently you can accidentally pass React Element to a Server Action. It
warns but in prod it actually works because we can encode the symbol and
otherwise it's mostly a plain object. It only works if you only pass
host components and no function props etc. which makes it potentially
error later. The first thing this does it just early hard error for
elements.
I made Lazy work by unwrapping though since that will be replaced by
Promises later which works.
Our protocol is not fully symmetric in that elements flow from Server ->
Client. Only the Server can resolve Components and only the client
should really be able to receive host components. It's not intended that
a Server can actually do something with them other than passing them to
the client.
In the case of a Reply, we expect the client to be stateful. It's
waiting for a response. So anything we can't serialize we can still pass
by reference to an in memory object. So I introduce the concept of a
TemporaryReferenceSet which is an opaque object that you create before
encoding the reply. This then stashes any unserializable values in this
set and encode the slot by id. When a new response from the Action then
returns we pass the same temporary set into the parser which can then
restore the objects. This lets you pass a value by reference to the
server and back into another slot.
For example it can be used to render children inside a parent tree from
a server action:
```
export async function Component({ children }) {
"use server";
return <div>{children}</div>;
}
```
(You wouldn't normally do this due to the waterfalls but for advanced
cases.)
A common scenario where this comes up accidentally today is in
`useActionState`.
```
export function action(state, formData) {
"use server";
if (errored) {
return <div>This action <strong>errored</strong></div>;
}
return null;
}
```
```
const [errors, formAction] = useActionState(action);
return <div>{errors}<div>;
```
It feels like I'm just passing the JSX from server to client. However,
because `useActionState` also sends the previous state *back* to the
server this should not actually be valid. Before this PR this actually
worked accidentally. You get a DEV warning but it used to work in prod.
Once you do something like pass a client reference it won't work tho. We
could perhaps make client references work by stashing where we got them
from but it wouldn't work with all possible JSX.
By adding temporary references to the action implementation this will
work again - on the client. It'll also be more efficient since we don't
send back the JSX content that you shouldn't introspect on the server
anyway.
However, a flaw here is that the progressive enhancement of this case
won't work because we can't use temporary references for progressive
enhancement since there's no in memory stash. What is worse is that it
won't error if you hydrate. ~It also will error late in the example
above because the first state is "undefined" so invoking the form once
works - it errors on the second attempt when it tries to send the error
state back again.~ It actually errors on the first invocation because we
need to eagerly serialize "previous state" into the form. So at least
that's better.
I think maybe the solution to this particular pattern would be to allow
JSX to serialize if you have no temporary reference set, and remember
client references so that client references can be returned back to the
server as client references. That way anything you could send from the
server could also be returned to the server. But it would only deopt to
serializing it for progressive enhancement. The consequence of that
would be that there's a lot of JSX that might accidentally seem like it
should work but it's only if you've gotten it from the server before
that it works. This would have to have pair them somehow though since
you can't take a client reference from one implementation of Flight and
use it with another.
The example earlier in the stack had unreachable code in the output because
there was an unnecessary memoization block around an assignment. This was a
holdover from before we moved the logic to expand mutable ranges for phis from
LeaveSSA to InferMutableRanges. We were conservatively assigning a mutable range
to all variables with a phi, even those that didn't strictly need one.
Removing the range extension logic in LeaveSSA fixed the issue, but uncovered
the fact that AlignReactiveScopesToBlockScopes was missing a case to handle
optionals.
## Test Plan
Synced internally and ran a snapshot/comparison of compilation before/after
(P1197734337 for those curious). The majority of components get fewer memo slots
thanks to not needing to memoize non-allocating value block expressions like
ternaries/optionals. In a few cases, the fact that we're no longer assigning a
mutable range for value blocks (unless there is actually a mutation!) means we
get more fine-grained memoization and increase the number of memoization blocks.
So overall this appears to be correct, improve memoization, and reduce code
size.
Extracts a helper from the repro earlier in the stack into a helper in
shared-runtime. This makes it easy to verify that memoization is actually
working.
This case is specific to early return inside an inlined IIFE (which can often
occur as a result of dropping manual memoization). When we inline IIFEs, as a
reminder we wrap the body in a labeled block and convert returns to assignment
of a temporary + break out of the label.
Those reassignments themselves are getting a reactive scope assigned since the
reassigned value has a mutable range. They don't really need a mutable range or
scope, though. And then the presence of the `break` statements means that we can
sometimes exit out of the scope before reaching the end - leading to unreachable
code.
This can only occur though where _all the values are already memoized_. So the
code works just fine and even memoizes just fine - it's just that we have some
extraneous scopes and there is technically unreachable code. I'll fix in a
follow-up, adding a repro here.
With this change, the different files in RN will have *different*
hashes. This replaces the git hash and means that the file content
(including version) is only updated when the rest of the file content
actually changes. This should remove "noop" changes that need to be
synced that only update the version string.
A difference to the www implementation here is (and I'd be looking at
updating www as well if this lands well) that each file has an
individual hash instead of a combined content hash. This further reduces
the number of updated files and I couldn't find a reason we need to have
these in sync. The best I can gather is that this hash is used so folks
don't directly compare version string and make future updates harder.
## Summary
We need to unblock flipping the default for RTR to be concurrent
rendering. Update ReactART-test to use `unstable_isConcurrent` in place.
## How did you test this change?
`yarn test packages/react-art/src/__tests__/ReactART-test.js`
of dependencies from source
---
`validatePreserveExistingMemoizationGuarantees` previously checked
- manual memoization dependencies and declarations (the returned value) do not
"lose" memoization due to inferred mutations
```
function useFoo() {
const y = {};
// bail out because we infer that y cannot be a dependency of x as its
mutableRange
// extends beyond
const x = useMemo(() => maybeMutate(y), [y]);
// similarly, bail out if we find that x or y are mutated here
return x;
}
```
- manual memoization deps and decls do not get deopted due to hook calls
```
function useBar() {
const x = getArray();
useHook();
mutate(x);
return useCallback(() => [x], [x]);
}
```
This PR updates `validatePreserveExistingMemoizationGuarantees` with the
following correctness conditions:
*major change* All inferred dependencies of reactive scopes between
`StartMemoize` and `StopMemoize` instructions (e.g. scopes containing manual
memoization code) must either:
1. be produced from earlier within the same manual memoization block
2. exactly match an element of depslist from source
This assumes that the source codebase mostly follows the `exhaustive-deps` lint
rule, which ensures that deps lists are (1) simple expressions composing of
reads from named identifiers + property loads and (2) exactly match deps usages
in the useMemo/useCallback itself.
---
Validated that this does not change source by running internally on ~50k files
(no validation on `main`, no validation on this PR, and validation on this PR).
## Summary
Creates a new `alwaysThrottleDisappearingFallbacks` feature flag that
gates the changes from https://github.com/facebook/react/pull/26802
(instead of being controlled by `alwaysThrottleRetries`). The values of
this new flag mirror the current values of `alwaysThrottleRetries` such
that there is no behavior difference.
This additional feature flag allows us to incrementally validate the
change (arguably bug fix) from
https://github.com/facebook/react/pull/26802 independently from
`alwaysThrottleRetries`.
## How did you test this change?
```
$ yarn test
$ yarn flow dom-browser
$ yarn flow dom-fb
$ yarn flow fabric
```
---
Previously, we always emitted `Memoize dep` instructions after the function
expression literal and depslist instructions
```js
// source
useManualMemo(() => {...}, [arg])
// lowered
$0 = FunctionExpression(...)
$1 = LoadLocal (arg)
$2 = ArrayExpression [$1]
$3 = Memoize (arg)
$4 = Call / LoadLocal
$5 = Memoize $4
```
Now, we insert `Memoize dep` before the corresponding function expression
literal:
```js
// lowered
$0 = StartMemoize (arg) <---- this moved up!
$1 = FunctionExpression(...)
$2 = LoadLocal (arg)
$3 = ArrayExpression [$2]
$4 = Call / LoadLocal
$5 = FinishMemoize $4
```
Design considerations:
- #2663 needs to understand which lowered instructions belong to a manual
memoization block, so we need to emit `StartMemoize` instructions before the
`useMemo/useCallback` function argument, which contains relevant memoized
instructions
- we choose to insert StartMemoize instructions to (1) avoid unsafe instruction
reordering of source and (2) to ensure that Forget output does not change when
enabling validation
This PR only renames `Memoize` -> `Start/FinishMemoize` and hoists
`StartMemoize` as described. The latter may help with stricter validation for
`useCallback`s, although testing is left to the next PR.
#2663 contains all validation changes
Remove private header from playground
Before we miss removing this from the public release, I think we can remove this
header now already. We're still behind a secret URL + password.
Bumps
[follow-redirects](https://github.com/follow-redirects/follow-redirects)
from 1.15.4 to 1.15.6.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="35a517c586"><code>35a517c</code></a>
Release version 1.15.6 of the npm package.</li>
<li><a
href="c4f847f851"><code>c4f847f</code></a>
Drop Proxy-Authorization across hosts.</li>
<li><a
href="8526b4a1b2"><code>8526b4a</code></a>
Use GitHub for disclosure.</li>
<li><a
href="b1677ce001"><code>b1677ce</code></a>
Release version 1.15.5 of the npm package.</li>
<li><a
href="d8914f7982"><code>d8914f7</code></a>
Preserve fragment in responseUrl.</li>
<li>See full diff in <a
href="https://github.com/follow-redirects/follow-redirects/compare/v1.15.4...v1.15.6">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps
[follow-redirects](https://github.com/follow-redirects/follow-redirects)
from 1.15.4 to 1.15.6.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="35a517c586"><code>35a517c</code></a>
Release version 1.15.6 of the npm package.</li>
<li><a
href="c4f847f851"><code>c4f847f</code></a>
Drop Proxy-Authorization across hosts.</li>
<li><a
href="8526b4a1b2"><code>8526b4a</code></a>
Use GitHub for disclosure.</li>
<li><a
href="b1677ce001"><code>b1677ce</code></a>
Release version 1.15.5 of the npm package.</li>
<li><a
href="d8914f7982"><code>d8914f7</code></a>
Preserve fragment in responseUrl.</li>
<li>See full diff in <a
href="https://github.com/follow-redirects/follow-redirects/compare/v1.15.4...v1.15.6">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps
[follow-redirects](https://github.com/follow-redirects/follow-redirects)
from 1.13.0 to 1.15.6.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="35a517c586"><code>35a517c</code></a>
Release version 1.15.6 of the npm package.</li>
<li><a
href="c4f847f851"><code>c4f847f</code></a>
Drop Proxy-Authorization across hosts.</li>
<li><a
href="8526b4a1b2"><code>8526b4a</code></a>
Use GitHub for disclosure.</li>
<li><a
href="b1677ce001"><code>b1677ce</code></a>
Release version 1.15.5 of the npm package.</li>
<li><a
href="d8914f7982"><code>d8914f7</code></a>
Preserve fragment in responseUrl.</li>
<li><a
href="65858205e5"><code>6585820</code></a>
Release version 1.15.4 of the npm package.</li>
<li><a
href="7a6567e16d"><code>7a6567e</code></a>
Disallow bracketed hostnames.</li>
<li><a
href="05629af696"><code>05629af</code></a>
Prefer native URL instead of deprecated url.parse.</li>
<li><a
href="1cba8e85fa"><code>1cba8e8</code></a>
Prefer native URL instead of legacy url.resolve.</li>
<li><a
href="72bc2a4229"><code>72bc2a4</code></a>
Simplify _processResponse error handling.</li>
<li>Additional commits viewable in <a
href="https://github.com/follow-redirects/follow-redirects/compare/v1.13.0...v1.15.6">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps
[follow-redirects](https://github.com/follow-redirects/follow-redirects)
from 1.15.4 to 1.15.6.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="35a517c586"><code>35a517c</code></a>
Release version 1.15.6 of the npm package.</li>
<li><a
href="c4f847f851"><code>c4f847f</code></a>
Drop Proxy-Authorization across hosts.</li>
<li><a
href="8526b4a1b2"><code>8526b4a</code></a>
Use GitHub for disclosure.</li>
<li><a
href="b1677ce001"><code>b1677ce</code></a>
Release version 1.15.5 of the npm package.</li>
<li><a
href="d8914f7982"><code>d8914f7</code></a>
Preserve fragment in responseUrl.</li>
<li>See full diff in <a
href="https://github.com/follow-redirects/follow-redirects/compare/v1.15.4...v1.15.6">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Reverting some of https://github.com/facebook/react/pull/27804 which
renamed this option to stable. This PR just replaces internal usage to
make upcoming PRs cleaner.
Keeping isConcurrent unstable for the next major release in order to
enable a broader deprecation of RTR and be consistent with concurrent
rendering everywhere for next major.
(https://github.com/facebook/react/pull/28498)
- Next major will use concurrent root
- The old behavior (legacy root by default, concurrent root with
unstable option) will be preserved for React Native until new
architecture is fully shipped.
- Flag and legacy root usage can be removed after RN dependency is
unblocked without an additional breaking change
A while back we implemented a heuristic that if a chunk was large it was
assumed to be produced by the render and thus was safe to stream which
results in transferring the underlying object memory. Later we ran into
an issue where a precomputed chunk grew large enough to trigger this
hueristic and it started causing renders to fail because once a second
render had occurred the precomputed chunk would not have an underlying
buffer of bytes to send and these bytes would be omitted from the
stream. We implemented a technique to detect large precomputed chunks
and we enforced that these always be cloned before writing.
Unfortunately our test coverage was not perfect and there has been for a
very long time now a usage pattern where if you complete a boundary in
one flush and then complete a boundary that has stylehsheet dependencies
in another flush you can get a large precomputed chunk that was not
being cloned to be sent twice causing streaming errors.
I've thought about why we even went with this solution in the first
place and I think it was a mistake. It relies on a dev only check to
catch paired with potentially version specific order of operations on
the streaming side. This is too unreliable. Additionally the low limit
of view size for Edge is not used in Node.js but there is not real
justification for this.
In this change I updated the view size for edge streaming to match Node
at 2048 bytes which is still relatively small and we have no data one
way or another to preference 512 over this. Then I updated the assertion
logic to error anytime a precomputed chunk exceeds the size. This
eliminates the need to clone these chunks by just making sure our view
size is always larger than the largest precomputed chunk we can possibly
write. I'm generally in favor of this for a few reasons.
First, we'll always know during testing whether we've violated the limit
as long as we exercise each stream config because the precomputed chunks
are created in module scope. Second, we can always split up large chunks
so making sure the precomptued chunk is smaller than whatever view size
we actually desire is relatively trivial.
## Summary
We're working on enabling the use of microtasks in React Native by
default when using the new architecture. To enable this we need to
synchronize the RN renderers from React, but doing this causes an error
because the renderers now rely on an object defined in
`React.__SECRET_INTERNALS_DO_NOT_USE_OR_YOU_WILL_BE_FIRED`
(`ReactCurrentCache`) that's hasn't been released as a stable version
yet (cache).
This reverts the change done in #28519 to avoid enabling the cache API
in RN until we release a new version of React in npm.
## How did you test this change?
Manually built the RN renderer, copied it to the RN repository and
tested e2e in RNTester.
Fixes T180504437. We expected `<fbt:param>` to always have no surrounding
whitespace or have both leading and trailing whitespace, it can have one but not
the other, though such cases are rare in practice.
Repro from T180504728 which reproduced internally and on playground, neither of
which have #2687 yet. That PR (earlier in this stack) already fixes the issue,
so i'm just adding the repro to help prevent regressions.
While i'm here, we know that there are a variety of cases that are not supported
yet around combining value blocks with other syntax constructs. Since we're
aware of these cases and detect them, we can make this a todo instead of an
invariant.
We need to revisit the conversion from value blocks into ReactiveFunction. Or
just revisit ReactiveFunction altogether (see my post about what this would look
like). For now, makes this case a todo.
"Support" in the sense of dropping these on the floor and compiling, rather than
bailing out with a todo.
We already don't make any guarantees about which type annotations we'll preserve
through to the output, so it seems fine for now to just drop type aliases.
I addressed some of the cases that lead to this invariant but there were still
more. In this case, we have scopes like this:
```
scope @1 declarations=[t$0] {
let t$0 = ArrayExpression []
if (...) {
return null;
}
}
scope @2 deps=[t$0] declarations=[t$1] {
let t$1 = Jsx children=[t$0] ...
}
```
Because scope 1 has an early return, PropagateEarlyReturns wraps its contents in
a label and converts the returns to breaks:
```
scope @1 declarations=[t$0] earlyReturn={t$2} {
let t$2
bb0: {
let t$0 = ArrayExpression []
if (...) {
t$2 = null;
break bb0;
}
}
}
scope @2 deps=[t$0] declarations=[t$1] {
let t$1 = Jsx children=[t$0] ...
}
```
But then MergeReactiveScopesThatInvalidateTogether smushes them together:
```
scope @1 declarations=[t$1] earlyReturn={t$2} {
let t$2
bb0: {
let t$0 = ArrayExpression [] // <--- Oops! We're inside a block now
if (...) {
t$2 = null;
break bb0;
}
}
let t$1 = Jsx children=[t$0] ...
}
```
Note that the `t$0` binding is now created inside the labeled block, so it's no
longer accessible to the Jsx instruction which follows the labeled block. This
isn't an issue with promoting temporaries or propagating outputs, but a simple
issue of the labeled block (used for early return) introducing a new block
scope. The solution here is to simply reorder the passes so that we transform
for early returns after other optimizations. This means the jsx element will
basically move inside the labeled block, solving the scoping issue:
```
scope @1 declarations=[t$1] earlyReturn={t$2} {
let t$2
bb0: {
let t$0 = ArrayExpression [] // ok, same block scope as its use
if (...) {
t$2 = null;
break bb0;
}
let t$1 = Jsx children=[t$0] // note this moved inside the labeled block
}
}
```
I addressed some of the cases that lead to this invariant but there were still
more. In this case, we have scopes like this:
```
scope @1 declarations=[t$0] {
let t$0 = ArrayExpression []
if (...) {
return null;
}
}
scope @2 deps=[t$0] declarations=[t$1] {
let t$1 = Jsx children=[t$0] ...
}
```
Because scope 1 has an early return, PropagateEarlyReturns wraps its contents in
a label and converts the returns to breaks:
```
scope @1 declarations=[t$0] earlyReturn={t$2} {
let t$2
bb0: {
let t$0 = ArrayExpression []
if (...) {
t$2 = null;
break bb0;
}
}
}
scope @2 deps=[t$0] declarations=[t$1] {
let t$1 = Jsx children=[t$0] ...
}
```
But then MergeReactiveScopesThatInvalidateTogether smushes them together:
```
scope @1 declarations=[t$1] earlyReturn={t$2} {
let t$2
bb0: {
let t$0 = ArrayExpression [] // <--- Oops! We're inside a block now
if (...) {
t$2 = null;
break bb0;
}
}
let t$1 = Jsx children=[t$0] ...
}
```
Note that the `t$0` binding is now created inside the labeled block, so it's no
longer accessible to the Jsx instruction which follows the labeled block. This
isn't an issue with promoting temporaries or propagating outputs, but a simple
issue of the labeled block (used for early return) introducing a new block
scope. The solution (in the next PR) is to simply reorder the passes so that we
transform for early returns after other optimizations. This means the jsx
element will basically move inside the labeled block, solving the scoping issue:
```
scope @1 declarations=[t$1] earlyReturn={t$2} {
let t$2
bb0: {
let t$0 = ArrayExpression [] // ok, same block scope as its use
if (...) {
t$2 = null;
break bb0;
}
let t$1 = Jsx children=[t$0] // note this moved inside the labeled block
}
}
```
This was an oversight in codegen. The entire pipeline supports multiple values
in a for initializer, but codegen was dropping all but the first initializer.
Fixes T180504437. In MergeOverlappingReactiveScopes we track the active scopes
and mark them as "ended" when reaching the first instruction after their mutable
range. However, in cases of interleaving that will be merged, we could
previously mark a scope as complete when it's original range was completed, even
though the range would get extended post-merge. The fix here detects
interleaving earlier, and eagerly updates the mutable ranges of the merged
scopes to ensure that neither is "ended" earlier than it should.
The repro here fails without this change.
Fixes T175282980. InferReactiveScopeVariables had logic to force assigning a
scope to MethodCall property lookups with the idea of forcing the method call
lookup to be in the same scope as the method call itself. But this doesn't work
if we never assign a scope to the method call! That can happen if we're able to
infer that the method call produces a primitive and doesn't need memoization.
This PR changes things so that:
* InferReactiveScopeVariables no longer assumes that MethodCall property values
need a scope
* We run a separate pass that ensures that _if_ a MethodCall has a scope, that
it's property is in the scope, and that otherwise its property doesn't get a
scope. This is similar to the existing passes that force a single scope for
related instructions like ObjectMethod+ObjectExpression and fbt operands/calls.
Fixes T180509722. What happened is that the logic in LeaveSSA to find
declarations within for initializers wasn't working with try/catch because the
initializer block gets broken up with a maybe-throw after every instruction that
can throw. These maybe-throws can then get turned into gotos by
PruneMaybeThrows, so LeaveSSA has to handle both cases.
The new logic scans from the start of the init block until reaching the end, and
creates declarations for all StoreLocals. Note that we don't yet support
maybe-throw in value blocks — that's already a todo — so the change here simply
allows us to compile farther until reaching that other todo. But i've
double-checked the HIR and it looks correct for this case, so it should just
work once we fix that todo. I've also added a comment to help us remember (and
of course, we'd have to add a snap fixture too)
## Summary
We want to enable the new event loop in React Native
(https://github.com/react-native-community/discussions-and-proposals/pull/744)
for all users in the new architecture (determined by the use of
bridgeless, not by the use of Fabric). In order to leverage that, we
need to also set the flag for the React reconciler to use microtasks for
scheduling (so we'll execute them at the right time in the new event
loop).
This migrates from the previous approach using a dynamic flag (to be
used at Meta) with the check of a global set by React Native. The reason
for doing this is:
1) We still need to determine this dynamically in OSS (based on
Bridgeless, not on Fabric).
2) We still need the ability to configure the behavior at Meta, and for
internal build system reasons we cannot access the flag that enables
microtasks in
[`ReactNativeFeatureFlags`](6c28c87c4d/packages/react-native/src/private/featureflags/ReactNativeFeatureFlags.js (L121)).
## How did you test this change?
Manually synchronized the changes to React Native and ran all tests for
the new architecture on it. Also tested manually.
> [!NOTE]
> This change depends on
https://github.com/facebook/react-native/pull/43397 which has been
merged already
## Overview
Adds a `pending` state to useFormState, which will be replaced by
`useActionState` in the next diff. We will keep `useFormState` around
for backwards compatibility, but functionally it will work the same as
`useActionState`, which has an `isPending` state returned.
We broke the ability to "break on uncaught exceptions" by adding a
try/catch higher up in the scheduling. We're giving up on fixing that so
we can remove the replay trick inside an event handler.
The issue with that approach is that we end up double logging a lot of
errors in DEV since they get reported to the page.
It's also a lot of complexity around this feature.
```diff
-expect(ReactTestUtils.isDOMComponent(maybeElement)).toBe(true);
+expect(maybeElement).toBeInstanceOf(Element);
```
It's not equivalent since `isDOMComponent` checks `maybeElement.nodeType
=== Element.ELEMENT_NODE && !!maybeElement.tagName` but `instanceof`
check seems sufficient here. Checking `nodeType` is mostly for
cross-realm checks and checking falsy `tagName` seems like a check
specifically for incomplete DOM implementations because tagName can't be
empty by spec I believe.
## Summary
Internal cleanup of ReactTestRenderer
## How did you test this change?
`yarn test packages/react/src/__tests__/ReactProfiler-test.internal.js`
## Summary
We need to unblock flipping the default for RTR to be concurrent
rendering. Update ReactDevToolsHooksIntegration-test to use
`unstable_isConcurrent` in place.
## How did you test this change?
`yarn test
packages/react-debug-tools/src/__tests__/ReactDevToolsHooksIntegration-test.js`
## Summary
Looks like this was added years ago for instrumentation at meta that
never ended up rolling out. Should be safe to clean up.
## How did you test this change?
`yarn test`
## Summary
This PR is a subset of https://github.com/facebook/react/pull/28425,
which only includes the feature flags that will be configured as
dynamic.
The following list summarizes the feature flag changes:
* RN FB
* Change to Dynamic
* consoleManagedByDevToolsDuringStrictMode
* enableAsyncActions
* enableDeferRootSchedulingToMicrotask
* enableRenderableContext
* useModernStrictMode
## How did you test this change?
Ran the following successfully:
```
$ yarn test
$ yarn flow native
$ yarn flow fabric
```
---
(This came out of running a sync and observing hundreds of bailouts due from
this validation)
Reading `fnType` from environment overgeneralizes, as inner functions are
usually not the type of the outer react function.
```
// Component type
function Component() {
// not Component type
const helper = () => {...};
}
```
Let's attach fnType to `HIRFunction` and use that for our inference +
validations
Fixture from T175283039, a reassignment within an expression can sometimes
generate a StoreLocal within a value block. Depending on the case this can end
up as the last instruction of the block, which then hits an invariant.
Adds a todo in HIRBuilder, before we prune unreachable code we check if there
were any function expressions. Realistically that's only going to occur for
hoisted functions, so this lets us target a todo rather than hit an invariant.
For T175282529. We already detect hoisted functions and have a specific todo for
them, but in this case the function is in unreachable code that gets pruned
during BuildHIR. The later check for hoisted functions doesn't find it.
## Summary
This PR is a subset of https://github.com/facebook/react/pull/28425,
which only includes the feature flags that will be configured as "always
on" (i.e. not "dynamic").
The following list summarizes the feature flag changes:
* RN FB
* Always Enable
* enableCache
* enableCustomElementPropertySupport
* RN OSS
* Always Enable
* disableLegacyContext
* enableCache
* enableCustomElementPropertySupport
* RN Test
* Always Enable
* disableModulePatternComponents
* enableCustomElementPropertySupport
## How did you test this change?
Ran the following successfully:
```
$ yarn test
$ yarn flow native
$ yarn flow fabric
```
## Summary
Internal cleanup of ReactTestRenderer
## How did you test this change?
`yarn test
packages/react-reconciler/src/__tests__/DebugTracing-test.internal.js`
## Summary
Currently, `ReactHooksInspection-test.js` fails because something is
polluting the resulting `Promise` with symbol properties. This changes
the unit test to be more resilient to such symbol properties.
## How did you test this change?
Ran the following successfully:
```
$ yarn test
```
One of our visitors wasn't visiting TryTerminal's handlerBinding, which meant
that we missed renaming those identifiers in RenameVariables. I also updated the
printers to print this binding.
Within a try/catch, every instruction is followed by a maybe-throw terminal.
This currently breaks the logic in BuildReactiveFunction which tries to
reassemble the value block, since it isn't expecting the maybe-throw.
Conceptually the logic should just ignore it — we could even flatten away
maybe-throw terminals before this pass — but for now since this pattern is rare
we can just make it a todo.
For T181507827 — adds an invariant in codegen when emitting identifiers to
ensure that we only create babel Identifier nodes for nodes that the compiler
has explicitly promoted to valid, named identifiers. This means that we'll fail
for unnamed temporaries (previously caught), as well as promoted temporaries
that somehow didn't get renamed by RenameVariables (newly caught).
Adds a visitor to collect all the globals that are referenced within the
function, and then uses this list to avoid synthesizing variables with
conflicting names. This is used in both RenameVariables (for promoted
temporaries) and Codegen (for `$` and change variables only, so far, but this
can be extended in follow-ups).
This is a key part of avoiding generating conflicting names in our output. To
start, RenameVariables now returns a Set of the unique identifier names that
exist in the function. Codegen uses this to avoid generating duplicate names for
change variables and for the `$` useMemoCache variable. Rather than always emit
`$` or `c_N`, codegen checks that this name would not conflict and appends an
incrementing suffix until it finds a unique name.
Note that it's still possible for us to generate conflicts with global
variables, both during RenameVariable and Codegen. The next step will be to
avoid conflicts with globals.
Another title for this PR could be "Yet another reason for HIR-everywhere"
ReactiveFunctionVisitor doesn't traverse into HIRFunctions from
FunctionExpression and ObjectMethod values. This means that
PromoteUsedTemporaries and RenameVariables also weren't traversing into such
functions, and those values weren't getting promoted and renamed correctly.
This PR updates ReactiveFunctionVisitor with a method that can optionally be
invoked to traverse an HIRFunction and call the appropriate visitor methods.
PromoteUsedTemporaries and RenameVariables invoke this to ensure they visit all
places, even in nested HIRFunctions.
I realized that codegen still had a fallback for generating identifier nodes for
unnamed temporaries. This PR updates codegen to throw if it needs to generate an
identifier for a temporary, and updates earlier passes to promote temporaries to
named values in all the cases that were missed:
* BuildHIR needs to promote temporaries for temporaries in destructuring
bindings and catch clause bindings
* PromoteUsedTemporaries has to promote temporaries for destructured function
parameters or function params that are context variables.
Uses an enum for Identifier.name to distinguish originally named identifiers vs
promoted temporaries. An opaque type for the named identifier variant makes it
hard to accidentally create that type.
When the compiler promotes temporary values to named variables, we currently
eagerly assign a name using the temporary's IdentifierId. This means that we're
sort of stuck with this name later in compilation, and RenameVariables can't be
100% sure whether a 't0' variable is a temporary or not. As a result, the names
of these promoted temporaries is influenced by how many temporaries we happened
to create during compilation (and what the next available identifier id was),
making them fluctuate more as we iterate on the compiler.
This is an RFC for showing how we can stabilize these names. The key elements:
* Distinguish promoted temporaries from other named identifiers. Here we use a
hack, naming them starting with '#t' or '#T', since '#' isn't a valid identifier
starting point. This lets us keep all of our logic that looks for non-null
identifiers names to distinguish named/unnamed, while also distinguishing real
names from generated names (if this was Rust, we'd use an Enum and have a
"isNamed()" method on it that was true for real/temporary names and false
otherwise)
* In RenameVariables, detect generated names and fall back to generating the
next available `tN`-style name (or `TN` for JSX tags).
* To reduce thrash overall, RenameVariables no longer keeps a global "next id"
value that uses to distinguish all conflicting identifiers, instead we restart
at 0 whenever we find a conflict, and keep bumping until we find a free name.
Thus if both `foo` and `bar` had conflicts, we previously would end up with
`foo$0` and `bar$1` as the deduped names, but now will end up with `foo$0` and
`bar$0`.
## RFC
I'm open to feedback on the approach. Two main questions:
* How to annotate promoted temporaries. The most type-safe option is to change
`Identifier.name` to be a union of `{kind: 'named', value: string} | `{kind:
'promoted', value: string} | `{kind: 'temporary'}` though TS then wouldn't allow
`identifier.name.value` (even as nullable) since it doesn't exist on one of the
variants. Maybe we could type the temporary one as `{kind: 'temporary', value?:
null}` so the value has to be null but you can always access that property?
* ?? Other concerns about the approach? We could keep the global
auto-incrementing id rather than attempting to reset to 0 for each conflict.
The previous implementation used IdentifierId, but since this pass operates
after LeaveSSA the identifier ids are no longer distinct for different SSA
instances. Instead we use the Identifier instance, which preserves SSA
information (even ever LeaveSSA) and allows distinguishing between variables
whose value always changes vs variables that may be reassigned such that they
don't always invalidate.
In the future when we use HIR everywhere, this pass should use the HIR CFG to
understand that phi nodes whose operands all will always invalidate can also be
treated as always invalidating.
## Test Plan
Synced to www, 91 files have output changes
(https://fburl.com/everpaste/3e3hjpjs). I spot checked these and confirmed that
they are all from cases where there was already missing memoization of earlier
values, where we now can prune later reactive scopes that depend on the
un-memoized values.
Implements the optimization described in the previous PR: if we know that a
scope's dependency will _always_ invalidate (it is not memoized and it is
guaranteed to be a new object if the instruction executes, such as an array or
object literal), then we can prune that scope. The invalidation is transitive:
we track always-invalidating types from within scopes, and if their scope gets
invalidated we prune downstream scope that depend on them.
## Test Plan
Tested via #2639 - see https://fburl.com/everpaste/3e3hjpjs. 91 files change
output due to reactive scopes which would always invalidate due to always
invalidating dependencies.
These fixtures demonstrate how currently, even if the dependency of a scope
doesn't get memoized (ie the scope gets pruned), we don't remove later scopes
that depend on that value. Those later scopes will always invalidate, so we
might as well remove them.
In #23176 we added a special case in completeWork for SuspenseBoundaries
if they still have trailing children. However, that misses a case
because it doesn't log a recoverable error for the hydration mismatch.
So we get an error that we rerendered.
I think this special case was done to avoid contexts getting out of
sync. I don't know why we didn't just move where the pop happens though
so that's what I did here and let the regular pass throw instead. Seems
to be pass the tests.
Summary: Currently Forget bails on mutations to globals within any callback function. However, callbacks passed to useEffect should not bail and are not subject to the rules of react in the same way.
We allow this by instead of immediately raising errors when we see illegal writes, storing the error as part of the function. When the function is called, or passed to a position that could call it during rendering, we bail as before; but if it's passed to `useEffect`, we don't raise the errors.
Stacked on https://github.com/facebook/react/pull/28351, please review
only the last commit.
Top-level description of the approach:
1. Once user selects an element from the tree, frontend asks backend to
return the inspected element, this is where we simulate an error
happening in `render` function of the component and then we parse the
error stack. As an improvement, we should probably migrate from custom
implementation of error stack parser to `error-stack-parser` from npm.
2. When frontend receives the inspected element and this object is being
propagated, we create a Promise for symbolicated source, which is then
passed down to all components, which are using `source`.
3. These components use `use` hook for this promise and are wrapped in
Suspense.
Caching:
1. For browser extension, we cache Promises based on requested resource
+ key + column, also added use of
`chrome.devtools.inspectedWindow.getResource` API.
2. For standalone case (RN), we cache based on requested resource url,
we cache the content of it.
`_debugSource` was removed in
https://github.com/facebook/react/pull/28265.
This PR migrates DevTools to define `source` for Fiber based on
component stacks. This will be done lazily for inspected elements, once
user clicks on the element in the tree.
`DevToolsComponentStackFrame.js` was just copy-pasted from the
implementation in `ReactComponentStackFrame`.
Symbolication part is done in
https://github.com/facebook/react/pull/28471 and stacked on this commit.
There is a weird behaviour in all shells of RDT: when user opens
`Components` tab and scrolls down a tree (without any prior click or
focus event), and then clicks on some element, the `click` event will
not be fired. Because `click` event hasn't been fired, the `focus` event
is fired for the whole list and we pre-select the first (root) element
in the tree:
034130c02f/packages/react-devtools-shared/src/devtools/views/Components/Tree.js (L217-L226)
Check the demo (before) what is happening. I don't know exactly why
`click` event is not fired there, but it only happens:
1. For elements, which were not previously rendered (for virtualization
purposes).
2. When HTML-element (div), which represents the container for the tree
was not focused previously.
Unlike the `click` event, the `mousedown` event is fired consistently.
### Before
https://github.com/facebook/react/assets/28902667/9f3ad75d-55d0-4c99-b2d0-ead63a120ea0
### After
https://github.com/facebook/react/assets/28902667/e34816be-644c-444c-8e32-562a79494e44
Tested that it works in all shells, including the select / deselect
features (with `metaKey` param in event).
Updates the `flushSync` tests to use react-dom instead of ReactNoop.
flushSync is primarily a react-dom API and asserting the implementation
of ReactNoop is not really ideal especially since we are going to be
refactoring flushSync soon to not be implemented in the reconciler
internals.
ReactNoop still have a flushSync api and it can still be used in other
tests that are primarily about testing other functionlity and use
ReactNoop as the renderer.
The idea here is that host dispatchers are not bound to renders so we
need to be able to dispatch to them at any time. This updates the
implementation to chain these dispatchers so that each renderer can
respond to the dispatch. Semantically we don't always want every
renderer to do this for instance if Fizz handles a float method we don't
want Fiber to as well so each dispatcher implementation can decide if it
makes sense to forward the call or not. For float methods server
disaptchers will handle the call if they can resolve a Request otherwise
they will forward. For client dispatchers they will handle the call and
always forward. The choice needs to be made for each dispatcher method
and may have implications on correct renderer import order. For now we
just live with the restriction that if you want to use server and client
together (such as renderToString in the browser) you need to import the
server renderer after the client renderer.
Adds a flag to disable legacy mode. Currently this flag is used to cause
legacy mode apis like render and hydrate to throw. This change also
removes render, hydrate, unmountComponentAtNode, and
unstable_renderSubtreeIntoContainer from the experiemntal entrypoint.
Right now for Meta builds this flag is off (legacy mode is still
supported). In OSS builds this flag matches __NEXT_MAJOR__ which means
it currently is on in experiemental. This means that after merging
legacy mode is effectively removed from experimental builds. While this
is a breaking change, experimental builds are not stable and users can
pin to older versions or update their use of react-dom to no longer use
legacy mode APIs.
The runtime contains a type check to determine if a user-provided ref is
a valid type — a function or object (or a string, when
`disableStringRefs` is off). This currently happens during child
reconciliation. This changes it to happen only when the ref is passed to
the component that the ref is being attached to.
This is a continuation of the "ref as prop" change — until you actually
pass a ref to a HostComponent, class, etc, ref is a normal prop that has
no special behavior.
Infer if a function is a component or hook when we're deciding to compile a
function and store that in the environment.
This is used in passes like InferReferenceEffects rather than having to re-parse
the name in each pass.
Previously, Forget would throw if _any_ of the arguments to a component are
modified. This isn't quite right as a ref argument can be modified.
This PR assumes the second argument of a component to be a ref and allows it to
be mutable.
A future PR will add types to this argument so the validateRefAccessDuringRender
can catch if ref is mutated in render. This PR contains a todo test for this.
Rather than force scopes to be created for primitives within
InferReactiveScopeVariables, here we move the creation of scopes for these
instructions to a later pass. Later in the pipeline we have more context, such
as whether e.g. a primitive or propertyload is being accessed within a scope or
not, and whether it therefore needs its own scope or not.
Currently we allocate all reactive scopes during a single pass,
InferReactiveScopeVariables, using a local incrementing number to assign
ScopeIds. This means we can't easily create additional scopes later since we
don't know the next available scope id.
Here we add `Environment.nextScopeId` and use that to synthesize scope ids.
Looking up certain properties on a hook is a common pattern for logging.
It's non-ideal but it's not a bug to do this.
This updates Forget to not error on this pattern.
filepath
Internal rollout currently has a good number of test failures.
`enableEmitInstrumentForget` can help developers understand which functions /
files they should look at:
```
// input
function Foo() {
userCode();
// ...
}
// output
function Foo() {
if (__DEV__ && inE2eTestMode) {
logRender("Foo", "/path/to/filename.js");
}
const $ = useMemoCache(...);
userCode();
}
```
Depends on:
- https://github.com/facebook/react/pull/28398
---
This removes string refs, which has been deprecated in Strict Mode for
seven years.
I've left them behind a flag for Meta, but in open source this fully
removes the feature.
## Summary
`isInputPending` is not in use. This PR cleans up the flags controlling
its gating and parameters to simplify Scheduler.
Makes `frameYieldMs` feature flag static, set to 10ms in www, which we
found built on the wins provided by a broader yield interval via
`isInputPending`. Flag remains set to 5ms in OSS builds.
## How did you test this change?
`yarn test Scheduler`
The code for value block handling assumes a small set of terminal kinds, but
try/catch causes the entire body to get wrapped in MaybeThrow terminals. We need
to skip over these and delegate to the inner content.
This invariant interpolated values into the `reason` which prevent our internal
tooling from grouping related errors. This PR updates to make the reason static
and interpolate the description.
Fixes T173101142 — we previously computed incorrect function expression
dependencies for JSXMemberExpressions. This PR applies similar logic to
JSXMemberExpression as we use for MemberExpression.
## Test Plan
Synced internally, only one file changes output. I manually investigated to
confirm — the change is that a function expression's dependencies are more
precise and correct. See https://fburl.com/everpaste/4dqewxqv
---
No changes to snap or sprout's functionality.
Tweaks to consolidate sprout into snap while keeping its simple interface and
most developer patterns.
- to keep `filter` mode fast, we do not run sprout in filter mode
- sprout is run in non-filter mode for both test and update
~~Small qol improvement: `--watch` will start you in `filter` mode~~
### Cost of this change
`performance.now()` is quite noisy due to background processes and ThreadPool
logic (especially with asymmetric task distribution), so I used
`process.cpuUsage` which reports time spent in user-space. This was much less
noisy (1-4% standard dev / mean)
Running all tests becomes slower by ~50%. Initial runs are slower because they
load in Forget's `require` chains.
- 23.9s previous initial run
- 34.6s current initial run
- 11.5s previous subsequent runs
- 15.4s current subsequent runs
Running filtered tests remains very fast (~100ms on the average case)
---
Additional modes or commands could be added as needed (e.g. run tests in filter
mode, with sprout output)
If there's invalid dom nesting, there will be mismatches following but
the nesting is the most important cause of the problem.
Previously we would include the DOM nesting when rerendering thanks to
the new model of throw and recovery. However, the log would come during
the recovery phase which is after we've already logged that there was a
hydration mismatch.
People would consistently miss this log. Which is fair because you
should always look at the first log first as the most probable cause.
This ensures that we log in the hydration phase if there's a dom nesting
issue. This assumes that the consequence of nesting will appear such
that the won't have a mismatch before this. That's typically the case
because the node will move up and to be a later sibling. So as long as
that happens and we keep hydrating depth first, it should hold true.
There might be an issue if there's a suspense boundary between the nodes
we'll find discover the new child in the outer path since suspense
boundaries as breadth first.
Before:
<img width="996" alt="Screenshot 2024-02-23 at 7 34 01 PM"
src="https://github.com/facebook/react/assets/63648/af70cf7f-898b-477f-be39-13b01cfe585f">
After:
<img width="853" alt="Screenshot 2024-02-23 at 7 22 24 PM"
src="https://github.com/facebook/react/assets/63648/896c6348-1620-4f99-881d-b6069263925e">
Cameo: RSC stacks.
This pattern is a petpeeve of mine. I don't consider this best practice
and so most don't have these prefixes. Very inconsistent.
At best this is useless and noisey that you have to parse because the
information is also in the stack trace.
At worse these are misleading because they're highlighting something
internal (like validateDOMNesting) which even suggests an internal bug.
Even the ones public to React aren't necessarily what you called because
you might be calling a wrapper around it.
That would be properly reflected in a stack trace - which can also
properly ignore list so that the first stack you see is your callsite,
Which might be like `render()` in react-testing-library rather than
`createRoot()` for example.
I'm a bit ambivalent about this one because it's not the main strategy
that I plan on pursuing. I plan on replacing most DEV-only specific
stacks like `console.error` stacks with a new take on owner stacks and
native stacks. The future owner stacks may or may not be exposed to
error boundaries in DEV but if they are they'd be a new errorInfo
property since they're owner based and not available in prod.
The use case in `console.error` mostly goes away in the future so this
PR is mainly for error boundaries. It doesn't hurt to have it in there
while I'm working on the better stacks though.
The `componentStack` property exposed to error boundaries is more like
production behavior similar to `new Error().stack` (which even in DEV
won't ever expose owner stacks because `console.createTask` doesn't
affect these). I'm not sure it's worth adding server components in DEV
(this PR) because then you have forked behavior between dev and prod.
However, since even in the future there won't be any other place to get
the *parent* stack, maybe this can be useful information even if it's
only dev. We could expose a third property on errorInfo that's DEV only
and parent stack but including server components. That doesn't seem
worth it over just having the stack differ in dev and prod.
I don't plan on adding line/column number to these particular stacks.
A follow up could be to add this to Fizz prerender too but only in DEV.
## Summary
Moving towards deprecation of ReactTestRenderer. Log a warning on each
render so we can remove the exports in a future major version.
We can enable this flag in web RTR without disrupting RN tests by
flipping the flag in
`packages/shared/forks/ReactFeatureFlags.test-renderer.js`
## How did you test this change?
`yarn test
packages/react-test-renderer/src/__tests__/ReactTestRenderer-test.js`
## Summary
Fixing something I accidentally broke this in
25dbb3556e.
## How did you test this change?
Ran the following successfully:
```
$ yarn flow dom-node
```
## Summary
Changes the `enableComponentStackLocations` feature flag to be dynamic
for React Native (FB), so that it can be evaluated for compatibility
before eventually being enabled for React Native.
## How did you test this change?
I'll be importing this PR to test it.
Following https://github.com/facebook/react/pull/28265, this should
disable location-based component filters.
```
// Following __debugSource removal from Fiber, the new approach for finding the source location
// of a component, represented by the Fiber, is based on lazily generating and parsing component stack frames
// To find the original location, React DevTools will perform symbolication, source maps are required for that.
// In order to start filtering Fibers, we need to find location for all of them, which can't be done lazily.
// Eager symbolication can become quite expensive for large applications.
```
I am planning to publish a patch version of RDT soon, so I think its
better to remove this feature, instead of shipping it in a broken state.
The reason for filtering out these filters is a potential cases, where
we load filters from the backend (like in RN, where we storing some
settings on device), or these filters can be stored in user land
(`window.__REACT_DEVTOOLS_COMPONENT_FILTERS__`).
Explicitly tested the case when:
1. Load current RDT extension, add location-based component filter
2. Reload the page and observe that previously created component filter
is preserved
3. Re-load RDT extension with these changes, observe there is no
previously created component filter and user can't create a new
location-based filter
4. Reload RDT extension without these changes, no location-based filters
saved, user can create location-based filters
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
This solves the problem of the devtools extension failing to parse hook
names for components that make use of `useSyncExternalStore` or
`useTransition`.
See #27889
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
I tested this against my own codebases and against the example repro
project that I linked in #27889.
To test, I opened up the Components tab of the dev tools extension,
selected a component with hooks that make use of `useSyncExternalStore`
or `useTransition`, clicked the "parse hook names" magic wand button,
and observed that it now succeeds.
1. Bumps `react-virtualized-auto-sizer` to 1.0.23, which has a fix for
cases with multiple realms -
https://github.com/bvaughn/react-virtualized-auto-sizer/pull/82
2. Removes `react-window` from react-devtools-shared/src/node_modules,
now listed as dependency in `package.json` and bumped to 1.8.10
Tested:
- Chrome extension
- Standalone shell with RN
## Summary
Cleaning up internal usage of ReactTestRenderer
## How did you test this change?
`yarn test
packages/react-reconciler/src/__tests__/StrictEffectsMode-test.js`
Builds on top of #28384.
This prefixes each log with a badge similar to how we badge built-ins
like "ForwardRef" and "Memo" in the React DevTools. The idea is that we
can add such badges in DevTools for Server Components too to carry on
the consistency.
This puts the "environment" name in the badge which defaults to
"Server". So you know which source it is coming from.
We try to use the same styling as the React DevTools. We use light-dark
mode where available to support the two different color styles, but if
it's not available I use a fixed background so that it's always readable
even in dark mode.
In Terminals, instead of hard coding colors that might not look good
with some themes, I use the ANSI color code to flip
background/foreground colors in that case.
In earlier commits I had it on the end of the line similar to the
DevTools badges but for multiline I found it better to prefix it. We
could try various options tough.
In most cases we can use both ANSI and the `%c` CSS color specifier,
because node will only use ANSI and hide the other. Chrome supports both
but the color overrides ANSI if it comes later (and Chrome doesn't
support color inverting anyway). Safari/Firefox prints the ANSI, so it
can only use CSS colors.
Therefore in browser builds I exclude ANSI.
On the server I support both so if you use Chrome inspector on the
server, you get nice colors on both terminal and in the inspector.
Since Bun uses WebKit inspector and it prints the ANSI we can't safely
emit both there. However, we also can't emit just the color specifier
because then it prints in the terminal.
https://github.com/oven-sh/bun/issues/9021 So we just use a plain string
prefix for now with a bracket until that's fixed.
Screen shots:
<img width="758" alt="Screenshot 2024-02-21 at 12 56 02 AM"
src="https://github.com/facebook/react/assets/63648/4f887ffe-fffe-4402-bf2a-b7890986d60c">
<img width="759" alt="Screenshot 2024-02-21 at 12 56 24 AM"
src="https://github.com/facebook/react/assets/63648/f32d432f-f738-4872-a700-ea0a78e6c745">
<img width="514" alt="Screenshot 2024-02-21 at 12 57 10 AM"
src="https://github.com/facebook/react/assets/63648/205d2e82-75b7-4e2b-9d9c-aa9e2cbedf39">
<img width="489" alt="Screenshot 2024-02-21 at 12 57 34 AM"
src="https://github.com/facebook/react/assets/63648/ea52d1e4-b9fa-431d-ae9e-ccb87631f399">
<img width="516" alt="Screenshot 2024-02-21 at 12 58 23 AM"
src="https://github.com/facebook/react/assets/63648/52b50fac-bec0-471d-a457-1a10d8df9172">
<img width="956" alt="Screenshot 2024-02-21 at 12 58 56 AM"
src="https://github.com/facebook/react/assets/63648/0096ed61-5eff-4aa9-8a8a-2204e754bd1f">
When developing in an RSC environment, you should be able to work in a
single environment as if it was a unified environment. With thrown
errors we already serialize them and then rethrow them on the client.
Since by default we log them via onError both in Flight and Fizz, you
can get the same log in the RSC runtime, the SSR runtime and on the
client.
With console logs made in SSR renders, you typically replay the same
code during hydration on the client. So for example warnings already
show up both in the SSR logs and on the client (although not guaranteed
to be the same). You could just spend your time in the client and you'd
be fine.
Previously, RSC logs would not be replayed because they don't hydrate.
So it's easy to miss warnings for example.
With this approach, we replay RSC logs both during SSR so they end up in
the SSR logs and on the client. That way you can just stay in the
browser window during normal development cycles. You shouldn't have to
care if your component is a server or client component when working on
logical things or iterating on a product.
With this change, you probably should mostly ignore the Flight log
stream and just look at the client or maybe the SSR one. Unless you're
digging into something specific. In particular if you just naively run
both Flight and Fizz in the same terminal you get duplicates. I like to
run out fixtures `yarn dev:region` and `yarn dev:global` in two separate
terminals.
Console logs may contain complex objects which can be inspected. Ideally
a DevTools inspector could reach into the RSC server and remotely
inspect objects using the remote inspection protocol. That way complex
objects can be loaded on demand as you expand into them. However, that
is a complex environment to set up and the server might not even be
alive anymore by the time you inspect the objects. Therefore, I do a
best effort to serialize the objects using the RSC protocol but limit
the depth that can be rendered.
This feature is only own in dev mode since it can be expensive.
In a follow up, I'll give the logs a special styling treatment to
clearly differentiate them from logs coming from the client. As well as
deal with stacks.
## Summary
swaps `react-test-renderer` for `react-noop-rendererer` in
ReactCacheOld-test
## How did you test this change?
`yarn test-www ReactCacheOld`
When enableRefAsProp is on, we should always use the props as the source
of truth for refs. Not a field on the fiber.
In the case of string refs, this presents a problem, because string refs
are not passed around internally as strings; they are converted to
callback refs. The ref used by the reconciler is not the same as the one
the user provided.
But since this is a deprecated feature anyway, what we can do is clone
the props object and replace it with the internal callback ref. Then we
can continue to use the props object as the source of truth.
This means the internal callback ref will leak into userspace. The
receiving component will receive a callback ref even though the parent
passed a string. Which is weird, but again, this is a deprecated
feature, and we're only leaving it around behind a flag so that Meta can
keep using string refs temporarily while they finish migrating their
codebase.
This removes the remaining `propTypes` validation calls, making
declaring `propTypes` a no-op. In other words, React itself will no
longer validate the `propTypes` that you declare on your components.
In general, our recommendation is to use static type checking (e.g.
TypeScript). If you'd like to still run propTypes checks, you can do so
manually, same as you'd do outside React:
```js
import checkPropTypes from 'prop-types/checkPropTypes';
function Button(props) {
checkPropTypes(Button.propTypes, prop, 'prop', Button.name)
// ...
}
```
This could be automated as a Babel plugin if you want to keep these
checks implicit. (We will not be providing such a plugin, but someone in
community might be interested in building or maintaining one.)
## Summary
Cleaning up internal usage of ReactTestRenderer
## How did you test this change?
`yarn test packages/react/src/__tests__/ReactCreateRef-test.js`
## Summary
Cleaning up internal usage of ReactTestRenderer
## How did you test this change?
`yarn test
packages/use-subscription/src/__tests__/useSubscription-test.js`
## Summary
Cleaning up internal usage of ReactTestRenderer
## How did you test this change?
`yarn test
packages/react-reconciler/src/__tests__/ReactSuspense-test.internal.js`
Since this is more about specifically the streaming protocol and I'll
add other dimensions that don't map 1:1.
E.g. some configs need to be the same across all servers.
Depends on:
- #28317
- #28320
---
Changes the behavior of the JSX runtime to pass through `ref` as a
normal prop, rather than plucking it from the props object and storing
on the element.
This is a breaking change since it changes the type of the receiving
component. However, most code is unaffected since it's unlikely that a
component would have attempted to access a `ref` prop, since it was not
possible to get a reference to one.
`forwardRef` _will_ still pluck `ref` from the props object, though,
since it's extremely common for users to spread the props object onto
the inner component and pass `ref` as a differently named prop. This is
for maximum compatibility with existing code — the real impact of this
change is that `forwardRef` is no longer required.
Currently, refs are resolved during child reconciliation and stored on
the fiber. As a result of this change, we can move ref resolution to
happen only much later, and only for components that actually use them.
Then we can remove the `ref` field from the Fiber type. I have not yet
done that in this step, though.
Depends on:
- #28317
---
There's a ton of overlap between the createElement implementation and
the JSX implementation, so I combined them into a single module.
In the actual build output, the shared code between JSX and
createElement will get duplicated anyway, because react/jsx-runtime and
react (where createElement lives) are separate, flat build artifacts.
So this is more about code organization — with a few key exceptions, the
implementations of createElement and jsx are highly coupled.
There are too many layers to the JSX runtime implementation. I think
basically everything should be implemented in a single file, so that's
what I'm going to do.
As a first step, this deletes ReactJSXElementValidator and moves all the
code into ReactJSXElement. I can already see how this will help us
remove more indirections in the future.
Next I'm going to do start moving the `createElement` runtime into this
module as well, since there's a lot of duplicated code.
Certain fiber types may have a ref attached to them. The main ones are
HostComponent and ClassComponent. During the render phase, we check if a
ref was passed to it, and if so, we schedule a Ref effect: `markRef`.
Currently, we're not consistent about whether we call `markRef` in the
begin phase or the complete phase. For some fiber types, I found that
`markRef` was called in both phases, causing redundant work.
After some investigation, I don't believe it's necessary to call
`markRef` in both the begin phase and the complete phase, as long as you
don't bail out before calling `markRef`.
I though that maybe it had to do with the
`attemptEarlyBailoutIfNoScheduledUpdates` branch, which is a fast path
that skips the regular begin phase if no new props, state, or context
were passed. But if the props haven't changed (referentially — the
`memo` and `shouldComponentUpdate` checks happen later), then it follows
that the ref couldn't have changed either. This is true even in the old
`createElement` runtime where `ref` is stored on the element instead of
as a prop, because there's no way to pass a new ref to an element
without also passing new props. You might argue this is a leaky
assumption, but since we're shifting ref to be just a regular prop
anyway, I think it's the correct way to think about it going forward.
I think the pattern of calling `markRef` in the complete phase may have
been left over from an earlier iteration of the implementation before
the bailout logic was structured like it is today.
So, I removed all the `markRef` calls from the complete phase. In the
case of ScopeComponent, which had no corresponding call in the begin
phase, I added one.
We already had a test that asserted that a ref is reattached even if the
component bails out, but I added some new ones to be extra safe.
The reason I'm changing this this is because I'm working on a different
change to move the ref handling logic in `coerceRef` to happen in render
phase of the component that accepts the ref, instead of during the
parent's reconciliation.
This won't ever be serialized and is likely just a mistake.
This should be covered by the "use server" compiler since it ensures
that something that accepts a "this" won't be allowed to compile and if
it doesn't accept it, TypeScript should ideally forbid it to be passed.
So maybe this is unnecessary.
If an error happens before the shell, we need to handle it. In this case
we choose the strategy of rendering a blank document and client
rendering the app. Which will intentionally have a hydration mismatch.
It's possible for the same function instance to appear more than once in
the same graph or even the same file.
Currently this errors on trying to reconfigure the property but it
really doesn't matter which one wins. First or last.
Regardless there will be an entry point generated that can get them.
Alternative to #28354.
If a client reference is one of the props being describes as part of
another error, we call toString on it, which errors.
We should error explicitly when a Symbol prop is extracted.
However, pragmatically I added the toString symbol tag even though we
don't know what the real tostring will be but we also lie about the
typeof.
We can however in addition to this give it a different description
because describing this property as an object isn't quite right.
We probably could extract the export name but that's kind of renderer
specific and I just added this shared module to Fizz which doesn't have
that which is unfortunate an consequence.
For default exports we don't have a good name of what the alias was in
the receiver. Could maybe call it "default" but for now I just call it
"client".
Also warn for symbols.
It's weird because for objects we throw a hard error but functions we do
a dev only check. Mainly because we have an object branch anyway.
In the object branch we have some built-ins that have bad errors like
forwardRef and memo but since they're going to become functions later, I
didn't bother updating those. Once they're functions those names will be
part of this.
We have an unresolved conflict where the Flight client wants to execute
inside Fizz to emit side-effects like preloads (which can be early) into
that stream. However, the FormState API requires the state to be passed
at the root, so if you're getting that through the RSC payload it's a
Catch 22.
#27314 used a hack to mutate the form state array to fill it in later,
but that doesn't actually work because it's not always an array. It's
sometimes null like if there wasn't a POST. This lead to a bunch of
hydration errors - which doesn't have the best error message for this
case neither. It probably should error with something that specifies
that it's form state.
This fixes it by teeing the stream into two streams and consuming it
with two Flight clients. One to read the form state and one to emit
side-effects and read the root.
Adds some test cases for hook calls in object methods. Initially we didn't catch
these because InferTypes doesn't actually visit ObjectMethod bodies. Once we fix
that we correctly reject these examples.
> Don’t call Hooks inside loops, conditions, or nested functions
Per https://react.dev/warnings/invalid-hook-call-warning#breaking-rules-of-hooks
it is invalid to call hooks inside function expressions. We now validate this by
default, i'll verify internally before landing.
Note the validation is somewhat more conservative and we only disallow known
hook calls here, this seems like a reasonable tradeoff but i'm open to
suggestions. We could reuse the same known/potential hook mechanism here but it
would take some more refactoring.
Updates the compiler to understand Flow hook syntax. Like component syntax, in
infer mode hooks are compiled by default unless opted out.
Looking ahead, i can imagine splitting up our compilation modes as follows:
* Annotations: opt-in explicitly
* Declarations: annotations + component/hook declarations
* Infer: annotations, component/hook declarations, + component/hook-like
functions
This also suggest an alternative annotation strategy: "use react" (or "use
component" / "use hook") as a general way to tell the compiler that a function
is intended for React. Then opting out of memoization could do "use
react(nomemo)".
Updates LowerReactiveScopes to rewrite to a ReactiveFunctionValue
(ReactiveFunction-based) instead of a FunctionExpression (HIR-based). This lets
us include terminals and even nested reactive scopes in the result.
Per the previous PR, we don't have a way to rewrite an arbitrary subset of a
ReactiveFunction into a function expression, since FunctionExpression's contents
is still in HIR.
While long-term our plan is to move to HIR everywhere, this PR adds a stopgap of
adding a ReactiveFunctionValue variant of ReactiveValue. As a reminder,
ReactiveValue is a union of (HIR) InstructionValue | SequenceExpression |
LogicalExpression | ConditionalExpression.
For now i did a first stab at the visitors and transforms with the idea that:
* By default, visitors/transforms _don't_ look into these function expressions,
since we didn't previously traverse into (HIR-based) FunctionExpression either
* But there is a visitor/transform method that you can override if you need to.
Adds an example demonstrating why we need the ability to rewrite parts of a
ReactiveFunction into a function expression. Here, the reactive scope needs to
contain an `if` terminal, but we can't put a ReactiveIfTerminal inside a
function expression, since that expects HIR.
There are two main paths forward:
* Use HIR everywhere. I wrote this up and we're all agreed, it's just a bunch of
work.
* Add an alternative FunctionExpression variant to ReactiveFunction
For now i'm going to take the second route.
We want to start moving away from "Forget", so this PR adds support "use memo"
and "use no memo"
I've left "use forget" and "use no forget" directives unchanged for now, as we
need to migrate existing users first and then come back and delete support for
these directives.
ErrorBoundaries are currently not fully composable. The reason is if you
decide your boundary cannot handle a particular error and rethrow it to
higher boundary the React runtime does not understand that this throw is
a forward and it recreates the component stack from the Boundary
position. This loses fidelity and is especially bad if the boundary is
limited it what it handles and high up in the component tree.
This implementation uses a WeakMap to store component stacks for values
that are objects. If an error is rethrown from an ErrorBoundary the
stack will be pulled from the map if it exists. This doesn't work for
thrown primitives but this is uncommon and stashing the stack on the
primitive also wouldn't work
The newer version triggers an error due to require() not being compiled.
This was upgraded in #27328. I'm not sure why that was needed. Maybe it
was just because it was allowed by the caret and something else upgraded
but I haven't been able to make it work with the newer version. So I'll
just pin it.
Removes all `propTypes` validation called from outside the JSX
factories. Haven't touched JSX.
Tests that verify related behavior are stripped down to the
non-`propTypes` logic.
Add code frame to snap errors
This should make it easier (possible) to see if errors point at the right lines.
No idea why I had to add 1 to the column, you'd think it's all babel-standard
(whatever it is) and there wouldn't be off by one errors, but I'm not quite in
the mood to debug babel issues more then necessary right now...
This caused a build error when Forget was used in an Expo app as the
react-forget-runtime package was itself being compiled with Forget. This broke
Metro as metro serializes modules to iifes, but the import syntax that was
injected by the useMemoCachePolyfill flag was left behind
In practice I don't think the runtime package needs to ever be compiled by
Forget, so this PR opts out the whole file. This would also prevent builds from
breaking if someone decided to use the "all" compilation mode.
Test plan: Ran the expo app and verified that it now builds with no errors
Currently we only allow adding the directive to function bodies, but there may
be cases where we want to always opt out an entire module from being compiled by
Forget
The `reference` that is passed into `registerServerReference` can be a
plain function. It does not need to have the three additonal properties
of a `ServerRefeference`. In fact, adding these properties (plus `bind`)
is precisely what `registerServerReference` does.
Same as #28327 but for Fizz.
One thing that's weird about this recoverable error is that we don't
send the regular stack for it, just the component stack it seems. This
is missing some potential information and if we move toward integrated
since stacks it would be one thing.
A labeled block will generally end with an implicit break out of the label.
However, if there are no _explicit_ breaks to the label, we'll end up with a
ReactiveFunction along the lines of:
```
bb1: {
...instructions with no explicit `break bb1`...
(implicit) break;
}
```
The `PruneUnusedLabels` pass removes such unused labels, inlining the content of
label terminal into the surrounding block. However, we weren't pruning the
`break`! This wasn't a problem in practice since codegen, and future passes,
would just ignore this. But it's more correct to go and find these unnecessary
implicit breaks and prune them, which this PR does.
Again, this shouldn't have any impact other than producing cleaner
ReactiveFunction data during debugging.
Also deals with symbols. Alternative to #28312.
We currently always normalize rejections or thrown values into `Error`
objects. Partly because in prod it'll be an error object and you
shouldn't fork behavior on knowing the value outside a digest. We might
want to even make the message always opaque to avoid being tempted and
then discover in prod that it doesn't work.
However, we do include the message in DEV.
If this is a non-Error object we don't know what the properties mean.
Ofc, we don't want to include too much information in the rendered
string, so we use the general `describeObjectForErrorMessage` helper.
Unfortunately it's pretty conservative about emitting values so it's
likely to exclude any embedded string atm. Could potentially expand it a
bit.
We could in theory try to serialize as much as possible and re-throw the
actual object to allow for inspection to be expanded inside devtools
which is what I plan on for consoles, but since we're normalizing to an
Error this is in conflict with that approach.
Continuing on my quest to clean up our feature flags, the logic for merging
consecutive feature flags is stable. Let's remove
`@enableMergeConsecutiveScopes` since this is enabled everywhere.
Some components stop being components over time and are used as regular
functions instead, but they may have lingering hook calls. Those hook calls make
it so the capitalized function calling them do not error (they appear to be a
function to existing eslint rules), but they are nonetheless unsafe to memoize.
This diff adds a conservative option to bail out on all capitalized function
calls.
There are a handful of known-non-component capitalized functions, like
`Boolean`, `String`, and `Number`. This diff also adds the ability to supply
capitalized function names that should not be considered in this analysis.
I added three tests:
1. Ensure an error occurs in the obvious case
2. Ensure an error occurs when the value is aliased simply
3. Ensure the allowlist works
This is my first commit so please go hard on me. I was unsure about where this
code should live, so please nitpick.
In preparation for https://github.com/facebook/react/pull/28207.
These tests aren't actually testing propTypes, they just use them to
verify we can display a meaningful component name. We've mostly moved
away from warnings that display component names directly in favor of
component stacks. So let's just replace these with tests asserting the
component names show up in stacks.
Part of https://github.com/facebook/react/pull/28207, this is easy to
land in isolation.
The approach I'm taking is slightly different — instead of leaving
validation on for legacy context, I disable the validation (it's
DEV-only) and leave just the parts that drive the runtime logic. I.e.
`contexTypes` and `childContextTypes` *values* are now ignored, the keys
are used just like before.
This option was added defensively but it's not needed. There's no cost
to including it always.
I suspect this optional was added mainly to avoid needing to update
tests. That's not a reason to have an unnecessary public API though.
We have a praxis for dealing with source location in tests to avoid them
failing tests. I also ported them to inline snapshots so that additions
to the protocol isn't such a pain.
All our sources are considered third party and should be hidden in stack
traces unless expanded. Our internals aren't actionable anyway.
This doesn't really do much without tooling that actually forwards this
to new generated source maps, in which case they probably just add them
to ignorelist anyway.
Previously, `<Context>` was equivalent to `<Context.Consumer>`. However,
since the introduction of Hooks, the `<Context.Consumer>` API is rarely
used. The goal here is to make the common case cleaner:
```js
const ThemeContext = createContext('light')
function App() {
return (
<ThemeContext value="dark">
...
</ThemeContext>
)
}
function Button() {
const theme = use(ThemeContext)
// ...
}
```
This is technically a breaking change, but we've been warning about
rendering `<Context>` directly for several years by now, so it's
unlikely much code in the wild depends on the old behavior. [Proof that
it warns today (check
console).](https://codesandbox.io/p/sandbox/peaceful-nobel-pdxtfl)
---
**The relevant commit is 5696782b428a5ace96e66c1857e13249b6c07958.** It
switches `createContext` implementation so that `Context.Provider ===
Context`.
The main assumption that changed is that a Provider's fiber type is now
the context itself (rather than an intermediate object). Whereas a
Consumer's fiber type is now always an intermediate object (rather than
it being sometimes the context itself and sometimes an intermediate
object).
My methodology was to start with the relevant symbols, work tags, and
types, and work my way backwards to all usages.
This might break tooling that depends on inspecting React's internal
fields. I've added DevTools support in the second commit. This didn't
need explicit versioning—the structure tells us enough.
There are three parts to an RSC set up:
- React
- Bundler
- Endpoints
Most customizability is in the bundler configs. We deal with those as
custom builds.
To create a full set up, you need to also configure ways to expose end
points for example to call a Server Action. That's typically not
something the bundler is responsible for even though it's responsible
for gathering the end points that needs generation. Exposing which
endpoints to generate is a responsibility for the bundler.
Typically a meta-framework is responsible for generating the end points.
There's two ways to "call" a Server Action. Through JS and through a
Form. Through JS we expose the `callServer` callback so that the
framework can call the end point.
Forms by default POST back to the current page with an action serialized
into form data, which we have a decoder helper for. However, this is not
something that React is really opinionated about just like we're not
opinionated about the protocol used by callServer.
This exposes an option to configure the encoding of the form props.
`encodeFormAction` is to the SSR is what `callServer` is to the Browser.
Alternative to #28295.
Instead of stashing all of the Usables eagerly, we can extract them by
replaying the render when we need them like we do with any other hook.
We already had an implementation of `use()` but it wasn't quite
complete.
These can also include further DebugInfo on them such as what Server
Component rendered the Promise or async debug info. This is nice just to
see which use() calls were made in the side-panel but it can also be
used to gather everything that might have suspended.
Together with https://github.com/facebook/react/pull/28286 we cover the
case when a Promise was used a child and if it was unwrapped with use().
Notably we don't cover a Promise that was thrown (although we do support
that in a Server Component which maybe we shouldn't). Throwing a Promise
isn't officially supported though and that use case should move to the
use() Hook.
The pattern of conditionally suspending based on cache also isn't really
supported with the use() pattern. You should always call use() if you
previously called use() with the same input. This also ensures that we
can track what might have suspended rather than what actually did.
One limitation of this strategy is that it's hard to find all the places
something might suspend in a tree without rerendering all the fibers
again. So we might need to still add something to the tree to indicate
which Fibers may have further debug info / thenables.
That way we can use it for debug information like component stacks and
DevTools. I used an extra stack argument in Child Fiber to track this as
it's flowing down since it's not just elements where we have this info
readily available but parent arrays and lazy can merge this into the
Fiber too. It's not great that this is a dev-only argument and I could
track it globally but seems more likely to make mistakes.
It is possible for the same debug info to appear for multiple child
fibers like when it's attached to a fragment or a lazy that resolves to
a fragment at the root. The object identity could be used in these
scenarios to infer if that's really one server component that's a parent
of all children or if each child has a server component with the same
name.
This is effectively a public API because you can use it to stash
information on Promises from a third-party service - not just Server
Components. I started outline the types for this for some things I was
planning to add but it's not final.
I was also planning on storing it from `use(thenable)` for when you
suspend on a Promise. However, I realized that there's no Hook instance
for those to stash it on. So it might need a separate data structure to
stash the previous pass over of `use()` that resets each render.
No tests yet since I didn't want to test internals but it'll be covered
once we have debugging features like component stacks.
This pains me because `React.Children` is really already
pseudo-deprecated.
`React.Children` takes any children that `React.Node` takes. We now
support Lazy and Thenable in this position elsewhere, but it errors in
`React.Children`.
This becomes an issue with async Server Components which can resolve
into a Lazy and in the future Lazy will just become Thenables. Which
causes this to error.
There are a few different semantics we could have:
1) Error like we already do (#28280). `React.Children` is about
introspecting children. It was always sketchy because you can't
introspect inside an abstraction anyway. With Server Components we fold
away the components so you can actually introspect inside of them kind
of but what they do is an implementation detail and you should be able
to turn it into a Client Component at any point. The type of an Element
passing the boundary actually reduces to `React.Node`.
2) Suspend and unwrap the Node (this PR). If we assume that Children is
called inside of render, then throwing a Promise if it's not already
loaded or unwrapping would treat it as if it wasn't there. Just like if
you rendered it in React. This lets you introspect what's inside which
isn't really something you should be able to do. This isn't compatible
with deprecating throwing-a-Promise and enable static compilation like
`use()` does. We'd have to deprecate `React.Children` before doing that
which we might anyway.
3) Wrap in a Fragment. If a Server Component was instead a Client
Component, you couldn't introspect through it anyway. Another
alternative might be to let it pass through but then it wouldn't be
given a flat key. We could also wrap it in a Fragment that is keyed.
That way you're always seeing an element. The issue with this solution
is that it wouldn't see the key of the Server Component since that gets
forwarded to the child that is yet to resolve. The nice thing about that
strategy is it doesn't depend on throw-a-Promise but it might not be
keyed correctly when things move.
A Flight Server can be a consumer of a stream from another Server. In
this case the meta data is attached to debugInfo properties on lazy,
Promises, Arrays or Elements that might in turn get forwarded to the
next stream. In this case we want to forward this debug information to
the client in the stream.
I also added a DEV only `environmentName` option to the Flight Server.
This lets you name the server that is producing the debug info so that
you can trace the origin of where that component is executing. This
defaults to `"server"`. DevTools could use this for badges or different
colors.
In our custom implementation for handling modals dismiss signal, we use
element's `ownerDocument` field, which expectedly doesn't work well with
shadow root. Now using
[`getRootNode`](https://developer.mozilla.org/en-US/docs/Web/API/Node/getRootNode)
instead of `ownerDocument` to support shadow root case.
Without this, if RDT Frontend is hosted inside the shadow root, the
modal gets closed after any click, including on the buttons hosted by
modal:
00d42ac354/packages/react-devtools-shared/src/devtools/views/hooks.js (L228-L238)
Test plan:
- Modals work as expected for Chrome DevTools integration
- Modals work as expected at every other surfaces: browser extension,
electron wrapper for RN, inline version for web
The hook guards are incompatible with using a forget-runtime. Specifically,
forget-runtime needs to make a call to `useState()` or some other hook to attach
data to the fiber, but all the builtin hooks are overridden to disallow calling
them outside of explicit boundaries. We'd either have to wrap the useMemoCache
call in a push/pop to allow it to call other hooks, or as in this PR, just move
it outside the enforcement.
These validations needs to be able to transitively check for violations within
function expressions, without immediately erroring. So the inner "-Impl" helpers
return a Result. But the outer, exported validate functions don't need to return
a Result, especially since TS has no Rust-style enforcement that return values
are actually used. Unwrapping within the validation means the caller can't
forget to do so and inadvertently silence the errors.
I had split this up from the main validation since function validation was less
precise; now that previous PRs fix the false positives we can remove this extra
flag.
This pass doesn't really make sense in light of
`@enableTransitivelyFreezeFunctionExpressions`. The original idea of
ValidateFrozenLambdas was that trying to pass a "mutable" lambda to a frozen
value was invalid. But since then we've realized that the better heuristic is
that freezing a lambda is transitive.
Rewrites the validation to not rely on the mutable range of functions to
determine whether they are called or not, since the range can be extended for
other reasons (they happen to reference a mutable value that is mutated later,
even though the function isn't called during render).
Instead we use the same approach as validateNoSetStateInRender, explicitly
tracking references to function expressions that access refs, and checking if
those function expressions appear to be called. This can have false negatives,
as with the setState validation, but catches lots of obviously incorrect code
without false positives.
Fixes T178003134. Previously we did not check whether values reassigned during a
destructuring assignment were context variables. This would either miscompile,
or as of my fix earlier in #2579, would fail validation. Specifically, this
happened on AssignmentEpression with an object/array pattern lvalue, where the
pattern contained an identifier that is a context variable.
This is now fixed: we track whether the outermost assignment is a normal
assignment or destructuring, and force destructuring to a temporary whenever the
identifier is a context variable. We apply the same logic to variable
declarations that are destructuring to a context variable.
---
I recall adding the navigator override because some React library file had done
an unconditional access, but this doesn't seem to be the case anymore.
Regardless, newer versions of nodejs comes with a global `navigator` [see
thread](https://github.com/nodejs/node/issues/39540) that error on writes
Turn this on
Edited: ope, nvm
<details>
Looks like there's still an outstanding issue with this. The original PR
turned off a strict effects test, which causes a stray
`componentWillUnmount` to fire.
5d1ce65139 (diff-19df471970763c4790c2cc0811fd2726cc6a891b0e1d5dedbf6d0599240c127aR70)
Before:
```js
expect(log).toEqual([
'constructor',
'constructor',
'getDerivedStateFromProps',
'getDerivedStateFromProps',
'render',
'render',
'componentDidMount',
]);
```
After:
```js
expect(log).toEqual([
'constructor',
'constructor',
'getDerivedStateFromProps',
'getDerivedStateFromProps',
'render',
'render',
'componentDidMount',
'componentWillUnmount',
'componentDidMount',
]);
```
So there's a bug somewhere
</details>
Fixes the one case discovered in the previous PR; for AssignmentExpression we
correctly lowered the store instruction to a local/context, but then always used
a `LoadLocal` to read the result back.
The load instruction appears like it might be dangling - i think what was
happening is that DCE cleaned up the unused LoadLocal whereas it leaves the
LoadContext alone. But this works for now, we can always clean up the extra
instruction later since this case isn't too common.
Validates that all references to a variable (pre-SSA) are consistently "local"
references or "context" references. Ie, if a variable is declared as
DeclareContext, any accesses must be eg LoadContext or StoreContext, not
LoadLocal/StoreLocal. This will help with the issue from #2577 (assuming that we
know a variable _is_ a context variable) but also provides a more precise
bailout for an existing case with destructuring assignment to a context
variable.
This is a partial redo of https://github.com/facebook/react/pull/26625.
Since that was unlanded due to some detected breakages. This now
includes a feature flag to be careful in rolling this out.
In #28123 I switched these to be lazy references. However that creates a
lazy wrapper even if they're synchronously available. We try to as much
as possible preserve the original data structure in these cases.
E.g. here in the dev outlining I only use a lazy wrapper if it didn't
complete synchronously:
https://github.com/facebook/react/pull/28272/files#diff-d4c9c509922b3671d3ecce4e051df66dd5c3d38ff913c7a7fe94abc3ba2ed72eR638
Unfortunately we don't have a data structure that tracks the status of
each emitted row. We could store the task in the map but then they
couldn't be GC:ed as they complete. We could maybe store the status of
each element but seems so heavy.
For now I just went back to direct reference which might be an issue
since it can suspend something higher up when deduped.
We could in theory actually support this case by throwing a Promise when
it's used inside a render. Allowing it to be synchronously unwrapped.
However, it's a bit sketchy because we officially only support this in
the render's child position or in `use()`.
Another alternative could be to actually pass the Promise/Lazy to the
callback so that you can reason about it and just return it again or
even unwrapping with `use()` - at least for the forEach case maybe.
## Overview
For events, the browser will yield to microtasks between calling event
handers, allowing time to flush work inbetween. For example, in the
browser, this code will log the flushes between events:
```js
<body onclick="console.log('body'); Promise.resolve().then(() => console.log('flush body'));">
<div onclick="console.log('div'); Promise.resolve().then(() => console.log('flush div'));">
hi
</div>
</body>
// Logs
div
flush div
body
flush body
```
[Sandbox](https://codesandbox.io/s/eloquent-noether-mw2cjg?file=/index.html)
The problem is, `dispatchEvent` (either in the browser, or JSDOM) does
not yield to microtasks. Which means, this code will log the flushes
after the events:
```js
const target = document.getElementsByTagName("div")[0];
const nativeEvent = document.createEvent("Event");
nativeEvent.initEvent("click", true, true);
target.dispatchEvent(nativeEvent);
// Logs
div
body
flush div
flush body
```
## The problem
This mostly isn't a problem because React attaches event handler at the
root, and calls the event handlers on components via the synthetic event
system. We handle flushing between calling event handlers as needed.
However, if you're mixing capture and bubbling events, or using multiple
roots, then the problem of not flushing microtasks between events can
come into play. This was found when converting a test to `createRoot` in
https://github.com/facebook/react/pull/28050#discussion_r1462118422, and
that test is an example of where this is an issue with nested roots.
Here's a sandox for
[discrete](https://codesandbox.io/p/sandbox/red-http-2wg8k5) and
[continuous](https://codesandbox.io/p/sandbox/gracious-voice-6r7tsc?file=%2Fsrc%2Findex.js%3A25%2C28)
events, showing how the test should behave. The existing test, when
switched to `createRoot` matches the browser behavior for continuous
events, but not discrete. Continuous events should be batched, and
discrete should flush individually.
## The fix
This PR implements the fix suggested by @sebmarkbage, to manually
traverse the path up from the element and dispatch events, yielding
between each call.
This adds a new DEV-only row type `D` for DebugInfo. If we see this in
prod, that's an error. It can contain extra debug information about the
Server Components (or Promises) that were compiled away during the
server render. It's DEV-only since this can contain sensitive
information (similar to errors) and since it'll be a lot of data, but
it's worth using the same stream for simplicity rather than a
side-channel.
In this first pass it's just the Server Component's name but I'll keep
adding more debug info to the stream, and it won't always just be a
Server Component's stack frame.
Each row can get more debug rows data streaming in as it resolves and
renders multiple server components in a row.
The data structure is just a side-channel and it would be perfectly fine
to ignore the D rows and it would behave the same as prod. With this
data structure though the data is associated with the row ID / chunk, so
you can't have inline meta data. This means that an inline Server
Component that doesn't get an ID otherwise will need to be outlined. The
way I outline Server Components is using a direct reference where it's
synchronous though so on the client side it behaves the same (i.e.
there's no lazy wrapper in this case).
In most cases the `_debugInfo` is on the Promises that we yield and we
also expose this on the `React.Lazy` wrappers. In the case where it's a
synchronous render it might attach this data to Elements or Arrays
(fragments) too.
In a future PR I'll wire this information up with Fiber to stash it in
the Fiber data structures so that DevTools can pick it up. This property
and the information in it is not limited to Server Components. The name
of the property that we look for probably shouldn't be `_debugInfo`
since it's semi-public. Should consider the name we use for that.
If it's a synchronous render that returns a string or number (text node)
then we don't have anywhere to attach them to. We could add a
`React.Lazy` wrapper for those but I chose to prioritize keeping the
data structure untouched. Can be useful if you use Server Components to
render data instead of React Nodes.
Along with all the places using it like the `_debugSource` on Fiber.
This still lets them be passed into `createElement` (and JSX dev
runtime) since those can still be used in existing already compiled code
and we don't want that to start spreading to DOM attributes.
We used to have a DEV mode that compiles the source location of JSX into
the compiled output. This was nice because we could get the actual call
site of the JSX (instead of just somewhere in the component). It had a
bunch of issues though:
- It only works with JSX.
- The way this source location is compiled is different in all the
pipelines along the way. It relies on this transform being first and the
source location we want to extract but it doesn't get preserved along
source maps and don't have a way to be connected to the source hosted by
the source maps. Ideally it should just use the mechanism other source
maps use.
- Since it's expensive it only works in DEV so if it's used for
component stacks it would vary between dev and prod.
- It only captures the callsite of the JSX and not the stack between the
component and that callsite. In the happy case it's in the component but
not always.
Instead, we have another zero-cost trick to extract the call site of
each component lazily only if it's needed. This ensures that component
stacks are the same in DEV and PROD. At the cost of worse line number
information.
The better way to get the JSX call site would be to get it from `new
Error()` or `console.createTask()` inside the JSX runtime which can
capture the whole stack in a consistent way with other source mappings.
We might explore that in the future.
This removes source location info from React DevTools and React Native
Inspector. The "jump to source code" feature or inspection can be made
lazy instead by invoking the lazy component stack frame generation. That
way it can be made to work in prod too. The filtering based on file path
is a bit trickier.
When redesigned this UI should ideally also account for more than one
stack frame.
With this change the DEV only Babel transforms are effectively
deprecated since they're not necessary for anything.
These used to be reserved props because the classic React.createElement
runtime passed this data as props, whereas the jsxDEV() runtime passes
them as separate arguments.
This brings us incrementally closer to being able to pass the props
object directly through to React instead of cloning a subset into a new
object.
The React.createElement runtime is unaffected.
This used to be trivial but it's no longer trivial.
In Fizz and Fiber this is split into renderWithHooks and
finishFunctionComponent since they also support indeterminate
components.
Interestingly thanks to this unification we always call functions with
an arity of 2 which is a bit weird - with the second argument being
undefined in everything except forwardRef and legacy context consumers.
This makes Flight makes the same thing but we could also call it with an
arity of 1.
Since Flight errors early if you try to pass it a ref, and there's no
legacy context, the second arg is always undefined.
The practical change in this PR is that returning a Promise from a
forwardRef now turns it into a lazy. We previously didn't support async
forwardRef since it wasn't supported on the client. However, since
eventually this will be supported by child-as-a-promise it seems fine to
support it.
The JSX runtime (both the new one and the classic createElement runtime)
check for reserved props like `key` and `ref` by doing a lookup in a
plain object map with `hasOwnProperty`.
There are only a few reserved props so this inlines the checks instead.
Every time we create a task we need to wait for it so we increase a ref
count. We can do this in `createTask`. This is in line with what Fizz
does too.
They differ in that Flight counts when they're actually flushed where as
Fizz decrements them when they complete.
Flight should probably count them when they complete so it's possible to
wait for the end before flushing for buffering purposes.
Not sure how this happened but there are two identical implementations
of the jsx and jsxDEV functions. One of them was unreachable. I deleted
that one.
Fixes T176436488. The logic for rewriting Destructure instructions was correct,
but the visitor implementation was accidentally dropping subsequent Destructure
instructions within a block after encountering one that needed a rewrite.
Switching to use the transform infra (added after this pass was written) fixes
it.
Instead of createElement.
We should have done this when we initially released jsx-runtime but
better late than never. The general principle is that our tests should
be written using the most up-to-date idioms that we recommend for users,
except when explicitly testing an edge case or legacy behavior, like for
backwards compatibility.
Most of the diff is related to tweaking test output and isn't very
interesting.
I did have to workaround an issue related to component stacks. The
component stack logic depends on shared state that lives in the React
module. The problem is that most of our tests reset the React module
state and re-require a fresh instance of React, React DOM, etc. However,
the JSX runtime is not re-required because it's injected by the compiler
as a static import. This means its copy of the shared state is no longer
the same as the one used by React, causing any warning logged by the JSX
runtime to not include a component stack. (This same issue also breaks
string refs, but since we're removing those soon I'm not so concerned
about that.) The solution I went with for now is to mock the JSX runtime
with a proxy that re-requires the module on every function invocation. I
don't love this but it will have to do for now. What we should really do
is migrate our tests away from manually resetting the module state and
use import syntax instead.
Adds a feature flag to control whether the client cache function is just
a passthrough. before we land breaking changes for the next major it
will be off and then we can flag it on when we want to break it.
flag is off for OSS for now and on elsewhere (though the parent flag
enableCache is off in some cases)
This is not that big a deal but a constant papercut, i often want to jump
directly to watch mode with a filter applied. I know @poteto likes to (or at
least used to) run watch with update enabled. Now instead of passing a mode, you
can pass `--watch`, `--filter`, and `--update` independently.
Server Context was never documented, and has been deprecated in
https://github.com/facebook/react/pull/27424.
This PR removes it completely, including the implementation code.
Notably, `useContext` is removed from the shared subset, so importing it
from a React Server environment would now should be a build error in
environments that are able to enforce that.
---
This change simply logs on every function we encounter with a `use no forget`
directive. A few nuances -- `compilationMode: "infer"` only compiles functions
we infer to be 'react functions'.
```js
// `add` would not be compiled, as it has no jsx, no hook calls,
// and is not named as a component or hook
function add(a, b) {
return a + b;
}
```
With this PR, we would report todos for functions that Forget wouldn't
ordinarily try to compile.
```js
// Todo: Skipped due to "use no forget" directive.
function add(a, b) {
"use no forget";
return a + b;
}
```
This seems fine to me as (1) it's a bit nonsensical to have a `use no forget`
direction on a non-react function, and (2) we're goalling on getting `use no
forget`s down to 0.
The goal of this PR is to move towards a uniform representation for all type
declarations, whether they are named type aliases, function declarations, or
inline annotations. We now assign every non-primitive type declaration (named or
anonymous) a unique DeclarationId. In the next PR, we'll also re-map inline
annotations back to this declaration id when encountering them.
This PR is extremely gross and my intent is to refactor a bunch of things in the
HIR to allow this to be less gross. Challenges:
* Babel name resolution requires using scopes but i really want to just work
with plain nodes, since NodePath and TypeScript do _not_ get along. So here, i
find all identifiers and store a mapping of identifier -> scope, so that i can
later look them up if necessary.
* HIR doesn't have a notion of a declaration id, and in general we don't want
to extend HIR. So i end up with a whole bunch of side table information and
indirection. For example, a function doesn't know it's own declaration id.
So we have to look it up. Function params don't track their Forest type, so
we have to look them up on the function declaration. Etc.
Conceptually a Server Component in the tree is the same as a Client
Component.
When we render a Server Component with a key, that key should be used as
part of the reconciliation process to ensure the children's state are
preserved when they move in a set. The key of a child should also be
used to clear the state of the children when that key changes.
Conversely, if a Server Component doesn't have a key it should get an
implicit key based on the slot number. It should not inherit the key of
its children since the children don't know if that would collide with
other keys in the set the Server Component is rendered in.
A Client Component also has an identity based on the function's
implementation type. That mainly has to do with the state (or future
state after a refactor) that Component might contain. To transfer state
between two implementations it needs to be of the same state type. This
is not a concern for a Server Components since they never have state so
identity doesn't matter.
A Component returns a set of children. If it returns a single child,
that's the same as returning a fragment of one child. So if you
conditionally return a single child or a fragment, they should
technically reconcile against each other.
The simple way to do this is to simply emit a Fragment for every Server
Component. That would be correct in all cases. Unfortunately that is
also unfortunate since it bloats the payload in the common cases. It
also means that Fiber creates an extra indirection in the runtime.
Ideally we want to fold Server Component aways into zero cost on the
client. At least where possible. The common cases are that you don't
specify a key on a single return child, and that you do specify a key on
a Server Component in a dynamic set.
The approach in this PR treats a Server Component that returns other
Server Components or Lazy Nodes as a sequence that can be folded away.
I.e. the parts that don't generate any output in the RSC payload.
Instead, it keeps track of their keys on an internal "context". Which
gets reset after each new reified JSON node gets rendered.
Then we transfer the accumulated keys from any parent Server Components
onto the child element. In the simple case, the child just inherits the
key of the parent.
If the Server Component itself is keyless but a child isn't, we have to
add a wrapper fragment to ensure that this fragment gets the implicit
key but we can still use the key to reset state. This is unusual though
because typically if you keyed something it's because it was already in
a fragment.
In the case a Server Component is keyed but forks its children using a
fragment, we need to key that fragment so that the whole set can move
around as one. In theory this could be flattened into a parent array but
that gets tricky if something suspends, because then we can't send the
siblings early.
The main downside of this approach is that switching between single
child and fragment in a Server Component isn't always going to reconcile
against each other. That's because if we saw a single child first, we'd
have to add the fragment preemptively in case it forks later. This
semantic of React isn't very well known anyway and it might be ok to
break it here for pragmatic reasons. The tests document this
discrepancy.
Another compromise of this approach is that when combining keys we don't
escape them fully. We instead just use a simple `,` separated concat.
This is probably good enough in practice. Additionally, since we don't
encode the implicit 0 index slot key, you can move things around between
parents which shouldn't really reconcile but does. This keeps the keys
shorter and more human readable.
Partially reverting what has been removed in
https://github.com/facebook/react/pull/28186.
We need `'scheduler/tracing'` mock for React >= 16.8.
The error:
```
Invariant Violation: It is not supported to run the profiling version of a renderer (for example, `react-dom/profiling`) without also replacing the `scheduler/tracing` module with `scheduler/tracing-profiling`. Your bundler might have a setting for aliasing both modules. Learn more at http://fb.me/react-profiling
```
Validated by running regression tests for the whole version matrix:
```
./scripts/circleci/download_devtools_regression_build.js 16.0 --replaceBuild && node ./scripts/jest/jest-cli.js --build --project devtools --release-channel=experimental --reactVersion 16.0 --ci && ./scripts/circleci/download_devtools_regression_build.js 16.5 --replaceBuild && node ./scripts/jest/jest-cli.js --build --project devtools --release-channel=experimental --reactVersion 16.5 --ci && ./scripts/circleci/download_devtools_regression_build.js 16.8 --replaceBuild && node ./scripts/jest/jest-cli.js --build --project devtools --release-channel=experimental --reactVersion 16.8 --ci && ./scripts/circleci/download_devtools_regression_build.js 17.0 --replaceBuild && node ./scripts/jest/jest-cli.js --build --project devtools --release-channel=experimental --reactVersion 17.0 --ci && ./scripts/circleci/download_devtools_regression_build.js 18.0 --replaceBuild && node ./scripts/jest/jest-cli.js --build --project devtools --release-channel=experimental --reactVersion 18.0 --ci
```
Adding getter-functions for renderer implementations, which can be used
for jest tests. If we are testing against React with version < 18, we
are going to use legacy rendering, otherwise the concurrent one.
- Moving `act` implementation to a single getter-function, which is
based on React version we are testing RDT against.
- Removing unused mocks for `act`, which were designed for legacy
versions of React, validated with running tests against React 16 build.
## Summary
Add support for `useFormState` Hook fixing "Unsupported hook in the
react-debug-tools package: Missing method in Dispatcher: useFormState"
when inspecting components using `useFormState`
## How did you test this change?
- Added test to ReactHooksInspectionIntegration
- Added dedicated section for form actions to devtools-shell

## Summary
Add support for `useOptimistic` Hook fixing "Unsupported hook in the
react-debug-tools package: Missing method in Dispatcher: useOptimistic"
when inspecting components using `useOptimistic`
## How did you test this change?
- Added test following the same pattern as for `useDeferredValue`
Adds a new entrypoint for the production jsx-runtime when using
react-server condition. Currently the entrypoints are the same but in
the future we will potentially change the implementation of the runtime
in ways that can only be optimized for react-server constraints and we
want to have the entrypoint already separated so environments using it
will be pulling in the right version
## Summary
Converts `ReactTestUtils.renderIntoDocument` and `ReactDOM.findDOMNode`
to `ReactDOMClient.createRoot`
## How did you test this change?
`yarn test ReactElementValidator`
Not sure if this was also meant to test findDOMNode. But sounded like it
was more interested in the rendering aspect and findDOMNode was just
used as a utility. If we want to keep the findDOMNode tests, I'd just
rename it to a legacy test to indicate it needs to be flagged.
## Overview
Branched off https://github.com/facebook/react/pull/28130
### ~Failing~ Fixed by @eps1lon
Most of the tests pass, but there are 3 tests that have additional
warnings due to client render error retries.
For example, before we would log:
```
Warning: Do not call Hooks inside useEffect(...), useMemo(...), or other built-in Hooks.
Warning: Expected server HTML to contain a matching text node for "0" in <div>.
```
And now we log
```
Warning: Do not call Hooks inside useEffect(...), useMemo(...), or other built-in Hooks.
Warning: Expected server HTML to contain a matching text node for "0" in <div>.
Warning: Do not call Hooks inside useEffect(...), useMemo(...), or other built-in Hooks.
```
We can't just update the expected error count for these tests, because
the additional error only happens on the client. So I need some guidance
on how to fix these.
---------
Co-authored-by: Sebastian Silbermann <sebastian.silbermann@klarna.com>
## Overview
Branched off https://github.com/facebook/react/pull/28130
## ~Failing~ Fixed by @eps1lon
The tests are currently failing because of two tests covering special
characters. I've tried a few ways to fix, but I'm stuck and will need
some help understanding why they fail and how to fix.
---------
Co-authored-by: Sebastian Silbermann <sebastian.silbermann@klarna.com>
## Overview
Branched off https://github.com/facebook/react/pull/28130
In `hydrateRoot`, we now error if you pass `undefined`:
```
Warning: Must provide initial children as second argument to hydrateRoot.
```
So we expect 1 error for this now.
## Overview
Branched off https://github.com/facebook/react/pull/28130
## React for count changing
### Before
These tests are weird because on main they pass, but log to the console:
```
We expected 2 warning(s), but saw 1 warning(s).
We saw these warnings:
Warning: Expected server HTML to contain a matching <select> in <div>.
at select
```
The other one is ignored. The `expect(console.errors).toBeCalledWith(2)`
doesn't account for ignored calls, so the test passes with the two
expected (the +1 is in the test utiles). The ignored warning is
```
Warning: ReactDOM.hydrate is no longer supported in React 18. Use hydrateRoot instead.
```
So the mismatch is in the ignored warnings.
### After
After switching to `createRoot`, it still logs:
```
We expected 2 warning(s), but saw 1 warning(s).
We saw these warnings:
Warning: Expected server HTML to contain a matching <select> in <div>.
at select
```
But the test fails due to an unexpected error count. The new ignored
errors are:
```
Error: Uncaught [Error: Hydration failed because the initial UI does not match what was rendered on the server.]
Warning: An error occurred during hydration. The server HTML was replaced with client content in <div>.
Error: Hydration failed because the initial UI does not match what was rendered on the server.
Error: There was an error while hydrating. Because the error happened outside of a Suspense boundary, the entire root will switch to client rendering.
```
These seem to be the correct warnings to fire in `createRoot`, so the
fix is to update the number of warnings we expect.
## Overview
Adds support for `ReactDOMClient` for `ServerIntegration*` tests.
Also converts tests that pass without any other changes. Will follow up
with other PRs for more complex cases.
There's no need to separate strict mode from strict effects mode any
more.
I didn't clean up the `StrictEffectMode` fiber flag, because it's used
to prevent strict effects in legacy mode. I could replace those checks
with `LegacyMode` checks, but when we remove legacy mode, we can remove
that flag and condense them into one StrictMode flag away.
## Summary
refactors ReactElement-test to use `createRoot` instead of
`renderIntoDocument`, which uses `ReactDOM.render` under the hood
## How did you test this change?
`yarn test ReactElement`
## Summary
This PR closes#25844
The original issue talks about `as const`, but seems like it fails for
any `as X` expressions since it adds another nesting level to the AST.
EDIT: Also closes#20162
## How did you test this change?
Added unit tests
Starting in version 19, users can import the `act` testing API from the
`react` package instead of using a renderer specific API, like
`react-dom/test-utils`.
The current error message "This mutates a global or a variable after it
was passed to React" no longer makes sense since we now have more
specific error messages for different kinds of Effect.Mutate or
Effect.Stores. This replaces the fallthrough "Other" case with a
more generic message. It's not perfect, but it's a little more accurate
than what is currently emitted
The proper fix might be to treat functions as mutable objects and allow
the mutation, or special case `Function.displayName`. For now though
this PR just updates the message in the meantime so it's less
confusing.
Semantically if you make your reason for aborting a Postpone instance
the render should not hit the error pathways but should instead follow
the postpone pathways. It's awkward today to actually get your hands on
a Postpone instance because you have to catch the throw from postpone
and then pass that into `abort()` or `AbortController.abort()`
(depending on the renderer API you are using)
This change makes it so that in most circumstances if you abort with a
postpone the `onPostpone` handler will be called and the Suspense
boundaries still pending will be put into client render mode with the
appropriate postpone digest to avoid trigger recoverable error pathways
on the client.
Similar to postponing in the shell during a resume or render however if
you abort before the shell is complete in a resume or render we will
fatally error. The fatal error is contextualized by React to avoid
passing the postpone object itself to the `onError` and related options.
While trying to resolve some issues with Flow in ESLint, noticed that we
are still listing `eslint-plugin-flowtype` as dev dependency, but it has
been deprecated in favour of `eslint-plugin-ft-flow`.
We're doing some internal benchmarking using a lightweight bundler that @pieterv
wrote for experimentation purposes. It's designed to fully preserve Flow type
annotations so we can experiment with type-driven compilation and test out what
benefits we might get from "cross-module" compilation more easily (ie by just
bundling together a few modules so we can see them all as one).
However, the bundler renames local variables and imports, so that a reference to
`useMemo()` might end up as `React$useMemo()` or similar. This PR adds a flag to
tell the compiler that builtin hooks might be prefixed and resolve them
appropriately.
---
Currently, we error on non-hoisted identifiers in EnterSSA with a somewhat
cryptic message. This PR changes `BuildHIR` hoisting logic to find ALL hoistable
bindings, then error when we try to lower hoisting for unsupported declaration
types.
Two benefits to this refactoring:
- Dedups "unhandled identifier declaration" logic (previous to #2552 and this
PR, we did this check in three places).
- More explicit todo diagnostic messages when we cannot hoist a declaration
---
Three functional changes:
- Instead of visiting all identifier references, explicitly traverse only
function decls/exprs. This avoids bugs like accidentally hoisting inline
references
```js
// input
const x = identity(y);
const y = 2;
// lowered HIR before this PR (simplified)
[0] DeclareContext HoistedConst y$0
[1] LoadContext y$0
[2] StoreLocal Const x$5 = identity([1])
```
- Rely on `isReferencedIdentifier()` instead of manually checking member
properties / assignments, which is error prone
```js
// added fixture hoisting-repro-variable-used-in-assignment
const callbk = () => {
// before this PR, we skip hoisting x because it's part of a declaration
const copy = x;
return copy;
};
const x = 2;
return callbk();
```
- Visit lvalues after rvalues. This allows for recursive self-references (e.g.
factorial)
From the Babel side, this change relies heavily on babel's scope binding
resolution logic. My understanding is:
- Babel guarantees node objects are uniqued (`node1 === node2` <--> node1 and
node2 are the same node in the ast)
- Each binding has exactly one `bindingIdentifier` (`binding.identifier`,
`getBindingIdentifier`, etc) which is identifier node @ its declaration site
```js
// x is a binding identifier
const x = 2;
// foo is a binding identifier
function foo() {
}
// param is a binding identifier
(param) => {...}
// this bar is a binding identifier
let bar;
// but not this bar
bar = 2;
```
Treat `<a href="" />` the same with and without
`enableFilterEmptyStringAttributesDOM`
in https://github.com/facebook/react/pull/18513 we started to warn and
ignore for empty `href` and `src` props since it usually hinted at a
mistake. However, for anchor tags there's a valid use case since `<a
href=""></a>` will by spec render a link to the current page. It could
be used to reload the page without having to rely on browser
affordances.
The implementation for Fizz is in the spirit of
https://github.com/facebook/react/pull/21153. I gated the fork behind
the flag so that the fork is DCE'd when the flag is off.
Previously we only warned during a synchronous update, because we
eventually want to support async client components in controlled
scenarios, like during navigations. However, we're going to warn in all
cases for now until we figure out how that should work.
Updates Fizz to handle Hoistables (Resources and Elements) in a way that
better aligns with Suspense fallbacks
1. Hoistable Elements inside a fallback (regardless of how deep and how
many additional boundaries are intermediate) will be ignored. The
reasoning is fallbacks are transient and since there is not good way to
clean up hoistables because they escape their Suspense container its
better to not emit them in the first place. SSR fallbacks are already
not full fidelity because they never hydrate so this aligns with that
somewhat.
2. Hoistable stylesheets in fallbacks will only block the reveal of a
parent suspense boundary if the fallback is going to flush with that
completed parent suspense boundary. Previously if you rendered a
stylesheet Resource inside a fallback any parent suspense boundaries
that completed after the shell flushed would include that resource in
the set required to resolve before the boundary reveal happens on the
client. This is not a semantic change, just a performance optimization
3. preconnect and preload hoistable queues are gone, if you want to
optimize resource loading you shoudl use `ReactDOM.preconnect` and
`ReactDOM.preload`. `viewport` meta tags get their own queue because
they need to go before any preloads since they affect the media state.
In addition to those functional changes this PR also refactors the
boundary resource tracking by moving it to the task rather than using
function calls at the start of each render and flush. Tasks also now
track whether they are a fallback task
supercedes prior work here: https://github.com/facebook/react/pull/27534
Follow-up to
https://github.com/facebook/react/pull/28139#discussion_r1468852457
I mistakenly kept the tests using comment nodes as containers as legacy
tests. It's not that comments nodes aren't allowed in createRoot
entirely. Only behind `disableCommentsAsDOMContainers`. We already had
one test following that pattern so I just applied the same pattern to
the other tests for consistency.
Now `DOMPluginEventSystem` no longer uses any legacy roots.
These were made dynamic again in
https://github.com/facebook/react/pull/27919, and already have the
dynamic flags set. It's a bummer to push this around, we should come up
with a better way.
Each it block here was duplicated to cover ReactDOM.render and
ReactDOMClient.createRoot. Here we delete the ReactDOM.render coverage.
Co-authored-by: Jack Pope <jackpope@meta.com>
---
This is likely a rare edge case, but it does produce a parse error.
RenameVariables visits all identifier references to ensure we don't end up
producing conflicting variable declarations, using a stack of block scopes to
check "in scope variables".
This pass is currently built to be conservative -- we explicitly rename shadowed
variables, and visit all rvalue references. The issue is for this IR:
```
{
1. decl t0;
2. scope 0 {
3. reassign t0 = ...
4. read(t0)
5. }
6. let t0 = ...
7. read(t0);
}
```
We currently visit t0 only on line 4 and 7 (and never rename t0). Instead we
should visit lvalues (declaration sites) which occur earlier than rvalues
(visiting lines 1 and 6 will show conflicting declarations)
The compiler bails out of compiling code that contains suppressions of the
official React ESLint rules. However, some apps may use additional rules that
they want to trigger bailouts for, or use the official rules under a different
name (we do this at Meta). This PR adds a compiler flag to specify a custom set
of line rule names, suppression of which should trigger a bailout.
The attribute-behavior fixture now uses `createRoot().render()` and
`renderToReadableStream` instead of depdrecated APIs.
This revealed some changes to the snapshots that I annotated for
discussion.
I also added some new tests related to upcoming changes for easier
future diffing.
Also adds support for running the attribute-behavior fixture using Apple
Silicon chips (Apple MBP M-series).
To make React.startTransition more consistent with the hook form of
startTransition, we capture errors thrown by the scope function and pass
them to the global reportError function. (This is also what we do as a
default for onRecoverableError.)
This is a breaking change because it means that errors inside of
startTransition will no longer bubble up to the caller. You can still
catch the error by putting a try/catch block inside of the scope
function itself.
We do the same for async actions to prevent "unhandled promise
rejection" warnings.
The motivation is to avoid a refactor hazard when changing from a sync
to an async action, or from useTransition to startTransition.
## Summary
In the precendences Map every key is prefixed with `p`. This fixes one
case where this is missing.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
This adds support for async actions to the "isomorphic" version of
startTransition (i.e. the one exported by the "react" package).
Previously, async actions were only supported by the startTransition
that is returned from the useTransition hook.
The interesting part about the isomorphic startTransition is that it's
not associated with any particular root. It must work with updates to
arbitrary roots, or even arbitrary React renderers in the same app. (For
example, both React DOM and React Three Fiber.)
The idea is that React.startTransition should behave as if every root
had an implicit useTransition hook, and you composed together all the
startTransitions provided by those hooks. Multiple updates to the same
root will be batched together. However, updates to one root will not be
batched with updates to other roots.
Features like useOptimistic work the same as with the hook version.
There is one difference from from the hook version of startTransition:
an error triggered inside an async action cannot be captured by an error
boundary, because it's not associated with any particular part of the
tree. You should handle errors the same way you would in a regular
event, e.g. with a global error event handler, or with a local
`try/catch`.
Before, we used to reset the thenable state and extract the previous
state very early so that it's only the retried task that can possibly
consume it. This is nice because we can't accidentally consume that
state for any other node.
However, it does add a lot of branches of code that has to pass this
around. It also adds extra bytes on the stack per node. Even though it's
mostly just null.
This changes it so that where ever we can create a thenable state (e.g.
entering a component with hooks) we first extract this from the task.
The principle is that whatever could've created the thenable state in
the first place, must always be rerendered so it'll take the same code
paths to get there and so we'll always consume it.
This refactors the Flight render loop to behave more like Fizz with
similar naming conventions. So it's easier to apply similar techniques
across both. This is not necessarily better/faster - at least not yet.
This doesn't yet implement serialization by writing segments to chunks
but we probably should do that since the built-in parts that
`JSON.stringify` gets us isn't really much anymore (except serializing
strings). When we switch to that it probably makes sense for the whole
thing to be recursive.
Right now it's not technically fully recursive because each recursive
render returns the next JSON value to encode. So it's kind of like a
trampoline. This means we can't have many contextual things on the
stack. It needs to use the Server Context `__POP` trick. However, it
does work for things that are contextual only for one sequence of server
component abstractions in a row. Since those are now recursive.
An interesting observation here is that `renderModel` means that
anything can suspend while still serializing the outer siblings.
Typically only Lazy or Components would suspend but in principle a Proxy
can suspend/postpone too and now that is left serialized by reference to
a future value. It's only if the thing that we rendered was something
that can reduce to Lazy e.g. an Element that we can serialize it as a
lazy.
Similarly to how Suspense boundaries in Fizz can catch errors, anything
that can be reduced to Lazy can also catch an error rather than bubbling
it. It only errors when the Lazy resolves. Unlike Suspense boundaries
though, those things don't render anything so they're otherwise going to
use the destructive form. To ensure that throwing in an Element can
reuse the current task, this must be handled by `renderModel`, not for
example `renderElement`.
## Overview
These tests are important for `ReactDOM.render`, so instead of just
re-writing them to `createRoot` and losing coverage:
- Moved the `.render` tests to `ReactLegacyUpdates`
- Re-wrote the tests in `ReactUpdates` to use `createRoot`
- Remove `unstable_batchedUpdates` from `ReactUpdates`
In a future PR, when I flag `batchedUpdates` with a Noop, I can add the
gate to just the tests in `ReactLegacyUpdates`.
To convert this file, I started replacing all the calls in line, and
quickly realized that we already have most of these tests covered in
other files. So I found the test that we didn't already have for
`create/hydrateRoot` and added them, then renamed `ReactMount` to
`ReactLegacyMount`.
If there are multiple updates inside an async action, they should all be
rendered in the same batch, even if they are separate by an async
operation (`await`). We currently implement this by suspending in the
`useTransition` hook to block the update from committing until all
possible updates have been scheduled by the action. The reason we did it
this way is so you can "cancel" an action by navigating away from the UI
that triggered it.
The problem with that approach, though, is that even if you navigate
away from the `useTransition` hook, the action may have updated shared
parts of the UI that are still in the tree. So we may need to continue
suspending even after the `useTransition` hook is deleted.
In other words, the lifetime of an async action scope is longer than the
lifetime of a particular `useTransition` hook.
The solution is to suspend whenever _any_ update that is part of the
async action scope is unwrapped during render. So, inside useState and
useReducer.
This fixes a related issue where an optimistic update is reverted before
the async action has finished, because we were relying on the
`useTransition` hook to prevent the optimistic update from finishing.
This also prepares us to support async actions being passed to the
non-hook form of `startTransition` (though this isn't implemented yet).
Convert ReactServerRenderingHydration-test to createRoot (partially)
Some tests seem to be specifically testing the legacy APIs, maybe we
need to keep those around. Keeping this PR to the simple updates.
Fixtures from T173102122 and T173101739 demonstrating cases where
MergeConsecutiveBlocks can move code out of its correct block scope, changing
behavior or breaking the program, in cases where a control flow structure (such
as switch) only has one non-returning control flow path. In these cases, the
non-returning path gets merged with the fallthrough, effectively lifting that
code out of the control flow structure and moving it into the outer scope. This
can create dead code or just invalid code (with references to variables that are
not in scope).
Sprout fails on both of these fixtures:
<img width="812" alt="Screenshot 2024-01-23 at 11 25 36 AM"
src="https://github.com/facebook/react-forget/assets/6425824/d397ea22-3fa3-436e-b655-09a45781274b">
See the previous PR, interleaved mutation can cause values that were not
reactive to become reactive. I swear I had a case where this was observable, but
I came up with it before reordering the PRs in this stack. I think my repro
relied on an immutable reference to a mutable value, which is now handled in
InferReactivePlaces. So here i'm just adding fixtures, and allowing this case
since it's unobservable.
Fix ReactFreshIntegration-test not running all tests as assumed
`testCommon` was executed twice without setting `compileDestructuring`
ever to true.
This fixes this and removes one layer of abstraction in this test by
using `describe.each`.
During PruneNonReactiveDependencies, we sometimes need to promote a value from
non-reactive to reactive if it ended up being grouped in the same reactive scope
as some other reactive value. This generally happens due to interleaving
mutations.
In this case all downstream usage of the promoted value need to also be
considered reactive. Fully propagating the reactivity requires re-running
InferReactivePlaces, to account for things like control reactivity. We can't yet
reuse that pass here though, because we haven't unified the pipeline on HIR yet.
For now, we propagate the reactivity through local variables and downstream
reactive scopes. See test fixtures for some examples that now correctly
propagate reactivity and some that need the full reactivity inference to run
correctly. The latter cases are handled in the next PR.
I found this by adding logic to reject inputs where reactivity gets newly
propagated in PruneNonReactiveDependencies. It's possible to create a readonly
alias to a mutable value such that we don't know the value is reactive yet when
the alias is created. Thus we need to do a fixpoint iteration even if there are
no loops in order to be able to revisit such aliases and reflow the reactivity
forward. Example:
```javascript
const x = [];
const y = x;
const z = [y]; // y isn't reactive yet when we first visit this, so z is
initially non-reactive
y.push(props.value); // then we realize y is reactive. we need a fixpoint to
propagate this back to z
const a = [z]; // need an indirection to get past the partial propagation in
PruneNonReactiveDependencies
let b = 0;
if (a[0][0]) {
b = 1;
}
return [b];
```
Existing fixtures don't change because the basic reactivity propagation in
PruneNonReactiveDependencies is enough to make common cases work. I confirmed
that the new fixture does not work on previous PR in the stack.
Fixes T175227223. When inferring reactivity, mutation of a value with a reactive
input marks the mutable value as reactive. However, we also need to account for
aliases:
```javascript
const x = [];
const y = x;
y.push(props.value);
```
Previously we would have only considered `y` reactive here, but `x` also becomes
reactive.
The implementation extracts out a helper from InferReactiveScopeVariables that
builds a `DisjointSet<Identifier>` of disjoint sets of mutably aliased values.
InferReactivePlaces then treats all instances of each mutable alias group as
equivalent for reactivity purposes.
In InferReactivePlaces, we already account for reactively controlled values:
where a value is never assigned a non-reactive value, but _which_ value is
assigned is based on a reactive condition (the test conditions of an if, switch,
loop, etc).
This PR extends that reactively-controlled inference to mutation that is
conditioned upon a reactive value. From the test case:
```javascript
let x = [];
if (props.cond) {
// This mutation has no reactive inputs.
// *But* the mutation conditionally occurs based on props.cond which is reactive
x.push(1);
}
let y = false;
if (x[0]) { // therefore the value observed here is reactive
y = true;
}
// so the value of y here is reactive via the reactive control dependency x[0]
return [y];
```
---
Previously, our logic was something like:
```js
fixed-point-loop {
foreach instruction {
mark referenced identifiers
// assume that usages are always visited before declarations
if (instruction is decl) {
prune(instruction);
}
}
foreach instruction {
if not referenced {
delete(instruction);
}
}
```
This contained a bug, as not all usages of a variable are guaranteed to be
visited before its declaration.
```js
// input
let x = 0;
while(x < 10) {
x += 2;
}
return x;
// hir
entry:
x$0 = 0
goto loop-test
loop-test:
x$1 = phi(x$0, x$2)
if ... goto loop-body else goto fallthrough
loop-body:
x$2 = x$1 ...
goto loop-test
fallthrough:
return x$1
```
In this example,`x$2` is defined by `loop-body` and used by `loop-test`.
Similarly, `x$1` is defined by `loop-test` and used by `loop-body`.
---
TODO: trying to come up with more test fixtures
Same babel identifier issue as #2510 but for HoistedConst
Not sure how we should best test this -- one possibility is using constant prop.
Currently, we have false positives for HoistedConst that prevent constant
propagation. I don't want to over-rotate on babel apis tests in our fixtures
(instead of semantically interesting ones)
```js
// input
function Component() {
{ x: 4 };
const x = 2;
return x;
}
// output
function Component() {
const $ = useMemoCache(1);
let x;
if ($[0] === Symbol.for("react.memo_cache_sentinel")) {
x = 2;
$[0] = x;
} else {
x = $[0];
}
return x;
}
```
identifiers
---
A few fixes for finding context identifiers:
Previously, we counted every babel identifier as a reference. This is
problematic because babel counts every string symbol as an identifier.
```js
print(x); // x is an identifier as expected
obj.x // x is.. also an identifier here
{x: 2} // x is also an identifier here
```
This PR adds a check for `isReferencedIdentifier`. Note that only non-lval
references pass this check
```js
print(x); // isReferencedIdentifier(x) -> true
obj.x // isReferencedIdentifier(x) -> false
{x: 2} // isReferencedIdentifier(x) -> false
x = 2 // isReferencedIdentifier(x) -> false
```
Which brings us to change #2.
Previously, we counted assignments as references due to the identifier visiting
+ checking logic. The logic was roughly the following (from #1691)
```js
contextVars = intersection(reassigned, referencedByInnerFn);
```
Now that assignments (lvals) and references (rvals) are tracked separately, the
equivalent logic is this. Note that assignment to a context variable does not
need to be modeled as a read (`console.log(x = 5)` always will evaluates and
prints 5, regardless of the previous value of x).
```
contextVars = union(reassignedByInnerFn, intersection(reassigned,
referencedByInnerFn))
```
---
Note that variables that are never read do not need to be modeled as context
variables, but this is unlikely to be a common pattern.
```js
function fn() {
let x = 2;
const inner = () => {
x = 3;
}
}
```
We haven't yet decided how we want `cache` to work on the client. The
lifetime of the cache is more complex than on the server, where it only
has to live as long as a single request.
Since it's more important to ship this on the server, we're removing the
existing behavior from the client for now. On the client (i.e. not a
Server Components environment) `cache` will have not have any caching
behavior. `cache(fn)` will return the function as-is.
We intend to implement client caching in a future major release. In the
meantime, it's only exposed as an API so that Shared Components can use
per-request caching on the server without breaking on the client.
This refactors the Server Components entrypoint for the `react` package
(ReactServer.js) so that it doesn't depend on the client entrypoint
(React.js). I also renamed React.js to ReactClient.js to make the
separation clearer.
This structure will make it easier to add client-only and server-only
features.
The internal file ReactSharedSubset is what the `react` module resolves
to when imported from a Server Component environment. We gave it this
name because, originally, the idea was that Server Components can access
a subset of the APIs available on the client.
However, since then, we've also added APIs that can _only_ by accessed
on the server and not the client. In other words, it's no longer a
subset, it's a slightly different overlapping set.
So this commit renames ReactSharedSubet to ReactServer and updates all
the references. This does not affect the public API, only our internal
implementation.
This fixes a bug that happened when the canonical value passed to
useOptimistic without an accompanying call to setOptimistic. In this
scenario, useOptimistic should pass through the new canonical value.
I had written tests for the more complicated scenario, where a new value
is passed while there are still pending optimistic updates, but not this
simpler one.
Upgrade ReactDOMShorthandCSSPropertyCollision-test to createRoot
Using the codemod from #27921 as a starting point, this migrates the
test to `createRoot`.
I sincerely appreciate the effort to get test262 up and running. This was my
idea, it seemed like a really good way to test our correctness on edge cases of
JS. Unfortunately test262 relies heavily on a few specific features that we
don't support, like classes and `var`, which has meant that we never actually
use this as a test suite.
In the meantime we've created a pretty extensive test suite and have tools like
Sprout to test actual memoization behavior at runtime, which is the right place
to invest our energy. Let's remove?
Do we still use these? I'm happy to close this PR if we still want this but it
feels like these may have served their purpose and no longer be necessary.
Fixes the false positive in the previous PR. When we prune a scope because it's
values are non-escaping, we now also remove any `Memoize` instructions for that
scope. The intuition being that we're actively removing unnecessary memoization,
so we don't need to check that the memoization occurred anymore.
This demonstrates a false positive in validatePreserveExistingManualMemoization.
We prune memoization of non-escaping values, but the validation pass just sees
that the value "should" have a scope and that scope doesn't exist, and thinks we
failed to preserve memoization.
Interpolating values into the `reason` field of an error breaks our error
aggregation. This PR moves the offending function name into the `description`
field which isn't used for aggregation.
I had trouble checking out the repo using Sapling because the submodule couldn't
clone properly. I got
> Error: Permission denied (publickey)
In my branch I tested that the https URL format seems to work okay with Sapling.
Add frozen reason for props and hook arguments
Improves the error message when mutating props or hook arguments.
Previously, this would print a generic error about mutating global variables.
If this is a client reference we shouldn't dot into it, which would
throw in the proxy.
Interestingly our client references don't really have a `name`
associated with them for debug information so a component type doesn't
show up in error logs even though it seems like it should.
While inspecting the build artifacts for Fabric in
https://www.internalfb.com/diff/D51816108, I've noticed it has some
leaking implementation details from Paper, such as
`ReactNativeFiberHostComponent`.
The reason for it is the single implementation of
`isChildPublicInstance` in `ReactNativePublicCompat`, in which we were
using `instanceof ReactNativeFiberHostComponent`.
This new implementation removes the `ReactNativeFiberHostComponent`
leak, but decreases the Flow coverage.
This was an oversight in the original definition of useContext (oops my bad).
Context values are owned by React and should not be modified. I found this
because some cases of existing useMemo were not preserved (tested via the
validatePreserveExistingManualMemo flag) due to function calls referencing
context being assumed to mutate.
This change will allow more memoization, it's also just more correct for the
rules of React. Note the new ValueReason variant so that we can provide a
precise error message about mutating context values.
## Summary
these were removed in https://github.com/facebook/react/pull/26617. adds
them back so we can conduct another experiment.
## How did you test this change?
`yarn test-www`
Bumps
[follow-redirects](https://github.com/follow-redirects/follow-redirects)
from 1.7.0 to 1.15.4.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="65858205e5"><code>6585820</code></a>
Release version 1.15.4 of the npm package.</li>
<li><a
href="7a6567e16d"><code>7a6567e</code></a>
Disallow bracketed hostnames.</li>
<li><a
href="05629af696"><code>05629af</code></a>
Prefer native URL instead of deprecated url.parse.</li>
<li><a
href="1cba8e85fa"><code>1cba8e8</code></a>
Prefer native URL instead of legacy url.resolve.</li>
<li><a
href="72bc2a4229"><code>72bc2a4</code></a>
Simplify _processResponse error handling.</li>
<li><a
href="3d42aecdca"><code>3d42aec</code></a>
Add bracket tests.</li>
<li><a
href="bcbb096b32"><code>bcbb096</code></a>
Do not directly set Error properties.</li>
<li><a
href="192dbe7ce6"><code>192dbe7</code></a>
Release version 1.15.3 of the npm package.</li>
<li><a
href="bd8c81e4f3"><code>bd8c81e</code></a>
Fix resource leak on destroy.</li>
<li><a
href="9c728c314b"><code>9c728c3</code></a>
Split linting and testing.</li>
<li>Additional commits viewable in <a
href="https://github.com/follow-redirects/follow-redirects/compare/v1.7.0...v1.15.4">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps
[follow-redirects](https://github.com/follow-redirects/follow-redirects)
from 1.14.0 to 1.15.4.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="65858205e5"><code>6585820</code></a>
Release version 1.15.4 of the npm package.</li>
<li><a
href="7a6567e16d"><code>7a6567e</code></a>
Disallow bracketed hostnames.</li>
<li><a
href="05629af696"><code>05629af</code></a>
Prefer native URL instead of deprecated url.parse.</li>
<li><a
href="1cba8e85fa"><code>1cba8e8</code></a>
Prefer native URL instead of legacy url.resolve.</li>
<li><a
href="72bc2a4229"><code>72bc2a4</code></a>
Simplify _processResponse error handling.</li>
<li><a
href="3d42aecdca"><code>3d42aec</code></a>
Add bracket tests.</li>
<li><a
href="bcbb096b32"><code>bcbb096</code></a>
Do not directly set Error properties.</li>
<li><a
href="192dbe7ce6"><code>192dbe7</code></a>
Release version 1.15.3 of the npm package.</li>
<li><a
href="bd8c81e4f3"><code>bd8c81e</code></a>
Fix resource leak on destroy.</li>
<li><a
href="9c728c314b"><code>9c728c3</code></a>
Split linting and testing.</li>
<li>Additional commits viewable in <a
href="https://github.com/follow-redirects/follow-redirects/compare/v1.14.0...v1.15.4">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps
[follow-redirects](https://github.com/follow-redirects/follow-redirects)
from 1.13.3 to 1.15.4.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="65858205e5"><code>6585820</code></a>
Release version 1.15.4 of the npm package.</li>
<li><a
href="7a6567e16d"><code>7a6567e</code></a>
Disallow bracketed hostnames.</li>
<li><a
href="05629af696"><code>05629af</code></a>
Prefer native URL instead of deprecated url.parse.</li>
<li><a
href="1cba8e85fa"><code>1cba8e8</code></a>
Prefer native URL instead of legacy url.resolve.</li>
<li><a
href="72bc2a4229"><code>72bc2a4</code></a>
Simplify _processResponse error handling.</li>
<li><a
href="3d42aecdca"><code>3d42aec</code></a>
Add bracket tests.</li>
<li><a
href="bcbb096b32"><code>bcbb096</code></a>
Do not directly set Error properties.</li>
<li><a
href="192dbe7ce6"><code>192dbe7</code></a>
Release version 1.15.3 of the npm package.</li>
<li><a
href="bd8c81e4f3"><code>bd8c81e</code></a>
Fix resource leak on destroy.</li>
<li><a
href="9c728c314b"><code>9c728c3</code></a>
Split linting and testing.</li>
<li>Additional commits viewable in <a
href="https://github.com/follow-redirects/follow-redirects/compare/v1.13.3...v1.15.4">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
If we end up client rendering a boundary due to an error after we have
already injected a postponed hole in that boundary we'll end up trying
to target a missing segment. Since we never insert segments for an
already errored boundary into the HTML. Normally an errored prerender
wouldn't be used but if it is, such as if it was an intentional client
error it triggers this case. Those should really be replaced with
postpones though.
This is a bit annoying since we eagerly build up the postponed path. I
took the easy route here and just cleared out the suspense boundary
itself from having any postponed slots. However, this still creates an
unnecessary replay path along the way to the boundary. We could probably
walk the path and remove any empty parent nodes.
What is worse is that if this is the only thing that postponed, we'd
still generate a postponed state even though there's actually nothing to
resume. Since this is a bit of an edge case already maybe it's fine.
In my test I added a check for the `error` event on `window` since this
error only surfaces by throwing an ignored error. We should really do
that globally for all tests. Our tests should fail by default if there's
an error logged to the window.
Fixes a bug in the experimental `initialValue` option for
`useDeferredValue` (added in #27500).
If rendering the `initialValue` causes the tree to suspend, React should
skip it and switch to rendering the final value instead. It should not
wait for `initialValue` to resolve.
This is not just an optimization, because in some cases the initial
value may _never_ resolve — intentionally. For example, if the
application does not provide an instant fallback state. This capability
is, in fact, the primary motivation for the `initialValue` API.
I mostly implemented this correctly in the original PR, but I missed
some cases where it wasn't working:
- If there's no Suspense boundary between the `useDeferredValue` hook
and the component that suspends, and we're not in the shell of the
transition (i.e. there's a parent Suspense boundary wrapping the
`useDeferredValue` hook), the deferred task would get incorrectly
dropped.
- Similarly, if there's no Suspense boundary between the
`useDeferredValue` hook and the component that suspends, and we're
rendering a synchronous update, the deferred task would get incorrectly
dropped.
What these cases have in common is that it causes the `useDeferredValue`
hook itself to be replaced by a Suspense fallback. The fix was the same
for both. (It already worked in cases where there's no Suspense fallback
at all, because those are handled differently, at the root.)
The way I discovered this was when investigating a particular bug in
Next.js that would happen during a 'popstate' transition (back/forward),
but not during a regular navigation. That's because we render popstate
transitions synchronously to preserve browser's scroll position — which
in this case triggered the second scenario above.
It's starting to get complex just with a couple of extra
passes — we either need to substantially extend the HIR or (as i've done so far)
pass information from early passes to later ones. This PR changes things so that
very early in the babel plugin we fork into a separate mode. Forest has
its own `compileProgram()` equivalent, its own pipeline, its own codegen, etc.
> Update: this is now passing all tests. The approach is likely wrong, and even
if it's fine it needs some cleanup. Putting up for review as folks (esp
@gsathya) have time.
## Background
InferTypes was intended to infer types for phi identifiers, but by accident we
ended up storing the inferred type on `phi.type` instead of `phi.id.type`, which
is the type that usages of the phi will reference. Because of this, we weren't
actually inferring types for several cases, for example if both if/else branches
assign `x` to an array literal, we'd ideally like the corresponding phi id to be
typed as a BuiltInArray:
```javascript
let x;
let y = { ... };
if (cond) {
x = [];
} else {
x = [];
}
// x should be BuiltnArray here. We inferred that on Phi.type but the x here
wouldn't get that type previously
x.push(y);
```
## Circular Types
I started by removing the `Phi.type` property and updating inference to store
the result of phi unification on `phi.id.type` — but this revealed other issues.
First was this can create circular types when there are loops. The solution is
to basically allow circular types _for phis only_, and when we detect them we
remove the cycle. Basically whenever we have a situation where we have some type
variable X, and a type Y that is a (nested) phi type one of whose transitive
operands contains X, we remove X from the transitive type and attempt to
collapse the phi type upwards if all of its remaining operands are the same:
```
X=Type(1)
Y=Phi [
Type(2),
Type(3) = Phi [
Type(1), // <-- cycle but we can prune this
Type(2),
Type(2),
]
]
=>
X=Type(1)
Y=Phi [
Type(2),
Type(3) = Phi [ // all remaining operands are the same, we can prune this
Type(2),
Type(2),
]
]
=>
X=Type(1)
Y=Phi [ // all remaining operands are the same, we can prune this
Type(2),
Type(2),
]
=>
X=Type(1)
Y=Type(2)
```
We have to do this not just doing unify(), but also in `get()` since there are
cases where we don't know yet which type variables we can remove from a phi.
Without also doing the pruning in get, we get an infinite loop.
## Reactive Scope Alignment
The above fixed the circular types, but exposed some new cases that can occur in
terms of mutable ranges and ast structures: it wasn't possible before to have a
Store on a phi node in practice, since that relied on type information which we
didn't have for phis.
The new validation that all instructions for a scope are part of that scope
caught a couple issues, which were basically like this:
```
[1] Sequence
...
[9] StoreLocal x@0[9:28]
[10] ...
```
Note that scope 0 starts at instruction 9, but that instruction is not at the
block scope level. The first instruction at the block scope level that is within
the range of scope 0 is instruction 10, which is after the scope should have
started! So I also had to update AlignScopesToBlockScopes to handle the case of
logical, conditional, and sequence expressions: we sometime need to adjust a
scope start earlier in case they contain instructions that should start a scope.
This Flow upgrade includes 2 fixes:
- Remove `React$StatelessFunctionalComponent` as that was replaced by
just `React$AbstractComponent` as Flow doesn't make any guarantees, see
the Flow change here:
521317c48f
- Flow no longer allows `number` type indexing into objects which
discovered an incorrect type that is actually an array of the data.
Used this command to upgrade
```
yarn add -W flow-bin flow-remove-types hermes-parser hermes-eslint
```
and ran `yarn flow-ci` to check for errors in different configurations.
Fixes the case from the previous PR by using a different sentinel for
uninitialized cache values and early returns. I confirmed with console.log that
the reactive scope for `x` only evaluates on the first execution, after which we
figure out that we don't need to execute it again.
RFC. This is a quick sketch of adding support to Sprout to render the same
component instance multiple times with different props. This doesn't test
memoization (though it forms a basis for testing it, more below), but does allow
us to test that the code properly reacts to inputs and doesn't get "stuck"
always returning the same output even when inputs change.
Possible extensions:
- Support calling non-component functions multiple times
- Test memoization by having the `toJSON()` helper track objects it has
encountered before, assign each object a unique id, and then emit subsequent
references to the same value as the id instead of the printed form of the
object.
For example if we call a memoized function with the same input twice in a row,
today we might get output like:
```
[{a: 1}],
[{a: 1}],
```
Which doesn't tell us if the object is equal. Instead we could emit output like:
```
[{a: 1}] #0,
#0,
```
Which allows verifying that memoization actually happened. Or we could automate
this and just assert that anything structurally equal has to be referentially
equal — though there are cases with conditionals that break this.
Adds support for early returns within reactive scopes, behind a new feature
flag. The flag is off by default, where this case continues to throw a Todo
bailout.
Since implementing a sketch of the codegen in the previous PR I realized that
it's easy enough to implement the more optimal output, so i've updated that
here. Rather than both the if and else branch of the reactive scope having an
"if the return value was not a sentinel return it" check, we instead make the
return temporary a proper declaration of the reactive scope. Then, since it's
actually an output it's available in the outer block scope, and we could do a
single if-return after the reactive scope.
Edit: see comment below for thoughts on test cases.
Implements codegen for reactive scopes with early returns, though we don't ever
construct such a case yet. See comments in the code. There is a slightly more
optimal output that would require a larger refactor (also described in code
comments), for now i'm starting with the simpler approach since this is
relatively rare so we don't need to optimize code size / runtime as much.
Adds a new `earlyReturnValue` property on ReactiveScope which will be set if the
scope had one or more early returns, with information about the temporary
identifier that the early return value will be assigned to, as well as the label
to be used for breaking (to simulate the early-return). The next PR shows the
intended codegen.
Adds a new compiler pass that will eventually actually handle early returns
within reactive scopes. For now it just detects them and throws a Todo error.
For clientReferences we can just check the instance of the
`clientReference`.
The implementation of `isClientReference` is provided via configuration.
The class for ClientReference has to implement an interface that has
`getModuleId() method.
Adds back a mode to transitively freeze function expressions, independently from
the mode to preserve existing manual memoization. This lets us experiment with a
few variants:
* Preserve existing memoization
* Validate existing memoization with:
* `enableAssumeHooksFollowRulesOfReact` &&
`enableTransitivelyFreezeFunctionExpressions`
* `enableAssumeHooksFollowRulesOfReact` only
* neither of those flags
Note that `enableTransitivelyFreezeFunctionExpressions` alone probably doesn't
make sense, it's more aggressive than
`enableAssumeHooksFollowRulesOfReact` so we might as well try them together.
https://github.com/facebook/react/pull/27805 broke integration tests for
React DevTools with React 17, these changes introduce a fallback for
such case when `act` is not available in `react`, but available in
`react-dom`, like before.
This wires up the use of `async_hooks` in the Node build (as well as the
Edge build when a global is available) in DEV mode only. This will be
used to track debug info about what suspended during an RSC pass.
Enabled behind a flag for now.
Historically React would produce component stacks for dev builds only.
There is a cost to tracking component stacks and given the prod builds
try to optimize runtime performance these stacks were left out. More
recently React added production component stacks to Fiber in because it
can be immensely helpful in tracking down hard to debug production
issues. Fizz was not updated to have a similar behavior.
With the advent of prerendering however stacks for production in Fizz
are more relevant because prerendering is not really a dev-time task. If
you want the ability to reason about errors or postpones that happen
during a prerender having component stacks to interrogate is helpful and
these component stacks need to be available in production otherwise you
are really never going to see them. (it is possible that you could do
dev-mode prerenders but we don't expect this to be a common dev mode
workflow)
To better support the prerender use case and to make error logging in
Fizz more useful the following changes have been made
1. `onPostpone` now accepts a second `postponeInfo` argument which will
contain a componentStack. Postpones always originate from a component
render so the stack should be consistently available. The type however
will indicate the stack is optional so we can remove them in the future
if we decide the overhead is the wrong tradeoff in certain cases
2. `onError` now accepts a second `errorInfo` argument which may contain
a componentStack. If an error originated from a component a stack will
be included in the following cases.
This change entails tracking the component hierarchy in prod builds now.
While this isn't cost free it is implemented in a relatively lean
manner. Deferring the most expensive work (reifying the stack) until we
are actually in an error pathway.
In the course of implementing this change a number of simplifications
were made to the code which should make the stack tracking more
resilient. We no longer use a module global to curry the stack up to
some handler. This was delicate because you needed to always reset it
properly. We now curry the stack on the task itself.
Another change made was to track the component stack on SuspenseBoundary
instances so that we can provide the stack when aborting suspense
boundaries to help you determine which ones were affected by an abort.
Adds a new mode which validates that existing manual memoization is preserved
_without_ using information from the manual memoization to affect compilation.
This gives us a way to try out the more aggressive version of Forget — ignoring
manual memoization — first and see how much code bails out and what patterns
cause this.
We can then proceed to enable the mode to actually _preserve_ existing memo
guarantees only where necessary.
Extends `@enablePreserveExistingMemoization` to validate that all of the
original values were actually memoized. This works nearly identically to how we
validate effect deps are memoized. We look for Memoize instructions whose values
need memoization but whose range extends past the memoize instruction, or where
the value isn't memoized at all.
Merges `@enableTransitivelyFreezeFunctionExpressions` into the new
`@enablePreserveExistingMemoizationGuarantees` mode, since they are both
motivated by the same use case of preserving effect behavior by preserving
existing memoization behavior.
The idea is that `useCallback` has an implicit assumption: that the variables
captured by the callback aren't subsequently modified. Previous PRs treated the
values directly captured by the callback as frozen. But if those variables were
themselves another function expression, and that expression captured a mutable
value, then we wouldn't consider the freeze to be transitive:
```javascript
const object = makeObject();
useHook(); // oops, hook call inside `object`'s mutable range, can't memoize
object, log, or onClick!
const log = () => { console.log(object) };
const onClick = useCallback(() => { log() });
maybeMutate(object);
```
However, the assumption of such code is that it _doesn't_ modify such
transitively captured values. So here we merge
`@enableTransitivelyFreezeFunctionExpressions` mode into the
memoization-preserving mode. Now, the memoize instructions emitted for
useCallback (and useMemo) will transitively freeze captured function
expressions, allowing us to memoize.
The flip side of this is that some code may be violating these rules. We'll rely
on runtime validation to detect such cases.
Adds test cases per the previous PR for useCallback:
* callback that references another callback, which in turn references a
possibly-mutated value
* callback that references a ref
Improves `@enablePreserveExistingMemoizationGuarantees` for the useCallback
case. Similar to useMemo, we add an explicit `Memoize` instruction for the
callback function itself _and_ for its dependencies. This means we'll assume the
callback doesn't mutate any captured variables.
TODO: check this with cases involving refs (should be allowed, but also not
accidentally freeze the ref) and reassignment of locals (should be disallowed,
though that might just be a validation we're missing today)
The previous PR introduced `memoize` instructions whose lvalues aren't used, but
which can't be pruned by DCE due to pipeline ordering. Here we change to make
memoize an instruction intended for its side effects only, and prune during
codegen.
See discussion on #2448 for full context. In the new
`@enablePreserveExistingMemoizationGuarantees` mode, the goal is to preserve the
existing referential equality guarantees from the original code. #2448 lays the
groundwork by explicitly marking the _output_ of each useMemo block as memoized,
hinting to the compiler that the value cannot subsequently change. This ensures
the mutable range doesn't extend _later_, possibly overlapping a hook call and
causing memoization to gett pruned.
This PR fixes the other direction. There are cases where free variables
referenced in the useMemo block could have been inferred as mutated, which could
then extend the _start_ of the range earlier past a hook:
```javascript
const foo = createObject();
useBar();
const baz = useMemo(() => {
const baz = createObject();
maybeMutate(foo, baz);
return baz;
}, [foo]);
```
Here the compiler would infer that both `baz` and `foo` are mutable at the
`maybeMutate()` call, grouping them in the same scope. But that scope would span
the `useBar()` call, and be pruned, meaning that `baz` went unmemoized.
However, useMemo blocks shouldn't be mutating free variables. Only variables
newly created within the useMemo block should be mutable. So this PR extends the
feature to treat all free variables referenced in a useMemo block as frozen as
of the block itself.
Adds an option to preserve existing memoization guarantees for values produced
with useMemo and useCallback. We still discard the calls to these hooks, but we
preserve the information that the value is frozen at that point in the program.
Because these values are produced solely within the useMemo/useCallback
callback, their mutation cannot have any interspersed hook calls. This means
that the values mutable range will never span a hook and end at the point of the
useMemo, ensuring that they are memoized at the same point.
The main things that can change (relative to the orignal code) are:
* Forget will infer a precise set of dependencies, ignoring the user-provided
values. In practice this should only occur if the original code had a lint
violation, which Forget would bail out on. So in practice this shouldn't happen
unless the code doesn't use the React linter.
* Forget may start the memoization block earlier than the developer did if other
values are mutated along with the value being produced. This can cause
memoization to fail, but only in situations where it would have failed
previously:
```javascript
const a = [];
useFoo();
const b = useMemo(() => {
const c = a;
c.push(1);
return c;
}, [a]);
```
In this example (sans Forget) the useMemo will invalidate on every render
because `a` will always be a new array and its listed as a dependency of the
useMemo. Forget would correctly determine that the memoization would have to
work as follows:
```javascript
let c;
if (...) {
const a = []
useFoo(); // OOPS we made a hook call conditional
const t0 = a;
t0.push(1);
c = t0;
...
} else {
c = $[...]
}
```
Because this is invalid, Forget would (later in the pipeline) strip out this
memoization block and (as with the original) leave `c` un-memoized.
In this same example, removing the hook would cause Forget to be able to memoize
a value that wasn't memoized before:
```javascript
const a = [];
const b = useMemo(() => {
const c = a;
c.push(1);
return c;
}, [a]);
```
This invalidates every render without Forget, but would memoize correctly with
Forget (it would expand the memoization block to include the declaration of
`a`).
Adds a fixture for our existing behavior that reactive scope dependencies
exclude values which are non-reactive. The idea is that regardless of whether
the value may actually get recreated over time or not, a "nonreactive" value
cannot semantically change and therefore we can ignore changes in its pointer
address.
After running the latest hook validation internally, I found some cases where
there was a violation but the error message was not ideal. For example on this
code:
```javascript
usePossiblyNullHook?.();
```
We reported a "hooks can't be used as normal values" violation, when we'd
ideally report a "hooks can't be called conditionally" violation. The solution
in this PR is to track errors by source location, and upgrade the former
violation to the latter, more serious violation. See fixtures for examples.
ObjectExpressions
---
Currently, we're removing all reactive scopes containing object methods. This
could produce incorrect output as object method instructions may still be
included in other reactive scopes (and will lose their dependencies).
Builds on the utilities added previously to infer types from type annotations on
variable declarations. This is a limited form, where currently we only infer for
local identifiers (not function parameters) and only infer a type for the
variable initializer and not subsequent reassignments.
This PR uses the information from type cast expressions (`as` or `(variable:
type)`) to inform type inference. BuildHIR converts the type annotation to our
internal type format where possible, falling back to the generic `makeType()`.
This is then used in InferTypes to help set the value's type.
Extends the previous analysis to work for PropertyLoad and ComputedLoad, so that
if the object is a prop we track the resulting value as a signal. We also
disallow PropertyLoad/ComputedLoad outside of a reactive scope where the object
is a signal (since that would drop reactivity).
Previously the only way to replace a value was to override transformInstruction
and transformTerminal, and to be careful to find nested values. This PR adds
`ReactiveFunctionTransform#transformValue()` which allows returning an optional
new value, which if present will replace the value in whatever context it
appeared. ReactiveFunctionTransform now reimplements all the methods necessary
to replace any value anywhere in the AST. See the next PR for an example usage.
I realized this while working on Forest. When computing the dependencies of a
reactive scope we can omit setState functions in the general case (exception
described below). Currently that's implemented in PruneNonReactiveDependencies.
However, this causes us to miss some optimizations — a value isn't reactive if
its only dependency is a setState, and that may allow further downstreams values
to become non-reactive. We lose out on that by only filtering out setStates in
PruneNonReactiveDependencies — this logic really belongs in InferReactivePlaces.
So this PR moves the check for setState types to that pass. The updated fixtures
show that this already uncovers some wins. The _new_ fixtures covers the
exception. It's possible for a value to be typed as being a setState function,
but to still be reactive: if its a local that is conditionally assigned
different setState function values. Currently this test happens to work because
our phi type inference is incomplete (see #2296). I'm adding the test now though
to prevent regressions when we fix phi type inference.
In normal React certain operations don't allocate new objects (property loads,
binary expressions, etc) and therefore don't need a reactive scope in Forget.
For example, property loads only extract part of an existing value and don't
allocate something new, while binary expressions are known to produce primitive
values that don't allocate. We rely on the fact that whenever their inputs
change we will re-run the component/hook and propagate the result forward.
For Forest, the only way to propagate data is via reactive scopes: the component
code is equivalent to a "setup" function. This PR updates some of our passes to
ensure that we create (and don't prune) scopes for these types of operations. I
started with a conservative set for now.
The previous PR converts reactive scopes to normal instructions, so that Forest
mode won't have any scopes left by the time we reach codegen. This PR removes
the now-unused codegen logic for forest.
For Forest, we previously converted reactive scopes into derived signals during
Codegen. I'm moving this to a separate pass primarily to keep codegen simple
since there's enough complexity just dealing with core JS semantics. Ideally
we'd do a similar setup even for regular Forget, ie lower reactive scopes just
prior to codegen.
At the same time i also reordered the forget passes to be just before codegen,
and cleaned things up a bit. For state lowering, we now just rewrite `useState`
-> `createState`, because we actually need to keep around the setter function to
trigger scheduling updates in addition to writing the signal value.
It seems worthwhile to me to run a test to experiment with different
expiration times. This moves the expiration times for scheduler and
reconciler into FeatureFlags for the facebook build. Non-facebook should
not be affected by these changes.
Postponing in a promise that is being serialized to the client from the
server should be possible however prior to this change Flight treated
this case like an error rather than a postpone. This fix adds support
for postponing in this position and adds a test asserting you can
successfully prerender the root if you unwrap this promise inside a
suspense boundary.
Add a regression test for the [minimal
repro](https://codesandbox.io/s/react-18-suspense-state-never-resolving-bug-hmlny5?file=/src/App.js)
from @kassens
And includes the fix from @acdlite:
> This is another place we special-case Retry lanes to opt them out of
expiration. The reason is we rely on time slicing to unwrap uncached
promises (i.e. async functions during render). Since that ability is
still experimental, and enableRetryLaneExpiration is Meta-only, we can
remove the special case when enableRetryLaneExpiration is on, for now.
---------
Co-authored-by: Andrew Clark <git@andrewclark.io>
Small test similar to few tests added in #27740 , the `reactDom-input`
error message was just modified to match the error message, and the
`reactDomTextarea-test.js` has tests added to ensure more coverage.
I recently added generation of this file in #27786, which builds the
file in CircleCI, but missed actually copying it to the facebook build
on GitHub Actions.
This adds the later.
## Summary
Concurrent rendering has been the default since React 18 release.
ReactTestRenderer requires passing `{unstable_isConcurrent: true}` to
match this behavior, which means by default tests written with RTR use a
different rendering method than the code they test.
Eventually, RTR should only use ConcurrentRoot. As a first step, let's
add a version of the concurrent option that isn't marked unstable. Next
we will follow up with removing the unstable option when it is safe to
merge.
## How did you test this change?
`yarn test
packages/react-test-renderer/src/__tests__/ReactTestRendererAsync-test.js`
As part of the process of removing the deprecated `react-dom/test-utils`
package references to `act` from this module are replaced with
references to `unstable_act` in `react`. It is likely that the unstable
act implementation will be made stable. The test utils act is just a
reexport of the unstable_act implementation in react itself.
Found from eslint validator on www after doing a local sync + RunForget test of
#2432
P898168203
> New Errors:
> no-undef:'VARIABLE_NAME' is not defined.
---
I modeled guards as try-finally blocks to be extremely explicit. An alternative
implementation could flatten all nested hooks and only set / restore hook guards
when entering / exiting a React function (i.e. hook or component) -- this
alternative approach would be the easiest to represent as a separate pass
```js
// source
function Foo() {
const result = useHook(useContext(Context));
...
}
// current output
function Foo() {
try {
pushHookGuard();
const result = (() => {
try {
pushEnableHook();
return useHook((() => {
try {
pushEnableHook();
return useContext(Context);
} finally {
popEnableHook();
}
})());
} finally {
popEnableHook();
};
})();
// ...
} finally {
popHookGuard();
}
}
// alternative output
function Foo() {
try {
// check current is not lazyDispatcher;
// save originalDispatcher, set lazyDispatcher
pushHookGuard();
allowHook(); // always set originalDispatcher
const t0 = useContext(Context);
disallowHook(); // always set LazyDispatcher
allowHook(); // always set originalDispatcher
const result = useHook(t0);
disallowHook(); // always set LazyDispatcher
// ...
} finally {
popHookGuard(); // restore originalDispatcher
}
}
```
Checked that IG Web works as expected
Unless I add a sneaky useState:
<img width="705" alt="Screenshot 2023-12-05 at 6 44 59 PM"
src="https://github.com/facebook/react-forget/assets/34200447/3790bd76-7d71-44b5-a62e-f53256fb5736">
---
Prior to this PR, we were mutating functions after CodegenReactiveFunction
completes (in `Entrypoint/Program.ts`).
The reasoning for this separation was that we wanted to keep non-compiler logic
out of the core Pipeline. However, it made our code difficult to read and reason
about.
Open to other alternatives, like adding a pass after Codegen.
---
Currently on main, rollup does not inline source files
```js
// in packages/babel-plugin-react-forget
// $yarn build
// output
var CompilerError_1 = require("./CompilerError");
Object.defineProperty(exports, "CompilerError", { enumerable: true, get:
function () { return CompilerError_1.CompilerError; } });
// ...
```
I debugged a bit but not familiar with node or rollup.
- It seems that rollup fails to recognize source file imports with this setting,
as resolveId no longer gets called
- current `module` option defaults to `ESNext`, which works for some reason.
Let's revert for now to unblock syncs.
Sanity checked my repro by reinstalling node-modules and cleaning rollup cache.
I do not see references to these modules. Unless there's some dynamic
loading going on (hopefully we should see that in CI) these seem like
they can be removed.
Follow-up on https://github.com/facebook/react/pull/27783.
React Native is actually using `ReactNativeTypes`, which are synced from
this repo. In order to make `isChildPublicInstance` visible for
renderers inside React Native repository, we need to list it in
`ReactNativeTypes`.
Because of current circular dependency between React Native and React,
it is impossible to actually type it properly:
- Can't import any types in `ReactNativeTypes` from local files, because
it will break React Native, once synced.
- Implementations can't use real types in their definitions, because it
will break these checks:
223db40d5a/packages/react-native-renderer/fabric.js (L12-L13)223db40d5a/packages/react-native-renderer/index.js (L12-L14)
I think these have been dead for a while now. If the purpose is
documentation, we should see if we need to improve `yarn test --help` or
something instead.
`hermes-parser` is recommended for all Flow files as it supports the
latest features. I noticed we were still using babel here.
Test Plan:
no diff in output before and after
Adds `isChildPublicInstance` method to both renderers (Fabric and
Paper), which will receive 2 public instances and return if first
argument is an ancestor of the second, based on fibers.
This will be used as a fallback when DOM node APIs are not available:
for Paper renderer or for Fabric without DOM node APIs.
How it is going to be used: to determine which `AppContainer` component
in RN is responsible for highlighting an inspected element on the
screen.
We should probably treat `React.use()` the same as `use()` to allow it
within loops and conditionals.
Ideally this would implement a test that `React` is imported or required
from `'react'`, but we don't otherwise implement such a test.
Bumps [@adobe/css-tools](https://github.com/adobe/css-tools) from 4.0.1
to 4.3.2.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/adobe/css-tools/blob/main/History.md"><code>@adobe/css-tools</code>'s
changelog</a>.</em></p>
<blockquote>
<h1>4.3.2 / 2023-11-28</h1>
<ul>
<li>Fix redos vulnerability with specific crafted css string -
CVE-2023-48631</li>
<li>Fix Problem parsing with :is() and nested :nth-child() <a
href="https://redirect.github.com/adobe/css-tools/issues/211">#211</a></li>
</ul>
<h1>4.3.1 / 2023-03-14</h1>
<ul>
<li>Fix redos vulnerability with specific crafted css string -
CVE-2023-26364</li>
</ul>
<h1>4.3.0 / 2023-03-07</h1>
<ul>
<li>Update build tools</li>
<li>Update exports path and files</li>
</ul>
<h1>4.2.0 / 2023-02-21</h1>
<ul>
<li>Add <a
href="https://github.com/container"><code>@container</code></a>
support</li>
<li>Add <a href="https://github.com/layer"><code>@layer</code></a>
support</li>
</ul>
<h1>4.1.0 / 2023-01-25</h1>
<ul>
<li>Support ESM Modules</li>
</ul>
<h1>4.0.2 / 2023-01-12</h1>
<ul>
<li><a
href="https://redirect.github.com/adobe/css-tools/issues/71">#71</a> :
<a href="https://github.com/import"><code>@import</code></a> does not
work if url contains ';'</li>
<li><a
href="https://redirect.github.com/adobe/css-tools/issues/77">#77</a> :
Regression in selector parsing: Attribute selectors not parsed
correctly</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a
href="https://github.com/adobe/css-tools/commits">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
## Summary
This PR:
- Adds the `"sideEffects": false` flag to the `react-is` package, to
enable proper tree-shaking
## How did you test this change?
React-Redux v9 beta switches its artifacts from separate JS files to
pre-bundled artifacts. While testing builds locally, I noticed that our
use of `react-is` was no longer getting tree-shaken from Vite builds,
despite `react-is` only being used by our `connect` API and `connect`
itself getting shaken out of the final bundle.
Hand-adding `"sideEffects": false` to the `react-is` package locally
convinced Vite (+Rollup) to properly tree-shake `react-is` out of the
bundle when it wasn't being used.
I'd love to see this published as v18.2.1 as soon as this PR is merged -
we're hoping to release React-Redux v9 in the next few weeks!
jsxBracketSameLine deprecated in v2.4.0 of Prettier, replaced by
bracketSameLine.
https://prettier.io/docs/en/options.html#deprecated-jsx-brackets
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
I've always wanted to contribute to open source, even if it's in the
smallest way possible. Resolves deprecated feature with currently used
version of Prettier (2.4+). Those doing things like using React as a
reference for their ".prettierrc" files will be using the non-deprecated
versions.
## How did you test this change?
Modified line 969 of App.js to push </h1> to line 971, saved the file,
then ran "yarn prettier" and formatting returned it to original position
confirming that jsxBracketSameLine acts in the same fashion to
bracketSameLine, but also is no longer deprecated that has additional
features which may be useful in the future to the project.
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
λ yarn prettier
yarn run v1.22.19
$ node ./scripts/prettier/index.js write-changed
> git merge-base HEAD main
> git diff --name-only --diff-filter=ACMRTUB
bbb9cb116d
> git ls-files --others --exclude-standard
Done in 1.52s.
## Summary
Follow up from #27717 based on feedback to rename the fork module itself
## How did you test this change?
- `yarn build`
- `yarn test
packages/scheduler/src/__tests__/SchedulerUMDBundle-test.internal.js`
Co-authored-by: Jack Pope <jackpope@meta.com>
New approach to hooks validation per recent discussion. The idea is to avoid
false positives while still preventing serious violations. See the comments in
the file for more details about the approach. It uses a somewhat similar idea to
InferReferenceEffects in that we track a "Kind" for each IdentifierId, and
various instructions propagate or derive a result Kind from the operands. Kinds
form a lattice and can be joined, allowing us to be more precise about known vs
potential hooks, and known vs potential _sources_ of hooks.
## Summary
Update legacy reactjs.org links and update to the corresponding ones on
react.dev
## How did you test this change?
Verify all links go to the expected pages
The previous PR helped me realize we weren't handling Array#at correctly. If the
receiver is a mutable value its effect should be Capture and the lvalue effect
needs to be Store. This PR updates the definition for Array#at to make the
receiver Capture, and then updates inference to automatically set the lvalue
effect to Store if _any_ argument (or the receiver) was Capture.
There was one missing piece to the optimization from the previous PR: Array#map
can return an alias to the receiver in its output, which means that mutations of
the result have to be treated as mutations of the receiver. This means we need
to use a Capture effect on the receiver. If that doesn't get downgraded to a
Read bc the value was immutable, we then also need to make the lvalue effect a
Store (so that InferMutableRanges actually looks at it for aliasing).
Improves memoization for cases such as #2409:
```javascript
const x = [];
useEffect(...);
return <div>{x.map(item => <span>{item}</span>)}</div>;
```
We previously thought that the `x.map(...)` call mutated `x` since its kind was
Mutable. However, in this case we can determine that the map call cannot mutate
`x` (or anything else): the lambda does not mutate any free variables and does
not mutate its arguments.
This PR adds a new flag to function signatures, used for method calls only, that
checks for such cases. The idea is that if the receiver is the only thing that
is mutable — including that there are no args which are function expressions
which mutate their parameters — then we can infer the effect as a read. See
tests which confirm that function expressions which capture or mutate their
params bypass the optimization.
Distilled repro of an internal example we found. Forget determines a mutable
range for the array, but that mutable range spans a hook call, so the reactive
scope gets pruned. That's all working as expected.
What isn't ideal though is that if we know `x` is an array and `f` can't mutate
its arguments, then `x.map(f)` shouldn't count as a mutation of `x`, since
Array.prototype.map can only mutate the receiver via the callback (if the
callback mutates its args).
Improving on this example requires a) we have to know it's an Array, via type
information or bc we saw an array literal and b) being precise about which
functions could possibly mutate their parameters, which is tricky because of
indirect mutations via stores, etc.
We were using `returnValueKind` from function signatures for CallExpression but
not MethodCall; this PR changes to use this signature information for both
instruction kinds.
---
Going to hold off on landing until after codefreeze, it's not urgent as we
already fixed playground in #2404. All other internal pipelines do error
handling through Entrypoint, which catches and creates UnexpectedErrors as
needed.
Instead of using the source location to check for hoisting, just stop checking
for a given component after we reach it's declaration.
By definition all references to it before are (potential) hoisting errors.
Note that there could be false positives but that's ok.
This PR adds a new FB-specific configuration of Flight. We also need to
bundle a version of ReactSharedSubset that will be used for running
Flight on the server.
This initial implementation does not support server actions yet.
The FB-Flight still uses the text protocol on the server (the flag
`enableBinaryFlight` is set to false). It looks like we need some
changes in Hermes to properly support this binary format.
Extends the validation that effect deps are memoized to handle an additional
case that @gsathya pointed out: when a dependency has a reactive scope but that
scope ends up being pruned. We track reactive scopes which actually exist in the
ReactiveFunction, and reject useEffect deps that have an associated reactive
scope but where that scope does not exist (bc it got pruned).
This is one approach to testing whether useEffect dependencies are memoized. The
idea is based off the observation that the only reason dependencies wouldn't be
memoized (other than compiler bugs) is that they are mutated later. If they're
mutated later, then the dep array will have a mutable range which encompasses
the InstructionId of the useEffect call. So we look for that pattern and throw a
validation error.
The downside of this approach is that we might reject code that happens to be
valid: specifically, that the lack of memoization isn't a problem in practice
because the effect won't trigger a loop. But (per test plan) this doesn't seem
to introduce that many new bailouts on www. Rather than implement a complex
validation that checks whether we un-memoized something that was memoized in the
input, it seems more practical to:
1. Enable this more comprehensive validation against any form of un-memo'd
effect dependency
2. Flip the default for hooks (to assume they follow the rules), which will fix
the primary cause of Forget pessimistically not memoizing dependencies.
## Test Plan
Synced to www and checked output via the upgrade script: a few components stop
getting memoized bc they have un-memoized effect dependencies. Let's chat!
Adds `Forget` badge to all relevant components.
Changes:
- If component is compiled with Forget and using a built-in
`useMemoCache` hook, it will have a `Forget` badge next to its display
name in:
- components tree
- inspected element view
- owners list
- Such badges are indexable, so Forget components can be searched using
search bar.
Fixes:
- Displaying the badges for owners list inside the inspected component
view
Implementation:
- React DevTools backend is responsible for identifying if component is
compiled with Forget, based on `fiber.updateQueue.memoCache`. It will
wrap component's display name with `Forget(...)` prefix before passing
operations to the frontend. On the frontend side, we will parse the
display name and strip Forget prefix, marking the corresponding element
by setting `compiledWithForget` field. Almost the same logic is
currently used for HOC display names.
We are currently just pass the first element, which diverges from the
implementation for web. This is especially bad if you are inspecting
something like a list, where host fiber can represent multiple elements.
This part runs on the backend of React DevTools, so it should not affect
cases for React Native when frontend version can be more up-to-date than
backend's. I will double-check it before merging.
Once version of `react-devtools-core` is updated in React Native, this
should be supported, I will work on that later.
## Summary
After changes in https://github.com/facebook/react/pull/27436, UMD
builds no longer expose Scheduler from ReactSharedInternals. This module
is forked in rollup for UMD builds and the path no longer matches. This
PR updates the path name to match the new module:
ReactSharedInternalsClient.
## How did you test this change?
- `yarn build`
- Inspect `react.development.js` UMD build, observe `Scheduler:
Scheduler` is set in `ReactSharedInternals`, matching
[18.2.0](https://unpkg.com/react@18.2.0/umd/react.development.js)
- ran attribute-behavior fixture app
- Observe no more error `Uncaught (in promise) TypeError: Cannot read
properties of undefined (reading 'unstable_cancelCallback')`
Co-authored-by: Jack Pope <jackpope@meta.com>
We were modifying the Babel AST as a shortcut to lowering function declarations,
instead we can explicitly lower them equivalently to a `let <id> =
<function-expression>`.
When you have your panic threshold set to "NONE" as we recommend, it's easy to
miss that your config is wrong (which makes everything not compile) because
those errors were being silenced. This made debugging FluentUI and the
forget-feedback testapp pretty difficult to figure out at first, and defeats the
purpose of having config validation in the first place.
This pr makes it so InvalidConfig errors always throw, regardless of the panic
threshold set. In general our plugin should never throw at build time due to
component bailouts, but because an InvalidConfig would bailout everything from
being compiled at all, it seems reasonable to throw here
Babel doesn't attach Comment nodes to anything, so they dangle off of
the Program node while only specifying a range. This meant that
previously we first had to traverse all of the Program's comments to
find an eslint suppression of the rules of React, then during traversal
of the individual functions, we would check if there were any *global*
eslint suppressions, then bailout all components.
This PR updates our logic to determine if individual functions are
affected by an eslint suppression range:
- If an eslint suppression range falls within its body; or
- If an eslint suppression wraps the function
---
16 out of ~150 recently added sprout fixtures have exceptions that reflect
easy-to-miss mistakes in the fixture input, like forgetting to import
`useState`.
This PR adds snapshot files for sprout to prevent these mistakes (or catch them
at diff review time). This describes what it implements, but happy to take other
suggestions as well!
1. One sprout snapshot file for each input.
This significantly increases the number of files we have, but makes it clear
what the fixture is testing. I was hoping to expand on these snapshots to record
the result of multiple re-renders, or mounts (with different parameters), but
the tradeoff is that adding / changing fixtures will now require running `yarn
sprout --mode update`.
Some alternatives I've considered:
- Only record snapshots for fixtures that error (`result.kind == "exception"`).
This change would be pretty easy. This doesn't help sanity check sprout results
for general mistakes though ("am I testing what I want to test?)
- Warn loudly for fixtures that error -- seems like these are easy to ignore,
but.. worth it for the convenience?
- Some github action that runs and comments on your PR with sprout fixture
changes; i.e. never manually update sprout files?
2. Sprout and snap share a common snapshot file, with some parsing hackery.
Previously, the implementation added new files to a separate sprout snapshot
directory, assuming that devs don't need to read these often.
After feedback from @josephsavona, I updated to have snap and sprout write to
the same file for ease of reviewing / debugging (to be able to see the input /
output side by side).
- `snap --mode update` will update snap's part of the file.
- `sprout --mode update` will update sprout's part
- `snap` and `sprout` will both compare oldSnapshot (read from the file) with
`newSnapshot = merge(oldSnapshot, newData)` to determine if a test pass.
3. Some hacks 😅 Absolute paths to project directory (e.g. stack traces) are
replaced with `<project_root>` in a mocked `console.log`
---
jsdom and other libraries seem to cause jest workers to exit with
`forceExit:true`. Not sure what option I set (or global I've overwritten) but
console logs aren't flushed as a result, making debugging a bit confusing.
This PR:
- Moves some code from `eval(...)` to a typechecked real js function. I always
had trouble debugging the `eval`ed code, so smaller code snippet is better here.
- waits for jest workers to end before exiting
## Summary
I had to change the commands to be windows specific so that it doesn't
cause any crashes
## How did you test this change?
I successfully built the different types of devtools extenstions on my
personal computer. In future may need to add a github action with
windows config to test these errors
#27193
I ran the plugin with the extended version of ValidateNoSetStateInRender enabled
(incl. function expressions) and there are no false positives. Let's remove the
flag for the function expression case since the whole rule is working
accurately.
Repro from T169063835. This works, but since it came up it seems good to add a
test case for it just in case there's something funny here that we could regress
on w/o realizing it.
Fixes one category of bugs with const hoisting. The algorithm finds all consts
that need to be hoisted, then looks through the statements of a block to find
the first statement which references that const, delaying the emission of the
HoistedConst instruction until its actually used. To determine if a statement
references a const we find every identifier in the statement and check if its
binding is one of the hoisted bindings.
There's a very small bug here: when we resolve the binding of each identifier,
we need to resolve it in its own scope. We're currently resolving these
identifiers agains the outer block statement's scope, which can cause us to
misattribute identifiers when there is shadowing:
```
const items = props.items.map(x => x); // we scan this statement, resolve 'x' in
the block statement scope, and mis-attribute it to the outer x.
const x = 42; // (1) this x is a candidate for hoisting, so the binding is in
the set of hoisted consts
```
I had added a repro for this earlier but hadn't realized it was due to const
hoisting. Renaming this test to clarify what's causing the problem and to make
it easier to find.
`onHeaders` can throw however for now we can assume that headers are
optimistic values since the only things we produce for them are preload
links. This is a pragmatic decision because React could concievably have
headers in the future which were not optimistic and thus non-optional
however it is hard to imagine what these headers might be in practice.
If we need to change this behavior to be fatal in the future it would be
a breaking change.
This commit adds error logging when `onHeaders` throws and ensures the
request can continue to render successfully.
This is non ideal but at least it's a step in the right direction.
Getting the correct error requires us to track every identifier and global,
which seems a bit excessive for now.
We can revisit and improve this error if this is starting to confuse folks.
In https://github.com/facebook/react/pull/27472 I've removed broken
`useMemoCache` implementation and replaced it with a stub. It actually
produces errors when trying to inspect components, which are compiled
with Forget.
The main difference from the implementation in
https://github.com/facebook/react/pull/26696 is that we are using
corresponding `Fiber` here, which has patched `updateQueue` with
`memoCache`. Previously we would check it on a hook object, which
doesn't have `updateQueue`.
Tested on pages, which are using Forget and by inspecting elements,
which are transpiled with Forget.
---
We were throwing `InvalidReact` errors on valid inputs.
```js
// Input
function Foo() {
log("block0");
for (const _ of foo) {
log("loop");
}
useBar();
}
// IR
bb0:
// log("block0");
ForOf init=bb2 loop=bb3 fallthrough=bb1
bb2:
// init
Branch: then:bb3 else:bb1
bb3:
// log("loop")
Goto(Continue) bb2
bb1:
// useBar();
Return
```
We correctly compute post dominators here.
```js
// In validateUnconditionalHooks
console.log(dominators.debug());
/* Output:
(read x => y as x is the post-dominator for y (all paths from x to the exit must
go through y))
"bb4" => "bb4",
"bb1" => "bb4",
"bb2" => "bb1",
"bb3" => "bb2",
"bb0" => "bb2",
*/
```
However, `findBlocksWithBackEdges` prevented us from adding `bb1` to the
`unconditionalBlocks` set as `bb2` (its post dominator) has a back edge. I'm not
sure what the `findBlocksWithBackEdges` was doing previously, so I replaced it
with an invariant asserting that the loop terminates.
---
Snap should compile all fixtures to record changes in results, even `todo`
prefixed ones. Previously, they were skipped as we noted the correlation of `//
@skip` pragmas and file naming.
Now, no fixture should be skipped as our compiler pipeline should be able to
handle every kind of error.
An attempt to see if we can bring back expiration of retry lanes to
avoid cases resolving Suspense can be starved by frequent updates.
In the past, this caused increase browser crashes, but a lot of time has
passed since then. Just trying if we can re-enable this.
Old PR that reverted adding the timeout:
https://github.com/facebook/react/pull/21300
Noticed from our paste that we weren't correctly rolling up hoisting related
errors due to specific information being in the error title, so this PR moves
them into description instead.
Updates the approach used in ValidateNoSetStateInRender to detect function
expressions called during render. We now do the following:
* Track function expression which are known to unconditionally call setState
themselves- if these functions get called, that’s equivalent to calling
setState. We call the validation recursively to compute this.
* Track LoadLocal/StoreLocal indirections for such function expressions.
* Check CallExpressions where the callee is either a known SetState (via type
info) _or_ (new) where the callee is in the set of known-to-setState function
expressions.
The Set is shared throughout the analysis, so we can even find multiple levels
of indirection (see new test case).
I found an interesting edge case in the previous diff with mutation of a value
that appears in the expression of an object key:
```javascript
const key = {}
const object = {
[mutateAndReturnOtherValue(key)]: 42,
};
mutate(key);
```
We analyze and represent this correctly all the way through to codegen, but then
we hit the bug that @mofeiZ has noticed before: the temporary for `t =
mutateAndReturnOtherValue(key)` isn't emitted immediately (bc its a temporary).
It gets emitted inside the memo block for `object`, which is incorrect.
I tried to reproduce that here with JSX and it works as expected. It's an
interesting case though so let's land this to ensure we don't regress.
Adds a separate compiler flag for enabling the incomplete validation of ref
access within function expressions. Unlike the previous PR for
set-state-in-render validation, ref access in render can be okay in some
circumstances so i'm leaving this off by default. The point of splitting this up
is that our linting will be able to enable the rule without risk of false
positives.
The approach i initially took to validating function expressions was to try to
extend the mutable range if they are called during render, and then use the
mutable range of a function to determine if it's called during render later.
However there are cases where the range can be extended for other reasons, as
@poteto discovered, so we can't rely on the range extension. We've had several
of our validations completely off as a result of this.
In this PR i'm re-enabling @poteto's ValidateNoSetStateInRender pass by default,
but making the function expression checking use a separate compiler flag. This
means we'll have some false negatives, but should guarantee that we avoid false
positives. This means we can definitely catch things like:
```
const [state, setState] = useState(false);
setState(true);
```
Which we would have allowed by default before.
This reverts commit 10d129a8406e9d226abdb6943bf8512e34ce91db
---
Reverts #2311 due to undocumented assumptions being broken. I also added some
comments to `LoggerEvents` to explain each event type.
In `Program.ts`, we have something like the following code. `compile` could
produce any number of errors (not just expected errors / instances of
`CompilerError`). As an example, we sometimes error in `Codegen` due to babel
version incompatibilities (`Error: ObjectMethod: Too many arguments passed.
Received 7 but can receive no more than 5`).
```js
try {
// any error could be thrown here
compile(input);
} catch (e) {
// unknown type for e
handleError(e, ...);
}
```
## Summary
Forget compiled code currently cannot be tested with ReactTestRender as
`useMemoCache` is not being set on the dispatcher. This PR ensures that
projects can execute unit tests with Forget compilation in the test
build pipeline.
```js
// source code
function Component(props) {
// ...
}
// transformed code, which also should be evaluated in unit tests
function Component(props) {
const $ = useMemoCache(...);
// ...
}
```
This PR enables the `enableUseMemoCacheHook` feature flag for all bundle
variations of ReactTestRenderer. Forget *should* be the only caller of
useMemoCache, so this should be a reversible change (in the event we
need to change the implementation or api of the hook).
## How did you test this change?
* Check that generated ReactTestRenderer bundles contain `useMemoCache`.
* Synced to Meta and checked that unit tests that use Forget +
@testing-library/react pass.
I did not add new tests to check that useMemoCache can be called when
using the test renderer as `useMemoCache` is not yet stable. Happy to
add a test case here if that would be helpful to reviewers though (I'm
guessing that would go in
`packages/react-test-renderer/src/__tests__/ReactTestRenderer-test.js` )
These are all functionally equivalent changes.
- remove double negation and more explicit naming of
`hadNoMutationsEffects`
- use docblock syntax that's consumed by Flow
- remove useless cast
When we postpone during a render we inject a new segment synchronously
which we postpone. That gets assigned an ID so we can refer to it
immediately in the postponed state.
When we do that, the parent segment may complete later even though it's
also synchronous. If that ends up not having any content in it, it'll
inline into the child and that will override the child's segment id
which is not correct since it was already assigned one.
To fix this, we simply opt-out of the optimization in that case which is
unfortunate because we'll generate many more unnecessary empty segments.
So we should come up with a new strategy for segment id assignment but
this fixes the bug.
Co-authored-by: Josh Story <story@hey.com>
In order to make Haste work with React's artifacts, It is important to
keep headers in this format:
```
/**
* ...
...
* ...
*/
```
For optimization purposes, Closure compiler will actually modify these
headers by removing * prefixes, which is expected.
We should pass sources to the compiler without license headers, with
these changes the current flow will be:
1. Apply top-level definitions. For UMD-bundles, for example, or
DEV-only bundles (e. g. `if (__DEV__) { ...`)
2. Apply licence headers for artifacts with sourcemaps: oss-production
and oss-profiling bundles, they don't need to preserve the header format
to comply with Haste. We need to apply these headers before passing
sources to Closure, so it can build correct mappings for sourcemaps.
3. Pass these sources to closure compiler for minification and
sourcemaps building.
4. Apply licence headers for artifacts without sourcemaps: dev bundles,
fb bundles. This way the header style will be preserved and not changed
by Closure.
Upgrade Flow to latest using
```
yarn add -W flow-bin flow-remove-types hermes-parser hermes-eslint
```
This also updates `createFlowConfigs.js` to get the Flow version from
`package.json` to avoid needing to bump the version there in the future.
I introduced a bug in a recent change to how bootstrap scripts are
handled. Rather than clearing out the bootstrap script state from
ResumableState on completion of the prerender I did it during the
flushing phase which comes later after the postponed state has likely
been serialized. We should freeze these objects in dev so this is not
possible to do easily in test (nor in actual code in real systems).
This fixes the bug by eliminating the bootstrap config during
getPostponedState which is before the state can be serialized.
Previously it was possible to postpone in the shell during a prerender
and then during a resume the bootstrap scripts would not be emitted
leading to no hydration on the client. This change moves the bootstrap
configuration to `ResumableState` where it can be serialized after
postponing if it wasn't flushed as part of the static shell.
## Summary
There's a bug with the existing stack comparison algorithm in
`describeNativeComponentFrame` — specifically how it attempts to find a
common root frame between the control and sample stacks. This PR
attempts to fix that bug by injecting a frame that can have a guaranteed
string in it for us to search for in both stacks to find a common root.
## Brief Background/How it works now
Right now `describeNativeComponentFrame` does the following to leverage
native browser/VM stack frames to get details (e.g. script path, row and
col #s) for a single component:
1. Throwing and catching a control error in the function
2. Calling the component which should eventually throw an error (most of
the time), that we'll catch as our sample error.
3. Diffing the stacks in the control and sample errors to find the line
which should represent our component call.
## What's broken
To account for potential stack trace truncation, the stack diffing
algorithm first attempts to find a common "root" frame by inspecting the
earliest frame of the sample stack and searching for an identical frame
in the control stack starting from the bottom. However, there are a
couple of scenarios which I've hit that cause the above approach to not
work correctly.
First, it's possible that for render passes of extremely large component
trees to have a lot of repeating internal react function calls, which
can result in an incorrect common or "root" frame found. Here's a small
example from a stack trace using React Fizz for SSR.
Our control frame can look like this:
```
Error:
at Fake (...)
at construct (native)
at describeNativeComponentFrame (...)
at describeClassComponentFrame (...)
at getStackByComponentStackNode (...)
at getCurrentStackInDEV (...)
at renderNodeDestructive (...)
at renderElement (...)
at renderNodeDestructiveImpl (...) // <-- Actual common root frame with the sample stack
at renderNodeDestructive (...)
at renderElement (...)
at renderNodeDestructiveImpl (...) // <-- Incorrectly chosen common root frame
at renderNodeDestructive (...)
```
And our sample stack can look like this:
```
Error:
at set (...)
at PureComponent (...)
at call (native)
at apply (native)
at ErrorBoundary (...)
at construct (native)
at describeNativeComponentFrame (...)
at describeClassComponentFrame (...)
at getStackByComponentStackNode (...)
at getCurrentStackInDEV (...)
at renderNodeDestructive (...)
at renderElement (...)
at renderNodeDestructiveImpl (...) // <-- Root frame that's common in the control stack
```
Here you can see that the earliest trace in the sample stack, the
`renderNodeDestructiveImpl` call, can exactly match with multiple
`renderNodeDestructiveImpl` calls in the control stack (including file
path and line + col #s). Currently the algorithm will chose the
earliest/last frame with the `renderNodeDestructiveImpl` call (which is
the second last frame in our control stack), which is incorrect. The
actual matching frame in the control stack is the latest or first frame
(when traversing from the top) with the `renderNodeDestructiveImpl`
call. This leads to the rest of the stack diffing associating an
incorrect frame (`at getStackByComponentStackNode (...)`) for the
component.
Another issue with this approach is that it assumes all VMs will
truncate stack traces at the *bottom*, [which isn't the case for the
Hermes
VM](df07cf713a/lib/VM/JSError.cpp (L688-L699))
which **truncates stack traces in the middle**, placing a
```
at renderNodeDestructiveImpl (...)
... skipping {n} frames
at renderNodeDestructive (...)
```
line in the middle of the stack trace for all stacks that contain more
than 100 traces. This causes stack traces for React Native apps using
the Hermes VM to potentially break for large component trees. Although
for this specific case with Hermes, it's possible to account for this by
either manually grepping and removing the `... skipping` line and
everything below it (see draft PR: #26999), or by implementing the
non-standard `prepareStackTrace` API which Hermes also supports to
manually generate a stack trace that truncates from the bottom ([example
implementation](https://github.com/facebook/react/compare/main...KarimP:react:component-stack-hermes-fix)).
## The Fix
I found different ways to go about fixing this. The first was to search
for a common stack frame starting from the top/latest frame. It's a
relatively small change ([see
implementation](https://github.com/facebook/react/compare/main...KarimP:react:component-stack-fix-2)),
although it is less performant by being n^2 (albeit with `n`
realistically being <= 5 here). It's also a bit more buggy for class
components given that different VMs insert a different amount of
additional lines for new/construct calls...
Another fix would be to actually implement a [longest common
substring](https://en.wikipedia.org/wiki/Longest_common_substring)
algorithm, which can also be roughly n^2 time (assuming the longest
common substring between control and sample will be most of the sample
frame).
The fix I ended up going with was have the lines that throw the control
error and the lines that call/instantiate the component be inside a
distinct method under an object property
(`"DescribeNativeComponentFrameRoot"`). All major VMs (Safari's
JavaScriptCore, Firefox's SpiderMonkey, V8, Hermes, and Bun) should
display the object property name their stack trace. I've also set the
`name` and `displayName` properties for method as well to account for
minification, any advanced optimizations (e.g. key crushing), and VM
inconsistencies (both Bun and Safari seem to exclusively use the value
under `displayName` and not `name` in traces for methods defined under
an object's own property...).
We can then find this "common" frame by simply finding the line that has
our special method name (`"DescribeNativeComponentFrameRoot"`), and the
rest of the code to determine the actual component line works as
expected. If by any chance we don't find a frame with our special method
name in either control or sample stack traces, we then revert back to
the existing approach mentioned above by searching for the last line of
the sample frame in the control frame.
## How did you test this change?
1. There are bunch of existing tests that ensure a properly formatted
component trace is logged for certain scenarios, so I ensured the
existing full test suite passed
2. I threw an error in a component that's deep in the component
hierarchy of a large React app (facebook) to ensure there's stack trace
truncation, and ensured the correct component stack trace was logged for
Chrome, Safari, and Firefox, and with and without minification.
3. Ran a large React app (facebook) on the Hermes VM, threw an error in
a component that's deep in the component hierarchy, and ensured that
component frames are generated despite stack traces being truncated in
the middle.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
The flag has been tested internally on WWW, should be good to set to
true for OSS. Added a dynamic flag for fb RN.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
yarn test
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
This PR updates the Rollup build pipeline to generate sourcemaps for
production build artifacts like `react-dom.production.min.js`.
It requires the Rollup v3 changes that were just merged in #26442 .
Sourcemaps are currently _only_ generated for build artifacts that are
_truly_ "production" - no sourcemaps will be generated for development,
profiling, UMD, or `shouldStayReadable` artifacts.
The generated sourcemaps contain the bundled source contents right
before that chunk was minified by Closure, and _not_ the original source
files like `react-reconciler/src/*`. This better reflects the actual
code that is running as part of the bundle, with all the feature flags
and transformations that were applied to the source files to generate
that bundle. The sourcemaps _do_ still show comments and original
function names, thus improving debuggability for production usage.
Fixes#20186 .
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
This allows React users to actually debug a readable version of the
React bundle in production scenarios. It also allows other tools like
[Replay](https://replay.io) to do a better job inspecting the React
source when stepping through.
## How did you test this change?
- Generated numerous sourcemaps with various combinations of the React
bundle selections
- Viewed those sourcemaps in
https://evanw.github.io/source-map-visualization/ and confirmed via the
visualization that the generated mappings appear to be correct
I've attached a set of production files + their sourcemaps here:
[react-sourcemap-examples.zip](https://github.com/facebook/react/files/11023466/react-sourcemap-examples.zip)
You can drag JS+sourcemap file pairs into
https://evanw.github.io/source-map-visualization/ for viewing.
Examples:
- `react.production.min.js`:

- `react-dom.production.min.js`:

- `use-sync-external-store/with-selector.production.min.js`:

<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
Adds a new option to `react-dom/server` entrypoints.
`onHeaders: (headers: Headers) => void` (non node envs)
`onHeaders: (headers: { Link?: string }) => void` (node envs)
When any `renderTo...` or `prerender...` function is called and this
option is provided the supplied function will be called sometime on or
before completion of the render with some preload link headers.
When provided during a `renderTo...` the callback will usually be called
after the first pass at work. The idea here is we want to get a set of
headers to start the browser loading well before the shell is ready. We
don't wait for the shell because if we did we may as well send the
preloads as tags in the HTML.
When provided during a `prerender...` the callback will be called after
the entire prerender is complete. The idea here is we are not responding
to a live request and it is preferable to capture as much as possible
for preloading as Headers in case the prerender was unable to finish the
shell.
Currently the following resources are always preloaded as headers when
the option is provided
1. prefetchDNS and preconnects
2. font preloads
3. high priority image preloads
Additionally if we are providing headers when the shell is incomplete
(regardless of whether it is render or prerender) we will also include
any stylesheet Resources (ones with a precedence prop)
There is a second option `maxHeadersLength?: number` which allows you to
specify the maximum length of the header content in unicode code units.
This is what you get when you read the length property of a string in
javascript. It's improtant to note that this is not the same as the
utf-8 byte length when these headers are serialized in a Response. The
utf8 representation may be the same size, or larger but it will never be
smaller.
If you do not supply a `maxHeadersLength` we defaul to `2000`. This was
chosen as half the value of the max headers length supported by commonly
known web servers and CDNs. many browser and web server can support
significantly more headers than this so you can use this option to
increase the headers limit. You can also of course use it to be even
more conservative. Again it is important to keep in mind there is no
direct translation between the max length and the bytelength and so if
you want to stay under a certain byte length you need to be potentially
more aggressive in the maxHeadersLength you choose.
Conceptually `onHeaders` could be called more than once as new headers
are discovered however if we haven't started flushing yet but since most
APIs for the server including the web standard Response only allow you
to set headers once the current implementation will only call it one
time
Had these stashed for some time, it includes:
- Some refactoring to remove unnecessary `FlowFixMe`s and type castings
via `any`.
- Optimized version of parsing component names. We encode string names
to utf8 and then pass it serialized from backend to frontend in a single
array of numbers. Previously we would call `slice` to get the
corresponding encoded string as a subarray and then parse each
character. New implementation skips `slice` step and just receives
`left` and `right` ranges for the string to parse.
- Early `break` instead of `continue` when Store receives unexpected
operation, like removing an element from the Store, which is not
registered yet.
`Activity` is the current candidate name. This PR starts the rename work
by renaming the exported unstable component name.
NOTE: downstream consumers need to rename the import when updating to
this commit.
## Summary
It's not clear to me why we currently create a new TaskController in
`runTask` – ultimately, we use the same signal and priority from the
original created in `unstable_scheduleCallback`
## How did you test this change?
```
yarn test SchedulerPostTask
```
I experimented with more variations but prettier collapses most of them: any run
of consecutive whitespace within a jsxtext node will get collapsed into a single
space, for example. So the main difference in practice is whether a jsxtext node
(preceding a value) has a trailing space/newline or not:
```
Text <fbt:param /> Text
// vs
Text<fbt:param />Text
```
which we now have tests for.
Turns out this will cause an OOM in node.js when running eslint as part of the
IDE
``` Before: 16M packages/eslint-plugin-react-forget/dist/index.js After: 2.2M
packages/eslint-plugin-react-forget/dist/index.js ```
Anytime we have a nested `.scope` in code my brain hurts. For example
`scope.scope.dependencies`. This PR updates the scope merging pass to use the
name `scopeBlock` for a ReactiveScopeBlock and `scope` only for ReactiveScope
values, to make things a bit more clear.
Addresses T168684688 (#2242). MergeReactiveScopesThatInvalidateTogether does not
merge scopes if their output is not guaranteed to change when their inputs do.
So for example a case such as `{session_id: bar(props.bar)}` will not merge the
scopes for `t0 = bar(props.bar)` and `t1 = {session_id: t0}`, because t0 isn't
guaranteed to change when `props.bar` does, and we want to avoid recreating the
t1 object unless it semantically changes.
But there's a special case: if a scope has no dependencies, then we'll never
execute it again anyway. So it doesn't matter what kind of value it produces and
it's safe to merge with subsequent scopes:
```javascript
return {session_id: bar()}
```
Without the reactive input, `bar()` will always return the same value since
we'll only ever call it once anyway. So it's safe to then merge with the scope
for the outer object literal.
Current sprout output (if you remove the line in `SproutTodoFilter`):
```
Failures:
FAIL: bug-fbt-preserve-whitespace
Difference in forget and non-forget results.
Expected result: {
"kind": "ok",
"value": "Before text hello world",
"logs": []
}
Found: {
"kind": "ok",
"value": "Before texthello world",
"logs": []
}
```
`fbt` transforms run before jsx ones, so our lowering should also account for
[fbt's whitespace
rules](https://github.com/facebook/fbt/blob/main/packages/babel-plugin-fbt/src/fbt-nodes/FbtImplicitParamNode.js#L230-L233)
in `BuildHIR:trimJsxText`.
Fbt + typescript [seems](https://github.com/facebook/fbt/issues/49) [to
be](https://github.com/facebook/sfbt/issues/72) a non-blessed workflow. We do
want to allow for both flow and typescript tests, so I followed some
instructions [from a
guide](https://dev.to/retyui/how-to-add-support-typescript-for-fbt-an-internationalization-framework-3lo0)
to add support.
- fbt tags desugar to.. "fbt" strings. By default, typescript removes unused
imports at parse step (and on autoformat steps). We pass special
babel-typescript configs and change vscode settings to mitigate this.
- I tried adding `fbt` to the global scope, but the fbt transform asserts that
`fbt` is actually imported in the source program.
- Other hacks are available, like saying we'll only allow for fbt in flow files,
or always patching the source code to have an "fbt" import. This seemed the most
reasonable and easiest to debug / follow when writing tests
---
Refactor selection logic to be easier to read; add support for .jsx test files
(feels a bit weird adding a `.jsx` fixture and not seeing it get run)
In order to make changes to the testapp's dependencies, we need to update the
lockfile which means modules need to actually exist. This adds a new script to
just run a build of the packages we sync so that module resolution in the
testapp will work
Reusing DEFAULT_HOOKS instance is a bit scary in case we mutate it by mistake
and this gets reflected across all compiles.
This isn't a concern now as we can't change the config during compilation. But
this PR keeps us safe in case we change this behavior in the future.
The tradeoff is a bit of perf which I think is the right tradeoff here.
I did a double take when I thought we didn't handle returning the
error when reading the code and when I edited the code, typescript told
me that there's no need to return as creating the error will throw.
This PR makes it clear from the name of the function that we will throw.
We should only add imports if we actually compiled anything, this is what caused
the internal issue despite the file in question not having any functions
opted-in to compilation.
When an `environment` isn't explicitly provided by the user's config, we used to
default this to `null` in `parsePluginOptions` which is called right at the
start of the Babel plugin. These parsed options were then being passed to zod,
which was expecting an object type, not null.
Zod can reify a default config based on the schema, if an empty object is passed
in. So by changing our default value to `{}` this should fix the compiler
bailing out incorrectly on valid compiler options
Test plan: tested this manually on the external repo by modifying node_modules
Use zod to do runtime validation and throw if incorrect.
This PR only adds validation for ExternalFunction, will validate other options
in follow on PRs.
This PR adds a feature flag to model a potential new-in-practice rule in React:
that freezing a function expression also freezes its closed-over values,
transitively. For example, in the following code `data` is frozen when the
lambda that captures it is is passed to useEffect:
```javascript
const data = [];
// useEffect freezes its argument (the function expr), which transitively
freezes its captured value data
useEffect(() => {
foo(data);
}, [data]);
data.push(true); // ERROR: mutating a frozen value
mutate(data); // we conservatively assume this doesn't mutate but could be wrong
```
Note that this rule has never been written down or enforced. It is theoretically
equivalent to the rule (already implemented in Forget) that values captured by
JSX are frozen:
```javascript
const style = {...};
<div style={style}>...</div>
style.width = 10; // ERROR: mutating a frozen value
mutate(style); // we conservatively assume this doesn't mutate but could be
wrong
```
However, JSX is typically constructed toward the very end of a render function.
Thus in practice there isn't much subsequent code that could even modify such a
captured value. But for the useEffect case (and other hooks that take closures
as arguments), they tend to occur much earlier in a render function. There's
more code that can run later and still modify the captured values, without
causing issues in practice. The _practical_ rule today is that you can't modify
values captured by frozen lambdas _after the component returns_: it's fine in
practice to modify captured values between calling eg useEffect and returning
from render.
Thus this feature flag is fairly likely to break some percent of real product
code. I'm adding this so that we can experiment and see how unsafe it actually
is.
Adds an internal compiler assertion pass which checks that all the instructions
which are necessary for constructing a given scope correctly end up within the
corresponding ReactiveScopeBlock. All known cases where this can occur are fixed
earlier in the stack, but this assertion will help us catch any other cases we
haven't thought of. See docblock comment for more info.
## Test Plan
I manually reverted the fixes from the previous PRs while keeping the new
fixtures, and verified that this new assertion pass flags the fixtures as
invalid.
The previous changes mostly meant that we removed the label terminal and didn't
have instructions for the same scope split in a way that we couldn't merge. But
logicals were still causing a split because MergeConsecutiveScopes can't merge
the blocks in that case. Here we move PruneUnusedLabels earlier in the pipeline
to ensure that instructions from IIFEs have floated up to the parent block scope
level.
Fixes for the previous PR. What was happening is that our inference was
inferring the correct mutable ranges and reactive scopes, but the inlining
process left the instructions from the IIFEs inside a separate block, with a
'label' terminal preceding it. When we converted to ReactiveFunction this was
preserved as a ReactiveLabelTerminal, which meant that the first instruction for
the mutable range could be nested inside one LabelTerminal, while more would be
in a subsequent LabelTerminal. But we close blocks based on the block scope!
This meant that we'd have leftover instructions (in the second LabelTerminal)
that got left out of the block.
Furthermore, because inlining was happening after EnterSSA we weren't creating
phis correctly. This PR fixes a bunch of these issues, and a subsequent PR
handles the remaining cases:
* We move DropManualMemo and InlineIIFEs before EnterSSA. This means we lose the
ability to use type information, but we ensure that we create proper SSA ids and
phis for any reassignments within the IIFE
* We also update PruneUnusedLabels to not just remove the unused labels, but to
actually remove LabelTerminals that don't need them.
We construct invalid mutable ranges in these cases because the range starts
within a labeled block. We need to run merge consecutive scopes and EnterSSA
after inlining so that the code is lifted out of the labeled block to the
correct scope, and so that we create phis for reassignments within the IIFE.
This has caused issues for people when things like Babel cause issues. It's not
actionable and it crashes eslint. Just like the Babel plugin, the eslint plugin
should never throw. Instead, let's log the error so the data isn't lost.
This combines our scripts and makes it so we no longer need to create a separate
commit to add the forget-feedback/dist directory into the react-forget repo. I
originally did that so I could run tests here, but now that the external repo is
created and has its test suite hooked up to CI, this is now unnecessary friction
to run a sync
All of these warnings go away: ``` ➜ playground git:(remove-prettier) ✗ yarn
dev yarn run v1.22.19 $ NODE_ENV=development && next dev ready - started server
on 0.0.0.0:3000, url: http://localhost:3000 warn - You have enabled
experimental feature (appDir) in next.config.js. warn - Experimental features
are not covered by semver, and may cause unexpected or broken application
behavior. Use at your own risk. info - Thank you for testing `appDir` please
leave your feedback at https://nextjs.link/app-feedback
event - compiled client and server successfully in 964 ms (199 modules) wait -
compiling /page (client and server)... warn -
../../node_modules/prettier/index.js Critical dependency: the request of a
dependency is an expression
../../node_modules/prettier/index.js Critical dependency: require function is
used in a way in which dependencies cannot be statically extracted
../../node_modules/prettier/index.js Critical dependency: the request of a
dependency is an expression
../../node_modules/prettier/index.js Critical dependency: the request of a
dependency is an expression
../../node_modules/prettier/third-party.js Critical dependency: the request of a
dependency is an expression wait - compiling... warn -
../../node_modules/prettier/index.js Critical dependency: the request of a
dependency is an expression
../../node_modules/prettier/index.js Critical dependency: require function is
used in a way in which dependencies cannot be statically extracted
../../node_modules/prettier/index.js Critical dependency: the request of a
dependency is an expression
../../node_modules/prettier/index.js Critical dependency: the request of a
dependency is an expression
../../node_modules/prettier/third-party.js Critical dependency: the request of a
dependency is an expression ```
Standalone prettier is meant to be used in the browser:
https://prettier.io/docs/en/browser
Support Flow `as` expressions in ESLint rules, e.g. `<expr> as <type>`.
This is the same syntax as TypeScript as expressions. I just looked for
any place referencing `TSAsExpression` (the TS node) or
`TypeCastExpression` (the previous Flow syntax) and added a case for
`AsExpression` as well.
Bumps
[browserify-sign](https://github.com/crypto-browserify/browserify-sign)
from 4.0.4 to 4.2.2.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/browserify/browserify-sign/blob/main/CHANGELOG.md">browserify-sign's
changelog</a>.</em></p>
<blockquote>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.2.1...v4.2.2">v4.2.2</a>
- 2023-10-25</h2>
<h3>Fixed</h3>
<ul>
<li>[Tests] log when openssl doesn't support cipher <a
href="https://redirect.github.com/browserify/browserify-sign/issues/37"><code>[#37](https://github.com/crypto-browserify/browserify-sign/issues/37)</code></a></li>
</ul>
<h3>Commits</h3>
<ul>
<li>Only apps should have lockfiles <a
href="09a8995939"><code>09a8995</code></a></li>
<li>[eslint] switch to eslint <a
href="83fe46374b"><code>83fe463</code></a></li>
<li>[meta] add <code>npmignore</code> and <code>auto-changelog</code> <a
href="44181838e7"><code>4418183</code></a></li>
<li>[meta] fix package.json indentation <a
href="9ac5a5eaaa"><code>9ac5a5e</code></a></li>
<li>[Tests] migrate from travis to github actions <a
href="d845d855de"><code>d845d85</code></a></li>
<li>[Fix] <code>sign</code>: throw on unsupported padding scheme <a
href="8767739a45"><code>8767739</code></a></li>
<li>[Fix] properly check the upper bound for DSA signatures <a
href="85994cd634"><code>85994cd</code></a></li>
<li>[Tests] handle openSSL not supporting a scheme <a
href="f5f17c27f9"><code>f5f17c2</code></a></li>
<li>[Deps] update <code>bn.js</code>, <code>browserify-rsa</code>,
<code>elliptic</code>, <code>parse-asn1</code>,
<code>readable-stream</code>, <code>safe-buffer</code> <a
href="a67d0eb4ff"><code>a67d0eb</code></a></li>
<li>[Dev Deps] update <code>nyc</code>, <code>standard</code>,
<code>tape</code> <a
href="cc5350b967"><code>cc5350b</code></a></li>
<li>[Tests] always run coverage; downgrade <code>nyc</code> <a
href="75ce1d5c49"><code>75ce1d5</code></a></li>
<li>[meta] add <code>safe-publish-latest</code> <a
href="dcf49ce85a"><code>dcf49ce</code></a></li>
<li>[Tests] add <code>npm run posttest</code> <a
href="75dd8fd6ce"><code>75dd8fd</code></a></li>
<li>[Dev Deps] update <code>tape</code> <a
href="3aec0386dc"><code>3aec038</code></a></li>
<li>[Tests] skip unsupported schemes <a
href="703c83ea72"><code>703c83e</code></a></li>
<li>[Tests] node < 6 lacks array <code>includes</code> <a
href="3aa43cfbc1"><code>3aa43cf</code></a></li>
<li>[Dev Deps] fix eslint range <a
href="98d4e0d7ff"><code>98d4e0d</code></a></li>
</ul>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.2.0...v4.2.1">v4.2.1</a>
- 2020-08-04</h2>
<h3>Merged</h3>
<ul>
<li>bump elliptic <a
href="https://redirect.github.com/browserify/browserify-sign/pull/58"><code>[#58](https://github.com/crypto-browserify/browserify-sign/issues/58)</code></a></li>
</ul>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.1.0...v4.2.0">v4.2.0</a>
- 2020-05-18</h2>
<h3>Merged</h3>
<ul>
<li>switch to safe buffer <a
href="https://redirect.github.com/browserify/browserify-sign/pull/53"><code>[#53](https://github.com/crypto-browserify/browserify-sign/issues/53)</code></a></li>
</ul>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.0.4...v4.1.0">v4.1.0</a>
- 2020-05-05</h2>
<h3>Merged</h3>
<ul>
<li>update deps, modernise usage, use readable-stream <a
href="https://redirect.github.com/browserify/browserify-sign/pull/49"><code>[#49](https://github.com/crypto-browserify/browserify-sign/issues/49)</code></a></li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="4af5a90bf8"><code>4af5a90</code></a>
v4.2.2</li>
<li><a
href="3aec0386dc"><code>3aec038</code></a>
[Dev Deps] update <code>tape</code></li>
<li><a
href="85994cd634"><code>85994cd</code></a>
[Fix] properly check the upper bound for DSA signatures</li>
<li><a
href="9ac5a5eaaa"><code>9ac5a5e</code></a>
[meta] fix package.json indentation</li>
<li><a
href="dcf49ce85a"><code>dcf49ce</code></a>
[meta] add <code>safe-publish-latest</code></li>
<li><a
href="44181838e7"><code>4418183</code></a>
[meta] add <code>npmignore</code> and <code>auto-changelog</code></li>
<li><a
href="8767739a45"><code>8767739</code></a>
[Fix] <code>sign</code>: throw on unsupported padding scheme</li>
<li><a
href="5f6fb17559"><code>5f6fb17</code></a>
[Tests] log when openssl doesn't support cipher</li>
<li><a
href="f5f17c27f9"><code>f5f17c2</code></a>
[Tests] handle openSSL not supporting a scheme</li>
<li><a
href="d845d855de"><code>d845d85</code></a>
[Tests] migrate from travis to github actions</li>
<li>Additional commits viewable in <a
href="https://github.com/crypto-browserify/browserify-sign/compare/v4.0.4...v4.2.2">compare
view</a></li>
</ul>
</details>
<details>
<summary>Maintainer changes</summary>
<p>This version was pushed to npm by <a
href="https://www.npmjs.com/~ljharb">ljharb</a>, a new releaser for
browserify-sign since your current version.</p>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps
[browserify-sign](https://github.com/crypto-browserify/browserify-sign)
from 4.2.1 to 4.2.2.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/browserify/browserify-sign/blob/main/CHANGELOG.md">browserify-sign's
changelog</a>.</em></p>
<blockquote>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.2.1...v4.2.2">v4.2.2</a>
- 2023-10-25</h2>
<h3>Fixed</h3>
<ul>
<li>[Tests] log when openssl doesn't support cipher <a
href="https://redirect.github.com/browserify/browserify-sign/issues/37"><code>[#37](https://github.com/crypto-browserify/browserify-sign/issues/37)</code></a></li>
</ul>
<h3>Commits</h3>
<ul>
<li>Only apps should have lockfiles <a
href="09a8995939"><code>09a8995</code></a></li>
<li>[eslint] switch to eslint <a
href="83fe46374b"><code>83fe463</code></a></li>
<li>[meta] add <code>npmignore</code> and <code>auto-changelog</code> <a
href="44181838e7"><code>4418183</code></a></li>
<li>[meta] fix package.json indentation <a
href="9ac5a5eaaa"><code>9ac5a5e</code></a></li>
<li>[Tests] migrate from travis to github actions <a
href="d845d855de"><code>d845d85</code></a></li>
<li>[Fix] <code>sign</code>: throw on unsupported padding scheme <a
href="8767739a45"><code>8767739</code></a></li>
<li>[Fix] properly check the upper bound for DSA signatures <a
href="85994cd634"><code>85994cd</code></a></li>
<li>[Tests] handle openSSL not supporting a scheme <a
href="f5f17c27f9"><code>f5f17c2</code></a></li>
<li>[Deps] update <code>bn.js</code>, <code>browserify-rsa</code>,
<code>elliptic</code>, <code>parse-asn1</code>,
<code>readable-stream</code>, <code>safe-buffer</code> <a
href="a67d0eb4ff"><code>a67d0eb</code></a></li>
<li>[Dev Deps] update <code>nyc</code>, <code>standard</code>,
<code>tape</code> <a
href="cc5350b967"><code>cc5350b</code></a></li>
<li>[Tests] always run coverage; downgrade <code>nyc</code> <a
href="75ce1d5c49"><code>75ce1d5</code></a></li>
<li>[meta] add <code>safe-publish-latest</code> <a
href="dcf49ce85a"><code>dcf49ce</code></a></li>
<li>[Tests] add <code>npm run posttest</code> <a
href="75dd8fd6ce"><code>75dd8fd</code></a></li>
<li>[Dev Deps] update <code>tape</code> <a
href="3aec0386dc"><code>3aec038</code></a></li>
<li>[Tests] skip unsupported schemes <a
href="703c83ea72"><code>703c83e</code></a></li>
<li>[Tests] node < 6 lacks array <code>includes</code> <a
href="3aa43cfbc1"><code>3aa43cf</code></a></li>
<li>[Dev Deps] fix eslint range <a
href="98d4e0d7ff"><code>98d4e0d</code></a></li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="4af5a90bf8"><code>4af5a90</code></a>
v4.2.2</li>
<li><a
href="3aec0386dc"><code>3aec038</code></a>
[Dev Deps] update <code>tape</code></li>
<li><a
href="85994cd634"><code>85994cd</code></a>
[Fix] properly check the upper bound for DSA signatures</li>
<li><a
href="9ac5a5eaaa"><code>9ac5a5e</code></a>
[meta] fix package.json indentation</li>
<li><a
href="dcf49ce85a"><code>dcf49ce</code></a>
[meta] add <code>safe-publish-latest</code></li>
<li><a
href="44181838e7"><code>4418183</code></a>
[meta] add <code>npmignore</code> and <code>auto-changelog</code></li>
<li><a
href="8767739a45"><code>8767739</code></a>
[Fix] <code>sign</code>: throw on unsupported padding scheme</li>
<li><a
href="5f6fb17559"><code>5f6fb17</code></a>
[Tests] log when openssl doesn't support cipher</li>
<li><a
href="f5f17c27f9"><code>f5f17c2</code></a>
[Tests] handle openSSL not supporting a scheme</li>
<li><a
href="d845d855de"><code>d845d85</code></a>
[Tests] migrate from travis to github actions</li>
<li>Additional commits viewable in <a
href="https://github.com/crypto-browserify/browserify-sign/compare/v4.2.1...v4.2.2">compare
view</a></li>
</ul>
</details>
<details>
<summary>Maintainer changes</summary>
<p>This version was pushed to npm by <a
href="https://www.npmjs.com/~ljharb">ljharb</a>, a new releaser for
browserify-sign since your current version.</p>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps
[browserify-sign](https://github.com/crypto-browserify/browserify-sign)
from 4.0.4 to 4.2.2.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/browserify/browserify-sign/blob/main/CHANGELOG.md">browserify-sign's
changelog</a>.</em></p>
<blockquote>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.2.1...v4.2.2">v4.2.2</a>
- 2023-10-25</h2>
<h3>Fixed</h3>
<ul>
<li>[Tests] log when openssl doesn't support cipher <a
href="https://redirect.github.com/browserify/browserify-sign/issues/37"><code>[#37](https://github.com/crypto-browserify/browserify-sign/issues/37)</code></a></li>
</ul>
<h3>Commits</h3>
<ul>
<li>Only apps should have lockfiles <a
href="09a8995939"><code>09a8995</code></a></li>
<li>[eslint] switch to eslint <a
href="83fe46374b"><code>83fe463</code></a></li>
<li>[meta] add <code>npmignore</code> and <code>auto-changelog</code> <a
href="44181838e7"><code>4418183</code></a></li>
<li>[meta] fix package.json indentation <a
href="9ac5a5eaaa"><code>9ac5a5e</code></a></li>
<li>[Tests] migrate from travis to github actions <a
href="d845d855de"><code>d845d85</code></a></li>
<li>[Fix] <code>sign</code>: throw on unsupported padding scheme <a
href="8767739a45"><code>8767739</code></a></li>
<li>[Fix] properly check the upper bound for DSA signatures <a
href="85994cd634"><code>85994cd</code></a></li>
<li>[Tests] handle openSSL not supporting a scheme <a
href="f5f17c27f9"><code>f5f17c2</code></a></li>
<li>[Deps] update <code>bn.js</code>, <code>browserify-rsa</code>,
<code>elliptic</code>, <code>parse-asn1</code>,
<code>readable-stream</code>, <code>safe-buffer</code> <a
href="a67d0eb4ff"><code>a67d0eb</code></a></li>
<li>[Dev Deps] update <code>nyc</code>, <code>standard</code>,
<code>tape</code> <a
href="cc5350b967"><code>cc5350b</code></a></li>
<li>[Tests] always run coverage; downgrade <code>nyc</code> <a
href="75ce1d5c49"><code>75ce1d5</code></a></li>
<li>[meta] add <code>safe-publish-latest</code> <a
href="dcf49ce85a"><code>dcf49ce</code></a></li>
<li>[Tests] add <code>npm run posttest</code> <a
href="75dd8fd6ce"><code>75dd8fd</code></a></li>
<li>[Dev Deps] update <code>tape</code> <a
href="3aec0386dc"><code>3aec038</code></a></li>
<li>[Tests] skip unsupported schemes <a
href="703c83ea72"><code>703c83e</code></a></li>
<li>[Tests] node < 6 lacks array <code>includes</code> <a
href="3aa43cfbc1"><code>3aa43cf</code></a></li>
<li>[Dev Deps] fix eslint range <a
href="98d4e0d7ff"><code>98d4e0d</code></a></li>
</ul>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.2.0...v4.2.1">v4.2.1</a>
- 2020-08-04</h2>
<h3>Merged</h3>
<ul>
<li>bump elliptic <a
href="https://redirect.github.com/browserify/browserify-sign/pull/58"><code>[#58](https://github.com/crypto-browserify/browserify-sign/issues/58)</code></a></li>
</ul>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.1.0...v4.2.0">v4.2.0</a>
- 2020-05-18</h2>
<h3>Merged</h3>
<ul>
<li>switch to safe buffer <a
href="https://redirect.github.com/browserify/browserify-sign/pull/53"><code>[#53](https://github.com/crypto-browserify/browserify-sign/issues/53)</code></a></li>
</ul>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.0.4...v4.1.0">v4.1.0</a>
- 2020-05-05</h2>
<h3>Merged</h3>
<ul>
<li>update deps, modernise usage, use readable-stream <a
href="https://redirect.github.com/browserify/browserify-sign/pull/49"><code>[#49](https://github.com/crypto-browserify/browserify-sign/issues/49)</code></a></li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="4af5a90bf8"><code>4af5a90</code></a>
v4.2.2</li>
<li><a
href="3aec0386dc"><code>3aec038</code></a>
[Dev Deps] update <code>tape</code></li>
<li><a
href="85994cd634"><code>85994cd</code></a>
[Fix] properly check the upper bound for DSA signatures</li>
<li><a
href="9ac5a5eaaa"><code>9ac5a5e</code></a>
[meta] fix package.json indentation</li>
<li><a
href="dcf49ce85a"><code>dcf49ce</code></a>
[meta] add <code>safe-publish-latest</code></li>
<li><a
href="44181838e7"><code>4418183</code></a>
[meta] add <code>npmignore</code> and <code>auto-changelog</code></li>
<li><a
href="8767739a45"><code>8767739</code></a>
[Fix] <code>sign</code>: throw on unsupported padding scheme</li>
<li><a
href="5f6fb17559"><code>5f6fb17</code></a>
[Tests] log when openssl doesn't support cipher</li>
<li><a
href="f5f17c27f9"><code>f5f17c2</code></a>
[Tests] handle openSSL not supporting a scheme</li>
<li><a
href="d845d855de"><code>d845d85</code></a>
[Tests] migrate from travis to github actions</li>
<li>Additional commits viewable in <a
href="https://github.com/crypto-browserify/browserify-sign/compare/v4.0.4...v4.2.2">compare
view</a></li>
</ul>
</details>
<details>
<summary>Maintainer changes</summary>
<p>This version was pushed to npm by <a
href="https://www.npmjs.com/~ljharb">ljharb</a>, a new releaser for
browserify-sign since your current version.</p>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps
[browserify-sign](https://github.com/crypto-browserify/browserify-sign)
from 4.2.1 to 4.2.2.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/browserify/browserify-sign/blob/main/CHANGELOG.md">browserify-sign's
changelog</a>.</em></p>
<blockquote>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.2.1...v4.2.2">v4.2.2</a>
- 2023-10-25</h2>
<h3>Fixed</h3>
<ul>
<li>[Tests] log when openssl doesn't support cipher <a
href="https://redirect.github.com/browserify/browserify-sign/issues/37"><code>[#37](https://github.com/crypto-browserify/browserify-sign/issues/37)</code></a></li>
</ul>
<h3>Commits</h3>
<ul>
<li>Only apps should have lockfiles <a
href="09a8995939"><code>09a8995</code></a></li>
<li>[eslint] switch to eslint <a
href="83fe46374b"><code>83fe463</code></a></li>
<li>[meta] add <code>npmignore</code> and <code>auto-changelog</code> <a
href="44181838e7"><code>4418183</code></a></li>
<li>[meta] fix package.json indentation <a
href="9ac5a5eaaa"><code>9ac5a5e</code></a></li>
<li>[Tests] migrate from travis to github actions <a
href="d845d855de"><code>d845d85</code></a></li>
<li>[Fix] <code>sign</code>: throw on unsupported padding scheme <a
href="8767739a45"><code>8767739</code></a></li>
<li>[Fix] properly check the upper bound for DSA signatures <a
href="85994cd634"><code>85994cd</code></a></li>
<li>[Tests] handle openSSL not supporting a scheme <a
href="f5f17c27f9"><code>f5f17c2</code></a></li>
<li>[Deps] update <code>bn.js</code>, <code>browserify-rsa</code>,
<code>elliptic</code>, <code>parse-asn1</code>,
<code>readable-stream</code>, <code>safe-buffer</code> <a
href="a67d0eb4ff"><code>a67d0eb</code></a></li>
<li>[Dev Deps] update <code>nyc</code>, <code>standard</code>,
<code>tape</code> <a
href="cc5350b967"><code>cc5350b</code></a></li>
<li>[Tests] always run coverage; downgrade <code>nyc</code> <a
href="75ce1d5c49"><code>75ce1d5</code></a></li>
<li>[meta] add <code>safe-publish-latest</code> <a
href="dcf49ce85a"><code>dcf49ce</code></a></li>
<li>[Tests] add <code>npm run posttest</code> <a
href="75dd8fd6ce"><code>75dd8fd</code></a></li>
<li>[Dev Deps] update <code>tape</code> <a
href="3aec0386dc"><code>3aec038</code></a></li>
<li>[Tests] skip unsupported schemes <a
href="703c83ea72"><code>703c83e</code></a></li>
<li>[Tests] node < 6 lacks array <code>includes</code> <a
href="3aa43cfbc1"><code>3aa43cf</code></a></li>
<li>[Dev Deps] fix eslint range <a
href="98d4e0d7ff"><code>98d4e0d</code></a></li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="4af5a90bf8"><code>4af5a90</code></a>
v4.2.2</li>
<li><a
href="3aec0386dc"><code>3aec038</code></a>
[Dev Deps] update <code>tape</code></li>
<li><a
href="85994cd634"><code>85994cd</code></a>
[Fix] properly check the upper bound for DSA signatures</li>
<li><a
href="9ac5a5eaaa"><code>9ac5a5e</code></a>
[meta] fix package.json indentation</li>
<li><a
href="dcf49ce85a"><code>dcf49ce</code></a>
[meta] add <code>safe-publish-latest</code></li>
<li><a
href="44181838e7"><code>4418183</code></a>
[meta] add <code>npmignore</code> and <code>auto-changelog</code></li>
<li><a
href="8767739a45"><code>8767739</code></a>
[Fix] <code>sign</code>: throw on unsupported padding scheme</li>
<li><a
href="5f6fb17559"><code>5f6fb17</code></a>
[Tests] log when openssl doesn't support cipher</li>
<li><a
href="f5f17c27f9"><code>f5f17c2</code></a>
[Tests] handle openSSL not supporting a scheme</li>
<li><a
href="d845d855de"><code>d845d85</code></a>
[Tests] migrate from travis to github actions</li>
<li>Additional commits viewable in <a
href="https://github.com/crypto-browserify/browserify-sign/compare/v4.2.1...v4.2.2">compare
view</a></li>
</ul>
</details>
<details>
<summary>Maintainer changes</summary>
<p>This version was pushed to npm by <a
href="https://www.npmjs.com/~ljharb">ljharb</a>, a new releaser for
browserify-sign since your current version.</p>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps
[browserify-sign](https://github.com/crypto-browserify/browserify-sign)
from 4.2.1 to 4.2.2.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/browserify/browserify-sign/blob/main/CHANGELOG.md">browserify-sign's
changelog</a>.</em></p>
<blockquote>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.2.1...v4.2.2">v4.2.2</a>
- 2023-10-25</h2>
<h3>Fixed</h3>
<ul>
<li>[Tests] log when openssl doesn't support cipher <a
href="https://redirect.github.com/browserify/browserify-sign/issues/37"><code>[#37](https://github.com/crypto-browserify/browserify-sign/issues/37)</code></a></li>
</ul>
<h3>Commits</h3>
<ul>
<li>Only apps should have lockfiles <a
href="09a8995939"><code>09a8995</code></a></li>
<li>[eslint] switch to eslint <a
href="83fe46374b"><code>83fe463</code></a></li>
<li>[meta] add <code>npmignore</code> and <code>auto-changelog</code> <a
href="44181838e7"><code>4418183</code></a></li>
<li>[meta] fix package.json indentation <a
href="9ac5a5eaaa"><code>9ac5a5e</code></a></li>
<li>[Tests] migrate from travis to github actions <a
href="d845d855de"><code>d845d85</code></a></li>
<li>[Fix] <code>sign</code>: throw on unsupported padding scheme <a
href="8767739a45"><code>8767739</code></a></li>
<li>[Fix] properly check the upper bound for DSA signatures <a
href="85994cd634"><code>85994cd</code></a></li>
<li>[Tests] handle openSSL not supporting a scheme <a
href="f5f17c27f9"><code>f5f17c2</code></a></li>
<li>[Deps] update <code>bn.js</code>, <code>browserify-rsa</code>,
<code>elliptic</code>, <code>parse-asn1</code>,
<code>readable-stream</code>, <code>safe-buffer</code> <a
href="a67d0eb4ff"><code>a67d0eb</code></a></li>
<li>[Dev Deps] update <code>nyc</code>, <code>standard</code>,
<code>tape</code> <a
href="cc5350b967"><code>cc5350b</code></a></li>
<li>[Tests] always run coverage; downgrade <code>nyc</code> <a
href="75ce1d5c49"><code>75ce1d5</code></a></li>
<li>[meta] add <code>safe-publish-latest</code> <a
href="dcf49ce85a"><code>dcf49ce</code></a></li>
<li>[Tests] add <code>npm run posttest</code> <a
href="75dd8fd6ce"><code>75dd8fd</code></a></li>
<li>[Dev Deps] update <code>tape</code> <a
href="3aec0386dc"><code>3aec038</code></a></li>
<li>[Tests] skip unsupported schemes <a
href="703c83ea72"><code>703c83e</code></a></li>
<li>[Tests] node < 6 lacks array <code>includes</code> <a
href="3aa43cfbc1"><code>3aa43cf</code></a></li>
<li>[Dev Deps] fix eslint range <a
href="98d4e0d7ff"><code>98d4e0d</code></a></li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="4af5a90bf8"><code>4af5a90</code></a>
v4.2.2</li>
<li><a
href="3aec0386dc"><code>3aec038</code></a>
[Dev Deps] update <code>tape</code></li>
<li><a
href="85994cd634"><code>85994cd</code></a>
[Fix] properly check the upper bound for DSA signatures</li>
<li><a
href="9ac5a5eaaa"><code>9ac5a5e</code></a>
[meta] fix package.json indentation</li>
<li><a
href="dcf49ce85a"><code>dcf49ce</code></a>
[meta] add <code>safe-publish-latest</code></li>
<li><a
href="44181838e7"><code>4418183</code></a>
[meta] add <code>npmignore</code> and <code>auto-changelog</code></li>
<li><a
href="8767739a45"><code>8767739</code></a>
[Fix] <code>sign</code>: throw on unsupported padding scheme</li>
<li><a
href="5f6fb17559"><code>5f6fb17</code></a>
[Tests] log when openssl doesn't support cipher</li>
<li><a
href="f5f17c27f9"><code>f5f17c2</code></a>
[Tests] handle openSSL not supporting a scheme</li>
<li><a
href="d845d855de"><code>d845d85</code></a>
[Tests] migrate from travis to github actions</li>
<li>Additional commits viewable in <a
href="https://github.com/crypto-browserify/browserify-sign/compare/v4.2.1...v4.2.2">compare
view</a></li>
</ul>
</details>
<details>
<summary>Maintainer changes</summary>
<p>This version was pushed to npm by <a
href="https://www.npmjs.com/~ljharb">ljharb</a>, a new releaser for
browserify-sign since your current version.</p>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps
[browserify-sign](https://github.com/crypto-browserify/browserify-sign)
from 4.2.1 to 4.2.2.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/browserify/browserify-sign/blob/main/CHANGELOG.md">browserify-sign's
changelog</a>.</em></p>
<blockquote>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.2.1...v4.2.2">v4.2.2</a>
- 2023-10-25</h2>
<h3>Fixed</h3>
<ul>
<li>[Tests] log when openssl doesn't support cipher <a
href="https://redirect.github.com/browserify/browserify-sign/issues/37"><code>[#37](https://github.com/crypto-browserify/browserify-sign/issues/37)</code></a></li>
</ul>
<h3>Commits</h3>
<ul>
<li>Only apps should have lockfiles <a
href="09a8995939"><code>09a8995</code></a></li>
<li>[eslint] switch to eslint <a
href="83fe46374b"><code>83fe463</code></a></li>
<li>[meta] add <code>npmignore</code> and <code>auto-changelog</code> <a
href="44181838e7"><code>4418183</code></a></li>
<li>[meta] fix package.json indentation <a
href="9ac5a5eaaa"><code>9ac5a5e</code></a></li>
<li>[Tests] migrate from travis to github actions <a
href="d845d855de"><code>d845d85</code></a></li>
<li>[Fix] <code>sign</code>: throw on unsupported padding scheme <a
href="8767739a45"><code>8767739</code></a></li>
<li>[Fix] properly check the upper bound for DSA signatures <a
href="85994cd634"><code>85994cd</code></a></li>
<li>[Tests] handle openSSL not supporting a scheme <a
href="f5f17c27f9"><code>f5f17c2</code></a></li>
<li>[Deps] update <code>bn.js</code>, <code>browserify-rsa</code>,
<code>elliptic</code>, <code>parse-asn1</code>,
<code>readable-stream</code>, <code>safe-buffer</code> <a
href="a67d0eb4ff"><code>a67d0eb</code></a></li>
<li>[Dev Deps] update <code>nyc</code>, <code>standard</code>,
<code>tape</code> <a
href="cc5350b967"><code>cc5350b</code></a></li>
<li>[Tests] always run coverage; downgrade <code>nyc</code> <a
href="75ce1d5c49"><code>75ce1d5</code></a></li>
<li>[meta] add <code>safe-publish-latest</code> <a
href="dcf49ce85a"><code>dcf49ce</code></a></li>
<li>[Tests] add <code>npm run posttest</code> <a
href="75dd8fd6ce"><code>75dd8fd</code></a></li>
<li>[Dev Deps] update <code>tape</code> <a
href="3aec0386dc"><code>3aec038</code></a></li>
<li>[Tests] skip unsupported schemes <a
href="703c83ea72"><code>703c83e</code></a></li>
<li>[Tests] node < 6 lacks array <code>includes</code> <a
href="3aa43cfbc1"><code>3aa43cf</code></a></li>
<li>[Dev Deps] fix eslint range <a
href="98d4e0d7ff"><code>98d4e0d</code></a></li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="4af5a90bf8"><code>4af5a90</code></a>
v4.2.2</li>
<li><a
href="3aec0386dc"><code>3aec038</code></a>
[Dev Deps] update <code>tape</code></li>
<li><a
href="85994cd634"><code>85994cd</code></a>
[Fix] properly check the upper bound for DSA signatures</li>
<li><a
href="9ac5a5eaaa"><code>9ac5a5e</code></a>
[meta] fix package.json indentation</li>
<li><a
href="dcf49ce85a"><code>dcf49ce</code></a>
[meta] add <code>safe-publish-latest</code></li>
<li><a
href="44181838e7"><code>4418183</code></a>
[meta] add <code>npmignore</code> and <code>auto-changelog</code></li>
<li><a
href="8767739a45"><code>8767739</code></a>
[Fix] <code>sign</code>: throw on unsupported padding scheme</li>
<li><a
href="5f6fb17559"><code>5f6fb17</code></a>
[Tests] log when openssl doesn't support cipher</li>
<li><a
href="f5f17c27f9"><code>f5f17c2</code></a>
[Tests] handle openSSL not supporting a scheme</li>
<li><a
href="d845d855de"><code>d845d85</code></a>
[Tests] migrate from travis to github actions</li>
<li>Additional commits viewable in <a
href="https://github.com/crypto-browserify/browserify-sign/compare/v4.2.1...v4.2.2">compare
view</a></li>
</ul>
</details>
<details>
<summary>Maintainer changes</summary>
<p>This version was pushed to npm by <a
href="https://www.npmjs.com/~ljharb">ljharb</a>, a new releaser for
browserify-sign since your current version.</p>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps
[browserify-sign](https://github.com/crypto-browserify/browserify-sign)
from 4.0.4 to 4.2.2.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/browserify/browserify-sign/blob/main/CHANGELOG.md">browserify-sign's
changelog</a>.</em></p>
<blockquote>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.2.1...v4.2.2">v4.2.2</a>
- 2023-10-25</h2>
<h3>Fixed</h3>
<ul>
<li>[Tests] log when openssl doesn't support cipher <a
href="https://redirect.github.com/browserify/browserify-sign/issues/37"><code>[#37](https://github.com/crypto-browserify/browserify-sign/issues/37)</code></a></li>
</ul>
<h3>Commits</h3>
<ul>
<li>Only apps should have lockfiles <a
href="09a8995939"><code>09a8995</code></a></li>
<li>[eslint] switch to eslint <a
href="83fe46374b"><code>83fe463</code></a></li>
<li>[meta] add <code>npmignore</code> and <code>auto-changelog</code> <a
href="44181838e7"><code>4418183</code></a></li>
<li>[meta] fix package.json indentation <a
href="9ac5a5eaaa"><code>9ac5a5e</code></a></li>
<li>[Tests] migrate from travis to github actions <a
href="d845d855de"><code>d845d85</code></a></li>
<li>[Fix] <code>sign</code>: throw on unsupported padding scheme <a
href="8767739a45"><code>8767739</code></a></li>
<li>[Fix] properly check the upper bound for DSA signatures <a
href="85994cd634"><code>85994cd</code></a></li>
<li>[Tests] handle openSSL not supporting a scheme <a
href="f5f17c27f9"><code>f5f17c2</code></a></li>
<li>[Deps] update <code>bn.js</code>, <code>browserify-rsa</code>,
<code>elliptic</code>, <code>parse-asn1</code>,
<code>readable-stream</code>, <code>safe-buffer</code> <a
href="a67d0eb4ff"><code>a67d0eb</code></a></li>
<li>[Dev Deps] update <code>nyc</code>, <code>standard</code>,
<code>tape</code> <a
href="cc5350b967"><code>cc5350b</code></a></li>
<li>[Tests] always run coverage; downgrade <code>nyc</code> <a
href="75ce1d5c49"><code>75ce1d5</code></a></li>
<li>[meta] add <code>safe-publish-latest</code> <a
href="dcf49ce85a"><code>dcf49ce</code></a></li>
<li>[Tests] add <code>npm run posttest</code> <a
href="75dd8fd6ce"><code>75dd8fd</code></a></li>
<li>[Dev Deps] update <code>tape</code> <a
href="3aec0386dc"><code>3aec038</code></a></li>
<li>[Tests] skip unsupported schemes <a
href="703c83ea72"><code>703c83e</code></a></li>
<li>[Tests] node < 6 lacks array <code>includes</code> <a
href="3aa43cfbc1"><code>3aa43cf</code></a></li>
<li>[Dev Deps] fix eslint range <a
href="98d4e0d7ff"><code>98d4e0d</code></a></li>
</ul>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.2.0...v4.2.1">v4.2.1</a>
- 2020-08-04</h2>
<h3>Merged</h3>
<ul>
<li>bump elliptic <a
href="https://redirect.github.com/browserify/browserify-sign/pull/58"><code>[#58](https://github.com/crypto-browserify/browserify-sign/issues/58)</code></a></li>
</ul>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.1.0...v4.2.0">v4.2.0</a>
- 2020-05-18</h2>
<h3>Merged</h3>
<ul>
<li>switch to safe buffer <a
href="https://redirect.github.com/browserify/browserify-sign/pull/53"><code>[#53](https://github.com/crypto-browserify/browserify-sign/issues/53)</code></a></li>
</ul>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.0.4...v4.1.0">v4.1.0</a>
- 2020-05-05</h2>
<h3>Merged</h3>
<ul>
<li>update deps, modernise usage, use readable-stream <a
href="https://redirect.github.com/browserify/browserify-sign/pull/49"><code>[#49](https://github.com/crypto-browserify/browserify-sign/issues/49)</code></a></li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="4af5a90bf8"><code>4af5a90</code></a>
v4.2.2</li>
<li><a
href="3aec0386dc"><code>3aec038</code></a>
[Dev Deps] update <code>tape</code></li>
<li><a
href="85994cd634"><code>85994cd</code></a>
[Fix] properly check the upper bound for DSA signatures</li>
<li><a
href="9ac5a5eaaa"><code>9ac5a5e</code></a>
[meta] fix package.json indentation</li>
<li><a
href="dcf49ce85a"><code>dcf49ce</code></a>
[meta] add <code>safe-publish-latest</code></li>
<li><a
href="44181838e7"><code>4418183</code></a>
[meta] add <code>npmignore</code> and <code>auto-changelog</code></li>
<li><a
href="8767739a45"><code>8767739</code></a>
[Fix] <code>sign</code>: throw on unsupported padding scheme</li>
<li><a
href="5f6fb17559"><code>5f6fb17</code></a>
[Tests] log when openssl doesn't support cipher</li>
<li><a
href="f5f17c27f9"><code>f5f17c2</code></a>
[Tests] handle openSSL not supporting a scheme</li>
<li><a
href="d845d855de"><code>d845d85</code></a>
[Tests] migrate from travis to github actions</li>
<li>Additional commits viewable in <a
href="https://github.com/crypto-browserify/browserify-sign/compare/v4.0.4...v4.2.2">compare
view</a></li>
</ul>
</details>
<details>
<summary>Maintainer changes</summary>
<p>This version was pushed to npm by <a
href="https://www.npmjs.com/~ljharb">ljharb</a>, a new releaser for
browserify-sign since your current version.</p>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps
[browserify-sign](https://github.com/crypto-browserify/browserify-sign)
from 4.0.4 to 4.2.2.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/browserify/browserify-sign/blob/main/CHANGELOG.md">browserify-sign's
changelog</a>.</em></p>
<blockquote>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.2.1...v4.2.2">v4.2.2</a>
- 2023-10-25</h2>
<h3>Fixed</h3>
<ul>
<li>[Tests] log when openssl doesn't support cipher <a
href="https://redirect.github.com/browserify/browserify-sign/issues/37"><code>[#37](https://github.com/crypto-browserify/browserify-sign/issues/37)</code></a></li>
</ul>
<h3>Commits</h3>
<ul>
<li>Only apps should have lockfiles <a
href="09a8995939"><code>09a8995</code></a></li>
<li>[eslint] switch to eslint <a
href="83fe46374b"><code>83fe463</code></a></li>
<li>[meta] add <code>npmignore</code> and <code>auto-changelog</code> <a
href="44181838e7"><code>4418183</code></a></li>
<li>[meta] fix package.json indentation <a
href="9ac5a5eaaa"><code>9ac5a5e</code></a></li>
<li>[Tests] migrate from travis to github actions <a
href="d845d855de"><code>d845d85</code></a></li>
<li>[Fix] <code>sign</code>: throw on unsupported padding scheme <a
href="8767739a45"><code>8767739</code></a></li>
<li>[Fix] properly check the upper bound for DSA signatures <a
href="85994cd634"><code>85994cd</code></a></li>
<li>[Tests] handle openSSL not supporting a scheme <a
href="f5f17c27f9"><code>f5f17c2</code></a></li>
<li>[Deps] update <code>bn.js</code>, <code>browserify-rsa</code>,
<code>elliptic</code>, <code>parse-asn1</code>,
<code>readable-stream</code>, <code>safe-buffer</code> <a
href="a67d0eb4ff"><code>a67d0eb</code></a></li>
<li>[Dev Deps] update <code>nyc</code>, <code>standard</code>,
<code>tape</code> <a
href="cc5350b967"><code>cc5350b</code></a></li>
<li>[Tests] always run coverage; downgrade <code>nyc</code> <a
href="75ce1d5c49"><code>75ce1d5</code></a></li>
<li>[meta] add <code>safe-publish-latest</code> <a
href="dcf49ce85a"><code>dcf49ce</code></a></li>
<li>[Tests] add <code>npm run posttest</code> <a
href="75dd8fd6ce"><code>75dd8fd</code></a></li>
<li>[Dev Deps] update <code>tape</code> <a
href="3aec0386dc"><code>3aec038</code></a></li>
<li>[Tests] skip unsupported schemes <a
href="703c83ea72"><code>703c83e</code></a></li>
<li>[Tests] node < 6 lacks array <code>includes</code> <a
href="3aa43cfbc1"><code>3aa43cf</code></a></li>
<li>[Dev Deps] fix eslint range <a
href="98d4e0d7ff"><code>98d4e0d</code></a></li>
</ul>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.2.0...v4.2.1">v4.2.1</a>
- 2020-08-04</h2>
<h3>Merged</h3>
<ul>
<li>bump elliptic <a
href="https://redirect.github.com/browserify/browserify-sign/pull/58"><code>[#58](https://github.com/crypto-browserify/browserify-sign/issues/58)</code></a></li>
</ul>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.1.0...v4.2.0">v4.2.0</a>
- 2020-05-18</h2>
<h3>Merged</h3>
<ul>
<li>switch to safe buffer <a
href="https://redirect.github.com/browserify/browserify-sign/pull/53"><code>[#53](https://github.com/crypto-browserify/browserify-sign/issues/53)</code></a></li>
</ul>
<h2><a
href="https://github.com/browserify/browserify-sign/compare/v4.0.4...v4.1.0">v4.1.0</a>
- 2020-05-05</h2>
<h3>Merged</h3>
<ul>
<li>update deps, modernise usage, use readable-stream <a
href="https://redirect.github.com/browserify/browserify-sign/pull/49"><code>[#49](https://github.com/crypto-browserify/browserify-sign/issues/49)</code></a></li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="4af5a90bf8"><code>4af5a90</code></a>
v4.2.2</li>
<li><a
href="3aec0386dc"><code>3aec038</code></a>
[Dev Deps] update <code>tape</code></li>
<li><a
href="85994cd634"><code>85994cd</code></a>
[Fix] properly check the upper bound for DSA signatures</li>
<li><a
href="9ac5a5eaaa"><code>9ac5a5e</code></a>
[meta] fix package.json indentation</li>
<li><a
href="dcf49ce85a"><code>dcf49ce</code></a>
[meta] add <code>safe-publish-latest</code></li>
<li><a
href="44181838e7"><code>4418183</code></a>
[meta] add <code>npmignore</code> and <code>auto-changelog</code></li>
<li><a
href="8767739a45"><code>8767739</code></a>
[Fix] <code>sign</code>: throw on unsupported padding scheme</li>
<li><a
href="5f6fb17559"><code>5f6fb17</code></a>
[Tests] log when openssl doesn't support cipher</li>
<li><a
href="f5f17c27f9"><code>f5f17c2</code></a>
[Tests] handle openSSL not supporting a scheme</li>
<li><a
href="d845d855de"><code>d845d85</code></a>
[Tests] migrate from travis to github actions</li>
<li>Additional commits viewable in <a
href="https://github.com/crypto-browserify/browserify-sign/compare/v4.0.4...v4.2.2">compare
view</a></li>
</ul>
</details>
<details>
<summary>Maintainer changes</summary>
<p>This version was pushed to npm by <a
href="https://www.npmjs.com/~ljharb">ljharb</a>, a new releaser for
browserify-sign since your current version.</p>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
## Summary
There is a bug in the `react-hooks/exhaustive-deps` rule that forbids
the dependencies argument from being `undefined`. It triggers the error
that the dependency list is not an array literal. This makes sense in
pre ES5 strict-mode environments as undefined could be redefined, but
should not be a concern in today's JS environments.
**Justification:**
* The deps argument being undefined (for `useEffect` calls etc.) is a
valid use case for hooks that should re-run on every render.
* The deps argument being omitted is considered a valid use case by the
`exhaustive-deps` rule already.
* The TypeScript type definitions support passing `undefined` because
hooks are typed as `useEffect(effect: EffectCallback, deps?:
DependencyList): void;`.
* Since omitting an argument and passing `undefined` are considered
equivalent, this eslint rule should consider them as equivalent too.
Further, I accidentally forgot passing a dependency array to `useEffect`
in code that I shared on Twitter, and people started abusing me about
it. I'd like to create an eslint rule for my projects that requires me
to provide a dep argument in all cases (`undefined`, `[]` or the list of
dependencies) so that I can avoid such problems in the future. This
would also force me to always think about the dependencies instead of
accidentally forgetting them and my hook running on each render. In an
audit of my own codebase I had about 3% of hooks that I want to run on
each render, and adding an explicit `undefined` seems reasonable in
those situations.
It could be argued this could be an option or part of the
`exhaustive-deps` rule, but it's probably better to merge this PR, make
a release and see if my custom eslint rule gains traction in the future.
## How did you test this change?
* Added a test.
* `yarn test ESLintRuleExhaustiveDeps-test`
* Careful code inspection.
Updates useFormState to allow a sync function to be passed as an action.
A form action is almost always async, because it needs to talk to the
server. But since we support client-side actions, too, there's no reason
we can't allow sync actions, too.
I originally chose not to allow them to keep the implementation simpler
but it's not really that much more complicated because we already
support this for actions passed to startTransition. So now it's
consistent: anywhere an action is accepted, a sync client function is a
valid input.
creating the root after closing the response can lead to a promise that
never rejects. This is not intended use of the decodeReply API but if
pathalogical cases where you pass a raw FormData into this fucntion with
no zero chunk it can hang forever. This reordering causes a connection
error instead
---------
Co-authored-by: Zack Tanner <zacktanner@gmail.com>
This script is used on CI in `yarn_lint` job. With current `glob` call
settings, it includes a bunch of build files, which are actually ignored
by listing them in `.prettierignore`. This check is not failing only
because there is no build step before it.
If you run `node ./scripts/prettier/index` with build files present, you
will see a bunch of files listed as non-formatted. These changes add a
simple logic to include all paths listed in `.prettierignore` to ignore
list of `glob` call with transforming them from gitignore-style to
glob-style.
This should unblock CI for https://github.com/facebook/react/pull/27612,
where `flow-typed` directory will be added, turned out that including it
in `.prettierignore` is not enough.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Updated the typo in test description
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
NA, correct test description improves readability of the code and
confusion for anyone who is new to the codebase.
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
[//]: # (dependabot-start)
⚠️ **Dependabot is rebasing this PR** ⚠️
Rebasing might not happen immediately, so don't worry if this takes some
time.
Note: if you make any changes to this PR yourself, they will take
precedence over the rebase.
---
[//]: # (dependabot-end)
Bumps [lodash](https://github.com/lodash/lodash) from 4.17.4 to 4.17.21.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="f299b52f39"><code>f299b52</code></a>
Bump to v4.17.21</li>
<li><a
href="c4847ebe7d"><code>c4847eb</code></a>
Improve performance of <code>toNumber</code>, <code>trim</code> and
<code>trimEnd</code> on large input strings</li>
<li><a
href="3469357cff"><code>3469357</code></a>
Prevent command injection through <code>_.template</code>'s
<code>variable</code> option</li>
<li><a
href="ded9bc6658"><code>ded9bc6</code></a>
Bump to v4.17.20.</li>
<li><a
href="63150ef764"><code>63150ef</code></a>
Documentation fixes.</li>
<li><a
href="00f0f62a97"><code>00f0f62</code></a>
test.js: Remove trailing comma.</li>
<li><a
href="846e434c7a"><code>846e434</code></a>
Temporarily use a custom fork of <code>lodash-cli</code>.</li>
<li><a
href="5d046f39cb"><code>5d046f3</code></a>
Re-enable Travis tests on <code>4.17</code> branch.</li>
<li><a
href="aa816b36d4"><code>aa816b3</code></a>
Remove <code>/npm-package</code>.</li>
<li><a
href="d7fbc52ee0"><code>d7fbc52</code></a>
Bump to v4.17.19</li>
<li>Additional commits viewable in <a
href="https://github.com/lodash/lodash/compare/4.17.4...4.17.21">compare
view</a></li>
</ul>
</details>
<details>
<summary>Maintainer changes</summary>
<p>This version was pushed to npm by <a
href="https://www.npmjs.com/~bnjmnt4n">bnjmnt4n</a>, a new releaser for
lodash since your current version.</p>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps [lodash](https://github.com/lodash/lodash) from 4.17.4 to 4.17.21.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="f299b52f39"><code>f299b52</code></a>
Bump to v4.17.21</li>
<li><a
href="c4847ebe7d"><code>c4847eb</code></a>
Improve performance of <code>toNumber</code>, <code>trim</code> and
<code>trimEnd</code> on large input strings</li>
<li><a
href="3469357cff"><code>3469357</code></a>
Prevent command injection through <code>_.template</code>'s
<code>variable</code> option</li>
<li><a
href="ded9bc6658"><code>ded9bc6</code></a>
Bump to v4.17.20.</li>
<li><a
href="63150ef764"><code>63150ef</code></a>
Documentation fixes.</li>
<li><a
href="00f0f62a97"><code>00f0f62</code></a>
test.js: Remove trailing comma.</li>
<li><a
href="846e434c7a"><code>846e434</code></a>
Temporarily use a custom fork of <code>lodash-cli</code>.</li>
<li><a
href="5d046f39cb"><code>5d046f3</code></a>
Re-enable Travis tests on <code>4.17</code> branch.</li>
<li><a
href="aa816b36d4"><code>aa816b3</code></a>
Remove <code>/npm-package</code>.</li>
<li><a
href="d7fbc52ee0"><code>d7fbc52</code></a>
Bump to v4.17.19</li>
<li>Additional commits viewable in <a
href="https://github.com/lodash/lodash/compare/4.17.4...4.17.21">compare
view</a></li>
</ul>
</details>
<details>
<summary>Maintainer changes</summary>
<p>This version was pushed to npm by <a
href="https://www.npmjs.com/~bnjmnt4n">bnjmnt4n</a>, a new releaser for
lodash since your current version.</p>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps [lodash](https://github.com/lodash/lodash) from 4.17.15 to
4.17.21.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="f299b52f39"><code>f299b52</code></a>
Bump to v4.17.21</li>
<li><a
href="c4847ebe7d"><code>c4847eb</code></a>
Improve performance of <code>toNumber</code>, <code>trim</code> and
<code>trimEnd</code> on large input strings</li>
<li><a
href="3469357cff"><code>3469357</code></a>
Prevent command injection through <code>_.template</code>'s
<code>variable</code> option</li>
<li><a
href="ded9bc6658"><code>ded9bc6</code></a>
Bump to v4.17.20.</li>
<li><a
href="63150ef764"><code>63150ef</code></a>
Documentation fixes.</li>
<li><a
href="00f0f62a97"><code>00f0f62</code></a>
test.js: Remove trailing comma.</li>
<li><a
href="846e434c7a"><code>846e434</code></a>
Temporarily use a custom fork of <code>lodash-cli</code>.</li>
<li><a
href="5d046f39cb"><code>5d046f3</code></a>
Re-enable Travis tests on <code>4.17</code> branch.</li>
<li><a
href="aa816b36d4"><code>aa816b3</code></a>
Remove <code>/npm-package</code>.</li>
<li><a
href="d7fbc52ee0"><code>d7fbc52</code></a>
Bump to v4.17.19</li>
<li>Additional commits viewable in <a
href="https://github.com/lodash/lodash/compare/4.17.15...4.17.21">compare
view</a></li>
</ul>
</details>
<details>
<summary>Maintainer changes</summary>
<p>This version was pushed to npm by <a
href="https://www.npmjs.com/~bnjmnt4n">bnjmnt4n</a>, a new releaser for
lodash since your current version.</p>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps [lodash](https://github.com/lodash/lodash) from 4.17.4 to 4.17.21.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="f299b52f39"><code>f299b52</code></a>
Bump to v4.17.21</li>
<li><a
href="c4847ebe7d"><code>c4847eb</code></a>
Improve performance of <code>toNumber</code>, <code>trim</code> and
<code>trimEnd</code> on large input strings</li>
<li><a
href="3469357cff"><code>3469357</code></a>
Prevent command injection through <code>_.template</code>'s
<code>variable</code> option</li>
<li><a
href="ded9bc6658"><code>ded9bc6</code></a>
Bump to v4.17.20.</li>
<li><a
href="63150ef764"><code>63150ef</code></a>
Documentation fixes.</li>
<li><a
href="00f0f62a97"><code>00f0f62</code></a>
test.js: Remove trailing comma.</li>
<li><a
href="846e434c7a"><code>846e434</code></a>
Temporarily use a custom fork of <code>lodash-cli</code>.</li>
<li><a
href="5d046f39cb"><code>5d046f3</code></a>
Re-enable Travis tests on <code>4.17</code> branch.</li>
<li><a
href="aa816b36d4"><code>aa816b3</code></a>
Remove <code>/npm-package</code>.</li>
<li><a
href="d7fbc52ee0"><code>d7fbc52</code></a>
Bump to v4.17.19</li>
<li>Additional commits viewable in <a
href="https://github.com/lodash/lodash/compare/4.17.4...4.17.21">compare
view</a></li>
</ul>
</details>
<details>
<summary>Maintainer changes</summary>
<p>This version was pushed to npm by <a
href="https://www.npmjs.com/~bnjmnt4n">bnjmnt4n</a>, a new releaser for
lodash since your current version.</p>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
Bumps [lodash](https://github.com/lodash/lodash) from 4.17.15 to
4.17.21.
<details>
<summary>Commits</summary>
<ul>
<li><a
href="f299b52f39"><code>f299b52</code></a>
Bump to v4.17.21</li>
<li><a
href="c4847ebe7d"><code>c4847eb</code></a>
Improve performance of <code>toNumber</code>, <code>trim</code> and
<code>trimEnd</code> on large input strings</li>
<li><a
href="3469357cff"><code>3469357</code></a>
Prevent command injection through <code>_.template</code>'s
<code>variable</code> option</li>
<li><a
href="ded9bc6658"><code>ded9bc6</code></a>
Bump to v4.17.20.</li>
<li><a
href="63150ef764"><code>63150ef</code></a>
Documentation fixes.</li>
<li><a
href="00f0f62a97"><code>00f0f62</code></a>
test.js: Remove trailing comma.</li>
<li><a
href="846e434c7a"><code>846e434</code></a>
Temporarily use a custom fork of <code>lodash-cli</code>.</li>
<li><a
href="5d046f39cb"><code>5d046f3</code></a>
Re-enable Travis tests on <code>4.17</code> branch.</li>
<li><a
href="aa816b36d4"><code>aa816b3</code></a>
Remove <code>/npm-package</code>.</li>
<li><a
href="d7fbc52ee0"><code>d7fbc52</code></a>
Bump to v4.17.19</li>
<li>Additional commits viewable in <a
href="https://github.com/lodash/lodash/compare/4.17.15...4.17.21">compare
view</a></li>
</ul>
</details>
<details>
<summary>Maintainer changes</summary>
<p>This version was pushed to npm by <a
href="https://www.npmjs.com/~bnjmnt4n">bnjmnt4n</a>, a new releaser for
lodash since your current version.</p>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot show <dependency name> ignore conditions` will show all
of the ignore conditions of the specified dependency
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
This was missed that we track the child index on the task. The
equivalent in retryRenderTask already has this.
The effect is that a lazy node that suspends gets its child index reset
to -1 even though it should resume in the index it left off.
Reverts facebook/react#27577.
We also sync React Native OSS bundles which means this didn't work as
hoped unless we abandon the commit hash in OSS which seems useful.
The loading state tracking for suspensey CSS is too complicated. Prior
to this change it had a state it could enter into where a stylesheet was
already in the DOM but the loading state did not know it was inserted
causing a later transition to try to insert it again.
This fix is to add proper tracking of insertions on the codepaths that
were missing it. It also modifies the logic of when to suspend based on
whether the stylesheet has already been inserted or not.
This is not 100% correct semantics however because a prior commit could
have inserted a stylesheet and a later transition should ideally be able
to wait on that load before committing. I haven't attempted to fix this
yet however because the loading state tracking is too complicated as it
is and requires a more thorough refactor. Additionally it's not
particularly valuable to delay a transition on a loading stylesheet when
a previous commit also relied on that stylesheet but didn't wait for it
b/c it was sync. I will follow up with an improvement PR later
fixes: https://github.com/facebook/react/issues/27585
Similar to #26734, this switches the RN builds for Meta to a content
hash instead of git commit number to make the builds reproducible and
avoid creating sync commits if the bundled content didn't change.
I don't know if it's possible to write a test for this as I can't seem to get
the codegen to change.
For the following testcase: ``` function useFoo(setOne) { let x; let y; if
(setOne) { x = 1; y = 3; } else { x = 2; y = 5; }
return { x, y }; } ```
The LeaveSSA changes from: ``` .... bb1 (block): predecessor blocks: bb2 bb3
x$36:TPrimitive: phi(bb2: x$19, bb3: x$19) y$21[8:14]:TPrimitive: phi(bb2:
y$21, bb3: y$21)
... ```
to ``` ... bb1 (block): predecessor blocks: bb2 bb3 x$36:TPrimitive:
phi(bb2: x$19, bb3: x$19) y$38:TPrimitive: phi(bb2: y$21, bb3: y$21) ... ```
Notice how `y`'s reassignment got skipped previously.
Previously if any operand was reactive, we transferred that reactivity to other
operands that had a mutable effect (capture, conditionally mutate, mutate, or
store). But a value can be captured without ever being modified again. This PR
updates the logic to only transfer reactivity among operands that are actually
mutable at the given instruction, based on the mutable range. This is strictly
more precise.
This PR adds one remaining feature to InferReactivePlaces: tracking indirections
like LoadLocal, PropertyLoad, and similar. Consider something like:
```
// INPUT
x.push(reactiveValue);
// HIR
t0 = LoadLocal 'x'
t1 = PropertyLoad t0, 'push'
t2 = LoadLocal 'reactiveValue' // reactive
t3 = CallExpression mutate t0 . read t1 ( read t2 )
```
Because a reactive value (`t2`) flows into `t0`, we want to record t0 as
reactive as well. But that's just the temporary for `LoadLocal 'x'` - what's
really happening is that from this point, `x` is reactive.
InferReactiveIdentifiers tracked this, and now that logic is ported into
InferReactivePlaces as well. That lets us remove all the actual inference from
InferReactiveIdentifiers.
Updates `InferReactivePlaces` to infer control dependencies. We build on the
formal definition of control dependencies, which is that statement S2 is
control-dependent on statement S1 if S1 is in the post-dominance-frontier of S2.
Intuitively, if S1 decides whether S2 is reached or not, then S1 is a control
dependency of S2. The post dominance frontier of a given statement S is the set
of statements which may or may not reach S, and captures the intuitive notion.
We take advantage of phis: phis are the point where a variable may have multiple
values depending on the path we took. If a phi is not already known to be
reactive from data dependencies we check for control dependencies. Specifically
we look at each phi operand. We check if the block that the operand came from
has any reactive control dependencies, and if so we mark the phi itself as
reactive.
The post-dominance-frontier (PDF) algorithm requires walking the post-dominator
tree a bunch, so we cache the PDF of blocks so that we don't have to recalculate
on subsequent iterations.
In addition, `InferReactiveIdentifiers` now uses the _union_ of its own
inference plus the new `InferReactivePlaces` output when deciding what
identifiers are reactive. This ensures that control dependencies are recorded
correctly, fixing the previous test cases. The next diff adds the remaining
features to InferReactivePlaces so that it can fully replace
InferReactiveIdentifiers.
See context from #2187 for background about control dependencies.
Our current `PruneNonReactiveIdentifiers` pass runs on ReactiveFunction, after
scope construction, and removes scope dependencies that aren't reactive. It
works by first building up a set of reactive identifiers in
`InferReactiveIdentifiers`, then walking the ReactiveFunction and pruning any
scope dependencies that aren't in that set.
The challenge is control variables, as demonstrated by the test cases in #2184.
`InferReactiveIdentifiers` runs against ReactiveFunction, and when we initially
wrote it we didn't consider control variables. To handle control variables we
really need to use precise control- & data-flow analysis, which is much easier
with HIR.
This PR adds the start of `InferReactivePlaces`, which annotates each `Place`
with whether it is reactive or not. This allows the annotation to survive
LeaveSSA, which swaps out the identifiers of places but leaves other properties
as-is. This version does _not_ yet handle control variables, but it's already
more precise than our existing inference. In our current inference, if `x` is
ever assigned a reactive value, then all `x`s are marked reactive. In our new
inference, each instance of `x` (each Place) gets a separate flag based on
whether x can actually be reactive at that point in the program.
There are two main next steps (in follow-up PRs):
* Update the mechanism by which we prune non-reactive dependencies from scopes.
* Handle control variables. I think we may be able to use dominator trees to
figure out the set of basic blocks whose reachability is gated by the control
variables. This should clearly work for if/else and switch, as for loops i'm not
sure but intuitively it seems right.
This is part of a stack for inferring variables which are reactive via *control
dependencies* as opposed to a data dependency. In compiler engineering, a
statement S2 is control-dependent on statement S1 if S1 is in the post-dominance
frontier of S2. Stated more intuitively: if S1 decides whether or not S2 is
reached, then S1 is a control dependency of S2.
As a start, we add `Place.reactive: boolean` so that individual places can track
whether they are reactive or not. This lets us do fine-grained reactivity
inference on the control-flow graph, even taking into account different SSA
instances of a variable, so that we can say that a particular SSA version of `x`
is reactive, while other "versions" of x (due to reassignment) are not.
Adds a toy next.js app which doesn't do anything interesting. It has a single
e2e test which can be run via `npm run test:e2e`, which checks if a `$` variable
was injected by the compiler, as a sanity check whenever we commit a new version
of the compiler to the external repo.
Not every consumer of Forget will be able to run an experimental version of
React. In the meantime before useMemoCache is stable, provide a way for OSS to
pass in a userspace impl.
Turns out we were only using this in PrintHIR and in the logger, so it should be
safe to inline and makes installing the plugin for external collaborators a
little easier.
I'm assuming inlining this is ok because we only need to defer to the host's
Babel version(s) when it affects parsing or the final codegen output, hence why
we continue to no-inline @babel/types – as it is responsible for creating AST
nodes during codegen
The flattening broke the shell script because the directory structure changed.
Instead of depending on a flaky shell script, this PR encodes the commands as
part of the github workflow.
Attempt to bundle the plugin with rollup instead of just tsc. I'm intentionally
not inlining babel related modules, as we should ideally rely on the host
environment's version instead
We can now fully remove prettier from babel-plugin-react-forget. I moved it to
devDependencies instead, to make the rollup build simpler and so we can continue
to prettify our internal source code.
This moves prettier formatting into fixture-test-utils instead, so we can remove
the dependency on prettier in the babel plugin. I want to do this because I
don't want to include prettier in the rolledup artifact when we build the babel
plugin.
I neglected to update the "last" pointer of the action queue. Since the
queue is circular, rather than dropping the update, the effect was to
add the update to the front of the queue instead of the back. I didn't
notice earlier because in my demos/tests, the actions would either
resolve really quickly or the actions weren't order dependent (like
incrementing a counter).
When we postpone a prerender in the shell, we should just leave an empty
prelude and resume from the root. While preserving any options passed
in.
Since we haven't flushed anything we can't assume we've already emitted
html/body tags or any resources tracked in the resumable state. This
introduces a resetResumableState function to reset anything we didn't
flush.
This is a bit hacky. Ideally, we probably shouldn't have tracked it as
already happened until it flushed or something like that.
Basically, it's like restarting the prerender with the same options and
then immediately aborting. When we add the preload headers, we'd track
those as preload() being emitted after the reset and so they get readded
to the resumable state in that case.
By default, partial hydration is given the lowest possible priority,
because until a tree is updated, the server-rendered HTML is assumed to
match the final resolved HTML.
However, this isn't completely true because a component may choose to
"upgrade" itself upon hydration. The simplest example is a component
that calls setState in a useEffect to switch to a richer implementation
of the UI. Another example is a component that doesn't have a server-
rendered implementation, so it intentionally suspends to force a client-
only render.
useDeferredValue is an example, too: the server only renders the first
pass (the initialValue) argument, and relies on the client to upgrade to
the final value.
What we should really do in these cases is emit some information into
the Fizz stream so that Fiber knows to prioritize the hydration of
certain trees. We plan to add a mechanism for this in the future.
In the meantime, though, we can at least ensure that the priority of the
upgrade task is correct once it's "discovered" during hydration. In this
case, the priority of the task spawned by useDeferredValue should have
Transition priority, not Offscreen priority.
Runs Forget on the playground, so we can dogfood Forget and experiment with
improvements to UX.
Opts out of compiling the layout page because thats run on the server which
doesn't seem to have access to useMemoCache.
This kept throwing warnings in our playground build because prettier uses node
APIs and is not meant to be bundled and run on the browser.
There's a separate standalone version that runs on the browser. A follow on PR
will make the playground use that but this PR is a first step towards using a
standalone prettier.
During a popstate event, we attempt to render updates synchronously even
if they are transitions, to preserve scroll position if possible. We do
this by entangling the transition lane with the Sync lane.
However, if rendering the transition spawns additional transition
updates (e.g. a setState inside useEffect), there's no reason to render
those synchronously, too. We should use the normal transition behavior.
This fixes an issue where useDeferredValue during a popstate event would
spawn a transition update that was itself also synchronous.
This upgrade made the `React$Element` type opaque, which is good for
product code where accessing props of elements is code smell, but React
needs to use that internally. I overrode the type to restore it.
Currently DCE can remove variable declarations that are unused, ie where all
control-flow paths to usage of the variable are overwritten by a reassignment.
We then have to reconstruct the original variable declaration at the appropriate
block scope during LeaveSSA, which is complex and can actually be incorrect in
some cases.
This PR updates to ensure that DCE will not remove the original variable
declaration for any variable that is used (even in the case of always being
reassigned before use). The main changes are:
* DCE retains variable declarations, but if a variable declaration is always
shadowed by reassignments then DCE will rewrite StoreLocal -> DeclareLocal so
that it can DCE the unused initial value.
* BuildHIR now has to change its handling for reassignment destructure
instructions with nesting. Nesting uses a temporary which would appear as a
declaration of a new variable, which is incompatible with other reassignments.
See comments in the file.
* LeaveSSA is quite a bit simpler now, since we never need to reconstruct a
declaration.
Now that we no longer support Server Context, we can now deduplicate
objects. It's not completely safe for useId but only in the same way as
it's not safe if you reuse elements on the client, so it's not a new
issue.
This also solves cyclic object references.
The issue is that we prefer to inline objects into a plain JSON format
when an object is not going to get reused. In this case the object
doesn't have an id. We could potentially serialize a reference to an
existing model + a path to it but it bloats the format and complicates
the client.
In a smarter flush phase like we have in Fizz we could choose to inline
or outline depending on what we've discovered so far before a flush. We
can't do that here since we use native stringify. However, even in that
solution you might not know that you're going to discover the same
object later so it's not perfect deduping anyway.
Instead, I use a heuristic where I mark previously seen objects and if I
ever see that object again, then I'll outline it. The idea is that most
objects are just going to be emitted once and if it's more than once
it's fairly likely you have a shared reference to it somewhere and it
might be more than two.
The third object gets deduplicated (or "detriplicated").
It's not a perfect heuristic because when we write the second object we
will have already visited all the nested objects inside of it, which
causes us to outline every nested object too even those weren't
reference more than by that parent. Not sure how to solve for that.
If we for some other reason outline an object such as if it suspends,
then it's truly deduplicated since it already has an id.
Code organization PR.
It looks like the `ReactServerStreamConfigFB` is only used in the
`relay-server` package. This PR moves it to `react-server` from
`react-server-dom-fb` (similar to how we have config for bun, for
example). This avoids cross-package imports from `react-server` to
`react-server-dom-fb.`
In https://github.com/facebook/react/pull/27541 I added tests to assert
that the write after close bug was fixed. However the Node
implementation has an abort behavior preventing reproduction of the
original issue and the Browser build does not use AsyncLocalStorage
which also prevents reproduction. This change moves the Browser test to
a Edge runtime where AsyncLocalStorage is polyfilled. In this
implementation the test does correctly fail when the patch is removed.
Float methods can hang on to a reference to a Request after the request
is closed due to AsyncLocalStorage. If a Float method is called at this
point we do not want to attempt to flush anything. This change updates
the closing logic to also call `stopFlowing` which will ensure that any
checks against the destination properly reflect that we cannot do any
writes. In addition it updates the enqueueFlush logic to existence check
the destination inside the work function since it can change across the
work scheduling gap if it is async.
fixes: https://github.com/facebook/react/issues/27540
### Based on #27509
Revealing a prerendered tree (hidden -> visible) is considered the same
as mounting a brand new tree. So, when an initialValue argument is
passed to useDeferredValue, and it's prerendered inside a hidden tree,
we should first prerender the initial value.
After the initial value has been prerendered, we switch to prerendering
the final one. This is the same sequence that we use when mounting new
visible tree. Depending on how much prerendering work has been finished
by the time the tree is revealed, we may or may not be able to skip all
the way to the final value.
This means we get the benefits of both prerendering and preview states:
if we have enough resources to prerender the whole thing, we do that. If
we don't, we have a preview state to show for immediate feedback.
### Based on https://github.com/facebook/react/pull/27505
If a parent render spawns a deferred task with useDeferredValue, but the
parent render suspends, we should not wait for the parent render to
complete before attempting to render the final value.
The reason is that the initialValue argument to useDeferredValue is
meant to represent an immediate preview of the final UI. If we can't
render it "immediately", we might as well skip it and go straight to the
"real" value.
This is an improvement over how a userspace implementation of
useDeferredValue would work, because a userspace implementation would
have to wait for the parent task to commit (useEffect) before spawning
the deferred task, creating a waterfall.
This code is executed once React DevTools panels are mounted, basically
when user opens browser's DevTools. Based on this fact, session in this
case is defined by browser's DevTools session, while they are open. A
session can involve debugging multiple React pages. `crypto.randomUUID`
is used to generate random user id.
Corresponding logger config changes -
[D50267871](https://www.internalfb.com/diff/D50267871).
Adds test cases for all the cases of control dependencies that I can think of.
We don't currently handle control dependencies correctly in any of these cases.
There's also another test case which demonstrates why reactive dependency
inference needs to be fixpoint, even for non-control dependencies.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Changes `before before` to `before` in error messages.
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
I want to improve error logs
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
A small refactor to how the lane entanglement mechanism works. We can
now distinguish between the lane that "spawned" a render task (i.e. a
new update) versus the lanes that it's entangled with. Both the update
lane and the entangled lanes will be included while rendering, but by
keeping them separate, we don't lose the original priority.
In practical terms, this means we can now entangle a low priority update
with a higher priority lane while rendering at the lower priority.
To do this, lanes that are entangled at the root are now tracked using
the same variable that we use to track the "base lanes" when revealing a
previously hidden tree — conceptually, they are the same thing. I also
renamed this variable (from subtreeLanes to entangledRenderLanes) to
better reflect how it's used.
My primary motivation is related to useDeferredValue, which I'll address
in a later PR.
This is the same problem as we had with keyPath before where if the
element itself suspends, we have to restore the replay node to what it
was before, however, if something below the element suspends we
shouldn't pop it because that will pop it back up the stack.
Instead of passing replay as an argument to every renderElement
function, I use a hack to compare if the node is still the same as the
one we tried to render, then that means we haven't stepped down into the
child yet. Maybe this is not quite correct because in theory you could
have a recursive node that just renders itself over and over until some
context bails out.
This solves an issue where if you suspended in an element it would retry
trying to replay from that element but using the postponed state from
the root.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
aligned the typing for `ReactNativeViewConfigRegistry` in
`react-native-host-hooks.js`
continuation of https://github.com/facebook/react/pull/27508
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
The `enableCustomElementPropertySupport` flag changes React's handling
of custom elements in a way that is more useful that just treating every
prop as an attribute. However when server rendering we have no choice
but to serialize props as attributes. When this flag is on and React
supports more prop types on the client like functions and objects the
server implementation needs to be a bit more naunced in how it renders
these components. With this flag on `false`, function, and object props
are omitted entirely and `true` is normalized to `""`. There was a bug
however in the implementation which caused children more complex than a
single string to be omitted because it matched the object type filter.
This change reorganizes the code a bit to put these filters in the
default prop handline case, leaving children, style, and innerHTML to be
handled via normal logic.
fixes: https://github.com/facebook/react/issues/27286
Reactive scopes are currently preceded by individual variable declarations, one
for each of the scope's dependencies. Only after checking independently if each
of these dependencies has changed do we then do an "or" to check if we should
actually recompute the body of the scope.
But that's wasteful: it's more efficient to rely on `||` short-circuiting, and
recompute as soon as any input changes.
The main reason I can see not to do this is debugging. Having the change
variables makes it easy to see what changed. But at this point I think it makes
sense to optimize for code size and performance; we can always add back a
dev-only mode that uses change variables if that turns out to help debugging.
Rewrites the core logic of MergeConsecutiveScopes to be easier to follow and fix
bugs. We now do a two-pass approach:
* First we iterate block instructions to identify scopes which can be merged,
without actually merging the instructions themselves.
* Then we iterate again, copying instructions from the block either into the new
output block, or into their merged scope, as appropriate.
I think the simplicity here is worth the performance cost, and we can always
revisit later as necessary.
## Summary
When transpiling `react-native` with `swc` this file caused some trouble
as it mixes ESM and CJS import/export syntax. This PR addresses this by
converting CJS exports to ESM exports. As
`ReactNativeViewConfigRegistry` is synced from `react` to `react-native`
repository, it's required to make the change here. I've also aligned the
mock of `ReactNativeViewConfigRegistry` to reflect current
implementation.
Related PR in `react-native`:
https://github.com/facebook/react-native/pull/40787
We only allow plain objects that can be faithfully serialized and
deserialized through JSON to pass through the serialization boundary.
It's a bit too expensive to do all the possible checks in production so
we do most checks in DEV, so it's still possible to pass an object in
production by mistake. This is currently exaggerated by frameworks
because the logs on the server aren't visible enough. Even so, it's
possible to do a mistake without testing it in DEV or just testing a
conditional branch. That might have security implications if that object
wasn't supposed to be passed.
We can't rely on only checking if the prototype is `Object.prototype`
because that wouldn't work with cross-realm objects which is
unfortunate. However, if it isn't, we can check wether it has exactly
one prototype on the chain which would catch the common error of passing
a class instance.
Adds a second argument to useDeferredValue called initialValue:
```js
const value = useDeferredValue(finalValue, initialValue);
```
During the initial render of a component, useDeferredValue will return
initialValue. Once that render finishes, it will spawn an additional
render to switch to finalValue.
This same sequence should occur whenever the hook is hidden and revealed
again, i.e. by a Suspense or Activity, though this part is not yet
implemented.
When initialValue is not provided, useDeferredValue has no effect during
initial render, but during an update, it will remain on the previous
value, then spawn an additional render to switch to the new value. (This
is the same behavior that exists today.)
During SSR, initialValue is always used, if provided.
This feature is currently behind an experimental flag. We plan to ship
it in a non-breaking release.
This morning @mofeiZ reminded me that our codegen doesn't really have any guards
against reordering, since temporaries are lazily emitted. We're relying on the
fact that our lowering and memoization carefully preserves order of evaluation,
such that delaying the instructions in codegen doesn't change semantics.
To help catch any mistakes with this, I had previously added code that reset the
codegen context's temporaries before/after exiting a reactive scope. That
ensured that temporaries from within the scope weren't accessible outside it.
This PR extends that approach to _all_ blocks, so that temporaries created
within a block aren't accessible outside it.
I'm also going to explore more actively resetting temporaries after they
"should" be used. There are a couple cases where temporaries are reused, though,
which we have to change first.
There are not so many changes, most of them are changing imports,
because I've moved types for UI in a single file.
In https://github.com/facebook/react/pull/27357 I've added support for
pausing polling events: when user inspects an element, we start polling
React DevTools backend for updates in props / state. If user switches
tabs, extension's service worker can be killed by browser and this
polling will start spamming errors.
What I've missed is that we also have a separate call for this API, but
which is executed only once when user selects an element. We don't
handle promise rejection here and this can lead to some errors when user
selects an element and switches tabs right after it.
The only change here is that this API now has
`shouldListenToPauseEvents` param, which is `true` for polling, so we
will pause polling once user switches tabs. It is `false` by default, so
we won't pause initial call by accident.
af8beeebf6/packages/react-devtools-shared/src/backendAPI.js (L96)
## Summary
Currently when cloning nodes in Fabric, we reset a node's children on
each clone, and then repeatedly call appendChild to restore the previous
list of children (even if it was quasi-identical to before). This causes
unnecessary invalidation of the layout state in Fabric's ShadowNode data
(which in turn may require additional yoga clones) and extra JSI calls.
This PR adds a feature flag to pass in the children as part of the clone
call, so Fabric always has a complete view of the node that's being
mutated.
This feature flag requires matching changes in the react-native repo:
https://github.com/facebook/react-native/pull/39817
## How did you test this change?
Unit test added demonstrates the new behaviour
```
yarn test -r www-modern ReactFabric-test
yarn test ReactFabric-test.internal
```
Tested a manual sync into React Native and verified core surfaces render
correctly.
So far we've been preserving JSX whitespace all the way through to codegen. But
JSX has clear rules around whitespace handling, which allows us to trim
whitespace in the input in lots of cases. For the most part this doesn't change
our output, but I think that’s generally because of prettier. This PR should
make a big difference when debugging the compiler, by removing all the
whitespace JsxText values.
But in some edge-cases it really makes a difference in the output since we can
avoid memo slots for strings like `"\n "`..
## Test Plan
* Experimented with our internal tool to verify transform output to confirm that
JSXText whitespace does not impact fbt transform results.
* Synced and tested profile page, looks fine
Rewrites the core logic of MergeConsecutiveScopes to be easier to follow and fix
bugs. We now do a two-pass approach:
* First we iterate block instructions to identify scopes which can be merged,
without actually merging the instructions themselves.
* Then we iterate again, copying instructions from the block either into the new
output block, or into their merged scope, as appropriate.
I think the simplicity here is worth the performance cost, and we can always
revisit later as necessary.
This is a repro for a bug that occurs when `enableMergeConsecutiveScopes` is
enabled. Reminder that this feature is off by default and not enabled yet
internally.
I found this via #2121, where eliminating extraneous whitespace JSXText
instructions meant that MergeConsecutiveScopes started merging a fixture
differently, revealing a bug. This PR reproduces that case by keeping the
identical structure, but using plain objects to represent the JSX elements
instead of JSX syntax.
This PR completes the refactor. We now do the following sequence:
* ValidateUseMemo. This is a new pass that extracts just the validation logic
from the existing InlineUseMemo. This was always being run before, so this pass
also always runs.
* DropManualMemoization. As before, this converts useMemo calls into an IIFE
(immediately invoked function expression).
* InlineImmediatelyInvokedFunctionExpressions (prev InlineUseMemo). This pass
now inlines _all_ IIFEs, including both useMemo calls that were dropped as well
as IIFEs that the user wrote.
The motivation for this change is that some codebases use IIFEs as a workaround
for lack of if expressions, but we're unable to optimize within function
expressions. This is the reason we originally added inlining for useMemo, but
given that IIFEs are common it makes sense to generalize the inlining.
## Test Plan
* Manually checked changes in output
* Synced internally and tested on profile page, no issues observed. Also
spot-checked some of the changes in ouput and it looks as expected.
The goal of this stack is to generalize `InlineUseMemo` into a pass that inlines
all immediately invoked function expressions (IIFEs). Rather than specialize
just useMemo calls, we'll rely on DropManualMemoization running first and
turning useMemo calls into IIFEs. Then the generalized inlining pass can handle
those IIFEs as well as others present in the source.
For now, moving the order of the pass makes the output closer to what it will
eventually be after this stack is complete.
#2127 introduced a special type for the result of `useContext()` that was sort
of ref-like. The intent was to allow code like this:
```
function Foo() {
const cx = useContext(...);
function onEvent() {
cx.foo = true;
};
return <Bar onEvent={onEvent} />;
}
```
However, that code actually is allowed by the compiler by default. It's only a
bailout when `@validateFrozenLambdas` is enabled. The "fix" in #2127 therefore
wasn't strictly necessary to unblock rollout, and it's also flawed in a few
ways:
* First, `useContext(FooContext)` should have equivalent behavior to a custom
hooks which does the same thing, ie `function useFooContext() { return
useContext(FooContext) }`. Specializing the type of useContext makes the
behavior different.
* Second, it meant that even readonly accesses of the context inside a callback
marked the function as capturing, which in turn prevented those callbacks from
being memoized.
So i'm reverting this and we'll have to think a bit more about this case.
---
Patch for original patch of injecting `useMemoCache` logic 😅 This is failing on
a good number React components internally (not in our current experiments)
The playground now uses the new pragma parser so it's guaranteed to use the
right defaults and have consistent parsing with snap/sprout. In addition, we now
emit a debug event from the compiler which contains pretty-printed environment
config, making it easy to check which settings are being applied in playground.
<img width="3008" alt="Screenshot 2023-10-05 at 11 05 58 AM"
src="https://github.com/facebook/react-forget/assets/6425824/2417f40c-1320-4c39-a661-a4e34e3d69c4">
Updates Snap and Sprout to use the new pragma parser, which also means they will
always use the same default flags as the compiler itself sets. A side benefit of
this is that you no longer need to rebuild snap/sprout to update their flags,
since they will take flags from the version of the compiler being executed.
Adds a helper function for parsing pragma strings to the compiler itself, and
exports it. This will be used in follow-ups to make Snap, Sprout, and Playground
all use the same pragma parser. The helper also starts from the default values,
so adopting this will also make it easy for all those places to have the same
defaults automatically.
in #27461 the experimental prefix was added back for `useFormState` and
`useFormStatus` in react-dom. However these functions are also exported
from the server rendering stub too and when using the stub with
experimental prefixes their absence causes unexpected errors.
This change adds back the experimental prefix for these two hooks to
match the experimental build of react-dom.
The way we collect component stacks right now are pretty fragile.
We expect that we'll call captureBoundaryErrorDetailsDev whenever an
error happens. That resets lastBoundaryErrorComponentStackDev to null
but if we don't, it just lingers and we don't set it to anything new
then which leaks the previous component stack into the next time we have
an error. So we need to reset it in a bunch of places.
This is still broken with erroredReplay because it has the inverse
problem that abortRemainingReplayNodes can call
captureBoundaryErrorDetailsDev more than one time. So the second
boundary won't get a stack.
We probably should try to figure out an alternative way to carry along
the stack. Perhaps WeakMap keyed by the error object.
This also fixes an issue where we weren't invoking the onShellReady
event if we error a replay. That event is a bit weird for resuming
because we're probably really supposed to just invoke it immediately if
we have already flushed the shell in the prerender which is always atm.
Right now, it gets invoked later than necessary because you could have a
resumed hole ready before a sibling in the shell is ready and that's
blocked.
The jsx-runtime uses the ReactCurrentDispatcher from shared internals.
Recently this was moved to ReactServerSharedInternals which broke
jsx-runtime. This change moves it back to ReactSharedInternals until we
can come up with a new forking mechanism.
This adds back the `experimental_`-prefixed Server Actions APIs to the
experimental builds only, so that apps that use those don't immediately
break when upgrading. The APIs will log a warning to encourage people to
move to the unprefixed version, or to switch to the canary release
channel.
We can remove these in a few weeks after we've given people a chance to
upgrade.
This does not affect the canary builds at all, since they never had the
prefixed versions to begin with.
Adds support for empty catch clauses in a try/catch. We add a new block kind
`catch` which prevents the empty catch block from being merged with other types
of blocks, preserving the block structure within the HIR and allowing us to
reconstruct the empty catch.
Upgrades the stability of Server Actions from experimental to canary.
- Turns on enableAsyncActions and enableFormActions
- Removes "experimental_" prefix from useOptimistic, useFormStatus, and
useFormState
---
Implements popular feature request ✨ per feedback from a majority of snap users.
**Add `@debug` to the first line of your `testfilter.txt` file to opt into
implicit debug mode**, in which debug logging is enabled anytime filter mode is
on + only one fixture file is found.
- live edits to testfilter.txt are reflected in watch mode, so you can add /
remove `@debug` to `testfilter.txt` in the middle of a watch session
- I personally don't use debug mode all the time (I often a single file filtered
+ a lot of console log traces), but it should be easy to add `@debug` to the top
of `testfilter.txt` and leave it there forever.
### Based on #27453
If optimistic state is updated, and there's no startTransition on the
stack, there are two likely scenarios.
One possibility is that the optimistic update is triggered by a regular
event handler (e.g. `onSubmit`) instead of an action. This is a mistake
and we will warn.
The other possibility is the optimistic update is inside an async
action, but after an `await`. In this case, we can make it "just work"
by associating the optimistic update with the pending async action.
Technically it's possible that the optimistic update is unrelated to the
pending action, but we don't have a way of knowing this for sure because
browsers currently do not provide a way to track async scope. (The
AsyncContext proposal, if it lands, will solve this in the future.)
However, this is no different than the problem of unrelated transitions
being grouped together — it's not wrong per se, but it's not ideal.
Once AsyncContext starts landing in browsers, we will provide better
warnings in development for these cases.
## Summary
These modules are no longer referenced in the React codebase. We should
remove them to limit the API surface area between React and React
Native.
## How did you test this change?
`yarn flow native && yarn flow fabric`
This is a (hopefully) better approach at printing ReactiveFunction. The nesting
wasn't always clear in the previous version, this should help. See playground to
experiment.
Updates `Environment` to store all feature flags on a single `config` object. We
now also define an object with all the default config values, and use this to
populate defaults for any missing values in the user-provided config.
I found a bug where if an optimistic update causes a component to
rerender, and there are no other state updates during that render, React
bails out without applying the update.
Whenever a hook detects a change, we must mark the component as dirty to
prevent a bailout. We check for changes by comparing the new state to
`hook.memoizedState`. However, when implementing optimistic state
rebasing, I incorrectly reset `hook.memoizedState` to the incoming base
state, even though I only needed to reset `hook.baseState`. This was
just a mistake on my part.
This wasn't caught by the existing tests because usually when the
optimistic state changes, there's also some other state that marks the
component as dirty in the same render.
I fixed the bug and added a regression test.
Most of our feature flags are accessed via the `Environment`, but a few cases
have slipped in where we look at the `config` object directly. The problem is
that the config object doesn't set defaults, so the check is effectively
encoding what the default is.
This PR moves to always accessing flags off of the environment, and adds a few
flags that weren't yet defined there.
Previously, we stored a global count variable that was updated every time we
added a property to the `arg` object. This was added to prevent collisions, and
make sure we do actually mutate the object.
But the count value was shared by the forget compiled and uncompiled versions,
so the same object mutated in either versions would result in having different
properties leading to potential test failures.
Instead, let's make count local and attempt to incrementally mutate the object
with different keys.
InferReferenceEffects uses object identity to merge states, which breaks when we
create a new object to model `undefined`.
Two value objects representing `undefined` are not equal due to referential
equality.
Instead, let's use a singleton to represent `undefined` value.
Handles an edge-case from earlier in the stack. When looking up a property on a
shape, if the property is defined we return it. But if it isn't defined, and the
property name is a hook, we treat it like a default custom hook.
Allows using hooks/methods off of the `React` namespace, for example
`React.useState(sathya)`. Thanks to the previous PR we correctly handle things
like validation of hooks called via propertyload syntax. The main change here is
to teach the compiler about the `React` namespace. This is a bit of a hack since
we treat it as a global, but we're transforming React code so this seems
reasonable (?).
There are a few additional touch-ups which I'll do in subsequent PRs to make
review easier. For example, we need to teach our useMemo/useCallback flattening
logic to also handle the case of `React.useMemo()` etc.
Hooks can be called via method call syntax, eg `Foo.useBar(sathya)`. This PR
teaches the compiler about this form of hooks for things like flattening scopes
with hooks, validating conditional hooks, etc.
Note that we still disallow calls on the React namespace, so things like
`React.useState()` continue to error. That's the next PR in the stack!
Adds a new type for representing context values, which is transitive. So
`useContext(a).b.c` also gets inferred as a context type. This allows us to
refine our inference, and allow passing callbacks that modify context where a
"frozen" lambda is exepcted.
This is a distilled version of the duplicate declaration @mofeiZ and I saw when
trying to sync latest Forget internally, plus a fix to avoid the duplicate
instruction.
Fixes an issue with incorrect spacing where spaces were getting dropped, despite
an explicit `{" "}` in the input. The issue is that we didn't maintain JSXText
all the way through compilation. BuildHIR distinguishes string literals (such as
the above, inside an expressioncontainer) from JSXText, and we propagate this
distinction all the way through to codegen.
But then codegen stores temporary values as `t.Expression` nodes, which means we
have to convert the JSXText nodes to StringLiteral and we lose the distinction.
This PR updates codegen to save temporaries as `t.Expression | t.JSXText` so
that we can preserve the difference. In most places we just coerce the value to
an expression, but the code for emitting JSX child items looks at the raw value
so it can distinguish them. JSXText is emitted as-is, while StringLiterals are
always wrapped in an expression container.
See the new test case which demonstrates the expression being preserved.
Object methods must not be cached independently, so this PR flattens the
reactive scope to prevent memoization.
In the future, we can combine the FlattenScopesWithObjectMethods and
FlattedScopesWithHooks passes by making them more modular. But this works for
now.
Fixes whatever part of https://github.com/facebook/react/issues/26876
and https://github.com/vercel/next.js/issues/49499 that
https://github.com/facebook/react/pull/27394 didn't fix, probably.
From manual tests I believe this behavior brings us back to parity with
latest stable release (18.2.0). It's awkward that we keep the user's
state even for controlled inputs, so the DOM is out of sync with React
state.
Previously the .defaultChecked assignment done in updateInput() was
changing the actual checkedness because the dirty flag wasn't getting
set, meaning that hydrating could change which radio button is checked,
even in the absence of user interaction! Now we go back to always
detaching again.
Fixes#26876 for real?
In 18.2.0 (last stable), we set .checked unconditionally:
https://github.com/facebook/react/blob/v18.2.0/packages/react-dom/src/client/ReactDOMInput.js#L129-L135
This is important because if we are updating two radios' checkedness
from (false, true) to (true, false), we need to make sure that
input2.checked is explicitly set to false, even though setting
`input1.checked = true` already unchecks input2.
I think this fix is not complete because there is no guarantee that all
the inputs rerender at the same time? Hence the TODO. But in practice
they usually would and I _think_ this is comparable to what we had
before.
Also treating function and symbol as false like we used to and like we
do on initial mount.
Object methods are lowered to functions and added to ObjectExpression. The
codegen is interesting because we shouldn't emit code that lowers the object
method into a separate statement and then stores it into an object expression.
An shorthand object method has different semantics than an object method using
the function syntax, so we need to preserve the shorthand object method syntax
in the generated code.
To do this, we don't immediately generate an AST node for the ObjectMethod but
instead store it in a side table during codegen. Only when emitting code for an
ObjectExpression, we lookup this side table and emit the object method inline in
the body.
This lets a registered object or value be "tainted", which we block from
crossing the serialization boundary. It's only allowed to stay
in-memory.
This is an extra layer of protection against mistakes of transferring
data from a data access layer to a client. It doesn't provide perfect
protection, because it doesn't trace through derived values and
substrings. So it shouldn't be used as the only security layer but more
layers are better.
`taintObjectReference` is for specific object instances, not any nested
objects or values inside that object. It's useful to avoid specific
objects from getting passed as is. It ensures that you don't
accidentally leak values in a specific context. It can be for security
reasons like tokens, privacy reasons like personal data or performance
reasons like avoiding passing large objects over the wire.
It might be privacy violation to leak the age of a specific user, but
the number itself isn't blocked in any other context. As soon as the
value is extracted and passed specifically without the object, it can
therefore leak.
`taintUniqueValue` is useful for high entropy values such as hashes,
tokens or crypto keys that are very unique values. In that case it can
be useful to taint the actual primitive values themselves. These can be
encoded as a string, bigint or typed array. We don't currently check for
this value in a substring or inside other typed arrays.
Since values can be created from different sources they don't just
follow garbage collection. In this case an additional object must be
provided that defines the life time of this value for how long it should
be blocked. It can be `globalThis` for essentially forever, but that
risks leaking memory for ever when you're dealing with dynamic values
like reading a token from a database. So in that case the idea is that
you pass the object that might end up in cache.
A request is the only thing that is expected to do any work. The
principle is that you can derive values from out of a tainted
entry during a request. Including stashing it in a per request cache.
What you can't do is store a derived value in a global module level
cache. At least not without also tainting the object.
## Summary
This is part of an effort to align the event loop in React Native with
its behavior on the Web. In this case, we're going to test enabling
microtasks in React Native (Fabric) and we need React to schedule work
using microtasks if available there. This just adds a feature flag to
configure that behavior at runtime.
## How did you test this change?
* Reviewed the generated code, which looks ok.
* Did a manual sync of this PR to Meta's internal infra and tested it
with my changes to enable microtasks in RN/Hermes.
The `resumeElement` function wasn't actually doing the correct thing
because it was resuming the element itself but what the child slot means
is that we're supposed to resume in the direct child of the element.
This is difficult to check for since it's all the possible branches that
the element can render into, so instead we just check this in
renderNode. It means the hottest path always checks the task which is
unfortunate.
And also, resuming using the correct nextSegmentId.
Fixes two bugs surfaced by this test.
---------
Co-authored-by: Josh Story <josh.c.story@gmail.com>
I do this by simply renaming the secret export name in the "subset"
bundle and this renamed version is what the FlightServer uses.
This requires us to be more diligent about always using the correct
instance of "react" in our tests so there's a bunch of clean up for
that.
This adds a regression test and fix for a case where a sync update
triggers selective hydration, which then leads to a "Maximum update
depth exceeded" error, even though there was only a single update. This
happens when a single sync update flows into many sibling dehydrated
Suspense boundaries.
This fix is, if a commit was the result of selective hydration, we
should not increment the nested update count, because those renders
conceptually are not updates.
Ideally, they wouldn't even be in a separate commit — we should be able
to hydrate a tree and apply an update on top of it within the same
render phase. We could do this once we implement resumable context
stacks.
`performSyncWorkOnRoot` has only a single caller, and the caller already
computes the next lanes (`getNextLanes`) before deciding to call the
function. So we can pass them as an argument instead of computing the
lanes again.
There was already a TODO comment about this, but it was mostly perf
related. However, @rickhanlonii noticed a discrepancy where the inner
`getNextLanes` call was not being passed the current work-in- progress
lanes. Usually this shouldn't matter because there should never be
work-in-progress sync work; it should finish immediately. There is one
case I'm aware of where we exit the work loop without finishing a sync
render, which is selective hydration, but even then it should switch to
the sync hydration lane, not the normal sync lane. So something else is
probably going on. I suspect it might be related to the
`enableUnifiedSyncLane` experiment.
This is likely related to a regression found internally at Meta. We're
still working on getting a proper regression test; I can come up with a
contrived one but I'm not confident it'll be the same as the actual
regression until we get a better repro.
Adds a missing test assertion for Server Context deprecation.
The PR that added this warning was based on an older revision than the
PR that added the test.
As agreed, we're removing Server Context. This was never official
documented.
We've found that it's not that useful in practice. Often the better
options are:
- Read things off the url or global scope like params or cookies.
- Use the module system for global dependency injection.
- Use `React.cache()` to dedupe multiple things instead of computing
once and passing down.
There are still legit use cases for Server Context but you have to be
very careful not to pass any large data, so in generally we recommend
against it anyway.
Yes, prop drilling is annoying but it's not impossible for the cases
this is needed. I would personally always pick it over Server Context
anyway.
Semantically, Server Context also blocks object deduping due to how it
plays out with Server Components that can't be deduped. This is much
more important feature.
Since it's already in canary along with the rest of RSC, we're adding a
warning for a few versions before removing completely to help migration.
---------
Co-authored-by: Josh Story <josh.c.story@gmail.com>
Build fails because the package does not exist. I've added the package
to npm but we need the publishing account to be a collaborator. I'm
reverting until we get that sorted so we don't block canaries
Adds support for lowering rest element parameters to spreads. We eagerly create
a temporary, similar to the approach for destructuring. In theory we could do
something more optimal if you have a `...foo` (rest element where the argument
is an Identifier) but it doesn't seem worth optimizing yet.
As noted earlier in the stack and in chat, there are some cases where the output
of a reactive scope is not guaranteed to change just because its inputs did.
Consider a function `foo(x) { return x < 10 }`. If x was 0 and changes to 1, the
result of `foo(x)` won't change.
For code such as `[foo(x)]`, then, merging the scope for `t0 = foo(x)` and `t1 =
[t0]` into a single `t1 = [foo(x)]` could cause us to invalidate `t1`
unnecessarily. For example, x changing from 0 to 1 would allocate a new array of
`[true]` even though the value didn't meaningfully change. This is the second
category of merging, where we merge scopes A and B if the outputs of A are the
inputs to B.
With this change, we only do this type of merge if the outputs of the first
scope are known to invalidate whenever the input does. We're conservative about
this, and only consider function expressions, arrays, object, and jsx to always
invalidate. Function calls _may_ invalidate, but as w the `foo()` example here
they also may not.
Note that this is purely about optimization and not correctness. We could always
merge in this case (per earlier in the stack) but that might invalidate more
often than we would like.
This is the optimization mentioned in #2113. When we merge scopes, often the
declarations from the first scope become unnecessary, since those values are
only consumed by the subsequent, now-merged scope. There's no point emitting
those values as outputs of the merged scope since no one can consume them.
Thanks to the logic in #2116 we now know the last place each identifier is used.
We use that again here, to prune declarations that aren't used past the end of
the merged scope. This is a pretty dramatic win on cache slots used.
We can't merge scopes if the intervening instructions produce values that are
used later on. This PR improves the mechanism for detecting this case: first we
build up a mapping of the last time (max instruction id) each identifier is
used. Then when we're about to merge scopes we check if all the intervening
lvalues are last used at or before the scope. If so that means it's safe to
merge.
I can't think of any edge cases that are problematic in the old behavior, but
this version is more trivially correct and should allow us to extend to other
types of instructions more easily.
This is something we've wanted to do for a while, and which @sophiebits also
brought up. The idea is to merge consecutive reactive scopes that will always
invalidate together. There are two cases of this:
* Both scopes have the exact same inputs
* Or the inputs of the second scope are the outputs of the first
In both these cases it's pure overhead to keep the scopes separate. In the first
case where both scopes have the same inputs, merging allows us to check the
inputs once instead of 2+ times. In the second case, we know that the second
scope will invalidate when the first does so it's wasteful to recheck the
outputs of the first scope for changes.
This is already cutting down on memoization quite a bit in the fixtures. Note
that there's an additional optimization we can do after merging the second
category, which is to remove the first scope's declarations if they were only
referenced by the second scope. I'll add that in a follow-up.
When I added react-server-dom-turbopack I failed to mark the package as
stable so it did not get published with the canary release. This adds
the package to the stable set so it will be published correctly
stacked on #27314
Turbopack requires a different module loading strategy than Webpack and
as such this PR implements a new package `react-server-dom-turbopack`
which largely follows the `react-server-dom-webpack` but is implemented
for this new bundler
Currently when we SSR a Flight response we do not emit any resources for
module imports. This means that when the client hydrates it won't have
already loaded the necessary scripts to satisfy the Imports defined in
the Flight payload which will lead to a delay in hydration completing.
This change updates `react-server-dom-webpack` and
`react-server-dom-esm` to emit async script tags in the head when we
encounter a modules in the flight response.
To support this we need some additional server configuration. We need to
know the path prefix for chunk loading and whether the chunks will load
with CORS or not (and if so with what configuration).
Refactors Resources to have a more compact and memory efficient
struture. Resources generally are just an Array of chunks. A resource is
flushed when it's chunks is length zero. A resource does not have any
other state.
Stylesheets and Style tags are different and have been modeled as a unit
as a StyleQueue. This object stores the style rules to flush as part of
style tags using precedence as well as all the stylesheets associated
with the precedence. Stylesheets still need to track state because it
affects how we issue boundary completion instructions. Additionally
stylesheets encode chunks lazily because we may never write them as html
if they are discovered late.
The preload props transfer is now maximally compact (only stores the
props we would ever actually adopt) and only stores props for
stylesheets and scripts because other preloads have no resource
counterpart to adopt props into. The ResumableState maps that track
which keys have been observed are being overloaded. Previously if a key
was found it meant that a resource already exists (either in this render
or in a prior prerender). Now we discriminate between null and object
values. If map value is null we can assume the resource exists but if it
is an object that represents a prior preload for that resource and the
resource must still be constructed.
This fixes so that you can postpone in a fallback. This postpones the
parent boundary. I track the fallbacks in a separate replay node so that
when we resume, we can replay the fallback itself and finish the
fallback and then possibly later the content. By doing this we also
ensure we don't complete the parent too early since now it has a render
task on it.
There is one case that this surfaces that isn't limited to
prerender/resume but also render/hydrateRoot. I left todos in the tests
for this.
If you postpone in a fallback, and suspend in the content but eventually
don't postpone in the content then we should be able to just skip
postponing since the content rendered and we no longer need the
fallback. This is a bit of a weird edge case though since fallbacks are
supposed to be very minimal.
This happens because in both cases the fallback starts rendering early
as soon as the content suspends. This also ensures that the parent
doesn't complete early by increasing the blocking tasks. Unfortunately,
the fallback will irreversibly postpone its parent boundary as soon as
it hits a postpone.
When you suspend, the same thing happens but we typically deal with this
by doing a "soft" abort on the fallback since we don't need it anymore
which unblocks the parent boundary. We can't do that with postpone right
now though since it's considered a terminal state.
I think I'll just leave this as is for now since it's an edge case but
it's an annoying exception in the model. Makes me feel I haven't quite
nailed it just yet.
1.
9fc04eaf3f (diff-2c5e1f5e80e74154e65b2813cf1c3638f85034530e99dae24809ab4ad70d0143)
introduced a vulnerability: we listen to `'fetch-file-with-cache'` event
from `window` to fetch sources of the file, in which we want to parse
hook names. We send this event via `window`, which means any page can
also use this and manipulate the extension to perform some `fetch()`
calls. With these changes, instead of transporting message via `window`,
we have a distinct content script, which is responsible for fetching
sources. It is notified via `chrome.runtime.sendMessage` api, so it
can't be manipulated.
2. Consistent structure of messages `{source: string, payload: object}`
in different parts of the extension
3. Added some wrappers around `chrome.scripting.executeScript` API in
`packages/react-devtools-extensions/src/background/executeScript.js`,
which support custom flow for Firefox, to simulate support of
`ExecutionWorld.MAIN`.
If we track a postponed SuspenseBoundary parent that we have to replay
through before it has postponed and it postpones itself later, we need
to upgrade it to a postponed replay boundary instead of adding two.
We currently abort a stream either it's explicitly told to abort (e.g.
by an abortsignal). In this case we still finish writing what we have as
well as instructions for the client about what happened so it can
trigger fallback cases and log appropriately.
We also abort a request if the stream itself cancels. E.g. if you can't
write anymore. In this case we should not write anything to the outgoing
stream since it's supposed to be closed already now. However, we should
still abort the request so that more work isn't performed and so that we
can log the reason for it to the onError callback.
We should also not do any work after aborting.
There we need to stop the "flow" of bytes - so I call stopFlowing in the
cancel case before aborting.
The tests were testing this case but we had changed the implementation
to only start flowing at initial read (pull) instead of start like we
used to. As a result, it was no longer covering this case. We have to
call reader.read() in the tests to start the flow so that we need to
cancel it.
We also were missing a final assertion on the error logs and since we
were tracking them explicitly the extra error was silenced.
Changes:
1. [Firefox-only] For some reason, Firefox might try to inject
dynamically registered content script in pages like `about:blank`. I
couldn't find a way to change this behaviour, `about:` is not a valid
scheme, so we can't exclude it and `match_about_blank` flag is not
supported in `chrome.scripting.registerContentScripts`.
2. While navigating the history in Firefox, some content scripts might
not be re-injected and still be alive. To handle this, we are now
patching `window` with `__REACT_DEVTOOLS_PROXY_INJECTED__` flag, to make
sure that proxy is injected and only once. This flag is cleared on
`pagehide` event.
---
(pasted from comment)
Instead of handling holey arrays, bail out with a TODO error.
Older versions of babel seem to have inconsistent handling of holey arrays, at
least when paired with HermesParser. When using these versions, we should bail
out instead of throwing a Babel validation error.
Issue:
The babel ast definition for array elements changed from Array<PatternLike> to
Array<PatternLike | null>. Older versions do not expect null in the ArrayPattern
ast and will throw a validation error during Codegen.
- HermesParser will parse [, b] into [NodePath<null>, NodePath<Identifier>]
- Forget will try to preserve this holey array when we codegen back to js
(e.g. we call a babel builder function arrayPattern([null, identifier]))
- Babel will fail with `TypeError: Property elements[0] of ArrayPattern
expected node to be of a type ["PatternLike"] but instead got null`
PR that changed the AST definition:
https://github.com/babel/babel/pull/10917/files#diff-19b555d2f3904c206af406540d9df200b1e16befedb83ff39ebfcbd876f7fa8aL52-R56
[ez] Add TODO bailout on non-backward compatible holey arrays
---
(pasted from comment)
Instead of handling holey arrays, bail out with a TODO error.
Older versions of babel seem to have inconsistent handling of holey arrays, at
least when paired with HermesParser. When using these versions, we should bail
out instead of throwing a Babel validation error.
Issue:
The babel ast definition for array elements changed from Array<PatternLike> to
Array<PatternLike | null>. Older versions do not expect null in the ArrayPattern
ast and will throw a validation error during Codegen.
- HermesParser will parse [, b] into [NodePath<null>, NodePath<Identifier>]
- Forget will try to preserve this holey array when we codegen back to js
(e.g. we call a babel builder function arrayPattern([null, identifier]))
- Babel will fail with `TypeError: Property elements[0] of ArrayPattern
expected node to be of a type ["PatternLike"] but instead got null`
PR that changed the AST definition:
https://github.com/babel/babel/pull/10917/files#diff-19b555d2f3904c206af406540d9df200b1e16befedb83ff39ebfcbd876f7fa8aL52-R56
This PR adds preliminary support for hoisting const variable declarations. We do
this via BuildHIR when lowering top level statements in a BlockStatement, by
first checking which bindings are in scope to be hoistable if referenced before
they are declared. The declarations are then hoisted to their earliest point
where they are referenced (ie the top level statement just before) as context
variables.
Later, prior to codegen, we restore the original source by removing the
DeclareContexts and transforming their associated StoreContexts back.
Support for hoisting other kinds of declarations will come in future PRs!
https://github.com/facebook/react/pull/26740 introduced regression:
React DevTools doesn't record updates for `useTransition` hook. I can
add more details about things on DevTools side, if needed.
The root cause is
491aec5d61/packages/react-reconciler/src/ReactFiberHooks.js (L2728-L2730)
React DevTools expects dispatch to be present for stateful hooks that
can schedule an update -
2eed132847/packages/react-devtools-shared/src/backend/renderer.js (L1422-L1428)
With these changes, we still call dispatch in `startTransition`, but
also patch `queue` object with it, so that React DevTools can recognise
`useTransition` as stateful hook that can schedule update.
I am not sure if this is the right approach to fix this, can we
distinguish if `startTransition` was called from `useTransition` hook or
as a standalone function?
The key is that instead of storing different tags of resumable points,
we just store if a replay node has any resumable slots and if that's at
the root `number` or if it has resumable slots by index.
This is a simpler and more compact format because we don't have to
separate the three Resume forms.
This helps deal with Postpone in fallbacks because it doesn't just
double all the cases.
Fixes#26876, I think. Review each commit separately (all assertions
pass in main already, except the last assertInputTrackingIsClean in
"should control radio buttons").
I'm actually a little confused on two things here:
* All the isCheckedDirty assertions are true. But I don't think we set
.checked unconditionally? So how does this happen?
* https://github.com/facebook/react/issues/26876#issuecomment-1611662862
claims that
d962f35ca...1f248bdd7 contains
the faulty change, but it doesn't appear to change the restoration logic
that I've touched here. (One difference outside restoration is that
updateProperties did previously set `.checked` when `nextProp !==
lastProp` whereas the new logic in updateInput is to set it when
`node.checked !== !!checked`.)
But it seems to me like we need this call here anyway, and if it fixes
it then it fixes it? I think technically speaking we probably should do
all the updateInput() calls and then all the updateValueIfChanged()
calls—in particular I think if clicking A changed the checked radio
button from B to C then the code as I have it would be incorrect, but
that also seems unlikely so idk whether to care.
cc @zhengjitf @Luk-z who did some investigation on the original issue
To support MPA-style form submissions, useFormState sends down a key
that represents the identity of the hook on the page. It's based on the
key path of the component within the React tree; for deeply nested
hooks, this keypath can become very long. We can hash the key to make it
shorter.
Adds a method called createFastHash to the Stream Config interface.
We're not using this for security or obfuscation, only to generate a
more compact key without sacrificing too much collision resistance.
- In Node.js builds, createFastHash uses the built-in crypto module.
- In Bun builds, createFastHash uses Bun.hash. See:
https://bun.sh/docs/api/hashing#bun-hash
I have not yet implemented createFastHash in the Edge, Browser, or FB
(Hermes) stream configs because those environments do not have a
built-in hashing function that meets our requirements. (We can't use the
web standard `crypto` API because those methods are async, and yielding
to the main thread is too costly to be worth it for this particular use
case.) We'll likely use a pure JS implementation in those environments;
for now, they just return the original string without hashing it. I'll
address this in separate PRs.
## Summary
Currently `ReactFizzServer.abort` allows you to pass in the a `reason`
error, which then gets passed to the `onError` handler for each task
that ends up getting aborted. This adds in the ability to pass down that
same `reason` error to `ReactDOMServerFB.abortStream` as well.
## How did you test this change?
Added a test case to ReactDOMServerFB-test.internal.js
Moves writing queues to renderState.
We shouldn't need the resource tracking's value. We just need to know if
that resource has already been emitted. We can use a Set for this. To
ensure that set is directly serializable we can just use a
dictionary-like object with no value.
See individual commits for special cases.
Changes:
1. Refactored react polling logic, now each `.eval()` call is wrapped in
Promise, so we can chain them properly.
2. When user has browser DevTools opened and React DevTools panels were
mounted, user might navigate to the page, which doesn't have React
running. Previously, we would show just blank white page, now we will
show disclaimer. Disclaimer appears after 5 failed attempts to find
React. We will also show this disclaimer if it takes too long to load
the page, but once any React instance is loaded and registered, we will
update the panels.
3. Dark theme support for this disclaimer and popups in Firefox &
Chromium-based browsers
**Important**: this is only valid for case when React DevTools panels
were already created, like when user started debugging React app and
then switched to non-React page. If user starts to debug non-React app
(by opening browser DevTools for it), we will not create these panels,
just like before.
Q: "Why do we poll to get information about react?"
A: To handle case when react is loaded after the page has been loaded,
some sandboxes for example.
| Before | After |
| --- | --- |
| <img width="1840" alt="Screenshot 2023-09-14 at 15 37 37"
src="https://github.com/facebook/react/assets/28902667/2e6ffb39-5698-461d-bfd6-be2defb41aad">
| <img width="1840" alt="Screenshot 2023-09-14 at 15 26 16"
src="https://github.com/facebook/react/assets/28902667/1c8ad2b7-0955-41c5-b8cc-d0fdb03e13ca">
|
This is a redo of #1640 now that we've established the necessary infrastructure,
most notably `Effect.ConditionallyMutate` and `noAlias` from #2103 earlier in
this stack. We can now understand the semantics of hooks that return deeply
readonly values composed of primitives, arrays, or objects such that any
`.map()` or `.filter()` calls are guaranteed to be the corresponding array
methods. That further allows us to refine, since we know that the lambdas passed
to these calls can't alias, are conditionally mutable, etc. All in all this
should let us memoize less in practice.
Adds `noAlias` support for CallExpression, including hooks. Note that we treat
hook arguments as escaping by default — ie we assume that they don't just flow
into the hook return value, but are just outright escape points equivalent to a
return. A `noAlias` annotation on a hook definition disables both: this will
allow us to avoid memoizing the `graphql` tag arguments to `useFragment`, for
example.
Skips compilation of code that has a reference to `useMemoCache()`, as a
last-resort to avoid double-compilation of code. This is meant as a quick way to
unblock since we're still seeing some double compilation issues when syncing
internally.
Originally the intension was to have React assign an ID to a user
rendered DOM node inside a `fallback` while it was loading. If there
already were an explicit `id` defined on the DOM element we would reuse
that one instead. That's why this was a DOM Config option and not just
built in to Fizz.
This became tricky since it can load late and so we'd have to transfer
it down and detect it only once it finished rendering and if there is no
DOM element it doesn't work anyway. So instead, what we do in practice
is to always use a `<template>` tag with the ID. This has the downside
of an extra useless node and shifting child CSS selectors.
Maybe we'll get around to fixing this properly but it might not be worth
it.
This PR just gets rid of the SuspenseBoundaryID concept and instead we
just use the same ID number as the root segment ID of the boundary to
refer to the boundary to simplify the implementation.
This also solves the problem that SuspenseBoundaryID isn't currently
serializable (although that's easily fixable by itself if necessary).
Based on #27385.
When we error or abort during replay, that doesn't actually error the
component that errored because that has already rendered. The error only
affects any child that is not yet completed. Therefore the error kind of
gets thrown at the resumable point.
The resumable point might be a hole in the replay path, in which case
throwing there errors the parent boundary just the same as if the replay
component errored. If the hole is inside a deeper Suspense boundary
though, then it's that Suspense boundary that gets client rendered. I.e.
the child boundary. We can still finish any siblings.
In the shell all resumable points are inside a boundary since we must
have finished the shell. Therefore if you error in the root, we just
simply just turn all incomplete boundaries into client renders.
The idea for this check is that we shouldn't flush anything before we
flush the shell. That may or may not hold true in future formats like
RN.
It is a problem for resuming because with resuming it's possible to have
root tasks that are used for resuming but the shell was already flushed
so we can have completed boundaries before the shell has fully resumed.
What matters is whether the parent has already flushed or not.
It's not technically necessary to bail early because there won't be
anything in partialBoundaries or completedBoundaries because nothing
gets added there unless the parent has already flushed.
It's not exactly slow to have to check the length of three arrays so
it's probably not a big deal.
Flush partials in an early preamble needs further consideration
regardless.
This has been nagging at me for a _long_ time: we unnecessarily memoize function
callbacks passed to things like Array.prototype.map, even though we know these
functions can't escape. This PR fixes this as follows:
* Adds a `noAlias?: boolean` flag to builtin function signatures, defaulting to
false if not specified.
* Adds a feature flag, `enableNoAliasOptimizations`, to gate optimizations based
on the value of that new flag.
* When the feature is enabled, `PruneNonEscapingScopes` now looks up the
signature of method calls, and avoids memoizing the arguments if the signatures
specifies `noAlias: true`.
* Annotates Array.prototype.map and Array.prototype.filter as `noAlias`.
This does not mean we'll never memoize arguments to Array.prototype.map, it just
means that the argument itself won't be considered as escaping. If the function
still escapes by some other means it will get memoized:
```
function Component(props) {
const f = () => {}; // memoized!
const x = [].map(f); // not from here..
return [x, f]; // but bc it escapes here
}
```
Note: this delivers some of the wins from #1640. That PR tried to do a bunch of
things, part of which I already landed w the introduction of
ConditionallyMutate, which allowed us to type Array.prototype.map. This PR
further gives us the ability to understand functions that don't alias their
params at all. The remaining bit from #1640 is the idea of understanding that
key hooks such as `useFragment()` return transitively readonly, transitively
array/object/primitive values, and any `.map()` or `.filter()` calls must be on
arrays, allowing us to optimize them. Without that extra step, we'll still have
to memoize a lot of `array.map()` lambdas just because we aren't sure that the
receiver is an Array. But this PR helps with some cases, and lays the groundwork
for the rest of that PR.
This forks Task into ReplayTask and RenderTask.
A RenderTask is the normal mode and it has a segment to write into.
A ReplayTask doesn't have a segment to write into because that has
already been written but instead it has a ReplayState which keeps track
of the next set of paths to follow. Once we hit a "Resume" node we
convert it into a RenderTask and continue rendering from there.
We can resume at either an Element position or a Slot position. An
Element pointing to a component doesn't mean we resume that component,
it means we resume in the child position directly below that component.
Slots are slots inside arrays.
Instead of statically forking most paths, I kept using the same path and
checked for the existence of a segment or replay state dynamically at
runtime.
However, there's still quite a bit of forking here like retryRenderTask
and retryReplayTask. Even in the new forks there's a lot of duplication
like resumeSuspenseBoundary, replaySuspenseBoundary and
renderSuspenseBoundary. There's opportunity to simplify this a bit.
Adds a separate entry point for the react-dom package when it's accessed
from a Server Component environment, using the "react-server" export
condition.
When you're inside a Server Component module, you won't be able to
import client-only APIs like useState. This applies to almost all React
DOM exports, except for Float ones like preload.
Per the title, `<fbt:param>0</fbt:param>` is invalid FBT, you must wrap the text
in an expression container. But that's not all, `fbt:param` can only have a
single child, which means we have to strip out the text elements that occur from
the whitespace in the source.
Fixes another special-case rule of fbt that i wasn't aware of: apparently
`<fbt:param>` elements don't have to appear as direct children of `<fbt>`, they
can be nested, and in this case they must appear as direct children of the fbt
and not via an identifier indirection. This PR recursively extends the scope of
FBT operands to make this work.
The type of ObjectProperty is specific to the key, not the ObjectProperty. In
the future, we want to add a type to represent the value of the ObjectProperty.
This PR moves out the fields related to the key of the ObjectProperty to a
separate type.
---
Recent commits added calls to `NodePath.hasNode`, which does not exist in babel
v7.1.6 (internal). Forget is failing with this error.
```js
TypeError: handlerPath.hasNode is not a function
at lowerStatement (.../babel-plugin-react-forget/HIR/BuildHIR.js:924:58)
...
```
@mofeiZ noticed that some configurations of prettier don't support JSXFragment
appearing as a JSXAttribute value, in violation of the spec. Coincidentally I
noticed that our internal build system also fails on this as i was trying to
roll out on more surfaces. This PR makes sure we wrap fragments in an
expressioncontainer if they appear as jsxattribute values.
Adds test cases that would demonstrate different output if we were to update
InferTypes to infer the types of phi identifiers when their operands have the
same type. We currently do infer such types, but attach them to phi.type instead
of phi.id.type, so the type doesn't effect inference. Fixing that would cause
the output on these examples to change — however, per the discussion on #2079,
we'd also incorrectly set the mutable ranges in some cases and cause incorrect
compilation.
I did a thorough review of InferReferenceEffects and can't figure out how to
trigger the bug in our current implementation — the bug only kicks in when phi
operands would be mutated as a store instead of a mutate, and that cannot happen
given our currently imprecise types on phi identifiers.
---
Changed `panicOnBailout: boolean` to `panicThreshold`, which has the following
options. Note that `ALL_ERRORS` corresponds to `panicOnBailout = true` and
`CRITICAL_ERRORS` corresponds to `panicOnBailout = false`. `NONE` is a new
option.
```js
export type PanicThresholdOptions =
// Bail out of compilation on all errors by throwing an exception.
| "ALL_ERRORS"
// Bail out of compilation only on critical or unrecognized errors.
// Instead, silently skip the erroring function.
| "CRITICAL_ERRORS"
// Never bail out of compilation. Instead, silently skip the erroring
// function or file.
| "NONE";
```
Jest seems to run babel through a different pipeline than Metro and -
(perhaps through its complex `require` interjection logic). When running jest
tests, exceptions thrown by babel transforms will bubble up to the nearest
exception boundary which is often the jest test itself. This may not be a useful
signal to anyone running a jest test with Forget enabled, as the erroring code
may be within Forget itself or a transitively required module.
Another reason to immediately bailing out on critical errors is that we may want
to record errors found in the rest of the file.
---
I'm not convinced that this change makes sense. A counterargument is that any
CriticalErrors *should* be reported as parse errors, regardless of the runtime
mode. Anyhow, this would be useful long term for our static analysis scripts
(e.g. collecting info on bailouts and compilation info e.g. # slots used for
JSX) as we want to compile-as-much-as-possible in those.
---
Add types for logged events, including a `CompileSuccess` event which can help
us record successfully compiled Forget functions and their compilation details
(e.g. # memoSlots used).
We currently have multiple flags for targeting which functions to compile, but
they are actually mutually exclusive. This PR consolidates to a single
`compilationMode: 'annotation' | 'infer' | 'all'` flag:
* Annotation compiles only functions that explicitly opt-in with "use forget"
* Infer compiles explicitly opted-in functions (via "use forget") as well as any
known/inferred components or hooks:
* Component declarations
* Component or hook-like functions (same rules as the ESLint plugin but with an
extra check for whether it uses JSX or calls a hook)
* All compiles all top-level functions. We should get rid of this in a follow-up
and make tests use infer mode by default, and add explicit opt-ins where
necessary.
In all modes, "use no forget" always takes precedence and can be used to
opt-out. The default mode is now "infer".
This is an optimization where useFormState will only emit extra comment
markers if a form state is passed at the root. If no state is passed, we
don't need to emit anything because none of the hooks will match.
The permalink option of useFormState controls which page the form is
submitted to during an MPA form submission (i.e. a submission that
happens before hydration, or when JS is disabled). If the same
useFormState appears on the resulting page, and the permalink option
matches, it should receive the form state from the submission despite
the fact that the keypaths do not match.
So the logic for whether a form state instance is considered a match is:
- Both instances must be passed the same action signature
- If a permalink is provided, the permalinks must match.
- If a permalink is not provided, the keypaths must match.
Currently, if there are multiple matching useFormStates, they will all
match and receive the form state. We should probably only match the
first one, and/or warn when this happens. I've left this as a TODO for
now, pending further discussion.
Typically we assign IDs lazily when flushing to minimize the ids we have
to assign and we try to maximize inlining.
When we prerender we could always flush into a buffer before returning
but that's not actually what we do right now. We complete rendering
before returning but we don't actually run the flush path until someone
reads the resulting stream. We assign IDs eagerly when something
postpone so that we can refer to those ids in the holes without flushing
first.
This leads to some interesting conditions that needs to consider this.
This PR also deals with rootSegmentId which is the ID of the segment
that contains the body of a Suspense boundary. The boundary needs to
know this in addition to the Suspense Boundary's ID to know how to
inject the root segment into the boundary.
Why is the suspense boundary ID and the rootSegmentID just not the same
ID? Why don't segments and suspense boundary not share ID namespace?
That's a good question and I don't really remember. It might not be a
good reason and maybe they should just be the same.
During an MPA form submission, useFormState should only reuse the form
state if same action is passed both times. (We also compare the key
paths.)
We compare the identity of the inner closure function, disregarding the
value of the bound arguments. That way you can pass an inline Server
Action closure:
```js
function FormContainer({maxLength}) {
function submitAction(prevState, formData) {
'use server'
if (formData.get('field').length > maxLength) {
return { errorMsg: 'Too many characters' };
}
// ...
}
return <Form submitAction={submitAction} />
}
```
If a Server Action is passed to useFormState, the action may be
submitted before it has hydrated. This will trigger a full page
(MPA-style) navigation. We can transfer the form state to the next page
by comparing the key path of the hook instance.
`ReactServerDOMServer.decodeFormState` is used by the server to extract
the form state from the submitted action. This value can then be passed
as an option when rendering the new page. It must be passed during both
SSR and hydration.
```js
const boundAction = await decodeAction(formData, serverManifest);
const result = await boundAction();
const formState = decodeFormState(result, formData, serverManifest);
// SSR
const response = createFromReadableStream(<App />);
const ssrStream = await renderToReadableStream(response, { formState })
// Hydration
hydrateRoot(container, <App />, { formState });
```
If the `formState` option is omitted, then the state won't be
transferred to the next page. However, it must be passed in both places,
or in neither; misconfiguring will result in a hydration mismatch.
(The `formState` option is currently prefixed with `experimental_`)
This field was not being initialized. Although the property is part of
the Flow type, the type error wasn't caught because the constructor
itself is not covered by Flow, which is unfortunate. (I assume this is
related to the dev-only componentStack property.)
Currently, if a component suspends, the keyPath has already been
modified to include the identity of the component itself; the path is
set before the component body is called (akin to the begin phase in
Fiber). An accidental consequence is that when the promise resolves and
component is retried, the identity gets appended to the keyPath again,
leading to a duplicate node in the path.
To address this, we should only modify contexts after any code that may
suspend. For maximum safety, this should occur as late as possible:
right before the recursive renderNode call, before the children are
rendered.
I did not add a test yet because there's no feature that currently
observes it, but I do have tests in my other WIP PR for useFormState:
#27321
There's a subtle difference if you suspend before the first array or
after. In Fiber, we don't deal with this because we just suspend the
parent and replay it if lazy() or Usable are used in its child slots. In
Fizz we try to optimize this a bit more and enable resuming inside the
component.
Semantically, it's different if you suspend/postpone before the first
child array or inside that child array. Because when you resume the
inner result might be another array and either that's part of the parent
path or part of the inner slot.
There might be more clever way of structuring this but I just use -1 to
indicate that we're not yet inside the array and is in the root child
position. If that renders an element, then that's just the same as the 0
slot.
We need to also encode this in the resuming. I called that resuming the
element or resuming the slot.
When Float was first developed the internal implementation and external
interface were the same. This is problematic for a few reasons. One, the
public interface is typed but it is also untrusted and we should not
assume that it is actually respected. Two, the internal implementations
can get called from places other than the the public interface and
having to construct an options argument that ends up being destructured
to process the request is computationally wasteful and may limit JIT
optimizations to some degree. Lastly, the wire format was not as
compressed as it could be and it was untyped.
This refactor aims to address that by separating the public interface
from the internal implementations so we can solve these challenges and
also make it easier to change Float in the future
* The internal dispatcher method preinit is now preinitStyle and
preinitScript.
* The internal dispatcher method preinitModule is now
preinitModuleScript in anticipation of different implementations for
other module types in the future.
* The wire format is explicitly typed and only includes options if they
are actually used omitting undefined and nulls.
* Some function arguments are not options even if they are optional. For
instance precedence can be null/undefined because we deafult it to
'default' however we don't cosnider this an option because it is not
something we transparently apply as props to the underlying instance.
* Fixes a problem with keying images in flight where srcset and sizes
were not being taken into account.
* Moves argument validation into the ReactDOMFloat file where it is
shared with all runtimes that expose these methods
* Fixes crossOrigin serialization to use empty string except when
'use-credentials'
Some context:
- When user selects an element in tree inspector, we display current
state of the component. In order to display really current state, we
start polling the backend to get available updates for the element.
Previously:
- Straight-forward sending an event to get element updates each second.
Potential race condition is not handled in any form.
- If user navigates from the page, timeout wouldn't be cleared and we
would potentially throw "Timed out ..." error.
- Bridge disconnection is not handled in any form, if it was shut down,
we could spam with "Timed out ..." errors.
With these changes:
- Requests are now chained, so there can be a single request at a time.
- Handling both navigation and shut down events.
This should reduce the number of "Timed out ..." errors that we see in
our logs for the extension. Other surfaces will also benefit from it,
but not to the full extent, as long as they utilize
"resumeElementPolling" and "pauseElementPolling" events.
Tested this on Chrome, running React DevTools on multiple tabs,
explicitly checked the case when service worker is in idle state and we
return back to the tab.
Replaces the use of `NextIterableOf` in for-in with a new `NextPropertyOf`
instruction. The key distinction is `for-of` invokes an arbitrary iterator,
which means a) each iteration may mutate the collection being iterated and b)
the returned value may be mutable. However, `for-in` invokes a language-level
mechanism to iterate: simply iterating alone _cannot_ modify the collection, and
the returned value is known to be a primitive.
It's possible to postpone a specific node and not using a wrapper
component. Therefore we encode the resumable slot as the index slot.
When it's a plain client component that postpones, it's encoded as the
child slot inside that component which is the one that's postponed
rather than the component itself.
Since it's possible for a child slot to suspend (e.g. React.lazy's
microtask in this case) retryTask might need to keep its index around
when it resolves.
First pass of ForInStatement support. This mostly just copies our handling of
ForOfStatement, but the next PR updates to use a different instruction instead
of `NextIterableOf`.
Found a hydration bug that happens when you pass a Server Action to
`formAction` and the next node is a text instance.
The HTML generated by Fizz is something like this:
```html
<button name="$ACTION_REF_5" formAction="" formEncType="multipart/form-data" formMethod="POST">
<input type="hidden" name="$ACTION_5:0" value="..."/>
<input type="hidden" name="$ACTION_5:1" value="..."/>
<input type="hidden" name="$ACTION_KEY" value="..."/>Count: <!-- -->0
</button>
```
Fiber is supposed to skip over the extra hidden inputs, but it doesn't
handle this correctly if the next expected node isn't a host instance.
In this case, it's a text instance.
Not sure if the proper fix is to change the HTML that is generated, or
to change the hydration logic, but in this PR I've done the latter.
Supports call expressions if the callee and args are themselves reorderable. As
part of this I realized that we currently allow identifier references to be
reordered. To be safe, this PR updates the logic to continue consider
identifiers as reorderable, but considers an arrow function to be not
reorderable if it contains a local variable reference. We can likely relax that
rule, but this quickly unblocks the next experiment.
Supports reordering of unary and arrow function expressions:
* Supports a trivially safe subset of unary operators, rejects things like
`void` just because we don't need it yet.
* Supports arrow function expressions that are either an empty block statement
or a single expression which is itself reorderable.
Adds handling for some cases where the handler is unreachable (or is provably
unreachable after analysis & optimization), where the try/catch can be flattened
away:
* The try block is empty. Nothing can throw, so the handler is unreachable.
* The try block will always return. It can't return anything interesting (ie the
result of a function call or variable load) since those could throw, but a try
block that always return a primitive means the handler is unreachable.
* The same, except where we only determine that the try block always returns via
constant propagation.
Enables sprout for all the new try/catch fixtures in this stack. I added new
helpers and tried to make sure we're testing the most interesting codepath of
each fixture. This is where property testing would help, since we could test
multiple paths with a single block of code, but for now this seems like a good
balance of coverage.
It's possible that the value thrown during a `try` block actually is a reference
to some value defined outside the scope of the try block. If the catch clause
param is also mutated, that means the mutable range of the variable would have
to include the entire try/catch.
We handle this by emitting a DeclareLocal temporary for the catch param prior to
the try/catch. If it is modified during the catch block, that will extend its
mutable range to cover the full try/catch. If any values are mutated inside the
try, their range will also (naturally) extend around the full try/catch block.
These ranges will overlap and be merged, ensuring that we capture the
possibility that the value is mutated via the catch param. See unit test.
Modeling `throw` inside of a try/catch is awkward because it's basically a
variable reassignment and a goto together. Thankfully that is an antipattern —
using exceptions instead of control-flow — so it seems pretty reasonable to just
put a todo here and leave it.
Adds an optimization pass to prune unnecessary maybe-throw terminals, when the
block can be proven not to throw. For now we're _very_ conservative about what
instructions we consider not to throw. There isn't too much of an advantage in
pruning further, either.
This PR also updates BuildReactiveFunction to handle the possibility of early
returns within try or catch blocks, making sure we don't hit the invariant of
emitting the same block twice.
Implements the core lowering logic for try/catch:
* Inside of the `try` block, we use the new HIRBuilder mode to wrap every
instruction in a separate basic block with a maybe-throw terminal
* We emit a 'try' terminal for the try/catch itself
For basic examples this already works correctly. But we don't handle catch
clause params yet.
When implementing `preloadModule` and `preinitModule` these methods were
not exposed on the server rendering stub when they should have been.
This PR corrects that omission.
This PR adds the other piece, a 'try' terminal which represents try/catch and
the possibility of fallthrough to the code afterwards. For now `finally` is
unsupported. We don't yet produce these terminals, see later in the stack.
Adds a "maybe-throw" terminal which represents the possibility that the block
may or may not throw, and can either continue forward or exit to an exception
handler (`catch`). Also updates HIRBuilder to track the current mode, and when
inside a try block to wrap every instruction inside a basic block that ends in a
maybe-throw.
So far this code isn't used yet, so doesn't affect output.
A planned feature of useFormState is that if the page load is the result
of an MPA-style form submission — i.e. a form was submitted before it
was hydrated, using Server Actions — the state of the hook should
transfer to the next page.
I haven't implemented that part yet, but as a prerequisite, we need some
way for Fizz to indicate whether a useFormState hook was rendered using
the "postback" state. That way we can do all state matching logic on the
server without having to replicate it on the client, too.
The approach here is to emit a comment node for each useFormState hook.
We use one of two comment types: `<!--F-->` for a normal useFormState
hook, and `<!--F!-->` for a hook that was rendered using the postback
state. React will read these markers during hydration. This is similar
to how we encode Suspense boundaries.
Again, the actual matching algorithm is not yet implemented — for now,
the "not matching" marker is always emitted.
We can optimize this further by not emitting any markers for a render
that is not the result of a form postback, which I'll do in subsequent
PRs.
img tags inside picture tags should not automatically be preloaded
because usually the img is a fallback. We will consider a more
comprehensive way of preloading picture tags which may require a
technique like using an inline script to construct the image in the
browser but for now we simply omit the preloads to avoid harming load
times by loading fallbacks.
Mostly reuses existing analysis of an identifier property key.
Adds a new type field to ObjectProperty to propogate the type of the key. This
is used in codegen to correctly emit a string literal or an identifier.
Just moving some internal code around again.
I originally encoded what type of work using startRender vs
startPrerender. I had intended to do more forking of the work loop but
we've decided not to go with that strategy. It also turns out that
forking when we start working is actually too late because of a subtle
thing where you can call abort before work begins. Therefore it's
important that starting the work comes later.
To generate IDs for useId, we modify a context variable whenever
multiple siblings are rendered, or when a component includes a useId
hook.
When this happens, we must ensure that the context is reset properly on
unwind if something errors or suspends. When I originally implemented
this, I did this by wrapping the child's rendering with a try/finally
block. But a better way to do this is by using the non-destructive
renderNode path instead of renderNodeDestructive.
Technically there is a body node created for implicit return expression in a
arrow function, so the existing logic should've worked fine. But there seems to
be a Babel bug, so let's work around it by traversing the function.
Added a test case that captures a dep as a param -- this is currently
unsupported and also something that would've been ignored before this PR. Added
a failing test to make sure we think about this case when we add support for
default params.
Future passes will lead to inconsistent state between passes and will require
passes to run in a specific order, so let's make sure no one will misconfigure
the passes.
Client reference proxy should implement getOwnPropertyDescriptor. One
practical place where this shows up is when consuming CJS module.exports
in ESM modules. Node creates named exports it statically infers from the
underlying source but it only sets the named export if the CJS exports
hasOwnProperty. This trap will allow the proxy to respond affirmatively.
I did not add unit tests because contriving the ESM <-> CJS scenario in
Jest is challenging. I did add new components to the flight fixture
which demonstrate that the named exports are properly constructed with
the client reference whereas they were not before.
This joins the static (prerender) builds with the server builds but
doesn't change the public entry points.
The idea of two separate bundles is that we'd have a specialized build
for Fizz just for the prerender that could do a lot more. However, in
practice the code is implemented with a dynamic check so it's in both.
It's also not a lot of code.
At the same time if you do have a set up that includes both the
prerender and the render in the same build output, this just doubles the
server bundle size for no reason.
So we might as well merge them into one build. However, I don't expose
the `prerender` from `/server`. Instead it's just exposed from the
public `/static` entry point. This leaves us with the option to go back
to separate builds later if it diverges more in the future.
In https://github.com/facebook/react/pull/21113 I moved this over to the
segment from the task. This partially reverts this two use two fields
instead. I was just trying to micro-optimize by reusing a single field.
This is really conceptually two different values. Task is keeping track
of the working state of the currently executing context.
The segment just needs to keep track of which parent context it was
created in so that it can be wrapped correctly when a segment is
written. We just happened to rely on the working state returning to the
top before completing.
The main motivation is that there is no `segment` for replaying.
- Instead of reconnecting ports from devtools page and proxy content
script, now handling their disconnection properly
- `proxy.js` is now dynamically registered as a content script, which
loaded for each page. This will probably not work well for Firefox,
since we are still on manifest v2, I will try to fix this in the next
few PRs.
- Handling the case when devtools page port was reconnected and bridge
is still present. This could happen if user switches the tab and Chrome
decides to kill service worker, devtools page port gets disconnected,
and then user returns back to the tab. When port is reconnected, we
check if bridge message listener is present, connecting them if so.
- Added simple debounce when evaluating if page has react application
running. We start this check in `chrome.network.onNavigated` listener,
which is asynchronous. Also, this check itself is asynchronous, so
previously we could mount React DevTools multiple times if navigates
multiple times while `chrome.devtools.inspectedWindow.eval` (which is
also asynchronous) can be executed.
00b7c43318/packages/react-devtools-extensions/src/main/index.js (L575-L583)https://github.com/facebook/react/assets/28902667/9d519a77-145e-413c-b142-b5063223d073
Internal version of babel/core doesn't support the `inherits` property, so let's
try removing it. The tests still seem to pass, so this might be vestigial from
the first iteration of the compiler from last year
Instead of emitting a memo block, emit a function expression and pass it as an
argument to derived (which will then create a computed).
The naming of 'derived' needs to be tweaked.
`chrome.devtools.inspectedWindow.eval` is asynchronous, so using it in
`setInterval` is a mistake.
Sometimes this results into mounting React DevTools twice, and user sees
errors about duplicated fibers in store.
With these changes, `executeIfReactHasLoaded` executed recursively with
a threshold (in case if page doesn't have react).
Although we minimize the risk of mounting DevTools twice here, this
approach is not the best way to have this problem solved. Dumping some
thoughts and ideas that I've tried, but which are out of the scope for
this release, because they can be too risky and time-consuming.
Potential changes:
- Have 2 content scripts:
- One `prepareInjection` to notify service worker on renderer attached
- One which runs on `document_idle` to finalize check, in case if there
is no react
- Service worker will notify devtools page that it is ready to mount
React DevTools panels or should show that there is no React to be found
- Extension port from devtools page should be persistent and connected
when `main.js` is executed
- Might require refactoring the logic of how we connect devtools and
proxy ports
Some corner cases:
- Navigating to restricted pages, like `chrome://<something>` and back
- When react is lazily loaded, like in an attached iframe, or just
opened modal
- In-tab navigation with pre-cached pages, I think only Chrome does it
- Firefox is still on manifest v2 and it doesn't allow running content
scripts in ExecutionWorld.MAIN, so it requires a different approach
Multiple `chrome.panels.create` calls result into having duplicate
panels created in Firefox, these changes fix that.
Now calling `chrome.panels.create` only if there are no panels created
yet.
This is basically the implementation for the prerender pass.
Instead of forking basically the whole implementation for prerender, I
just add a conditional field on the request. If it's `null` it behaves
like before. If it's non-`null` then instead of triggering client
rendered boundaries it triggers those into a "postponed" state which is
basically just a variant of "pending". It's supposed to be filled in
later.
It also builds up a serializable tree of which path can be followed to
find the holes. This is basically a reverse `KeyPath` tree.
It is unfortunate that this approach adds more code to the regular Fizz
builds but in practice. It seems like this side is not going to add much
code and we might instead just want to merge the builds so that it's
smaller when you have `prerender` and `resume` in the same bundle -
which I think will be common in practice.
This just implements the prerender side, and not the resume side, which
is why the tests have a TODO. That's in a follow up PR.
Minimal repro extracted from our internal codebase. Our inference mode sees that
this arrow function is component-like and attempts to compile it, which then
fails because the function accesses `this` which we bailout on.
This is mostly hotfix for https://github.com/facebook/react/pull/27215.
Contains 3 fixes:
- Handle cases when `react` is not loaded yet and user performs in-tab
navigation. Previously, because of the uncleared interval we would try
to mount DevTools twice, resulting into multiple errors.
- Handle case when extension port disconnected (probably by the browser
or just due to its lifetime)
- Removed duplicate `render()` call on line 327
`dom-legacy` does not make sense for Flight. we could still type check
the files but it adds maintenance burden in the inlinedHostConfigs
whenever things change there. Going to make these configs opaque mixed
types to quiet flow since no entrypoints use the flight code
---
quality of life improvement as this seemed to be confusing (oops, and thanks for
the feedback!)
We don't *really* need static annotations for whether a function returns jsx
(e.g. should be rendered as a React element) or not (e.g. should be wrapped in a
wrapper component. This PR adds check for returned jsx objects at runtime
---
Tested by running diffing the output of `yarn sprout --verbose` between this PR
and base.
I ran into the same issue that @poteto and @gsathya (and probably @mofeiZ) have
run into: "Duplicate declaration of '$'" caused by Babel visiting a function
twice despite our calling `skip()`. This PR keeps a set of nodes that we have
already visited to avoid visiting them again, as a workaround for skip not
working.
# Test Plan
Synced to www and confirmed that the previous bug no longer reproduces, and the
compiled output looks sane.
Completes a todo (ie fixes a silly mistake) from a PR earlier in the stack, so
we now correctly recognize and compile arguments to `React.forwardRef()` and
`React.memo()`.
This PR changes the way we compile ArrowFunctionExpression to allow compiling
more cases, such as within `React.forwardRef()`. We no longer convert arrow
functions to function declarations. Instead, CodeGenerator emits a generic
`CodegenFunction` type, and `Program.ts` is responsible for converting that to
the appropriate type. The rule is basically:
* Retain the original node type by default. Function declaration in, function
declaration out. Arrow function in, arrow function out.
* When gating is enabled, we emit a ConditionalExpression instead of creating a
temporary variable. If the original (and hence compiled) functions are function
declarations, we force them into FunctionExpressions only here, since we need an
expression for each branch of the conditional. Then the rules are:
* If this is a `export function Foo` ie a named export, replace it with a
variable declaration with the conditional expression as the initializer, and the
function name as the variable name.
* Else, just replace the original function node with the conditional. This works
for all other cases.
I'm open to feedback but this seems like a pretty robust approach and will allow
us to support a lot of real-world cases that we didn't yet, so i think we need
_something_ in this direction.
We currently have multiple flags for targeting which functions to compile, but
they are actually mutually exclusive. This PR consolidates to a single
`compilationMode: 'annotation' | 'infer' | 'all'` flag:
* Annotation compiles only functions that explicitly opt-in with "use forget"
* Infer compiles explicitly opted-in functions (via "use forget") as well as any
known/inferred components or hooks:
* Component declarations
* Component or hook-like functions (same rules as the ESLint plugin but with an
extra check for whether it uses JSX or calls a hook)
* All compiles all top-level functions. We should get rid of this in a follow-up
and make tests use infer mode by default, and add explicit opt-ins where
necessary.
In all modes, "use no forget" always takes precedence and can be used to
opt-out. The default mode is now "infer".
Adds a new option to infer which functions to compile, based on React's ESLint
rule. The main difference is that in addition to checking the function name we
also check that it creates JSX or calls a hook. This should cover a significant
majority of components and reduce the chance of accidentally targeting
non-components, but it will leave some false negatives.
Note that some cases that the ESLint plugin infers as React functions don't work
yet: we don't compile FunctionExpressions, only ArrowFunctionExpressions, and
the way we handle ArrowFunctionExpression doesn't work with things like
forwardRef or variable declarations. We'll need more updates to fully handle all
these cases, which I'll do later in the stack.
When the `permalink` option is passed to `useFormState`, and the form is
submitted before it has hydrated, the permalink will be used as the
target of the form action, enabling MPA-style form submissions.
(Note that submitting a form without hydration is a feature of Server
Actions; it doesn't work with regular client actions.)
It does not have any effect after the form has hydrated.
## Summary
Fixes: https://github.com/facebook/react/issues/27296
On actions that cause a component to change its signature, and therefore
to remount, the `_debugSource` property of the fiber updates in delay
and causes the `devtools` source field to vanish.
This issue happens in
https://github.com/facebook/react/blob/main/packages/react-reconciler/src/ReactFiberBeginWork.js
```js
function beginWork(
current: Fiber | null,
workInProgress: Fiber,
renderLanes: Lanes,
): Fiber | null {
if (__DEV__) {
if (workInProgress._debugNeedsRemount && current !== null) {
// This will restart the begin phase with a new fiber.
return remountFiber(
current,
workInProgress,
createFiberFromTypeAndProps(
workInProgress.type,
workInProgress.key,
workInProgress.pendingProps,
workInProgress._debugOwner || null,
workInProgress.mode,
workInProgress.lanes,
),
);
}
}
// ...
```
`remountFiber` uses the 3rd parameter as the new fiber
(`createFiberFromTypeAndProps(...)`), but this parameter doesn’t contain
a `_debugSource`.
## How did you test this change?
Tested by monkey patching
`./node_modules/react-dom/cjs/react-dom.development.js`:
<img width="1749" alt="image"
src="https://github.com/facebook/react/assets/75563024/ccaf7fab-4cc9-4c05-a48b-64db6f55dc23">
https://github.com/facebook/react/assets/75563024/0650ae5c-b277-44d1-acbb-a08d98bd38e0
## Summary
passing both a signal and a priority to `postTask`/`yield` in chrome
causes memory to spike and potentially causes OOMs. a fix for this has
landed in chrome 118, but we can avoid the issue in earlier versions by
setting priority on just the TaskController instead.
https://bugs.chromium.org/p/chromium/issues/detail?id=1469367
## How did you test this change?
```
yarn test SchedulerPostTask
```
Fixes https://github.com/facebook/react/issues/27119,
https://github.com/facebook/react/issues/27185.
Fixed:
- React DevTools now works as expected when user performs in-tab
navigation, previously it was just stuck.
https://github.com/facebook/react/assets/28902667/b11c5f84-7155-47a5-8b5a-7e90baca5347
- When user closes browser DevTools panel, we now do some cleanup to
disconnect ports and emit shutdown event for bridge. This should fix the
issue with registering duplicated fibers with the same id in Store.
Changed:
- We reconnect proxy port once in 25 seconds, in order to [keep service
worker
alive](https://developer.chrome.com/docs/extensions/whatsnew/#m110-sw-idle).
- Instead of unregistering dynamically injected content scripts, wen now
get list of already registered scripts and filter them out from scripts
that we want to inject again, see dynamicallyInjectContentScripts.js.
- Split `main.js` and `background.js` into multiple files.
Tested on Chromium and Firefox browsers.
Currently, we are unable to publish a release to Firefox extensions
store, due to `parseHookNames` chunk size, which is ~5mb.
We were not minifying production builds on purpose, to have more
descriptive error messages. Now, Terser plugin will only:
- remove comments
- mangle, but keeping function names (for understandable bug reports)
When some element is inspected in DevTools, we have a polling which
updates the data for this element.
Sometimes when service worker dies or bridge is getting shutdown, we
continue to poll this data and will spam with the same "timed out
error".
<img width="1728" alt="Screenshot 2023-07-28 at 17 39 23"
src="https://github.com/facebook/react/assets/28902667/220c4504-1ccc-4e87-9d78-bfff8b708230">
These changes add an explicit check that polling is allowed only while
bridge is alive.
Fixes https://github.com/facebook/react/issues/26911,
https://github.com/facebook/react/issues/26860.
Currently, we are parsing user agent string to determine which browser
is running the extension. This doesn't work well with custom user
agents, and sometimes when user turns on mobile dev mode in Firefox, we
stop resolving that this is a Firefox browser, extension starts to use
Chrome API's and fails to inject.
Changes:
Since we are building different extensions for all supported browsers
(Chrome, Firefox, Edge), we predefine env variables for browser
resolution, which are populated in a build step.
This implements useFormState in Fiber. (It does not include any
progressive enhancement features; those will be added later.)
useFormState is a hook for tracking state produced by async actions. It
has a signature similar to useReducer, but instead of a reducer, it
accepts an async action function.
```js
async function action(prevState, payload) {
// ..
}
const [state, dispatch] = useFormState(action, initialState)
```
Calling dispatch runs the async action and updates the state to the
returned value.
Async actions run before React's render cycle, so unlike reducers, they
can contain arbitrary side effects.
That way when you bind arguments to a Server Reference, it's still a
server reference and works with progressive enhancement.
This already works on the Server (RSC) layer.
A transition that flows into a dehydrated boundary should not suspend if
the boundary is showing a fallback.
This is related to another issue where Fizz streams in the initial HTML
after a client navigation has already happened. That issue is not fixed
by this commit, but it does make it less likely. Need to think more
about the larger issue.
Import maps need to be emitted before any scripts or preloads so the
browser can properly locate these resources.
Unlike most scripts, importmaps are singletons meaning you can only have
one per document and they must appear before any modules are loaded or
preloaded. In the future there may be a way to dynamically add more
mappings however the proposed API for this seems likely to be a
javascript API and not an html tag.
Given the unique constraints here this PR implements React's support of
importMaps as the following
1. an `importMap` option accepting a plain object mapping module
specifier to path is accepted in any API that renders a preamble (head
content). Notably this precludes resume rendering because in resume
cases the preamble should have already been produced as part of the
prerender step.
2. the importMap is stringified and emitted as a `<script
type="importmap">...</script>` in the preamble.
3. the importMap is escaped identically to how bootstrapScriptContent is
escaped, notably, isntances of `</script>` are escaped to avoid breaking
out of the script context
Users can still render importmap tags however with Float enabled this is
rather pointless as most modules will be hoisted above the importmap
that is rendered. In practice this means the only functional way to use
import maps with React is to use this config API.
Updates the parser-benchmark script to use a benchmarking framework, and
also brings in yargs to make it easier to handle parsing arguments.
Non-CI usage:
```
$ cd bench/parser-benchmark
$ yarn bench --help
Options:
--help Show help [boolean]
--ci [boolean] [default: false]
--sampleSize [number] [default: 1]
$ yarn bench --sampleSize=3
[ISOBENCH ENDED] Parser Benchmark (3 times)
OXC - 32 op/s. 3 samples in 9518 ms. 5.288x (BEST)
SWC - 20 op/s. 3 samples in 9487 ms. 3.256x
HermesParser - 6 op/s. 3 samples in 9124 ms. 1.000x (WORST)
Forget (Rust) - 15 op/s. 3 samples in 9749 ms. 2.499x
```
In CI this outputs JSON instead of logging to stdout. The results are
stored in github's action cache and used as a point of comparison when
new commits are pushed to main. The comparison should be shown on
workflow [summary
pages](https://github.com/facebook/react-forget/actions/runs/5956421081), but
nothing will be populated until we merge this PR.
We intentionally only run this workflow on main as any run would
override the last cached result, so a PR with multiple pushes would then
start having comparisons with itself.
This exposes, but does not yet implement, a new experimental API called
useFormState. It's gated behind the enableAsyncActions flag.
useFormState has a similar signature to useReducer, except instead of a
reducer it accepts an (async) action function. React will wait until the
promise resolves before updating the state:
```js
async function action(prevState, payload) {
// ..
}
const [state, dispatch] = useFormState(action, initialState)
```
When used in combination with Server Actions, it will also support
progressive enhancement — a form that is submitted before it has
hydrated will have its state transferred to the next page. However, like
the other action-related hooks, it works with fully client-driven
actions, too.
This URL is generated on the client (there's an equivalent but shorter
SSR version too) when a function is used as an action. It should never
happen but it'll be invoked if a form is manually submitted or event is
stopped early.
The `'` wasn't escaped so this yielded invalid syntax. Which is an error
too but much less helpful. `missing ) after argument list`. Added a test
that evals to make sure it's correct syntax.
This exposes a `resume()` API to go with the `prerender()` (only in
experimental). It doesn't work yet since we don't yet emit the postponed
state so not yet tested.
The main thing this does is rename ResponseState->RenderState and
Resources->ResumableState. We separated out resources into a separate
concept preemptively since it seemed like separate enough but probably
doesn't warrant being a separate concept. The result is that we have a
per RenderState in the Config which is really just temporary state and
things that must be flushed completely in the prerender. Most things
should be ResumableState.
Most options are specified in the `prerender()` and transferred into the
`resume()` but certain options that are unique per request can't be.
Notably `nonce` is special. This means that bootstrap scripts and
external runtime can't use `nonce` in this mode. They need to have a CSP
configured to deal with external scripts, but not inline.
We need to be able to restore state of things that we've already emitted
in the prerender. We could have separate snapshot/restore methods that
does this work when it happens but that means we have to explicitly do
that work. This design is trying to keep to the principle that we just
work with resumable data structures instead so that we're designing for
it with every feature. It also makes restoring faster since it's just
straight into the data structure.
This is not yet a serializable format. That can be done in a follow up.
We also need to vet that each step makes sense. Notably stylesToHoist is
a bit unclear how it'll work.
Sorry about the thrash in advance! This removes the top level `forget` directory
which adds unnecessary nesting to our repo
Hopefully everything still works
renderToString is a legacy server API which used a trick to avoid having
the DOCTYPE included when rendering full documents by setting the root
formatcontext to HTML_MODE rather than ROOT_HTML_MODE. Previously this
was of little consequence but with Float the Root mode started to be
used for things like determining if we could flush hoistable elements
yet. In issue #27177 we see that hoisted elements can appear before the
<html> tag when using a legacy API `renderToString`.
This change exports a DOCTYPE from FizzConfigDOM and FizzConfigDOMLegacy
respectively, using an empty chunk in the legacy case. The only runtime
perf cost here is that for legacy APIs there is an extra empty chunk to
write when rendering a top level <html> tag which is trivial enough
Fixes#27177
This fixes the regression test added in the previous commit. The
"Suspensey commit" implementation relies on the
`shouldRemainOnPreviousScreen` function to determine whether to 1)
suspend the commit 2) activate a parent fallback and schedule a retry.
The issue was that we were sometimes attempting option 2 even when there
was no parent fallback.
Part of the reason this bug landed is due to how `throwException` is
structured. In the case of Suspensey commits, we pass a special "noop"
thenable to `throwException` as a way to trigger the Suspense path. This
special thenable must never have a listener attached to it. This is not
a great way to structure the logic, it's just a consequence of how the
code evolved over time. We should refactor it into multiple functions so
we can trigger a fallback directly without having to check the type. In
the meantime, I added an internal warning to help detect similar
mistakes in the future.
Since we're not using haste at all, we can just remove the config to
disable haste instead of enabling, just to inject an implementation that
blocks any haste modules from being recognized.
Test Plan:
Creating a module and required it to get the expected error that the
module doesn't exist.
ESTree expects the `range` value to be an array of `[start, end]`, we support
deserializing from that format but serialized as an object of `{start,end}`, now
we serialize to the array form.
Adds a failing test for a case discovered by Next.js. An error boundary
is triggered during initial hydration, and the error fallback includes a
stylesheet. If the stylesheet has not yet been loaded, the commit
suspends, but never resolves even after the stylesheet finishes loading.
Triggering this bug depends on several very specific code paths being
triggered simultaneously. There are a few ways we could fix the bug;
I'll submit as one or more separate PRs to show that each one is
sufficient.
We’ve had this feature turned on internally for a while with only a couple minor
bugs and no fundamental issues. It’s a necessary change for simplifying function
expression dependencies and context variables, so let’s remove the feature flag
and fix forward for any issues.
Tracks the currently executing parent path of a task, using the name of
the component and the key or index.
This can be used to uniquely identify an instance of a component between
requests - assuming nothing in the parents has changed. Even if it has
changed, if things are properly keyed, it should still line up.
It's not used yet but we'll need this for two separate features so
should land this so we can stack on top.
Can be passed to `JSON.stringify(...)` to generate a unique key.
Adds SAFETY comments for the two instances of unsafe blocks that are *not* just
FFI. It seems like overkill to annotate all the FFI calls so i'm skipping that,
let me know if anyone has strong preferences otherwise.
Search for more generic fork files if an exact match does not exist. If
`forks/MyFile.dom.js` exists but `forks/MyFile.dom-node.js` does not
then use it when trying to resolve forks for the `"dom-node"` renderer
in flow, tests, and build
consolidate certain fork files that were identical and make semantic
sense to be generalized
add `dom-browser-esm` bundle and use it for
`react-server-dom-esm/client.browser` build
Stacked on #27224
### Implements `ReactDOM.preloadModule()`
`preloadModule` is a function to preload modules of various types.
Similar to `preload` this is useful when you expect to use a Resource
soon but can't render that resource directly. At the moment the only
sensible module to preload is script modules along with some other `as`
variants such as `as="serviceworker"`. In the future when there is some
notion of how to preload style module script or json module scripts this
API will be extended to support those as well.
##### Arguments
1. `href: string` -> the href or src value you want to preload.
2. `options?: {...}` ->
2.1. `options.as?: string` -> the `as` property the modulepreload link
should render with. If not provided it will be omitted which will cause
the modulepreload to be treated like a script module
2.2. `options.crossOrigin?: string` -> modules always load with CORS but
you can provide `use-credentials` if you want to change the default
behavior
2.3. `options.integrity?: string` -> an integrity hash for subresource
integrity APIs
##### Rendering
each preloaded module will emit a `<link rel="modulepreload" href="..."
/>`
if `as` is specified and is something other than `"script"` the as
attribute will also be included
if crossOrigin or integrity as specified their attributes will also be
included
During SSR these script tags will be emitted before content. If we have
not yet flushed the document head they will be emitted there after
things that block paint such as font preloads, img preloads, and
stylesheets.
On the client these link tags will be appended to the document.head.
### Implements `ReactDOM.preinitModule()`
`preinitModule` is a function to loading module scripts before they are
required. It has the same use cases as `preinit`.
During SSR you would use this to tell the browsers to start fetching
code that will be used without having to wait for bootstrapping to
initiate module fetches.
ON the client you would use this to start fetching a module script early
for an anticipated navigation or other event that is likely to depend on
this module script.
the `as` property for Float methods drew inspiration from the `as`
attribute of the `<link rel="preload" ... >` tag but it is used as a
sort of tag for the kind of thing being targetted by Float methods. For
`preinitModule` we currently only support `as: "script"` and this is
also the assumed default type so you current never need to specify this
`as` value. In the future `preinitModule` will support additional module
script types such as `style` or `json`. The support of these types will
correspond to [Module Import
Attributes](https://github.com/tc39/proposal-import-attributes).
##### Arguments
1. `href: string` -> the href or src value you want to preinitialize
2. `options?: {...}` ->
2.1 `options.as?: string` -> only supports `script` and this is the
default behavior. Until we support import attributes such as `json` and
`style` there will not be much reason to provide an `as` option.
2.2. `options.crossOrigin?: string`: modules always load with CORS but
you can provide `use-credentials` if you want to change the default
behavior
2.3 `options.integrity?: string` -> an integrity hash for subresource
integrity APIs
##### Rendering
each preinitialized `script` module will emit a `<script type="module"
async="" src"...">` During SSR these will appear behind display blocking
resources such as font preloads, img preloads, and stylesheets. In the
browser these will be appende to the head.
Note that for other `as` types the rendered output will be slightly
different. `<script type="module">import "..." with {type: "json"
}</script>`. Since this tag is an inline script variants of React that
do not use inline scripts will simply omit these preinitialization tags
from the SSR output. This is not implemented in this PR but will appear
in a future update.
This adds an experimental `unstable_postpone(reason)` API.
Currently we don't have a way to model effectively an Infinite Promise.
I.e. something that suspends but never resolves. The reason this is
useful is because you might have something else that unblocks it later.
E.g. by updating in place later, or by client rendering.
On the client this works to model as an Infinite Promise (in fact,
that's what this implementation does). However, in Fizz and Flight that
doesn't work because the stream needs to end at some point. We don't
have any way of knowing that we're suspended on infinite promises. It's
not enough to tag the promises because you could await those and thus
creating new promises. The only way we really have to signal this
through a series of indirections like async functions, is by throwing.
It's not 100% safe because these values can be caught but it's the best
we can do.
Effectively `postpone(reason)` behaves like a built-in [Catch
Boundary](https://github.com/facebook/react/pull/26854). It's like
`raise(Postpone, reason)` except it's built-in so it needs to be able to
be encoded and caught by Suspense boundaries.
In Flight and Fizz these behave pretty much the same as errors. Flight
just forwards it to retrigger on the client. In Fizz they just trigger
client rendering which itself might just postpone again or fill in the
value. The difference is how they get logged.
In Flight and Fizz they log to `onPostpone(reason)` instead of
`onError(error)`. This log is meant to help find deopts on the server
like finding places where you fall back to client rendering. The reason
that you pass in is for that purpose to help the reason for any deopts.
I do track the stack trace in DEV but I don't currently expose it to
`onPostpone`. This seems like a limitation. It might be better to expose
the Postpone object which is an Error object but that's more of an
implementation detail. I could also pass it as a second argument.
On the client after hydration they don't get passed to
`onRecoverableError`. There's no global `onPostpone` API to capture
postponed things on the client just like there's no `onError`. At that
point it's just assumed to be intentional. It doesn't have any `digest`
or reason passed to the client since it's not logged.
There are some hacky solutions that currently just tries to reuse as
much of the existing code as possible but should be more properly
implemented.
- Fiber is currently just converting it to a fake Promise object so that
it behaves like an infinite Promise.
- Fizz is encoding the magic digest string `"POSTPONE"` in the HTML so
we know to ignore it but it should probably just be something neater
that doesn't share namespace with digests.
Next I plan on using this in the `/static` entry points for additional
features.
Why "postpone"? It's basically a synonym to "defer" but we plan on using
"defer" for other purposes and it's overloaded anyway.
This is mostly to test that the new configuration skips the Rust CI step if
there are no rust changes - yay, that worked! But also worth mentioning in the
readme so lets land.
Adds name resolution support for class declarations and expressions. Mostly this
involves _not_ visiting some `Identifier` nodes that don't actually represent
variables. For example, method names don't introduce new variables (but if they
are computed, they may _refer_ to variables).
Adds an option to pass a list of known globals into the semantic analyzer so
that references to globals can be checked. As a follow-up we'll need to
distinguish between different types of semantic analysis errors, so that callers
which don't want to validate globals can ignore "unknown variable" reference
errors while still handling definite errors such as duplicate declarations.
Since we no longer have externally configured "process" methods, I just
inlined all of those.
The main thing in this refactor is that I just inlined all the error
branches into just `emitErrorChunk`. I'm not sure why it was split up an
repeated before but this seems simpler. I need it since I'm going to be
doing similar copies of this.
JavaScript has ~sane~ fun rules around where variables can be redeclared or not,
and which kinds of variables this applies to. Actually the rules are pretty
straightforward:
* `var` can be redeclared any number of times.
* In strict mode, other declarations cannot be redeclared within the same scope.
This implies that a `var` declaration cannot conflict with these other forms,
which must take into account hoisting. So you can't have a `var a; let a` in the
same scope, but you also can't have a `let a` at a scope and then a `var a`
which will hoist to that same scope.
The [temporal dead
zone](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/let#temporal_dead_zone_tdz),
often abbreviated TDZ, is the period between the start of its declaring block
and the line that contains the let/const/class declaration. Not all instances of
TDZ can be detected statically, because whether or not a TDZ error will occur at
runtime is a property of which control flow path is taken and whether some other
code has initialized the value. However, a subset of cases can be detected, and
that's what we implement here.
When we encounter a variable reference we record the next declaration id at that
point in time. Then when resolving references after visiting the program, we can
check: did the reference end up referring to a let/const/class binding whose id
is equal or greater to that "next declaration"? If so, it means the reference
refers to a variable that is provably declared later and is a known TDZ
violation. The catch is that when resolving references, we reset the "next
declaration" limit value when we bubble up out of a function scope. That's
because references to let/const within a function may occur after the
declaration, and we can't statically validate them.
Previously we attempted to resolve each reference at the close of its defining
scope, and if it couldn't be resolved yet we bubbled the unresolved reference up
to the parent scope. That approach isn't ideal for two reasons:
* First, it's inefficient since we may have to make multiple attempts to resolve
the same reference.
* Second, it's incorrect. There can be cases where we think we can resolve a
reference to a value defined in an outer scope, but there is a hoisted
declaration from an intermediate scope that we haven't seen yet.
The safest and most optimal thing is to just queue all references and resolve
them at the end.
Rather than always create a Global scope and then immediately add a Module child
node, we now set the kind of the root scope to global (for scripts) or module
(for modules) based on the program node.
Teaches the semantic analyzer about import statements. We now treat imports as
declarations, so that subsequent references to the imported value can be
resolved.
Teaches the hermes->estree conversion to convert source ranges. This means our
diagnostics now point to the actual source of the error:
<img width="903" alt="Screenshot 2023-08-14 at 5 39 50 PM"
src="https://github.com/facebook/react-forget/assets/6425824/2960d114-0cc6-4531-9e7d-00ff3bfb1eb3">
Of course I still need to teach our semantic analysis about imports, but that's
a separate issue!
---
I added ~20 more tests to Sprout to get more of a feel for what the test
framework would need to support all fixtures. I'm relatively confident that the
approach outlined in [the original workplace
post](https://fburl.com/workplace/ftu8woch) works to migrate almost all existing
fixture tests to sprout (TLDR: use shared functions when possible, otherwise
write helper functions in-file).
Add `shared-runtime` file to reduce the amount of overhead needed to set up a
fixture test.
- All generalizable functions and values should be added here (e.g.
`shallowCopy`, `deepCopy`, `sum`).
- Editor integration is set up through a custom tsconfig, so importing from
`shared-runtime` should just work (with hover annotations, click-to-definition,
etc).
<img width="682" alt="Screenshot 2023-08-17 at 11 09 47 AM"
src="https://github.com/facebook/react-forget/assets/34200447/78c3dff9-ba10-4057-b3f6-2fa842d19b1d">
---
Tested new test fixtures added to sprout by adding them to `testfilter.txt` and
running with `--verbose --filter`.
Note that there are no unexpected exceptions, and all logs + returned values
match.
```
feifei0@feifei0-mbp babel-plugin-react-forget % yarn sprout:build && yarn sprout
--verbose --filter
yarn run v1.22.19
$ yarn workspace sprout run build
$ rimraf dist && tsc --build
✨ Done in 2.07s.
yarn run v1.22.19
$ node ../sprout/dist/main.js --verbose --filter
PASS console-readonly
ok {"a":1,"b":2} [
"{ a: 1, b: 2 }",
"{ a: 1, b: 2 }",
"{ a: 1, b: 2 }",
"{ a: 1, b: 2 }",
"{ a: 1, b: 2 }"
]
PASS constant-propagate-global-phis-constant
ok <div>global string 0</div>
PASS constant-propagate-global-phis
ok <div>global string 1</div>
PASS dce-loop
ok 10
PASS destructure-capture-global
ok {"a":"value 1","someGlobal":{}}
PASS destructuring-mixed-scope-and-local-variables-with-default
ok {"media":null,"allUrls":["url1","url2","url3"],"onClick":"[[ function
params=1 ]]"}
PASS holey-array-expr
ok [null,"global string 0",{"a":1,"b":2}]
PASS infer-global-object
ok {"primitiveVal1":2,"primitiveVal2":null,"primitiveVal3":null}
PASS infer-phi-primitive
ok 1
PASS infer-types-through-type-cast.flow
ok 4
PASS issue933-disjoint-set-infinite-loop
ok [2]
PASS jsx-tag-evaluation-order-non-global
ok <div>StaticText1<div>StaticText2</div></div>
PASS jsx-tag-evaluation-order
ok <div>StaticText1string value 1<div>StaticText2</div></div>
PASS method-call
ok 4
PASS mutable-lifetime-loops
ok {"a":{"value":6},"b":{"value":5},"c":{"value":4},"d":{"value":6}}
PASS mutable-lifetime-with-aliasing
ok {"b":[{}],"value":[{"c":{},"value":"[[ cyclic ref *0 ]]"},null]}
PASS update-expression-in-sequence
ok [4,2,3,4]
PASS update-expression-on-function-parameter
ok [4,1,4,2,4,3,1,4,4]
PASS update-expression
ok {"x":1,"y":1,"z":2}
PASS useMemo-multiple-if-else
ok 2
20 Tests, 20 Passed, 0 Failed
✨ Done in 4.11s.
```
---
This PR is an example of how to update fixture to add sprout annotations.
Running with `yarn sprout --verbose --filter` shows the fixture outputs.
```
PASS array-access-assignment
ok [[2],[[2],[],[3]]]
PASS array-expression-spread
ok [0,1,2,3,null,4,5,6,"z"]
PASS array-map-frozen-array
ok [[],[]]
PASS array-map-mutable-array-mutating-lambda
ok [[],[]]
PASS array-pattern-params
ok [{"a":"val1"},{"b":"val2"}]
PASS array-properties
ok {"a":[[1,2],2,"hello"],"x":3,"y":"[[ function params=1 ]]","z":"[[ function
params=1 ]]"}
PASS array-property-call
ok {"a":[1,2,"hello",42],"x":4,"y":1}
PASS assignment-expression-computed
ok [7]
PASS assignment-expression-nested-path
ok {"b":{"c":6}}
PASS capturing-func-mutate-2
ok {"a":2}
PASS capturing-function-alias-computed-load-2
ok "val2"
PASS capturing-function-alias-computed-load-4
ok "val2"
```
---
Rename `SproutOnlyFilterTodoRemove.ts` to `SproutTodoFilter.ts`. I've tried to
group the skipped fixtures by difficulty and add comments about what need to be
done, also happy to change the structure of this.
From this point, sprout will run on all new fixtures by default. If the fixture
forgets to export a `FIXTURE_ENTRYPOINT`, sprout will fail with this error.
<img width="853" alt="Screenshot 2023-08-15 at 5 59 32 PM"
src="https://github.com/facebook/react-forget/assets/34200447/0f80d650-1dc1-4df4-9710-e49acbb424b0">
See #1961 for an example of how to annotate existing skipped fixtures or new
ones. The `README.md` is also updated with a guide.
---
```
yarn sprout --verbose
```
Verbose mode prints out all outputs of tests. The test output is a status (`ok`
or `exception`), a returned or thrown value, and a set of console logs.
Currently as of #1960 , this is the output:
```sh
$ yarn workspace babel-plugin-react-forget run build && node
../sprout/dist/main.js --verbose
$ rimraf dist && tsc
PASS alias-nested-member-path
ok {"y":{"z":[]}}
PASS assignment-variations-complex-lvalue
ok {"y":{"z":4}}
PASS assignment-variations
ok 1
PASS chained-assignment-expressions
ok {"z":null}
PASS computed-call-evaluation-order
ok {"f":"[[ function params=0 ]]"} [
"A",
"B",
"arg",
"original"
]
PASS const-propagation-into-function-expression-primitive
ok 42 [
"42"
]
PASS constant-propagation-for
ok 0
PASS constant-propagation-while
ok 0
PASS constant-propagation
ok -6 [
"foo"
]
PASS controlled-input
ok <input value="0">
PASS do-while-continue
ok [1.5,1,0.5]
PASS do-while-simple
ok [6,4,2]
PASS expression-with-assignment
ok 5
PASS for-of-break
ok []
PASS for-of-conditional-break
ok []
PASS for-of-continue
ok [0.5,1,1.5]
PASS for-of-destructure
ok [0,2,4]
PASS for-of-simple
ok [0,2,4]
PASS function-declaration-reassign
ok {}
PASS function-declaration-redeclare
ok "[[ function params=0 ]]"
PASS lambda-reassign-primitive
ok 41
PASS lambda-reassign-shadowed-primitive
ok {}
PASS property-call-evaluation-order
ok {"f":"[[ function params=0 ]]"} [
"A",
"arg",
"original"
]
PASS reactive-scope-grouping
ok {"y":[{}]}
PASS sequentially-constant-progagatable-if-test-conditions
ok "ok"
PASS simple-function-1
ok "[[ function params=1 ]]"
PASS ssa-complex-multiple-if
ok
PASS ssa-complex-single-if
ok
PASS ssa-for
ok 11
PASS ssa-if-else
ok
PASS ssa-objectexpression-phi
ok {"x":1,"y":3}
PASS ssa-property-call
ok {"x":[[]]}
PASS ssa-property
ok {"x":[]}
PASS ssa-return
ok 2
PASS ssa-simple-phi
ok
PASS ssa-simple
ok
PASS ssa-single-if
ok
PASS ssa-switch
ok
PASS ssa-throw
exception undefined
PASS ssa-while
ok 10
PASS type-field-load
ok 1
PASS type-test-field-store
ok {}
PASS type-test-primitive
ok 2
PASS update-expression-constant-propagation
ok {"a":0,"b":0,"c":2,"d":2,"e":0}
44 Tests, 44 Passed, 0 Failed
✨ Done in 9.27s.
```
---
Not sure why, but snap kept silently crashing when I used fs/promises to write
to many file handles. I tried a `.catch(...)`, but couldn't figure it out. This
diff changes snap to use sync fs apis to avoid crashes, but I'd love to get
feedback if someone knows how to debug this.
This PR moves the phi evaluation to a separate function.
Most importantly, it inverts the default case to _not_ constant propagate unless
we have explicit validation of the phi operands.
---
## Sprout 🌱 Overview
**(Overview copied from
[sprout/README.md](0468ddf8bb/forget/packages/sprout/README.md))**
React Forget test framework that executes compiler fixtures.
Currently, Sprout runs each fixture with a known set of inputs and annotations.
We hope to add fuzzing capabilities to Sprout, synthesizing sets of program
inputs based on type and/or effect annotations.
Sprout is currently WIP and only executes files listed in
`src/SproutOnlyFilterTodoRemove.ts`.
### Milestones:
- [✅] Render fixtures with React runtime / `testing-library/react`.
- [ ] Make Sprout CLI -runnable and report results in process exit code.
After this point:
- Sprout can be enabled by default and added to the Github Actions pipeline.
- `SproutOnlyFilterTodoRemove` can be renamed to `SproutSkipFilter`.
- All new tests should provide a `FIXTURE_ENTRYPOINT`.
- [ ] Annotate `FIXTURE_ENTRYPOINT` (fn entrypoint and params) for rest of
fixtures.
- [ ] Edit rest of fixtures to use shared functions or define their own helpers.
- [ ] *(optional)* Store Sprout output as snapshot files. i.e. each fixture
could have a `fixture.js`, `fixture.snap.md`, and `fixture.sprout.md`.
### Constraints
Each fixture test executed by Sprout needs to export a `FIXTURE_ENTRYPOINT`, a
single function and parameter set with the following type signature.
```js
type FIXTURE_ENTRYPOINT<T> = {
// function to be invoked
fn: ((...params: Array<T>) => any),
// params to pass to fn
params: Array<T>,
// true if fn should be rendered as a React Component
// i.e. returns jsx or primitives
isComponent?: boolean,
}
```
Example:
```js
// test.js
function MyComponent(props) {
return <div>{props.a + props.b}</div>;
}
export const FIXTURE_ENTRYPOINT = {
fn: MyComponent,
params: [{a: "hello ", b: "world"}],
isComponent: true,
};
```
---
## Implementation Details
- jest-worker test orchestrator (similar to Snap 🫰).
I chose to write a test runner instead of directly using Jest for flexibility
and speed.
- Sprout 🌱 currently runs much more code per fixture (2 babel transform
pipelines + 2 `exec(...)` than snap, so all scaling concerns apply.
- Sprout may need more customization in the future (e.g. fuzzing component
inputs, caching artifacts)
- We probably want to add snapshot files for Sprout, which is much easier with a
custom runner.
This is also one of the main reasons we wrote Snap. Jest consolidates all
external snapshots (i.e. non-inline snapshots) from a test into [a single
file](d0a006ffa9/forget/src/__tests__/__snapshots__/compiler-test.ts.snap).
This was painful mainly for rebasing changes, but also for small papercuts (e.g.
needing to run `yarn test -u` twice when deleting a fixture)
- Currently does not save output to snapshot file, but we can easily add this
later (i.e. each test would have a `.snap.md` and `.sprout.md` file)
- Supports filter mode (same testfilter.txt file as snap)
- Currently does not support watch mode. I expect that sprout's primary use will
be catching bugs in the PR / Github Actions phase. Can be changed if we need to
iterate on sprout output while developing.
- All tests are run with `react-test-renderer` to access the React Runtime,
which is needed for calls to `useMemoCache` (and other potential hooks).
- react-test-renderer required a mocked DOM, so I ~~used js-dom~~ did a terrible
js-dom hack to add document, window, and other browser globals to the
jest-worker globals, then exec the test code in the jest worker global.
I can clean this up later by bundling library code (e.g. react,
react-test-renderer) to not use `require(...)`, then calling `exec` on all "test
client code" in the js-dom mock global (instead of the real jest worker one)
- Tests marked `isComponent` need to return valid jsx or primitives. Values
returned by all other tests are converted to a string primitive via
JSON.stringify.
```sh
# install new dependencies to node_modules
$ yarn
$ cd forget/packages/babel-plugin-react-forget
$ yarn sprout:build && yarn sprout
PASS alias-nested-member-path
PASS assignment-variations-complex-lvalue
PASS assignment-variations
PASS chained-assignment-expressions
PASS computed-call-evaluation-order
PASS const-propagation-into-function-expression-primitive
PASS constant-propagation-for
PASS constant-propagation-while
PASS constant-propagation
...
✨ Done in 3.91s.
```
Nice find from @mofeiz, we weren't adding declarations for function params in
LeaveSSA. This caused us to hit an invariant for update expressions that updated
params which assumed that all named variables had a declaration. This is why
it's helpful to add invariants, it helps you find places where you violate them
:-)
Adds basic support for hoisting semantics: * Resolution of variable references
is _always_ deferred in case the correct binding hasn't been seet yet due to
hoisting. * Var and function declarations bubble to the appropriate scope
There are lots of subtleties that aren't implemented yet but these rules cover a
lot.
Stacked on #27223
When a script resource adopts certain props from a preload for that
resource the integrity prop was incorrectly getting assinged to the
referrerPolicy prop instead. This is now fixed.
stacked on #27222
When I initially developed Float I was trying to be extremely clever in
how to explain when there are mismatching Resource instances. I still
think that we should do some kind of validation here but I want to
implement something much simpler. In practice there are not many cases
where you would accidentally create the same resource twice but with
differing props. Since I am going to land `preloadModule` and
`preinitModule` soon and I want to avoid adding to the overly complex
dev validation there I am going to remove it now and add something later
that is simplified.
This is a precursor to adding support for hoisting in semantic analysis.
Previously when we encountered an unknown reference we immediately reported an
error. But hoisted variables may be referenced before they're defined, so we
don't know for sure when we see an unknown variable if its actually unbound or
not.
This PR adds the first part of hoistingn support: rather than immediately report
an error when encountering an unbound variable we store it in a list of
unresolved references on the current scope. As we close each scope we recheck
and see if the variable can now be resolved. If yes we record that, otherwise we
bubble up the unresolved reference to the parent scope (and try again there).
The next PR(s) will handle hoisting of `var` and other syntax to the apropriate
nearest scope boundary (function/module).
When updating the data model for operands from instruction indices to
identifiers, I forgot to rewrite terminal operands.Doing so required a refactor
to use the new BlockRewriter helper.
Data URI's in images can't effectively be preloaded (the URI contains
the data so preloading only duplicates the data in the stream. If we
encounter an image with this protocol in the src attribute we should
avoid preloading it.
Adds a `Destructure` instruction closely following the design of the TS-based
compiler. The main change is fairly small: the TS compiler doesn't support rest
spreads that are not identifiers, such as the `...y[]` in `const [x, ...[y]] =
z`. I added support for this in the Rust compiler.
`compileProgram` was getting complex, so this extracts some of the logic into
smaller functions. Additionally, the `try` block now only wraps the `compileFn`
generator from Pipeline, which means not accidentally catching other non-Forget
errors
imageSrcSet should have been srcSet when referencing an img tag.
imageSizes should have been sizes. This caused preloads for img tags
using srcSet and sizes to incorrectly render as having a href only,
dropping the srcSet and sizes part of the preload
Eventually we will treat images without `loading="lazy"` as suspensey
meaning we will coordinate the reveal of boundaries when these images
have loaded and ideally decoded. As a step in that direction this change
prioritizes these images for preloading to ensure the highest chance
that they are loaded before boundaries reveal (or initial paint). every
img rendered that is non lazy loading will emit a preload just behind
fonts.
This change implements a new resource queue for high priority image
preloads
There are a number of scenarios where we end up putting a preload in
this queue
1. If you render a non-lazy image and there are fewer than 10 high
priority image preloads
2. if you render a non-lazy image with fetchPriority "high"
3. if you preload as "image" with fetchPriority "high"
This means that by default we won't overrsaturate this queue with every
img rendered on the page but the earlier encountered ones will go first.
Essentially this is React's own implementation of fetchPriority="auto".
If however you specify that the fetchPriority is higher then in theory
an unlimited number of images can preload in this queue. This gives
users some control over queuing while still providing a good default
that does not require any opting into
Additionally we use fetchPriority "low" as a signal that an image does
not require preloading. This may end up being pointless if not using
lazy (which also opts out of preloading) because it might delay initial
paint but we'll start with this hueristic and consider changes in the
future when we have more information
Initial data types for `forget_reactive_ir`, which is the Rust analogue of
`ReactiveFunction` in the TS compiler. I'm renaming here for clarity, though
naming suggestions are very welcome!
Aligns the data model for `Instruction` closer to JS: * Adds an `lvalue:
IdentifierOperand` property (Identifier + Effect) * Changes rvalues from being a
reference to the definining instruction by instruction offset (InstrIx) to be
a variable reference (IdentifierOperand)
There are pros and cons to the previous offset-based approach. It's definitely
convenient to be able to jump directly to the instruction that defined an
operand value. However: * Many passes need to track things like basic
reassignments, which mean they need to build up mappings of IdentifierId to
some data. When all operands are IdentifierOperands, this can be a single
mapping. * It aligns closer to JS, which makes porting a bit easier.
But most of all: porting the `ReactiveFunction` data type — which is in tree
form - is non-trivial with the offset-based approach. As we map HIR to the tree
form, we'd have to remap every operand offset. Using identifiers for operands
simplifies this.
We can always revisit this design choice later.
After the previous PR we no longer depend on SWC for the critical path of
development/testing. Notably this unblocks adding support for the rest of the
language: the new `forget_hermes_parser` crate automatically converts Hermes
Parser's AST into our `forget_estree` format via codegen. Achieving full
language support with SWC would have required manually defining the remaining
conversions for the rest of the language.
Long-term we'll need to revisit how to integrate into SWC, and more generally
into setups build atop SWC such as Next.js's Turbopack-based build
configuration. But i'll delete for now since we don't depend on it for
iteration, it's slow to build, and requires us to opt-in to nightly Rust.
Replaces the use of SWC parser in the Forget fixture tests with Hermes Parser.
This includes aligning on a single type to represent JS Values and numbers
(combining semi-duplicated code from forget_hir and forget_estree) and adding
support for lowering babel-style
NumericLiteral/BooleanLiteral/StringLiteral/NullLiteral node types (since Hermes
Parser produces a mix of estree/babel node types)
Updates HIR builder to rely on the new semantic analysis instead of assuming
that the ast nodes will already have binding info attached. That was a stopgap
until we had our own name resolution :-)
Once this lands we can remove SWC and switch everything to forget_hermes_parser,
and also remove the non-spec Identifier.binding field (which stored the
temporary name resolution data).
Update links from the old documentation to the new version
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
I changed the links to get started with react from the old documentation
that is no longer being updated to the new one
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
This adds a regression test for a bug where, after a store mutation, the
updated data causes the shell of the app to suspend.
When re-rendering due to a concurrent store mutation, we must check for
the RootDidNotComplete exit status again.
As a follow-up, I'm going to look into to cleaning up the places where
we check the exit status, so bugs like these are less likely. I think we
might be able to combine most of it into a single switch statement.
Currently React attempts to prioritize certain preloads over others
based on their type. This is at odds with allowing the user to control
priority by ordering which calls are made first. There are some asset
types that generally should just be prioritized first such as fonts
since we don't know when fonts will be used and they either block
display or may lead to fallback fonts being used. But for scripts and
stylesheets we can emit them in the order received with other arbitrary
preload types.
We will eventually add support for emitting suspensey image preloads
before other resources because these also block display however that
implementation will look at which images are actually rendered rather
than simply preloaded.
Generally scripts should not be preloaded before images but if they
arrive earlier than image preloads (or images) the network (or server)
may be saturated responding to inflight script preloads and not
sufficiently prioritize images arriving later. This change marks the
preloaded bootstrap script with a `low` fetch priority to signal to
supporting browsers that the request should be deprioritized. This
should make the preload operate similar to async script fetch priority
which is low by default according to https://web.dev/fetch-priority/
Additionally the bootstrap script preloads will emit before
preinitialized scripts do. Normal script preloads will continue to be
prioritized after stylesheets
This change can land separatrely but is part of a larger effort to
implement elevating image loading and making script loading less
blocking. Later changes will emit used suspensey images earlier in the
queue and will stop favoring scripts over images that are explicitly
preloaded
Fixes: #27200
preloads for images that appear before the viewport meta may be loaded
twice because the proper device image information is not used with the
preload but is with the image itself. The viewport meta should be
emitted earlier than all preloads to avoid this.
this change moves the queue for the viewport meta to preconnects which
already has the right priority for this tag
Adds new instructions to accurately model UpdateExpression semantics, since
`x++` is un-intuitively not the same as `x = x + 1`. There are a few different
ways to model the combination of prefix/postfix and increment/decrement:
* One instruction for all combinations of prefix/postfix and
increment/decrement, eg 'UpdateExpression'
* Instructions for Increment/Decrement, each with a property to distinguish
prefix/postfix
* Instructions for Prefix/Postfix, each with aproperty to distinguish
increment/decrement.
I chose the latter, `PrefixUpdate` and `PostfixUpdate`, because it keeps the
number of new instructions minimal while keeping separate instructions for the
most important distinction: whether the result of the instruction is the value
before applying the operation or after. I'm open to suggestions about this
though.
A few quick notes:
* Constant propagation is supported but only for numbers (we don't support
bigint yet anyway)
* LeaveSSA needs to know about these instructions since their presence requires
making the original variable declaration Let, not Const.
* EnterSSA mapped lvalues before rvalues, which is out of order but didn't
previously matter. I just had to flip the order and everything worked.
The for loop over eachInstructionLValue already rewrites instr.lvalue: ```
for (const place of eachInstructionLValue(instr)) {
rewritePlace(place, rewrites); } ```
Adds semantic analysis support for normal `for` statements and for JSX. The main
catch with JSX is that there are a bunch of identifiers that we have to ignore
since they aren't variable references: jsx attribute names, namespace names, jsx
member expression properties, and closing elements.
Updates `estree` codegen to emit a Visitor trait (temporarily named `Visitor2`
since there is a hand-rolled one that some code is using). We use knowledge of
the grammar to only visit fields whose type is a Node or Enum, or an "object"
type that opts into being visitable. The latter is used for Function and Class.
This will make it much easier to write the semantic analyzer.
This is two things:
* A toy semantic analysis that handles a tiny subset of JS, including labeled
statements, labeled break/continue, and variable
declaration/reference/reassignment. This only exists as a way to prove out the
API for the more important bit:
* More importantly, this defines a data model for the semantic analysis results
and an API for building up the semantic analysis.
Subsequent diffs will replace the first bit (toy analysis impl), while keeping
the second part.
Fixes https://github.com/facebook/react/issues/26793.
I have received a constantly reproducible example of the error, that is
mentioned in the issue above.
When starting `Reload and Profile` in DevTools, React reports an unmount
of a functional component inside Suspense's fallback via
[`onCommitFiberUnmount`](3ff846d106/packages/react-devtools-shared/src/hook.js (L408-L413))
in
[`commitDeletionEffectsOnFiber`](https://github.com/facebook/react/blob/main/packages/react-reconciler/src/ReactFiberCommitWork.js#L2025),
but this fiber was never registered as mounted in DevTools.
While debugging, I've noticed that in timed-out case for Suspense trees
we only check if both previous fallback child set and next fiber
fallback child set are non-null, but in these recursive calls there is
also a case when previous fallback child set is null and next set is
non-null, so we were skipping the branch.
<img width="1746" alt="Screenshot 2023-07-25 at 15 26 07"
src="https://github.com/facebook/react/assets/28902667/da21a682-9973-43ec-9653-254ba98a0a3f">
After these changes, the issue is no longer reproducible, but I am not
sure if this is the right solution, since I don't know if this case is
correct from reconciler perspective.
---
Changes in `@enableOptimizeFunctionExpressions` caused a bug in the last Forget
sync to VR Store. The repro can be summarized to something like this:
```js
function foo() {
const x = true; // some constant or global
// Add some branching for type inference
// This can be a Logical expression as well (e.g. `4 || 5`)
if (...) { }
// In this HIR block, SSA inserts a `x$2 = phi(x$1, x$1)`.
// EliminateRedundantPhiNodes needs to rewrite all references of `x$2` to `x$1`
const accessXInLambda = () => x;
return accessXInLambda;
}
---
Revives e2e test infra from #587.
- All React component-like functions are compiled.
- `yarn jest` runs each e2e test twice (forget and no forget)
Github Actions is already running `yarn test`, which includes all jest tests
```
Run yarn test
yarn run v1.22.19
$ yarn workspaces run test
> babel-plugin-react-forget
$ yarn jest && yarn snap:build && yarn snap
$ tsc && jest
PASS main src/__tests__/Result-test.ts
PASS main src/__tests__/DisjointSet-test.ts
PASS e2e with forget src/__tests__/e2e/hello.e2e.js
PASS e2e no forget src/__tests__/e2e/hello.e2e.js
Test Suites:
[4](https://github.com/facebook/react-forget/actions/runs/5732016200/job/15534129231?pr=1881#step:8:5)
passed, 4 total
Tests: 23 passed, 23 total
Snapshots: 11 passed, 11 total
Time:
6.1[5](https://github.com/facebook/react-forget/actions/runs/5732016200/job/15534129231?pr=1881#step:8:6)3
s
```
Using an arena allocator can be faster, but it comes with several challenges:
* It requires tediously tagging nearly every value with a lifetime. Any function
that has to deal with arena-allocated data (which is every meaningful function)
ends up with a lifetime parameter. Bleh. We also have to thread the allocator
itself wherever we need to allocate, though this is less of a problem since
_most_ functions already need the Environment and we can store the allocator
there.
* There is not yet widespread support in the Rust ecosystem for using custom
allocators with custom data types. This means that things like HashMap/Set and
IndexMap/Set can't be arena allocated. This means that either we have to add
support to these data types (by upstreaming or forking) or just accept that
we're only partially using the arena allocator.
* Finally, `bumpalo`'s `Box` cannot be moved out of, which turns out to be an
annoying limitation that i've already had to work around several times.
In the end i'm not sure arena allocators are worth it at this stage of the
project. Relay Compiler has been successful without one, and other Rust-based
internal compilers get by without them too.
The current heuristic to check if setState is called in render is based on
whether the lambda containing the call to setState has a mutable range that got
extended. This doesn't seem to work in all cases so this validation needs a bit
more work before we can turn it on by default
This includes a fix where the HermesToBabelAdapter was incorrectly outputting a
`ClassMethod` instead of `ClassPrivateMethod` in certain scenarios. This was
causing issues with our eslint plugin as it would crash on any file containing
private methods because a malformed AST was formed.
There was a bug in our internal Hermes to Babel adapter which caused some
malformed AST to be constructed, which babel would then validate as being
incorrect. That bug was fixed, but we still have to add this plugin so that
private class methods can be parsed by babel.
Tested internally
Adds GitHub actions to build and test the Rust version of Forget on every commit
to main. I didn't enable this on PRs for now just to avoid slowing down other
folks, this seemed like a reasonable compromise while we're still in the
experimentation phase. I test locally, and CI will catch if I or anyone else
slips up.
Rejects unknown fields during deserialization of helper structs (which don't
have a `type` field). This would be super useful for AST `Node` types, too, but
that requires implementing a custom deserializer so i'm punting on that for now.
Adds more AST types to handle the full ES2021 spec. At least, in theory I
defined the schema correctly, and we'll have to just fix any bugs as we
encounter them.
Updates to use our own codegen'd `Serialize` implementation for AST node types.
Notably, this allows us to ensure that we always emit a `type` field, even when
the type is obvious from context (serde doesn't do this) and avoid
double-emitting `type` fields (which serde can do if you try to force a tag to
be emitted). We still use the Deserialize impl because it works fine for our
purposes.
Adds almost all the remaining AST types from ES2015 to `estree`, and updates the
swc->estree->hir conversions accordingly. In a few places i punted with a
`Diagnostic::todo()`.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
- Remove unused webpack 4 dependencies
## How did you test this change?
- Ran `yarn test --prod`
- Ran `yarn test`
## Related PRs:
- https://github.com/facebook/react/pull/26887
Ports InlineUseMemo to Rust, this is the only missing transform pass on the
pipeline up through constant propagation. I wanted to finish this so that we
could do benchmarking of the early phase of compilation. UseMemo does a bunch of
rewriting so it seemed worth comparing performance.
Included:
* Add swc -> estree and estree -> HIR conversions for arrow functions and call
expressions
* Add HIR definition for labeled terminals and call expressions
* Utility for inlining one function into another — note that this requires
remapping InstrIx operands since instruction indices will change. An alternative
would be to store all the instructions for both outer/inner functions in the
same array, in which case we wouldn't need to remap.
* Helpers for mutably iterating the operands of an instruction or terminal.
* The actual inline_use_memo() function. The overall logic is similar, i just
had to slightly shuffle the order of operations to satisfy the borrow checker.
Console warnings when running tests: ``` ts-jest[versions] (WARN) Version 5.1.3
of typescript installed has not been tested with ts-jest. ```
Our typescript version is ahead of what's supported in ts-jest. This PR updates
ts-jest to work with the latest typescript compiler.
This PR adds a Hole kind that can be present in both ArrayExpression and
ArrayPatterns.
This Hole type is not interesting for our inference passes and is skipped over
for all of the pipeline.
Forget doesn't understand the React namespace object and generates incorrect
code when compiling code that loads props from this namespace object.
This PR makes Forget bailout when we see a property load from React namespace
object.
Upgrades every dependency on `hermes-parser` and `prettier` to the versions that
we're using in the rest of our other codebases. Notably, these package versions
are necessary for our other codebases to make use of mapped types in Flow.
8d021e5d797c5ef3b4e18a0be735c04005f2ae7a configured `./forget` as a workspace
root, so these `yarn.lock` files in `app/*` and `packages/*` are no longer
relevant. This PR deletes them to reduce noise and confusion.
## Summary
Since we are enabling `useModernStrictMode` flag internally, to make
sure the internal testing of half StrictMode doesn't suddenly break,
this PR makes sure it also works with `useModernStrictMode` true.
## Test plan:
Manually set `useModernStrictMode` to true.
`yarn test ReactOffscreenStrictMode-test -r=www-modern --env=development
--variant=true`
`yarn test ReactStrictMode-test.internal -r=www-modern --env=development
--variant=true`
## Summary
This was not exposed as a dynamic flag in the build for facebook www. By
adding it, we'll be able to roll this out incrementally before cleaning
up this code altogether.
## How did you test this change?
`yarn build`
Before changes, `disableSchedulerTimeoutInWorkLoop` flag is not included
in ReactDOM-* build output for facebook www. Afterwards, it is included.
Ports `MergeConsecutiveBlocks` to Rust. This was a tricky one: as we iterate
through the blocks _if_ the block ends up being merged with its predecessor we
need to consume it and modify its predecessor block (ie, mutating two things
from the same data structure - shared mutation!). But if we _don't_ need to
merge, then we need to not drop the current block. Ie, we sort of need to
conditionally take ownership of the current block during iteration and put it
back.
I added a `BlockRewriter` helper type for this which has a helper to iterate
safely. It calls the iterator lambda, moving blocks one at a time into the
lambda. The lambda returns either `Keep(block)` to give the block back and keep
it or `Remove` to tell the rewriter to drop the block. Thanks to making the
Blocks data structure hold `Option<Box<BasicBlock>>` items, "moving" the block
actually just means nulling out the option and conceptually giving ownership of
the pointer to the callback - the data itself never moves.
This involved creating a custom `Blocks` wrapper type, which i had been putting
off doing. This cleans up a bunch of other logic around traversing blocks.
This PR adapts the `Diagnostic` type and helpers from Relay Compiler to Forget.
The main changes are:
* Removing some fields it doesn't seem we'll use for a while, if ever (like
machine-readable arbitrary key/value data)
* Switching from Relay Compiler's `Location` type to our SourceRange type
* Using the severity enum previously established in the `forget_build_hir`
crate, with Todo/Unsupported/InvalidSyntax/InvalidReact/Invariant variants
* Adding support for translating our `Diagnostic` into a `miette::Diagnostic` so
we can use miette's pretty printing
With the new Diagnostic type in place i updated the existing build_hir code to
use it and confirmed that the errors are now even nicer (when we attach extra
data to annotate labels):
<img width="860" alt="Screenshot 2023-07-14 at 3 10 00 PM"
src="https://github.com/facebook/react-forget/assets/6425824/9d29425a-938b-4872-b999-aa174a3c329a">
This addresses (or brings us closer to addressing) many of your comments on the
last diagnostics PR, @poteto!
Per the title, this updates the main readme file with a guide to contributing to
the Rust compiler, and ensures that we have a brief description of every crate
in local readme.md files. The `forget_hir` one is the most extensive and
describes the high-level design of the HIR.
I've primarily used what Cargo calls virtual workspaces, where the top-level
Cargo.toml just lists a bunch of packages and they each have their own
dependencies. This is fine, but i've noticed that more repos are using real
workspaces and they offer a bunch of benefits. You define the dependencies in
the top-level Cargo.toml and then can easily refer to them from multiple crates,
ensuring all the versions match up. It makes it easier to refer to other crates
in the workspace, too, because you define the path once at the root, then every
other crate can just say `forget_foo = { workspace = true }`.
I also renamed all the crates to be prefixed with `forget_`, in some cases
removing the redundant `hir` name, So `hir-optimization` became
`forget_optimization`, `hir-ssa` became `forget_ssa`. Also note the switch from
hyphenated names to underscores everywhere, since at the end of the day you have
to write the name with underscores in source code.
I also deleted the demo crate that i started with since we don't need it
anymore.
And finally, i added an explicit publish = false to all the crates just to
prevent mistakes.
This is a quick "good enough" first pass at computing function expression
context variables. It definitely needs to be overhauled, but it's enough to make
a lot of common cases work correctly.
First, this PR adds a hand-rolled Visitor trait for `estree`. Long-term that
should probably be code-generated, but there are some subtleties to it such as
the `visit_lvalue(callback)` helper which has to be wrapped around various calls
(or we need some other way to distinguish identifiers within lvalues from
identifiers within rvaluess). So for now it makes sense to hand-roll it until we
are more confident in exactly how it should work.
Given that visitor, i was able to port part of the existing
`gatherCapturedDeps()` to Rust with some modifications. Note that we assume
_something_ has run name resolution on the estree to match up identifiers to the
declaration they refer to. But we don't store information about parent scopes so
we can't walk up to check where things were defined. Instead we do the
following:
* Build up a list of all referenced identifiers
* Also build up a set of bindings defined in the function itself
* After visiting, filter our the first list to only include identifiers not
defined by the function itself, and to eliminate duplicates.
This covers the majority of cases: the most obvious gap is nested function
expressions though actually that should just work.
Updates eliminate_redundant_phis and constant_propagation to recurse into
function expressions. I also realized there was a bug in EliminateRedundantPhis
in which we wouldn't traverse into function expressions encountered after
finding a back edge, so i fixed that logic in both versions.
Updates `enter_ssa()` to recurse into function expressions. In the TS compiler
we use a single Builder instance and copy (references to) the function
expression's blocks into the builder. That type of sharing just does not play
nicely with Rust. But... we don't need to do that! We already know the context
variables of the function expression, so we can lookup each of them to find
their re-mapped identifier, and set that as the starting state for the entry
block of the function expression. That lets us use normal recursion and
otherwise not share any information between the outer and inner builders.
Of course to make this work we actually have to populate Function.context, but
the algorithm _should_ work.
Start of function expression support:
* Basic structure for representing function expressions in the HIR
* Printer support
* swc -> estree -> hir conversion for function expression _bodies_. Dependencies
and context are not handled yet.
Makes the same improvement to constant propagation in both the JS and Rust
versions. The core algorithm only populates phi variables if all operands have a
known value (no back edges) and all those values are the same: this allows us to
propagate constants in most cases and simply punts on handling propagating
values that are affected by loops. However, since we collapse if statements into
gotos when the test condition is a constant, there can be cases where a phi that
originally existed will be pruned out:
```
// bb0
let x1;
if (true) {
// bb1
x2 = 1;
} else {
// bb2
x3 = 2; // this block becomes unreachable
}
// bb3
x4 = phi(bb1: x2, bb2: x3); // this phi will get pruned s.t. x4 = x2 = 1
return x4;
```
However, the algorithm doesn't prune phis until _after_ applying constants, so
currently we would see this phi node w different inputs and not propagate a
constant for the final usage of x, even though it will clearly be `1`.
The change is to make constant propagation use fixpoint iteration, iterating so
long as terminals changed on the previous iteration. If no terminals change the
algorithm completes in a single pass, but if terminals do change then we update
phis and continue. As you can see from the new test case this allows us to find
arbitrary length sequences of values and terminals that can be pruned.
Ports constant propagation to Rust. The algorithm is broadly similar to the TS
version, and most of the differences come from the slightly different HIR data
model (operands are instruction indices not identifier ids). What this means is
that the Constants map that we build up is really only used for variables that
existed in the original program, and only comes into play with instructions like
LoadLocal and StoreLocal. Other instructions such as Binary just look up their
operands directly, ie they load the referenced instruction to check if both
left/right are primitives.
Note that with SSA form and the index-based operands we could actually get rid
of StoreLocal/LoadLocal completely, which would further simplify constant
propagation. However:
* we'd need to add a Phi instruction kind, not a big deal but it diverges even
more
* more importantly, it makes it super hard to implement LeaveSSA
That second point is a deal-breaker so unless someone has a great idea for how
to exit SSA form without having Load/Stores, let's keep them.
This is a nearly 1:1 port of EliminateRedundantPhis to Rust, the algorithm is
identical and all differences are superficial. There are few things missing (an
invariant instead of a panic in one place, recursing into function expressions)
but the Rust version is still going to end up shorter despite keeping all the
comments.
This is a first pass at porting EnterSSA to Rust. First pass in the sense that
it's hard to fully test it, and also in the sense that we'll likely figure out
even better ways to work w the HIR as we iterate. Oh and i didn't do recusing
into function expressions yet, since we can't even represent function
expressions yet, and that may require modifying the design a bit (though i have
an idea that i think will work, which is for the Builder to have an optional
parent. When we encounter a block with no predecessors, we check the parent. I
_think_ this will make all the borrowing "just work").
A few notes:
Rust's compilation model parallelizes and incrementally computes at the crate
granularity, so builds are faster if we split up our code into more but smaller
crates. Setting up a clean dependency graph can dramatically improve build
performance too. For example, to run the `fixtures` tests we can build `estree`
and `hir` in parallel, then once those build _all_ of our other crates can be
built in parallel until we get to `fixtures` which depends on the everything
else. The various passes don't have any build dependencies on each other so they
can build in parallel. Hence the new code for SSA stuff is in a separate
`hir-ssa` crate. We should similarly group other passes (approximately one crate
per folder in the babel-plugin-react-forget/src/ directory, eg SSA, Inference,
Optimization, etc).
Second, shared mutable ownership can be modeled in Rust but requires wrappers
such as `Rc<RefCell<>>`. It's generally more efficient and more idiomatic to
rethink the data model and algorithm. For EnterSSA, the Builder object holds a
reference into the HIR that it only ever reads, and the pass (which drives the
builder) also holds a reference into the HIR, which it mutates. The previous PR
split up Blocks and Instructions, and the value of that is more apparent in
`enter_ssa()`. The Rust equivalent of the builder holds a _shared_ (immutable)
reference to just the HIR's blocks, while the pass (driving the builder) holds a
_unique_ (mutable) reference to just the HIR's instructions. This lets us keep
the overall feel of the algorithm while keeping Rust happy.
Also note that the other change — to making operands be InstrIx indices into the
instructions array — means that the SSA logic is simpler. Most instructions
don't have to be visited at all, since they don't deal with loads/stores.
Terminals also don't need to be visited, since they reference instructions, not
identifiers. The Phi concept seems to just work too.
I also updated the printer to print predecessors and phis.
## Summary
`scheduler.yield` is entering [Origin Trial soon in Chrome
115](https://chromestatus.com/feature/6266249336586240). This diff adds
it to `SchedulerPostTask` when scheduling continuations to allow Origin
Trial participation for early feedback on the new API.
It seems the difference here versus the current use of `postTask` will
be minor – the intent behind `scheduler.yield` seems to mostly be better
ergonomics for scheduling continuations, but it may be interesting to
see if the follow aspect of it results in any tangible difference in
scheduling (from
[here](https://github.com/WICG/scheduling-apis/blob/main/explainers/yield-and-continuation.md#introduction)):
> To mitigate yielding performance penalty concerns, UAs prioritize
scheduler.yield() continuations over tasks of the same priority or
similar task sources.
## How did you test this change?
```
yarn test SchedulerPostTask
```
This change is motivated by starting to explore porting EnterSSA to Rust. It's a
good medium complexity pass and quickly demonstrates why a direct port of our
existing data model and algorithms won't work so well. For examples just these
first lines at the top of the transform create multiple references to the
function body/blocks:
58da89888e/forget/packages/babel-plugin-react-forget/src/SSA/EnterSSA.ts (L230-L231)
But more generally it's always felt wrong that instructions have an LValue that
isn't really used. So here i'm exploring making operands a newtype index into a
single instructions array (shared for the entire function), and using different
types for identifier references in SetLocal and LoadLocal. Incidentally this
also declutters the printed HIR quite a bit.
I'm not going to land this until i actually finish enter_ssa() and some other
passes. We definitely need to balance fidelity to the existing code (to
facilitate porting) with using idiomatic Rust (to facilitate porting in the
sense of not fighting the borrow checker).
This mode improves compilation and makes optimizations easier, let's make it the
default. I previously confirmed that enabling this mode didn't affect output
when synced internally, and I'll do that again before landing the PR.
I added this as a quick workaround, since we didn't support unused
logical/conditional expression statements. Now that we handle them we don't need
InstructionValue::ExpressionStatement anymore. I found this when porting our
lowering to Rust.
The previous PRs to make `estree` use codegen broke the swc->estree and
estree->hir conversions. This PR updates those conversions so everything builds
now.
The overall goal of this workstream is to have a Rust representation of ESTree
that we can use as the input and output of the compiler. In Rust environments we
can convert between the native AST of SWC or OXC and ESTree, and when invoked
from JavaScript we can serialize to/from ESTree-compliant JSON. Given that our
first target is to plug into a JS-based compilation toolchain, we need to have a
working serialization to/from ESTree JSON. The point of the codegen-based
`estree` crate is to allow us to model estree as ergonomic, idiomatic Rust (to
make consuming it in code easier) while also allowing us to serialize to/from
spec-compliant ESTree. This PR flushes out one remaining piece.
Updates our estree codegen to generate a custom `Deserialize` implementation
instead of using the derived one from serde. ESTree has some enums whose
variants are themselves enums, for example we have
```rust
enum ModuleItem {
ImportExportDeclaration(ImportExportDeclaration),
Statement(Statement),
}
enum ImportExportDeclaration { ... }
enum Statement { ... }
```
This sort of works with serde's derive implementation: you have to use the "tag"
representation for the inner enums, and an "untagged" representation for the
outer one (ModuleItem). The problem is that with an untagged representation,
serde doesn't know what type of data it's expecting. All it can do is go one by
one and try to parse the data as the first variant (eg ImportExportDeclaration)
then the next one (Statement) and fail when it gets to the end of the list. If
the data isn't valid for any reason, deserialization will fail with a "not a
valid ModuleItem" error. That's true but not helpful, especially if you're
developing estree, are confident that the input json is valid, and need to
figure out where you messed up the definition. It's also not helpful as an
end-user if you're not sure your input json is valid.
So this PR updates our codegen to emit a custom derive implementation that is
identical for both regular enums (like Statement) and recursive ones (like
ModuleItem). We first extract the tag to know what type the value is, then
deserialize exactly as that type. So in the above case, rather than have to
first try parsing every ModuleItem as an ImportExportDeclaration and then fall
through to statement, we just decode the tag (`type` in our case, for example
say it's an "ForStatement"), then deserialize directly as that type (eg, as
ForStatement), then wrap it in the enum variant (ModuleItem::Statement(...)).
For recursive enums like ModuleItem we add an extra wrapper as necessary.
The end result is that we get much more precise errors and deserialization is
more efficient: we always decode just the tag, then as exactly that type.
Note that our serialization is also not perfect right now, because we don't
always emit the `type` key. Serde only emits it when a value appears in an enum.
We can similarly generate custom serializers for all our types to always emit
the tag. That will be straightforward when it's necessary. The current PR was
more of a blocker, because it was really hard to figure out mistakes in the
estree definition given the ambiguous errors. Thanks to this PR we now get
precise errors along the lines of "unknown type `JSXElement`" which are easy to
resolve.
Uses the `syn` crate, which can parse various Rust syntax forms, to parse the
`type` field from json schema description. This allows us to describe complex
types like `"type": "Vec<Option<ArrayElement>>"` directly, rather than requiring
flags like nullable, plural, and nullable_item. The main flag that i'm keeping
is "optional", which is used to indicate when the field itself (not the value)
is optional.
Adds some parts of the ES2015 spec, such as imports and ForOfStatement. This is
enough to get a few more fixtures compiling. The last one uses JSX which I
haven't defined yet.
This is meant to replace the initial `estree` crate with a version that is
generated from a JSON description of ESTree. The idea is to make it easy to
experiment with slightly different representations to balance ergonomic usage of
the data at runtime with serialization compatible with ESTree spec. The JSON
schema looks like this (somewhat abbreviated):
```
{
// Objects are struct types that don't have a `type` and can't appear as an enum
variant
objects: {
Position: {
line: {type: "NonZeroU32"},
column: {type: "u32"}
},
...
},
// Nodes are struct types with a `type` and which can appear as enum variants
(statements, expressions, patterns, etc)
nodes: {
ArrayExpression: {
elements: {
type: "Expression",
plural: true,
nullable_item: true,
}
}
...
},
// Categories of nodes with multiple variants, represented as enums.
// Can be recursive, eg ForInit can be VariableDeclaration or Expression,
// where Expression is also an enum
enums: {
Expression: [
"ArrayExpression",
...
]
},
// Simple enums which have a corresponding string value. Used primarily for
operators (binary/unary/logical/etc)
// but also for things like variable declaration kind (var/const/let)
operators: {
BinaryOperator: {
Plus: "+",
Instanceof: "instanceof",
}
}
}
```
The core estree files are now generated using Cargo's build script mechanism.
Right now i only defined the types and fields from ES5, so i'll have to flush
out the rest of the modern JS spec and extensions like JSX, TypeScript, and
Flow. But already the for-statement example works, showing that this approach
can handle complex cases such as unions of types or other unions (ForStatement
initializer is tricky bc it can be a VariableDeclaration or an Expression - that
works now!).
This is still WIP a bit - now that the ESTree definition is more precise i can
go back and clean up some other code (have to, because the swc -> estree
conversion needs some tweaks now).
Until now i've freely used `panic!`, `unwrap()`, and friends for "error
handling". This PR switches to consistently returning `Result` within the HIR
builder, using a structured error representation that exploits helpers from
`thiserror` and `miette` crates. Miette has a super graphical formatter for
diagnostics as you can see in the screenshot (also see the
[repo](https://docs.rs/miette/5.9.0/miette/index.html)).
This is just a first pass and we'll need to flush out the error handing story
more. Two obvious directions to go next:
* Make HIR construction error-tolerant, so that it can find as many errors as
possible at once rather than failing on the first error. We did this in Relay
Compiler as well, and we can likely borrow some of its helpers.
* Decouple from `miette`. It's very nice but less flexible than I'd like. We can
define our own more generic diagnostic type that contains structured data, then
have a generic conversion mechanism into a miette type so we can use their
display logic.
<img width="789" alt="Screenshot 2023-07-06 at 3 55 38 PM"
src="https://github.com/facebook/react-forget/assets/6425824/e1f1ed4b-5188-4af5-9af4-8f6c5c345023">
Implements support for `ForStatement` from swc -> estree -> hir, flushing out
more of the HIR representation and porting pieces from HIRBuilder as necessary.
We already did this for Server References on the Client so this brings
us parity with that. This gives us some more flexibility with changing
the runtime implementation without having to affect the loaders.
We can also do more in the runtime such as adding `.bind()` support to
Server References.
I also moved the CommonJS Proxy creation into the runtime helper from
the register so that it can be handled in one place.
This lets us remove the forks from Next.js since the loaders can be
simplified there to just use these helpers.
This PR doesn't change the protocol or shape of the objects. They're
still specific to each bundler but ideally we should probably move this
to shared helpers that can be used by multiple bundler implementations.
## Summary
as we began [discussing
yesterday](https://github.com/facebook/react/pull/27056#discussion_r1253282784),
`SuspenseList` is not actually stable yet, and should likely be exported
with the `unstable_` prefix.
the conversation yesterday began discussing this in the context of the
fb-specific packages, but changing it there without updating everywhere
else leads to test failures, so here the change is made across packages.
## How did you test this change?
```
yarn flow dom-browser
yarn test
```
When selecting a package variant from an export map we should favor node
over edge-light
edge-light represents a runtime with some minimal set of web apis
generally found across edge runtimes. However some environments might be
both edge-light compatible and node compatible and (node is adding many
web APIs) and when both conditions exist we want to favor the node
implementations. A followup to this change will add the web streams APIs
to Flight and Fizz so the node version exports the same interfaces for
web streams that edge does in addition to the node specific
implementations.
Fundamentally this PR is about lowering identifiers during construction of HIR.
For now i'm punting on context variables and assuming all variables are either
global, module-scoped, or locals. The implementation involves a few pieces:
* `estree::Identifer` gets extended with optional binding information. The idea
is that _some_ name resolution mechanism will populate this. Eventually our own,
but we can also borrow data from another source...
* `estree-swc` now configures SWC's (possibly broken?) name resolution mechanism
and sets the above binding data when translating identifiers from swc into our
estree format.
* hir `Builder` tracks identifiers based on `(name, BindingId)` pairs, and
assigns a unique `hir::Identifier` instance for each pair. `Identifiers` are
clone-able (shared).
* Tangential: i updated the printer to handle more instruction variants,
including the now-ported LoadGlobal instr.
I don't love this but it's a start. Long-term we definitely should have our own
name resolution mechanism which we run on the estree prior to lowering to HIR.
Implements a pretty-printer for the HIR and switches the fixture tests to use
this instead of the debug format. It's much more readable now!
Note that not all types are properly printed, I only implemented the
instructions and terminals used in the example. For others we fall back to the
Debug impl so we at least print something.
Adds a new `fixtures` crate intended for running end-to-end tests of the
compiler. As we expand the compiler this will eventually match our JS fixture
setup, where we have .js files as input and produce memoized JS output.
For now, this does the following:
* Parses with SWC (omg this was painful to setup)
* Runs SWC's name resolution, which annotates the SWC ast in-place
* Convert the SWC ast into our `estree` representation
* Convert `estree` into `hir` for each top-level function declaration in the
input program
* Print the Rust `Debug` view of the resulting HIR
As a next step i'll add a pretty-printer for the HIR to roughly match what we
have in JS.
Multiple Place instances can share a reference to a given Identifier in our JS
implementation. For simplicity of the initial port I’m using Rc (for sharing)
and RefCell (for runtime-checked mutability). This is the standard pattern for
shared mutable references in Rust when you don’t need multi-threaded support. We
don’t need HIR to be accessible by multiple threads so this is fine, if we do
multiple threads it will be to parallelize compilation of separate functions.
There are other idioms w less runtime overhead, such as Place holding an index
into a separate vec of identifiers, but that would make the port much less
straightforward.
Starts to port BuildHIR, in the Rust case this means the ESTree -> HIR
conversion. This necessitated flushing out the Builder struct a bit more. Mostly
the logic translates over very directly, and if anything it's cleaner because of
the lack of noise dealing with TypeScript unsoundness for Babel typedefs and
switch statements.
This is a start to porting HIRBuilder, with a largely complete implementation of
`build()`. Notably this includes all the passes which build() calls, and the
helper functions those passes call in turn:
```rust
reverse_postorder_blocks(&mut hir);
remove_unreachable_for_updates(&mut hir);
remove_unreachable_fallthroughs(&mut hir);
remove_unreachable_do_while_statements(&mut hir);
mark_instruction_ids(&mut hir)?;
mark_predecessors(&mut hir);
```
This was pretty straightforward. I ran into one borrow checker issue with (iirc)
`remove_unreachable_for_updates` where i needed to simultaneously hold a mutable
reference into the HIR (to write the ForTerminal) and also get an immutable
reference to check if the update block is reachable. The challenge is this:
```rust
for block in hir.blocks.values_mut() {
^^^^^^^^^^^^^^^^^^^^^^^ hir borrowed mutably here
if let TerminalValue::ForTerminal(terminal) = &mut block.terminal.value {
if let Some(update) = terminal.update {
if !hir.blocks.contains(&update) {
^^^^^^^^^^ borrowed immutably here
terminal.update = None;
^^^^^^^^ mutable borrow still active here (and also bc of the loop)
}
}
}
}
```
I quickly worked around this as we do in the other passes here by first building
a set of the block ids contained in the function (so that the
`hir.blocks.contains()` call becomes a call to the copied set of block ids).
An alternative would be to add a helper function for mutable iteration which
takes the desired value out of the data structure so that you can safely mutate
it and reference the rest of the HIR. Usage might look like this:
```rust
hir.blocks.each_mut(|mut block, hir| {
if let TerminalValue::ForTerminal(terminal) = &mut block.terminal.value {
if let Some(update) = terminal.update {
if !hir.blocks.contains(&update) {
terminal.update = None;
}
}
}
})
```
The lambda would receive the current `block` as a mutable reference, and for the
duration of the call `hir.blocks[block.id]` would be set to a sentinel value
that would crash if accessed. Meanwhile, `hir` would be a readonly reference to
the HIR, allowing the lambda to otherwise lookup information on the HIR but not
mutate it. This seems...kinda fine? But also not immediately necessary as
there's an easy and efficient-enough-workaround for the cases i've encountered
so far.
This is an initial translation of HIR (minus the ReactiveFunction bits). It's
mostly a straightforward translation. A few differences:
* Instead of Effect having an Unknown variant, we type `Place.effect:
Option<Effect>`. Maybe i'll revert that but it seems right.
* Terminal is divided into `Terminal { id: InstructionId, value: TerminalValue
}` and `enum TerminalValue { ... }`, so that we can reference the terminal's id
without caring about which kind of terminal it is.
* Each instruction value variant gets a named struct, whereas in JS we had lots
of anonymous InstructionValue variants.
* Rust generators are still an unstable nightly feature and likely to change
syntax enough that it seems safer not to rely on them. So
`eachTerminalSuccessor()` returns a `Vec<BlockId>`. If the perf of this is bad
enough we can switch to something like SmallVec (a popular crate) which stores a
few elements inline on the stack to optimize for small vecs (which our case
should be).
Perhaps more importantly, what's _not different_: I kept the existing approach
of BasicBlocks having a Vec of owned instruction instances, with
InstructionValue variant operands as Places rather than indices into a shared
instruction array. If this works out it will make porting straightforward.
However there's one aspect of this that is incorrect: right now each `Place`
owns its `Identifier`, whereas in JS the Identifier instances are shared mutable
references. I'll definitely need to refactor the data structures to allow
sharing Identifiers in some form, at which point we may want to change other
things too.
Start of an `estree` crate for representing ESTree with serialization to/from
ESTree JSON. To get the serialization to work quickly I took some shortcuts and
uses a slightly less precise modeling. Longer-term we can write some custom
serialization code and get more precise types (eg avoid the `ExpressionLike`
enum in favor of proper Expression and ExpressionOrFoo types).
## Summary
came across these TODOs – an internal grep indicated that remaining
callsites have been cleaned up, so these can now be removed.
## How did you test this change?
```
yarn flow dom-browser
yarn test
```
Hooks cannot be called in async functions, on either the client or the
server. This mistake sometimes happens when using Server Components,
especially when refactoring a Server Component to a Client Component.
React logs a warning at runtime, but it's even better to catch this with
a lint rule since it will show immediate inline feedback in the editor.
I added this to the existing "Rules of Hooks" ESLint rule.
lowerIdentifierForAssignment does extra checks such as checking if globals are
lvalues.
UpdateExpression lowers into an assignment and previously we missed out on such
checks.
I incorrectly included these as deps, we were only using these to verify
codegen. It seems fine to leave in but when I imported it internally vscode
would error, so just remove it
Adds a development warning to complement the error introduced by
https://github.com/facebook/react/pull/27019.
We can detect and warn about async client components by checking the
prototype of the function. This won't work for environments where async
functions are transpiled, but for native async functions, it allows us
to log an earlier warning during development, including in cases that
don't trigger the infinite loop guard added in
https://github.com/facebook/react/pull/27019. It does not supersede the
infinite loop guard, though, because that mechanism also prevents the
app from crashing.
I also added a warning for calling a hook inside an async function. This
one fires even during a transition. We could add a corresponding warning
to Flight, since hooks are not allowed in async Server Components,
either. (Though in both environments, this is better handled by a lint
rule.)
Modern runtimes support native async/await, as does the version of Node
we use for our tests. To match how most of our users run React, this
disables the transpilation of async/await in our test suite.
`unstable_batchedUpdates` shouldn't really be called on the server but
the semantics are clear enough and we can provide a trivial
implementation that calls the provided callback so we are adding it to
the server-rendering-stub.
This means we will also keep it around when we make the top level
react-dom exports match the server-rendering-stub in the next major
Suspending with an uncached promise is not yet supported. We only
support suspending on promises that are cached between render attempts.
(We do plan to partially support this in the future, at least in certain
constrained cases, like during a route transition.)
This includes the case where a component returns an uncached promise,
which is effectively what happens if a Client Component is authored
using async/await syntax.
This is an easy mistake to make in a Server Components app, because
async/await _is_ available in Server Components.
In the current behavior, this can sometimes cause the app to crash with
an infinite loop, because React will repeatedly keep trying to render
the component, which will result in a fresh promise, which will result
in a new render attempt, and so on. We have some strategies we can use
to prevent this — during a concurrent render, we can suspend the work
loop until the promise resolves. If it's not a concurrent render, we can
show a Suspense fallback and try again at concurrent priority.
There's one case where neither of these strategies work, though: during
a sync render when there's no parent Suspense boundary. (We refer to
this as the "shell" of the app because it exists outside of any loading
UI.)
Since we don't have any great options for this scenario, we should at
least error gracefully instead of crashing the app.
So this commit adds a detection mechanism for render loops caused by
async client components. The way it works is, if an app suspends
repeatedly in the shell during a synchronous render, without committing
anything in between, we will count the number of attempts and eventually
trigger an error once the count exceeds a threshold.
In the future, we will consider ways to make this case a warning instead
of a hard error.
See https://github.com/facebook/react/issues/26801 for more details.
This uses the same mechanism as [large
strings](https://github.com/facebook/react/pull/26932) to encode chunks
of length based binary data in the RSC payload behind a flag.
I introduce a new BinaryChunk type that's specific to each stream and
ways to convert into it. That's because we sometimes need all chunks to
be Uint8Array for the output, even if the source is another array buffer
view, and sometimes we need to clone it before transferring.
Each type of typed array is its own row tag. This lets us ensure that
the instance is directly in the right format in the cached entry instead
of creating a wrapper at each reference. Ideally this is also how
Map/Set should work but those are lazy which complicates that approach a
bit.
We assume both server and client use little-endian for now. If we want
to support other modes, we'd convert it to/from little-endian so that
the transfer protocol is always little-endian. That way the common
clients can be the fastest possible.
So far this only implements Server to Client. Still need to implement
Client to Server for parity.
NOTE: This is the first time we make RSC effectively a binary format.
This is not compatible with existing SSR techniques which serialize the
stream as unicode in the HTML. To be compatible, those implementations
would have to use base64 or something like that. Which is what we'll do
when we move this technique to be built-in to Fizz.
Currently, only the browser build exposes the `$$FORM_ACTION` helper.
It's used for creating progressive enhancement fro Server Actions
imported from Client Components. This helper is only useful in SSR
builds so it should be included in the Edge/Node builds of the client.
I also removed it from the browser build. We assume that only the Edge
or Node builds of the client are used
together with SSR. On the client this feature is not needed so we can
exclude the code. This might be a bit unnecessary because it's not that
much code and in theory you might use SSR in a Service Worker or
something where the Browser build would be used but currently we assume
that build is only for the client. That's why it also don't take an
option for reverse
look up of file names.
Currently, since we use a module cache for async modules, it doesn't
automatically get updated when the module registry gets updated (HMR).
This technique ensures that if Webpack replaces the module (HMR) then
we'll get the new Promise when we require it again.
This technique doesn't work for ESM and probably not Vite since ESM will
provide a new Promise each time you call `import()` but in the
Webpack/CJS approach this Promise is an entry in the module cache and
not a promise for the entry.
I tried to replicate the original issue in the fixture but it's tricky
to replicate because 1) we can't really use async modules the same way
without compiling both server and client 2) even then I'm not quite sure
how to repro the HMR issue.
We already support these in the sense that they're Iterable so they just
get serialized as arrays. However, these are part of the Structured
Clone algorithm [and should be
supported](https://github.com/facebook/react/issues/25687).
The encoding is simply the same form as the Iterable, which is
conveniently the same as the constructor argument. The difference is
that now there's a separate reference to it.
It's a bit awkward because for multiple reference to the same value,
it'd be a new Map/Set instance for each reference. So to encode sharing,
it needs one level of indirection with its own ID. That's not really a
big deal for other types since they're inline anyway - but since this
needs to be outlined it creates possibly two ids where there only needs
to be one or zero.
One variant would be to encode this in the row type. Another variant
would be something like what we do for React Elements where they're
arrays but tagged with a symbol. For simplicity I stick with the simple
outlining for now.
This PR contains a regression test and two separate fixes: a targeted
fix, and a more general one that's designed as a last-resort guard
against these types of bugs (both bugs in app code and bugs in React).
I confirmed that each of these fixes separately are sufficient to fix
the regression test I added.
We can't realistically detect all infinite update loop scenarios because
they could be async; even a single microtask can foil our attempts to
detect a cycle. But this improves our strategy for detecting the most
common kind.
See commit messages for more details.
## Summary
This PR cleans up `useMutableSource`. This has been blocked by a
remaining dependency internally at Meta, but that has now been deleted.
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
```
yarn flow
yarn lint
yarn test --prod
```
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
Suppose that you have this setup for devtools test:
```
// @reactVersion <= 18.1
// @reactVersion >= 17.1
```
With previous implementation, the accumulated condition will be `"<=
18.1" && ">= 17.1"`, which is just `">= 17.1"`, when evaluated. That's
why we executed some tests for old versions of react on main (and
failed).
With these changes the resulting condition will be `"<= 18.1 >= 17.1"`,
not using `&&`, because semver does not support this operator. All
currently failing tests will be skipped now as expected.
Also increased timeout value for shell server to start
- Made most static methods on CompilerError take a single options object as an
argument. With the exception of invariant which takes a condition and an options
object. - Added a new `suggestions` field on CompilerErrorDetail, which we'll
use to provide eslint suggestions - Updated eslint-plugin-react-forget to handle
suggestions
Most of these errors were incorrectly using InvalidInput as a catchall for
rejecting code. I went through each one and manually updated them to be more
accurate
In https://github.com/facebook/react/pull/26914 I added an extra logic
to turn off double useEffect if there is an `Offscreen`
tag. But `Suspense` uses `Offscreen` tag internally and that turns off
`disableStrictPassiveEffect` for everything.
## Summary
Running `yarn test --project devtools --build` currently skips all
non-gated (without `@reactVersion` directives) devtools tests. This is
not expected behaviour, these changes are fixing it.
There were multiple related PRs to it:
- https://github.com/facebook/react/pull/26742
- https://github.com/facebook/react/pull/25712
- https://github.com/facebook/react/pull/24555
With these changes, the resulting behaviour will be:
- If `REACT_VERSION` env variable is specified:
- jest will not include all non-gated test cases in the test run
- jest will run only a specific test case, when specified
`REACT_VERSION` value satisfies the range defined by `@reactVersion`
directives for this test case
- If `REACT_VERSION` env variable is not specified, jest will run all
non-gated tests:
- jest will include all non-gated test cases in the test run
- jest will run all non-gated test cases, the only skipped test cases
will be those, which specified the range that does not include the next
stable version of react, which will be imported from `ReactVersions.js`
## How did you test this change?
Running `profilingCache` test suite without specifying `reactVersion`
now skips gated (>= 17 & < 18) test
<img width="1447" alt="Screenshot 2023-06-15 at 11 18 22"
src="https://github.com/facebook/react/assets/28902667/cad58994-2cb3-44b3-9eb2-1699c01a1eb3">
Running `profilingCache` test suite with specifying `reactVersion` to
`17` now runs this test case and skips others correctly
<img width="1447" alt="Screenshot 2023-06-15 at 11 20 11"
src="https://github.com/facebook/react/assets/28902667/d308960a-c172-4422-ba6f-9c0dbcd6f7d5">
Running `yarn test --project devtools ...` without specifying
`reactVersion` now runs all non-gated test cases
<img width="398" alt="Screenshot 2023-06-15 at 12 25 12"
src="https://github.com/facebook/react/assets/28902667/2b329634-0efd-4c4c-b460-889696bbc9e1">
Running `yarn test --project devtools ...` with specifying
`reactVersion` (to `17` in this example) now includes only gated tests
<img width="414" alt="Screenshot 2023-06-15 at 12 26 31"
src="https://github.com/facebook/react/assets/28902667/a702c27e-4c35-4b12-834c-e5bb06728997">
## Summary
Overlooked when was working on
https://github.com/facebook/react/pull/26887.
- Added `webpack` packages as dev dependencies to `react-devtools-core`,
because it calls webpack to build
- Added `process` package as dev dependency, because it is injected with
`ProvidePlugin` (otherwise fails with Safari usage)
- Updated rule for sourcemaps
- Listed required externals for `standalone` build
Tested on RN application & Safari
For React Native environment, we sometimes spam the console with
warnings `"Could not find Fiber with id ..."`.
This is an attempt to fix this or at least reduce the amount of such
potential warnings being thrown.
Now checking if fiber is already unnmounted before trying to get native
nodes for fiber. This might happen if you try to inspect an element in
DevTools, but at the time when event has been received, the element was
already unmounted.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
We are upgrading React 17 codebase to React18, and `StrictMode` has been
great for surfacing potential production bugs on React18 for class
components. There are non-trivial number of test failures caused by
double `useEffect` in StrictMode. To prioritize surfacing and fixing
issues that will break in production now, we need a flag to turn off
double `useEffect` for now in StrictMode temporarily. This is a
Meta-only hack for rolling out `createRoot` and we will fast follow to
remove it and use full strict mode.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
jest
Found this while running Forget on the React tests.
This isn't a high priority because the ESLint plugin would've caught this. But
it'd be nice if either our validation rules caught this or if our compiler did
correctly eliminate the dep array.
This allows us to mimic the `invariant` api, which means you can just assert
that something holds true after execution proceeds to the next line without
throwing
These were effectively unused since we almost always passed in null when
creating errors, so remove them and instead pass in a `loc` explicitly. The
downside is that we no longer will see Babel codeframes in our test fixtures,
which doesn't seem like a huge loss
Fixes the mutable range validation in PrintHIR: when we checked the identifier
scope's range we failed to allow end=start=0 cases which are also valid.
While I was here, I created a separate assertion pass to check all ranges, that
way we aren't relying on the printer to validate them. The pass is on for
playground and tests, but disabled by default so it can't break internal apps.
Distinguishes between two types of "validation" passes:
- Passes which assert the validity of the HIR. These remain in HIR/ but are
renamed "assertFoo".
- Passes which validate that the user code is correct. These move to
Validation/.
Fixes#1751. Function ids can be plain strings, and we can refer to them as
globals rather than via a local identifier. In addition to the bug from $1751
this also cleans up an existing todo.
When we diffInCommitPhase there's no updatePayload, which caused no
update to be applied.
This is unfortunate because it would've been a lot easier to see this
oversight if we didn't have to support both flags.
I also carified that updateHostComponent is unnecessary in the new flag.
We reuse updateHostComponent for HostSingleton and HostHoistables since
it has a somewhat complex path but that means you have to remember when
editing updateHostComponent that it's not just used for that tag.
Luckily with the new flag, this is actually unnecessary since we just
need to mark it for update if any props have changed and then we diff it
later.
This is a fix specifically for the `enableOptimizeFunctionExpression` feature
(disabled by default). I tried running all of our fixtures with that flag on
everywhere, and this was the only issue. It's actually extracted from another
fixture which is more complicated, this is a distilled version. There were two
bugs:
* DCE was running after LeaveSSA when it needs to run before. Fixing the order
means code inside the function expression stops getting removed.
* In the feature flag, context variables share Identifier instances with the
surrounding code, whereas they are distinct instances without the feature. This
meant that mutable ranges from inside the function propagated outside the
function, throwing off our inference. The fix was to reset the ranges of context
variables after inferring the function expression's effects.
inference
Integrates the new inference to detect definitive mutations of context
variables. This allows us to more precisely infer mutable function expressions
and validate that they aren't passed where frozen values are expected.
New pass to infer context variables which are definitively mutated,
distinguishing from context variables which _may_ have been mutated. See the
code comment on the new pass for more details.
Small tweak necessary for the subsequent PRs, refs and ref values take
precedence over other mutations when computing the effect type of context
variables. We always want to record ref access within a function as capture
(since we have later validation) rather than a mutation. For now this has no
impact, either order records a Capture. But it allows later diffs to make
non-ref cases have other effects.
The original version of the code wasn't checking return values. I missed this
since my examples were passing functions _into_ the return value, as opposed to
return the functions directly. This revealed some existing test fixtures that
were technically invalid, but easy to fix by changing the return value.
In InferReferenceEffects, locations that are ConditionallyMutate are either
recorded as a Mutate or Read, which means we lose the distinction btw
conditional/unconditional mutation in later passes. This PR changes to remember
that these places were conditionally mutable, used in later analysis.
Defaults to false, ie it runs the codegen pass. When enabled it will simply run
all passes up to codegen and then skip over it. Naming of this option is copied
from [TypeScript](https://www.typescriptlang.org/tsconfig#noEmit) which has the
same named option that makes the compiler only perform typechecking.
I'm adding this option primarily to get around some issues running the eslint
plugin on Meta code. The plugin would error because Forget would report
duplicate Babel AST nodes, which I presume would only occur during codegen. It
should also make it a tiny bit faster to not run codegen, which is a nice plus.
This was causing some issues in the eslint plugin where the babel `hub` wasn't
defined. afaik the hub is only setup when running the plugin as part of a babel
pipeline, instead of a manual parse/traversal. We're using some of that infra
for printing codeframes
The existing errors thrown were marked as InvalidInput, which is now considered
critical. This was causing an error in the sync since we had 2 occurrences of
the errors being thrown. These are really todos and not invalid code.
For float methods the href argument is usually all we need to uniquely
key the request. However when preloading responsive images it is
possible that you may need more than one preload for differing
imagesizes attributes. When using imagesrcset for preloads the href
attribute acts more like a fallback href. For keying purposes the
imagesrcset becomes the primary key conceptually.
This change updates the keying logic for `ReactDOM.preload()` when you
pass `{as: "image"}`
1. If `options.imageSrcSet` is a non-emtpy string the key is defined as
`options.imageSrcSet + options.imageSizes`. The `href` argument is still
required but does not participate in keying.
2. If `options.imageSrcSet` is empty, missing, or an invalid format the
key is defined as the `href`. Changing the `options.imageSizes` does not
affect the key as this option is inert when not using
`options.imageSrcSet`
Additionally, currently there is a bug in webkit (Safari) that causes
preload links to fail to use imageSrcSet and fallback to href even when
the browser will correctly resolve srcset on an `<img>` tag. Because the
drawbacks of preloading the wrong image (href over imagesrcset) in a
modern browser outweight the drawbacks of not preloading anything for
responsive images in browsers that do not support srcset at all we will
omit the `href` attribute whenever `options.imageSrcSet` is provided. We
still require you provide an href since we want to be able to revert
this behavior once all major browsers support it
bug link: https://bugs.webkit.org/show_bug.cgi?id=231150
Some browsers, with some CSP configuration, will not preload a script if
the prelaod link tag does not provide a valid nonce attribute. This
change adds the ability to specify a nonce for `ReactDOM.preload(..., {
as: "script" })`
Turning off this flag makes only critical errors throw, so TODO errors will no
longer be surfaced by the plugin. The previously failing test for unsupported
syntax is now valid.
## Summary
- Updated `webpack` (and all related packages) to v5 in
`react-devtools-*` packages.
- I haven't touched any `TODO (Webpack 5)`. Tried to poke it, but each
my attempt failed and parsing hook names feature stopped working. I will
work on this in a separate PR.
- This work is one of prerequisites for updating Firefox extension to
manifests v3
related PRs:
https://github.com/facebook/react/pull/22267https://github.com/facebook/react/pull/26506
## How did you test this change?
Tested on all surfaces, explicitly checked that parsing hook names
feature still works.
## Summary
>Warning: Received NaN for the `children` attribute. If this is
expected, cast the value to a string.
Fixes this warning, when we try to display NaN as NaN in key-value list.
Follow up to #26932
For regular rows, we're increasing the index by one to skip past the
last trailing newline character which acts a boundary. For length
encoded rows we shouldn't skip an extra byte because it'll leave us
missing one.
This only accidentally worked because this was also the end of the
current chunk which tests don't account for since we're just passing
through the chunks. So I added some noise by splitting and joining the
chunks so that this gets tested.
Float types are currently spread out. this moves them to a single place
to ensure we properly handle the public type interface in all three
renderers.
This is a step towards moving the public interface and validation to a
common file shared by all three runtimes. Will also probably change the
function interface to be flatter
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn debug-test --watch TestName`, open
`chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Fix devtools cannot be shutdown by bridge.shutdown().
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
This introduces a Text row (T) which is essentially a string blob and
refactors the parsing to now happen at the binary level.
```
RowID + ":" + "T" + ByteLengthInHex + "," + Text
```
Today, we encode all row data in JSON, which conveniently never has
newline characters and so we use newline as the line terminator. We
can't do that if we pass arbitrary unicode without escaping it. Instead,
we pass the byte length (in hexadecimal) in the leading header for this
row tag followed by a comma.
We could be clever and use fixed or variable-length binary integers for
the row id and length but it's not worth the more difficult
debuggability so we keep these human readable in text.
Before this PR, we used to decode the binary stream into UTF-8 strings
before parsing them. This is inefficient because sometimes the slices
end up having to be copied so it's better to decode it directly into the
format. The follow up to this is also to add support for binary data and
then we can't assume the entire payload is UTF-8 anyway. So this
refactors the parser to parse the rows in binary and then decode the
result into UTF-8. It does add some overhead to decoding on a per row
basis though.
Since we do this, we need to encode the byte length that we want decode
- not the string length. Therefore, this requires clients to receive
binary data and why I had to delete the string option.
It also means that I had to add a way to get the byteLength from a chunk
since they're not always binary. For Web streams it's easy since they're
always typed arrays. For Node streams it's trickier so we use the
byteLength helper which may not be very efficient. Might be worth
eagerly encoding them to UTF8 - perhaps only for this case.
We were incorrectly calculating the dependencies of nested lambdas, because the
"component" scope was incorrectly set to the next closest parent rather than
outermost React function (component/hook) being compiled.
Follow up to #26827.
These can't include binary data and we don't really have any use cases
that really require these to already be strings.
When the stream is encoded inside another protocol - such as HTML we
need a different format that encode binary offsets and binary data.
## Summary
This is required for the case when we have an instance and want to get
inspector data for it. Such case occurs when RN's application being
debugged via React DevTools.
React DevTools sends instance to RN, which then gets all auxiliary data
to highlight some elements. Having `getInspectorDataForInstance` method
exposed makes it possible to easily get current props from fiber, which
then can be used to display some margins & paddings for hovered element
(via props.style).
I see that `getInspectorDataForInstance` is being exported at the top
level of the renderer, but feels like this should also be inside
DevTools global hook, the same way we use it for
[`getInspectorDataForViewAtPoint`](e7d3662904/packages/react-native/Libraries/Inspector/getInspectorDataForViewAtPoint.js).
This PR adds a new feature which enables additional validation/optimization of
function expressions, gated by the `enableOptimizeFunctionExpressions` feature
flag. When disabled, we actually revert the changes earlier in this stack, and
do all our lowering of function expressions in AnalyzeFunctions.
When the feature is enabled, we incrementally process function expressions in
the various compilation stages, eg InferTypes infers into function expressions,
ConstantPropagation propagates constants into function expressions, etc. Because
this stage optimizes function expressions, in this mode codegen uses the HIR as
the source rather than the original babel node.
The feature is disabled by default so it has no impact on generated code. For
now i've enabled the feature on just one test to demonstrate constant
propagation into a function expression.
Updates InferTypes to perform type inference across function boundaries.
Specifically InferTypes is now responsible for driving type inference of
function expressions (rather than deferring to AnalyzeFunctions to infer
functions), and type inference now traverses into function expressions and
infers types of free variables taking into account information from the outer
context. This relies on the fact that identifier ids are consistent across
function expression boundaries and that all free variables in functions are
guaranteed to be effectively `const`, since we promote non-const variables used
in function expressions to context variables.
Currently the process of lowering function expression bodies is deferred until
AnalyzeFunctions. However, per the motivation of the previous PR, we'd like to
be able to perform inference across function expression boundaries. To do that
we need to use consistent identifier ids across function expression boundaries.
This requires SSA conversion of function expressions at the same time as we
enter SSA.
To start, this PR moves MergeConsecutiveBlocks for function expressions into
that phase.
Generally we should reserve the `packages` directory for packages that
are needed to run the compiler, while `apps` is for frontends that might
make use of the compiler (and optionally, related packages)
This PR updates the conditions for which variables are promoted to context
variables.
The previous rule was to promote any variable where the variable was reassigned
in some function expression other than the function that declared the variable.
Notably, this meant that we did not use context variables for variables which
were captured in a function expression, but reassigned _outside_ a function
expression.
The new rule is more consistent: we promote any variable which is a) reassigned
somewhere and b) referenced in some function expression outside of their
declaring function. The implementation builds two sets of identifiers, one for
each criteria, then takes the union of these two sets.
## Motivation
The motivation for this change is to unblock additional validations and
optimizations of function expressions. It's currently difficult to translate
metadata that we infer about identifiers outside of a function expression into
metadata about the identifiers within a function expression — for example to
infer types within function expression bodies based on type information outside,
propagate constants into functions, infer reference effects, etc.
After this change, the only free variables inside function expressions will be
variables that are effectively `const` - never reassigned anywhere. Thus it will
be safe to renumber those identifiers to match the outer context (during
EnterSSA), making it trivial to map metadata from outside the function into the
function.
This change also more closely models the runtime representation — any variable
referenced in a function, and reassigned somewhere, would have to be compiled
(ie in a JS engine) to use a context variable.
The goal of this PR is to improve ValidateNoRefAccessInRender to find function
expressions which a) access refs and b) may be called during render. Currently
we always allow ref access in any function expression, but that's obviously
optimistic.
For the approach, the observation is that we already have a system that tells us
whether a function may get called — mutable range inference. So long as we
consider a function "mutable", we'll infer a range for it, but the problem is
that we don't currently view functions which depend on refs to be mutable. So
here I'm doing ~~sort of~~ a hack to force function deps on refs to be treated
as Effect.Capture. This is enough for the function to be considered mutable, for
a mutable range to be assigned, and for us to detect that during ref validation.
I don't love the hack, i'm open to other ideas!
---
- [patch] Find context variables within FunctionDeclarations (previously
missing)
- [todo] Need to fix non-allocating values / variables being DCE'd
One approach is to label everything referenced by a lambda as context variables.
I couldn't come up with other examples that break without this change, so I
wonder if something lighter / hackier works just as well. (My only hesitation is
that we may end up losing out on potential optimizations for everything aliased
to these variables).
---
(wip, waiting for feedback on workplace post)
- remove calls to `isInROMode`, as we want to log all mutations after 'freezing'
a value (both within and outside of render cycle)
- add `source` parameter -- this is the function name of the parent component /
hook
- Gating checks for debugging / profiling can be moved to within the
instrumentation or makeReadOnly functions. This simplifies codegen and reduces
code bloat.
- Warn if importing conflicting identifiers
- Aggregate imports from the same source
---
Emit calls to makeReadOnly for memoized values.
```js
function MyComponent() {
let x;
if (c_0) {
x = // ... (recompute x)
$[0] = __DEV__ ? makeReadOnly(x, "MyComponent") : x;
} else {
x = $[0]
}
}
```
- import source / specifier should be configurable, as
- we'll likely want to add gk gating to `makeReadOnly` itself to reduce codesize
bloat
- each Forget project needs different logging and filter configurations
- codegen function name as an argument for easier debugging
- only freeze memoized outputs

This is an attempt to scaffold yarn workspaces into our repo with as minimal as
possible changes to our current setup and directory structure. Essentially this
PR moves current `src` into `packages/babel-plugin-react-forget` as a first step
to keep everything working. Later on when we're ready we can split out a
`react-compiler` package that is decoupled from Babel, but it's too early for
that now
Not to get ahead of myself (sorry i had to), but i think this is the last order
of evaluation bug. At least it's the last one we know of[1]. Per the previous
PR, the issue is that constant propagation can copy the last value of a sequence
expression to where the sequence is used, leaving the original sequence
expression out of order after other instructions are moved around. We fix that
here by explicitly skipping constant propagation for the last value of a
sequence block.
[1] There are some places where we _would_ have evaluation order bugs if we
allowed arbitrary expressions, but we explicitly limit the expressions we allow
in those places. For the curious: switch test case values and destructuring
default values.
Changes the lowering for sequence expressions to use the new terminal. When
converting to a ReactiveFunction, we convert these terminals into
ReactiveSequenceValues, which nests the instructions and preserves order of
evaluation in the output.
The only catch is constant propagation — constant propagation breaks
order-of-evaluation because it can effectively copy the final value of a
sequence elsewhere, leaving the original sequence in the wrong place. I'll
address that in a follow-up.
I realized that we can use our value block system to fix _most_ of the remaining
order-of-evaluation issues we had with sequence expressions. This PR adds a new
SequenceTerminal to HIR; there is already a ReactiveFunction equivalent
(ReactiveSequenceValue) that the next PR will convert this terminal into.
Handles three more cases:
* Template literals
* deletion (property/computed)
* type casts
Only the latter has an observable impact, though i added tests for deletion just
in case and found a bug. For type casts, they're reasonably common internally
for fixmes, so this PR will help to ensure we don't drop type information just
because of a cast.
Renames some error fixtures for clarity, "error.invalid-*" are fixtures that are
expected to fail for invalid input, where other "error.*" fixtures are basically
todos. While i was here i clarified the error messages for invalid useMemo
callbacks, and changes the error severity from Invariant to InvalidInput.
Fixes one more category of bug. For assignment expressions, we validating
against redeclaring a global variable when the assignment target was an
identifier, but not when the global was reassigned via destructuring. This PR
adds a `lowerIdentifierForAssignment()` helper and uses it for assignment of all
identifier variants, including destructuring.
I reviewed the test cases we have marked as bugs ("_bug.*") and realized that
several of them are already fixed — woohoo! Then one wasn't fixed _yet_: our
type inference loses track of refs if you stash them inside an object/array. But
that's why I added the ValidateNoRefAccessInRender pass, which i've updated to
detect and reject these invalid cases. There are now only a few bugs left (more
fixes coming).
We currently support passing an XHR request to Flight for broader compat
and possibly better perf than `fetch()`. However, it's a little tricky
because ideally the RSC protocol is really meant to support binary data
too. XHR does support binary but it doesn't support it while also
streaming.
We could maybe support this only when you know it's going to be only
text streams but it has some limitations in how we can encode separators
if we can't use binary.
Nobody is really asking for this so we might as well delete it.
This isn't really meant to be actually used, there are many issues with
this approach, but it shows the capabilities as a proof-of-concept.
It's a new reference implementation package `react-server-dom-esm` as
well as a fixture in `fixtures/flight-esm` (fork of `fixtures/flight`).
This works pretty much the same as pieces we already have in the Webpack
implementation but instead of loading modules using Webpack on the
client it uses native browser ESM.
To really show it off, I don't use any JSX in the fixture and so it also
doesn't use Babel or any compilation of the files.
This works because we don't actually bundle the server in the reference
implementation in the first place. We instead use [Node.js
Loaders](https://nodejs.org/api/esm.html#loaders) to intercept files
that contain `"use client"` and `"use server"` and replace them. There's
a simple check for those exact bytes, and no parsing, so this is very
fast.
Since the client isn't actually bundled, there's no module map needed.
We can just send the file path to the file we want to load in the RSC
payload for client references.
Since the existing reference implementation for Node.js already used ESM
to load modules on the server, that all works the same, including Server
Actions. No bundling.
There is one case that isn't implemented here. Importing a `"use
server"` file from a Client Component. We don't have that implemented in
the Webpack reference implementation neither - only in Next.js atm. In
Webpack it would be implemented as a Webpack loader.
There are a few ways this can be implemented without a bundler:
- We can intercept the request from the browser importing this file in
the HTTP server, and do a quick scan for `"use server"` in the file and
replace it just like we do with loaders in Node.js. This is effectively
how Vite works and likely how anyone using this technique would have to
support JSX anyway.
- We can use native browser "loaders" once that's eventually available
in the same way as in Node.js.
- We can generate import maps for each file and replace it with a
pointer to a placeholder file. This requires scanning these ahead of
time which defeats the purposes.
Another case that's not implemented is the inline `"use server"` closure
in a Server Component. That would require the existing loader to be a
bit smarter but would still only "compile" files that contains those
bytes in the fast path check. This would also happen in the loader that
already exists so wouldn't do anything substantially different than what
we currently have here.
These are still quite Babel specific, but the interface is slightly more
generic: CompilerEntrypoint takes a non-Babel specific CompilerPass as an
argument instead of passing Babel's PluginPass directly.
In the future we can consider lowering the whole Program into HIR but that
involves a significant lift in our representation and a small amount of new
syntax to support (eg import statements), so this PR is the extent of this stack
for now
Currently we preload all scripts that are not hoisted. One of the
original reasons for this is we stopped SSR rendering async scripts that
had an onLoad/onError because we needed to be able to distinguish
between Float scripts and non-Float scripts during hydration. Hydration
has been refactored a bit and we can not get around this limitation so
we can just emit the async script in place. However, sync and defer
scripts are also preloaded. While this is sometimes desirable it is not
universally so and there are issues with conveying priority properly
(see fetchpriority) so with this change we remove the automatic
preloading of non-Float scripts altogether.
For this change to make sense we also need to emit async scripts with
loading handlers during SSR. we previously only preloaded them during
SSR because it was necessary to keep async scripts as unambiguously
resources when hydrating. One ancillary benefit was that load handlers
would always fire b/c there was no chance the script would run before
hydration. With this change we go back to having the ability to have
load handlers fired before hydration. This is already a problem with
images and we don't have a generalized solution for it however our
likely approach to this sort of thing where you need to wait for a
script to load is to use something akin to `importScripts()` rather than
rendering a script with onLoad.
We previously preloaded stylesheets that were rendered in Fizz. The idea
was we'd get a headstart fetching these resources since we know they are
going to be rendered. However to really be effective non-float
stylesheets need to rendered in the head and the preload here is not
helpful and potentially hurtful to perf in a minor way. This change
removes this functionality to make the code smaller and simpler
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
In StrictMode, React currently only triggers `componentWillUnmount` if
`componentDidMount` is defined. This would miss detecting issues like
initializing resources in constructor or componentWillMount, for
example:
```
class Component {
constructor() {
this._subscriptions = new Subscriptions();
}
componentWillUnmount() {
this._subscriptions.reset();
}
}
```
The PR makes `componentWillUnmount` always run in StrictMode.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
`yarn test ci`
## Overview
Does a few things:
- Renames `enableSyncDefaultUpdates` to
`forceConcurrentByDefaultForTesting`
- Changes the way it's used so it's dead-code eliminated separate from
`allowConcurrentByDefault`
- Deletes a bunch of the gated code
The gates that are deleted are unnecessary now. We were keeping them
when we originally thought we would come back to being concurrent by
default. But we've shifted and now sync-by default is the desired
behavior long term, so there's no need to keep all these forked tests
around.
I'll follow up to delete more of the forked behavior if possible.
Ideally we wouldn't need this flag even if we're still using
`allowConcurrentByDefault`.
stacked on #26753
Adds support for preloading bootstrapModules. We don't yet support
modules in Float's public interface but this implementation should be
compatible with what we do when we add it.
This PR adds a preload for bootstrapScripts. preloads are captured
synchronously when you create a new Request and as such the normal logic
to check if a preload already exists is skipped.
Updates PruneNonReactiveDependencies to treat setState functions as
non-reactive, since we know they have a stable identity. This is based on type
inference and our recently added definitions for useState and its return type,
so it's conservative and will only work when our inference can prove that the
scope dependency has the SetState type.
Note that this approach is simple and has limitations, notably the fact that the
setState is non-reactive doesn't propagate. But it's simple, trivially correct,
and already improves codegen somewhat, so i figured it's worth landing for now.
## Test Plan
Tested on internal app
Adds validation to reject freezing mutable lambdas, since lambdas cannot _be_
frozen, they're either frozen or not. Example invalid code:
```javascript
function Component(props) {
const x = {value: ""};
const onChange = (e) => {
// MUTATION!!!!!
x.value = e.target.value;
setX(x);
};
return <input value={x.value} onChange={onChange} />;
}
```
Note that there is a separate issue in which we are not detecting lambdas that
would definitely modify immutable values. We may need to distinguish
ConditionallyCapture (captures if the value is mutable, otherwise readonly) from
Capture (definitely mutates) in order to make that case work. But already this
validation helps prevent some invalid code.
Adds a `removeAllMemoization` flag that runs the entire compiler pipeline but
strips out all memoization. The intent is to be able to compare (in limited
use-cases) the performance of an existing app with all memoization removed, vs
the performance with manual memoization, vs the performance with Forget enabled.
In terms of how this works: we already strip out useMemo/useCallback since
Forget is more accurate. The new option adds an extra pass that strips out all
reactive scopes. Collectively this leaves ~zero memoization within components
(this does leave React.memo, but close enough).
clearContainer and clearSingleton both assumed scripts could be safely
removed from the DOM because normally once a script has been inserted
into the DOM it is executable and removing it, even synchronously, will
not prevent it from running. However There is an edge case in a couple
browsers (Chrome at least) where during HTML streaming if a script is
opened and not yet closed the script will be inserted into the document
but not yet executed. If the script is removed from the document before
the end tag is parsed then the script will not run. This change causes
clearContainer and clearSingleton to retain script elements. This is
generally thought to be safe because if we are calling these methods we
are no longer hydrating the container or the singleton and the scripts
execution will happen regardless.
---
Remove jest fixture tests in favor of snap runner. Main reasons:
- maintaining feature flags and compatible behavior required syncing all changes
to 3 files (`generateTestsFromFixtures`, `compiler-test`, and `compiler-worker`)
- jest snapshot test file causes rebase conflicts on most rebases
- speed 🙌
$ time yarn test compiler-test
(the extra test here is `has a consistent extension for input fixtures`)
```
Test Suites: 1 passed, 1 total
Tests: 37 skipped, 480 passed, 517 total
Snapshots: 479 passed, 479 total
Time: 27.668 s
Ran all test suites matching /compiler-test/i.
✨ Done in 43.18s.
yarn test compiler-test 57.05s user 3.85s system 139% cpu 43.546 total
```
$ time yarn snap
```
478 Tests, 478 Passed, 0 Failed
✨ Done in 13.12s.
yarn snap 53.96s user 9.35s system 468% cpu 13.518 total
```
Jest and snap should have the same set of features:
- report test failures via exit status (used by Git Actions)
- watch mode
- breakpoints + `debugger` statements
- note that `--sync` is not required for this
- skip `todo.` prefixed fixtures
- fixtures in nested directories e.g. `rules-of-hooks/testname.js`
- filter mode (via editing `testfilter.txt`)
- filter + debug mode
(1) edit `testfilter.txt` to filter out all but one test
(2) add `@debug` pragma to the first line of the test
testfilter.txt
```js
// @only
testfixture_basename1
testfixture_basename2
```
Turns out I just forgot to forward `process.env` when forking 😅
`debugger` statements and breakpoints should work with both `--sync` and
`--no-sync` (default) modes
This solves an issue where if you inject a hidden field in the beginning
of the form, we might mistakenly hydrate the injected one that was part
of an action.
I'm not too happy about how specific this becomes. It's similar to Float
but in general we don't do this deep comparison.
See https://github.com/vercel/next.js/issues/50087
There was a CircleCI bug that prevented the sizebot job from accessing
the artifacts API. I had added a temporary workaround to pull from a
mirror instead. This seems to have been fixed, so I can remove the
workaround.
With df12d7eac4 I accidentally made it so
that tests aren't run with the 2 variant modes for most
SchedulerFeatureFlags anymore. This fixes it with the same approach as
ee4233bdbc.
Test Plan:
Run and notice the boolean flags follow the variant:
```
yarn test-www --variant=true
yarn test-www --variant=false
```
This is the example we discussed in our design sync.
```javascript
function Component(props) {
const [x, setX] = useState({ value: "" });
const onChange = (e) => {
// INVALID! should use copy-on-write and pass the new value
x.value = e.target.value;
setX(x);
};
return <input value={x.value} onChange={onChange} />;
}
```
Here `onChange` is a mutable lambda, and it should be invalid to pass a mutable
lambda where a frozen value is expected. This is because unlike other value
types, you cannot freeze a lambda — the only choice is to not call it at all.
Note that there is a harder case to catch:
```js
function Component(props) {
const [x, setX] = useState({ value: "" });
const onChange = (e) => {
// INVALID! should use copy-on-write and pass the new value
x.value = e.target.value;
setX(x);
};
const x = constructAValueThatMaybeAliasesItsInput(onChange);
return <input value={x.value} onChange={x.maybeGetTheLambdaBack()} />;
}
```
This case demonstrates how mutable lambdas can be captured and then accessed
later — the analysis to catch this case is more sophisticated bc it involves
inferring that `x` aliases a mutable lambda. But we also can't be sure that `x`
does alias the lambda, so disallowing this code could prevent a lot of valid
code from compiling. My hypothesis is that we should start with at least
validating the example at the top, while allowing the second case for now.
We can now type `Array.prototype.{map,filter}`:
* The callee is ConditionallyMutable because, although the array itself is not
modified, its items flow into the lambda and may be modified there.
* The argument is ConditionallyMutable because it accepts both mutable and
immutable lambdas. Mutate would disallow immutable lambdas (wrong), while Read
would be incorrect for mutable lambdas since calling them triggers mutation.
Adds test cases to ensure we're correctly inferring mutative builtin operations
— property store, computed property store, property deletion, and computed
property deletion — as definite mutation and that we're rejecting inputs where
these operations are used on immutable/frozen values.
Adds back `Effect.Mutate`, and changes so that `Effect.ConditionallyMutate`
never rejects frozen/immutable values, while `Effect.Mutate` _always_ rejects
frozen/immutable values.
We currently use `Effect.Mutate` both for places that _may_ mutate (ie untyped
function calls) and for places that have known mutation (typed function calls,
or operations like `delete x.y`). We then use a separate mechanism to decide
whether to reject the input, with some call paths checking the effect and others
not.
This stack refactors this logic in InferReferenceEffects per our discussion, so
that `Effect.ConditionallyMutate` is for "may or may not mutate" either because
we're not 100% sure (untyped function) or because the mutation depends on the
operand (ie, a callback arg that will be invoked and thus will mutate if the
lambda is mutable, not mutate if the lambda is immutable). Later diffs add back
`Effect.Mutate` as "definitely 100% mutating".
Defines 4 new types:
* Return type of `useState()`, which has properties "0" and "1" to allow us to
infer the types when destructuring
* Type of useState() set state function
* Return type of `useRef()` so we know what is a ref
* Type of ref.current, so we know what is a ref *value*
Example:
<img width="1670" alt="Screenshot 2023-05-24 at 9 59 37 AM"
src="https://github.com/facebook/react-forget/assets/6425824/3ee7d04a-fda3-4b7b-89b7-d205d9a6fd0d">
---
Toggle default to true, since this should be a no-op refactor.
Tests:
- test fixtures
- ran on Store + - and saw no difference in compiled output
- [diff](P744101621) with
`enableTreatHooksAsFunctions=false`
- [diff](P744105565) with
`enableTreatHooksAsFunctions=true`
Currently when React generates rel=preload link tags for script/stylesheet resources, it will not carryover nonce and fetchpriority values if specified on the original elements.
This change ensures that the preload links use the nonce and fetchPriority values if they were specified.
…affiliates.
## Summary
There were 8 different places where the copyright comment was wrong.
Rewrote from "Copyright (c) Facebook, Inc. and its affiliates." to
"Copyright (c) Meta Platforms, Inc. and its affiliates."
## How did you test this change?
No code was changed. Comment was still a comment after changes.
Co-authored-by: Dennis Moradkhani <denmo530@student.liu.se>
## Summary
Changed the comment in react/packages/react
/react.shared-subset.js saying
```
Copyright (c) Facebook, Inc. and affiliates ..
```
To
```
Copyright (c) Meta Platforms, Inc. and affiliates ..
```
as raised in the following issues:
https://github.com/facebook/react/issues/26829
Files Changed:
react/packages/react/react.shared-subset.js
## How did you test this change?
Tests Required: No
Adds a new feature flag which tells the compiler to assume that hooks follow the
Rules of React. Specifically, the idea that since any hook could be wrapped in a
giant `useMemo()` call, all arguments to hooks have to be treated as if they're
owned by React — and therefore become immutable — and that the return value of
the hook is immutable.
Our default is to assume that hooks break the rules, but in practice nearly
every component follows them.
Updates the InferReferenceEffects logic for CallExpression to work similarly to
MethodCall, where we take into account the function signature (if present) when
inferring the effects and return kind.
Defines the `Boolean`, `String`, and `Number` global functions. This will be
useful for allowing developers to wrap statements that produce a primitive in a
way that Forget knows about in order to optimize better.
The bindings upstream in Relay has been removed so we don't need these
builds anymore. The idea is to revisit an FB integration of Flight but
it wouldn't use the Relay specific bindings. It's a bit unclear how it
would look but likely more like the OSS version so not worth keeping
these around.
The `dom-relay` name also included the FB specific Fizz implementation
of the streaming config so I renamed that to `dom-fb`. There's no Fizz
implementation for Native yet so I just removed `native-relay`.
We created a configurable fork for how to encode the output of Flight
and the Relay implementation encoded it as JSON objects instead of
strings/streams. The new implementation would likely be more stream-like
and just encode it directly as string/binary chunks. So I removed those
indirections so that this can just be declared inline in
ReactFlightServer/Client.
Handles some edge-cases where we previously flattened away some of the structure
of a labeled block, instead ensuring that we retain the original shape. See the
output.
## Test Plan
Tested on the internal app we're focused on (w useMemo inlining enabled), it
works fine.
I realized a wayyyy simpler approach to inlining a lambda: wrap it in a labeled
block. The transformation is roughly as follows:
```javascript
// Before
const x = useMemo(() => {
if (a) {
return b;
}
return c;
}, [a, b, c]);
return x;
// After
let x;
label: {
if (a) {
x = b;
break label;
}
x = c;
break label;
}
return x;
```
The key to making this work is fixing up some edge cases in labeled blocks,
hence the previous PRs.
This is part of a stack to fix some edge cases in inlining of useMemo closures.
In this first step, I'm disabling `shrink()` in order to retain more information
about the data flow. For example,
```
label: if (cond) {
break label;
}
return foo;
```
Would previously have shrunk away the if body, making the IfTerminal.consequent
point directly to the fallthrough block (w the return). Now we retain a separate
block.
- delete output files when we detect input files are deleted
- enable test fixtures in nested directories
- exit with error code when we detect failures
Note that the test failure on this PR is expected and will be fixed by #1608 (or
happy to abandon that PR and fold the changes)
---
Looks like we delete `.js` files but missed `.expect` files. Jest probably
didn't catch this because the basename of the fixtures had duplicates (in
rule-of-hooks)
---
(`react-forget-runtime` package seems to be synced to -.)
RFC: useRenderCounter hook:
- tracks # renders (increments on render path)
- exposes a global renderCounterRegistry (counting # renders in alive / mounted
components)
Next PR will modify BabelPlugin to add codegen
```js
// Similar to how we're currently importing `isForgetEnabled`
import {isInstrumentForgetEnabled_Secret} from "ReactForgetFeatureFlag";
// ...
function Component_uncompiled(props) {
if (isInstrumentForgetEnabled_Secret) {
useRenderCounter();
}
// ...
}
function Component_forget(props) {
if (isInstrumentForgetEnabled_Secret) {
useRenderCounter();
}
// ...
}
```
Now that the throttling mechanism applies more often, we've decided to
lower this a tad to ensure it's not noticeable. The idea is it should be
just large enough to prevent jank when lots of different parts of the UI
load in rapid succession, but not large enough to make the UI feel
sluggish. There's no perfect number, it's just a heuristic.
The throttling mechanism for fallbacks should apply to both their
appearance _and_ disappearance.
This was mostly addressed by #26611. See that PR for additional context.
However, a flaw in the implementation is that we only update the the
timestamp used for throttling when the fallback initially appears. We
don't update it when the real content pops in. If lots of content in
separate Suspense trees loads around the same time, you can still get
jank.
The issue is fixed by updating the throttling timestamp whenever the
visibility of a fallback changes. Not just when it appears.
I originally created a separate test for the mode with JSX memoization disabled,
but we can merge this into the main compiler-test and enable the feature with a
pragma.
Reverts #1502, but flips test flags (e.g. `inlineUseMemo` by default, unless a
test specifies `@inlineUseMemo false`. I figured this add less thrash for test
fixtures, but happy to just do a clean revert (or remove the pragma altogether
and always pass `inlineUseMemo: true`)
Previously, we'd call and use getSnapshot on the second render resulting
in `Warning: Text content did not match. Server: "Nay!" Client: "Yay!"`
and then `Error: Text content does not match server-rendered HTML.`.
Fixes#26095. Closes#26113. Closes#25650.
---------
Co-authored-by: eps1lon <silbermann.sebastian@gmail.com>
---
In `lower`, we now ensure that all context variables are declared by a
`DeclareContext` instruction. `DeclareContext` always produces a `let`
declaration, and `StoreContext` is always a reassign. There are a few reasons we
need `DeclareContext`:
- DeclareLocal assumes it is storing to a SSA-fied identifier (which always
stores an immutable primitive). This does not fit context variables.
- Without DeclareContext, we need custom logic in some passes to initialize
identifier / context state (e.g. `MutableRange`, ValueKind, etc) for the
`StoreContext` that declares the context.
This PR stack models context variables as concrete identifiers (with references
to context variables modeled by `Place` referencing the context variable
identifier). @josephsavona pointed out that this is abusing the notion of
Identifier/Place, as context variables are essentially interior properties of a
ContextEnvironment. Since we are not modeling `ContextEnvironment` implicitly or
explicitly, all inference for context variables is essentially pointer analysis.
---
This PR adds LoadContext and StoreContext to handle reading and writing to
context variables.
A context variable is any variable that is declared within a Forget-compiled
function and reassigned within a closure. Conceptually, we want to treat these
variables as attributes of a `EnvironmentContext` variable (as most javascript
VMs do).
- context variables currently do not participate in type inference (i.e. we do
not produce type equations for loads from context variables). In the future, we
can try typing this as `Phi(assignment1Type, assignment2Type, ...)`.
- context variables are always treated as `Effect.Mutable`.
- context variables do not participate in SSA, or certain optimizing passes
(e.g. dead code elimination, constant propagation, etc).
There is some still follow ups:
- From my understanding, we should introduce a `DeclareContext` instruction.
- currently, declaring a context variable (without initializing it) is broken.
This is because the declaration lowers to `DeclareLocal`, which assumes it is
storing to a SSA-fied identifier.
```js
let x;
x = 4;
() => { x = {}; };
```
- DeclareContext will also make some initialization logic easier. In this PR, I
added some hack-y code to handle initializing effects / mutable ranges / other
inference state for the first StoreContext.
- Handle or bail on stores to context variables through destructuring assignment
-
~~Next PR:~~
- ~~Change closures to track reassigned identifiers (to extend mutable range of
primitives)~~
## Summary
To support incremental adoption of bridgeless logic we want to default
to using these globals whenever they're available.
## How did you test this change?
https://github.com/facebook/react-native/pull/37410
## Summary
Initially reported in https://github.com/facebook/react/issues/26797.
Was not able to reproduce the exact same problem, but found this case:
1. Open corresponding codepen from the issue in debug mode
2. Open components tab of the extension
3. Refresh the page
Received multiple errors:
- Warning in the Console tab: Invalid renderer id "2".
- Error in the Components tab: Uncaught Error: Cannot add node "3"
because a node with that id is already in the Store.
This problem has occurred after landing a fix in
https://github.com/facebook/react/pull/26779. Looks like Chrome is
keeping the injected scripts (the backend in this case) and we start
backend twice.
Enables hooks validation in playground. Also adds a tab to show the output of
validation (in case it passes) with the inferred post dominator tree. We can use
this to debug the dominator in case of false negatives.
<img width="1724" alt="Screenshot 2023-05-11 at 11 07 08 AM"
src="https://github.com/facebook/react-forget/assets/6425824/8f7ae472-8415-4899-aedf-c8f26094ebfe">
Incorporates the fixtures from eslint-plugin-react-hooks using a script, so that
we can easily update them in the future. For each fixture we run the compiler
with and without hooks validation first so that we know if the fixture is
expected to pass — we have some false positives and false negatives that i can
work through. For example we accidentally think that `userFetch()` is a hook,
oops. Fixtures that should pass but error, or that should error but pass, are
marked as `todo.<name>` or `todo.error.<name>`.
While i was here i added the ability to have fixtures in subdirectories for
grouping purposes.
---
Try to fix bug from #1589:
> If a declaration for an immutable identifier (i.e. one that is not later
re-assigned, since undefined is a primitive) is sandwiched between mutations, we
currently do not record it as an output or hoist it out of the reactive scope.
One simple fix is to add all declared (and later referenced) identifiers as
declarations of a reactive scope. This has some undesired effects (e.g.
additional instructions + memo cache slots), but in practice, this shouldn't be
happening often.
Alternatively, we could 1.) add a pass to hoist declarations, 2.) account for
this in constant propagation, or 3.) add a bailout
---
Record incorrect output.
If a declaration for an immutable identifier (i.e. one that is not later
re-assigned, since `undefined` is a primitive) is sandwiched between mutations,
we currently do not record it as an output or hoist it out of the reactive
scope.
While optimizing per @josephsavona's suggestions in #1592, I noticed that we
were clearing quite a few require cache entries.
As of this PR, `Object.keys(require.cache)` holds
- 1258 entries total
- 67 files compiled from Forget source code (this is what
`ts.createWatchCompilerHost` modifies)
- 1120 babel source files (from node_modules)
When working on watch mode, I'm almost always making changes to Forget source or
test fixture files. It's a bit faster to just clear those entries (assuming that
babel has no global state we need to invalidate).
On my computer, re-running tests in watch mode (triggered by source code
changes) takes:
| | All tests | One test (filter) |
|-- |--------|----------|
| current | 4.7s | 1.8s |
| this PR | 1.8s | 0.1s |
---
Some typed functions need to annotate callees or arguments as `Effect.Store`.
This PR modifies alias analysis (`InferAliasForStores`) to account for this
When I was renaming the next channel to canary, I updated the
`publish_preleases` workflow correctly, but I skipped over
`publish_preleases_nightly`. Oops.
The idea is that the default `yarn test` command should be the one that
includes the most bleeding edge features, because during development you
probably want as many features enabled as possible.
That used to be `www-modern` but nowadays it's `experimental` because
we've landed a bunch of async actions stuff in experimental but it isn't
yet being tested at Meta.
So this switches the default to `experimental`.
Snap currently has a bug in which the require cache is not correctly cleared
when running in filter mode (#tests < 2 * #workers).
- We're currently clearing all entries in the require cache of worker threads,
including `jest-worker` and `snap/dist/...` files
- jest-worker seems to `require` these files on every dispatch (i.e.
`worker.compile` seems to call `require(`compiler-worker`).compile`)
I noticed some instances of this error when running forget on an internal
product. I previously fixed the case if a logical/conditional used only for side
effects (not assigned to a variable) but the new cases were assigned to an
unused variable. I double-checked and we’ve actually fixed all the steps after
these invariants so we can just remove them and support these cases.
When we calculate the dependencies of a FunctionExpression we were only adding
new items if the binding identifier had not been seen yet. That is correct for
`capturedIds` since its the set of identifiers, but incorrect for `capturedRefs`
since its an array of all the distinct places. This meant that if a function
expression referenced multiple properties of the same binding, we'd only record
the first one. We now correctly record all of them.
Just a small upgrade to keep us current and remove unused suppressions
(probably fixed by some upgrade since).
- `*` is no longer allowed and has been an alias for `any` for a while
now.
Tidies up the implementation a bit, splitting the single function and class into
distinct computeDominatorTree() and computePostDominatorTree() functions and
helper classes.
React will retry or abort components that throw (depending on a few conditions),
so from React's perspective a `throw` statement is not a normal exit node. Thus
the Rules of Hooks really have a caveat: the set of hooks that are called _in an
execution that returns successfully_ must be consistent. Examples such as the
following are therefore allowed:
```javascript
function Component(props) {
if (props.cond) {
throw new Error(...);
}
useHook();
}
```
By modeling `throw` as an exit node, we rejected cases such as this. This diff
changes to not model throws as exit nodes. #1584 changes this to make it an
option, since some cases will want to consider throw as an exit node.
Incorporates the fixtures from eslint-plugin-react-hooks using a script, so that
we can easily update them in the future. For each fixture we run the compiler
with and without hooks validation first so that we know if the fixture is
expected to pass — we have some false positives and false negatives that i can
work through. For example we accidentally think that `userFetch()` is a hook,
oops. Fixtures that should pass but error, or that should error but pass, are
marked as `todo.<name>` or `todo.error.<name>`.
While i was here i added the ability to have fixtures in subdirectories for
grouping purposes.
- The whole project root is included by default anyway, the include
section should be redundant and just misleading.
- The generated ignore paths ignore more than intended as they didn't
escape the `.` for regex.
Test Plan:
- wait for CI
- tested the ignore pattern change with renaming files and seeing the
expected files ignored for flow
See the code comments for more, but the basic idea here is that we use the post
dominator tree to find the set of basic blocks which are guaranteed reachable in
each function. Those are the only blocks where it is safe to call hooks, and we
error for hook calls in any other blocks.
Implements an efficient algorithm for computing the dominator (or post
dominator) tree of a CFG, following
https://www.cs.rice.edu/~keith/Embed/dom.pdf. This is used/tested in the next PR
to validate that hooks are called unconditionally.
note: I clean up the implementation quite a bit late in the stack in #1584
I noticed this while demoing Forget to React Org alum Christoph Nakazawa — in
array.map calls (and other APIs that take a lambda as input) we sometimes end up
memoizing the lambda. It's technically correct since the function _could_ return
the lambda, and then we'd need it to be memoized. It's tricky because array.map
is often called on nested objects, where even if we had type inference on the
outer value we wouldn't know for sure that the inner property is an Array and
not some other data type with a custom .map. For example in
`data.feedback.comments.edges.map(edge => ...)`, even if we knew that `data` was
an Object, we wouldn't know that data.feedback.comments.edges is an Array
without cross-file type knowledge.
But it's definitely wasteful to memoize these lambdas, so we should brainstorm
options. One option that stands out right away: if the lambda has zero
dependencies, then we could lift it out to module scope and refer to it by name.
Adds a validation pass to check that the only thing you can do with hooks is
call them. A follow-up PR (still early WIP) will check the other aspect of the
rules of hooks, that they are not called conditionally. That's a more involved
algorithm.
## Summary
We have a case:
1. Open components tab
2. Close Chrome / Firefox devtools window completely
3. Reopen browser devtools panel
4. Open components tab
Currently, in version 4.27.6, we cannot load the components tree.
This PR contains two changes:
- non-functional refactoring in
`react-devtools-shared/src/devtools/store.js`: removed some redundant
type castings.
- fixed backend manager logic (introduced in
https://github.com/facebook/react/pull/26615) to activate already
registered backends. Looks like frontend of devtools also depends on
`renderer-attached` event, without it component tree won't load.
## How did you test this change?
This fixes the case mentioned prior. Currently in 4.27.6 version it is
not working, we need to refresh the page to make it work.
I've tested this in several environments: chrome, firefox, standalone
with RN application.
This automatically exposes `$$FORM_ACTIONS` on Server References coming
from Flight. So that when they're used in a form action, we can encode
the ID for the server reference as a hidden field or as part of the name
of a button.
If the Server Action is a bound function it can have complex data
associated with it. In this case this additional data is encoded as
additional form fields.
To process a POST on the server there's now a `decodeAction` helper that
can take one of these progressive posts from FormData and give you a
function that is prebound with the correct closure and FormData so that
you can just invoke it.
I updated the fixture which now has a "Server State" that gets
automatically refreshed. This also lets us visualize form fields.
There's no "Action State" here for showing error messages that are not
thrown, that's still up to user space.
E.g. if we suspend (throw a promise) in pushStartInstance today we might
have already pushed some chunks (or even child segments potentially). We
should revert back to where we were.
This doesn't usually happen because when we suspend in a component it
doesn't write anything itself, it'll always defer to som host instance
to do the writing.
There was a todo about this already but I'm not 100% sure it's always
safe when suspending. It should be safe when suspending just regularly
because it's just a noop. We might not even want "throwing a promise" in
this mechanism to be supported longer term but for now that's how a
suspend in internals.
We previously disallowed OptionalMemberExpression inside a normal
MemberExpression, eg `(a?.b).c`. The new representation handles this case
correctly so we can remove the restriction.
Our previous lowering for OptionalMemberExpression reordered the evaluation of
properties, such that we had to restrict the allowed properties to those that
were safe for reordering. With the new representation we preserve order of
evaluation, so we can relax the restriction. This unblocks a few cases in an
internal product.
Now that _all_ optional expression types use the new representation, the
optionality of all PropertyLoad and ComputedLoad is modeled via control flow (in
HIR) and the structure of OptionalExpression (in ReactiveFunction). Thus we no
longer need the `optional` properties on these load instructions — they're
optional if they're part of an OptionalExpression.
Earlier PRs in the stack change the way we lower OptionalMemberExpression, but
only when they ultimately appear inside some OptionalCallExpression. This PR
ensures that _all_ OptionalMemberExpressions get the new lowering. Note that one
test case has what is arguably a regression, but the new behavior is also
reasonable: if we see both `a.b?.c` and `a.b.c.` as dependencies of a scope, we
previously inferred `a.b.c` as the dependency, but we now infer `a.b` as the
dependency. This isn't as optimal as what we had before, but it also seems good
enough for now. Also note that some cases are improved: `foo(a.b?.c)` would
previously have taken `a.b` as a dependency, we now take the full value of
`a.b?.c` as a dependency - more precise.
So overall i'm inclined to land and follow-up on the one regression, since the
overall model is more cohesive.
Usually we don't have to do this since we only set these in the loop but
the ReactCustomFormAction props are optional so they might be undefined.
Also moved it to a general type since it's a semi-public API.
## Summary
Fixes#26756.
DevTools is failing to inject `__REACT_DEVTOOLS_GLOBAL_HOOK__` hook in
incognito mode. This is not happening straight-forward, but if extension
is toggled on and off, the next time I try to open it I am receiving an
error that content script was already registered.
<img width="676" alt="Screenshot 2023-05-02 at 14 36 53"
src="https://user-images.githubusercontent.com/28902667/235877692-51c5d284-79d9-4b00-b62e-d25d5bb5e056.png">
- Unregistering content scripts before attempting to register them
again. We need to inject `__REACT_DEVTOOLS_GLOBAL_HOOK__` on each page,
so this should be expected behaviour.
- Fixed error logging
## How did you test this change?
Local build of extension for Chrome, trying the same steps, which
resulted in an error.
No regression in performance, tested on react.dev, still the same.
The "next" prerelease channel represents what will be published the next
time we do a stable release. We publish a new "next" release every day
using a timed CI workflow.
When we introduced this prerelease channel a few years ago, another name
we considered was "canary". But I proposed "next" instead to create a
greater distinction between this channel and the "experimental" channel
(which is published at the same cadence, but includes extra experimental
features), because some other projects use "canary" to refer to releases
that are more unstable than how we would use it.
The main downside of "next" is someone might mistakenly assume the name
refers to Next.js. We were aware of this risk at the time but didn't
think it would be an issue in practice.
However, colloquially, we've ended up referring to this as the "canary"
channel anyway to avoid precisely that confusion.
So after further discussion, we've agreed to rename to "canary".
This affects the label used in the version string (e.g.
`18.3.0-next-a1c2d3e4` becomes `18.3.0-canary-a1c2d3e4`) as well as the
npm dist tags used to publish the releases. For now, I've chosen to
publish the canaries using both `@canary` and `@next` dist tags, so that
downstream consumers who might depend on `@next` have time to adjust. We
can remove that later after the change has been communicated.
call
When we traverse an OptionalExpression in PropagateScopeDependencies, we
previously considered the entire value to be optional. With the changes in this
stack to more accurately model OptionalMemberExpression, the `object` portion of
an OptionalMemberExpression is now evaluated within the OptionalExpression. This
PR refines the handling of OptionalExpression accordingly, so that we only treat
the optional portion as conditional.
The previous OptionalCall terminal and reactive value kinds are now used not
just for optional calls, but for optional member expressions that appear within
an optional call. This PR renames those data types to OptionalTerminal and
OptionalExpression for clarity.
Extends the new modeling of the previous diff to OptionalMemberExpression. In an
example such as `a?.b?.c`, we now model that not only is the `.c` conditional,
but our control flow graph accurately reflects the fact that the `.c` is only
evaluated if `a.b` exists. Previously we knew it was conditional but the CFG
allowed a path from a being null through to evaluation of `.c`.
More accurately models nested OptionalCallExpression. Consider:
```javascript
a?.(b)?.(c)
```
Our previous representation modeled it such that we treated the second function
call as if it would be called regardless of whether `a` existed or not. We knew
that the second call was conditional, so our test output was correct, but the
control-flow graph didn't faithfully model the semantics. That bothered me.
The new representation correctly models the control flow, and the fact that if
`a` is null/undefined execution immediately aborts (not reaching the second call
at all, nor the evaluation of its args), and evaluates the whole outer
OptionalCallExpression to `undefined`.
Note that nested optional member expressions still have the previous model —
that's next to address.
A common idiom is to map over some possibly-missing list of items from a data
payload and fall back to an empty array:
```javascript
const renderedItems = data?.items?.map(renderItem) ?? [];
```
The way we were lowering OptionalCallExpression meant that in this case, we'd
end up with an OptionalCallTerminal as the terminal of the logical expression's
test block, which violates our internal invariant. Logical test blocks must end
in a Branch! This PR fixes the immediate issue, which is that the callee - in
this case `data?.items?.map` — was being lowered prior to the
OptionalCallTerminal instead of inside its test block. Changing that fixes the
shape of the IR and makes this example work.
As part of investigating this I realized that the way I originally handled
lowering of optional call isn't quite right. The difference isn't observable
unless we did more sophisticated DCE but we don't correctly model the fact that
if `data.items` is null that the `map()` call won't occur. That is technically
fine bc we do model the fact that the `map()` call is conditional, and notably
its arguments are only conditional dependencies. So it's good enough. But in a
follow-up I'll change to model the fact that `data.items` is null, that the map
call isn't reachable at all.
Fix the previous bug — this was a simple oversight, where FlattenScopesWithHooks
overrode `visitValue()` but failed to call `traverseValue()`. This meant that
when we reached compound expressions such as LogicalExpressions that we didn't
traverse into their nested values, and didn't see the hooks hidden there.
Repro of a bug in which we incorrect memoize hook calls that are inside logical
expressions (though the bug could occur for ternaries, optional calls, and
sequence expressions too).
This is an attempt to get down some of the principles and goals that we've had
partially written down, partially just thoroughly discussed amongst the team.
It's rough draft quality but better than nothing, and gives us someplace to add
to.
Stacked on top of #26735.
This allows a framework to add a `$$FORM_ACTION` property to a function.
This lets the framework return a set of props to use in place of the
function but only during SSR. Effectively, this lets you implement
progressive enhancement of form actions using some other way instead of
relying on the replay feature.
This will be used by RSC on Server References automatically by
convention in a follow up, but this mechanism can also be used by other
frameworks/libraries.
This allows us to emit extra ephemeral data that will only be used on
server rendered forms.
First I refactored the shouldSkip functions to now just do that work
inside the canHydrate methods. This makes the Config bindings a little
less surface area but it also helps us optimize a bit since we now can
look at the code together and find shared paths.
canHydrate returns the instance if it matches, that used to just be
there to refine the type but it can also be used to just return a
different instance later that we find. If we don't find one, we'll bail
out and error regardless so no need to skip past anything.
in https://github.com/facebook/react/pull/26738 we added nonce to the
ResponseState. Initially it was used in a variety of places but the
version that got merged only included it with the external fizz runtime.
This PR updates the config for the external fizz runtime so that the
nonce is encoded into the script chunks at request creation time.
The rationale is that for live-requests, streaming is more likely than
not so doing the encoding work at the start is better than during flush.
For cases such as SSG where the runtime is not required the extra
encoding is tolerable (not a live request). Bots are an interesting case
because if you want fastest TTFB you will end up requiring the runtime
but if you are withholding until the stream is done you have already
sacrificed fastest TTFB and the marginal slowdown of the extraneous
encoding is hopefully neglibible
I'm writing this so later if we learn that this tradeoff isn't worth it
we at least understand why I made the change in the first place.
This adds an experimental hook tentatively called useOptimisticState.
(The actual name needs some bikeshedding.)
The headline feature is that you can use it to implement optimistic
updates. If you set some optimistic state during a transition/action,
the state will be automatically reverted once the transition completes.
Another feature is that the optimistic updates will be continually
rebased on top of the latest state.
It's easiest to explain with examples; we'll publish documentation as
the API gets closer to stabilizing. See tests for now.
Technically the use cases for this hook are broader than just optimistic
updates; you could use it implement any sort of "pending" state, such as
the ones exposed by useTransition and useFormStatus. But we expect
people will most often reach for this hook to implement the optimistic
update pattern; simpler cases are covered by those other hooks.
This can't be tested yet - we only support simple, safely re-orderable values as
case test values - but it will easy to overlook later so i'm adding now.
This test started failing recently in older versions of React because
the Scheduler priority inside a microtask is Normal instead of
Immediate. This is expected because microtasks are not Scheduler tasks;
it's an implementation detail.
I gated the test to only run in v17 because it's a regression test for
legacy Suspense behavior, and the implementation details of the snapshot
changed in v18.
Test plan
---------
Using latest:
```
yarn test --build --project devtools --release-channel=experimental profilingcache
```
Using v17 (typically runs in a timed CI workflow):
```
/scripts/circleci/download_devtools_regression_build.js 17.0 --replaceBuild
yarn test --build --project devtools --release-channel=experimental --reactVersion 17.0 profilingcache
```
PropagateScopeDependencies is one of the few places we don't use the new visitor
infra for traversing ReactiveFunction. Or rather it _was_!
Note that there's a bit less value here than in other places since we have to
handle each terminal variant with custom logic, but at least it's more
consistent with the rest of the codebase now.
Currently there is no way to provide a nonce when using
`ReactDOM.preinit(..., { as: 'script' })`
This PR adds `nonce?: string` as an option
While implementing this PR I added a test to also show you can pass
`integrity`. This test isn't directly related to the nonce change.
This fixes a bug with `use` where if you update a component that's
currently suspended, React will sometimes mistake it for a render phase
update.
This happens because we don't reset `currentlyRenderingFiber` until the
suspended is unwound. And with `use`, that can happen asynchronously,
most commonly when the work loop is suspended during a transition.
The fix is to make sure `currentlyRenderingFiber` is only set when we're
in the middle of rendering, which used to be true until `use` was
introduced.
More specifically this means clearing `currentlyRenderingFiber` when
something throws and setting it again when we resume work.
In many cases, this bug will fail "gracefully" because the update is
still added to the queue; it's not dropped completely. It's also
somewhat rare because it has to be the exact same component that's
currently suspended. But it's still a bug. I wrote a regression test
that shows a sync update failing to interrupt a suspended component.
We previously didn't support ternaries whose value was unused, so we had an
extraneous temporary and console.log call to ensure the value counted as used.
We now special-case ternary/conditional expressions which are in an
ExpressionStatement to not prune them, so the temporary and log are now
unnecessary.
It turns out the third parameter to `cloneNode` is ["If the third parameter is
true, the cloned nodes exclude location
properties."](c060e5e3d5/packages/babel-types/src/clone/cloneNode.ts (L35-L39))
strips away locations if its true, so to fix simply change this to false
Defines common `console` methods to tell the compiler that they take readonly
args. This ensures that things like `console.log()` aren't accidentally viewed
as a mutation. Previously the pattern of "build object, then log it after
mutation is done" would have grouped the console.log as part of the mutation and
the log only would fire if the value got reconstructed. Now we know the log
isn't mutating, and the log will happen regardless of whether the value is
rebuilt or cached.
Updates two points in the compiler that were easy to miss when adding new
terminals:
* HIRBuilder's `removeUnreachableFallthroughs()` nulls out unreachable
fallthroughs, but this had a non-exhaustive `if` statement. It now uses a helper
function which internally has an exhaustive switch.
* LeaveSSA needs to schedule block fallthroughs, but had a non-exhaustive `if`
statement. It also uses a helper function which internally has an exhaustive
switch.
cc @poteto since you ran into this (ie the compiler not alerting you to update
these places) w your diffs.
This hook reads the status of its ancestor form component, if it exists.
```js
const {pending, data, action, method} = useFormStatus();
```
It can be used to implement a loading indicator, for example. You can
think of it as a shortcut for implementing a loading state with the
useTransition hook.
For now, it's only available in the experimental channel. We'll share
docs once its closer to being stable. There are additional APIs that
will ship alongside it.
Internally it's implemented using startTransition + a context object.
That's a good way to think about its behavior, but the actual
implementation details may change in the future.
Because form elements cannot be nested, the implementation in the
reconciler does not bother to keep track of multiple nested "transition
providers". So although it's implemented using generic Fiber config
methods, it does currently make some assumptions based on React DOM's
requirements.
Discovered this in a recent attempt at syncing Forget to Meta, it seems
that calling path.stop() is unsafe as it appears to have strange
behavior in plugins that come after. This resulted in `import type
{...}` not being compiled away in the post-babel output which isn't
valid JS syntax. Removing the `stop()` calls fixes it
Test plan: made these changes locally, synced my local changes to Meta and reran
- in simulator and observe that it now runs and doesn't throw a syntax error
This is a more general version of the change from #1521. That PR ensured that
LoadLocal temporaries accessed outside the instruction's scope are correctly
promoted. However, we have a similar pattern with PropertyLoad.
This PR adds a general mechanism for handling these type of indirections: any
LoadLocal/PropertyLoad temporary accessed when it's defining scope is not active
will be promoted to a declaration of the defining scope. Notably, we do this in
a way that ensures that the dependencies are preserved, ie that we correctly
view the operand of LoadLocal/PropertyLoad as a dependency of the current scope.
Supports EmptyStatement nodes by ignoring them. Note no tests because
format-on-save clears away any empty statements and there is, rather
frustratingly, no way to tell VSCode not to format on save for a specific file
via the file contents itself or project configuration (at least, not that i can
find).
Uses the new ExpressionStatement instruction to ensure that logical and
conditional expressions are never pruned. This addresses an issue where we were
unable to construct a ReactiveFunction for unused logical/conditional bc there
wasn't a single Identifier assigned in both branches. The ExpressionStatement
ensures that the result is used, that we don't prune the phi, and that both
branches have a single assignment target.
In theory we could be more sophisticated with DCE and still prune these
instructions if their operands are also safe to prune, but in practice you're
only like to have a logical/conditional as an expression statement (in the
source) if it's for side effects.
Adds an `ExpressionStatement` instruction variant to model values that are
otherwise "unused" but which we don't want to remove. The next diff changes
BuildHIR to use this where appropriate.
We previously represented JsxExpressions using builtin tags - `<div>`, `<b>` etc
- by lowering the tag name to a Primitive with the string name of the tag.
However, by lowering into an independent value, it was possible that the lowered
tag name could be grouped into a different memo slot, such that we ended up with
output like:
```javascript
let t0;
if (c_1) {
...
t0 = "div"
...
} else { ... }
return <t0>{children}</t0>
```
This is obviously wrong. It's also wrong to rename `t0` -> `T0`, because React
treats that as a custom component, not a builtin. The right thing is to
explicitly model builtin components, which this PR does by making
`JsxExpression.tag` be a union of Place | BuiltinTag.
Ensures that temporaries used in JsxExpression tags are named with a capital
letter so that they are treated as custom components rather than builtins.
When there are multiple async actions at the same time, we entangle them
together because we can't be sure which action an update might be
associated with. (For this, we'd need AsyncContext.) However, if one of
the async actions fails with an error, it should only affect that
action, not all the other actions it may be entangled with.
Resolving each action independently also means they can have independent
pending state types, rather than being limited to an `isPending`
boolean. We'll use this to implement an upcoming form API.
I found a couple scenarios where preloads were issued too aggressively
1. During SSR, if you render a new stylesheet after the preamble flushed
it will flush a preload even if the resource was already preloaded
2. During Client render, if you call `ReactDOM.preload()` it will only
check if a preload exists in the Document before inserting a new one. It
should check for an underlying resource such as a stylesheet link or
script if the preload is for a recognized asset type
---
Changes:
- Added `testfilter.txt`
```
// @only
call
capture-param-mutate
jsx-spread
```
or
```
// @skip
call
error.todo-kitchensink
```
- grouped all commands under `--mode`
```js
// runs all tests
yarn snap
// runs all tests and updates fixtures
yarn snap --mode update
// runs only tests that pass `testfilter.txt`
yarn snap --mode filter
// run in watch mode
yarn snap --mode watch
```
- in watch mode, toggle between running all tests or filtered tests
```
386 Tests, 386 Passed, 0 Failed
Completed in 4994 ms
Current mode = NORMAL, run all test fixtures.
Waiting for input or file changes...
u - update all fixtures
f - toggle (turn on) filter mode
q - quit
[any] - rerun tests
> f
PASS call
PASS capture_mutate-across-fns
PASS timers
3 Tests, 3 Passed, 0 Failed
Completed in 39 ms
Current mode = FILTER, filter test fixtures by "testfilter.txt"
Waiting for input or file changes...
u - update all fixtures
f - toggle (turn off) filter mode
q - quit
[any] - rerun tests
```
---
- `runner.ts` is pretty large now, happy to split it up into multiple files
- I'd also like to refactor `watch` to make its shared state and control flow
explicit
A bit of a hack -
We currently trigger test runs when we detect changes in the test fixtures
directory. This trigger is also hit when we run `snap` in update mode, since
updating performs file writes.
This PR will ignore subscription changes (callbacks) that trigger within 5
seconds of the last update.
It seems difficult to be more granular with a timestamp, since `@parcel/watcher`
doesn't give us the file change timestamp and (from my understanding), other
promises and tasks can be queued to run between the update and callback.
## Summary
We added some post-processing in the build for RN in #26616 that broke
for users on Windows due to how line endings were handled to the regular
expression to insert some directives in the docblock. This fixes that
problem, reported in #26697 as well.
## How did you test this change?
Verified files are still built correctly on Mac/Linux. Will ask for help
to test on Windows.
useMemoCache wasn't previously supported in the DevTools, so any attempt
to inspect a component using the hook would result in a
`dispatcher.useMemoCache is not a function (it is undefined)` error.
This is enabled in the canary channels, but because it's relatively
untested, we'll disable it at Meta until they're ready to start trying
it out. It can change some behavior even if you don't intentionally
start using the API.
The reason it's not a dynamic flag is that it affects the external Fizz
runtime, which currently can't read flags at runtime.
We used to have Event Replaying for any kind of Discrete event where
we'd track any event after hydrateRoot and before the async code/data
has loaded in to hydrate the target. However, this didn't really work
out because code inside event handlers are expected to be able to
synchronously read the state of the world at the time they're invoked.
If we replay discrete events later, the mutable state around them like
selection or form state etc. may have changed.
This limitation doesn't apply to Client Actions:
- They're expected to be async functions that themselves work
asynchronously. They're conceptually also in the "navigation" events
that happen after the "submit" events so they're already not
synchronously even before the first `await`.
- They're expected to operate mostly on the FormData as input which we
can snapshot at the time of the event.
This PR adds a bit of inline script to the Fizz runtime (or external
runtime) to track any early submit events on the page - but only if the
action URL is our placeholder `javascript:` URL. We track a queue of
these on `document.$$reactFormReplay`. Then we replay them in order as
they get hydrated and we get a handle on the Client Action function.
I add the runtime to the `bootstrapScripts` phase in Fizz which is
really technically a little too late, because on a large page, it might
take a while to get to that script even if you have displayed the form.
However, that's also true for external runtime. So there's a very short
window we might miss an event but it's good enough and better than
risking blocking display on this script.
The main thing that makes the replaying difficult to reason about is
that we can have multiple instance of React using this same queue. This
would be very usual but you could have two different Reacts SSR:ing
different parts of the tree and using around the same version. We don't
have any coordinating ids for this. We could stash something on the form
perhaps but given our current structure it's more difficult to get to
the form instance in the commit phase and a naive solution wouldn't
preserve ordering between forms.
This solution isn't 100% guaranteed to preserve ordering between
different React instances neither but should be in order within one
instance which is the common case.
The hard part is that we don't know what instance something will belong
to until it hydrates. So to solve that I keep everything in the original
queue while we wait, so that ordering is preserved until we know which
instance it'll go into. I ended up doing a bunch of clever tricks to
make this work. These could use a lot more tests than I have right now.
Another thing that's tricky is that you can update the action before
it's replayed but we actually want to invoke the old action if that
happens. So we have to extract it even if we can't invoke it right now
just so we get the one that was there during hydration.
We currently use rollup to make an adhoc bundle from the file system
when we're testing an import of an external file.
This doesn't follow all the interception rules that we use in jest and
in our actual builds.
This switches to just using jest require() to load these. This means
that they effectively have to load into the global document so this only
works with global document tests which is all we have now anyway.
This wires up, but does not yet implement, an experimental hook called
useFormStatus. The hook is imported from React DOM, not React, because
it represents DOM-specific state — its return type includes FormData as
one of its fields. Other renderers that implement similar methods would
use their own renderer-specific types.
The API is prefixed and only available in the experimental channel.
It can only be used from client (browser, SSR) components, not Server
Components.
Run snap tester on a forked node process so runs can be interrupted. (Currently,
`Ctrl+C` is not handled until after all test fixtures finish compiling). This
*feels* a bit heavy-handed, but main.ts is pretty small and doesn't do much
other than listen for input / signals. Would love feedback here since I haven't
really worked with nodejs / JS cli tools before
- main.ts
new file that spawns forked runner
- pipe stdin/out/err to and from the child runner process, details described in
comments.
- listens for exit event of child
- runner.ts
- added logic to listen for interrupts and clean up (not really familiar with
how file and tsc watchers are implemented, so we try to call 'close' on them
just in case they need to release locks / do other cleanup)
---
`yarn snap --sync` currently fails on `error.file-has-non-critical-errors`. This
is because we're relying on a globally overwritten `console.error` function to
report non-fatal errors. However, executing `Promise.all(...)` on a single
nodejs thread will interleave calls to `run` (which is an async function).
---
Next PRs: skip / only tests, pretty diffing
This PR:
1. Add help messages:
```
$ node packages/snap/dist/runner.js --help
Options:
--version Show version number [boolean]
--sync Run compiler in main thread (instead of using worker threads
or subprocesses). Defaults to false.
[boolean] [default: true]
--worker-threads Run compiler in worker threads (instead of subprocesses).
Defaults to true. [boolean] [default: true]
--watch Run in watch mode. Defaults to false (single run).
[boolean] [default: false]
--update Run in update mode. Update mode only affects the first run,
subsequent runs (in watch mode) require typing `u` to
update. Defaults to false. [boolean] [default: false]
--help Show help [boolean]
✨ Done in 0.62s.
```
```
...
386 Tests, 386 Passed, 0 Failed
Completed in 4434 ms
Waiting for input or file changes...
u - update fixtures
q - quit
[any] - rerun tests
```
2. Surface typescript diagnostics; skip test fixtures if source code has errors
```
$ node packages/snap/dist/runner.js
src/Optimization/ConstantPropagation.ts:87:3 - error TS1434: Unexpected keyword
or identifier.
src/Optimization/ConstantPropagation.ts:87:3 - error TS2304: Cannot find name
'lt'.
src/Optimization/ConstantPropagation.ts:87:6 - error TS2552: Cannot find name
'hasChanges'. Did you mean 'onhashchange'?
src/Optimization/ConstantPropagation.ts:135:11 - error TS2552: Cannot find name
'hasChanges'. Did you mean 'onhashchange'?
src/Optimization/ConstantPropagation.ts:155:10 - error TS2552: Cannot find name
'hasChanges'. Did you mean 'onhashchange'?
Compilation failed (5 errors).
Found errors in Forget source code, skipping test fixtures.
✨ Done in 10.73s.
```
```
Compiling...
src/Optimization/ConstantPropagation.ts:86:39 - error TS2552: Cannot find name
'HIRFunctin'. Did you mean 'HIRFunction'?
Compilation failed (1 error).
Test: Found errors in Forget source code, skipping test fixtures.
Waiting for input or file changes...
u - update fixtures
q - quit
[any] - rerun tests
```
DevTools relies on built-in hook names at their call site to be unprefixed in
order to correctly track them. This PR updates our Babel plugin to:
- Check if there are any existing import declarations of `import { /* ... /* }
from 'react';`
- If true, we add the specifier `unstable_useMemoCache as useMemoCache`
- Otherwise, we synthesize a new import declaration
- In Codegen we now emit `useMemoCache(n)` rather than
`React.unstable_useMemoCache(n)`
Insert temporary input node to polyfill submitter argument in FormData.
This works for buttons too and fixes a bug where the type attribute
wasn't reset.
I also exclude the submitter if it's a function action. This ensures
that we don't include the generated "name" when the action is a server
action. Conceptually that name doesn't exist.
Fizz can emit whatever it wants for the SSR version of these fields when
it's a function action so they might not align with what is in the
previous props. Therefore we need to force them to update if we're
updating to a non-function where they might be relevant again.
Use the Blob constructor + append with filename instead of File
constructor. Node.js doesn't expose a global File constructor but does
support it in this form.
Queue fields until we get the 'end' event from the previous file. We
rely on previous files being available by the time a field is resolved.
However, since the 'end' event in Readable is fired after two
micro-tasks, these are not resolved in order.
I use a queue of the fields while we're still waiting on files to
finish. This still doesn't resolve files and fields in order relative to
each other but that doesn't matter for our usage.
Stacked on #26557
Supporting Float methods such as ReactDOM.preload() are challenging for
flight because it does not have an easy means to convey direct
executions in other environments. Because the flight wire format is a
JSON-like serialization that is expected to be rendered it currently
only describes renderable elements. We need a way to convey a function
invocation that gets run in the context of the client environment
whether that is Fizz or Fiber.
Fiber is somewhat straightforward because the HostDispatcher is always
active and we can just have the FlightClient dispatch the serialized
directive.
Fizz is much more challenging becaue the dispatcher is always scoped but
the specific request the dispatch belongs to is not readily available.
Environments that support AsyncLocalStorage (or in the future
AsyncContext) we will use this to be able to resolve directives in Fizz
to the appropriate Request. For other environments directives will be
elided. Right now this is pragmatic and non-breaking because all
directives are opportunistic and non-critical. If this changes in the
future we will need to reconsider how widespread support for async
context tracking is.
For Flight, if AsyncLocalStorage is available Float methods can be
called before and after await points and be expected to work. If
AsyncLocalStorage is not available float methods called in the sync
phase of a component render will be captured but anything after an await
point will be a noop. If a float call is dropped in this manner a DEV
warning should help you realize your code may need to be modified.
This PR also introduces a way for resources (Fizz) and hints (Flight) to
flush even if there is not active task being worked on. This will help
when Float methods are called in between async points within a function
execution but the task is blocked on the entire function finishing.
This PR also introduces deduping of Hints in Flight using the same
resource keys used in Fizz. This will help shrink payload sizes when the
same hint is attempted to emit over and over again
In React DOM, we use HostContext to represent the namespace of whatever
is currently rendering — SVG, Math, or HTML. Because there is a fixed
set of possible values, we can switch this to be a number instead. My
motivation is that I want to start tracking additional information in
this type, and I want to pack all of it into a single number instead of
turning it into an object. For better performance.
(In dev, the host context type is already an object that includes
additional information, but that's dev so who cares.)
Technically, before this change, the host context could be any namespace
URI string, but any value other than SVG or Math was treated the same
way. Only SVG and Math have special behavior. So in the new structure,
there are three enum values: SVG, Math, or None, which represents the
HTML namespace as well as all other possible namespaces.
This is the next step toward full support for async form actions.
Errors thrown inside form actions should cause the form to re-render and
throw the error so it can be captured by an error boundary. The behavior
is the same if the `<form />` had an internal useTransition hook, which
is pretty much exactly how we implement it, too.
The first time an action is called, the form's HostComponent is
"upgraded" to become stateful, by lazily mounting a list of hooks. The
rest of the implementation for function components can be shared.
Because the error handling behavior added in this commit is just using
useTransition under-the-hood, it also handles pending states, too.
However, this pending state can't be observed until we add a new hook
for that purpose. I'll add this next.
I forgot to remove this when we removed the diagram output. This brings test
time from 6s -> 5s on my machine, still much slower than the new test runner in
#1486.
#1507 Ensured that declarations of reactive scopes were propagated to parent
reactive scopes as necessary to ensure that those declarations would be
available at the appropriate block scope. This meant that some scopes that were
previously pruned would no longer be pruned. Specifically, an outer scope wo any
declarations, but which contained a nested scope _with_ a propagated
declaration, would now end up with non-empty declarations and not be pruned.
This PR changes to track the declaring scope of each declaration, so we still
prune scopes that don't have any of their own declarations.
Originally I defined `Stack` as an interface to ensure both Node and Empty
variants would have an identical API. But exporting an interface allows a
developer to define other implementations, when we really want to ensure that a
Stack is precisely a Node or Empty instance. This PR changes to exporting a
union of `Stack = Node | Empty`, and makes the interface private to the module.
Fixed a bug identified in repro cases earlier in the stack. The case is where
some later value is composed of several values, say A and B, where A is an
identifier that is reassigned within B. Also, the mutable range of B surrounds
the evaluation of A. In this case, the reference to A gets lowered to a
temporary (say a t0 = LoadLocal A), and that temporary is created within the
reactive scope for B.
PropagateScopeDependencies bypasses LoadLocal indirections, and considers the
reference to the temporary (t0) as if it was a reference to the identifier (A).
That breaks the whole reason we lower Identifiers to temporaries - to preserve
evaluation order.
This PR fixes the bug by promoting temporaries to names values if they are
referenced outside their defining scope. So, the reference to t0 stays a
reference to t0, which correctly preserves the value of A at the right point in
time.
This is all much easier to see in the new test case.
When lowering a JSX element we were correctly lowering to a temporary in all but
one case: the common case of an identifier. That is fine in practice but breaks
in the presence of the tag identifier being reassigned in the props/children.
This PR fixes to always lower the tag to a temporary.
This PR updates ConstantPropagation to support propagating global references:
```javascript
// Before
const x = Math;
foo(x);
// After
foo(Math);
```
This is a generally useful optimization but also helps with a subset of cases
around JSX element tags, which are frequently globals.
During codegen, when we now cache and restore the temporary values map as we
enter and exit the scope. This ensures that any temporaries within the reactive
scope are only visible within that scope, and not to subsequent code. In a
subsequent PR this surfaces a bug with temporaries not correctly exported from a
reactive scope.
In codegen when we lower an operand we check to see if we have an already
lowered value for it (stored in `cx.temp`). Currently we silently handle missing
values by emitting a raw identifier, but this is really an error. This PR adds
validation, which uncovered a few places where we legitimately won't have a
value - things like function parameters that got swapped for temporaries bc of
destructuring. We populate those as `null` values now, and fail if a temporary
had a truly missing value.
InvokeGuardedCallback is now implemented with the browser fork done at
error-time rather than module-load-time. Originally it also tried to
freeze the window/document references to avoid mismatches in prototype
chains when testing React in different documents however we have since
updated our tests to not do this and it was a test only feature so I
removed it.
Stacked on #26570
Previously we restricted Float methods to only being callable while
rendering. This allowed us to make associations between calls and their
position in the DOM tree, for instance hoisting preinitialized styles
into a ShadowRoot or an iframe Document.
When considering how we are going to support Flight support in Float
however it became clear that this restriction would lead to compromises
on the implementation because the Flight client does not execute within
the context of a client render. We want to be able to disaptch Float
directives coming from Flight as soon as possible and this requires
being able to call them outside of render.
this patch modifies Float so that its methods are callable anywhere. The
main consequence of this change is Float will always use the Document
the renderer script is running within as the HoistableRoot. This means
if you preinit as style inside a component render targeting a ShadowRoot
the style will load in the ownerDocument not the ShadowRoot. Practially
speaking it means that preinit is not useful inside ShadowRoots and
iframes.
This tradeoff was deemed acceptable because these methods are
optimistic, not critical. Additionally, the other methods, preconntect,
prefetchDNS, and preload, are not impacted because they already operated
at the level of the ownerDocument and really only interface with the
Network cache layer.
I added a couple additional fixes that were necessary for getting tests
to pass that are worth considering separately.
The first commit improves the diff for `waitForThrow` so it compares
strings if possible.
The second commit makes invokeGuardedCallback not use metaprogramming
pattern and swallows any novel errors produced from trying to run the
guarded callback. Swallowing may not be the best we can do but it at
least protects React against rapid failure when something causes the
dispatchEvent to throw.
In anticipation of making Fiber use the document global for dispatching
Float methods that arrive from Flight I needed to update some tests that
commonly recreated the JSDOM instance after importing react.
This change updates a few tests to only create JSDOM once per test,
before importing react-dom/client.
Additionally the current act implementation for server streaming did not
adequately model streaming semantics so I rewrite the act implementation
in a way that better mirrors how a browser would parse incoming HTML.
The new act implementation does the following
1. the first time it processes meaningful streamed content it figures
out whether it is rendering into the existing document container or if
it needs to reset the document. this is based on whether the streamed
content contains tags `<html>` or `<body>` etc...
2. Once the streaming container is set it will typically continue to
stream into that container for future calls to act. The exception is if
the streaming container is the `<head>` in which case it will switch to
streaming into the body once it receives a `<body>` tag.
This means for tests that render something like a `<div>...</div>` it
will naturally stream into the default `<div id="container">...` and for
tests that render a full document the HTML will parse like a real
browser would (with some very minor edge case differences)
I also refactored the way we move nodes from buffered content into the
document and execute any scripts we find. Previously we were using
window.eval and I switched this to just setting the external script
content as script text. Additionally the nonce logic is reworked to be a
bit simpler.
Adds an option to always throw errors regardless of severity (default, ie the
status quo), or when the flag is disabled, only critical errors will be thrown.
Any error that isn't considered a critical error (see
`CompilerError.isCritical()`) since it might indicate that the compiler is
buggy, while non-critical errors will result in that file being skipped for
compilation, but otherwise continue compiling other files
This puts the change introduced by #26611 behind a flag until Meta is
able to roll it out. Disabling the flag reverts back to the old
behavior, where retries are throttled if there's still data remaining in
the tree, but not if all the data has finished loading.
The new behavior is still enabled in the public builds.
* JSX tag value temporaries getting promoted due to being sandwiched inside the
mutation of some other item
* Incorrect order-of-evaluation for jsx tag relative to props/children
- substr is Annex B
- substring silently flips its arguments if they're in the "wrong order", which is confusing
- slice is better than sliced bread (no pun intended) and also it works the same way on Arrays so there's less to remember
---
> I'd be down to just lint and enforce a single form just for the potential compression savings by using a repeated string.
_Originally posted by @sebmarkbage in https://github.com/facebook/react/pull/26663#discussion_r1170455401_
snapshotting
As demo'd on our sync. This is meant as a replacement for `yarn test` just for
fixtures. On my machine, a test run from a steady state of Jest watch mode takes
6 seconds. With this script, it takes ~800ms.
Workflow: make edits in `packages/snap/`, then `yarn build` in that directory to
build the test runner.
To run tests, `node packages/snap/dist/runner.js` from the main forget/
directory to run tests. Pass `--watch` for watch mode, `--update` to update
snapshots. Note that this _only_ updates .expect.md files, it does not update
Jest's `__snapshots__` directory (this is intentional, our use of Jest snapshots
is a hack that this script is meant to replace).
When running in watch mode, ctrl-c or q will quit, 'u' will update snapshots,
and any other key will re-run tests. Tests will re-run on changes to the source
code (after an incremental TS rebuild) and on changes to the fixtures.
Main things that are missing:
* Don't run tests if TS compilation had errors (the errors should be logged to
console already, but we need to wire that up so that we abort tests if there are
errors)
* Actually delete stale files in update mode (there is some commented-out code
to double-check and then uncomment)
* Improve diff view: just print the diffed segments, not the whole file diff.
See the API at https://github.com/facebook/jest/tree/main/packages/jest-diff
(right now we're using `diff()` but should probably use one of the lower-level
functions)
* Properly parse/validate args with `yargs`, add a help option, etc
* In watch mode, when tests finish print a list of commands so users know what
they can do (like Jest does)
* Support skipping tests and selecting a single test to focus. Suggestions:
* Name files with `skip.` to skip
* Allow passing a test name to the script to run only tests matching that
pattern, eg `node runner.js -p <pattern>`
* In watch mode, support typing 'p' to prompt the user for a pattern. After
that, support typing 'a' to clear the pattern and run all tests.
This lets you pass a function to `<form action={...}>` or `<button
formAction={...}>` or `<input type="submit formAction={...}>`. This will
behave basically like a `javascript:` URL except not quite implemented
that way. This is a convenience for the `onSubmit={e => {
e.preventDefault(); const fromData = new FormData(e.target); ... }`
pattern.
You can still implement a custom `onSubmit` handler and if it calls
`preventDefault`, it won't invoke the action, just like it would if you
used a full page form navigation or javascript urls. It behaves just
like a navigation and we might implement it with the Navigation API in
the future.
Currently this is just a synchronous function but in a follow up this
will accept async functions, handle pending states and handle errors.
This is implemented by setting `javascript:` URLs, but these only exist
to trigger an error message if something goes wrong instead of
navigating away. Like if you called `stopPropagation` to prevent React
from handling it or if you called `form.submit()` instead of
`form.requestSubmit()` which by-passes the `submit` event. If CSP is
used to ban `javascript:` urls, those will trigger errors when these
URLs are invoked which would be a different error message but it's still
there to notify the user that something went wrong in the plumbing.
Next up is improving the SSR state with action replaying and progressive
enhancement.
Implements initial (client-only) support for async actions behind a
flag. This is an experimental feature and the design isn't completely
finalized but we're getting closer. It will be layered alongside other
features we're working on, so it may not feel complete when considered
in isolation.
The basic description is you can pass an async function to
`startTransition` and all the transition updates that are scheduled
inside that async function will be grouped together. The `isPending`
flag will be set to true immediately, and only set back to false once
the async action has completed (as well as all the updates that it
triggers).
The ideal behavior would be that all updates spawned by the async action
are automatically inferred and grouped together; however, doing this
properly requires the upcoming (stage 2) Async Context API, which is not
yet implemented by browsers. In the meantime, we will fake this by
grouping together all transition updates that occur until the async
function has terminated. This can lead to overgrouping between unrelated
actions, which is not wrong per se, just not ideal.
If the `useTransition` hook is removed from the UI before an async
action has completed — for example, if the user navigates to a new page
— subsequent transitions will no longer be grouped with together with
that action.
Another consequence of the lack of Async Context is that if you call
`setState` inside an action but after an `await`, it must be wrapped in
`startTransition` in order to be grouped properly. If we didn't require
this, then there would be no way to distinguish action updates from
urgent updates caused by user input, too. This is an unfortunate footgun
but we can likely detect the most common mistakes using a lint rule.
Once Async Context lands in browsers, we can start warning in dev if we
detect an update that hasn't been wrapped in `startTransition`. Then,
longer term, once the feature is ubiquitous, we can rely on it for real
and allow you to call `setState` without the additional wrapper.
Things that are _not_ yet implemented in this PR, but will be added as
follow ups:
- Support for non-hook form of `startTransition`
- Canceling the async action scope if the `useTransition` hook is
deleted from the UI
- Anything related to server actions
I accidentally made a behavior change in the refactor. It turns out that
when switching off `checked` to an uncontrolled component, we used to
revert to the concept of "initialChecked" which used to be stored on
state.
When there's a diff to this computed prop and the value of props.checked
is null, then we end up in a case where it sets `checked` to
`initialChecked`:
5cbe6258bc/packages/react-dom-bindings/src/client/ReactDOMInput.js (L69)
Since we never changed `initialChecked` and it's not relevant if
non-null `checked` changes value, the only way this "change" could
trigger was if we move from having `checked` to having null.
This wasn't really consistent with how `value` works, where we instead
leave the current value in place regardless. So this is a "bug fix" that
changes `checked` to be consistent with `value` and just leave the
current value in place. This case should already have a warning in it
regardless since it's going from controlled to uncontrolled.
Related to that, there was also another issue observed in
https://github.com/facebook/react/pull/26596#discussion_r1162295872 and
https://github.com/facebook/react/pull/26588
We need to atomically apply mutations on radio buttons. I fixed this by
setting the name to empty before doing mutations to value/checked/type
in updateInput, and then set the name to whatever it should be. Setting
the name is what ends up atomically applying the changes.
---------
Co-authored-by: Sophie Alpert <git@sophiebits.com>
## Summary
Removing `enableNamedHooksFeature`, `enableProfilerChangedHookIndices`,
`enableProfilerComponentTree` feature flags, they are the same for all
configurations.
Some minor changes, observed while working on 24.7.5 release:
- Updated numeration of text instructions
- `reactjs.org` -> `react.dev`
- Fixed using `npm view` command for node 16+, `publish-release` script
currently fails if used with node 16+
Fix for bug demonstrated in #1506. When we add variables as output of their
defining scope, we need to propagate this information upwards to all parent
scopes which are not current active.
Minimal(ish) repro of a bug we saw internally, where an output of a nested
reactive scope is defined at the wrong block scope, and so later references to
that value are invalid.
The simplified structure is:
```
scope0 inputs=[] outputs=[] {
scope1 inputs=[] outputs=[t0] {
t0 = ...
}
}
t0
```
Note that `t0` correctly appears as an output of the inner scope1, but not as an
output of the outer scope0. We need to propagate outputs upward as necessary to
ensure they are available at the right block scope: in this case, that would add
`t0` as an output of scope0.
An earlier version of PropagateScopeDependencies did this but it looks like it
got lost along the way (not a big deal)
This aligns the playground configuration with our internal compiler
configuration to make it easier to repro compilation issues on playground. There
is a bug that doesn't repro right now and i suspect it's because of different
hooks being configured.
Test plan:
Before: playground output has no obvious bugs, but is different than internal
compilation output where the bug occurs
After: playground output matches internal compilation output w the bug
Builds on top of https://github.com/facebook/react/pull/26661
This lets you pass FormData objects through the Flight Reply
serialization. It does that by prefixing each entry with the ID of the
reference and then the decoding side creates a new FormData object
containing only those fields (without the prefix).
Ideally this should be more generic. E.g. you should be able to pass
Blobs, Streams and Typed Arrays by reference inside plain objects too.
You should also be able to send Blobs and FormData in the regular Flight
serialization too so that they can go both directions. They should be
symmetrical. We'll get around to adding more of those features in the
Flight protocol as we go.
---------
Co-authored-by: Sophie Alpert <git@sophiebits.com>
Making ReturnTerminal.value non-nullable broke our optimization to elide final
value-less return statements. We now check if a return value is explicitly
`undefined` and elide the value in this case, which then also propagates to
allow removing the final `return` statement of a function if the value is
missing.
Since this is an observable behavior and is hard to think about, seems
good to have tests for this.
The expected value included in each test is the behavior that existed
prior to #26546.
In
2019ddc75f,
we changed to set .defaultValue before .value on updates. In some cases,
setting .defaultValue causes .value to change, and since we only set
.value if it has the wrong value, this resulted in us not assigning to
.value, which resulted in inputValueTracking not knowing the right
value. See new test added.
My fix here is to (a) move the value setting back up first and (b)
narrowing the fix in the aforementioned PR to newly remove the value
attribute only if it defaultValue was previously present in props.
The second half is necessary because for types where the value property
and attribute are indelibly linked (hidden checkbox radio submit image
reset button, i.e. spec modes default or default/on from
https://html.spec.whatwg.org/multipage/input.html#dom-input-value-default),
we can't remove the value attribute after setting .value, because that
will undo the assignment we just did! That is, not having (b) makes all
of those types fail to handle updating props.value.
This code is incredibly hard to think about but I think this is right
(or at least, as right as the old code was) because we set .value here
only if the nextProps.value != null, and we now remove defaultValue only
if lastProps.defaultValue != null. These can't happen at the same time
because we have long warned if value and defaultValue are simultaneously
specified, and also if a component switches between controlled and
uncontrolled.
Also, it fixes the test in https://github.com/facebook/react/pull/26626.
In the extension, currently we do the following:
1. check whether there's at least one React renderer on the page
2. if yes, load the backend to the page
3. initialize the backend
To support multiple versions of backends, we are changing it to:
1. check the versions of React renders on the page
2. load corresponding React DevTools backends that are shipped with the
extension; if they are not contained (usually prod builds of
prereleases), show a UI to allow users to load them from UI
3. initialize each of the backends
To enable this workflow, a backend will ignore React renderers that does
not match its version
This PR adds a new file "backendManager" in the extension for this
purpose.
------
I've tested it on Chrome, Edge and Firefox extensions
Updates our Babel plugin to add an import to React if we succesfully compiled a
function and cached one or more values. For now this logic is entirely in the
Babel plugin itself, but long term we should move this into codegen and teach
Forget to start the pipeline by lowering the whole Program node to an HIR (which
would also allow us to understand imports and other module scope values being
used). Right now it's not possible to add in codegen (without some ugly code) as
a file containing multiple components would result in duplicate imports being
generated
Previously useMemo inlining created a new StoreLocal assignment (not
reassignment!) instruction for every return value. This breaks when the return
is inside a block (like an if-block) as the scope is tied to the block.
For example: ``` let x = useMemo(() => { if (...) { return { ... }; } })
``` would become: ``` if (...) { const temp = { ... }; } const x = temp; ```
This PR instead changes the inlining to declare a temporary in the function
prologue and then reassign values to it when replacing return statements.
``` let x = useMemo(() => { if (...) { return { ... }; } }) ```
becomes
``` let temp; if (...) { temp = { ... }; } const x = temp; ```
This lets the client bundle encode Server References without them first
being passed from an RSC payload. Like if you just import `"use server"`
from the client. A bundler could already emit these proxies to be called
on the client but the subtle difference is that those proxies couldn't
be passed back into the server by reference. They have to be registered
with React.
We don't currently implement importing `"use server"` from client
components in the reference implementation. It'd need to expand the
Webpack plugin with a loader that rewrites files with the `"use server"`
in the client bundle.
```
"use server";
export async function action() {
...
}
```
->
```
import {createServerReference} from "react-server-dom-webpack/client";
import {callServer} from "some-router/call-server";
export const action = createServerReference('1234#action', callServer);
```
The technique I use here is that the compiled output has to call
`createServerReference(id, callServer)` with the `$$id` and proxy
implementation. We then return a proxy function that is registered with
a WeakMap to the particular instance of the Flight Client.
This might be hard to implement because it requires emitting module
imports to a specific stateful runtime module in the compiler. A benefit
is that this ensures that this particular reference is locked to a
specific client if there are multiple - e.g. talking to different
servers.
It's fairly arbitrary whether we use a WeakMap technique (like we do on
the client) vs an `$$id` (like we do on the server). Not sure what's
best overall. The WeakMap is nice because it doesn't leak implementation
details that might be abused to consumers. We should probably pick one
and unify.
We currently don't just "require" a module by its module id/path. We
encode the pair of module id/path AND its export name. That's because
with module splitting, a single original module can end up in two or
more separate modules by name. Therefore the manifest files need to
encode how to require the whole module as well as how to require each
export name.
In practice, we don't currently use this because we end up forcing
Webpack to deopt and keep it together as a single module, and we don't
even have the code in the Webpack plugin to write separate values for
each export name.
The problem is with CJS we don't statically know what all the export
names will be. Since these cases will never be module split, we don't
really need to know.
This changes the Flight requires to first look for the specific name
we're loading and then if that name doesn't exist in the manifest we
fallback to looking for the `"*"` name containing the entire module and
look for the name in there at runtime.
We could probably optimize this a bit if we assume that CJS modules on
the server never get built with a name. That way we don't have to do the
failed lookup.
Additionally, since we've recently merged filepath + name into a single
string instead of two values, we now have to split those back out by
parsing the string. This is especially unfortunate for server references
since those should really not reveal what they are but be a hash or
something. The solution might just be to split them back out into two
separate fields again.
cc @shuding
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn debug-test --watch TestName`, open
`chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Browsers restore state like forms and scroll position right after the
popstate event. To make sure the page work as expected on back or
forward button, we need to flush transitions scheduled in a popstate
synchronously, and only yields if it suspends.
This PR adds a new HostConfig method to check if `window.event ===
'popstate'`, and `scheduleMicrotask` if a transition is scheduled in a
`PopStateEvent`.
## How did you test this change?
yarn test
If a Suspense fallback is shown, and the data finishes loading really
quickly after that, we throttle the content from appearing for 500ms to
reduce thrash.
This already works for successive fallback states (like if one fallback
is nested inside another) but it wasn't being applied to the final step
in the sequence: if there were no more unresolved Suspense boundaries in
the tree, the content would appear immediately.
This fixes the throttling behavior so that it applies to all renders
that are the result of suspended data being loaded. (Our internal jargon
term for this is a "retry".)
Many of our Suspense-related tests were written before the `act` API was
introduced, and use the lower level `waitFor` helpers instead. So they
are less resilient to changes in implementation details than they could
be.
This converts some of our test suite to use `act` in more places. I
found these while working on a PR to expand our fallback throttling
mechanism to include all renders that result from a promise resolving,
even if there are no more fallbacks in the tree.
I think this covers all the remaining tests that are affected.
Fixes https://github.com/facebook/react/issues/26500
## Summary
- No more using `clipboard-js` from the backend side, now emitting
custom `saveToClipboard` event, also adding corresponding listener in
`store.js`
- Not migrating to `navigator.clipboard` api yet, there were some issues
with using it on Chrome, will add more details to
https://github.com/facebook/react/pull/26539
## How did you test this change?
- Tested on Chrome, Firefox, Edge
- Tested on standalone electron app: seems like context menu is not
expected to work there (cannot right-click on value, the menu is not
appearing), other logic (pressing on copy icon) was not changed
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Addresses #26352.
This PR explicitly passes an icon to `chrome.devtools.panels.create()`,
so that edge devtools will display the icon when in [Focus
Mode](https://learn.microsoft.com/en-us/microsoft-edge/devtools-guide-chromium/experimental-features/focus-mode).
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
Passing test suite (`yarn test` & `yarn test --prod`) ✅
Passing lint (`yarn linc`) ✅
Passing type checks (`yarn flow`) ✅
**Visual Testing**
Before Changes | After Changes
:-------------------------:|:-------------------------:

|

<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
Many of our Suspense-related tests were written before the `act` API was
introduced, and use the lower level `waitFor` helpers instead. So they
are less resilient to changes in implementation details than they could
be.
This converts some of our test suite to use `act` in more places. I
found these while working on a PR to expand our fallback throttling
mechanism to include all renders that result from a promise resolving,
even if there are no more fallbacks in the tree. This isn't all the
affected tests, just some of them — I'll be sharding the changes across
multiple PRs.
Since `props.x` is a possibly megamorphic access, it can be slow to
access and trigger recompilation.
When we are looping over the props and pattern matching every key,
anyway, we've already done this work. We can just reuse the same value
by stashing it outside the loop in the stack.
This only makes sense for updates in diffInCommitPhase since otherwise
we don't have the full set of props in that loop.
We also have to be careful not to skip over equal values since we need
to extract them anyway.
This traces back to https://github.com/facebook/react/pull/6449 and then
another before that.
I think that back then we favored the property over the attribute, and
setting the property wouldn't be enough. However, the default path for
these are now using attributes if we don't special case it. So we don't
need it.
The only difference is that we currently have a divergence for
symbol/function behavior between controlled values that use the
getToStringValue helpers which treat them as empty string, where as
everywhere else they're treated as null/missing.
Since this comes with a warning and is a weird error case, it's probably
fine to change.
Updates that are marked as part of a transition are allowed to block a
render from committing. Generally, other updates cannot — however,
there's one exception that's leftover from a previous iteration of our
Suspense architecture. If an update is not the result of a known urgent
event type — known as "Default" updates — then we allow it to suspend
briefly, as long as the delay is short enough that the user won't
notice. We refer to this delay as a "Just Noticable Difference" (JND)
delay. To illustrate, if the user has already waited 400ms for an update
to be reflected on the screen, the theory is that they won't notice if
you wait an additional 100ms. So React can suspend for a bit longer in
case more data comes in. The longer the user has already waited, the
longer the JND.
While we still believe this theory is sound from a UX perspective, we no
longer think the implementation complexity is worth it. The main thing
that's changed is how we handle Default updates. We used to render
Default updates concurrently (i.e. they were time sliced, and were
scheduled with postTask), but now they are blocking. Soon, they will
also be scheduled with rAF, too, which means by the end of the next rAF,
they will have either finished rendering or the main thread will be
blocked until they do. There are various motivations for this but part
of the rationale is that anything that can be made non-blocking should
be marked as a Transition, anyway, so it's not worth adding
implementation complexity to Default.
This commit removes the JND delay for Default updates. They will now
commit immediately once the render phase is complete, even if a
component suspends.
This removes the concept of `prepareUpdate()`, behind a flag.
React Native already does everything in the commit phase, but generates
a temporary update payload before applying it.
React Fabric does it both in the render phase. Now it just moves it to a
single host config.
For DOM I forked updateProperties into one that does diffing and
updating in one pass vs just applying a pre-diffed updatePayload.
There are a few downsides of this approach:
- If only "children" has changed, we end up scheduling an update to be
done in the commit phase. Since we traverse through it anyway, it's
probably not much extra.
- It does more work in the commit phase so for a large tree that is
mostly unchanged, it'll stall longer.
- It does some extra work for special cases since that work happens if
anything has changed. We no longer have a deep bailout.
- The special cases now have to each replicate the "clean up old props"
loop, leading to extra code.
The benefit is that this doesn't allocate temporary extra objects
(possibly multiple per element if the array has to resize). It's less
work overall. It also gives us an option to reuse this function for a
sync render optimization.
Another benefit is that if we do the loop in the commit phase I can do
further optimizations by reading all props that I need for special cases
in that loop instead of polymorphic reads from props. This is what I'd
like to do in future refactors that would be stacked on top of this
change.
We have moved away from HostConfig since the name does not fully
describe the configs we customize per runtime like FlightClient,
FlightServer, Fizz, and Fiber. This commit generalizes $$$hostconfig to
$$$config
part of https://github.com/facebook/react/pull/26571
merging separately to improve tracking of files renames in git
Rename HostConfig files to FiberConfig to clarify they are configs for
Fiber and not Fizz/Flight. This better conforms to the naming used in
Flight and now Fizz of `ReactFlightServerConfig` and `ReactFizzConfig`
Part of https://github.com/facebook/react/pull/26571
Implements wiring for Flight to have it's own "HostConfig" from Fizz.
Historically the ServerFormatConfigs were supposed to be generic enough
to be used by Fizz and Flight. However with the addition of features
like Float the configs have evolved to be more specific to the renderer.
We may want to get back to a place where there is a pure FormatConfig
which can be shared but for now we are embracing the fact that these
runtimes need very different things and DCE cannot adequately remove the
unused stuff for Fizz when pulling this dep into Flight so we are going
to fork the configs and just maintain separate ones.
At first the Flight config will be almost empty but once Float support
in Flight lands it will have a more complex implementation
Additionally this commit normalizes the component files which make up
FlightServerConfig and FlightClientConfig. Now each file that
participates starts with ReactFlightServerConfig... and
ReactFlightClientConfig...
## Summary
This pull request aims to improve the maintainability of the codebase by
consolidating types and constants that are shared between the backend
and frontend. This consolidation will allow us to maintain backwards
compatibility in the frontend in the future.
To achieve this, we have moved the shared types and constants to the
following blessed files:
- react-devtools-shared/src/constants
- react-devtools-shared/src/types
- react-devtools-shared/src/backend/types
- react-devtools-shared/src/backend/NativeStyleEditor/types
Please note that the inclusion of NativeStyleEditor in this list is
temporary, and we plan to remove it once we have a better plugin system
in place.
## How did you test this change?
I have tested it by running `yarn flow dom-node`, which reports no
errors.
`act` uses the `didScheduleLegacyUpdate` field to simulate the behavior
of batching in React <17 and below. It's a quirk leftover from a
previous implementation, not intentionally designed.
This sets `didScheduleLegacyUpdate` every time a legacy root receives an
update as opposed to only when the `executionContext` is empty. There's
no real reason to do it this way over some other way except that it's
how it used to work before #26512 and we should try our best to maintain
the existing behavior, quirks and all, since existing tests may have
come to accidentally rely on it.
This should fix some (though not all) of the internal Meta tests that
started failing after #26512 landed.
Will add a regression test before merging.
In #26573 I changed it so that textareas get their defaultValue reset if
you don't specify one.
However, the way that was implemented, it always set it for any update
even if it hasn't changed.
We have a test for that, but that test only works if no properties
update at all so that no update was scheduled. This fixes the test so
that it updates some unrelated prop.
I also found a test for `checked` that needed a similar fix.
Interestingly, we don't do this deduping for `defaultValue` or
`defaultChecked` on inputs and there's no test for that.
This is mainly renaming some stuff. The behavior change is
hasOwnProperty to nullish check.
I had a bigger refactor that was a dead-end but might as well land this
part and see if I can pick it up later.
This is a simplified version of #1454. The goal of this PR is to inline the
contents of `useMemo()` callbacks, rather than just immediately invoke the
lambda. Turning useMemo() into an IIFE works, but it means that we can't
optimize within the lambda block. Our investigations showed that there's a lot
of room to optimize at a finer granularity than manually written useMemo calls.
For example, one product instance had a useMemo that created a list of child JSX
elements. Most of those elements only relied on a single variable (`a`), but a
few relied on a second variable (`b). Thus _all_ elements were invalidated
whenever `b` changed. If Forget retains the original lambda, we have no choice
but to keep that (coarse) granularity for memoization. When we inline, we can
optimize to make e.g. individual JSX elements depend on their precise
dependencies.
The rough idea is:
* Keep track of all function expressions
* When we find a useMemo, lookup its function expression, and add its CFG to the
main function (the previous PR ensures that BlockIds won't collide)
* Replace any return statements with a StoreLocal to save the result and a Goto
to the code following the useMemo call.
* Then we run the usual set of passes to patch the HIR back up again.
Example:
```javascript
// Before
function Component(props) {
const x = useMemo(() => {
if (props.cond) {
return null;
}
return foo(props.x);
}, [props.x]);
return x + props.y;
}
// Intended - **before** memoization
function Component(props) {
let x;
if (props.cond) {
x = null;
} else {
x = foo(props.x);
}
return x + props.y;
}
```
Currently, `waitForThrow` tries to diff the expected value against the
thrown value if it doesn't match. However if the expectation is a
string, we are not diffing against the thrown message. This commit makes
it so if we are matching against message we also diff against message.
## Summary
- #26234 is reverted and replaced with a better approach
- introduce a new global devtools variable to decouple the global hook's
dependency on backend/console.js, and add it to react-devtools-inline
and react-devtools-standalone
With this PR, I want to introduce a new principle to hook.js: we should
always be alert when editing this file and avoid importing from other
files.
In the past, we try to inline a lot of the implementation because we use
`.toString()` to inject this function from the extension (we still have
some old comments left). Although it is no longer inlined that way, it
has became now more important to keep it clean as it is a de facto
global API people are using (9.9K files contains it on Github search as
of today).
**File size change for extension:**
Before:
379K installHook.js
After:
21K installHook.js
363K renderer.js
This PR ensures (via a static assertion function) that all terminal variants
have a SourceLocation, and adds locations to the variants which didn't have it
before. This also adds a static assertion that terminals have an InstructionId,
though we already relied on that so it was checked via usage.
This is a prerequisite to inlining `useMemo()` lambdas so that we can better
optimize them. Nested functions are evaluated with a fresh HIRBuilder, which
means that they currently have their own `bindings` object for mapping
identifier instances to IdentifierIds. This means that identifier ids in a
closure are _always_ different that those outside the closure, even when they
refer to the same identifier:
```
function Component(props) {
props; // becomes e.g. props$1
const onClick = () => {
props // becomes e.g. props$2
};
}
```
For useMemo inlining this is problematic because we've lost the association that
these identifiers actually refer to the same thing. This PR changes that,
sharing the name resolution data structure between the top-level function and
any nested function expressions.
To unblock internal experimentation, for now let's just skip over compiling any
file that contains one or more disables of React's eslint rules, and log that.
This is a little coarse in the sense that we could skip over just functions that
contain the comments, but Babel doesn't provide an easy way to traverse comments
afaict so this is the simplest solution. I did check our internal repo and noted
that there was only one disable of exhaustive-hooks in that entire directory in
one file, so this should be fine.
Notably we are not throwing any errors if we detect these violations as we don't
want to fail the build, we just want to skip them for now.
This fixes the "double free" bug illustrated by the regression test
added in the previous commit.
The underlying issue is that `effect.destroy` field is a mutable field
but we read it during render. This is a concurrency bug — if we had a
borrow checker, it would not allow this.
It's rare in practice today because the field is updated during the
commit phase, which takes a lock on the fiber tree until all the effects
have fired. But it's still theoretically wrong because you can have
multiple Fiber copies each with their own reference to a single destroy
function, and indeed we discovered in production a scenario where this
happens via our current APIs.
In the future these types of scenarios will be much more common because
we will introduce features where effects may run concurrently with the
render phase — i.e. an imperative `hide` method that synchronously hides
a React tree and unmounts all its effects without entering the render
phase, and without interrupting a render phase that's already in
progress.
A future version of React may also be able to run the entire commit
phase concurrently with a subsequent render phase. We can't do this now
because our data structures are not fully thread safe (see: the Fiber
alternate model) but we should be able to do this in the future.
The fix I've introduced in this commit is to move the `destroy` field to
a separate object. The effect "instance" is a shared object that remains
the same for the entire lifetime of an effect. In Rust terms, a RefCell.
The field is `undefined` if the effect is unmounted, or if the effect
ran but is not stateful. We don't explicitly track whether the effect is
mounted or unmounted because that can be inferred by the hiddenness of
the fiber in the tree, i.e. whether there is a hidden Offscreen fiber
above it.
It's unfortunate that this is stored on a separate object, because it
adds more memory per effect instance, but it's conceptually sound. I
think there's likely a better data structure we could use for effects;
perhaps just one array of effect instances per fiber. But I think this
is OK for now despite the additional memory and we can follow up with
performance optimizations later.
---------
Co-authored-by: Dan Abramov <dan.abramov@gmail.com>
Co-authored-by: Rick Hanlon <rickhanlonii@gmail.com>
Co-authored-by: Jan Kassens <jan@kassens.net>
While running the latest Forget build on www I noticed that a lot of the
bailouts were special-cases where we used interpolation in the error `reason`
string to provide more context for debugging. This is a pretty cool result,
because it means that we actually support nearly all the common syntax (at least
based on a sample of the codebase). But it makes our tools for aggregating
errors break down a bit.
This PR adds a new, nullable `description` property to CompilerErrorDetail, and
manually updates to ensure that we always pass a static `reason` and only use
interpolation in the `description`. This will allow our aggregation tools to
group by the reason.
## Summary
The electron package was recently upgraded from ^11.1.0 to ^23.1.2
(#26337). However, the WebContents `new-window` event – that is used in
the react-devtools project – was deprecated in
[v12.0.0](https://releases.electronjs.org/release/v12.0.0) and removed
in [v22.2.0](https://releases.electronjs.org/release/v22.2.0). The event
was replaced by `webContents.setWindowOpenHandler()`. This PR replaces
the `new-window` event with `webContents.setWindowOpenHandler()`.
## How did you test this change?
I created a simple electron application with similar functionality:
```
const { app, BrowserWindow, shell } = require('electron')
const createWindow = () => {
const mainWindow = new BrowserWindow({
width: 800,
height: 600
})
mainWindow.webContents.setWindowOpenHandler(({ url }) => {
shell.openExternal(url)
return { action: 'deny' }
})
mainWindow.loadFile('index.html')
}
app.whenReady().then(() => {
createWindow()
})
```
---------
Co-authored-by: root <root@DESKTOP-KCGHLB8.localdomain>
NOTE: See background in #1476.
Updates BuildHIR to use the new LabelTerminal for LabeledStatements, and adds
support for HIR->ReactiveFunction transformation and codegen. Note that we
sometimes produce an extraneous block wrapper if it turns out the label wasn't
necessary, that seems...fine?
Adds a new `LabelTerminal` which will be used to represent LabeledStatements
that contain a statement other than a loop. What we do for these cases is
basically break the containing block in two, with a goto after the inner
statement to the fallthrough. This allows us to model the label, and any `break`
to it, in the HIR. However this fails in codegen because we can't find the
fallthrough branch — we need a high level terminal that knows about this
structure.
Hence LabelTerminal. Now, instead of just a continuation block and a goto, we
have a structured terminal. The LabelTerminal expresses the block for the
labeled statement and the continuation, and we can use this to put it back
together when constructing a ReactiveFunction. Note that this PR is just the
scaffolding for LabelTerminal, the next PR is the interesting bits.
Adds a script to automate adding/updating the copyright header to all
appropriate files. For now i've excluded fixture inputs, just because it would
impact fixture outputs too, but we can add them in a later PR if we want.
Type inference currently assumes that a `FunctionSignature`'s effects have no
false positives. If a `mutate` effect is observed on a read-only place, Forget
currently assumes this is an user error and
[throws](207595e04e/forget/src/Inference/InferReferenceEffects.ts (L275-L281)).
Array.from is polymorphic -- its effects are dependent on the type of its
parameters
This PR ensures that we use a single id space for the `BlockId`s in both
top-level functions as well as any nested FunctionExpressions (note, we already
do this for `IdentifierId`). This will make it easier for follow-ups to merge
the CFG of nested functions (ie useMemo bodies) with the parent without block id
collisions.
This is a follow up to https://github.com/facebook/react/pull/26546
This is strictly a perf optimization since we know that switches over
strings aren't optimally implemented in current engines. Basically
they're a sequence of ifs.
As a result, we're better off putting the unusual cases in a Map and the
very common cases in the beginning of the switch. We might be better off
putting very common cases in explicit ifs - just in case the engine does
optimize switches to a hash table which is potentially worse.
---------
Co-authored-by: Sophie Alpert <git@sophiebits.com>
Fixes `<fbt>`. This required a bunk of yak shaving to work through several
issues:
* First, there was a bug in codegen for JsxNamedspacedName. I added handling for
it for identifiers, but JsxNamespacedName gets converted to a Primitive. The
output looked correct because Babel happily creates invalid Jsx identifiers!
* Next, I needed to add locations to JSX nodes. It took me a while to pinpoint
which specific node needed the location, so I ended up just adding locations to
all the parts of a Jsx element.
* That uncovered the fact that FBT was expecting the `<fbt:param>`'s `name`
attribute value to be a StringLiteral, not a StringLiteral wrapped in a
JsxExpressionContainer. So now we special-case JsxAttribute and emit raw
StringLiteral (either is allowed per the spec)
And with that, voila, `<fbt>` works.
Adds the two FBT (https://facebook.github.io/fbt/) plugins to our test setup so
that we can verify Forget plays well with FBT. Unfortunately FBT's plugins are a
bit finicky, and things that are technically allowed per the JSX spec (such as
wrapping string attribute values in a JsxExpressionContainer) aren't supported
by FBT's plugin. This PR is just to add the fbt plugins and highlight some cases
that fail; these are fixed in later PRs in the stack.
For example, the `fbt-params.js` fixture fails on this PR:
Input
```error.fbt-params.js
import fbt from "fbt";
function Component(props) {
return (
<fbt desc={"Dialog to show to user"}>
Hello <fbt:param name="user name">{props.name}</fbt:param>
</fbt>
);
}
```
Output
```
React Forget › __tests__/fixtures/compiler › fixtures › fbt-params
Expected fixture 'fbt-params' to succeed but it failed with error:
/Users/joesavona/github/react-forget/forget/fbt-params: fbt: unsupported babel
node: MemberExpression
---
props.name
---
```
See fixes later in the stack.
Adds support for `for` statements with an empty or unreachable update
expression. In both cases, reversePostorderBlocks() will remove the
empty/unreachable update block, leaving the ForTerminal.update pointing to a
non-existent block. We explicitly rewrite this (much like we null out
unreachable fallthroughs after shrink). When transforming to ReactiveFunction,
we emit the update block as null if it was the same as the test block.
Fix for the previous issue, suggested by @gsathya: when we run
InferReferenceEffects on the outer function we check each closure to see if it
actually captured any mutable values. If it didn't, we can mark the closure as
readonly and memoize it independently.
Repro of a closure that we currently treat as readonly because it captures a
possibly-mutable value, but which we later realize is not mutable. Specifically,
when we check `exit()` we think `dispatch()` is mutable and therefore consider
it captured, which means we can't independently memoize `exit`.
Updates `PruneNonEscapingScopes` to consider hook arguments as potentially
escaping. This is because hook inputs are "owned" by React — for example,
closures passed to `useEffect`, or a value that is passed to a custom hook and
which then becomes a memoized input.
## Summary
First three parameters of `findInstanceBlockingEvent` are unused since I
think if we remove the unused parameters it makes it easier to know that
which parameters is need by `findInstanceBlockingEvent`.
## How did you test this change?
Existing tests.
There are four places we have special cases based off the DOMProperty
config:
1) DEV-only: ReactDOMUnknownPropertyHook warns for passing booleans to
non-boolean attributes. We just need a simple list of all properties
that are affected by that. We could probably move this in under setProp
instead and have it covered by that list.
2) DEV-only: Hydration. This just needs to read the value from an
attribute and compare it to what we'd expect to see if it was rendered
on the client. This could use some simplification/unification of the
code but I decided to just keep it simple and duplicated since code size
isn't an issue.
3) DOMServerFormatConfig pushAttribute: This just maps the special case
to how to emit it as a HTML attribute.
4) ReactDOMComponent setProp: This just maps the special case to how to
emit it as setAttribute or removeAttribute.
Basically we just have to remember to keep pushAttribute and setProp
aligned. There's only one long switch in prod per environment.
This just turns it all to a giant simple switch statement with string
cases. This is in theory the most optimizable since syntactically all
the information for a hash table is there. However, unfortunately we
know that most VMs don't optimize this very well and instead just turn
them into a bunch of ifs. JSC is best. We can minimize the cost by just
moving common attribute to the beginning of the list.
If we shipped this, maybe VMs will get it together to start optimizing
this case but there's a chicken and egg problem here and the game theory
reality is that we probably don't want to regress. Therefore, I intend
to do a follow up after landing this which reintroduces an object
indirection for simple property aliases. That should be enough to make
the remaining cases palatable. I'll also extract the most common
attributes to the beginning or separate ifs.
Ran attribute-behavior fixture and the table is the same.
We shouldn't be referencing internal fields like fiber's `flag` directly
of DevTools. It's an implementation detail. However, over the years a
few of these have snuck in. Because of how DevTools is currently
shipped, where it's expected to be backwards compatible with older
versions of React, this prevents us from refactoring those fields inside
the reconciler.
The plan we have to address this is to fix how DevTools is shipped:
DevTools will be released in lockstep with each version of React.
Until then, though, I need a temporary solution because it's blocking a
feature I'm working on. So in meantime, I'm going to have to fork the
DevTool's code based on the React version, like we already do with the
fiber TypeOfWork enum.
As a first step, I've inlined all the references to fiber flags into the
specific call sites where they are used. Eventually we'll import these
functions from the reconciler so they stay in sync, rather than
maintaining duplicate copies of the logic.
This reverts commit b2ae9ddb3b.
While the feature flag is fully rolled out, these tests are also testing
behavior set with an unstable flag on root, which for now we want to
preserve.
Not sure if there's a better way then adding a dynamic feature flag to
the www build?
## Summary
This adds the ability to create public instances for text nodes in
Fabric. The implementation for the public instances lives in React
Native (as it does for host components after #26437). The logic here
just handles their lazy instantiation when requested via
`getPublicInstanceFromInternalInstanceHandle`, which is called by Fabric
with information coming from the shadow tree.
It's important that the creation of public instances for text nodes is
done lazily to avoid regressing memory usage when unused. Instances for
text nodes are left intact if the public instance is never accessed.
This is necessary to implement access to text nodes in React Native as
explained in
https://github.com/react-native-community/discussions-and-proposals/pull/607
## How did you test this change?
Added unit tests (also fixed a test that was only testing the logic in a
mock :S).
Similar to what we did for `<fbt>` jsx elements, this PR ensures that `fbt()`
calls have their operands memoized in the same scope to honor the limited
contract for what's allowed as an argument of an fbt() call expression.
There was a bug in the attribute seralization for stylesheet resources
injected by the Fizz runtime. For boolean properties the attribute value
was set to an empty string but later immediately set to a string coerced
value. This PR fixes that bug and refactors the code paths to be clearer
## Summary
Fixes https://github.com/facebook/react/issues/24781
Restricting from editing props, which are class instances, because their
internals should be opaque.
Proposed changes:
1. Adding new data type `class_instance`: based on prototype chain of an
object we will check if its plain or not. If not, then will be marked as
`class_instance`. This should not affect `arrays`, ..., because we do
this in the end of an `object` case in `getDataType` function.
Important detail: this approach won't work for objects created with
`Object.create`, because of the custom prototype. This can also be
bypassed by manually deleting a prototype ¯\\\_(ツ)_/¯
I am not sure if there might be a better solution (which will cover all
cases) to detect if object is a class instance. Initially I was trying
to use `Object.getPrototypeOf(object) === Object.prototype`, but this
won't work for cases when we are dealing with `iframe`.
2. Objects with a type `class_instance` will be marked as unserializable
and read-only.
## Demo
`person` is a class instance, `object` is a plain object
https://user-images.githubusercontent.com/28902667/228914791-ebdc8ab0-eb5c-426d-8163-66d56b5e8790.mov
There are some internal restrictions in Metro that only allow us to specify one
gating module as an injected dependency. To allow multiple projects, this PR
updates the Babel plugin to take a gating options config specifiying a project
name. The project name is used as a suffix for the generated import; for
example:
```js
const options = {
// ...
gating: {
module: "ReactForgetFeatureFlag",
importSpecifierName: "isForgetEnabled_Secret",
};
// generates
import {isForgetEnabled_Secret} from "ReactForgetFeatureFlag"; // a module that
exports multiple flags
// ...
```
We almost never want to show content before its styles have loaded. But
eventually we will give up and allow unstyled content. So this extends
the timeout to a full minute. This somewhat arbitrary — big enough that
you'd only reach it under extreme circumstances.
Note that, like regular Suspense, the app is still interactive while
we're waiting for content to load. Only the unstyled content is blocked
from appearing, not updates in general. A new update will interrupt it.
We should figure out what the browser engines do during initial page
load and consider aligning our behavior with that. It's supposed to be
render blocking by default but there may be some cases where they, too,
give up and FOUC.
I originally made it so that a Suspensey commit — i.e. a commit that's
waiting for a stylesheet, image, or font to load before proceeding —
could not be interrupted by transitions. My reasoning was that Suspensey
commits always time out after a short interval, anyway, so if the
incoming update isn't urgent, it's better to wait to commit the current
frame instead of throwing it away.
I don't think this rationale was correct, for a few reasons. There are
some cases where we'll suspend for a longer duration, like stylesheets —
it's nearly always a bad idea to show content before its styles have
loaded, so we're going to be extend this timeout to be really long.
But even in the case where the timeout is shorter, like fonts, if you
get a new update, it's possible (even likely) that update will allow us
to avoid showing a fallback, like by navigating to a different page. So
we might as well try.
The behavior now matches our behavior for interrupting a suspended
render phase (i.e. `use`), which makes sense because they're not that
conceptually different.
When React receives new input (via `setState`, a Suspense promise
resolution, and so on), it needs to ensure there's a rendering task
associated with the update. Most of this happens
`ensureRootIsScheduled`.
If a single event contains multiple updates, we end up running the
scheduling code once per update. But this is wasteful because we really
only need to run it once, at the end of the event (or in the case of
flushSync, at the end of the scope function's execution).
So this PR moves the scheduling logic to happen in a microtask instead.
In some cases, we will force it run earlier than that, like for
`flushSync`, but since updates are batched by default, it will almost
always happen in the microtask. Even for discrete updates.
In production, this should have no observable behavior difference. In a
testing environment that uses `act`, this should also not have a
behavior difference because React will push these tasks to an internal
`act` queue.
However, tests that do not use `act` and do not simulate an actual
production environment (like an e2e test) may be affected. For example,
before this change, if a test were to call `setState` outside of `act`
and then immediately call `jest.runAllTimers()`, the update would be
synchronously applied. After this change, that will no longer work
because the rendering task (a timer, in this case) isn't scheduled until
after the microtask queue has run.
I don't expect this to be an issue in practice because most people do
not write their tests this way. They either use `act`, or they write
e2e-style tests.
The biggest exception has been... our own internal test suite. Until
recently, many of our tests were written in a way that accidentally
relied on the updates being scheduled synchronously. Over the past few
weeks, @tyao1 and I have gradually converted the test suite to use a new
set of testing helpers that are resilient to this implementation detail.
(There are also some old Relay tests that were written in the style of
React's internal test suite. Those will need to be fixed, too.)
The larger motivation behind this change, aside from a minor performance
improvement, is we intend to use this new microtask to perform
additional logic that doesn't yet exist. Like inferring the priority of
a custom event.
This is a Meta-ism, but adding it for now to unblock. We special-case the
`<fbt>` element for translation purposes, and have a transform that requires the
children of this element to be a limited subset of nodes. Notably, any dynamic
translation values must appear as `<fbt:param>` children — we disallow
identifiers as children of `<fbt>` nodes.
This PR adds a new pass which finds `<fbt>` nodes and ensures their immediate
operands are not independently memoized. Note that this still allows the values
of `<fbt:param>` to be independently memoized, as demonstrated in the unit test.
This flag is already enabled everywhere except for www, which is blocked
by a few tests that assert on the old behavior. Once www is ready, I'll
land this.
```js
// here, `a?.b.c` is a single optional chain
// (evaluates to undefined if a is nullish)
a?.b.c;
// here, 'a?.b` is an optional chain, and `.c` is an unconditional load
// (nullthrows if a is nullish)
(a?.b).c;
```
---
Next PR in stack will add a bailout for `(a?.b).c`.
(If we want to properly handle `(a?.b).c`, we might want to model optional
chains explicitly in the HIR. We currently assume that any `PropertyLoad` whose
lhs is an optional property load is read conditionally.)
This is incredibly obvious in hindsight, but for exposure logging to work
correctly we need to *call* the underlying `MobileConfig.getBool` function at
the callsite – otherwise the bool is evaluated once (and only once) when the
module is loaded.
Tested internally and verified that in dogfooding the exposure logging was
working correctly
This PR has a bunch of surrounding refactoring. See individual commits.
The main change is that we no longer special case `typeof is ===
'string'` as a special case according to the
`enableCustomElementPropertySupport` flag.
Effectively this means that you can't use custom properties/events,
other than the ones React knows about on `<input is="my-input">`
extensions.
This is unfortunate but there's too many paths that are forked in
inconsistent ways since we fork based on tag name. I think __the
solution is to let all React elements set unknown properties/events in
the same way as this flag__ but that's a bigger change than this flag
implies.
Since `is` is not universally supported yet anyway, this doesn't seem
like a huge loss. Attributes still work.
We still support passing the `is` prop and turn that into the
appropriate createElement call.
@josepharhar
## Summary
Our toy webpack plugin for Server Components is pretty broken right now
because, now that `.client.js` convention is gone, it ends up adding
every single JS file it can find (including `node_modules`) as a
potential async dependency. Instead, it should only look for files with
the `'use client'` directive.
The ideal way is to implement this by bundling the RSC graph first.
Then, we would know which `'use client'` files were actually discovered
— and so there would be no point to scanning the disk for them. That's
how Next.js bundler does it.
We're not doing that here.
This toy plugin is very simple, and I'm not planning to do heavy
lifting. I'm just bringing it up to date with the convention. The change
is that we now read every file we discover (alas), bail if it has no
`'use client'`, and parse it if it does (to verify it's actually used as
a directive). I've changed to use `acorn-loose` because it's forgiving
of JSX (and likely TypeScript/Flow). Otherwise, this wouldn't work on
uncompiled source.
## Test plan
Verified I can get our initial Server Components Demo running after this
change. Previously, it would get stuck compiling and then emit thousands
of errors.
Also confirmed the fixture still works. (It doesn’t work correctly on
the first load after dev server starts, but that’s already the case on
main so seems unrelated.)
Normally we allow any attribute/property on custom elements. However
it's a shared namespace. The `aria-` namespace applies to all generic
elements which are shared with custom elements. So arguably adding
custom extensions there is a really bad idea since it can conflict with
future additions.
It's possible there is a new standard one that's polyfilled by a custom
element but the same issue applies to React in general that we might
warn for very new additions so we just have to be quick on that.
cc @josepharhar
- Fixes a missing break in InferTypes - I disabled no-fallthrough previously
because it would erroneously report that certain cases with non-builtin throws
(eg `invariant`) would fall through. This brings the rule back but allows
disabling it with a `// break omitted` comment, since it's still helpful in
catching some actual missing breaks.
- Add `DEFAULT_SHAPES` ShapeRegistry, which holds builtins and all
`ObjectShapes` used in `DEFAULT_GLOBALS`.
- Add a few typed objects / functions into `DEFAULT_GLOBALS` (used for tests)
- Add type inference and `infer-global-object` test
Adds `GlobalRegistry`, which holds the names and types of known global objects,
i.e.
```js
type GlobalRegistry = Map<string, PrimitiveType | ObjectType | FunctionType |
HookType | PolyType>;
// ...
globalRegistry.get("NaN"); // {kind: "Primitive"}
globalRegistry.get("parseInt"); // {kind: "Function", shapeId: "..."}
globalRegistry.get("Math"); // {kind: "Object", shapeId: "..."}
```
Since we currently do not track module imports and module-level declarations,
builtin and custom hooks currently also live in GlobalRegistry.
```js
globalRegistry.get("useState"); // {kind: "Hook", definition: {...}}
globalRegistry.get("useFreeze"); // {kind: Hook, definition: {...}}
```
This PR does not allow Forget users to define their own globals. When we add
this as a configuration, we should not expose `ShapeRegistry` to the user, as a
user-provided ShapeRegistry may accidentally be not well formed. (i.e. missing
(1) required shapes (BuiltInArray for [] and BuiltInObject for {}) or (2) some
recursive shapeIds)
```js
export type UserType = UserObject | UserFunction | "Primitive" | "BuiltinObject"
| ...;
export type UserObject = {
kind: "Object",
properties: Map<string, UserType>
}
export type UserFunction = {
kind: "Function",
properties: Map<string, UserType>,
signature: ...
}
export type UserGlobals = Map<string, UserType>;
class Environment {
constructor(globals: Map<string, UserType>, ...) {
// ...
addUserDefinedGlobals(this.#globals, this.#shapes);
```
---
Simplify Environment options by:
- EnvironmentOptions -> EnvironmentConfig
config is now directly passed around instead of being eagerly merged.
- Moving merging / initialization logic into `Environment` constructor. From my
understanding, there is no need to decouple merged options from an environment.
This prepares Environment for the next PR, which adds non-stateful properties to
Environment (i.e. a `GlobalRegistry`) that should be converted from config
values (i.e. not directly exposed to the user due to potentially inconsistent
inputs)
---
#1254 added inference for hooks loaded from globals. This is the only time we
need to generate a type equation assigning `lval` to a resolved`Hook` type.
@gsathya Would love to get your feedback here on the change. From my
understanding, this change is technically incorrect, since the type equation we
generate should be dependent on the `callee` type (i.e. `Hook` if callee is a
hook, `Function` if callee is a function).
Would the next step be to consolidate `Hook` and `Function` types?
```js
type Function {
...
isHook: boolean, // set by inference
}
type FunctionSignature {
isHook: boolean, // set when adding to ShapeRegistry
}
```
This is a step towards getting rid of the meta programming in
DOMProperty and CSSProperty.
This moves isAttributeNameSafe and isUnitlessNumber to a separate shared
modules.
isUnitlessNumber is now a single switch instead of meta-programming.
There is a slight behavior change here in that I hard code a specific
set of vendor-prefixed attributes instead of prefixing all the unitless
properties. I based this list on what getComputedStyle returns in
current browsers. I removed Opera prefixes because they were [removed in
Opera](https://dev.opera.com/blog/css-vendor-prefixes-in-opera-12-50-snapshots/)
itself. I included the ms ones mentioned [in the original
PR](5abcce5343).
These shouldn't really be used anymore anyway so should be pretty safe.
Worst case, they'll fallback to the other property if you specify both.
Finally I inline the mustUseProperty special cases - which are also the
only thing that uses propertyName. These are really all controlled
components and all booleans.
I'm making a small breaking change here by treating `checked` and
`selected` specially only on the `input` and `option` tags instead of
all tags. That's because those are the only DOM nodes that actually have
those properties but we used to set them as expandos instead of
attributes before. That's why one of the tests is updated to now use
`input` instead of testing an expando on a `div` which isn't a real use
case. Interestingly this also uncovered that we update checked twice for
some reason but keeping that logic for now.
Ideally `multiple` and `muted` should move into `select` and
`audio`/`video` respectively for the same reason.
No change to the attribute-behavior fixture.
This is a change to some undefined behavior that we though we would do
at one point but decided not to roll out. It's already disabled
everywhere, so this just deletes the branch from the implementation and
the tests.
## Summary
Updates the `useMemoCache()` tests to validate that the memo cache
persists when a component does a setState during render or throws during
render. Forget's compilation output follows the general pattern used in
this test and is resilient to rendering running partway and then again
with different inputs.
## How did you test this change?
`yarn test` (this is a test-only change)
This is not really part of the bindings, it's more part of the package
entry points. /shared/ is not really right neither because it's more
like an isomorphic entry point and not some utility.
We currently throw an error when disableJavaScriptURLs is on and trigger
an error boundary. I kind of thought that's what would happen with CSP
or Trusted Types anyway. However, that's not what happens. Instead, in
those environments what happens is that the error is triggered when you
try to actually visit those links. So if you `preventDefault()` or
something it'll never show up and since the error just logs to the
console or to a violation logger, it's effectively a noop to users.
We can simulate the same without CSP by simply generating a different
`javascript:` url that throws instead of executing the potential attack
vector.
This still allows these to be used - at least as long as you
preventDefault before using them in practice. This might be legit for
forms. We still don't recommend using them for links-as-buttons since
it'll be possible to "Open in a New Tab" and other weird artifacts. For
links we still recommend the technique of assigning a button role etc.
It also is a little nicer when an attack actually happens because at
least it doesn't allow an attacker to trigger error boundaries and
effectively deny access to a page.
This deletes the ReactIncrementalTriangle test suite, which I originally
added back in 2017 when I was working on Fiber's "resuming" feature. It
was meant to simulate a similar scenario as Seb's "Sierpinski Triangle"
Fiber demo.
We eventually ended up removing resuming, but we kept this fuzz tester
around since it wasn't really harming anything. However, over the years,
we've had to make many small tweaks to decouple it from implementation
details, to the point that it doesn't test anything useful anymore. And
the thing that it originally tested has long since been removed.
If or when we do add back resuming, we would write a different fuzz
tester from scratch rather than build on this one.
So rather than continue to contrive ways to prevent it from breaking, I
propose we delete it.
We still have other fuzz testers for things like Suspense and context
propagation. Only this particular one has outlived its usefulness.
## Summary
With https://github.com/facebook/react/pull/26349 we now serialize
`undefined`. However, deserializing it on the client is currently
indistinguishable from the value missing entirely due to how
`JSON.parse` treats `undefined` return value of reviver functions.
This leads to inconsistent behavior of the `Object.hasOwn` or `in`
operator (used for narrowing in TypeScript). In TypeScript-speak, `{
prop: T | undefined}` will arrive as `{ prop?: T }`.
## How did you test this change?
- Added test that is expected to fail. Though ideally the implementation
of the component would not care whether it's used on the client or
server.
I use a shared helper when setting properties into a helper whether it's
initial or update.
I moved the special cases per tag to commit phase so we can check it
only once. This also effectively inlines getHostProps which can be done
in a single check per prop key.
The diffProperties operation is simplified to mostly just generating a
plain diff of all properties, generating an update payload. This might
generate a few more entries that are now ignored in the commit phase.
that previously would've been ignored earlier. We could skip this and
just do the whole diff in the commit phase by always scheduling a commit
phase update.
I tested the attribute table (one change documented below) and a few
select DOM fixtures.
This updates the Suspense fuzz tester to use `act` to recursively flush
timers instead of doing it manually.
This still isn't great because ideally the fuzz tester wouldn't fake
timers at all. It should resolve promises using a custom queue instead
of Jest's fake timer queue, like we've started doing in our other
Suspense tests (i.e. the `resolveText` pattern). That's because our
internal `act` API (not the public one, the one we use in our tests)
uses Jest's fake timer queue as a way to force Suspense fallbacks to
appear.
However I'm not interested in upgrading this test suite to a better
strategy right now because if I were writing a Suspense fuzzer today I
would probably use an entirely different approach. So this is just an
incremental improvement to make it slightly less decoupled to React
implementation details.
I already taught `lowerAssignment()` to handle assignment patterns for
destructuring, we just have to call this helper for assignment pattern params
too.
In a lambda, a return/throw terminal could return a captured context ref needs
to be treated as a mutation to correctly alias the returned context ref and the
lvalue.
Terminal operands are generally not mutating so this hasn't mattered so far. But
in a lambda, a return terminal could return a captured context ref which needs
to be treated as a mutation to correctly alias the returned context ref and the
lvalue.
I rewrote some of our tests that deal with microtasks with the aim of
making them less coupled to implementation details. This is related to
an upcoming change to move update processing into a microtask.
`JSXEmptyExpression` is never added to a React element's children [in
`react.buildChildren`](https://github.com/babel/babel/blob/main/packages/babel-types/src/builders/react/buildChildren.ts),
which is [used
by](https://github.com/babel/babel/blob/main/packages/babel-plugin-transform-react-jsx/src/create-plugin.ts#L649)
`plugin-transform-react-jsx`].
An alternative would be to represent JSX expressions differently in HIR, then
codegen `JSXEmptyExpression`s back when we encounter an `EmptyExpression`
```js
- children: Array<Place>,
- children: Array<Place | "EmptyExpression">,
```
(We could also retain `JSXEmptyExpression` as an `InstructionValue` that
produces a Primitive. However, this would make babel types in Codegen a bit more
messy, as `JSXEmptyExpression` does not extend `Expression` (which currently is
the result of every `InstructionValue`).)
Continuing my journey to migrate all the Scheduler flush* methods to
async versions of the same helpers.
`unstable_flushExpired` is a rarely used helper that is only meant to be
used to test a very particular implementation detail (update starvation
prevention, or what we sometimes refer to as "expiration").
I've prefixed the new helper with `unstable_`, too, to indicate that our
tests should almost always prefer one of the other patterns instead.
Creates a new helper, `const temp: Place = lowerValueToTemporary(builder,
value)` which creates a new temporary and an instruction to write that value to
the temporary. We have this pattern all over BuildHIR, and the new helper makes
this all a bit tidier.
Adds support for `await` expressions. We have primarily seen await used inside
callbacks, not directly within component render logic, but because we construct
HIR for lambdas it is helpful to be able to model await rather than require
everyone to rewrite to use the Promise API. Note a subtlety: awaiting a promise
is a mutative operation, so we a) model it as a Mutate effect and b) avoid DCE
of await expressions since they may cause side effects. See the test cases for
examples.
Adds a new helper method that we can use when processing expressions whose
evaluation ordering may not be preserved. This was previously the case only for
switch test case values, but we can use this for AssignmentPattern
(destructuring default values) as well.
"Supports" default values in destructuring (AssignmentPattern) by lowering to a
ternary, even in the output. Examples:
```javascript
// Input:
const [x = 'default'] = y;
// Output:
const [t0] = y;
const x = t0 === undefined ? 'default' : t0;
```
```javascript
// Input 2
const [{x} = makeObject()] = y;
// Output 2
const [t0] = y;
const {x} = t0 === undefined ? makeObject() : t0;
```
Note that this is how Babel lowers AssignmentPattern, so it isn't too bad. This
should help avoid the need to update product code, even if the output isn't
perfectly ideal.
This is kind of a hack, but i think it's worth it given that JSXNamespacedName
is relatively uncommon. Adding a new InstructionValue variant to represent a
namespaced name is one option, but then that isn't a valid expression and can't
appear as an operand anywhere else. Instead, we lower namespaced names as a
primitive (string) as `${namespace}:${name}` — exploiting the fact the namespace
and name can't have a colon, and non-namespaced tagnames also can't have colons.
It's a bit of a hack but it's contained to the JSX processing code. If folks
have strong opinions on this i'm happy to change but this felt reasonable as a
quick and reliable way to unblock support.
NOTE: there is a larger question of what to do about compiling `fbt` tags.
Before we can do anything with them, though, we need to parse them.
We need to check reactivity of both the operand and its resolved source (if
operand is produced by a LoadLocal / PropertyLoad / ComputedLoad).
Both the operand and its source can have reactivity.
e.g.
```js
const o = makeObject(); // source has no reactivity
const x = o[props.x]; // x is reactive
```
Rather than having a special FunctionCall type that deduces the return type,
change the FunctionType to include the return type.
This return type is inferred as part of unification.
---
Every `OptionalMemberExpression` rvalue has the form
`<requiredPath>?.<optionalPath>`.
```
// required = [a], optional: [b, c]
props.a?.b.c;
props.a?.b?.c;
```
When calculating reactive dependencies, recall that it is always correct to add
a subpath of a dependency (e.g. we can always take `props.a` instead of
`props.a.b` as a dependency). See comments in `DeriveMinimalDependencies` for a
longer explanation.
There are two ways we can deal with `OptionalMemberExpression`:
- We can always truncate a OptionalMemberExpression dependency to its
`requiredPath`, taking only the required path as a dependency.
- this is the simpler approach, but it potentially loses granularity.
e.g.
```
// here, since props.a is already unconditionally accessed,
// we can safely add props.a.b as a dependency and preserve both
// nullthrows and the correct dependency set.
scope @0 {
let x = [];
x.push(props.a?.b);
x.push(props.a.b);
}
```
(See added test case `reduce-reactive-cond-memberexpr-join` + its comment block
for a more detailed explanation`
- (the approach taken by this PR)
We can add the `requiredPath` as a potentially unconditional access (dependent
on other control flow) and `requiredPath + optionalPath` as a conditional
dependency.
Added an explicit type to all $FlowFixMe suppressions to reduce
over-suppressions of new errors that might be caused on the same lines.
Also removes suppressions that aren't used (e.g. in a `@noflow` file as
they're purely misleading)
Test Plan:
yarn flow-ci
Prerendering a tree (i.e. with Offscreen) should not suspend the commit
phase, because the content is not yet visible. However, when revealing a
prerendered tree, we should suspend the commit phase if resources in the
prerendered tree haven't finished loading yet.
To do this properly, we need to visit all the visible nodes in the tree
that might possibly suspend. This includes nodes in the current tree,
because even though they were already "mounted", the resources might not
have loaded yet, because we didn't suspend when it was prerendered.
We will need to add this capability to the Offscreen component's
"manual" mode, too. Something like a `ready()` method that returns a
promise that resolves when the tree has fully loaded.
Also includes some fixes to #26450. See PR for details.
## Summary
Just copied the types over from the internal types. Type error was
hidden by overly broad FlowFixMe. With `$FlowFixMe[not-a-function]` we
would've seen the actual issue:
```
Cannot return `dispatcher.useEffectEvent(...)` because `T` [1] is incompatible with undefined [2].Flow(incompatible-return)
```
## How did you test this change?
- [x] yarn flow dom-node
- [x] CI
Before a commit is finished if any new stylesheet resources are going to
mount and we are capable of delaying the commit we will do the following
1. Wait for all preloads for newly created stylesheet resources to load
2. Once all preloads are finished we insert the stylesheet instances for
these resources and wait for them all to load
3. Once all stylesheets have loaded we complete the commit
In this PR I also removed the synchronous loadingstate tracking in the
fizz runtime. It was not necessary to support the implementation on not
used by the fizz runtime itself. It makes the inline script slightly
smaller
In this PR I also integrated ReactDOMFloatClient with
ReactDOMHostConfig. It leads to better code factoring, something I
already did on the server a while back. To make the diff a little easier
to follow i make these changes in a single commit so you can look at the
change after that commit if helpful
There is a 500ms timeout which will finish the commit even if all
suspended host instances have not finished loading yet
At the moment error and load events are treated the same and we're
really tracking whether the host instance is finished attempting to
load.
Follow-up to https://github.com/facebook/react/pull/26442.
It looks like we missed a few cases where we default import a CommonJS
module, which leads to Rollup adding `.default` access, e.g.
`require('webpack/lib/Template').default` in the output.
To fix, add the remaining cases to the list of exceptions. Verified by
going through all `externals` in the bundle list, and manually checking
the webpack plugin.
---
Previously, both `path=null` and `path=[]` could represent a dependency with no
property path (i.e. the result of a LoadLocal with no PropertyLoad).
Make path non-nullable so we don't have to add null checks everywhere.
---
We don't need to store whether a `PropertyLoad` happens within a conditional
(within its reactive scope). In fact, the PropertyLoad producing a rval often is
in a different ReactiveScope from where the rval is used.
We only need to add `#inConditionalWithinScope` when we actually visit a
reactive dependency.
Earlier PRs bailed out when the callee of an OptionalCallExpression was a
MemberExpression or OptionalMemberExpression (ie for optional method calls).
This PRs expands support for optional method calls, including when the receiver,
method, or both are optional. Even better, we don't need to add any additional
terminals or instruction variants for this case - the one new OptionalCall
terminal from earlier in the stack works for all these cases.
Tests, focusing on two key behaviors:
* Dependencies of the args are treated as conditional, since the call may not
happen
* Args cannot be memoized independently, even when that would be valid for a
non-optional call.
Implements HIR->ReactiveFunction conversion and Codegen for optional calls. We
add a new OptionalCall variant of ReactiveValue, which is a SequenceExpression
that describes the evaluation of the args and the call itself. This is then
straightforward to codgen.
Implements lowering for a subset of optional calls - specifically, we don't
(yet) support when the callee is a member expression or an optional member
expression. So `foo?.()` works but we bailout on `object?.foo()` and
`object.foo?.()`.
For `<calleee>?.(<args>)` we lower as roughly:
```
bb0:
t0 = <callee>
OptionalCall test=bb1 fallthrough=
bb1 (value):
Branch t0 consequent=bb2 alternate=bb3
bb2 (value):
...lower <args> here...
t1 = Call t0, args
StoreLocal res, t1
Goto bb4
bb3 (value):
t2 = undefined
StoreLocal res, t2
Goto bb4
bb4:
// result in `res` here
```
Adds a new `optional-call` terminal and sets up the appropriate handling in the
visitors, with lowering/reactivefunction/codegen as todos for now and
implemented in follow-ups.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
This PR:
- Updates Rollup from 2.x to latest 3.x, and updates associated plugins
- Updates deprecated / altered config settings in the Rollup plugin
pipeline
- Fixes some file extension and import issues related to use of ESM in
`react-dom-webpack-server`
- Removes a now-obsolete `strip-unused-imports` Rollup plugin
- <s>Fixes an _existing_ bug with the Rollup 2.x plugin pipeline on
`main` that was causing parts of `DOMProperty.js` to get left out of the
`react-dom-webpack-server` JS bundles, by adding a new plugin to tell
Rollup to treat that file as if it as side effects</s>
This PR should be functionally identical to the other existing "Rollup 3
upgrade" PR at #26078 . I'm filing this as a near-duplicate because I'm
ready to push this change through ASAP so that I can follow it up with a
PR that adds sourcemap support, that PR's artifact diffing seems like
it's possibly stuck and I want to compare the build results, and I've
got this set up against latest `main`.
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
This gets React's build setup updated to the latest Rollup version,
which is generally a good practice, but also ensures that any further
Rollup config tweaks can be done using the current Rollup docs as a
reference.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
- Made builds from the latest `main`
- Updated Rollup package versions and cross-compared the changes I
needed to make locally to get successful builds vs #26078
- Diffed the output folders between `main` and this PR, and confirmed
that the bundle contents are identical (with the exception of version
strings and the `react-dom-webpack-server` bundle fix re-adding missing
`DOMProperty.js` content)
---
Expand Hindley Milner type inference to infer dependent types.
Say `t` is a typevar and `t'` is some type (a built-in type, phi node, or
another typevar).
Our type equations are as follows (please edit/correct notation 😅)
- type substitution: `t = t'`,
- ~~dependent~~ polymorphic property load: `t = t'.prop`
- polymorphic function call `t = fnCall{returnType}`
- ~~dependent property call: `t = t'.prop` (only if t'.prop is a function
type)~~
- ~~dependent return type: `t = t'.[[returntype]]`~~
---
+10 −1,698 lines [[insert impacc macro]]
The ObjectShape stacks (#1350, #1358) used these tests to record changes in
inferred types (and associated ObjectShapes), reference effects, and mutable
ranges.
Now that those PRs have landed, we can delete these tests. They are somewhat
fragile (changing anytime HIR / printHIR is changed) and easily cause
rebase/merge conflicts.
---
This PR does not add inference for normal `CallExpression`s, since built-in
functions for `Array` and `Object` are usually only valid if called with a
correctly-typed `this`. If we want codegen to preserve source code semantics,
Forget should only add inferred types it is confident about.
This PR also adds `returnEffect` to FunctionSignature. `returnEffect = Store` if
this function is known to always return a captured value from `receiver` or
`args`.
---
Expand Hindley Milner type inference to infer dependent types.
Say `t` is a typevar and `t'` is some type (a built-in type, phi node, or
another typevar).
Our type equations are as follows (please edit/correct notation 😅)
- type substitution: `t = t'`,
- ~~dependent~~ polymorphic property load: `t = t'.prop`
- polymorphic function call `t = fnCall{returnType}`
- ~~dependent property call: `t = t'.prop` (only if t'.prop is a function
type)~~
- ~~dependent return type: `t = t'.[[returntype]]`~~
We limit the types of expressions allowed as switch case test values because we
our HIR doesn't yet preserve order-of-evaluation for switch test values (we
model them as being evaluated prior to entering the switch, as opposed to
lazily, when the case is reached). One common pattern internally is test case
values that are properties of a global, eg you have some bag of enum values and
are comparing against that:
```javascript
// at module scope, or imported from another module:
const OPTIONS = {FOO: 'foo'};
// in a component
switch (value) {
case OPTIONS.FOO: { ... }
}
```
This PR allows this specific case, ie member expressions where the innermost
object is a global identifier.
Now that we model the method resolution via a PropertyLoad or ComputedLoad, we
don't need to distinguish between PropertyCall and ComputedCall. These two call
variants are now combined into a single MethodCall variant.
This is the version of @mofeiZ's change for PropertyLoad, but made to work on
ComputedCall. We force the method to be evaluated in the same scope as the call
in InferReactiveScopeVariables.
---
(I'm not sure if these are already known issues. I found them while playing
around with lambda captures. They are also reproducible on main / stable)
I have some limited understanding of lambda captures after reading Sathya's
posts -- please correct if/where this is incorrect
```
function Component() {
// instr1
// instr2
const func3 = function(...) {
// func3instr1
}
}
```
We currently determine effects of captured references in `AnalyzeFunctions`,
before InferReferenceEffects.
- i.e. for some function
1. dependencies of all functions (func3.deps)
2. prefix traversal of all instructions (e.g. instr1, instr2, func3.deps,
func3instr1, ...)
- is this just an implementation decision? i.e. what is stopping us from postfix
traversal in InferReferenceEffects (e.g. instr1, instr2, func3instr1,
func3.deps)
As such, for each captured reference, `AnalyzeFunctions` needs to assign a
reference effect. We currently check `MutableRange`, which seems to miss a few
cases
- We do not model assignments to primitives correctly, since primitives do not
have a mutable range.
- We're not able to model captured (but not mutated) values correctly.
Would it be possible to consolidate `AnalyzeFunctions` into
InferReferenceEffects, using some post-order traversal (iterating over a
function's instructions to collect its dependencies + associated capture
effects)? I definitely don't understand lambdas completely, so please tell me
what I'm missing
---
This PR does not add inference for normal `CallExpression`s, since built-in
functions for `Array` and `Object` are usually only valid if called with a
correctly-typed `this`. If we want codegen to preserve source code semantics,
Forget should only add inferred types it is confident about.
This PR also adds `returnEffect` to FunctionSignature. `returnEffect = Store` if
this function is known to always return a captured value from `receiver` or
`args`.
---
I didn't properly understand Capture and Store effects previously, just
correcting those mistakes!
These functions are all synchronously mutative, so they should use Read /
Mutate, not Capture + Store
---
Expand Hindley Milner type inference to infer dependent types.
Say `t` is a typevar and `t'` is some type (a built-in type, phi node, or
another typevar).
Our type equations are as follows (please edit/correct notation 😅)
- type substitution: `t = t'`,
- ~~dependent~~ polymorphic property load: `t = t'.prop`
- polymorphic function call `t = fnCall{returnType}`
- ~~dependent property call: `t = t'.prop` (only if t'.prop is a function
type)~~
- ~~dependent return type: `t = t'.[[returntype]]`~~
## Summary
Now that React Native owns the definition for public instances in Fabric
and ReactNativePrivateInterface provides the methods to create instances
and access private fields (see
https://github.com/facebook/react-native/pull/36570), we can remove the
definitions from React.
After this PR, React Native public instances will be opaque types for
React and it will only handle their creation but not their definition.
This will make RN similar to DOM in how public instances are handled.
This is a new version of #26418 which was closed without merging.
## How did you test this change?
* Existing tests.
* Manually synced the changes in this PR to React Native and tested it
end to end in Meta's infra.
## Overview
This PR unfortunately removes the warning emitted when using layout
effects on the server:
> useLayoutEffect does nothing on the server, because its effect cannot
be encoded into the server renderer's output format. This will lead to a
mismatch between the initial, non-hydrated UI and the intended UI. To
avoid this, useLayoutEffect should only be used in components that
render exclusively on the client. See
https://reactjs.org/link/uselayouteffect-ssr for common fixes.
## Why this warning exists
The new docs explain this really well. Adding a screenshot because as
part of this change, we'll be removing these docs.
<img width="1562" alt="Screenshot 2023-03-15 at 10 56 17 AM"
src="https://user-images.githubusercontent.com/2440089/225349148-f0e57c3f-95f5-4f2e-9178-d9b9b221c28d.png">
## Why are we changing it
In practice, users are not just ignoring this warning, but creating
hooks to bypass this warning by switching the useLayoutEffect hook on
the server instead of fixing it. This battle seems to be lost, so let's
remove the warning so at least users don't need to use the indirection
hook any more. In practice, if it's an issue, you should see the
problems like flashing the wrong content on first load in development.
Fixes a bug in SuspenseList that @kassens found when deploying React to
Meta. In some scenarios, SuspenseList would force the fallback of a
deeply nested Suspense boundary into fallback mode, which should never
happen under any circumstances — SuspenseList should only affect the
nearest descendent Suspense boundaries, without going deeper.
The cause was that the internal ForceSuspenseFallback context flag was
not being properly reset when it reached the nearest Suspense boundary.
It should only be propagated shallowly.
We didn't discover this earlier because the scenario where it happens is
not that common. To trigger the bug, you need to insert a new Suspense
boundary into an already-mounted row of the list. But often when a new
Suspense boundary is rendered, it suspends and shows a fallback, anyway,
because its content hasn't loaded yet.
Another reason we didn't discover this earlier is because there was
another bug that was accidentally masking it, which was fixed by #25922.
When that fix landed, it revealed this bug.
The SuspenseList implementation is complicated but I'm not too concerned
with the current messiness. It's an experimental API, and we intend to
release it soon, but there are some known flaws and missing features
that we need to address first regardless. We'll likely end up rewriting
most of it.
Co-authored-by: Jan Kassens <jkassens@meta.com>
With this flag off, we don't throw and therefore don't patch up the tree
when suppression is off.
Haven't tested.
---------
Co-authored-by: Rick Hanlon <rickhanlonii@fb.com>
## Summary
This type was defined as `mixed` to avoid bringing the whole definition
from React to React Native, but its definition is visible to RN. This
type should be opaque to RN, so this makes it explicit.
## How did you test this change?
Applied the same changes in the React Native repository and could use
the type without issues.
How Forget currently lowers PropertyCall:
```js
// source: [[ calleeExpr ]].propertyName( [[ argExpr0 ]])
$0 = [[ calleeExpr ]]
$1 = [[ argExpr0 ]]
$2 = PropertyCall callee=$0 property="propertyName" args=[$1]
```
This PR changes the lowering:
```js
// source: [[ calleeExpr ]].propertyName( [[ argExpr0 ]])
$0 = [[ calleeExpr ]]
$1 = PropertyLoad $0 "propertyName"
$2 = [[ argExpr0 ]]
$3 = PropertyCall callee=$0 fn=$1 args=[$2]
```
From my understanding, `PropertyCall` needs the receiver to properly model JS
semantics which is something like `resolvedFn.apply(resolvedCallee, arg0, arg1,
...)`. This is additionally useful for:
- Fine-grained mutability / alias analysis. The property call is technically a
read of the resolved function, and a mutate of the callee.
- Dependency tracking. While we could special case PropertyCall, this
representation would correctly add both callee and callee.propertyName as
dependencies for PropertyCall.
e.g.
```js
let x = [];
mutate(x);
useFreeze(x);
let y = {};
y.a = x.bar();
return y;
```
Reverts #1199, which was added before we properly supported destructuring
assignment.
Next PR (changes to PropertyCall in #1384) will lower two references to the same
named identifier (the property call receiver)
The previous PR only updated simple assignment expressions (where the lvalue is
an identifier), this PR extends the same idea to all assignment variants. Note
that there is one case that doesn't work yet, which is complex destructuring
assignment as a value:
```javascript
let x = makeObject();
x.foo(([[x]] = makeObject()));
```
What happens here is that we lower the destructuring to a series of steps:
```
tmp1: Destructure Const [ tmp0 ] = makeObject();
tmp2: Destructure Reassign [ x ] = tmp0;
PropertyCall x, 'foo', [ tmp1 ]
```
Thankfully we can detect this case: if we have a const/let declaration with an
lvalue, that's invalid. See the new error test case which shows we correctly
detect & reject this case for now.
This PR subtly changes how we represent assignment expressions in order to
accurately model them _as expressions_. Specifically, the result of lowering an
assignment is now the temporary created for the assignment's lvalue. This allows
us to restore the assignment as a value (expression) during codegen. Note how
this fixes a bug and cleans up some output.
Updates ConstantPropagation so that each instruction is responsible for whether
to replace its `.value` with the resolved constant value (if found).
Specifically, for `StoreLocal` we don't want to replace the value — we want to
keep the assignment — but we do want to propagate the _result_ of the assignment
downstream. This more accurately models the semantics of assignment expressions,
and helps with subsequent PRs.
Today if something suspends, React will continue rendering the siblings
of that component.
Our original rationale for prerendering the siblings of a suspended
component was to initiate any lazy fetches that they might contain. This
was when we were more bullish about lazy fetching being a good idea some
of the time (when combined with prefetching), as opposed to our latest
thinking, which is that it's almost always a bad idea.
Another rationale for the original behavior was that the render was I/O
bound, anyway, so we might as do some extra work in the meantime. But
this was before we had the concept of instant loading states: when
navigating to a new screen, it's better to show a loading state as soon
as you can (often a skeleton UI), rather than delay the transition.
(There are still cases where we block the render, when a suitable
loading state is not available; it's just not _all_ cases where
something suspends.) So the biggest issue with our existing
implementation is that the prerendering of the siblings happens within
the same render pass as the one that suspended — _before_ the loading
state appears.
What we should do instead is immediately unwind the stack as soon as
something suspends, to unblock the loading state.
If we want to preserve the ability to prerender the siblings, what we
could do is schedule special render pass immediately after the fallback
is displayed. This is likely what we'll do in the future. However, in
the new implementation of `use`, there's another reason we don't
prerender siblings: so we can preserve the state of the stack when
something suspends, and resume where we left of when the promise
resolves without replaying the parents. The only way to do this
currently is to suspend the entire work loop. Fiber does not currently
support rendering multiple siblings in "parallel". Once you move onto
the next sibling, the stack of the previous sibling is discarded and
cannot be restored. We do plan to implement this feature, but it will
require a not-insignificant refactor.
Given that lazy data fetching is already bad for performance, the best
trade off for now seems to be to disable prerendering of siblings. This
gives us the best performance characteristics when you're following best
practices (i.e. hoist data fetches to Server Components or route
loaders), at the expense of making an already bad pattern a bit worse.
Later, when we implement resumable context stacks, we can reenable
sibling prerendering. Though even then the use case will mostly be to
prerender the CPU-bound work, not lazy fetches.
(This was reviewed and approved as part of #26380; I'm extracting it
into its own PR so that it can bisected later if it causes an issue.)
I noticed while working on a PR that when an error happens during
hydration, and we revert to client rendering, React actually does _two_
additional render passes instead of just one. We didn't notice it
earlier because none of our tests happened to assert on how many renders
it took to recover, only on the final output.
It's possible this extra render pass had other consequences that I'm not
aware of, like messing with some assumption in the recoverable errors
logic.
This adds a test to demonstrate the issue. (One problem is that we don't
have much test coverage of this scenario in the first place, which
likely would have caught this earlier.)
This is in line with the refactor I already did on Fizz earlier and
brings Fiber up to a similar structure.
We end up with a lot of extra checks due the extra abstractions we use
to check the various properties. This uses a flatter and more inline
model which makes it easier to see what each property does. The tradeoff
is that a change might need changes in more places.
The general structure is that there's a switch for tag first, then a
switch for each attribute special case, then a switch for the value. So
it's easy to follow where each scenario will end up and there shouldn't
be any unnecessary code executed along the way.
My goal is to eventually get rid of the meta-programming in DOMProperty
and CSSProperty but I'm leaving that in for now - in line with Fizz.
My next step is moving around things a bit in the diff/commit phases.
This is the first step to more refactors for perf and size, but also
because I'm adding more special cases so I need to have a flatter
structure that I can reason about for those special cases.
Rewrite ArrowFunctionExpression to FunctionDeclaration and compile it. This lets
us reuse all the export gating logic, rather than writing separate, specific
logic for ArrowFunctionExpression.
Cleans up duplicated code for processing call/constructor arguments. As a side
benefit, we now support spread elements for constructor arguments (and if we
want to change how we represent that, we can do it in one place).
When rendering a suspensey resource that we haven't seen before, it may
have loaded in the background while we were rendering. We should yield
to the main thread to see if the load event fires in an immediate task.
For example, if the resource for a link element has already loaded, its
load event will fire in a task right after React yields to the main
thread. Because the continuation task is not scheduled until right
before React yields, the load event will ping React before it resumes.
If this happens, we can resume rendering without showing a fallback.
I don't think this matters much for images, because the `completed`
property tells us whether the image has loaded, and during a non-urgent
render, we never block the main thread for more than 5ms at a time (for
now — we might increase this in the future). It matters more for
stylesheets because the only way to check if it has loaded is by
listening for the load event.
This is essentially the same trick that `use` does for userspace
promises, but a bit simpler because we don't need to replay the host
component's begin phase; the work-in-progress fiber already completed,
so we can just continue onto the next sibling without any additional
work.
As part of this change, I split the `shouldSuspendCommit` host config
method into separate `maySuspendCommit` and `preloadInstance` methods.
Previously `shouldSuspendCommit` was used for both.
This raised a question of whether we should preload resources during a
synchronous render. My initial instinct was that we shouldn't, because
we're going to synchronously block the main thread until the resource is
inserted into the DOM, anyway. But I wonder if the browser is able to
initiate the preload even while the main thread is blocked. It's
probably a micro-optimization either way because most resources will be
loaded during transitions, not urgent renders.
## Summary
We are going to move the definition of public instances from React to
React Native to have them together with the native methods in Fabric
that they invoke. This will allow us to have a better type safety
between them and iterate faster on the implementation of this proposal:
https://github.com/react-native-community/discussions-and-proposals/pull/607
The interface between React and React Native would look like this after
this change and a following PR (#26418):
React → React Native:
```javascript
ReactNativePrivateInterface.createPublicInstance // to provide via refs
ReactNativePrivateInterface.getNodeFromPublicInstance // for DevTools, commands, etc.
ReactNativePrivateInterface.getNativeTagFromPublicInstance // to implement `findNodeHandle`
```
React Native → React (ReactFabric):
```javascript
ReactFabric.getNodeFromInternalInstanceHandle // to get most recent node to call into native
ReactFabric.getPublicInstanceFromInternalInstanceHandle // to get public instances from results from native
```
## How did you test this change?
Flow
Existing unit tests
Sizebot works by fetching the base artifacts from CI. CircleCI recently
updated this endpoint to require an auth token. This is a problem for PR
branches, where sizebot runs, because we don't want to leak the token to
arbitrary code written by an outside contributor.
This only affects PR branches. CI workflows that run on the main branch
are allowed to access environment variables, because only those with
push access can land code in main.
As a temporary workaround, we'll fetch the assets from a mirror,
react-builds.vercel.app. This is the same app that hosts the sizebot
diff previews.
Need to figure out a longer term solution. Perhaps by converting sizebot
into a proper GitHub app.
This adds a new capability for renderers (React DOM, React Native):
prevent a tree from being displayed until it is ready, showing a
fallback if necessary, but without blocking the React components from
being evaluated in the meantime.
A concrete example is CSS loading: React DOM can block a commit from
being applied until the stylesheet has loaded. This allows us to load
the CSS asynchronously, while also preventing a flash of unstyled
content. Images and fonts are some of the other use cases.
You can think of this as "Suspense for the commit phase". Traditional
Suspense, i.e. with `use`, blocking during the render phase: React
cannot proceed with rendering until the data is available. But in the
case of things like stylesheets, you don't need the CSS in order to
evaluate the component. It just needs to be loaded before the tree is
committed. Because React buffers its side effects and mutations, it can
do work in parallel while the stylesheets load in the background.
Like regular Suspense, a "suspensey" stylesheet or image will trigger
the nearest Suspense fallback if it hasn't loaded yet. For now, though,
we only do this for non-urgent updates, like with startTransition. If
you render a suspensey resource during an urgent update, it will revert
to today's behavior. (We may or may not add a way to suspend the commit
during an urgent update in the future.)
In this PR, I have implemented this capability in the reconciler via new
methods added to the host config. I've used our internal React "no-op"
renderer to write tests that demonstrate the feature. I have not yet
implemented Suspensey CSS, images, etc in React DOM. @gnoff and I will
work on that in subsequent PRs.
CircleCI now enforces passing a token when fetching artifacts. I'm also
deleting the old request-promise-json dependency because AFAIK we were
only using it to fetch json from circleci about the list of available
artifacts – which we can just do using node-fetch. Plus, the underlying
request package it uses has been deprecated since 2019.
## Summary
We had to revert the last React sync to React Native because we saw
issues with Responder events using stale event handlers instead of
recent versions.
I reviewed the merged PRs and realized the problem was in the refactor I
did in #26321. In that PR, we moved `currentProps` from `canonical`,
which is a singleton referenced by all versions of the same fiber, to
the fiber itself. This is causing the staleness we observed in events.
This PR does a partial revert of the refactor in #26321, bringing back
the `canonical` object but moving `publicInstance` to one of its fields,
instead of being the `canonical` object itself.
## How did you test this change?
Existing unit tests continue working (I didn't manage to get a repro
using the test renderer).
I manually tested this change in Meta infra and saw the problem was
fixed.
In concurrent mode we error if child nodes mismatches which triggers a
recreation of the whole hydration boundary. This ensures that we don't
replay the wrong thing, transform state or other security issues.
For text content, we respect `suppressedHydrationWarning` to allow for
things like `<div suppressedHydrationWarning>{timestamp}</div>` to
ignore the timestamp. This mode actually still patches up the text
content to be the client rendered content.
In principle we shouldn't have to do that because either value should be
ok, and arguably it's better not to trigger layout thrash after the
fact.
We do have a lot of code still to deal with patching up the tree because
that's what legacy mode does which is still in the code base. When we
delete legacy mode we would still be stuck with a lot of it just to deal
with this case.
Therefore I propose that we change the semantics to not patch up
hydration errors for text nodes. We already don't for attributes.
We currently are not lowering property calls in evaluation order.
I wonder if the following lowering for a PropertyCall (with static or computed
property) is semantically equivalent to source:
1. eval + resolve receiver (store in t0)
2. eval computed property (if present)
3. resolve t0.property (binding the call to receiver and storing in t1)
4. eval args
5. eval t1(args)
Although codegen might then generate something like this (if args are named
temporaries)
```js
const tmp = receiver.property.bind(receiver);
// lower args to temporaries
tmp(arg1, arg2);
```
Just noticed the test isn't testing what it is meant to test properly.
The error `Warning: ReactDOM.render is no longer supported in React 18.
Use createRoot instead. Until you switch to the new API, your app will
behave as if it's running React 17. Learn more:
https://reactjs.org/link/switch-to-createroot` is thrown, the inner
`expect(error).toContain('Warning: Maximum update depth exceeded.');`
failed and threw jest error, and the outer `.toThrow('Maximum update
depth exceeded.')` happens to catch it and makes the test pass.
As I understand it this isn't used at Meta and it would let us get rid
of at least legacy mode hydration code when we remove legacy mode from
OSS builds.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
`react-dom/server` in Bun (correctly) chooses `react-dom/server.bun`,
but `react-dom/server.bun` currently can't be imported because it is not
included in package.json `"exports"` (`react-dom/server` works,
`react-dom/server.bun` doesn't). Previously, I didn't think it was
necessary to do that, but it is too easy to accidentally run the browser
build in unit tests when importing `react-dom/server`
This also aligns behavior of package.json `"exports"` of
`react-dom/server.bun` with `react-dom/server.browser`,
`react-dom/server.node`, and the rest.
## How did you test this change?
Manually edited package.json in node_modules in a separate folder and
ran tests in Bun with `react-dom/server.bun` as the import specifier
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
Adds a `DeclareLocal` instruction which represents declaring a named variable
without initializing it. Currently declarations without an initializer (`let x`)
are transformed into a declaration to undefined (`let x = undefined`) which
changes the semantics due to hoisting and TDZ (temporary dead zone). The correct
thing is to represent declaration without initialization.
These examples previously errored all the way in codegen, when we detected that
a value block (eg a `while` test expression) was declaring a new variable. We
now detect this in LeaveSSA and error. The actual fix is a bit tricky, we'd need
to add a new declaration in the nearest block scope (or selectively not DCE the
declaration if its reassigned in just this way).
If a logical or conditional expression is unused, then a phi node isn't created
for the identifier it assigns to. Then when we leave SSA form the two branches
will assign to separate values, and we aren't sure which identifier to use as
the lvalue of the resulting ReactiveInstruction (remember that
logicals/conditionals decompose into control flow in HIR, but are a single
compound instruction in ReactiveFunction). If the two sides don't assign to the
same location, it could be because of a bug in the compiler or because the value
wasn't used. Ideally we'd represent this explicitly, but for now i'm just making
this a TODO since most logicals/conditionals should have their value used.
## Summary
I refactored this code in #26290 but forgot to add guards when the fiber
or the state node where null, and this is typed as `any` so Flow didn't
catch it.
This restores the same logic to guard against null.
## How did you test this change?
Existing tests.
Enables support for assignment expressions in value blocks (which includes in
loop init/test/update blocks). This was pretty straightforward, the main changes
are:
* During PropagateScopeDependencies, we currently record scope reassignments
based on `Identifier` object identity. In the case where a variable is
reassigned in multiple control-flow paths of a value block, however, there can
be multiple object identities. So we now de-dupe reassignments based on
identifier id.
* MergeOverlappingScopes now treats value blocks as regular blocks, allowing it
to correctly merge scopes from the value with other scopes from the outer block.
Otherwise this is mostly just lots of tests. Note that there is an outstanding
todo, which is that we currently error for ternaries and logicals whose value is
unused (eg `cond ? (x = 1) : null`). I'll address that in a follow-up.
There's currently a giant cycle between the event system, through
react-dom-bindings, reconciler and then react-dom. We resolve this cycle
using dependency injection. However, this all ends up in the same
bundle. It can be reordered to resolve the cycles. If we avoid
side-effects and avoid reading from module exports during
initialization, this should be resolvable in a more optimal way by the
compiler.
I'm trying to get rid of all meta programming in the module scope so
that closure can do a better job figuring out cyclic dependencies and
ability to reorder.
This is converting a lot of the patterns that assign functions
conditionally to using function declarations instead.
```
let fn;
if (__DEV__) {
fn = function() {
...
};
}
```
->
```
function fn() {
if (__DEV__) {
...
}
}
```
These used to be used by partial render.
ReactDOMDispatcher ended up not being used in this way.
Move shared DOM files to client. These are only used by client
abstractions now. They're inlined in the Fizz code so they're no longer
shared.
This PR clarifies the logic for adjust mutable ranges of phis and their operands
during LeaveSSA. Previously we had logic in several places to determine
whether/how to extend the ranges of each phi and its operands: this occurred
while traversing reassignmentPhis (in 2+ places) and rewritePhis, as well as in
rewritePlace().
This was kind of a band-aid to make things work, but the logic was imprecise.
The actual rules are as follows:
If there is a back-edge, or the phi id is unnamed, then were extend the ranges
of the phi and its operands to min(starts) and max(ends). This ensures that the
operands are computed as one unit, ie put into a single reactive scope. For
loops this is necessary because...looping! For unnamed values this is necessary
because of the way we collapse logical and ternary expressions back to a
hierarchical ReactiveFunction — we need to make sure the final mutable range
extends from the start of the final instruction up to the end of the
logical/ternaries value blocks.
Otherwise this is a phi where operands come from predecessors and are named. If
the phi is mutated later, then we have to extend the end of each operand's range
to account for the fact that they can be mutated later. Else, we leave the
operands alone.
Behavior doesn't change, but we consolidate all of the mutable range logic in
one place.
Now that promises are renderable nodes, we can remove the `use` call
from the root of the Flight fixture.
Uncached promises will likely be accompanied by a warning when they are
rendered outside a transition. But this promise is the result of a
Flight response, so it's cached. And it's also a rendered as part of a
transition. So it's fine. Indeed, this is the canonical way to use this
feature.
This doesn't need its own set of flags. We use things like `__PROFILE__`
in the regular feature flags file to fork for the `react-dom/profiling`
build so we can do the same here if needed but I don't think we actually
need to fork this anywhere as far as I can tell.
Makes JSX memoized by default again, but adds an option to disable memoization
of JSX. Also adds a new test and fixtures directory to test the opt-in
no-jsx-memoization behavior.
---
Currently, we run type inference passes early in the pipeline and do not check
inference output in any tests, test fixtures, or verifier passes. In fact, the
only ways to view inferred types are (1) locally add a test fixture with`@only`
and inspect console logs or (2) scroll to the relevant section on a playground
example.
However, inferred types and effects significantly affect the output of later
passes (Alias / MutableRange analysis, InferReactiveIdentifiers, etc), and we
have already found some bugs due to incorrect inference (e.g. #1274).
This PR add the `typer-tests` fixture with the following goals
1. Record relevant current compiler type + effect inference output.
2. Have relatively stable output (with respect to changes in HIR and PrintHIR).
- we try to achieve this by annotating the source code.
---
Currently, we run type inference passes early in the pipeline and do not check
inference output in any tests, test fixtures, or verifier passes. In fact, the
only ways to view inferred types are (1) locally add a test fixture with`@only`
and inspect console logs or (2) scroll to the relevant section on a playground
example.
However, inferred types and effects significantly affect the output of later
passes (Alias / MutableRange analysis, InferReactiveIdentifiers, etc), and we
have already found some bugs due to incorrect inference (e.g. #1274).
This PR add the `typer-tests` fixture with the following goals
1. Record relevant current compiler type + effect inference output.
2. Have relatively stable output (with respect to changes in HIR and PrintHIR).
- we try to achieve this by annotating the source code.
We disallow empty strings for `href` and `src` since they're common
mistakes that end up loading the current page as a preload, image or
link. We also disallow it for `action`. You have to pass `null` which is
the same.
However, for `formAction` passing `null` is not the same as passing
empty string. Passing empty string overrides the form's action to be the
current page even if the form's action was set to something else.
There's no easy way to express the same thing `#` show up in the user
visible URLs and `?` clears the search params.
Since this is also not a common mistake, we can just allow this.
## Summary
The current definition of `Instance` in Fabric has 2 fields:
- `node`: reference to the native node in the shadow tree.
- `canonical`: public instance provided to users via refs + some
internal fields needed by Fabric.
We're currently using `canonical` not only as the public instance, but
also to store internal properties that Fabric needs to access in
different parts of the codebase. Those properties are, in fact,
available through refs as well, which breaks encapsulation.
This PR splits that into 2 separate fields, leaving the definition of
instance as:
- `node`: reference to the native node in the shadow tree.
- `publicInstance`: public instance provided to users via refs.
- Rest of internal fields needed by Fabric at the instance level.
This also migrates all the current usages of `canonical` to use the
right property depending on the use case.
To improve encapsulation (and in preparation for the implementation of
this [proposal to bring some DOM APIs to public instances in React
Native](https://github.com/react-native-community/discussions-and-proposals/pull/607)),
this also **moves the creation of and the access to the public instance
to separate modules** (`ReactFabricPublicInstance` and
`ReactFabricPublicInstanceUtils`). In a following diff, that module will
be moved into the `react-native` repository and we'll access it through
`ReactNativePrivateInterface`.
## How did you test this change?
Existing unit tests.
Manually synced the PR in Meta infra and tested in Catalyst + the
integration with DevTools. Everything is working normally.
For various reasons some of the DevTools e2e tests uses our repo's
private internal version of `act`. It should really just be using the
public one.
This converts one of the usages, because it was causing CI to fail.
## Based on #25634
Like promises, this adds support for Context as a React node.
In this initial implementation, the context dependency is added to the
parent of child node. This allows the parent to re-reconcile its
children when the context updates, so that it can delete the old node if
the identity of the child has changed (i.e. if the key or type of an
element has changed). But it also means that the parent will replay its
entire begin phase. Ideally React would delete the old node and mount
the new node without reconciling all the children. I'll leave this for a
future optimization.
Implements Promise as a valid React node types. The idea is that any
type that can be unwrapped with `use` should also be renderable.
When the reconciler encounters a Usable in a child position, it will
transparently unwrap the value before reconciling it. The value of the
inner value will determine the identity of the child during
reconciliation, not the Usable object that wraps around it.
Unlike `use`, the reconciler will recursively unwrap the value until it
reaches a non-Usable type, e.g. `Usable<Usable<Usable<T>>>` will resolve
to T.
In this initial commit, I've added support for Promises. I will do
Context in the [next
step](https://github.com/facebook/react/pull/25641).
Being able to render a promise as a child has several interesting
implications. The Server Components response format can use this feature
in its implementation — instead of wrapping references to client
components in `React.lazy`, it can just use a promise.
This also fulfills one of the requirements for async components on the
client, because an async component always returns a promise for a React
node. However, we will likely warn and/or lint against this for the time
being because there are major caveats if you re-render an async
component in response to user input. (Note: async components already
work in a Server Components environment — the caveats only apply to
running them in the browser.)
To suspend, React uses the same algorithm as `use`: by throwing an
exception to unwind the stack, then replaying the begin phase once the
promise resolves. It's a little weird to suspend during reconciliation,
however, `lazy` already does this so if there were any obvious bugs
related to that we likely would have already found them.
Still, the structure is a bit unfortunate. Ideally, we shouldn't need to
replay the entire begin phase of the parent fiber in order to reconcile
the children again. This would require a somewhat significant refactor,
because reconciliation happens deep within the begin phase, and
depending on the type of work, not always at the end. We should consider
as a future improvement.
Adding `.internal` to a test file prevents it from being tested in build
mode. The best practice is to instead gate the test based on whether the
feature is enabled.
Ideally we'd use the `@gate` pragma in these tests, but the `itRenders`
test helpers don't support that.
The www builds include disableLegacyContext as a dynamic flag, so we
should be running the tests in that mode, too. Previously we were
overriding the flag during the test run. This strategy usually doesn't
work because the flags get compiled out in the final build, but we
happen to not test www in build mode, only source.
To get of this hacky override, I added a test gate to every test that
uses legacy context. When we eventually remove legacy context from the
codebase, this should make it slightly easier to find which tests are
affected. And removes one more hack from our hack-ridden test config.
Given that sometimes www has features enabled that aren't on in other
builds, we might want to consider testing its build artifacts in CI,
rather than just source. That would have forced this cleanup to happen
sooner. Currently we only test the public builds in CI.
`Scheduler.unstable_flushAll` in existing tests doesn't work with
microtask. This PR converts most of the remaining
`Scheduler.unstable_flushAll()` calls to using internal test utilities
to unblock refactoring `ensureRootIsScheduled` with scheduling a
microtask.
We're decompressing and then writing and recompressing in the proxy.
This causes it to stall if buffered because `.pipe()` doesn't force
flush automatically.
I updated some of the Float tests that intentionally trigger an error to
assert on the specific error message, rather than swallow any errors
that may or may not happen.
If something throws as a result of `flushSync`, and there's remaining
work left in the queue, React should keep working until all the work is
complete.
If multiple errors are thrown, React will combine them into an
AggregateError object and throw that. In environments where
AggregateError is not available, React will rethrow in an async task.
(All the evergreen runtimes support AggregateError.)
The scenario where this happens is relatively rare, because `flushSync`
will only throw if there's no error boundary to capture the error.
This adds `encodeReply` to the Flight Client and `decodeReply` to the
Flight Server.
Basically, it's a reverse Flight. It serializes values passed from the
client to the server. I call this a "Reply". The tradeoffs and
implementation details are a bit different so it requires its own
implementation but is basically a clone of the Flight Server/Client but
in reverse. Either through callServer or ServerContext.
The goal of this project is to provide the equivalent serialization as
passing props through RSC to client. Except React Elements and
Components and such. So that you can pass a value to the client and back
and it should have the same serialization constraints so when we add
features in one direction we should mostly add it in the other.
Browser support for streaming request bodies are currently very limited
in that only Chrome supports it. So this doesn't produce a
ReadableStream. Instead `encodeReply` produces either a JSON string or
FormData. It uses a JSON string if it's a simple enough payload. For
advanced features it uses FormData. This will also let the browser
stream things like File objects (even though they're not yet supported
since it follows the same rules as the other Flight).
On the server side, you can either consume this by blocking on
generating a FormData object or you can stream in the
`multipart/form-data`. Even if the client isn't streaming data, the
network does. On Node.js busboy seems to be the canonical library for
this, so I exposed a `decodeReplyFromBusboy` in the Node build. However,
if there's ever a web-standard way to stream form data, or if a library
wins in that space we can support it. We can also just build a multipart
parser that takes a ReadableStream built-in.
On the server, server references passed as arguments are loaded from
Node or Webpack just like the client or SSR does. This means that you
can create higher order functions on the client or server. This can be
tokenized when done from a server components but this is a security
implication as it might be tempting to think that these are not fungible
but you can swap one function for another on the client. So you have to
basically treat an incoming argument as insecure, even if it's a
function.
I'm not too happy with the naming parity:
Encode `server.renderToReadableStream` Decode: `client.createFromFetch`
Decode `client.encodeReply` Decode: `server.decodeReply`
This is mainly an implementation details of frameworks but it's annoying
nonetheless. This comes from that `renderToReadableStream` does do some
"rendering" by unwrapping server components etc. The `create` part comes
from the parity with Fizz/Fiber where you `render` on the server and
`create` a root on the client.
Open to bike-shedding this some more.
---------
Co-authored-by: Josh Story <josh.c.story@gmail.com>
This fixes a handful of tests that were accidentally relying on React
synchronously queuing work in the Scheduler after a setState.
Usually this is because they use a lower level SchedulerMock method
instead of either `act` or one of the `waitFor` helpers. In some cases,
the solution is to switch to those APIs. In other cases, if we're
intentionally testing some lower level behavior, we might have to be a
bit more clever.
Co-authored-by: Tianyu Yao <skyyao@fb.com>
## Summary
Adds support for returning `undefined` from Server Components.
Also fixes a bug where rendering an empty fragment would throw the same
error as returning undefined.
## How did you test this change?
- [x] test failed with same error message I got when returning undefined
from Server Components in a Next.js app
- [x] test passes after adding encoding for `undefined`
We were treating Destructuring as if it could never allocate and therefore
didn't have to be memoized. That's only true if there are no rest spreads
though. This PR teaches the compiler to treat rest spreads differently for
scoping and memoization
purposes, fixing the newly added test case and some existing bugs.
Adds a new pass that uses escape analysis and React-specific heuristics to tune
the amount of memoization applied. Specifically, the pass ensures that we only
memoize:
* Values which escape (are directly returned or transitively aliased by a
returned value)
* ...and that are not JSX elements
* OR values which are _dependencies_ of scopes that produce an escaping value.
The latter case is necessary to avoid breaking memoization of an escaping value
bc a scope happened to have a non-escaping dependency.
## Algorithm
1. First we build up a graph, a mapping of IdentifierId to a node describing all
the scopes and inputs involved in creating that identifier. Individual nodes are
marked as definitely aliased, conditionally aliased, or unaliased:
a. Arrays, objects, function calls all produce a new value and are always marked
as aliased
b. Conditional and logical expressions (and a few others) are conditinally
aliased, depending on whether their result value is aliased.
c. JSX is always unaliased (though its props children may be)
2. The same pass which builds the graph also stores the set of returned
identifiers
3. We traverse the graph starting from the returned identifiers and mark
reachable dependencies as escaping, based on the combination of the parent
node's type and its children (eg a conditional node with an aliased dep promotes
to aliased).
4. Finally we prune scopes whose outputs weren't marked.
Node's MessageChannel implementation will leak if you don't explicitly
close the port. This updates the enqueueTask function we use in our
internal testing helpers to close the port once it's no longer needed.
We attempt to preload scripts that we detect during Fizz rendering
however when `noModule={true}` we should not because it will force
modern browser to fetch scripts they will never execute
Hoisted script resources already don't preload because we just emit the
resource immediately. This change currently on affects the preloads for
scripts that aren't hoistable
This was the actual bug. When EliminateRedundantPhis eliminates a phi, it has to
rewrite downstream usages of the phi id to the single operand id. We were
correctly doing that in all but one place. When we iterate _downstream phis_, we
were looking up the operands against the rewrite table, but not updating the phi
operands themselves to the rewritten value.
This fixes the bug, and incidentally fixes a test that has been broken for a
while and nagging at me.
Found while debugging the previous issue: `mapInstructionOperands()` should not
look at lvalues. The previous version was causing us to create extra phi nodes,
which interestingly weren't the actual problem behind the "SSA" bug, but sure
looked like it at first.
This is just moving some stuff around and renaming things.
This tuple is opaque to the Flight implementation and we should probably
encode it separately as a single string instead of a model object.
The term "Metadata" isn't the same as when used for ClientReferences so
it's not really the right term anyway.
I also made it optional since a bound function with no arguments bound
is technically different than a raw instance of that function (it's a
clone).
I also renamed the type ReactModel to ReactClientValue. This is the
generic serializable type for something that can pass through the
serializable boundary from server to client. There will be another one
for client to server.
I also filled in missing classes and ensure the serializable sub-types
are explicit. E.g. Array and Thenable.
Prior to #26347, our internal `act` API (not the public API) behaved
differently depending on whether the scope function returned a promise
(i.e. was an async function), for historical reasons that no longer
apply. Now that this is fixed, I've codemodded all async act scopes that
don't contain an await to be sync.
No pressing motivation other than it looks nicer and the codemod was
easy. Might help avoid confusion for new contributors who see async act
scopes with nothing async inside and infer it must be like that for a
reason.
This adds an async gap to our internal implementation of `act` (the one
used by our repo, not the public API). Rather than call the provided
scope function synchronously when `act` is called, we call it in a
separate async task. This is an extra precaution to ensure that our
tests do not accidentally rely on work being queued synchronously,
because that is an implementation detail that we should be allowed to
change. We don't do this in the public version of `act`, though we maybe
should in the future, for the same rationale. That might be tricky,
though, because it could break existing tests.
This also fixes the issue where our internal `act` requires an async
function. You can pass it a regular function, too.
We rely heavily on being able to batch rendering after multiple fetches
etc. have completed on the server. However, we only do this in the
Node.js build. Node.js `setImmediate` has the exact semantics we need.
To be after the current cycle of I/O so that we can collect after all
those I/O events already in the queue has been processed.
This doesn't exist in standard browsers, so we ended up not using it
there. We could've used `setTimeout` but that risks being throttled
which would severely negatively affect the performance so we just did it
synchronously there. We probably could just use the `scheduler` there.
Now we have a separate build for Edge where `setTimeout(..., 0)`
actually behaves like `setImmediate` which is what we want. So we can
just use that in that build.
@Jarred-Sumner not sure what you want for Bun.
To wait for the microtask queue to empty, our internal test helpers
schedule an arbitrary task using `setImmediate`. It doesn't matter what
kind of task it is, only that it's a separate task from the current one,
because by the time it fires, the microtasks for the current event will
have already been processed.
The issue with `setImmediate` is that Jest mocks it. Which can lead to
weird behavior.
I've changed it to instead use a message event, via the MessageChannel
implementation exposed by the `node:worker_threads` module.
We should consider doing this in the public implementation of `act`,
too.
Our internal `act` implementation flushes Jest's fake timer queue as a
way to force Suspense fallbacks to appear. So we should avoid using
timers in our internal tests.
This is not a public API. We only use it for our internal tests, the
ones in this repo. Let's move it to this private package. Practically
speaking this will also let us use async/await in the implementation.
- Specifies Node 16 as the minimum supported version.
- Remove no longer supported 17.x version (per
https://nodejs.dev/en/about/releases/)
- Add 19.x
Test Plan:
(using node 19) as that's what I'm adding)
- yarn build
- yarn test
**This commit only affects the internal version of `act` that we use in
this repo. The public `act` API is unaffected, for now.**
We should always await the result of an `act` call so that any work
queued in a microtask has a chance to flush. Neglecting to do this can
cause us to miss bugs when testing React behavior.
I codemodded all the existing `act` callers in previous PRs.
Similar to the rationale for `waitFor` (see #26285), we should always
await the result of an `act` call so that microtasks have a chance to
fire.
This only affects the internal `act` that we use in our repo, for now.
In the public `act` API, we don't yet require this; however, we
effectively will for any update that triggers suspense once `use` lands.
So we likely will start warning in an upcoming minor.
## Summary
In #26283, I changed definition of `NativeMethods` from an object to an
interface. This is correct but introduces a lot of errors in React
Native, so this restores the original definition and exports the fixed
type as a separate type so we can gradually migrate in React Native.
## How did you test this change?
Manually applied this change in React Native and validated the errors
are gone.
## Summary
resolves#25667
This PR also resolves several security issues in the standalone app
## How did you test this change?
Tested locally `yarn start` in react-devtools package. Everything works
normal
---
- To see the specific tasks where the Asana app for GitHub is being
used, see below:
- https://app.asana.com/0/0/1204123419819195
Similar to the rationale for `waitFor` (see #26285), we should always
await the result of an `act` call so that microtasks have a chance to
fire.
This only affects the internal `act` that we use in our repo, for now.
In the public `act` API, we don't yet require this; however, we
effectively will for any update that triggers suspense once `use` lands.
So we likely will start warning in an upcoming minor.
Similar to the rationale for `waitFor` (see #26285), we should always
await the result of an `act` call so that microtasks have a chance to
fire.
This only affects the internal `act` that we use in our repo, for now.
In the public `act` API, we don't yet require this; however, we
effectively will for any update that triggers suspense once `use` lands.
So we likely will start warning in an upcoming minor.
Similar to the rationale for `waitFor` (see
https://github.com/facebook/react/pull/26285), we should always await
the result of an `act` call so that microtasks have a chance to fire.
This only affects the internal `act` that we use in our repo, for now.
In the public `act` API, we don't yet require this; however, we
effectively will for any update that triggers suspense once `use` lands.
So we likely will start warning in an upcoming minor.
There's an old collection of test suites that test class component
behavior across ES6 (regular JavaScript classes), CoffeeScript classes,
and TypeScript classes. They work by running the same tests in all
environments and comparing the results.
Rather than use `act` or `waitFor` in these, I've changed them to use
`flushSync` instead so that they can flush synchronously. The reason is
that CoffeeScript doesn't have async/await, so we'd have to write those
tests differently than how they are written in the corresponding
modules. Since none of these tests cover any concurrent behavior, I
believe it's fine in this case to do everything synchronously; they
don't use any concurrent features, anyway, so effectively it's just
skipping a microtask.
## Summary
This is a small refactor of `ReactFabricHostComponent` to remove
unnecessary dependencies, unused methods and type definitions to
simplify a larger refactor of the class in a following PR
(https://github.com/facebook/react/pull/26321).
## How did you test this change?
Existing unit tests.
This PR is now based on #26256
The original matching function for `hydrateHoistable` some challenging
time complexity since we built up the list of matchable nodes for each
link of that type and then had to check to exclusion. This new
implementation aims to improve the complexity
For hoisted title tags we match the first title if it is valid (not in
SVG context and does not have `itemprop`, the two ways you opt out of
hoisting when rendering titles). This path is much faster than others
and we use it because valid Documents only have 1 title anyway and if we
did have a mismatch the rendered title still ends up as the
Document.title so there is no functional degradation for misses.
For hoisted link and meta tags we track all potentially hydratable
Elements of this type in a cache per Document. The cache is refreshed
once each commit if and only if there is a title or meta hoistable
hydrating. The caches are partitioned by a natural key for each type
(href for link and content for meta). Then secondary attributes are
checked to see if the potential match is matchable.
For link we check `rel`, `title`, and `crossorigin`. These should
provide enough entropy that we never have collisions except is contrived
cases and even then it should not affect functionality of the page. This
should also be tolerant of links being injected in arbitrary places in
the Document by 3rd party scripts and browser extensions
For meta we check `name`, `property`, `http-equiv`, and `charset`. These
should provide enough entropy that we don't have meaningful collisions.
It is concievable with og tags that there may be true duplciates `<meta
property="og:image:size:height" content="100" />` but even if we did
bind to the wrong instance meta tags are typically only read from SSR by
bots and rarely inserted by 3rd parties so an adverse functional outcome
is not expected.
Refactors the representation of ObjectExpression properties from a Map to an
`Array<ObjectProperty>` to prepare for the next diff which adds spread element
support.
## Do not hoist elements with `itemProp`
In HTML `itemprop` signifies a property of an `itemscope` with respect
to the Microdata spec
(https://html.spec.whatwg.org/multipage/microdata.html#microdata)
additionally `itemprop` is valid on any tag and can even make some tags
that are otherwise invalid in the `<body>` valid there (`<meta>` for
instance).
Originally I tried an approach where if you rendered something otherwise
hoistable inside an `itemscope` it would not hoist if it had an
`itemprop`. This meant that some components with `itemprop` could hoist
(if they were not scoped, which is generally invalid microdata
implementation). However the problem is things that do hoist, hoist into
the head and body and these tags can have an `itemscope`. This creates a
ton of ambiguity when trying to hydrate in these hoist scopes because we
can't know for certain whether a DOM node we find there was hoisted or
not even if it has an `itemprop` attribute. There are other scenarios
too that have abiguous semantics like rendering a hoistable with
`itemProp` outside of `<html itemScope={true>`. Is it fair to embed that
hoistable inside that itemScope even though it was defined outside?
To simplify the situation and disambiguate I dropped the `itemscope`
portion from the implementation and now any host component that could
normally be hoisted will not hoist if it has an `itemProp` prop.
In addition to the changes made for `itemProp` this PR also modifies
part of the hydration implementation to be more tolerant of tags
injected by 3rd parties. This was opportunistically done when we needed
to have context information like `inItemScope` but with the most recent
implementation that has been removed. I have however left the hydration
changes in place as it is a goal to make React handle hydrating the
entire Document even when we cannot control whether 3rd parties are
going to inject tags that React will not render but are also not
hoistables
-------
##### Original Description when we considered tracking itemScope
>One recent decision was to make elements using the `itemProp` prop not
hoistable if they were inside and itemScope. This better fits with
Microdata spec which allows for meta tags and other tag types usually
reserved for the `<head>` to be used in the `<body>` when using
itemScope.
>
>To implement this a number of small changes were necessary
>
>1. HostContext in prod needed to expand beyond just tracking the
element namespace for new element creation. It now tracks whether we are
in an itemScope. To keep this efficient it is modeled as a bitmask.
>2. To disambiguate what is and is not a potential instance in the DOM
for hoistables the hydration algo was updated to skip past non-matching
instances while attempting to claim the instance rather than ahead of
time (getNextHydratable).
>3. React will not consider an itemScope on `<html>`, `<head>`, or
`<body>` as a valid scope for the hoisting opt-out. This is important as
an invariant so we can make assumptions about certain tags in these
scopes. This should not be a functional breaking change because if any
of these tags have an `itemScope` then it can just be moved into the
first node inside the `<body>`
>
>Since we were already updating the logic for hydration to better
support `itemScope` opt-out I also changed the hydration behavior for
suspected 3rd party nodes in `<head>` and `<body>`. Now if you are
hydrating in either of those contexts hydration will skip past any
non-matching nodes until it finds a match. This allows 3rd party scripts
and extensions to inject nodes in either context that React does not
expect and still avoid a hydration mismatch.
>
>This new algorithm isn't perfect and it is possible for a mismatch to
occur. The most glaring case may be if a 3rd party script prepends a
`<div>` into `<body>` and you render a `<div>` in `<body>` in your app.
there is nothing to signal to React that this div was 3rd party so it
will claim is as the hydrated instance and hydration will almost
certainly fail immediately afterwards.
>
>The expectation is that this is rare and that if falling back to client
rendering is transparent to the user then there is not problem here. We
will continue to evaluate this and may change the hydration matching
algorithm further to match user and developer expectations
BuildHIR currently propagates UnsupportedNodes for collection types where the
element itself can fail (for example object expressions where the key may not be
valid). However, given that we currently abort compilation after the first
failing pass (and will probably do so for quite a while) I think we can simplify
and just always return the collection. Note that I already did this for
destructuring. I'm open to leaving the code as-is if you prefer, though.
This PR starts to clean up our handling of lvalues and rvalues by adding new
`eachInstructionLValues()` and `mapInstructionLValues()` helpers. Now,
`eachInstructionOperand()` and `mapInstructionOperands()` only visit true
rvalues, and the new passes must be used to visit lvalues. This allows us to
remove the special-casing for StoreLocal and Destructure in most of the passes.
Currently, any commit to React causes an internal sync since the Git
commit hash is part of the build. This creates a lot more sync commits
and noise than necessary, see:
https://github.com/facebook/react/commits/builds/facebook-www
This PR changes the version string to be a hash of the target build
files instead. This way we get a new version with any change that
actually impacts the generated files and still have a matching version
across the files.
Some build artifacts contain multiple version strings. It seems like an
oversight to me that this `.replace` call just replaces the one that
happens to be first.
Instead of replacing original function with compiled code, this adds an option
to append the code and switch between the two based on an `isForgetEnabled` test
condition that's imported from the specified gatingModule.
---
**This PR slightly changes the semantics of ReactiveScopeDependencies**.
Previously, reading a ReactiveScopeDependency is guaranteed to preserve the
`nullthrows` semantics of its own declarations (not that of its inner scopes).
This does not affect the overall correctness properties, since we already hoist
reading of conditional dependencies (and thus may throw earlier than the
original source).
E.g. we already do not preserve *where* the nullthrows occurs.
```javascript
function Component(props) {
// throws here, before print(x)
const c_0 = props.a.b !== $[0];
let x;
if (c_0) {
x = {};
print(x);
if (...) mutate1(x, props.a.b);
mutate2(x, props.a.b);
// ...
```
### Summary
This is an optimization, not a correctness property.
When propagating reactive dependencies of an inner scope up to its parent, we
want to *retain information about conditional dependencies* -- not the derived
unconditional dependencies. This helps us produce more granular dependencies in
the parent scope.
Current implementation:
```javascript
const innerScopeDeps = innerScope.depTree.deriveMinimalUnconditionalDeps();
for (const dep of innerScopeDeps) {
currentScope.depTree.addDep(dep);
}
```
New implementation:
```javascript
// union of a tree takes union of each node
currentScope.depTree = currentScope.depTree.union(innerScope.depTree);
```
### Example
In the below example:
- `scope @1` has a conditional dependency of `props.a.b`, but that reduces to
the unconditional dependency `props`
- `scope @0` itself has a unconditional dependency of `props.a.b`
- Currently, Forget joins the derived / reduced dependencies of inner scopes,
which adds `props` as unconditional dependency of `scope @0`
- With this change, Forget joins the property trees and retains info about
conditional deps, which adds `props.a.b` as a conditional dep of `scope @0`.
```javascript
// scope @0 (deps=[???] decls=[x, y])
let y = {};
// scope @1 (deps=[props] decls=[x])
let x = {};
if (foo) mutate1(x, props.a.b);
mutate2(y, props.a.b);
```
### Followup
We currently keep track of properties unconditionally accessed per
ReactiveBlock. Eventually we want to keep track of properties unconditionally
accessed across blocks (as according to control flow).
Consider the following code, in which sibling scopes 0 and 1 are sequentially
executed. In this case, we can safely add props.a.b as a dependency of scope 1.
```javascript
// scope@0 (deps=[props.a.b], decls=[x])
let x = { a: foo(props.a.b) };
// scope@1 (deps=[???], decls=[y])
let y = {};
if (...) {
mutate(y, props.a.b);
}
```
---
Implementation details summarized in comments.
Overall, we want to calculate a `ReactiveDependencyTree` for every conditional
block. If we know that conditional blocks are exhaustive (e.g. all CFG paths
calculates a tree), we can take `intersection(depsFromEachBlock)` and add this
to the parent Reactive + conditional scope `parentDeps = union(parentDeps,
intersection(...))`.
We use trees instead of individual deps here because we can still derive
unconditional accesses.
e.g.
```
let x = {};
// props.a is an unconditional access here
if (foo(other)) {
x.a = props.a.b;
} else {
x.b = props.a.c;
}
```
---
Small refactor of reactive dependency logic, no behavioral change.
- Moves ReactiveDependencyTree logic into `DeriveMinimalDependencies`.
- this moves hides most helper functions + types 🥳
- made `ReactiveDependencyTree` a class
- Changes `#dependencies` type: `Set<ReactiveScopeDep>` ->
`ReactiveDependencyTree`
- instead of collecting all dependencies into a tree in the end, we now eagerly
join dependencies into the tree on `visitDep`
- this is needed for the next PR in the stack, which relies on incremental
merging
When the work loop is suspended, we shouldn't schedule a new render task
until the promise has resolved. When I originally implemented this, I
wasn't sure where to put this logic — `ensureRootIsScheduled` is the
more natural place for it, but that's also a really hot path, so I chose
to do it elsewhere, and left a TODO to reconsider later.
Now it's later. I'm working on a refactor to move the
`ensureRootIsScheduled` call to always happen in a microtask, so that if
there are multiple updates/pings in a single event, they get batched
into a single operation. Which means I can put the logic in that
function where it belongs.
(This only affects our own internal repo; it's not a public API.)
I think most of us agree this is a less confusing name. It's possible
someone will confuse it with `console.log`. If that becomes a problem we
can warn in dev or something.
## Summary
The following methods have exactly the same implementation on Fabric and
the legacy renderer:
* `findHostInstance_DEPRECATED`
* `findNodeHandle`
* `dispatchCommand`
* `sendAccessibilityEvent`
This just extracts those functions to a common module so they're easier
to change (no need to sync changes in 2 files).
## How did you test this change?
Existing tests (this is a refactor).
Based on a bug report from @bvaughn.
`act` should not consult `shouldYield` when it's performing work,
because in a unit testing environment, I/O (such as `setTimeout`) is
likely mocked. So the result of `shouldYield` can't be trusted.
In the regression test, I simulate the bug by mocking `shouldYield` to
always return `true`. This causes an infinite loop in `act`, because it
will keep trying to render and React will keep yielding.
We support any super type of anything that we can serialize. Meaning
that as long as the Type that's passed through is less precise, it means
that we can encoded it as any subtype and therefore the incoming type
doesn't have to be the subtype in that case. Basically, as long as
you're only passing through an `Iterable<T>` in TypeScript, then you can
pass any `Iterable<T>` and we'll treat it as an array.
For example we support Promises *and* Thenables but both are encoded as
Promises.
We support Arrays and since Arrays are also Iterables, we can support
Iterables.
For @wongmjane
Previously when a called server reference function was rejected, the
emitted error chunk was not flushed, and the request was not properly
closed.
Co-authored-by: Sebastian Markbage <sebastian@calyptus.eu>
We always look up these references in a map so it doesn't matter what
their value is. It could be a hash for example.
The loaders now encode a single $$id instead of filepath + name.
This changes the react-client-manifest to have a single level. The value
inside the map is still split into module id + export name because
that's what gets looked up in webpack.
The react-ssr-manifest is still two levels because that's a reverse
lookup.
This converts some of our test suite to use the `waitFor` test pattern,
instead of the `expect(Scheduler).toFlushAndYield` pattern. Most of
these changes are automated with jscodeshift, with some slight manual
cleanup in certain cases.
See #26285 for full context.
This converts some of our test suite to use the `waitFor` test pattern,
instead of the `expect(Scheduler).toFlushAndYield` pattern. Most of
these changes are automated with jscodeshift, with some slight manual
cleanup in certain cases.
See #26285 for full context.
This converts some of our test suite to use the `waitFor` test pattern,
instead of the `expect(Scheduler).toFlushAndYield` pattern. Most of
these changes are automated with jscodeshift, with some slight manual
cleanup in certain cases.
See #26285 for full context.
This converts some of our test suite to use the `waitFor` test pattern,
instead of the `expect(Scheduler).toFlushAndYield` pattern. Most of
these changes are automated with jscodeshift, with some slight manual
cleanup in certain cases.
See #26285 for full context.
I'm in the process of codemodding our test suite to the waitFor pattern.
See #26285 for full context.
This module required a lot of manual changes so I'm doing it as its own
PR. The reason is that most of the tests involved simulating an async
import by wrapping them in `Promise.resolve()`, which means they would
immediately resolve the next time the microtask queue was flushed. I
rewrote the tests to resolve the simulated import explicitly.
While converting these tests, I also realized that the `waitFor` helpers
weren't properly waiting for the entire microtask queue to recursively
finish — if a microtask schedules another microtask, the subsequent one
wouldn't fire until after `waitFor` had resolved. To fix this, I used
the same strategy as `act` — wait for a real task to finish before
proceeding, such as a message event.
## Summary
Fix bug in how the Fizz external runtime processes existing template
elements.
Bug:
- getElementsByTagName returns a HTMLCollection, which is live.
- while iterating over an HTMLCollection, we call handleNode which
removes nodes
Fix:
- Call Array.from to copy children of `document.body` before processing.
- We could use `querySelectorAll` instead, but that is likely slower due
to reading more nodes.
## How did you test this change?
Did ad-hoc testing on Facebook home page by commenting out the mutation
observer and adding the following.
```javascript
window.addEventListener('DOMContentLoaded', function () {
handleExistingNodes(document.body);
});
```
This converts some of our test suite to use the `waitFor` test pattern,
instead of the `expect(Scheduler).toFlushAndYield` pattern. Most of
these changes are automated with jscodeshift, with some slight manual
cleanup in certain cases.
See #26285 for full context.
In #1287 i implemented basic handling for destructuring in DCE: if any of the
pattern values are used, we retained the whole instruction as-is. However,
ideally we could prune out unused elements from the pattern. There are pretty
simple rules:
* ArrayPattern we can eliminate unused elements from the end.
* ObjectPattern we can eliminate any unused element, but only if there is no
rest element.
This is more followup toward deleting Instruction.lvalue. The previous PR
ensured that all Instruction.lvalue identifiers are only ever assigned to once.
Now we ensure that `lowerExpression()` is _only_ called via
`lowerExpressionToTemporary()`, ie we now always lower every single expression
to a temporary.
This will make it easier to make lvalue a part of the InstructionValue instead
of the instruction itself, in follow-up PRs.
As part of removing Instruction.lvalue we need to ensure that it is only used to
represent that instruction's value — the InstructionKind should always be Const.
The one place where we violated this was for value blocks, specifically
ConditionalExpression and LogicalExpression. For both of those, we generate a
single temporary place to represent the expression result. Then the consequent
and alternate branch ended in a `LoadLocal` that reassigned that temporary (in
the lvalue) to the result of that branch.
This PR changes to use StoreLocal instead, and updates the recently added
validation pass to ensure that all identifiers that appear in an
Instruction.lvalue are only ever assigned once.
Changes to explicitly model destructuring (array and object patterns), expanding
support to include rest elements and preserving destructuring through the
output. The new "Destructure" instruction is similar to "StoreLocal" but has a
pattern instead of a place. For now each level of nested array/object patterns
creates a separate destructure instruction, which ensures we have a temporary
Place to talk about the intermediate array/object and its type/effects etc.
Example:
```
// INPUT
const [x, {y}, ...z] = a; // yay rest elements work now!
// HIR
[1] <unknown> $2 = LoadLocal a$1
[2] <unknown> $6 = Destructure Const [ <unknown> x$3, <unknown> $4, ...<unknown>
z$5 ] = <unknown> $2
[3] <unknown> $8 = Destructure Const { y: <unknown> y$8 } = <unknown> $4
// OUTPUT
const [x, t0, ...z] = a;
const {y} = t0;
```
Note that we can still collapse to a single destructure statement during
codegen, independently of whether we have separate instructions internally. For
now i'm going w the simple approach of emitting multiple statements in codegen
(the code will very likely get further rewritten by downstream babel passes
anyway).
Also, I don't love the "if StoreLocal/Destructure else ..." pattern that the
StoreLocal created and that this PR entrenches. As discussed w @gsathya offline,
the long-term direction will be to add a separate visitor, roughly
`eachLValue()` and `eachOperand()` so that we can treat all instructions the
same. Existing Instruction.lvalue will go away and become a property of the
other types of instructions.
## Summary
I'm working on a refactor of the definition of `Instance` in Fabric and
I came across this code that seemed to be for compatibility with Paper,
but that it would actually throw an error in that case.
In Paper, `stateNode` is an instance of `ReactNativeFiberHostComponent`,
which doesn't have a `canonical` field. We try to access nested
properties in that field in a couple of places here, which would throw a
type error (cannot read property `_nativeTag` of `undefined`) if we
actually happened to pass a reference to a Paper state node.
In this line:
```javascript
const isFabric = !!(
fromOrToStateNode && fromOrToStateNode.canonical._internalInstanceHandle
);
```
If it wasn't Fabric, `fromOrToStateNode.canonical` would be undefined,
and we don't check for that before accessing
`fromOrToStateNode.canonical._internalInstanceHandle`. This means that
we actually never use this logic in Paper or we would've seen the error.
## How did you test this change?
Existing tests.
This converts some of our test suite to use the `waitFor` test pattern,
instead of the `expect(Scheduler).toFlushAndYield` pattern. Most of
these changes are automated with jscodeshift, with some slight manual
cleanup in certain cases.
See #26285 for full context.
This converts some of our test suite to use the `waitFor` test pattern,
instead of the `expect(Scheduler).toFlushAndYield` pattern. Most of
these changes are automated with jscodeshift, with some slight manual
cleanup in certain cases.
See #26285 for full context.
There is a problem with <style> as resource. For css-in-js libs there
may be an very large number of these hoistables being created. The
number of style tags can grow quickly and to help reduce the prevalence
of this FIzz now aggregates all style tags for a given precedence into a
single tag. The client can 'hydrate' against these compound tags but
currently on the client insertions are done individually.
additionally drops the implementation where style tags are embedding in
a template for one where `media="not all"` is set. The idea is to have
the browser construct the underlying stylesheet eagerly which does not
happen if the tag is embedded in a template
Key Decision:
One choice made in this PR is that we flush style tags eagerly even if a
boundary is blocked that is the only thing that depends on that style
rule. The reason we are starting with this implementation is that it
allows a very condensed representation of the style resources. If we
tracked which rules were used in which boundaries we would need a style
resource for every rendered <style> tag. This could be problematic for
css-in-js libs that might render hundreds or thousands of style tags.
The tradeoff here is we slightly delay content reveal in some cases (we
send extra bytes) but we have fewer DOM tags and faster SSR runtime
The codemod I used in #26288 accidentally caused some comments to be
deleted. Because not all affected lines included comments, I didn't
notice until after landing.
This adds the comments back.
## Summary
When looking into the compiled code of `installHook.js` of the extension
build, I noticed that it actually includes the large `attach` function
(from renderer.js). I don't think it was expected.
This is because `hook.js` imports from `backend/console.js` which
imports from `backend/renderer.js` for `getInternalReactConstants`
A straightforward way is to extract function
`getInternalReactConstants`. However, I think it's more simplified to
just merge these two files and save the 361K renderer.js from the
extension build since we have always been loading this code anyways.
I changed the execution check from `__REACT_DEVTOOLS_ATTACH__ ` to the
session storage.
## How did you test this change?
Everything works normal in my local build.
InferMutableRangesForAlias is about extending the mutable ranges, not for
updating the alias sets. Let's refactor this into a separate pass.
InferMutableRangesForAlias was iterating over alias sets and not the HIR so this
refactor isn't costing us any additional perf cost (in terms of an extra
iteration over the HIR).
Identifiers don't need skipping anyways, so this doesn't affect the existing
behavior.
In the future, we will special case handling of LHS of AssignmentExpression
which will require us to not skip the RHS.
The mutable range difference for assignment is just 1 which is something we
usually don't track as we care about mutation and not assignment.
But this isn't true for context refs whose (re) assignment is actually a
mutation.
Having undefined as the initial value makes this a primitive. There's a separate
bug where we need to remove type inference for captured refs that get mutated
but that's secondary -- we're currently not even marking the Identifier LHS as a
captured ref. Fix the test to repro this bug for now.
## Summary
A few methods in `ReactFiberReconciler` are supposed to return
`PublicInstance` values, but they return the `stateNode` from the fiber
directly. This assumes that the `stateNode` always matches the public
instance (which it does on Web) but that's not the case in React Native,
where the public instance is a field in that object.
This hasn't caused issues because everywhere where we use that method in
React Native we actually extract the real public instance from this
"fake" public instance.
This PR fixes the inconsistency and cleans up some code.
## How did you test this change?
Existing tests.
This converts some of our test suite to use the `waitFor` test pattern,
instead of the `expect(Scheduler).toFlushAndYield` pattern. Most of
these changes are automated with jscodeshift, with some slight manual
cleanup in certain cases.
See #26285 for full context.
Over the years, we've gradually aligned on a set of best practices for
for testing concurrent React features in this repo. The default in most
cases is to use `act`, the same as you would do when testing a real
React app. However, because we're testing React itself, as opposed to an
app that uses React, our internal tests sometimes need to make
assertions on intermediate states that `act` intentionally disallows.
For those cases, we built a custom set of Jest assertion matchers that
provide greater control over the concurrent work queue. It works by
mocking the Scheduler package. (When we eventually migrate to using
native postTask, it would probably work by stubbing that instead.)
A problem with these helpers that we recently discovered is, because
they are synchronous function calls, they aren't sufficient if the work
you need to flush is scheduled in a microtask — we don't control the
microtask queue, and can't mock it.
`act` addresses this problem by encouraging you to await the result of
the `act` call. (It's not currently required to await, but in future
versions of React it likely will be.) It will then continue flushing
work until both the microtask queue and the Scheduler queue is
exhausted.
We can follow a similar strategy for our custom test helpers, by
replacing the current set of synchronous helpers with a corresponding
set of async ones:
- `expect(Scheduler).toFlushAndYield(log)` -> `await waitForAll(log)`
- `expect(Scheduler).toFlushAndYieldThrough(log)` -> `await
waitFor(log)`
- `expect(Scheduler).toFlushUntilNextPaint(log)` -> `await
waitForPaint(log)`
These APIs are inspired by the existing best practice for writing e2e
React tests. Rather than mock all task queues, in an e2e test you set up
a timer loop and wait for the UI to match an expecte condition. Although
we are mocking _some_ of the task queues in our tests, the general
principle still holds: it makes it less likely that our tests will
diverge from real world behavior in an actual browser.
In this commit, I've implemented the new testing helpers and converted
one of the Suspense tests to use them. In subsequent steps, I'll codemod
the rest of our test suite.
## Summary
I'm going to start implementing parts of this proposal
https://github.com/react-native-community/discussions-and-proposals/pull/607
As part of that implementation I'm going to refactor a few parts of the
interface between React and React Native. One of the main problems we
have right now is that we have private parts used by React and React
Native in the public instance exported by refs. I want to properly
separate that.
I saw that a few methods to attach event handlers imperatively on refs
were also exposing some things in the public instance (the
`_eventListeners`). I checked and these methods are unused, so we can
just clean them up instead of having to refactor them too. Adding
support for imperative event listeners is in the roadmap after this
proposal, and its implementation might differ after this refactor.
This is essentially a manual revert of #23386.
I'll submit more PRs after this for the rest of the refactor.
## How did you test this change?
Existing jest tests. Will test a React sync internally at Meta.
Add a `logger` option so compiler errors are surfaced in our metrics collection
pipeline.
We can probably later merge the global `log` function with it.
Adds a new `StoreLocal <kind> <place> = <value>` instruction which stores
<value> into <place>. With this change, Instruction.lvalue is _always_ a `const`
temporary, and never a named identifier (there's a new validation pass to assert
this). StoreLocal is the only way to declare or update a named identifier: the
instructionKind property says whether it's a const/let declaration or a
reassignment. Naturally a _lot_ of passes had to be updated to make this work,
but the existing Effect.Store variant that @gsathya added made this overall
straightforward.
Note that as of this PR several passes still have code to handle the possibility
of an instruction lvalue being something other than a temporary. When we clean
that up in a follow-up, there will be a lot less of the duplication that appears
here. For example, CodegenReactiveFunction has two places to handle variable
declarations in this PR. However, one of them is to handle lvalues, which should
now _always_ be temporaries and never emit a regular variable declaration.
Similarly, several passes have to build up a table of identifier -> identifier
(because of LoadLocal). Longer-term, we should update the Place abstraction so
that it directly specifies the instruction which created that temporary, so we
can look it up on demand instead of needing an extra mapping.
Adds support for DoWhileStatements. It's pretty similar to how we handle While,
except in the case where a test block is unreachable (for example, an early
unconditional `break` within the loop body). In this scenario we eliminate the
terminal altogether and replace it with a goto to the loop block.
Changes InstructionValue::Place to InstructionValue::LoadLocal for clarity, this
is intended as the only instruction where a variable can appear as an operand.
All other instructions operands will be temporaries.
Selective hydration is implemented by suspending the current render
using a special internal opaque object. This is conceptually similar to
suspending with a thenable in userspace, but the opaque object should
not leak outside of the reconciler.
We were accidentally passing this object to DevTool's
markComponentSuspended function, which expects an actual thenable. This
happens in the error handling path (handleThrow).
The fix is to check for the exception reason before calling
markComponentSuspended. There was already a naive check in place, but it
didn't account for all possible enum values of the exception reason.
Builds on #26257.
To do this we need access to a manifest for which scripts and CSS are
used for each "page" (entrypoint).
The initial script to bootstrap the app is inserted with
`bootstrapScripts`. Subsequent content are loaded using the chunks
mechanism built-in.
The stylesheets for each pages are prepended to each RSC payload and
rendered using Float. This doesn't yet support styles imported in
components that are also SSR:ed nor imported through Server Components.
That's more complex and not implemented in the node loader.
HMR doesn't work after reloads right now because the SSR renderer isn't
hot reloaded because there's no idiomatic way to hot reload ESM modules
in Node.js yet. Without killing the HMR server. This leads to hydration
mismatches when reloading the page after a hot reload.
Notably this doesn't show serializing the stream through the HTML like
real implementations do. This will lead to possible hydration mismatches
based on the data. However, manually serializing the stream as a string
isn't exactly correct due to binary data. It's not the idiomatic way
this is supposed to work. This will all be built-in which will make this
automatic in the future.
This proxies requests through the global server instead of requesting
RSC responses from the regional server. This is a bit closer to
idiomatic, and closer to SSR.
This also wires up HMR using the Middleware technique instead of server.
This will be an important part of RSC compatibility because there will
be a `react-refresh` aspect to the integration.
This convention uses `Accept` header to branch a URL between HTML/RSC
but it could be anything really. Special headers, URLs etc. We might be
more opinionated about this in the future but now it's up to the router.
Some fixes for Node 16/17 support in the loader and fetch polyfill.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Adding `preconnect` and `prefetchDNS` to rendering-stub build
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
---
> If this operand is used in a scope, has a dynamic value, and was defined
before this scope, then its a dependency of the scope.
> (from current comments in PropagateScopeDependencies::visitDependency)
A reactive scope can take a dependency from a definition produced by an
incomplete parent scope. Our tests previously did not cover this, since most
object types aliased together and remained mutable throughout a ReactiveScope.
e.g. our tests did not have
```
scope @0 (deps=..., declarations=[x, y]) {
x = {};
// define a reactive, immutable value that is not aliased to become mutable
const immutableVal = ...;
scope @1 (deps=immutableVal, declarations=[y]) {
y = read(immutableVal)
}
mutateX(x, ...);
}
```
We should not add a dependency if it is produced in exactly the same scope as
the one it is used. It is safe (and correct) to depend on values produced by a
parent scope.
---
Note that we still should check for whether a defining scope is active to
determine whether it should be added as a output of that scope
([src](b608ab20d5/forget/src/ReactiveScopes/PropagateScopeDependencies.ts (L469-L478))).
Access of an identifier produced by a parent scope (i.e. adding a variable
defined by a scope's parent as its own dependency) does not require adding that
identifier to the parent's `declarations`, since that identifier is already
valid to access via identifier binding rules.
---
Following #1216:
If a value is known to be immutable, then it doesn't need to be considered
'captured' since no mutation should occur.
Couldn't figure out a unit test in which this specific fix matters, but we need
this to fix test output of #1273
cc. @gsathya, would love some feedback / eyes on this. This makes sense for
Primitives in particular (which are always read / copied in rval position), but
I'm not as familiar with edge cases for other immutable values especially around
lambdas.
---
Our current compiler has specific logic for determining what can be a reactive
value / reactive dependency.
Currently, all of the following affect whether an identifier is a reactive:
- **alias analysis** (applicable to objects)
- **data + control flow** (whether any other reactive identifiers is used in
determining it)
- **reactive scopes** (we generalize and say anything produced by a block with
reactive dependencies must be non-stable and reactive)
- this is not true in the case of const primitives, but an overestimate is safe
- whether the **scope that declares this identifier** is ~~currently active~~
the same scope in which it is used (fixed by #1275)
(since a scope cannot be dependent on itself)
These conditions are complex. We end up inferring most identifiers as `mutable`
and `object` types, which have different stability and aliasing properties from
primitives. As a result, we're missing some cases in our existing test coverage.
Test case output is fixed by #1274 and #1275
---
(This can be separated from the stack below, which implements conditional
dependencies. Happy to merge that first and open this as a new stack if that
produces a significantly better Git PR history.)
---
See comment block in `PropagateScopeDependencies` and added test case
`reduce-reactive-conditional-dependencies` for correctness properties /
dependency merging logic.
---
See comment block in `PropagateScopeDependencies` and added test case
`reduce-reactive-unconditional-dependencies` for correctness properties /
dependency merging logic.
---
We never use the `Place` of a ReactiveScopeDependency, except for when we want
to access its identifier. Later PRs in this stack will convert
`ReactiveScopeDependency` to property access trees (and traverse over the tree).
This usually involves merging multiple Dependencies into trees (where each root
is a unique identifier). We then traverse over each tree to extract its
dependencies (e.g. unconditional leaves).
```
{place: {loc: 1, identifier: 'props'}, path: ['a', 'b']}
{place: {loc: 2, identifier: 'props'}, path: ['a']}
// merges into a single tree root, which should represent a single identifier
```
The `place` of each individual `ReactiveScopeDependency` will be lost during the
tree traversal, and it doesn't really make sense to recreate them using the
`Place` attached to the tree root.
---
Patch and simplify logic around merging overlapping reactive dependencies.
Added `reduce-reactive-unconditional-deps` test fixtures, which tries to cover
all cases of merging unconditional dependencies (to a minimal dependencies set).
Please let me know if I missed any
preloads often need to come with a type attribute which allows browsers
to decide if they support the preloading resource's type. If the type is
unsupported the preload will not be fetched by the Browser. This change
adds support for `type` in `ReactDOM.preload()` as a string option.
Adds two new ReactDOM methods
### `ReactDOM.prefetchDNS(href: string)`
In SSR this method will cause a `<link rel="dns-prefetch" href="..." />`
to flush before most other content both on intial flush (Shell) and late
flushes. It will only emit one link per href.
On the client, this method will case the same kind of link to be
inserted into the document immediately (when called during render, not
during commit) if there is not already a matching element in the
document.
### `ReactDOM.preconnect(href: string, options?: { crossOrigin?: string
})`
In SSR this method will cause a `<link rel="dns-prefetch" href="..."
[corssorigin="..."] />` to flush before most other content both on
intial flush (Shell) and late flushes. It will only emit one link per
href + crossorigin combo.
On the client, this method will case the same kind of link to be
inserted into the document immediately (when called during render, not
during commit) if there is not already a matching element in the
document.
This lets us put it in the same server that would be serving this
content in a more real world scenario.
I also de-CRA:ified this a bit by simplifying pieces we don't need.
I have more refactors coming for the SSR pieces but since many are
eyeing these fixtures right now I figured I'd push earlier.
The design here is that there are two servers:
- Global - representing a "CDN" which will also include the SSR server.
- Regional - representing something close to the data with low waterfall
costs which include the RSC server.
This is just an example.
These are using the "unbundled" strategy for the RSC server just to show
a simple case, but an implementation can use a bundled SSR server.
A smart SSR bundler could also put RSC and SSR in the same server and
even the same JS environment. It just need to ensure that the module
graphs are kept separately - so that the `react-server` condition is
respected. This include `react` itself. React will start breaking if
this isn't respected because the runtime will get the wrong copy of
`react`. Technically, you don't need the *entire* module graph to be
separated. It just needs to be any part of the graph that depends on a
fork. Like if "Client A" -> "foo" and "Server B" -> "foo", then it's ok
for the module "foo" to be shared. However if "foo" -> "bar", and "bar"
is forked by the "react-server" condition, then "foo" also needs to be
duplicated in the module graph so that it can get two copies of "bar".
Fixes https://github.com/facebook/react/issues/25924 for React DevTools
specifically.
## Summary
If we remove the script after it's loaded, it creates a race condition
with other code. If some other code is searching for the first script
tag or first element of the document, this might broke it.
## How did you test this change?
I've tested in my local build that even if we remove the script tag
immediately, the code is still correctly executed.
When resuming a suspended render, there may be more Hooks to be called
that weren't seen the previous time through. Make sure to switch to the
mount dispatcher when calling use() if the next Hook call should be
treated as a mount.
Fixes#25964.
We encode strings 2048 UTF-8 bytes at a time. If the string we are
encoding crosses to the next chunk but the current chunk doesn't fit an
integral number of characters, we need to make sure not to send the
whole buffer, only the bytes that are actually meaningful.
Fixes#24985. I was able to verify that this fixes the repro shared in
the issue (be careful when testing because the null bytes do not show
when printed to my terminal, at least). However, I don't see a clear way
to add a test for this that will be resilient to small changes in how we
encode the markup (since it depends on where specific multibyte
characters fall against the 2048-byte boundaries).
## Summary
We had this as a temporary fix for #24626. Now that Chrome team decides
to turn the flag on again (with good reasons explained in
https://bugs.chromium.org/p/chromium/issues/detail?id=1241986#c31), we
will turn it into a long term solution.
In the future, we want to explore whether we can render React elements
on panel.html instead, as `requestAnimationFrame` produces higher
quality animation.
## How did you test this change?
Tested on local build with "Throttle non-visible cross-origin iframes"
flag enabled.
This PR changes BuildHIR to lower all operands to temporaries. Example:
```javascript
// Input
a + b;
// Previous Lowering
Const t0 = BinaryOperation Place(a) "+" Place(b)
// New Lowering
Const t0 = Place(a);
Const t1 = Place(b);
BinaryOperation Place(t0) "+" Place(t1)
```
This is necessary to ensure we're always referring to the correct version of a
variable, even in the case of reassignment mid-expression. For example, we
previously evaluated `let x=1; x + (x = 2) + x` incorrectly to 6 because we
lowered the `x = 2` prior to the binary operators. We now lowers each instance
of x to a temporary, ensuring they refer to the correct SSA version of the
variable, and produce the correct result (5).
Note that with this change, the _only_ place a variable can appear as an
operator is when the InstructionValue is a raw identifier. This was already the
case for globals (as of the LoadGlobal instruction). All other instruction value
variants will only ever receive temporaries as arguments.
This necessitated a few changes to our inference:
* The logic to extend the range of phi operands (if the phi is mutated) was
previously in LeaveSSA, but that was actually too late. The introduction of
lowering to temporaries help discover failing cases, which I fixed earlier in
the stack by moving the logic to extend the range of phi operands into the
InferMutableRanges fixpoint loop.
* PropagateScopeDependencies now has to track variable reassignments in addition
to tracking property accesses
* AnalyzeFunctions now has to track variable reassignments in addition to
tracking property accesses
* InferReactiveIdentifiers now needs a fixpoint iteration, because identifiers
don't directly appear together in the same instruction anymore (such that we can
directly propagate the reactivity between them). Instead, we'll first see that
the temporaries are reactive, and have to propagate that back to the identifiers
the temporaries were loaded from.
Overall while this does introduce a bit more complexity, it also makes the
compiler more robust. As with the phi example illustrates, there are legitimate
inputs that can create similar indirections to that introduced by lowering
identifiers to temporaries.
Note that there’s a theme to the changes here: several analysis passes need to
map an operand back to its identifier value. Ideally our HIR structure would
directly support looking up the value for a temporary. For example, if operands
were references to eg the index of the instruction that produced them. Because
we don’t have such a representation yet (it would fall out naturally if we were
writing in Rust), we have to do some bookkeeping. The key takeaway here is that
this bookkeeping is incidental complexity given our current representation, not
fundamental complexity of the algorithm.
`eventTime` is a vestigial field that can be cleaned up. It was
originally used as part of the starvation mechanism but it's since been
replaced by a per-lane field on the root.
This is a part of a series of smaller refactors I'm doing to
simplify/speed up the `setState` path, related to the Sync Unification
project that @tyao1 has been working on.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn test --debug --watch TestName`,
open `chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
The `yarn flow` command, as suggested for every PR Submission (Task No.
9), tells us `The yarn flow command now requires you to pick a primary
renderer` and provides a list for the same. However, in at the bottom of
the prompt, it suggests `If you are not sure, run yarn flow dom`. This
command `yarn flow dom` does not exist in the list and thus the command
does nothing and exits with `status code 1` without any flow test.
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
While trying to submit a different PR for code cleaning, just during
submission I read the PR Guidelines, and while doing `yarn test`, `yarn
lint`, and `yarn flow`, I came across this issue and thought of
submitting a PR for the same.
## How did you test this change?
Since this code change does not change any logic, just the text
information, I only ran `yarn linc` and `yarn test` for the same.
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
Here is how the issue currently looks like:
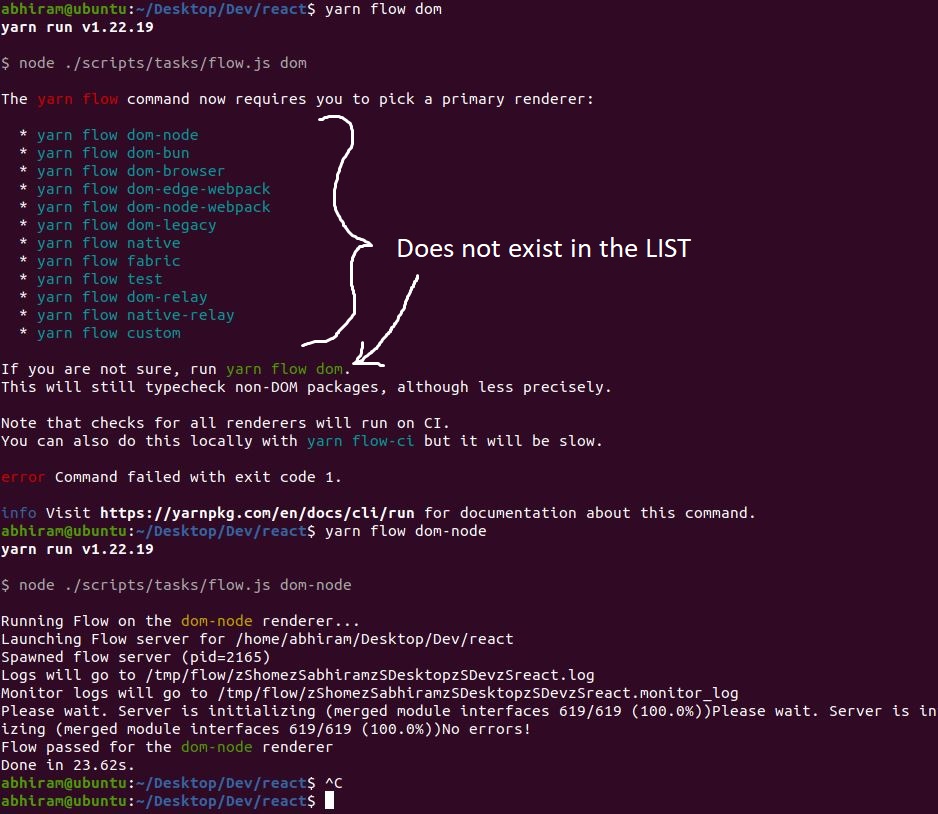
Signed-off-by: abhiram11 <abhiramsatpute@gmail.com>
Co-authored-by: abhiram11 <abhiramsatpute@gmail.com>
Using the `link:` protocol to create a dependency doesn't work when we
edit the `package.json` to lock the version to a specific version. It
didn't really work before neither, it was just that `yarn` installed an
existing `scheduler` dependency from npm instead of using the built one.
So I'm updating all the fixture to use the technique where we copy files
instead.
The `start` convention is a CRA convention but nobody else of the modern
frameworks / tools use this convention for a file watcher and dev mode.
Instead the common convention is `dev`. Instead `start` is for running a
production build that's already been built.
---------
Co-authored-by: Sebastian Silbermann <silbermann.sebastian@gmail.com>
This splits out the Edge and Node implementations of Flight Client into
their own implementations. The Node implementation now takes a Node
Stream as input.
I removed the bundler config from the Browser variant because you're
never supposed to use that in the browser since it's only for SSR.
Similarly, it's required on the server. This also enables generating a
SSR manifest from the Webpack plugin. This is necessary for SSR so that
you can reverse look up what a client module is called on the server.
I also removed the option to pass a callServer from the server. We might
want to add it back in the future but basically, we don't recommend
calling Server Functions from render for initial render because if that
happened client-side it would be a client-side waterfall. If it's never
called in initial render, then it also shouldn't ever happen during SSR.
This might be considered too restrictive.
~This also compiles the unbundled packages as ESM. This isn't strictly
necessary because we only need access to dynamic import to load the
modules but we don't have any other build options that leave
`import(...)` intact, and seems appropriate that this would also be an
ESM module.~ Went with `import(...)` in CJS instead.
> All notifications of mutations that have already been detected, but
not yet reported to the observer, are discarded. To hold on to and
handle the detected but unreported mutations, use the takeRecords()
method.
> -- ([Mozilla docs for disconnect](
https://developer.mozilla.org/en-US/docs/Web/API/MutationObserver/disconnect))
Fizz external runtime needs to process mutation records (representing
potential Fizz instructions) before calling `disconnect()`. We currently
do not do this (and might drop some instructions).
We should never use any logic beyond declarations in the module scope,
including conditions, because in a cycle that can lead to problems.
More importantly, the compiler can't safely reorder statements between
these points which limits the optimizations we can do.
## Summary
In rollup v1.19.4, The "treeshake.pureExternalModules" option is
deprecated. The "treeshake.moduleSideEffects" option should be used
instead, see
https://github.com/rollup/rollup/blob/v1.19.4/src/Graph.ts#L130.
## How did you test this change?
ci green
I found this while working to ensure that we always lower all operands to
temporaries. This works:
```javascript
// the whole computation of x is memoized in one block, bc of the mutation after
the phi
let x;
if (cond) {
x = someObj();
} else {
x = someObj();
}
mutate(x);
```
However, if you alias either of the operands, we lose the mutation:
```javascript
let x;
if (cond) {
const y = someObj(); // OOPS this gets independently memoized
x = y;
} else {
x = someObj();
}
mutate(x);
```
The core issue is that InferMutableRanges does not take into account mutation of
phis. ~~My first thought is that we need an additional, outer fixpoint iteration
loop to flow mutation back "up" to phi operands~~
edit: there was a much easier fix, we need to alias phi operands and phi id
within the existing fixpoint iteration. See follow-up PR which fixes.
It's confusing to new contributors, and me, that you're supposed to use
`yarn build-combined` for almost everything but not fixtures.
We should use only one build command for everything.
Updated fixtures to use the folder convention of build-combined.
This is a precursor to validating that all identifiers are defined - we need to
know about gobals and module declarations, so this PR adds the ability to
configure a Set<string> of defined globals. The default list is inspired by the
globals that prepack defines, which just comes from the spec definition.
Updates BuildHIR to produce LoadGlobal instructions for references to globals.
Note that this breaks our previous strategy of finding hook calls: that relied
on looking at the callee of a CallExpression and checking its name, which relied
on the callee not being lowered to a temporary. By lowering the name (eg
`useState`) to a temporary first, we now no longer see the name at the callsite.
Thankfully @gsathya solved this for us already by teaching type inference about
hooks, and more generally implementing type inference. I updated this so that we
infer the type of a LoadGlobal if the name is a hook: the type inference picks
this up and propagates the type forward correctly. So now, all places that
needed to check for a hook can just look at the type and everything works.
This is much more robust than before - you can now reassign a hook to a local
variable and we'll still detect that when you call it, you're calling a hook.
When we were upgrading flow in
6ddcbd4f96
we added `$FlowFixMe` for some parameters in this file. However, this
file is not compiled at all, and the `:` syntax breaks the code.
This PR removes the flow check in this file
Adds a new `LoadGlobal` InstructionValue variant which will be used to represent
identifiers that refer to globals. We don't construct this value type yet.
Updates the babel plugin so that environment options — including custom hook
definitions — can be passed in through the plugin:
* Renames `CompilerFlags` => `PluginOptions` since they are specific to the
babel plugin, and are no longer just flags.
* Moves the definition of `useFreeze()` out of the builtin hook list and instead
passes it when our unit tests configure the plugin.
InferReferenceEffects needs to be able to pass around the function's
Environment, but there is already a local class with that name. It's confusing
to have two "environment" concepts in one file, so this PR renames that local
class to the more appropriate `InferenceState` and renames local variables and
updates comments accordingly.
We currently have an awkward set up because the server can be used in
two ways. Either you can have the server code prebundled using Webpack
(what Next.js does in practice) or you can use an unbundled Node.js
server (what the reference implementation does).
The `/client` part of RSC is actually also available on the server when
it's used as a consumer for SSR. This should also be specialized
depending on if that server is Node or Edge and if it's bundled or
unbundled.
Currently we still assume Edge will always be bundled since we don't
have an interceptor for modules there.
I don't think we'll want to support this many combinations of setups for
every bundler but this might be ok for the reference implementation.
This PR doesn't actually change anything yet. It just updates the
plumbing and the entry points that are built and exposed. In follow ups
I'll fork the implementation and add more features.
---------
Co-authored-by: dan <dan.abramov@me.com>
## Summary
CSS has a new property called `scale` (`scale: 2` is a shorthand for
`transform: scale(2)`).
In vanilla JavaScript, we can do the following:
```js
document.querySelector('div').scale = 2;
```
which will make the `<div>` twice as big. So in JavaScript, it is
possible to pass a plain number.
However, in React, the following does not work currently:
```js
<div style={{scale: 2}}>
```
because `scale` is not in the list of unitless properties. This PR adds
`scale` to the list.
## How did you test this change?
I built `react` and `react-dom` from source and copied it into the
node_modules of my project and verified that now `<div style={{scale:
2}}>` does indeed work whereas before it did not.
While reviewing @poteto's PR I noticed that there were some cases of missing
dependencies. I tracked it down to a bug I introduced
[here](5b827eb85c (r100646304)).
Decl.id is meant to be the id of the instruction that declares the variable. We
then test to see if a dependency is later than that. If the Decl.id is
incorrectly too high, then we miss some dependencies thinking they aren't
defined yet.
This is to help prep for @poteto's renaming PR. To make that PR work we
generally need to use IdentifierId to distinguish "the same identifier" rather
than Identifier object identity.
InferReactiveIdentifiers has some extra logic to find identifiers declared in
the same scope, and promote non-reactive identifiers to reactive if they appear
inside a reactive scope (reactive scope == scope with one or more (reactive)
dependencies). Even though the identifier alone might not be technically
reactive (have no reactive inputs), it can get re-recreated if the scope
re-evaluates.
We can now do this during PruneNonReactiveDependencies as we exit out of each
scope.
I removed fixpoint iteration and all tests pass, which matches my intuition that
it's really that we need strictly two passes. Removing to simplify and for
performance (avoid unnecessary extra visits of the ast)
The fact that InferReactiveIdentifiers is integrated directly into
PropagateScopeDependencies has made the latter pretty tricky to debug at times.
If a dependency is missing, we have to introspect and figure out if that's
because it was somehow inferred as non-reactive. This PR creates a new
PruneNonReactiveDependencies pass to separate out these phases.
Optimizes dead code elimination. Currently it keeps iterating the control flow
graph until no new usages have been discovered, which accounts for usages across
loops. However, when there are no loops it's sufficient to iterate the CFG
exactly once.
With the upcoming changes to SSA renaming in #1194, we rewrite phi operand
identifiers to have the same IdentifierId as the declaration the identifier
originated from: so downstream checks need to compare ids instead of the
identifier instance.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn debug-test --watch TestName`, open
`chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
This TODO mentions an issue with JSDOM that [seems to have been
resolved](https://github.com/jsdom/jsdom/pull/2996).
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
- Ensured that the `document.activeElement` is no longer `node` after
`node.blur` is called.
- Verified that the tests still pass.
- Looked for [a merged PR that fixes the
issue](https://github.com/jsdom/jsdom/pull/2996).
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
## Summary
Fixes "ReferenceError: You are trying to access a property or method of
the Jest environment after it has been torn down." in
`ReactIncrementalErrorHandling-test.internal.js`
Alternatives:
1. Additional `await act(cb)` call where `cb` makes sure we can flush
until next paint without throwing
```js
// Ensure test isn't exited with pending work
await act(async () => {
root.render(<App shouldThrow={false} />);
});
```
1. Use `toFlushAndThrow`
```diff
- let error;
- try {
- await act(async () => {
- root.render(<App shouldThrow={true} />);
- });
- } catch (e) {
- error = e;
- }
+ root.render(<App shouldThrow={true} />);
- expect(error.message).toBe('Oops!');
+ expect(Scheduler).toFlushAndThrow('Oops!');
expect(numberOfThrows < 100).toBe(true);
```
But then it still wouldn't make sense to pass `resolve` and `reject` to
the next `flushActWork`. Even if the next `flushActWork` would flush
until next paint without throwing, we couldn't resolve or reject because
we already did reject.
## How did you test this change?
- `yarn test --watch
packages/react-reconciler/src/__tests__/ReactIncrementalErrorHandling-test.internal.js`
produces no more errors after the test finishes.
I forgot to guard the `getRootNode` call in #26106 and it fails in IE8
and old jsdom. I consolidated the implementation a bit and removed the
unguarded call
## Summary
Due to https://github.com/facebook/react/issues/25928 the attribute
fixture could no longer finish since it expects at least something to
render. But since Fizz currently breaks down completely on malformed
`<meta>` tags, the fixture could no longer handle this.
The fixture now renders valid types for `meta` tags.
Note that the snapshot change to `viewTarget`` is already on `main`.
Review by commit helps to understand this.
Added `html[lang]` so that we test at least one standard attribute on
`<html>`. `version` is obsolete so results are not that trustworthy.
## How did you test this change?
With Chrome Version 109.0.5414.119 (Official Build) (64-bit)
- `yarn build --type=UMD_DEV react/index,react-dom && cd
fixtures/attribute-behavior && yarn install && yarn start`
This tracks whether a value is a context ref or generated from a context ref.
This lets us track mutations to context refs and treat it separately as we want
this to be more conservative than our existing inference.
ValueKind.Context is exactly like ValueKind.Mutable but is more conservative.
## Summary
I ran into some two factor certification issue and had to resume the
publish script. However, this time if I confirmed the published package,
it will still try to publish the same version and fail. This is not
expected, and it blocks me from publishing the rest of the packages.
## How did you test this change?
I re-run the publish script after the change and successfully publish
the rest of the packages.
```
? Have you run the build-and-test script? Yes
✓ Checking NPM permissions for ryancat. 881 ms
? Please provide an NPM two-factor auth token: 278924
react-devtools version 4.27.2 has already been published.
? Is this expected (will skip react-devtools@4.27.2)? Yes
react-devtools-core version 4.27.2 has already been published.
? Is this expected (will skip react-devtools-core@4.27.2)? Yes
✓ Publishing package react-devtools-inline 23.1 secs
You are now ready to publish the extension to Chrome, Edge, and Firefox:
https://fburl.com/publish-react-devtools-extensions
When publishing to Firefox, remember the following:
Build id: 625690
Git archive: ******
```
When we have a key we read displayName eagerly for future warnings.
In general, React should be inspecting if something is a client
reference before dotting into it. However, we use displayName a lot and
it kind of has defined meaning for debugging everywhere it's used so
seems fine to treat this as undefined.
## Hoistables
In the original implementation of Float, all hoisted elements were
treated like Resources. They had deduplication semantics and hydrated
based on a key. This made certain kinds of hoists very challenging such
as sequences of meta tags for `og:image:...` metadata. The reason is
each tag along is not dedupable based on only it's intrinsic properties.
two identical tags may need to be included and hoisted together with
preceding meta tags that describe a semantic object with a linear set of
html nodes.
It was clear that the concept of Browser Resources (stylesheets /
scripts / preloads) did not extend universally to all hositable tags
(title, meta, other links, etc...)
Additionally while Resources benefit from deduping they suffer an
inability to update because while we may have multiple rendered elements
that refer to a single Resource it isn't unambiguous which element owns
the props on the underlying resource. We could try merging props, but
that is still really hard to reason about for authors. Instead we
restrict Resource semantics to freezing the props at the time the
Resource is first constructed and warn if you attempt to render the same
Resource with different props via another rendered element or by
updating an existing element for that Resource.
This lack of updating restriction is however way more extreme than
necessary for instances that get hoisted but otherwise do not dedupe;
where there is a well defined DOM instance for each rendered element. We
should be able to update props on these instances.
Hoistable is a generalization of what Float tries to model for hoisting.
Instead of assuming every hoistable element is a Resource we now have
two distinct categories, hoistable elements and hoistable resources. As
one might guess the former has semantics that match regular Host
Components except the placement of the node is usually in the <head>.
The latter continues to behave how the original implementation of
HostResource behaved with the first iteration of Float
### Hoistable Element
On the server hoistable elements render just like regular tags except
the output is stored in special queues that can be emitted in the stream
earlier than they otherwise would be if rendered in place. This also
allow for instance the ability to render a hoistable before even
rendering the <html> tag because the queues for hoistable elements won't
flush until after we have flushed the preamble (`<DOCTYPE
html><html><head>`).
On the client, hoistable elements largely operate like HostComponents.
The most notable difference is in the hydration strategy. If we are
hydrating and encounter a hoistable element we will look for all tags in
the document that could potentially be a match and we check whether the
attributes match the props for this particular instance. We also do this
in the commit phase rather than the render phase. The reason hydration
can be done for HostComponents in render is the instance will be removed
from the document if hydration fails so mutating it in render is safe.
For hoistables the nodes are not in a hydration boundary (Root or
SuspenseBoundary at time of writing) and thus if hydration fails and we
may have an instance marked as bound to some Fiber when that Fiber never
commits. Moving the hydration matching to commit ensures we will always
succeed in pairing the hoisted DOM instance with a Fiber that has
committed.
### Hoistable Resource
On the server and client the semantics of Resources are largely the same
they just don't apply to title, meta, and most link tags anymore.
Resources hoist and dedupe via an `href` key and are ref counted. In a
future update we will add a garbage collector so we can clean up
Resources that no longer have any references
## `<style>` support
In earlier implementations there was no support for <style> tags. This
PR adds support for treating `<style href="..."
precedence="...">...</style>` as a Resource analagous to `<link
rel="stylesheet" href="..." precedence="..." />`
It may seem odd at first to require an href to get Resource semantics
for a style tag. The rationale is that these are for inlining of actual
external stylesheets as an optimization and for URI like scoping of
inline styles for css-in-js libraries. The href indicates that the key
space for `<style>` and `<link rel="stylesheet" />` Resources is shared.
and the precedence is there to allow for interleaving of both kinds of
Style resources. This is an advanced feature that we do not expect most
app developers to use directly but will be quite handy for various
styling libraries and for folks who want to inline as much as possible
once Fizz supports this feature.
## refactor notes
* HostResource Fiber type is renamed HostHoistable to reflect the
generalization of the concept
* The Resource object representation is modified to reduce hidden class
checks and to use less memory overall
* The thing that distinguishes a resource from an element is whether the
Fiber has a memoizedState. If it does, it will use resource semantics,
otherwise element semantics
* The time complexity of matching hositable elements for hydration
should be improved
This is a temporary fix for the issue we discovered on our first integration,
where destructuring of a function return value is emitting the function call
multiple times:
```javascript
// Input
const [x, setX] = useState(null);
// Output
const x = useState(null)[0];
const setX = useState(null)[1];
```
The reason this happens is that we lower `useState(null)` to a temporary, and
then generate a ComputedLoad for each of x and setX. Codegen doesn't emit
temporaries eagerly - it assumes they are going to be used exactly once and it
re-emits the value each time the temporary is used. Hence why the
`useState(null)` part gets duplicated in the output.
Right now destructuring is the only place i'm aware of where we reuse
temporaries this way. And we do want to change codegen to preserve destructuring
in the output to correctly handle array patterns. However, that's a more
involved change. For now, this PR is a stopgap. During the pass where we promote
temporaries used in scopes to named variables, we now check to see if those
temporaries are used multiple times and promote them.
The above example would then generate something like
```javascript
const t0 = useState(null);
const x = t0[0];
const setX = t0[1];
```
This is still incorrect (it assumes t0 is an array), but it's more likely to
work in practice. I'll revert this change once we correctly handle
destructuring.
This is the first of a series of PRs, that let you pass functions, by
reference, to the client and back. E.g. through Server Context. It's
like client references but they're opaque on the client and resolved on
the server.
To do this, for security, you must opt-in to exposing these functions to
the client using the `"use server"` directive. The `"use client"`
directive lets you enter the client from the server. The `"use server"`
directive lets you enter the server from the client.
This works by tagging those functions as Server References. We could
potentially expand this to other non-serializable or stateful objects
too like classes.
This only implements server->server CJS imports and server->server ESM
imports. We really should add a loader to the webpack plug-in for
client->server imports too. I'll leave closures as an exercise for
integrators.
You can't "call" a client reference on the server, however, you can
"call" a server reference on the client. This invokes a callback on the
Flight client options called `callServer`. This lets a router implement
calling back to the server. Effectively creating an RPC. This is using
JSON for serializing those arguments but more utils coming from
client->server serialization.
Configures typescript-eslint for the project with an initial configuration that
starts with their recommended rules, and adds/disables a few (generally either
disabling warnings or promoting them to errors). The new `yarn lint` command is
not hooked up to CI yet, so for now this is something we can opt-in to running
locally. If you have some free time, help get us down to zero errors!
My general philosophy for linting, which I propose we follow, is that lints
should be very high-signal:
* Error, don't warn. If it's worth mentioning it's worth fixing.
* Enable rules that consistently identify real problems. If we frequently would
have to disable the rule due to false positives, it isn't high-signal.
* Enable rules that help improve consistent style (to avoid code review about
style rather than substance).
We're fixing the timing of layout and passive effects in React Native,
and adding support for some Web APIs so common use cases for those
effects can be implemented with the same code on React and React Native.
Let's take this example:
```javascript
function MyComponent(props) {
const viewRef = useRef();
useLayoutEffect(() => {
const rect = viewRef.current?.getBoundingClientRect();
console.log('My view is located at', rect?.toJSON());
}, []);
return <View ref={viewRef}>{props.children}</View>;
}
```
This could would work as expected on Web (ignoring the use of `View` and
assuming something like `div`) but not on React Native because:
1. Layout is done asynchronously in a background thread in parallel with
the execution of layout and passive effects. This is incorrect and it's
being fixed in React Native (see
afec07aca2).
2. We don't have an API to access layout information synchronously. The
existing `ref.current.measureInWindow` uses callbacks to pass the
result. That is asynchronous at the moment in Paper (the legacy renderer
in React Native), but it's actually synchronous in Fabric (the new React
Native renderer).
This fixes point 2) by adding a Web-compatible method to access layout
information (on Fabric only).
This has 2 dependencies in React Native:
1. Access to `getBoundingClientRect` in Fabric, which was added in
https://github.com/facebook/react-native/blob/main/ReactCommon/react/renderer/uimanager/UIManagerBinding.cpp#L644-
L676
2. Access to `DOMRect`, which was added in
673c7617bc
.
As next step, I'll modify the implementation of this and other methods
in Fabric to warn when they're accessed during render. We can't do this
on Web because we can't (shouldn't) modify built-in DOM APIs, but we can
do it in React Native because the refs objects are built by the
framework.
## Summary
- yarn.lock diff +-6249, **small pr**
- use jest-environment-jsdom by default
- uncaught error from jsdom is an error object instead of strings
- abortSignal.reason is read-only in jsdom and node,
https://developer.mozilla.org/en-US/docs/Web/API/AbortSignal/reason
## How did you test this change?
ci green
---------
Co-authored-by: Sebastian Silbermann <silbermann.sebastian@gmail.com>
## Summary
Prefer `getChildrenAsJSX` or `toMatchRenderedOutput` over `getChildren`.
Use `dangerouslyGetChildren` if you really need to (e.g. for `toBe`
assertions).
Prefer `getPendingChildrenAsJSX` over `getPendingChildren`. Use
`dangerouslyGetPendingChildren` if you really need to (e.g. for `toBe`
assertions).
`ReactNoop.getChildren` contains the fibers as non-enumerable
properties. If you pass the children to `toEqual` and have a mismatch,
Jest performance is very poor (to the point of causing out-of-memory
crashes e.g.
https://app.circleci.com/pipelines/github/facebook/react/38084/workflows/02ca0cbb-bab4-4c19-8d7d-ada814eeebb9/jobs/624297/parallel-runs/5?filterBy=ALL&invite=true#step-106-27).
Mismatches can sometimes be intended e.g. on gated tests.
Instead, I converted almost all of the `toEqual` assertions to
`toMatchRenderedOutput` assertions or compare the JSX instead. For
ReactNoopPersistent we still use `getChildren` since we have assertions
on referential equality. `toMatchRenderedOutput` is more accurate in
some instances anyway. I highlighted some of those more accurate
assertions in review-comments.
## How did you test this change?
- [x] `CIRCLE_NODE_TOTAL=20 CIRCLE_NODE_INDEX=5 yarn test
-r=experimental --env=development --ci`: Can take up to 350s (and use up
to 7GB of memory) on `main` but 11s on this branch
- [x] No more slow `yarn test` parallel runs of `yarn_test` jobs (the
steps in these runs should take <1min but sometimes they take 3min and
end with OOM like
https://app.circleci.com/pipelines/github/facebook/react/38084/workflows/02ca0cbb-bab4-4c19-8d7d-ada814eeebb9/jobs/624258/parallel-runs/5?filterBy=ALL:
Looks good with a sample size of 1
https://app.circleci.com/pipelines/github/facebook/react/38110/workflows/745109a2-b86b-429f-8c01-9b23a245417a/jobs/624651
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn debug-test --watch TestName`, open
`chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
This PR:
- Replaces the existing usages of methods from the `semver` library in
the React DevTools source with an inlined version based on
https://www.npmjs.com/package/semver-compare.
This appears to drop the unminified bundle sizes of 3 separate
`react-devtools-extensions` build artifacts by about 50K:

## How did you test this change?
I was originally working on [a fork of React
DevTools](https://github.com/replayio/react/pull/2) for use with
https://replay.io , specifically our integration of the React DevTools
UI to show the React component tree while users are debugging a recorded
application.
As part of the dev work on that fork, I wanted to shrink the bundle size
of the extension's generated JS build artifacts. I noted that the
official NPM `semver` library was taking up a noticeable chunk of space
in the bundles, and saw that it's only being used in a handful of places
to do some very simple version string comparisons.
I was able to replace the `semver` imports and usages with a simple
alternate comparison function, and confirmed via hands-on checks and
console logging that the checks behaved the same way.
Given that, I wanted to upstream this particular change to help shrink
the real extension's bundle sizes.
I know that it's an extension, so bundle size isn't _as_ critical a
concern as it would be for a pure library. But, smaller download sizes
do benefit all users, and that also includes sites like CodeSandbox and
Replay that are using the React DevTools as a library as well.
I'm happy to tweak this PR if necessary. Thanks!
I realized we hadn't updated InferReferenceEffects to match our latest thinking
on hooks. Specifically, we will default to assuming that hooks can mutate their
arguments and return mutable values — this works with our model since we don't
treat hooks specially for reactive scope construction. Ie, first we figure out
what variables construct together, then we create scopes, then we prune scopes
that contain hooks. So changing the reference effects for hooks "just works".
Note that it is helpful for our unit tests to have an example hook that we know
_does_ freeze its input and return a frozen value, so i've temporarily added
`useFreeze()` to the list of defined hooks. That is meant as a stopgap: the
right solution is to allow some way to tell the compiler about specific custom
hooks and their semantics.
Adds a subclass of ReactiveFunctionVisitor, ReactiveFunctionTransform, which
makes it easier to write passes that change the shape of a ReactiveFunction. The
two use-cases converted so far are both flattening away certain categories of
reactive scopes — this will make it easier to add a similar pass to prune scopes
that contain hook calls.
as reported in #26128 `ReactDOM.render(..., document)` crashed when
`enableHostSingletons` was on. This is because it had a different way of
clearing the container than `createRoot(document)`. I updated the legacy
implementation to share the clearing behavior of `creatRoot` which will
preserve the singleton instances.
I also removed the warning saying not to use `document.body` as a
container
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn debug-test --watch TestName`, open
`chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
This pull request emit the trace update events `drawTraceUpdates` with
the trace frame information when the trace update drawer runs outside of
web environment. This allows React Devtool running in mobile or other
platforms have a chance to render such highlights and provide similar
feature on web to provide re-render highlights. This is a feature needed
for identifying unnecessary re-renders.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
I tested this change with Flipper desktop app running against mobile
app, and verified that the event with correct array of frames are
passing through properly.
We currently abuse the browser builds for Web streams derived
environments. We already have a special build for Bun but we should also
have one for [other "edge"
runtimes](https://runtime-keys.proposal.wintercg.org/) so that we can
maximally take advantage of the APIs that exist on each platform.
In practice, we currently check for a global property called
`AsyncLocalStorage` in the server browser builds which we shouldn't
really do since browsers likely won't ever have it. Additionally, this
should probably move to an import which we can't add to actual browser
builds where that will be an invalid import. So it has to be a separate
build. That's not done yet in this PR but Vercel will follow
Cloudflare's lead here.
The `deno` key still points to the browser build since there's no
AsyncLocalStorage there but it could use this same or a custom build if
support is added.
This updates the Flight fixture to support the new ESM loaders in newer
versions of Node.js.
It also uses native fetch since react-fetch is gone now. (This part
requires Node 18 to run the fixture.)
I also updated everything to use the `"use client"` convention instead
of file name based convention.
The biggest hack here is that the Webpack plugin now just writes every
`.js` file in the manifest. This needs to be more scoped. In practice,
this new convention effectively requires you to traverse the server
graph first to find the actual used files. This is enough to at least
run our own fixture though.
I didn't update the "blocks" fixture.
More details in each commit message.
Effect.Capture is very similar to Effect.Read, but the only difference is that
this reference is stored somewhere via a Effect.Store.
Previously, any operand associated with a Effect.Store in the same instruction
would get aliased -- so there was no need to explicitly differentiate between a
"normal read" and "read that gets stored".
This difference is now explicit with FunctionExpression where every dependency
is "read" but only a few are "captured" for store (and mutation). In a follow up
PR, the mutating deps will have an Effect.Capture to differentiate from the
other non mutating deps (Effect.Read).
## Summary
Prettier was bumped recently. So any branch not including that bump,
might bring in outdated formatting (e.g.
https://github.com/facebook/react/pull/26068)
## How did you test this change?
- [x] `yarn prettier-all`
This commit adds a new Program visitor to our Babel plugin which then calls our
FunctionDeclaration visitor. Babel does some "smart" merging of plugin passes so
so even if plugin A is inserted prior to plugin B, if A does not have a Program
visitor and B does, B will run first.
Note that we also can't use Forget inside of a Babel preset as plugins run
_before_ presets (https://babeljs.io/docs/en/plugins/#plugin-ordering).
## Summary
This is to fix some edge cases I recently observed when developing and
using the extension:
- When you reload the page, there's a chance that a port (most likely
the devtools one) is not properly unloaded. In this case, the React
DevTools will stop working unless you create a new tab.
- For unknown reasons, Chrome sometimes spins up two service worker
processes. In this case, an error will be thrown "duplicate ID when
registering content script" and sometimes interrupt the execution of the
rest of service worker.
This is an attempt to make the logic more robust
- Automatically shutting down the double pipe if the message fails, and
allowing the runtime to rebuild the double pipe.
- Log the error message so Chrome believes we've handled it and will not
interrupt the execution.
This also seems to be helpful in fixing #25806.
The current caching of steps of `node_modules` doesn't work reliable as
is because it includes `arch` in the cache key. `arch` might be
different across workers in the same commit.
I couldn't find a way to optionally restore caches, so what this PR does
is:
- remove the setup step that ran before all other steps and essentially
just populates a circle CI cache key
- all other steps now do: restore yarn cache, `yarn install`, save yarn
cache (fast if already exists)
With this change the initial batch of jobs all race to populate the
cache, but any subsequent jobs should find the existing cache. The
expected downside would be slightly more worker CPU time with all the
parallel jobs, but wall time might be shorter (1 step less in the
critical path) and we should be more reliable as we no longer have the
failure with multiple archs.
## Alternative 1
Remove the `{arch}` from the cache key.
Downside: this might run into weird issues with native dependencies.
## Alternative 2
Somehow check if the cache was restored and only then run a yarn
install.
Downside: couldn't figure out if it's possible to only restore the yarn
cache if restoring the node_modules cache failed. Without that we'd
either always restore both the yarn and node_modules cache or do yarn
installs w/o cache which are prone to failure in the past.
The "dom" configuration is actually the node specific configuration. It
just happened to be that this was the mainline variant before so it was
implied but with so many variants, this is less obvious now.
The "bun" configuration is specifically for "bun". There's no "native"
renderer for "bun" yet.
When this flag is enabled, Forget will only compile function declarations opted
in via the `'use forget'` directive. By default this is false.
Tested internally, see related diffs
Improves DCE, using fixpoint iteration to detect values that are updated across
loops but otherwise never read. There is still some further optimization we can
do (the dce-loop case could optimize out `y`), but this seems like plenty for
now.
Actually, we probably have to add some return statements to our fixtures before
landing this, because otherwise most of the code goes away.
This is a first pass at DCE without having read any literate on the subject, so
lemme know if there's a better approach. That said the algorithm is:
* Keep a `Set<Identifier>` of identifiers that are used (and whose constructing
logic cannot be removed).
* Do a first RPO iteration of all block's phis. Any phi operand that
participates in a loop is preemptively marked as "used" even if it isn't
strictly used somewhere. This step is necessary bc these operands may otherwise
not be used.
* Do a second post-order iteration of all blocks, including iterating first
their terminals, then reverse iteration of instructions, then their phis. Mark
the operands of each as used as we encounter them, and prune instructions whose
lvalue is never used.
For now I was conservative about which types of instructions can be pruned. For
example, call instructions are never pruned, even if the result of the call is
never used.
However one catch is that we currently prune instructions that cause values to
become frozen. We had planned to add runtime calls (in dev) to freeze values for
runtime enforcement, and if we want to do that we can always add these
instructions back (or replace them with explicit freeze calls).
There are a few potential next steps but we should discuss whether they're worth
it:
* Use fixpoint iteration to find exactly which operands are actually used. This
would allow us to to prune cases such as `let x = 0; while (...) { x += 1 }` eg
where there's a phi but the result is never used. Such cases should be rare in
practice though.
* Eliminate more types of instructions, eg eliminate function calls that don't
have any mutable arguments.
There's a bug in the HIR->ReactiveFunction conversion for certain categories of
compound value blocks where we replace operands (which must be a Place) with a
ReactiveValue. This approach worked in practice for lots of cases so I thought a
type coercion was safe, but then I found a case where this assumption breaks
(see new test).
The updated logic fixes the bug and is simpler. When a value block gets split up
(because there was a nested value block), instead of replacing the earlier value
in the later instructions, we append the instructions together. This can result
in some extra nesting (which if we wanted we could flatten away) but ensures
that we maintain type-safety.
A SequenceExpression currently doesn't store the InstructionId that produced its
final `.value`. This PR adds that instruction id, which is then used in the next
PR as we compose SequenceExpressions.
Just small things I noticed when looking at InferTypes. I was thinking about how
we'd adjust this pass to account for hooks, i'll probably pause that for now but
putting this up in case you like the changes. If not no big deal!
This is because Webpack has a `typeof ... === 'object'` before its esm
compat test.
This is unfortunate because it means we can't have a nice error in CJS
when someone does this:
```
const fn = require('client-fn');
fn();
```
I also fixed some checks in the validator that read off the client ref.
It shouldn't do those checks against a client ref, since those now
throw.
We currently lower switch case test values within the wrong scope: the test
value really should be a value block rather than a `Place`. Until then, this PR
adds a bailout for complex test values: we allow primitives and identifiers
which should cover most real-world use-cases.
No need for InferAliasForStores to know about the semantics of each instruction
anymore. It's just a simple pass that iterates over every operand and lvalue.
The FunctionExpression is special cased because it's slightly different but I
have a follow up that removes this special casing.
This doesn't change codegen as the lvalue is unused but it lets us make this
pass be semantically the same across all instructions -- "alias lvalue and
operands of an instr".
Adds limited support for UpdateExpressions (`x++`). We now support the postfix
form (`x++` ok, `++x` is a todo) and only when the argument is an identifier. We
can relax these restrictions with more work, but this PR should be sufficient
for the examples we've seen so far.
This lets you pass Promises from server components to client components
and `use()` them there.
We still don't support Promises as children on the client, so we need to
support both. This will be a lot simpler when we remove the need to
encode children as lazy since we don't need the lazy encoding anymore
then.
I noticed that this test failed because we don't synchronously resolve
instrumented Promises if they're lazy. The second fix calls `.then()`
early to ensure that this lazy initialization can happen eagerly. ~It
felt silly to do this with an empty function or something, so I just did
the attachment of ping listeners early here. It's also a little silly
since they will ping the currently running render for no reason if it's
synchronously available.~ EDIT: That didn't work because a ping might
interrupt the current render. Probably need a bigger refactor.
We could add another extension but we've already taken a lot of
liberties with the Promise protocol. At least this is one that doesn't
need extension of the protocol as much. Any sub-class of promises could
do this.
Support TypeCastExpressions — `(x: TypeAnnotation)`. This is pretty
straightforward, it's semantically identical to a raw identifier.
One catch is that our prettier config is hard-coded to use the babel-ts parser,
i wasn't sure how to make that dynamic based on the file extension so for now i
just ignored .flow.js files in our pretter config.
```
function useBar(props) {
let z;
if (props.a) {
if (props.b) {
z = baz();
}
}
return z;
}
```
Currently fails with
```
InvariantViolation: A phi cannot have two operands initialized before its
declaration
```
Changes ReactiveWhileTerminal’s test to use the new value block representation.
This means logical and condition expressions will work as while test values now.
Updates some passes from ReactiveScopes/ to use the visitor added in the
previous PR. The +124/-354 line count on this diff tells the story — the new
visitor avoids a lot of boilerplate and helps focus on the logic not the
traversal.
Note that there are a few passes which transform the function such as
adding/removing scopes. A follow-up will extend the visitor to support that and
convert the remaining passes.
This adds a truly general-purpose visitor pattern for ReactiveFunction, modeled
on what's worked well in Relay Compiler. All types of node that have children
get a visitFoo/traverseFoo pair of functions. By default the visitFoo() function
delegates to the traverseFoo() function, but the visit variant is meant to be
overridden and can delegate to the traverseFoo() variant — this gives you
precise control so that you can save/restore state before/after traversing
children.
Probably the only interesting thing is that visitLValue() does not call
visitPlace() by default though it technically could. So far that is making sense
in the passes i converted.
Note that once all passes are updated to use this, i'll delete the other visitor
helpers for ReactiveFunction.
There's a bug with assignment expression in normal value blocks due to LeaveSSA.
Until that's resolved i'm temporarily distinguishing "loop" blocks and "value"
blocks, and disallowing assignment expressions in value blocks specifically.
Support conditional expressions from AST -> HIR -> ReactiveFunction -> AST. This
also helps make the patterns for value block handling more clear, so i was able
to extract some reusable logic in the HIR -> ReactiveFunction conversion phase.
Implements the conversion from LogicalTerminal into a ReactiveLogicalValue (and
ReactiveSequenveValue if necessary). The implementation is a bit rough, i clean
it up in subsequent PRs which revealed parts of the logic that could be shared w
ternaries.
Extends ReactiveInstruction's value type to be a regular InstructionValue *or* a
LogicalValue. LogicalValue is operator, left, and right. It's really convenient
that we've already distinguished Instruction/ReactiveInstruction now — while the
_helpers_ here are updated to handle this new value type, the types ensure that
HIR can never encounter a LogicalValue.
The actual conversion of logical terminals into this value is complex and is
later in the stack.
Changes the lowering for LogicalExpression to use the new 'logical' terminal.
Whereas before we tried to more directly model the semantics of `??` by
generating an `if (<lhs> != null)`, we now generate a branch terminal that looks
at the lhs.
The HIR -> ReactiveFunction construction for logical and branch terminals are
placeholders while I refactor the ReactiveFunction representation to support
value blocks.
This is just shifting around some encoding strategies for Flight in
preparation for more types.
```
S1:"react.suspense"
J2:["$", "$1", {children: "@3"}]
J3:"Hello"
```
```
1:"$Sreact.suspense"
2:["$", "$1", {children: "$L3"}]
3:"Hello"
```
## Summary
This PR removes the unused dependency 'abort-controller' from the
project. it helps to keep the project clean and maintainable.
## How did you test this change?
ci green
## Summary
Removing package jest-mock-scheduler introduced in PR
https://github.com/facebook/react/pull/14358, as it is no longer
referenced in the main branch code. The following files previously
referenced it:
- packages/scheduler/src/__tests__/Scheduler-test.js
- packages/scheduler/src/__tests__/SchedulerDOM-test.js
- packages/shared/__tests__/ReactDOMFrameScheduling-test.js
- scripts/jest/setupTests.js
- scripts/rollup/bundles.js
## How did you test this change?
ci green
The old version of prettier we were using didn't support the Flow syntax
to access properties in a type using `SomeType['prop']`. This updates
`prettier` and `rollup-plugin-prettier` to the latest versions.
I added the prettier config `arrowParens: "avoid"` to reduce the diff
size as the default has changed in Prettier 2.0. The largest amount of
changes comes from function expressions now having a space. This doesn't
have an option to preserve the old behavior, so we have to update this.
## Summary
The flag was first added in #16157 and was rolled out to employees in
D17430095. #25997 removed this flag because it wasn't dynamically set to
a value in www. The www side was mistakenly removed in D41851685 due to
deprecation of a TypedJSModule but we still want to keep this flag, so
let's add it back in + add a GK on the www side to match the previous
rollout.
See D42574435 for the dynamic value change in www
## How did you test this change?
```
yarn test
yarn test --prod
```
Revert https://github.com/facebook/react/commit/353c30252. The commit
breaks old React Native where `nativeFabricUIManager` is undefined. I
need to add unit test for this to make sure it doesn't happen in the
future and create a mechanism to deal with undefined
`nativeFabricUIManager`.
This is to unblock React sync to React Native.
This moves the bailout recording mechanism into a separate CompilerErrors class
instead of repurposing HIRBuilder. This is to allow other passes to also record
errors instead of immediately throwing.
This renames Module References to Client References, since they are in
the server->client direction.
I also changed the Proxies exposed from the `node-register` loader to
provide better error messages. Ideally, some of this should be
replicated in the ESM loader too but neither are the source of truth.
We'll replicate this in the static form in the Next.js loaders. cc
@huozhi @shuding
- All references are now functions so that when you call them on the
server, we can yield a better error message.
- References that are themselves already referring to an export name are
now proxies that error when you dot into them.
- `use(...)` can now be used on a client reference to unwrap it server
side and then pass a reference to the awaited value.
## Summary
resolves#26051
After we upgrade to Manifest V3, the browser no longer allow us to run
`eval` within the extension. It's not a problem for prod build, but for
dev build, webpack has been using eval to inject the source map for
devtool. This PR changes it to an alternative method.
Previously we were storing a pointer to the HIR or ReactiveFunction
prior to printing, so when we printed them it would always print the
results of the last pass. This commit changes it so we print them to
strings when iterating through the compiler pipeline so each snapshot is
correctly preserved

This was causing issues in various places where errors would be stringified.
Because the inner detail objects would contain a NodePath with circular
structures this would cause a JSON.stringify error in code outside of our
control. This change makes it so we always print the codeframe from the NodePath
and then passing the string.
We need to know the kind of each block (regular or value). Rather than specify
the kind when closing the block — when we've lost context about why the block
was created — it's simpler and more accurate to specify the kind when
creating/reserving the block.
Previously, `yarn prettier` didn't write changed files since `glob` produced
paths relative to cwd and `git diff --name-only` produced paths relative to git
root directory.
This changes `git diff --name-only` to `git diff --name-only --relative`
(Implemented as per discussions with @gsathya )
Handle OptionalMemberExpression by adding an 'optional' flag to `PropertyLoad`
instruction, which is set during `BuildHIR` and read during
`CodegenReactiveFunction`.
This commit repurposes CompilerError to represent an aggregate of error details
accumulated during HIR lowering. It also fixes the playground to correctly
render errors again.
Functions can capture variables declared after the definition of the function.
This re runs SSA to map the captured identifiers to the new SSA identifiers if
available.
As discussed, this repurposes OtherStatement as a catch all variant for
unsupported syntax or errors in the source. This also renames the previously
added ErrorTerminal to UnsupportedTerminal for consistency (plus makes it a
little bit less confusing that it's not an actual terminal representing an
Error).
Not loving the name but couldn't think of anything better, open to suggestions!
When `MergeOverlappingReactiveScopes` identified scopes to be merged, it was
currently (oops, my bad) updating the _existing_ scope's id and range. Later,
PropagateScopeDependencies marks outputs of a scope by updating that
identifier's scope instance — so if that scope instance isn't shared, then the
output is lost. This PR fixes MergeOverlappingReactiveScopes to correctly update
all operands for a scope to have the same scope instance.
Makes debugging a little easier as the previous console.error would be logged
out of band with the jest error message. And the jest error would be missing the
error stack.
After some painful debugging I isolated the infinite loop when attempting to use
the BabelPlugin in hir-test rather than manually parsing and traversing it. The
issue is that in the BabelPlugin we were replacing the original
FunctionDeclaration with a new one, which would add it to Babel's traversal
queue. This would effectively create an infinite loop where we would try to
optimize a function that was already compiled by Forget (aside: _should_ running
the compiler multiple times on code work?).
To get around this we can just call the handy `skip` method on the new
FunctionDeclaration to tell Babel to stop traversing it. I'm also moving the
scope check here because I'll remove it from hir-test in a later commit.
Lower member expression if the receiver is in scope. Skip the remaining path
before capturing so we don't recurse down the identifiers in the member
expression.
Avoids printing debug information if it exactly matches what was last printed.
This means when debug printing (eg with `@only`) you'll see things like:
```
BuildReactiveFunctions:
...debug view...
FlattenReactiveLoops: (no change)
PropagateScopeDependencies:
...debug view...
```
Which saves time figuring out if something changed in a given pass.
Per design discussion, this PR changes BuildHIR to maintain the invariant that,
for each distinct variable in the input, that all references to that variable in
the HIR will have the same unique `name` _and_ same unique `id`. Phrased
differently: Identifiers with the same id will have the same name and
vice-versa.
This isn't an invariant we maintain throughout compilation — SSA form changes
the `id`s — but crucially, ensuring that the `name` is also unique allows us to
understand later which identifiers referred to the same original variable and
which were different.
Follow-up PRs will ensure that we maintain variable identifiers in the output as
well, in all cases except shadowing (and for shadowing, we'll rewrite
identifiers inside lambdas).
Adds `PropertyCall` and `ComputedCall`, which are a combination of
CallExpression and PropertyLoad/ComputedLoad, respectively. The goal is to
ensure that we correctly model the receiver of a call where the callee is a
member expression, and also accurately record scope dependencies in for both the
computed and non-computed (property) cases.
An alternative that I tried first was to add a `receiver: Place | null` to
CallExpression. That works well for HIR construction, but it's then very
difficult at codegen time to correctly reconstruct the original call: if the
receiver and callee share part of their structure then we can transform back to
a non-computed member expression, otherwise it has to be computed. Eg we have to
distinguish `a.b.c[d.foo]()` from `a.b.c[a.b.c.foo]()`. Given that our target is
high-level code, it seems reasonable to have a higher-level representation for
these cases.
I'm open to feedback but this feels pretty reasonable in terms of complexity /
precision of modeling.
Previously when converting from HIR -> ReactiveFunction we elided break/continue
terminals in places where control would implicitly transfer to the
break/continue target and therefore nothing has to be emitted. The one downside
of this approach is that it makes scope analysis a bit trickier. We want to
close scopes once we see an instruction id past the end of the scope's range,
but these implicit breaks were causing us to miss some instruction ids. We
compensated for this, but it's helpful to keep the representation explicit and
discard these terminals later in codegen.
Collapses HIRTReeVisitor into BuildReactiveFunction, allowing us to remove the
generic interface and simplify the code. Note that because the visitor was
already not attempting to group instructions by scope anymore, the visitor code
was very straightforward. This is mostly replacing calls to `appendBlock(block,
instr)` with `block.push(instr)`.
I noticed this was an experiment concluded 16 months ago (#21679) that
this extra work is beneficial
to break up cycles leaking memory in product code.
## Summary
Should unblock https://github.com/facebook/react/pull/25970
If the callback for `toWarnDev` was `async` and threw, we didn't
ultimately reject the await Promise from the matcher. This resulted in
tests failing even though the failure was expected due to a test gate.
## How did you test this change?
- [x] tested in https://github.com/facebook/react/pull/25970 with `yarn
test --r=stable --env=development
packages/react-dom/src/__tests__/ReactDOMFizzServer-test.js --watch`
- [x] `yarn test`
- [x] CI
This shim is no longer needed on www, in fact I had already deleted it
there and it's currently not on www. See D42503692 which is trying to
add it back as I didn't realize this file was synced from GitHub.
Cleans up the public exports for the package itself:
* `parseFunctions()` was only used in playground, so this moves the definition
there. I had to update playground's dependencies to ensure the babel version
matched.
* Flattens away the `HIR` const in the export, and exports just 4 functions all
at the top-level: `run()`, `compile()`, `printHIR()`, and
`printReactiveFunction()`.
This will make it very easy to split the core compiler into a separate package
from the babel plugin, though i'm not sure it's worth doing that (yet).
Other than BuildReactiveFunction (HIR -> ReactiveFunction), Codegen.ts was the
only other remaining place that we use HIRTreeVisitor. However, we've already
switched the compiler to use the new form of codegen,
CodegenReactiveFunction.ts. This PR extracts the shared code from Codegen.ts
into the latter, and deletes the unused bits of Codegen.ts which relied on the
visitor API.
This now frees us up to merge BuildReactiveFunction and HIRTreeVisitor, removing
all the complexity of the visitor trait and type params.
Note that the `ReactiveFunction` data type can represent non-reactive functions.
So we can still compile non-React code after this change, the pipeline is `AST`
-> (BuildHIR) -> `HIR` -> (BuildReactiveFunction) -> `ReactiveFunction` ->
(CodegenReactiveFunction) -> `AST`. Which is the exact sequence I mapped out at
the start of this project ;-) (happy that worked out!)
See the background in #982. This PR reimplements part of InferReactiveScopes,
merging overlapping reactive scopes, but against ReactiveFunction instead of the
HIR.
See the background in #982. This PR reimplements part of InferReactiveScopes,
aligning reactive scopes to block boundaries, but against ReactiveFunction
instead of the HIR.
The primary goal of this stack is to change HIRTreeVisitor to make it easier to
handle value blocks. That's complicated by the fact that the visitor is a
general-purpose visitor, used in several analysis passes including
BuildReactiveFunction (which translates HIR->ReactiveFunction while also
grouping instructions into scopes) and InferReactiveScopes (which is actually
two passes, one to align scopes to block boundaries, one to merge overlapping
scopes). The long-term goal then is as follows:
1. Make BuildReactiveFunction transform HIR->ReactiveFunction but _without_
reactive scopes.
2. Align scopes to block boundaries, but rewritten to operate on
ReactiveFunction
3. Merge overlapping scopes, again rewritten to operate on ReactiveFunction
4. Group statements within ReactiveFunction into ReactiveScopeBlocks (today this
occurs when constructing the ReactiveFunction).
This PR implements 1 and 4. Because the implementation is incomplete this would
break the whole compiler, so for now both versions are still around. By default
compilation uses the old pipeline, but if a feature flag is enabled we use the
new version. The plan is to incrementally fix up the new version of the passes
in this stack, and then cutover: removing the flag and the old version of the
passes.
These values are never imported into `ReactFeatureFlags.www.js`, so
they're unused:
- `allowConcurrentByDefault`
- `consoleManagedByDevToolsDuringStrictMode`
These values are never set in the WWW module
(https://fburl.com/code/dsb2ohv8), so they're always `undefined` on www:
- `createRootStrictEffectsByDefault`
- `enableClientRenderFallbackOnTextMismatch`
It's not enough to only update the mutable range of the canonical id created
instead of the phi but we need to update the mutable range of each of the
operands of the phi as well to account for the fact that the phi could've been
mutated later.
The operands are updated only if the phi is mutated later. Otherwise these
operands can be cached in their blocks.
Fixes https://github.com/facebook/react-forget/issues/978
Changes playground to use the modified `run()` function of the compiler, polling
the generator and building up a Map of tabs automatically based on the passes
that the compiler runs. This means tabs are always derived from the current
state of the compiler and we can never forget to add a pass.
<img width="1497" alt="Screen Shot 2023-01-10 at 11 06 03 AM"
src="https://user-images.githubusercontent.com/6425824/211639442-da421f73-e19e-4b63-9f33-0ce5a68cceb7.png">
Note the inclusion of some recently added passes that weren't added to the
playground — which was my fault but only bc i intended to ship this PR soon :-)
Turns CompilerPipeline into two functions:
* `run()` is a generator and yields values that are a disjoint union of either
AST/HIR/ReactiveFunction along with a name for that step. The idea is to use
this in the playground so that it always matches the exact steps for
compilation. I'll update playground in a follow-up.
* `compile()` is ast in, ast out, and uses `run()` under the hood.
This mock exists in 2 directories (with identical implementation) and
Jest just picks one at random. This removes one which makes it at least
deterministic and fixes a Jest warning on startup.
It existed in these 2 places:
-
`packages/react-server-dom-relay/src/__mocks__/JSResourceReferenceImpl.js`
-
`packages/react-server-native-relay/src/__mocks__/JSResourceReferenceImpl.js`
(removed)
These suppressions are no longer required.
Generated using:
```sh
flow/tool update-suppressions .
```
followed by adding back 1 or 2 suppressions that were only triggered in
some configurations.
## Summary
I was reading the source code of `ReactFiberLane.js` and I found the
third parameter of the function markRootPinged was not used. So I think
we can remove it.
## How did you test this change?
There is no logic changed, so I think there is no need to add unit
tests. So I run `yarn test` and `yarn test --prod` locally and all tests
are passed.
Co-authored-by: Jan Kassens <jkassens@meta.com>
Implements constant propagation/constant folding for a conservative subset of
the language. The approach is described in detail in the comments in the file
itself, a key note here is that this pass currently emits what looks like
garbage:
```
// input
const x = 1;
const y = x + 1;
// output
const x = 1;
2; // <---- you'll see a bunch of lines like this
const y = 2;
```
These useless lines occur where previously there was a temporary getting
calculated that was used later (so we saved it until it was used), but now it
isn't used later so we just emit it in-place. Dead code elimination (DCE) can
eliminate these and other useless statements later.
Note that a key motivation for implementing this pass is to reduce memoization
blocks to what is strictly required for dynamic computations. Why memoize at
runtime when we compute at build time?
After the previous changes these upgrade are easy.
- removes config options that were removed
- object index access now requires an indexer key in the type, this
cause a handful of errors that were fixed
- undefined keys error in all places, this needed a few extra
suppressions for repeated undefined identifiers.
Flow's
[CHANGELOG.md](https://github.com/facebook/flow/blob/main/Changelog.md).
This enables the "exact_empty_objects" setting for Flow which makes
empty objects exact instead of building up the type as properties are
added in code below. This is in preparation to Flow 191 which makes this
the default and removes the config.
More about the change in the Flow blog
[here](https://medium.com/flow-type/improved-handling-of-the-empty-object-in-flow-ead91887e40c).
This setting is an incremental path to the next Flow version enforcing
type annotations on most functions (except some inline callbacks).
Used
```
node_modules/.bin/flow codemod annotate-functions-and-classes --write .
```
to add a majority of the types with some hand cleanup when for large
inferred objects that should just be `Fiber` or weird constructs
including `any`.
Suppressed the remaining issues.
Builds on #25918
When we convert a LabeledStatement to HIR we can end up emitting "consecutive"
blocks, ie where there are two blocks such that control flow will always go from
from one block to the other, with no other way to reach the second block but
through the first. Example:
```javascript
label: {
foo();
break label;
}
bar();
```
Converts to
```
bb0:
foo()
goto bb1:
bb1:
bar();
...
```
Ideally in this case we would merge these into a single block:
* When debugging, the extra goto makes it look like there is conditional control
flow when there isn't. If the code is consecutive it's easier to understand that
if it's a single block.
* Conversion from HIR -> AST relies on consecutive code all being in a single
block, so this breaks codegen (we never visit the goto target since all gotos
are assumed to be safe to convert to a break or continue).
This PR adds a failing test case, the next PR fixes it.
Phi operands and Block predecessors currently use a `BasicBlock` reference
rather than the BlockId. This diverges from other places (like terminals) where
we use an id and not a direct object reference. Especially since blocks may get
rewritten or pruned, it's a bit cleaner to use the block id in these places.
Changes `shrink()` and `reversePostorderBlocks()` to modify the HIR in-place
rather than return a new function, for consistency with all our other passes
which mutate in-place (for performance reasons).
~~[Fizz] Duplicate completeBoundaryWithStyles to not reference globals~~
## Summary
Follow-up / cleanup PR to #25437
- `completeBoundaryWithStylesInlineLocals` is used by the Fizz external
runtime, which bundles together all Fizz instruction functions (and is
able to reference / rename `completeBoundary` and `resourceMap` as
locals).
- `completeBoundaryWithStylesInlineGlobals` is used by the Fizz inline
script writer, which sends Fizz instruction functions on an as-needed
basis. This version needs to reference `completeBoundary($RC)` and
`resourceMap($RM)` as globals.
Ideally, Closure would take care of inlining a shared implementation,
but I couldn't figure out a zero-overhead inline due to lack of an
`@inline` compiler directive. It seems that Closure thinks that a shared
`completeBoundaryWithStyles` is too large and will always keep it as a
separate function. I've also tried currying / writing a higher order
function (`getCompleteBoundaryWithStyles`) with no luck
## How did you test this change?
- generated Fizz inline instructions should be unchanged
- bundle size for unstable_external_runtime should be slightly smaller
(due to lack of globals)
- `ReactDOMFizzServer-test.js` and `ReactDOMFloat-test.js` should be
unaffected
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn debug-test --watch TestName`, open
`chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
This is the other approach for unifying default and sync lane
https://github.com/facebook/react/pull/25524.
The approach in that PR is to merge default and continuous lane into the
sync lane, and use a new field to track the priority. But there are a
couple places that field will be needed, and it is difficult to
correctly reset the field when there is no sync lane.
In this PR we take the other approach that doesn't remove any lane, but
batch them to get the behavior we want.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
yarn test
Co-authored-by: Andrew Clark <hi@andrewclark.io>
## Summary
Updating import for babel-code-frame to use the official @babel package,
as babel-code-frame is a ghost dependency. This change is necessary to
avoid potential issues and stay up-to-date with the latest version of
@babel/code-frame, which is already declared in our project's
package.json.
## How did you test this change?
yarn test
Flow introduced a new syntax to annotated the context type of a
function, this tries to update the rest and add 1 example usage.
- 2b1fb91a55 already added the changes
required for eslint.
- Jest transform is updated to use the recommended `hermes-parser` which
can parse current and Flow syntax and will be updated in the future.
- Rollup uses a new plugin to strip the flow types. This isn't ideal as
the npm module is deprecated in favor of using `hermes-parser`, but I
couldn't figure out how to integrate that with Rollup.
## Summary
This PR adds a "perf regression tests" page to react-devtools-shell.
This page is meant to be used as a performance sanity check we will run
whenever we release a new version or finish a major refactor.
Similar to other pages in the shell, this page can load the inline
version of devtools and a test react app on the same page. But this page
does not load devtools automatically like other pages. Instead, it
provides a button that allows us to load devtools on-demand, so that we
can easily compare perf numbers without devtools against the numbers
with devtools.
<img width="561" alt="image"
src="https://user-images.githubusercontent.com/1001890/184059633-e4f0852c-8464-4d94-8064-1684eee626f4.png">
As a first step, this page currently only contain one test:
mount/unmount a large subtree. This is to catch perf issues that
devtools can cause on the react applications it's running on, which was
once a bug fixed in #24863.
In the future, we plan to add:
- more test apps covering different scenarios
- perf numbers within devtools (e.g. initial load)
## How did you test this change?
In order to show this test app can actually catch the perf regression
it's aiming at, I reverted #24863 locally. Here is the result:
https://user-images.githubusercontent.com/1001890/184059214-9c9b308c-173b-4dd7-b815-46fbd7067073.mov
As shown in the video, the time it takes to unmount the large subtree
significantly increased after DevTools is loaded.
For comparison, here is how it looks like before the fix was reverted:
<img width="452" alt="image"
src="https://user-images.githubusercontent.com/1001890/184059743-0968bc7d-4ce4-42cd-b04a-f6cbc078d4f4.png">
## about the `requestAnimationFrame` method
For this test, I used `requestAnimationFrame` to catch the time when
render and commit are done. It aligns very well with the numbers
reported by Chrome DevTools performance profiling. For example, in one
run, the numbers reported by my method are
<img width="464" alt="image"
src="https://user-images.githubusercontent.com/1001890/184060228-990a4c75-f594-411a-9f85-fa5532ec8c37.png">
They are very close to the numbers reported by Chrome profiling:
<img width="456" alt="image"
src="https://user-images.githubusercontent.com/1001890/184060355-a15d1ec5-c296-4016-9c83-03e761f387e3.png">
<img width="354" alt="image"
src="https://user-images.githubusercontent.com/1001890/184060375-19029010-3aed-4a23-890e-397cdba86d9e.png">
`<Profiler>` is not able to catch this issue here.
If you are aware of a better way to do this, please kindly share with
me.
When unwrapping a promise with `use`, we sometimes suspend the work loop
from rendering anything else until the data has resolved. This is
different from how Suspense works in the old throw-a-promise world,
where rather than suspend rendering midway through the render phase, we
prepare a fallback and block the commit at the end, if necessary;
however, the logic for determining whether it's OK to block is the same.
The implementation is only incidentally different because it happens in
two different parts of the code. This means for `use`, we end up doing
the same checks twice, which is wasteful in terms of computation, but
also introduces a risk that the logic will accidentally diverge.
This unifies the implementation by moving it into the SuspenseContext
module. Most of the logic for deciding whether to suspend is already
performed in the begin phase of SuspenseComponent, so it makes sense to
store that information on the stack rather than recompute it on demand.
The way I've chosen to model this is to track whether the work loop is
rendering inside the "shell" of the tree. The shell is defined as the
part of the tree that's visible in the current UI. Once we enter a new
Suspense boundary (or a hidden Offscreen boundary, which acts a Suspense
boundary), we're no longer in the shell. This is already how Suspense
behavior was modeled in terms of UX, so using this concept directly in
the implementation turns out to result in less code than before.
For the most part, this is purely an internal refactor, though it does
fix a bug in the `use` implementation related to nested Suspense
boundaries. I wouldn't be surprised if it happens to fix other bugs that
we haven't yet discovered, especially around Offscreen. I'll add more
tests as I think of them.
This code was originally added in the old ExpirationTime implementation
of Suspense. The idea is that if multiple updates suspend inside the
same Suspense boundary, and both of them resolve, we should render both
results in the same batch, to reduce jank.
This was an incomplete idea, though. We later discovered a stronger
requirement — once we show a fallback, we cannot fill in that fallback
without completing _all_ the updates that were previously skipped over.
Otherwise you get tearing. This was fixed by #18411, then we discovered
additional related flaws that were addressed in #24685. See those PR
descriptions for additional context.
So I believe this older code is no longer necessary.
shrink visits all the fallthroughs even if they are unreachable so this isn't
the right place to prune unreachable blocks.
This PR moves pruning into a separate pass.
Supports computed properties (as LHS and RHS) correctly. Previously we only
handled member expressions where the property was an identifier, and would
incorrect treat `a[b]` the same as `a.b`. Now we correctly distinguish these and
convert `a[b]` as an IndexLoad and `a.b` as a PropertyLoad. Similar for
assignment, `a[b] = c` is an IndexStore. For both IndexLoad and IndexStore we
lower the property to a Place first.
Implements support for array and object de-structuring in variable declarations
and assignment expressions. Note that the code currently makes the overly
optimistic assumption that the RHS is an array or object that can be safely
indexed into. The correct representation would instead treat the RHS as possibly
iterable, but we need to consider the appropriate representation. I think it's
worth landing a first optimistic pass and we can iterate forward, this helps
make it more clear what the ideal representation would have to be and should
make a bunch of examples work. It also allows us to experiment with
representations of, and handling for, scope dependencies that involve computed
property access.
Adds new types for IndexLoad/IndexStore (renamed later in the stack to
ComputedLoad/ComputedStore) which will be used to represent computed property
access/update. The actual lowering to use these is later in the stack.
After the previous PR to change the scope dependency representation,
`Place.memberPath` is now completely unused, this PR deletes that field and all
references. Rejoice!
This is a pre-req to deleting the `Place.memberPath` field. We no longer need
memberPath in the HIR now that we have PropertyStore and PropertyLoad. However,
scope dependencies use memberPath to track the precise fields that a computation
depends upon. This PR changes scopes dependencies to use a new
`ReactiveScopeDependency` type (Place + optional path), which allows the next PR
to remove `Place.memberPath`.
Fixes codegen for chained assignment expressions. Previously each intermediate
assignment would be generated independently _in addition_ to the final chained
expression being emitted. We now emit a single chained expression, almost
exactly matching the input except for expanding from `x += 1` into `x = x + 1`.
There are two key changes:
* Ensuring that assignment expressions always generate an lvalue, which is
necessary for alias analysis to kick in, since it relies on the effect of the
lvalue to know where to look for aliasing.
* The above makes codegen think the entire assignment expression value is a
temporary that can be emitted later, but that isn't true. The new
PruneTemporaryLValue pass nulls out lvalues that are never read later, ensuring
that codegen can eagerly emit the value instead of saving it as a temporary.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn debug-test --watch TestName`, open
`chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
- Fixes https://github.com/facebook/react/issues/25682
## How did you test this change?
I tried this but it didn't work
```
yarn build --type=UMD_DEV react/index,react-dom && cd fixtures/attribute-behavior && yarn install && yarn start
```
Co-authored-by: eps1lon <silbermann.sebastian@gmail.com>
Converts assignment expressions where the lvalue is a MemberExpression to use
PropertyStore, rather than creating an lvalue with a member path. The net effect
is that lvalue will always have a null member path.
There are two main cases:
* `x.y = <value>`. We lower <value> to a Place, lower the object of the member
expression to a place (`object)` create a temporary Place for the result of the
assignment, and then create a `PropertyStore <object>, "<property>", <value>`.
* `x.y += <value>` (and similar update-in-place operands). We extract the object
of the member expression, read the current value via a PropertyLoad, compute the
updated value, and store it back with a PropertyStore (each of these goes into
its own temporary).
Adds a `InstructionValue::PropertyStore` variant and the minimal necessary
handling across the passes to get things to compile. Lowering is in the next PR.
…-realsies"
This reverts commit 3c8700cbc7502e56cca8d4bb77a08e1ee747c166.
I'm not sure how this happened but I accidentally hit up + enter on a previous
`ghstack land` command for a different stack and it landed this one.
Infuriating.
For unknown reasons I didn't have the energy to dig into, some Babel Error
objects can't be written to so despite formatting the error message, the
original one would still be used. To get around this I'm just constructing a
fake object with a `name` and `message` so the correctly formatted messages are
used.
This is an incremental step to removing `Place.memberPath`. This PR changes how
we handle MemberExpressions in rvalue position, converting to a new
`PropertyLoad` InstructionValue variant. Example:
```
let x = a.b;
x.y = b.c;
=>
Const tmp1 = PropertyLoad a, 'b';
Const x = Place tmp1;
Const tmp2 = PropertyLoad b, 'c';
Reassign x.y = tmp2
```
That we already recently made a chance to ensure that _if_ the lvalue is a
member expression, that we convert the RHS to a Place. So although `x.y = b.c`
could technically be lowered to a single instruction (with the`b.c` as a
PropertyLoad), we force this to a temporary to ensure that we can independently
memoize the RHS value.
The net result is that the following combinations are possible:
* `x = y`, lvalue identifier, rvalue identifier
* `x.y = y` lvalue member path, rvalue identifier
* `x = y.z` lvalue identifier, rvalue property load
As noted above, `x.y = a.b` no longer occurs (and there's an invariant for this
in one of the passes).
A follow-up PR will add a PropertyStore instruction so that we can remove member
paths in lvalue position too.
@josephsavona had the intuition that we were picking the wrong root in the
previous infinite loop test case, so the fix for this is to force a root to
always be picked. This works because `find` implements path compression (if a <-
b and b <- c, then we can just point a <- c to "flatten" the tree which makes
subsequent `find` operations more efficient since we don't have to follow the
ancestor chain each time), so we're forcing all those unions to pick one parent.
From some googling it looks like the traditional way to implement union is to
call `find` so this should be the "right" way to fix it (?).
I'm also adding a basic unit test for DisjointSet, I think we could revisit
later and see if property testing is worth it but for now I mainly wanted to
capture the regression test as a unit test.
Discovered this by accident modifying Joe's playground example. This seemed to
be triggered in inferReactiveScopeVariables when iterating over the DisjointSet
of scopeIdentifiers. In particular this test case contains a cycle and
DisjointSet.find would never terminate.
The github action was exceeding maximum allowed memory size because we were no
longer grouping messages correctly prior to formatting them in the script. I
think these were introduced when we integrated the Babel plugin into the
preprocessor. This PR strips out filenames from the message so they can be
grouped together again. Also added some light comments
Test plan: manually ran `scripts/test262.sh` and verified that the JSON was
grouped together correctly
I found this bug when working on a different task.
`pingSuspendedRoot` sometimes calls `prepareFreshStack` to interupt the
work-in-progress tree and force a restart from the root. The idea is
that if the current render is already in a state where it be blocked
from committing, and there's new data that could unblock it, we might as
well restart from the beginning.
The problem is that this is only safe to do if `pingSuspendedRoot` is
called from a non-React task, like an event handler or a microtask.
While this is usually the case, it's entirely possible for a thenable to
resolve (i.e. to call `pingSuspendedRoot`) synchronously while the
render phase is already executing. If that happens, and work loop
attempts to unwind the stack, it causes the render phase to crash.
Previously we weren't ever clearing the `dist` directory so there were likely
some vestigial files left over from previous builds that might have confused the
import path. This commit fixes the import path and also deletes the `dist`
directory on every build to ensure a clean slate.
Given that our type inference needs to be very conservative, there's not a lot
of benefit to having such fine grained type inference.
In the future, we can use type information from flow/ts for inference.
For now, we've decided to punt on super fine grained aliasing of fields (ie,
mutating x.y shouldn't mutate x.z or it's aliases).
This PR removes the code that tracks the aliases of each field. We can re-add
this when we revisit this functionality.
For the rest of the field aliasing, most of it has been replaced by
InferAliasForStores.
Splits handling of simple assignment updates (`=`) from update-assignments (`+=`
etc). This unblocks starting to support destructuring for the simple case in the
subsequent PR.
The test262 preprocessor was correctly running forget against all the functions
in each test file, but it was incorrectly transforming the file contents
overall. Previously we swapped the contents of the file for the transformed
output of the last function, now we use the babel plugin to rewrite functions in
place and keep the rest of the file intact.
Of course, the tests that failed before still fail. But when we fix them the
tests will work now.
Addressed a TODO from the previous PR. When we enter SSA form, when we rewrite
variable reassignments we currently change the identifier but leave the kind of
the lvalue alone; technically we should convert from Reassign to Const. After
doing that, it's easier to correctly update when we leave SSA form, we can
convert just a subset back into let/reassign (but leave most things alone as
const).
Reorders LeaveSSA so that it runs before we begin evaluating reactive scopes.
Note that reactive scopes must span the full construction of each variable — for
variables with a phi, this must span the declaration and all assignments of the
phi operands. And that's exactly what the new LeaveSSA does! LeaveSSA removes
phi nodes and ensure that all versions of a variable which flow into a phi have
been assigned a single canonical identifier (with an appropriate mutable range).
This PR includes this and some related changes:
* Reorders the pass
* Changes hir-test to print the final HIR, eg just prior to codegen
* Teaches LeaveSSA to update the mutable range of the canonical identifiers it
assigns, based on the min/max of the variables assigned.
Rather than special casing for field stores, look for Effect.Store to alias
fields.
In the future, this will be extended to other constructs like Array#push.
Effect.Store is exactly like Effect.Mutate, the only difference is that Store
aliases one into a another value.
There is no practical difference between Effect.Mutate and Effect.Store
currently.
Hermes parser is the preferred parser for Flow code going forward. We
need to upgrade to this parser to support new Flow syntax like function
`this` context type annotations or `ObjectType['prop']` syntax.
Unfortunately, there's quite a few upgrades here to make it work somehow
(dependencies between the changes)
- ~Upgrade `eslint` to `8.*`~ reverted this as the React eslint plugin
tests depend on the older version and there's a [yarn
bug](https://github.com/yarnpkg/yarn/issues/6285) that prevents
`devDependencies` and `peerDependencies` to different versions.
- Remove `eslint-config-fbjs` preset dependency and inline the rules,
imho this makes it a lot clearer what the rules are.
- Remove the turned off `jsx-a11y/*` rules and it's dependency instead
of inlining those from the `fbjs` config.
- Update parser and dependency from `babel-eslint` to `hermes-eslint`.
- `ft-flow/no-unused-expressions` rule replaces `no-unused-expressions`
which now allows standalone type asserts, e.g. `(foo: number);`
- Bunch of globals added to the eslint config
- Disabled `no-redeclare`, seems like the eslint upgrade started making
this more precise and warn against re-defined globals like
`__EXPERIMENTAL__` (in rollup scripts) or `fetch` (when importing fetch
from node-fetch).
- Minor lint fixes like duplicate keys in objects.
Assignment expressions to a member path are a special case because they're the
only place where a value isn't assigned to a (possibly temporary) variable,
which is our unit of memoization. #901 demonstrated how this can lead to values
that can't be independently memoized:
```javascript
const x = {a: a}
x.y = [b, c]; // array recomputed w `x`, even if only `a` changed
```
This PR ensures that assignment expressions where the LHS is a member path lower
the RHS to a Place. That means the above example is handled as if you wrote:
```javascript
const x = {a: a};
const tmp1 = [b, c];
x.y = tmp1;
```
And we independently memoize the temporary.
Completes a todo for the `if` condition of scopes without any inputs. In this
case since there are no inputs we can check for changes, we check if the first
_output_ cache slot is set to the sentinel.
For this to work we need to ensure that all scopes have at least one output,
which isn't currently the case. Dead code can produce output-less sentinels. So
this PR also adds a pass to find scopes w/o any outputs and convert them to
regular blocks. We could in theory also just delete them, but for now let's be
more conservative. This is something we'd want to highlight as a diagnostic in
an IDE, though existing dead code linters would almost certainly find this case
too.
Remove our existing compiler flags since they were only being used for
enabling/disabling passes to aid debugging and to simplify in preparation for
the upcoming work on diagnostics and bailouts. Additionally with the new
playground tabs disabling passes has become less necessary. In the future when
we have actual compiler flags (eg tweaking optimization levels) we can add this
back.
I opted to keep the existing `CompilerResult` return value instead of just
returning the optimized AST as we're still using `scopes` in our test fixtures.
Small reorganization to move Pipeline out of HIR since it's a compiler module.
It used to make sense before to be in HIR since the old architecture was the
still the primary, but no longer!
It's not safe to infer types of arguments and return values because Javascript
is so polymorphic. Instead just infer the type of the callee for non methods.
Interestingly, even this is not conservative enough for JavaScript because Proxy
can also be callable. But I think for our use cases we will treat Proxy and
Functions similarly (they're all just objects) so it's ok.
Thanks old architecture! We learned a lot about what does and doesn't work via
this POC, but it's time to move forward w the ~~new~~ current architecture.
When collecting the output of each scope I was checking to see whether each
operand was being used after the end of the _current_ scope. What we really want
to be checking is whether the operand is used after _the scope in which it's
defined_. Those are the same thing when there is no nesting, involved, so the
previous logic worked for most examples.
It isn't super easy to tell when if the operand's scope has ended, because we
don't always know what the "current" InstructionId is inside a ReactiveFunction.
And that in turn isn't quite so easy to change, because of some edge cases like
break statements that we synthesize. The solution here is to track the set of
active scopes, and if an operand is used and its scope is not active then voila,
it's scope must have completed and its an output.
Moves _some_ files from HIR into new top-level directories. To not make
@gsathya's life a pain I left the files he's touching alone, but I moved some
others. My intent is to have something like this:
* Babel/ - code for the Babel plugin, though ideally this actually gets split
into a separate package and the compiler itself is AST in, AST out w no Babel
dep.
* HIR/ - the core HIRFunction, HIR and related data types, plus the HIR
construction and printing, HIR visitors.
* Inference/ - the core inference passes that operate on the HIR, including type
inference, reference effects, alias analysis, mutable range analysis, etc. I'll
let @gsathya move these files when at a good stopping point.
* ReactiveScopes/ - inference relating to reactive scopes,
constructing/printing/codegenning ReactiveFunction
* SSA/ - enter/leave SSA and eliminate redundant phis
* Utils/ - every project needs a place to put stuff that doesn't fit into the
other categories, this is ours.
This leaves just index.ts at the top level, and overall feels pretty tidy. Not
too tedious to figure out where anything goes, hopefully.
It's pretty tedious to keep the playground in sync w `Pipeline` — we need some
abstraction so we can write the sequence of passes once and reuse it (while
inspecting intermediate states).
Depends on #25876
Resubmit #25711 again(previously reverted in #25812), and added the fix
for unwinding in selective hydration during a hydration on the sync
lane.
This PR includes the previously reverted #25695 and #25754, and the fix
for the regression test added in #25867.
Tested internally with a previous failed test, and it's passing now.
Co-authored-by: Andrew Clark <git@andrewclark.io>
This is mostly unused and there's just not enough benefit for now. We can re-add
this if folks start using this site on mobile. Removing now to simplify the
codebase.
Updates the ReactiveFunction-based codegen from the previous PR to emit
memoization code for each scope. This is currently naive and has some bugs, but
it gets the idea across. The core logic is straightforward at this point, all
the hard work is in earlier passes:
* Compute one change variable per scope dependency, eg `const c_0 = $[0] ===
maxItems`
* Generate one `let` binding for each scope output
* Generate an if block where the test is if any of the change variables are true
(`||` them together)
* Generate the consequent block with the original code block, plus statements to
save dependencies and outputs to their cache slots
* Generate the alternate block to populate the scope outputs from their cached
values
## Todos
A few things don't quite work yet:
* Codegen is designed to avoid emitting variables for temporary values, but
that's causing a few values to sort of disappear n the examples, or get emitted
twice. There are a variety of ways to achieve this but we'll need to ensure that
this category of values gets assigned to a variable and then reference the
variable. This is more involved.
* Scopes can end up with zero dependencies, in which case we should check that
the first output cache is initialized. This one is more straightforward.
* If there are early returns, we don't record that they occurred and replay them
in the `else` branch for each scope. We know the algorithm though so i'm okay
delaying that for now.
Currently codegen operates from HIR using a tree visitor, but for scope
construction we're converting the HIR (CFG) into a ReactiveFunction (AST-like).
Our original idea for codegen was that we would convert the ReactiveFunction
back to HIR, and then codegen from there. However, the ReactiveFunction is
already in tree form...which makes it very straightforward to generate code
from.
So this PR implements codegen from ReactiveFunction. The output is _identical_
thanks in large part to reusing as much logic from Codegen.ts as possible. The
next PR will add memoization logic.
While we're collecting scope dependencies, we have the exact right information
to record scope outputs. These are variables that need to be defined outside of
the scope and populated by recomputing (on change) or via the cached value (if
no change).
We originally had grand plans for using this Event concept for more but
now it's only meant to be used in combination with effects.
It's an Event in the FRP terms, that is triggered from an Effect.
Technically it can also be from another function that itself is
triggered from an existing side-effect but that's kind of an advanced
case.
The canonical case is an effect that triggers an event:
```js
const onHappened = useEffectEvent(() => ...);
useEffect(() => {
onHappened();
}, []);
```
I realized that properly propagating scope dependencies requires reusing the
same logic as dependency collection itself: a dependency of an inner scope
should only be propagated upward if the dependency was declared before the outer
scope, for example. So this PR reimplements dependency collection in the
propagation pass.
At the same time I made a few other improvements:
* Don't report dependencies that are "constant". This is a bit simplistic for
now, we can use a more advanced analysis later.
* Try to avoid creating duplicate dependencies.
This addresses the todo from the previous PR (flattening scopes in loops) since
now we don't need to compute deps until after that runs. As a follow-up i'll
remove the existing dependency collection.
Dependency collection has to visit the instruction id first before evaluating
the instruction, in order to completely any scopes that would end at that
instruction. Note the removed dependencies that don't appear within the scopes.
We can't independently memoize values created within a loop, so this pass
flattens scopes within loops. Right now this just flattens the scope away
without propagating any dependency (or output) information, follow-ups will
extend it to do that.
We don't need to create scopes for primitive values that are never reassigned.
The actual rules are more complex — we could choose to skip creating scopes for
values that don't allocate — but this simple heuristic is good for now.
The new LeaveSSA looks ahead to the phis of fallback blocks. However, HIR can
sometimes have multiple blocks with the same fallthrough (totally fine), so this
diff clears the phis of fallbacks as they are reached to avoid reprocessing
them. This caused a previously incorrect case to now fail, yay.
There are a bunch of ways we can go about converting from the input HIR into a
final form that has the preamble inserted and memoized blocks of code wrapped
with change detection and caching. This is just one way, it might not be the
ideal way. In any case, this pass converts HIRFunction -> ReactiveFunction. The
latter is a recursive (tree-shaped) data structure that attempts to represent
blocks each of composed of scopes or instructions, where scopes are themselves
composed of blocks etc. The idea is a) this makes it easy to visualize the
structure and check that the scopes and their dependencies are correct and b)
this is a really nice form for adding the memoization code. We can convert from
a ReactiveFunction back to an HIRFunction, wrapping each scope in the
appropriate if checks and caching.
## Example
Consider the following example, which has 2 main scopes: an outer one for `x`
and an inner one in the consequent for `y`:
```javascript
function foo(a, b, c) {
const x = [];
if (a) {
const y = [];
y.push(b);
x.push(<div>{y}</div>);
} else {
x.push(c);
}
return x;
}
```
## Output
The new builder constructs a ReactiveFunction for this example along the lines
of the following (note that inputs are always empty bc we don't collect those
yet):
```
{
scope @0 [1:11] inputs=[] {
[1] Const mutate x$11_@0[1:11] = Array []
[2] if (read a$8) {
scope @1 [3:5] inputs=[] {
[3] Const mutate y$12_@1[3:5] = Array []
[4] Call mutate y$12_@1.push(read b$9)
}
scope @2 [5:6] inputs=[] {
[5] Const mutate $13_@2 = "div"
}
scope @3 [6:7] inputs=[] {
[6] Const mutate $14_@3 = JSX <read $13_@2>{freeze y$12_@1}</read $13_@2>
}
[7] Call mutate x$11_@0.push(read $14_@3)
} else {
[9] Call mutate x$11_@0.push(read c$10)
}
}
[10] return x$11;
}
```
This shows the hierarchy: there's an outer scope, `@0` to compute `x` (the first
scope), then within the if consequent there's another scope, `@1`, to compute
`y`. We have some technically extraneous scopes to compute the JSX element; that
can be cleaned up with a bit more refinement.
With this structure — and the inputs and outputs of each scope filled in — we
can convert to code in a straightforward manner. Each scope turns into a block
along the lines of the following:
(note here we use strings to index the cache, in reality these would be ints)
```javascript
// one change variable pet input:
let c_a = a !== $['a'];
...
// one variable for each output:
let x;
...
// if (changed) { recompute } else { use-cache }
if (c_a || ... ) {
x = ...;
// one assignment per output
$['x'] = x;
// update cache per input
$['a'] = a;
...
} else {
// one assignment per output
x = $['x'];
...
}
```
TreeVisitor didn't distinguish between the type of a block and the type of an
item that can occur within a block - this was fine for Codegen which can use
`t.Statement` for both of those values. However, the upcoming scope construction
needs to distinguish instructions in a block from a block itself, so this PR
adds a new type parameter.
Per the title, this PR adds support for assignment expressions in update
clauses. This was mostly fixed by the previous diff to improve value block
handling, and there's only a bit more to do here to allow a "value block" that
doesn't produce a value (we need a better name).
This is a pre-req to construct reactive scopes in #857. "Value blocks" such as
`for` init/test/update and `while` test need to be consistently wrapped in
enter/leave calls so that we can extend the range of values properly. We also
need to handle `for` init blocks a bit differently, since they allow variable
declarations but not other types of statements.
This PR ensures that we use consistent methods for handling value blocks (`for`
test/update and `while` test) and treats `for` init as a new type with its own
enter/append/leave visitor functions.
`Offscreen.attach` is imperative API to signal to Offscreen that its
updates should be high priority and effects should be mounted. Coupled
with `Offscreen.detach` it gives ability to manually control Offscreen.
Unlike with mode `visible` and `hidden`, it is developers job to make
sure contents of Offscreen are not visible to users.
`Offscreen.attach` only works if mode is `manual`.
Example uses:
```jsx
let offscreenRef = useRef(null);
<Offscreen mode={'manual'} ref={offscreenRef)}>
<Child />
</Offscreen>
// ------
// Offscreen is attached by default.
// For example user scrolls away and Offscreen subtree is not visible anymore.
offscreenRef.current.detach();
// User scrolls back and Offscreen subtree is visible again.
offscreenRef.current.attach();
```
Co-authored-by: Andrew Clark <git@andrewclark.io>
Previously, this step just set the mutable range of any alias set including any
mutation to the end of the last mutable range of any of the containing
identifiers.
This change makes it so that the ends are only updated of the ranges that end
before the last mutation.
Fixes#852
Fixes https://github.com/facebook/react-forget/pull/858#discussion_r1044626137.
The case is
```javascript
function foo() {
let x$1 = 1;
let y = 2;
if (y === 2) {
x$2 = 3;
}
x$3 = phi(x$1, x$2)
if (y === 3) {
x4 = 5;
}
x$5 = phi(x$3, x$4);
y = x$5;
}
```
What happens here is that there are two _sequential_ phis for `x`. Previously
when we encountered the second phi we would find that there is no `let`
declaration for the phi or any of its operands, and create a new one before the
second `if`. That's incorrect, these should all merge into a single `x`
declaration. We now look up the phi operands to see if they are part of a
previous phi, and merge them correctly.
Reorders LeaveSSA so that it runs before we begin evaluating reactive scopes.
Note that reactive scopes must span the full construction of each variable — for
variables with a phi, this must span the declaration and all assignments of the
phi operands. And that's exactly what the new LeaveSSA does! LeaveSSA removes
phi nodes and ensure that all versions of a variable which flow into a phi have
been assigned a single canonical identifier (with an appropriate mutable range).
This PR includes this and some related changes:
* Reorders the pass
* Changes hir-test to print the final HIR, eg just prior to codegen
* Teaches LeaveSSA to update the mutable range of the canonical identifiers it
assigns, based on the min/max of the variables assigned.
Add support for `setNativeProps` in Fabric to make migration to the new
architecture easier. The React Native part of this has already landed in
the core and iOS in
1d3fa40c59.
It is still recommended to move away from `setNativeProps` because the
API will not work with future features.
A wise Joe once said, "We only care about observed aliasing".
Instead of performing aliasing for fields and non fields together, split the
analysis to happen over separate passes. Similarly split inferring mutable
lifetimes pass for fields and non fields.
Now, we can identify the aliases of fields that are *not* mutated and only alias
the ones that do mutate.
The algorithm is roughly as follows:
1. Build the set of aliases for non fields
2. Infer mutable ranges for all instructions except aliasing fields
3. Infer mutable ranges for all aliased instructions based on the alias set
calculated in step 1 (this doesn't include aliasing fields)
4. Extend the set of aliases (calculated in step 1) to include fields only if
the field or the receiver is mutated after the aliasing, ie, if _mutability is
observed_.
5. Run infer mutable ranges again for all instructions including the fields that
were aliased in the previous step.
6. Run infer mutable ranges for all aliased instructions including the fields
that were aliased.
## Problem
The previous version of LeaveSSA used a very simple approach in which
identifiers stored their pre-ssa id, and LeaveSSA restored this id back. The
upside of this approach is that it's very simple and trivially correct (assuming
no reordering of code). The downside is that after running LeaveSSA we lose all
information about which versions of variable declarations are distinct, and
which might merge together in a phi. That information is really useful for scope
analysis! Consider this input (variables are numbered as they would be in SSA
form):
```javascript
function foo(a, b, c) {
let x$1 = null;
if (a) {
x$2 = b;
} else {
x$3 = c;
}
x$4 = phi(x$2, x$3);
return x$4;
```
The current LeaveSSA assigns all 4 variables back to `x$1`, with a single let
declaration at `let x$1 = null`. However, from a reactive scopes perspective,
there are really just 2 versions of x: the initial x$1 (defined and never used)
and then x$2, x$3, and x$4, which have to be merged into a single scope because
they are part of a phi. In other words, we can't independently compute x$2, x$3,
or x$4 - if any of their inputs changes, we have to redo all the computation.
However, the existing structure makes it difficult to figure out the correct
starting point for this scope — there is no initial `let` declaration that we
can refer to.
Instead, we can represent the program as follows after LeaveSSA, and then use
this form for scope analysis:
```javascript
function foo(a, b, c) {
const x$1 = null; // NOTE: rewritten to const
let x$2; // synthesized declaration to allow later reassignment
if (a) {
x$2 = b;
} else {
x$2 = c;
}
return x$2;
```
Note that there are only 2 versions of x, and we have synthesized a variable
declaration for x$2 at the appropriate scope. Our scope analysis can then
determine that the range of x$2 is from the declaration to the end of the if.
## Approach
This pass does two main rewrites:
* For variables that do *not* appear as a phi id or operand, it rewrites the
declaration to be `const`. You can see this above for x$1.
* For variables that *do* appear as a phi or operand, it synthesizes a new `let`
binding at the appropriate scope (ie, in the appropriate block), and updates all
other operands from the phi to use the same id for the variable. You can see
this above for x$2, x$3, and x$4.
Note that the let binding is generated at the narrowest scope possible. In this
example, we generate distinct let bindings for the other if and else branches:
```javascript
function foo(a, b, c) {
let x = null;
if (a) {
// we generate a `let x$2` here
if (b) {
x = 0; // becomes x$2
} else {
x = 1; // becomes x$2
}
x // becomes x$2
} else {
// we generate a `let x$3` here
if (c) {
x = 2; // becomes x$3
} else {
x = 3; // becomes x$3
}
x; // becomes x$3
}
}
```
Because the different x values from the outer if/else can never join in a phi,
we can treat them as independent variables and (re)compute them independently.
The algorithm works by iterating in reverse-postorder, and looking ahead at
fallthrough blocks to find phi nodes that may need a let declaration (see above
example of where these are generated). It also tracks variables which _don't_
participate in a phi so that it can rewrite their declarations to `const`.
## TODO
This PR does *not* yet work for cases where there is unconditional assignment
within a `while` test condition. That would technically create a distinct
version of the variable that shadows the value for the loop, and you can't have
variable declarations in a while test condition.
That case already doesn't work, though, so i'm punting on it for now until we
figure out a bit more around
"value" blocks. We have some good options, like desugaring to a `for(;;)` and
manually implementing the while semantics in that case.
Some tests fail when float is off but when singletons are on. This PR
makes some adjustments
1. 2 singleton tests assert float semantics so will fail.
2. the float dispatcher was being set on the server even when float was
off. while the float calls didn't do anything warnings were still
generated. Instead we provide an empty object for the dispatcher if
float is off. Longer term the dispatcher should move to formatconfig and
just reference the float methods if the flag is on
3. some external fizz runtime tests did not gate against float but
should have
children of title can either behave like children or like an attribute.
We're kind of treating it more like an attribute now so we should
support toString/valueOf like we do on attributes.
## Summary
We see recent bug reports like #25755 and #25769 for devtools. Whenever
a component uses hook `useEffect`, it triggers an error.
This was introduced in #25663 when we try to keep the `ReactFiberFlags`
numbers consistent with reconciler, in order to fix an issue with server
components.
However, the values of `ReactFiberFlags` in reconciler were actually
changed a while ago in
b4204ede66
We made this mistake because, although it's not mentioned in the
comment, `DidCapture` and `Hydrating` are actually used by DevTools
This caused
- the latest (not stable) react version is broken on devtools before
4.27.0 (but only in uncommon cases such server components)
- all earlier react versions are broken on latest devtools (4.27.0)
To keep most versions work, we need to revert the commit that changed
the `ReactFiberFlags` values
## How did you test this change?
1. add a `useEffect` in a component in the TodoList of the shell,
trigger the error in devtools
2. after change, the error is gone
The changes here are pretty significant and there's a bunch more left:
- support for with any of `<init>`, `<test>` or `<update>` empty. - support for
with `<init>` as `Expression` instead of VariableDeclaration` node - support
assignment expressions in `<update>`, this seems like it might require further
new abstractions to allow something like a block to codegen into a single
expression.
Bumps [qs](https://github.com/ljharb/qs) from 6.4.0 to 6.4.1.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a
href="https://github.com/ljharb/qs/blob/main/CHANGELOG.md">qs's
changelog</a>.</em></p>
<blockquote>
<h2><strong>6.4.1</strong></h2>
<ul>
<li>[Fix] <code>parse</code>: ignore <code>__proto__</code> keys (<a
href="https://github-redirect.dependabot.com/ljharb/qs/issues/428">#428</a>)</li>
<li>[Fix] fix for an impossible situation: when the formatter is called
with a non-string value</li>
<li>[Fix] use <code>safer-buffer</code> instead of <code>Buffer</code>
constructor</li>
<li>[Fix] <code>utils.merge</code>: avoid a crash with a null target and
an array source</li>
<li>[Fix]<code> </code>utils.merge`: avoid a crash with a null target
and a truthy non-array source</li>
<li>[Fix] <code>stringify</code>: fix a crash with
<code>strictNullHandling</code> and a custom
<code>filter</code>/<code>serializeDate</code> (<a
href="https://github-redirect.dependabot.com/ljharb/qs/issues/279">#279</a>)</li>
<li>[Fix] <code>utils</code>: <code>merge</code>: fix crash when
<code>source</code> is a truthy primitive & no options are
provided</li>
<li>[Fix] when <code>parseArrays</code> is false, properly handle keys
ending in <code>[]</code></li>
<li>[Robustness] <code>stringify</code>: avoid relying on a global
<code>undefined</code> (<a
href="https://github-redirect.dependabot.com/ljharb/qs/issues/427">#427</a>)</li>
<li>[Refactor] use cached <code>Array.isArray</code></li>
<li>[Refactor] <code>stringify</code>: Avoid arr = arr.concat(...), push
to the existing instance (<a
href="https://github-redirect.dependabot.com/ljharb/qs/issues/269">#269</a>)</li>
<li>[readme] remove travis badge; add github actions/codecov badges;
update URLs</li>
<li>[Docs] Clarify the need for "arrayLimit" option</li>
<li>[meta] fix README.md (<a
href="https://github-redirect.dependabot.com/ljharb/qs/issues/399">#399</a>)</li>
<li>[meta] Clean up license text so it’s properly detected as
BSD-3-Clause</li>
<li>[meta] add FUNDING.yml</li>
<li>[actions] backport actions from main</li>
<li>[Tests] remove nonexistent tape option</li>
<li>[Dev Deps] backport from main</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a
href="486aa46547"><code>486aa46</code></a>
v6.4.1</li>
<li><a
href="727ef5d346"><code>727ef5d</code></a>
[Fix] <code>parse</code>: ignore <code>__proto__</code> keys (<a
href="https://github-redirect.dependabot.com/ljharb/qs/issues/428">#428</a>)</li>
<li><a
href="cd1874eb17"><code>cd1874e</code></a>
[Robustness] <code>stringify</code>: avoid relying on a global
<code>undefined</code> (<a
href="https://github-redirect.dependabot.com/ljharb/qs/issues/427">#427</a>)</li>
<li><a
href="45e987c603"><code>45e987c</code></a>
[readme] remove travis badge; add github actions/codecov badges; update
URLs</li>
<li><a
href="90a3bced51"><code>90a3bce</code></a>
[meta] fix README.md (<a
href="https://github-redirect.dependabot.com/ljharb/qs/issues/399">#399</a>)</li>
<li><a
href="9566d25019"><code>9566d25</code></a>
[Fix] fix for an impossible situation: when the formatter is called with
a no...</li>
<li><a
href="74227ef022"><code>74227ef</code></a>
Clean up license text so it’s properly detected as BSD-3-Clause</li>
<li><a
href="35dfb227e2"><code>35dfb22</code></a>
[actions] backport actions from main</li>
<li><a
href="7d4670fca6"><code>7d4670f</code></a>
[Dev Deps] backport from main</li>
<li><a
href="0485440902"><code>0485440</code></a>
[Fix] use <code>safer-buffer</code> instead of <code>Buffer</code>
constructor</li>
<li>Additional commits viewable in <a
href="https://github.com/ljharb/qs/compare/v6.4.0...v6.4.1">compare
view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't
alter it yourself. You can also trigger a rebase manually by commenting
`@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits
that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after
your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge
and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating
it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop
Dependabot creating any more for this major version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop
Dependabot creating any more for this minor version (unless you reopen
the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop
Dependabot creating any more for this dependency (unless you reopen the
PR or upgrade to it yourself)
- `@dependabot use these labels` will set the current labels as the
default for future PRs for this repo and language
- `@dependabot use these reviewers` will set the current reviewers as
the default for future PRs for this repo and language
- `@dependabot use these assignees` will set the current assignees as
the default for future PRs for this repo and language
- `@dependabot use this milestone` will set the current milestone as the
default for future PRs for this repo and language
You can disable automated security fix PRs for this repo from the
[Security Alerts
page](https://github.com/facebook/react/network/alerts).
</details>
Signed-off-by: dependabot[bot] <support@github.com>
Co-authored-by: dependabot[bot] <49699333+dependabot[bot]@users.noreply.github.com>
The instructions of a while test node cannot just be pushed to the previous
block. This creates a new block for the test node and then during code gen
converts the statements pushed to the "value block" into expressions.
This adds a field sensitive, flow-insensitive, context-insensitive alias
analysis for lvalue aggregates.
In the future, InferMutableLifetimes can refine it's analysis using these field
sensitive alias sets.
Currently AbstractState.alias performs three operations: - Reading a value -
Storing the value - Updating aliasing (in the DisjointSet)
This commit makes AbstractState.alias only responsible for updating the alias
information. The rest of the operations are split into separate functions.
We're reverting the stack of changes that this code belongs to in order
to unblock the sync to Meta's internal codebase. We will attempt to
re-land once the sync is unblocked.
I have not yet verified that this fixes the error that were reported
internally. I will do that before landing.
This isn't the right way to do this, but internally we have some
restrictions so we need to add an indirection. Let's land this now so we
can catch up our sync and then fix forward from there.
Co-authored-by: Jan Kassens <jkassens@meta.com>
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn debug-test --watch TestName`, open
`chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
This is discovered by @acdlite.
In dev we replay errors so debugger will treat them as uncaught errors,
but we need to ignore internal exceptions.
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
manually console.log in some tests, and noticed replay didn't happen.
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
The error message to warn user about state update coming from inside an
update function does not contain name of the offending component. Other
warnings StrictMode has, always have offending component mentioned in
top level error message.
Previous error message:
```
An update (setState, replaceState, or forceUpdate) was scheduled
from inside an update function. Update functions should be pure
with zero side-effects. Consider using componentDidUpdate or a
callback.
```
New error message:
```
An update (setState, replaceState, or forceUpdate) was scheduled
from inside an update function. Update functions should be pure
with zero side-effects. Consider using componentDidUpdate or a
callback.
Please update the following component: Foo
```
Calling any function on `nativeFabricUIManager`, for example
`nativeFabricUIManager.measure`, results in a round trip to the host
platform through jsi layer. It is the same for repeated calls to same
host function. This is unnecessary overload which can be avoided by
retaining host function in a variable.
We've heard from multiple contributors that the Reconciler forking
mechanism was confusing and/or annoying to deal with. Since it's
currently unused and there's no immediate plans to start using it again,
this removes the forking.
Fully removing the fork is split into 2 steps to preserve file history:
**#25774 previous PR that did the bulk of the work:**
- remove `enableNewReconciler` feature flag.
- remove `unstable_isNewReconciler` export
- remove eslint rules for cross fork imports
- remove `*.new.js` files and update imports
- merge non-suffixed files into `*.old` files where both exist
(sometimes types were defined there)
**This PR**
- rename `*.old` files
We've heard from multiple contributors that the Reconciler forking
mechanism was confusing and/or annoying to deal with. Since it's
currently unused and there's no immediate plans to start using it again,
this removes the forking.
Fully removing the fork is split into 2 steps to preserve file history:
**This PR**
- remove `enableNewReconciler` feature flag.
- remove `unstable_isNewReconciler` export
- remove eslint rules for cross fork imports
- remove `*.new.js` files and update imports
- merge non-suffixed files into `*.old` files where both exist
(sometimes types were defined there)
**#25775**
- rename `*.old` files
Log more info on the status of the process_artifacts_combined job to
help with debugging, and exit with exitcode 1 if anything goes wrong
Test plan: Ran the workflow
[successfully](https://github.com/facebook/react/actions/runs/3595185062)
Moves the existing alias set building logic from inferMutableLifetimes to a
separate pass.
Additionally maintain abstract state to refine aliasing to not include
primitives.
HIRTreeVisitor previously passed a string label (for certain blocks). This
changes to pass the raw BlockId, and have codegen convert that to a string. I'm
not sure if we'll need this but it would be helpful for eg visiting the IR and
emitting a new IR, while mapping block ids forward. Even if we don't need that
it makes sense for Codegen to decide how to convert a block id into a label
(which has to obey the rules of an identifier, not the visitor's concern).
### Changes made:
- Running with enableFizzExternalRuntime (feature flag) and
unstable_externalRuntimeSrc (param) will generate html nodes with data
attributes that encode Fizz instructions.
```
<div
hidden data-rxi=""
data-bid="param0"
data-dgst="param1"
></div>
```
- Added an external runtime browser script
`ReactDOMServerExternalRuntime`, which processes and removes these nodes
- This runtime should be passed as to renderInto[...] via
`unstable_externalRuntimeSrc`
- Since this runtime is render blocking (for all streamed suspense
boundaries and segments), we want this to reach the client as early as
possible. By default, Fizz will send this script at the end of the shell
when it detects dynamic content (e.g. suspenseful pending tasks), but it
can be sent even earlier by calling `preinit(...)` inside a component.
- The current implementation relies on Float to dedupe sending
`unstable_externalRuntimeSrc`, so `enableFizzExternalRuntime` is only
valid when `enableFloat` is also set.
They're fairly related, but I figured it's worth keeping more examples.
- For the `while` example we need to codegen into a single expression. - For the
expression with contained assignment we need to either keep the SSA ids around
or re-create a similar expression during codegen.
This builds upon @josephsavona's prior PR #817 to add support for inferring
reactive scope dependencies for all instructions and terminals.
Still TODO (probably in follow up PRs):
- [ ] fix duplicate/different identity scope issue (see this [test
fixture](5f3b260aaa/forget/src/__tests__/fixtures/hir/overlapping-scopes-while.expect.md))
- [ ] also collect outputs of each scope - [ ] add new tree visitor that only
visits, consider renaming the current `visitTree` to `mapTree` or similar
Co-authored-by: Joe Savona <joesavonafb.com>
Add option for ref function to return a clean up function.
```jsx
<div ref={(_ref) => {
// Use `_ref`
return () => {
// Clean up _ref
};
}} />
```
If clean up function is not provided. Ref function is called with null
like it has been before.
```jsx
<div ref={(_ref) => {
if (_ref) {
// Use _ref
} else {
// Clean up _ref
}
}} />
```
The `automaticLayout` config option for Monaco causes it to remeasure itself,
and the parent container's height being longer than the screen causes it to
constantly grow infinitely. You can observe this bug by going to the playground,
expanding any tab, and watch the scrollbar grow as the editor quickly grows to
ridiculous heights and your laptop starts glowing red hot and̶͙̕ H̴͉͘e comes
t̵͙́o ̴̜̿de̷̼̚s̷̻̍ec̶̮͒rate all knowled̵̥̆ge
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn debug-test --watch TestName`, open
`chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Jest caching wasn't working correctly for
`transform-react-version-pragma`. One condition for including
`transform-react-version-pragma` is that `process.env.REACT_VERSION` is
set, but it wasn't included in the cache key computation. Thus local
test runs would only run without `transform-react-version-pragma`, if
jest runs weren't using the `-reactVersion` flag and then added it.
Inlined the `scripts/jest/devtools/preprocessor.js` file, because it
makes it more obvious that `process.env.REACT_VERSION` is used in
`scripts/jest/preprocessor.js`
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
Repro step:
- Clear jest cache
- node ./scripts/jest/jest-cli.js --build --project devtools
--release-channel=experimental --reactVersion 18.0
- node ./scripts/jest/jest-cli.js --build --project devtools
--release-channel=experimental
Before:
Jest cached the first run with `REACT_VERSION` set, so in the second run
`transform-react-version-pragma` is still there and runs only the
regression tests on old react versions.
After:
- The second run runs all tests and ignore `// @reactVersion` as
expected.
The argument was unused and a confusing boolean argument that's easy to mix up.
Suggesting to remove it until we see a need for it at which point we might want
to introduce an enum to make the argument more obvious.
In `<StrictMode>` in dev hooks are run twice on each render.
For `useId` the re-render pass uses the `updateId` implementation rather
than `mountId`. In the update path we don't increment the local id
counter. This causes the render to look like no id was used which
changes the tree context and leads to a different set of IDs being
generated for subsequent calls to `useId` in the subtree.
This was discovered here: https://github.com/vercel/next.js/issues/43033
It was causing a hydration error because the ID generation no longer
matched between server and client. When strict mode is off this does not
happen because the hooks are only run once during hydration and it
properly sees that the component did generate an ID.
The fix is to not reset the localIdCounter in `renderWithHooksAgain`. It
gets reset anyway once the `renderWithHooks` is complete and since we do
not re-mount the ID in the `...Again` pass we should retain the state
from the initial pass.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn debug-test --watch TestName`, open
`chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Submit https://github.com/facebook/react/pull/25698 again after fixing
the devtools regression tests in CI.
The PR changed lanes representation and some snapshot tests of devtools
captures lanes. In devtools tests for older versions, the updated lanes
representation no longer matched. The fix is to disable regression tests
for those tests.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
```
./scripts/circleci/download_devtools_regression_build.js 18.0 --replaceBuild
node ./scripts/jest/jest-cli.js --build --project devtools --release-channel=experimental --reactVersion 18.0
```
Unrelated to this PR. There was some issue with jest caching when I
locally ran that command. it didn't seem to include the @reactVersion
transform, but if I manually modified `scripts/jest/preprocessor.js` or
ran ` yarn test --clearCache`, the jest test runs correctly.
This is a follow-up to merging ranges. I realized that we need to mark terminal
ids as visited _before_ processing the branches of that terminal (whereas before
we were marking terminal ids only _after_ processing the branches). That exposed
another bug where interleaving could fail to be detected (with an error,
thankfully) if one of the branches had completed already.
Our small test suite is already really good!
This demonstrates a situation we don't handle well today. The basic structure is
that you have some variable defined at the top level, then some control flow
like if/switch where _all_ branches reassign the variable, then some code after
that references the resulting phi node:
```javascript
let x1;
// ... mutate/read x1
if (cond) {
x2 = {};
} else {
x3 = {};
}
x4 = phi(x2, x3);
```
We currently group x3, x3, and x4 into a scope together, but note that...there's
no `let` declaration for any of those! This means that it looks like the scope
for x2 and x3 start in the consequent/alternate, but the true scope spans from
before-after the if. I'm inclined to say that LeaveSSA should run _before_ scope
analysis, and produce something like the following in this case:
```javascript
let x1;
// ...mutate/read x1
let x2; // new variable declaration for the new version of x
if (cond) {
x2 = {};
} else {
x2 = {};
}
x2;
```
This then allows us to construct a correct range for x2, which starts in the
other block.
- [x] Merge scopes that are interleaved
- [x] Merge scopes if they both cross control-flow boundaries together
- [x] Don't merge scopes that strictly shadow
Still WIP because I want to double-check and see if i can find a simpler
algorithm for this. But it works.
This is a random driveby improvement. I realized that we can eliminate `return`
statements if a) they have no value and b) they are in the top-level block.
Functions implicitly return at that point — there can't be any succeeding
instructions anyway — so we can save bytes in the output.
Visits the HIR as a tree and updates mutable ranges to ensure their range end is
aligned with the block in which the scope is declared:
```javascript
function foo(cond, a) {
⌵ original scope
⌵ expanded scope
const x = []; ⌝ ⌝
if (cond) { ⎮ ⎮
... ⎮ ⎮
x.push(a); ⌟ ⎮
... ⎮
} ⎮
... ⌟
}
```
The implementation tracks the block in which each scope "starts" (first
instruction with an operand in that scope), and then finds the first instruction
at that block (or a parent) which is after the scope's end.
Refactors `Identifier.scope` to be a `ReactiveScope` object with an id and
range. This gives us a place to later add a list of dependencies for the scope.
## Edit
Went for another approach after talking with @gnoff. The approach is
now:
- add a dev-only error when a precomputed chunk is too big to be written
- suggest to copy it before passing it to `writeChunk`
This PR also includes porting the React Float tests to use the browser
build of Fizz so that we can test it out on that environment (which is
the one used by next).
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn debug-test --watch TestName`, open
`chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
Someone reported [a bug](https://github.com/vercel/next.js/issues/42466)
in Next.js that pointed to an issue with Node 18 in the streaming
renderer when using importing a CSS module where it only returned a
malformed bootstraping script only after loading the page once.
After investigating a bit, here's what I found:
- when using a CSS module in Next, we go into this code path, which
writes the aforementioned bootstrapping script
5f7ef8c4cb/packages/react-dom-bindings/src/server/ReactDOMServerFormatConfig.js (L2443-L2447)
- the reason for the malformed script is that
`completeBoundaryWithStylesScript1FullBoth` is emptied after the call to
`writeChunk`
- it gets emptied in `writeChunk` because we stream the chunk directly
without copying it in this codepath
a438590144/packages/react-server/src/ReactServerStreamConfigBrowser.js (L63)
- the reason why it only happens from Node 18 is because the Webstreams
APIs are available natively from that version and in their
implementation, [`enqueue` transfers the array buffer
ownership](9454ba6138/lib/internal/webstreams/readablestream.js (L2641)),
thus making it unavailable/empty for subsequent calls. In older Node
versions, we don't encounter the bug because we are using a polyfill in
Next.js, [which does not implement properly the array buffer transfer
behaviour](d354a7457c/src/lib/abstract-ops/ecmascript.ts (L16)).
I think the proper fix for this is to clone the array buffer before
enqueuing it. (we do this in the other code paths in the function later
on, see ```((currentView: any): Uint8Array).set(bytesToWrite,
writtenBytes);```
## How did you test this change?
Manually tested by applying the change in the compiled Next.js version.
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
Co-authored-by: Sebastian Markbage <sebastian@calyptus.eu>
Should hopefully be final tweaks! Sorry about all the noise.
Test plan: temporarily ran the workflow on this branch, verified output
in the builds/facebook-www branch is correct:
bfc0eb6cd4
- Add a `loc` to the `while` terminal node.
- Move location data for assignments 1 level higher as that seems to work better
in the generated code (not tested with actual debugger yet though, we'll
probably want to look at this more closely.
This PR adds a new GitHub action to commit build artifacts for Facebook
into a new protected branch. This will later be used to setup an
automatic sync to www.
The hacky spinloop is meant to be a temporary implementation until we
can support running a script internally on top of the synced diff
(coming soon). A GitHub token is otherwise required if we want to setup
a pub/sub between cirleci and github but it's not straightforward to
provision one for our org. So this workaround should do for now since we
won't keep it around for too long.
Example of it running and creating a commit on the `builds/facebook-www`
branch:
https://github.com/facebook/react/actions/runs/3516958576/jobs/5894251359
Refactors Codegen to extract the core "visit IR as a tree" logic separately from
the code to emit JS:
* `HIRTreeVisitor` is a new helper that visits the HIR as a tree. You call
`visitTree(ir, yourVisitor)` and it drives visiting of the IR, tracking blocks
and scopes and calling methods as appropriate.
* `Codegen` is now implemented as a Visitor implementation. For example
`enterBlock()` creates an empty `Array<t.Statement>`, `leaveBlock()` wraps that
in a `t.BlockStatement`, etc.
* `printHIRTree()` is a new IR printer (implemented as a visitor) that prints
the HIR in tree form, so it retains the original shape of the code but with each
block replaced with its IR equivalent.
The new pretty printed scopes "syntax" breaks mermaid labels because the `@`
character seems to be reserved. This wraps them all as a string so they work
again.
Expands InferReactiveScopeVariables to update the mutableRange of all
identifiers to be the range of its scope. The result is that all identifiers in
a given scope will have the same range, whose start is the minimum of the
identifiers range starts, and end is the maximum.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn debug-test --watch TestName`, open
`chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
<!--
Explain the **motivation** for making this change. What existing problem
does the pull request solve?
-->
For more context: https://github.com/facebook/react/pull/25692
Based on https://github.com/facebook/react/pull/25695. This PR adds the
`SyncHydrationLane` so we rewind on sync updates during selective
hydration. Also added tests for ContinuouseHydration and
DefaultHydration lanes.
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
yarn test
Now that hook state is preserved while the work loop is suspended, we
don't need to track the thenable state in the work loop. We can track
it alongside the rest of the hook state.
This is a nice simplification and also aligns better with how it works
in Fizz and Flight.
The promises will still be cleared when the component finishes rendering
(either complete or unwind). In the future, we could stash the promises
on the fiber and reuse them during an update. However, this would only
work for `use` calls that occur before an prop/state/context is
processed, because `use` calls can only be assumed to execute in the
same order if no other props/state/context have changed. So it might not
be worth doing until we have finer grained memoization.
Now that hook state is preserved while the work loop is suspended, we
don't need to track the thenable state in the work loop. We can track
it alongside the rest of the hook state.
Before deleting the thenable state variable from the work loop, I need
to remove the other places where it's referenced.
One of them is `isThenableStateResolved`. This grabs the last thenable
from the array and checks if it has resolved.
This was a pointless indirection anyway. The thenable is already stored
as `workInProgressThrownValue`. So we can check that directly.
When a component suspends, under some conditions, we can wait for the
data to resolve and replay the component without unwinding the stack or
showing a fallback in the interim. When we do this, we reuse the
promises that were unwrapped during the previous attempts, so that if
they aren't memoized, the result can still be used.
We should do the same for all hooks. That way, if you _do_ memoize an
async function call with useMemo, it won't be called again during the
replay. This effectively gives you a local version of the functionality
provided by `cache`, using the normal memoization patterns that have
long existed in React.
Currently, if you call setState in render, you must render the exact
same hooks as during the first render pass.
I'm about to add a behavior where if something suspends, we can reuse
the hooks from the previous attempt. That means during initial render,
if something suspends, we should be able to reuse the hooks that were
already created and continue adding more after that. This will error
in the current implementation because of the expectation that every
render produces the same list of hooks.
In this commit, I've changed the logic to allow more hooks to be added
when replaying. But only during a mount — if there's already a current
fiber, then the logic is unchanged, because we shouldn't add any
additional hooks that aren't in the current fiber's list. Mounts are
special because there's no current fiber to compare to.
I haven't change any other behavior yet. The reason I've put this into
its own step is there are a couple tests that intentionally break the
Hook rule, to assert that React errors in these cases, and those happen
to be coupled to the behavior. This is undefined behavior that is always
accompanied by a warning and/or error. So the change should be safe.
When replaying a suspended function components, we want to reuse the
hooks that were computed during the original render.
Currently we reset the state of the hooks right after the component
suspends (or throws an error). This is too early because it doesn't
give us an opportunity to wait for the promise to resolve.
This refactors the work loop to reset the hooks right before unwinding
instead of right after throwing. It doesn't include any other changes
yet, so there should be no observable behavioral change.
Before suspending, check if there are other pending updates that might
possibly unblock the suspended component. If so, interrupt the current
render and switch to working on that.
This logic was already implemented for the old "throw a Promise"
Suspense but has to be replicated for `use` because it suspends the
work loop much earlier.
I'm getting a little anxious about the divergence between the two
Suspense patterns. I'm going to look into enabling the new behavior for
the old pattern so that we can unify the implementations.
When an update flows into a dehydrated boundary, React cannot apply the
update until the boundary has finished hydrating. The way this currently
works is by scheduling a slightly higher priority task on the boundary,
using a special lane that's reserved only for this purpose. Because the
task is slightly higher priority, on the next turn of the work loop, the
Scheduler will force the work loop to yield (i.e. shouldYield starts
returning `true` because there's a higher priority task).
The downside of this approach is that it only works when time slicing is
enabled. It doesn't work for synchronous updates, because the
synchronous work loop does not consult the Scheduler on each iteration.
We plan to add support for selective hydration during synchronous
updates, too, so we need to model this some other way.
I've added a special internal exception that can be thrown to force the
work loop to interrupt the work-in-progress tree. Because it's thrown
from a React-only execution stack, throwing isn't strictly necessary —
we could instead modify some internal work loop state. But using an
exception means we don't need to check for this case on every iteration
of the work loop. So doing it this way moves the check out of the fast
path.
The ideal implementation wouldn't need to unwind the stack at all — we
should be able to hydrate the subtree and then apply the update all
within a single render phase. This is how we intend to implement it in
the future, but this requires a refactor to how we handle "stack"
variables, which are currently pushed to a per-render array. We need to
make this stack resumable, like how context works in Flight and Fizz.
This completes the implementation of InferReactiveScopeVariables, adding support
for phi nodes. Example:
```javascript
let x$0 = null;
mutate(x$0);
if (cond) {
x$1 = a;
mutate(x$1)
} else {
x$2 = b;
}
x$3 = phi(x$1, x$2);
mutate(x$3);
```
We now add x$1, x$2, and x$3 to the same reactive scope. This reflects the fact
that x$3 cannot be computed without also computing both x$1 and x$2. Note that
x$3 can never be x$0, so x$0 is _not_ added to the same scope. This allows us to
take advantage of SSA form to note that _some_ instances of an identifier really
are distinct.
This improves the error message a bit and ensures that we recommend
putting the key first, not last, which ensures that the faster
`jsx-runtime` is used.
This only affects the modern "automatic" JSX transform.
There's no option to output the results of the test262 harness in silent mode so
every pass and failure outputs multiple lines to stdout. Since there are many
thousands of tests this results in unusable log files that are over 200k lines
long. This PR redirects stdout to a tmp file and then we reformat the result
into a small JSON object, grouped by the failure message with count.
Example:
```json [ { "pass": false, "data": { "message": "Expected no
error, got Error: TODO: Support complex object assignment", "count": 66
} }, { "pass": false, "data": { "message": "Expected no
error, got Error: TODO: lowerExpression(FunctionExpression)", "count": 4
} }, { "pass": false, "data": { "message": "Expected no
error, got Error: TODO: lowerExpression(UnaryExpression)", "count": 6
} }, { "pass": false, "data": { "message": "Expected no error,
got Error: todo: lower initializer in ForStatement", "count": 28 }
}, { "pass": false, "data": { "message": "Expected no error, got
Invariant Violation: Expected value for identifier `15` to be initialized.",
"count": 14 } }, { "pass": false, "data": { "message":
"Expected no error, got Invariant Violation: `var` declarations are not
supported, use let or const", "count": 76 } }, { "pass": true,
"data": { "message": null, "count": 1 } } ] ```
This micro-optimization never made sense and less so now that they're
rare.
This still initializes the class with a shared immutable object in the
constructor - which is also what createClass() does.
Then we override it during mount. This is done in case someone messes up
the initialization of the super() constructor for example, which was
more common in polyfills.
This change means that if a ref is initialized during the constructor
itself it wouldn't be lazily initialized but that's not user code that
does it, it's React so that shouldn't happen.
This makes string refs codemoddable as described in.
https://github.com/facebook/react/pull/25334
Some old environments like IE11 or very old versions of jsdom are
missing `getRootNode()`. Use feature detection to fall back to
`ownerDocuments` in these environments that also won't be supporting
shadow DOM anyway.
Add a new workflow to run the test262 tests on commits to main but not in pull
requests. This is to keep this test non-blocking on PRs but lets us track pass
rates over time
This just removes the error but the underlying issue is still there, and
it's likely that the best course of action is to not update in effects
and to wrap most updates in startTransition. However, that's more of a
performance concern which is not something we generally do even in
recoverable errors since they're less actionable and likely belong in
another channel. It is also likely that in many cases this happens so
rarely because you have to interact quickly enough that it can often be
ignored.
After changes to other parts of the model, this only happens for
sync/discrete updates. There are three scenarios that can happen:
- We replace a server rendered fallback with a client rendered fallback.
Other than this potentially causing some flickering in the loading
state, it's not a big deal.
- We replace the server rendered content with a client side fallback if
this suspends on the client. This is in line with what would happen
anyway. We will loose state of forms which is not intended semantics.
State and animations etc would've been lost anyway if it was client-side
so that's not a concern.
- We replace the server rendered content with a client side rendered
tree and lose selection/state and form state. While the content looks
the same, which is unfortunate.
In most scenarios it's a bad loading state but it's the same scenario as
flushing sync client-side. So it's not so bad.
The big change here is that we consider this a bug of React that we
should fix. Therefore it's not actionable to users today because it
should just get fixed. So we're removing the error early. Although
anyone that has fixed these issues already are probably better off for
it.
To fix this while still hydrating we need to be able to rewind a sync
tree and then replay it.
@tyao1 is going to add a Sync hydration lane. This is will allow us to
rewind the tree when we hit this state, and replay it given the previous
Context, hydrate and then reapply the update. The reason we didn't do
this originally is because it causes sync mode to unwind where as for
backwards compatibility we didn't want to cause that breaking semantic -
outside Suspense boundaries - and we don't want that semantic longer
term. We're only do this as a short term fix.
We should also have a way to leave a partial tree in place. If the sync
hydration lane suspends, we should be able to switch to a client side
fallback without throwing away the state of the DOM and then hydrate
later.
We now know how we want to fix this longer term. We're going to move all
Contexts into resumable trees like what Fizz/Flight does. That way we
can leave the original Context at the hydration boundaries and then
resume from there. That way the rewinding would never happen even in the
existence of a sync hydration lane which would only apply locally to the
dehydrated tree.
So the steps are 1) remove the error 2) add the sync hydration lane with
rewinding 3) Allow hiding server-rendered content while still not
hydrated 4) add resumable contexts at these boundaries.
Fixes#25625 and #24959.
Adds a new pass `InferReactiveScopeVariables` which determines the sets of
variables (by Identifier) which "construct together" and belong in the same
reactive scope. Concretely, `Identifier` gets a new property `scope: ScopeId`,
and this pass assigns each identifier a ScopeId value. The algorithm iterates
over all instructions in all blocks (in a single pass) and builds up disjoint
sets of identifiers that appear as mutable operands in the same instruction.
The algorithm is relatively simple (especially since I had already implemented a
union-find data structure): however looking at some examples reinforced that
other planned todos around alias analysis are really important. We also have to
think more about what "mutable lifetime" means in the context of SSA: currently
variables that are reassigned (but never "mutated", eg bc they're assigned a
value type) never appear as mutable.
Just realized we can run all tests without encountering the arg limit if a
string is passed in.
This is much better because the test runner will count all tests in the parent
test directory rather than run the tests in each subdirectory
Noticed this while running test262 tests that many variables were throwing an
invariant for being undefined. This includes things like the special `arguments`
object, a global `assert` function used by test262, etc.
- Adds a shallow git submodule for test262 as the tests aren't available as an
npm module - To run all tests: `yarn test262:all`. Note that this chunks up the
tests by test262 folder as there are over 50k+ tests and the test harness only
accepts arrays of filepaths which exceeds arg limits - To run a specific test:
`yarn test262 test262/test/folder/file.js`. You can also pass globs which
expand into an array of filepaths: `yarn test262 test262/test/folder/**/*.js` -
More instructions for the test-harness can be found here:
https://github.com/bterlson/test262-harness
I noticed on @kassens's #771 that despite running LeaveSSA there are still cases
where we still reassign to a unique identifier: functions that have reassignment
but no phi nodes, such as:
```javascript
function foo() {
let x$1 = 0;
x$2 = x$1 + 1;
}
```
Here SSA form rewrote the second statement's LHS, but bc there's no phi node we
can't recover what the original was supposed to be (`x = x + 1`). This was my
oversight when suggesting the simpler LeaveSSA algorithm, it works for
eliminating phis but not other reassignments. The only alternative to removing
SSA form is to add assignment statements, which we obviously don't want to do
since that generates bloat.
This PR addresses the issue by adding an additional, optional property to
`Identifier` called `preSsaId` that starts off null. When entering SSA we save
the original id in this property and update id to a new SSA value. LeaveSSA does
the inverse, setting id = preSsaId and nulling out the latter. This means that
an identifier can always be uniquely identified by its `id` value at any point
in the compiler, while it's trivial to correctly undo SSA form.
```typescript
type Identifier = {
// Unique value for each original identifier
id: IdentifierId;
// The original, un-mangled variable name if this was a variable present in the
source (null if it's generated)
name: string | null;
// When in SSA mode, this is set to the original, pre-SSA `id` value
preSsaId: IdentifierId | null;
}
```
Implements assignment expressions with operators other than `=` (such as `+=`)
by lowering to an assignment.
I think this isn't fully correct for something like `a.b.c += 1`, but it seems
like there's more gaps in object accesses.
- Get rid of `indent` as it was making the code hard to read - Remove
unnecessary 2nd iteration over blocks - Remove extra newline between the bb
subgraphs and the jumps section - Remove trailing spaces - Remove newlines
between each subgraph and jump
We might need to revisit the tabs vs. options split, but for now this just adds
a checkbox toggle that outputs codegenned JS instead of HIR in the HIR tab. Open
to ideas to organize this in the future...
## Summary
This PR is to fix a bug: an "element cannot be found" error when
hydrating Server Components
### The problem
<img width="1061" alt="image"
src="https://user-images.githubusercontent.com/1001890/201206046-ac32a5e3-b08a-4dc2-99f4-221dad504b28.png">
To reproduce:
1. setting up a vercel next.js 13 playground locally
https://github.com/vercel/app-playground
2. visit http://localhost:3000/loading
3. click "electronics" button to navigate to
http://localhost:3000/loading/electronics to trigger hydrating
4. inspect one of the skeleton card UI from React DevTools extension
### The root cause & fix
This bug was introduced in #22527. When syncing reconciler changes, the
value of `Hydrating` was copied from another variable `Visibility` (one
more zero in the binary number).
To avoid this kind of issue in the future, a new file `ReactFiberFlags`
is created following the same format of the one in reconciler, so that
it's easier to sync the number without making mistakes.
The reconciler fiber flag file is also updated to reflect which of the
flags are used in devtools
## How did you test this change?
I build it locally and the bug no longer exist on
http://localhost:3000/loading
This PR adds a new section to fixture tests, which renders the HIR into
a visualization using mermaid.js syntax which can then be embedded
directly into markdown.
The nice thing about the mermaid syntax is that it's quite readable, so
if desired we could replace the current basic block textual output with
the mermaid block. I'm opting to append it for now and wait for feedback
if we want to keep both or replace.
To view the graphs in your editor, download an extension that
adds mermaid.js support:
https://mermaid-js.github.io/mermaid/#/integrations?id=editor-plugins. In vscode
you can use this plugin by right clicking on "Open Preview" on any expect.md
file. No extra dependencies are required for GitHub which should have builtin
support for mermaid in markdown
Instead of hacking into the babel plugin passes, this now takes a new approach
for the HIR tab:
- The different passes are exported from the babel plugin (for simplicity)
- The tab actually runs the compiler steps based on local config in the tab.
- Re-purposed the CompilerFlags component to configure what passes to run. This
is currently mostly causing different errors, but could be useful going forward
as a direction.
The `--watch` argument forwarding wasn't working anymore because `yarn build`
doesn't have the `tsc` command at the end anymore. There's maybe something that
can be done to forward the watch argument, just call `tsc --watch` directly.
Nested Offscreens can run into a case where outer Offscreen is revealed
while inner one is hidden in a single commit. This is an edge case that
was previously missed. We need to prevent call to disappear layout
effects.
When we go from state:
```jsx
<Offscreen mode={'hidden'}> // outer offscreen
<Offscreen mode={'visible'}> // inner offscreen
{children}
</Offscreen>
</Offscreen>
```
To following. Notice that visibility of each offscreen flips.
```jsx
<Offscreen mode={'visible'}> // outer offscreen
<Offscreen mode={'hidden'}> // inner offscreen
{children}
</Offscreen>
</Offscreen>
```
Inner offscreen must not call
`recursivelyTraverseDisappearLayoutEffects`.
Check unit tests for an example of this.
Small adjustment to the previous PR for a special case:
```javascript
while (cond) {
break;
}
```
The loop body is an indirection to the fallthrough, so shrink() collapses that
and makes the while.loop === while.fallthrough. We now detect that this is the
case in codegen and correctly emit a `break` rather than trying to write the
fallthrough block inside the loop.
Adds a new 'while' terminal variant, which will be a model for other loop
terminals, and adds support for the entire compilation pipeline through codegen.
To understand the structure of the terminal consider this input:
```javascript
let x = 0;
while (x) {
x = foo(x);
}
return x;
```
We currently lower this to ifs and gotos:
```
bb0: precursor to loop
let x = 0;
goto(break) bb1; // <-- **The new terminal replaces this**
bb1: test block, whether to (re-)enter the loop
if (x) consequent=bb2 alternate=bb3;
bb2: loop body
x = foo(x);
goto(continue) bb1;
bb3: fallthrough after the loop
return x
```
This representation correctly models the semantics of while statements, but
loses the high-level information that there was a loop. The new 'while' terminal
replaces the first 'goto(break) bb1'. Conceptually, the 'while' terminal means
"enter the starting point of a while loop". In this example the terminal would
look like this:
```
{
kind: 'while',
testBlock: 'bb1', // the basic block that checks whether to enter the loop or
not
loop: 'bb2', // the block containing the loop body
fallthrough: 'bb3' // the block that goes after the loop
}
```
Most passes will only look at 'testBlock', ie they will treat this terminal as a
simple goto:testBlock. However, codegen uses the full information in the
terminal to reconstruct the loop. My previous PR, #755, added a mechanism to be
smart about when to emit or not emit `break` statements; this PR improves upon
that to accurately emit the minimal break and continue statements: ie omitting
entirely where they are extraneous, emitting unlabeled break/continue when
sufficient, and falling back to labeled break/continue only where strictly
necessary. The logic is very much analogous to IR construction.
Alternative approach to #750. We now store the original identifier on the Phi
node, then rewrite every BasicBlock's identifiers to reference the original id
instead of the SSA'd id.
This solves the shadowing problem and also lets us omit adding copies of
instructions.
The approach is very similar to what BuildHIR does to resolve break and continue
targets during IR construction:
* We annotate goto targets as either a break or a continue (during HIR
construction). This is necessary to reconstruct the right kind in codegen.
* Codegen continues to work by traversing the IR as if it were a tree, relying
on the `fallthrough` branches of if/switch to be able to visit the
consequent/alternate recursively and then emit the fallthrough branch.
* We track a Set of blocks that are scheduled to be emitted by some parent in
the tree. Nested ifs may all have the same fallthrough branch, which we only
want to emit once. This set helps us to know that a parent is already going to
emit some block, such that children can skip it.
* We also keep a stack of break targets that are in scope, and use this to
convert gotos appropriately, as either a break, continue, or nothing at all (for
example a switch case that falls through has no explicit syntax to model this
fall-through, the only option is to emit nothing for the goto).
* Then, if/switch have to carefully check whether each branch should be emitted
or not. For example, if the alternate is already scheduled to be emitted (by a
parent), then we emit a block with a break statement instead.
* Switch in particular is tricky, because we need to know that subsequent cases
are scheduled, but only for preceding blocks. So we visit the cases in reverse
order (not surprisingly, we do the same thing during IR construction for similar
reasons!).
The bookkeeping is a bit finicky but this works reliably. There are some cases
where we could try to emit an unlabeled break instead of a labeled break, or
avoid emitting a label at all (if nothing will explicitly break to that label),
but overall the generated code is readable enough that i'm inclined to ship and
iterate. I'm open to feedback though, as always!
Reverts #726 which added an early optimization to the SSAify pass in skipping
over phi creation if only one unique operand. This is no longer necessary with
the addition of a phi elimination pass added in #739.
This is an alternate take on phi elimination to the one we pursued over VC w
@poteto driving. This version exploits the RPO ordering of blocks to do phi
elimination in a single pass when there are no loops, and to minimize repeated
visits when there are loops. The main difference is when redundant phis are
removed. Rather than eagerly walking through the CFG for each pruned phi to
rewrite its uses, we build up a mapping of rewritten identifiers. As we walk
through subsequent instructions, we rewrite each place based on that mapping. We
continue cycling through the blocks so long as a given iteration *both* added
new rewrites (meaning there may be subsequent uses to rewrite) *and* there are
back-edges. With no loops this results in a single visit of each block and of
each instruction, but even with loops this is bounded.
This is a follow up on https://github.com/facebook/react/pull/25592
There is another condition Offscreen calls
`recursivelyTraverseDisappearLayoutEffects` when it shouldn't. Offscreen
may be nested. When nested Offscreen is hidden, it should only unmount
layout effects if it meets following conditions:
1. This is an update, not first mount.
2. This Offscreen was hidden before.
3. No ancestor Offscreen is hidden.
Previously, we were not accounting for the third condition.
I don't think we need this anymore. It was added originally because
RootSuspended would take priority over RootSuspendedWithDelay. But we've
since changed it: any "bad" fallback state is permitted to block a
"good" fallback state.
The other status flags that this check used to account for are
RootDidNotComplete and RootFatalErrored:
- RootFatalErrored is like an invariant violation, it means something
went really wrong already and we can't recover from it
- RootCompleted and RootDidNotComplete are only set at the very end of
the work loop, there's no way for renderDidSuspendDelayIfPossible to
sneak in after that (at least none that I can think of — it's only
called from the render phase)
So I think we can just delete this.
It's entirely possible there's some scenario I haven't considered,
though, which is why I'm submitting this change as its own PR. To
preserve the ability to bisect to it later.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn debug-test --watch TestName`, open
`chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
Following
[comment](https://github.com/facebook/react/pull/25437#discussion_r1010944983)
in #25437 , the external runtime implementation should be moved from
`react-dom` to `react-dom-bindings`.
I did have a question here:
I set the entrypoint to `react-dom/unstable_server-external-runtime.js`,
since a.) I was following #25436 as an example and b.)
`react-dom-bindings` was missing a `README.md` and `npm/`. This also
involved adding the external runtime to `package.json`.
However, the external runtime isn't really a `react-dom` entrypoint. Is
this change alright, or should I change the bundling code instead?
## How did you test this change?
<!--
Demonstrate the code is solid. Example: The exact commands you ran and
their output, screenshots / videos if the pull request changes the user
interface.
How exactly did you verify that your PR solves the issue you wanted to
solve?
If you leave this empty, your PR will very likely be closed.
-->
type validateDOMNesting
move `isHostResourceType` to ReactDOMHostConfig
type `AncestorInfo`
refactor `resourceFormOnly` into `ancestorInfo.containerTagInScope`
provide hostContext from reconciler
Makes it slightly more blazing.
No host config actually uses null as any useful and we use this as a
placeholder value anyway. It's also better for perf since it doesn't let
two different hidden classes pass around. It's also a magic place holder
that triggers error if we do try to access anything from it.
`title` is a valid element descendent of `svg`. this PR adds a
prohibition on turning titles in svg into Resources.
This PR also adds additional warnings if you render something that is
almost a Resource inside an svg.
Initial draft. I need to test this more.
If a promise is passed to `use`, but the I/O isn't cached, we should
still be able to unwrap it.
This already worked in Server Components, and during SSR.
For Fiber (in the browser), before this fix the state would get lost
between attempts unless the promise resolved immediately in a microtask,
which requires IO to be cached. This was due to an implementation quirk
of Fiber where the state is reset as soon as the stack unwinds. The
workaround is to suspend the entire Fiber work loop until the promise
resolves.
The Server Components and SSR runtimes don't require a workaround: they
can maintain multiple parallel child tasks and reuse the state
indefinitely across attempts. That's ideally how Fiber should work, too,
but it will require larger refactor.
The downside of our approach in Fiber is that it won't "warm up" the
siblings while you're suspended, but to avoid waterfalls you're supposed
to hoist data fetches higher in the tree regardless. But we have other
ideas for how we can add this back in the future. (Though again, this
doesn't affect Server Components, which already have the ideal
behavior.)
`wasHidden` is evaluted to false if `current` is null. This means
Offscreen has never been shown but this code assumes it is going from
'visible' to 'hidden' and unmounts layout effects.
To fix this, only unmount layout effects if `current` is not null.
I'm not able to repro this problem or write unit test for it. I see this
crash bug in production test.
The problem with repro is that if Offscreen starts as hidden, it's
render is deferred and current is no longer null.
Pure refactor, no change in behavior.
Extracts the logic for detecting whether a suspended component will
result in a "bad" Suspense fallback into a helper function. An example
of a bad Suspense fallback is one that causes already-visible content
to disappear.
I want to reuse this same logic in the work loop, too.
Refactors the logic for handling when the work loop is suspended into
separate functions for replaying versus unwinding. This allows us to
hoist certain checks into the caller.
For example, when rendering due to flushSync, we will always unwind the
stack without yielding the microtasks.
No intentional behavior change in this commit.
This is a pure refactor, no change to behavior.
When a component throws, the work loop can handle that in one of several
ways — unwind immediately, wait for microtasks, and so on. I'm about
to add another one, too. So I've changed the variable that tracks
whether the work loop is suspended from a boolean
(workInProgressIsSuspended) to an enum (workInProgressSuspendedReason).
In Strict Mode, during development, user functions are double invoked to
help detect side effects. Currently, the way we implement this is to
completely discard the first pass and start over. Theoretically this
should be fine because components are idempotent. However, it's a bit
tricky to get right because our implementation (i.e. `renderWithHooks`)
is not completely idempotent with respect to internal data structures,
like the work-in-progress fiber. In the past we've had to be really
careful to avoid subtle bugs — for example, during the initial mount,
`setState` functions are bound to the particular hook instances that
were created during that render. If we compute new hook instances, we
must also compute new children, and they must correspond to each other.
This commit addresses a similar issue that came up related to `use`:
when something suspends, `use` reuses the promise that was passed during
the first attempt. This is itself a form of memoization. We need to be
able to memoize the reactive inputs to the `use` call using a hook (i.e.
`useMemo`), which means, the reactive inputs to `use` must come from the
same component invocation as the output.
The solution I've chosen is, rather than double invoke the entire
`renderWithHook` function, we should double invoke each individual user
function. It's a bit confusing but here's how it works:
We will invoke the entire component function twice. However, during the
second invocation of the component, the hook state from the first
invocation will be reused. That means things like `useMemo` functions
won't run again, because the deps will match and the memoized result
will be reused.
We want memoized functions to run twice, too, so account for this, user
functions are double invoked during the *first* invocation of the
component function, and are *not* double invoked during the second
incovation:
- First execution of component function: user functions are double
invoked
- Second execution of component function (in Strict Mode, during
development): user functions are not double invoked.
It's hard to explain verbally but much clearer when you run the test
cases I've added.
The old (unstable) mechanism for suspending was to throw a promise. The
purpose of throwing is to interrupt the component's execution, and also
to signal to React that the interruption was caused by Suspense as
opposed to some other error.
A flaw is that throwing is meant to be an implementation detail — if
code in userspace catches the promise, it can lead to unexpected
behavior.
With `use`, userspace code does not throw promises directly, but `use`
itself still needs to throw something to interrupt the component and
unwind the stack.
The solution is to throw an internal error. In development, we can
detect whether the error was caught by a userspace try/catch block and
log a warning — though it's not foolproof, since a clever user could
catch the object and rethrow it later.
The error message includes advice to move `use` outside of the try/catch
block.
I did not yet implement the warning in Flight.
stacked on https://github.com/facebook/react/pull/25569
On the client noscript already never renders children so no resources
will be extracted from this context. On the server we now track if we
are in a noscript context and turn off Resource semantics in this scope
there are a few bugs where dom representations from SSR aren't
identified as Resources when they should be.
There are 3 semantics
Resource -> hoist to head, deduping, etc...
hydratable Component -> SSR'd and hydrated in place
non-hydratable Component -> never SSR'd, never hydrated, always inserted
on the client
this last category is small
(non stylesheet) links with onLoad and/or onError
async scripts with onLoad and/or onError
The reason we have this distinction for now is we need every SSR'd async
script to be assumable to be a Resource. we don't currently encode
onLoad on the server and so we couldn't otherwise tell if an async
script is a Resource or is an async script with an onLoad which would
not be a resource. To avoid this ambiguity we never emit the scripts in
SSR and assume they need to be inserted on the client.
We can explore changes to these semantics in the future or possibly
encode some identifier when we want to opt out of resource semantics but
still SSR the link or script.
# Summary
* This PR adds support for persisting certain settings to device
storage, allowing e.g. RN apps to properly patch the console when
restarted.
* The device storage APIs have signature `getConsolePatchSettings()` and
`setConsolePatchSettings(string)`, in iOS, are thin wrappers around the
`Library/Settings` turbomodule, and wrap a new TM that uses the `SharedPreferences` class in Android.
* Pass device storage getters/setters from RN to DevTools'
`connectToDevtools`. The setters are then used to populate values on
`window`. Later, the console is patched using these values.
* If we receive a notification from DevTools that the console patching
fields have been updated, we write values back to local storage.
* See https://github.com/facebook/react-native/pull/34903
# How did you test this change?
Manual testing, `yarn run test-build-devtools`, `yarn run prettier`,
`yarn run flow dom`
## Manual testing setup:
### React DevTools Frontend
* Get the DevTools frontend in flipper:
* `nvm install -g react-devtools-core`, then replace that package with a
symlink to the local package
* enable "use globally installed devtools" in flipper
* yarn run start in react-devtools, etc. as well
### React DevTools Backend
* `yarn run build:backend` in react-devtools-core, then copy-paste that
file to the expo app's node_modules directory
### React Native
* A local version of React Native can be patched in by modifying an expo
app's package.json, as in `"react-native":
"rbalicki2/react-native#branch-name"`
# Versioning safety
* There are three versioned modules to worry about: react native, the
devtools frontend and the devtools backend.
* The react devtools backend checks for whether a `cachedSettingsStore`
is passed from react native. If not (e.g. if React Native is outdated),
then no behavior changes.
* The devtools backend reads the patched console values from the cached
settings store. However, if nothing has been stored, for example because
the frontend is outdated or has never synced its settings, then behavior
doesn't change.
* The devtools frontend sends no new messages. However, if it did send a
new message (e.g. "store this value at this key"), and the backend was
outdated, that message would be silently ignored.
<!--
Thanks for submitting a pull request!
We appreciate you spending the time to work on these changes. Please
provide enough information so that others can review your pull request.
The three fields below are mandatory.
Before submitting a pull request, please make sure the following is
done:
1. Fork [the repository](https://github.com/facebook/react) and create
your branch from `main`.
2. Run `yarn` in the repository root.
3. If you've fixed a bug or added code that should be tested, add tests!
4. Ensure the test suite passes (`yarn test`). Tip: `yarn test --watch
TestName` is helpful in development.
5. Run `yarn test --prod` to test in the production environment. It
supports the same options as `yarn test`.
6. If you need a debugger, run `yarn debug-test --watch TestName`, open
`chrome://inspect`, and press "Inspect".
7. Format your code with
[prettier](https://github.com/prettier/prettier) (`yarn prettier`).
8. Make sure your code lints (`yarn lint`). Tip: `yarn linc` to only
check changed files.
9. Run the [Flow](https://flowtype.org/) type checks (`yarn flow`).
10. If you haven't already, complete the CLA.
Learn more about contributing:
https://reactjs.org/docs/how-to-contribute.html
-->
## Summary
In https://github.com/facebook/react/pull/25504,
`react-server-dom-webpack/` was deprecated in favor of
`react-server-dom-webpack/client`, but a remaining import wasn't
adjusted accordingly.
As a result, the remaining conditions within the file are no longer
firing appropriately, which I ran into while playing around with a fork
of
[server-components-demo](https://github.com/reactjs/server-components-demo).
The `index.js` file now contains a
[placeholder](https://github.com/facebook/react/blob/main/packages/react-server-dom-webpack/index.js)
and the actual logic of the client now sits in `/client`.
## How did you test this change?
I replaced `require.resolve('../')` with `require.resolve('../client')`
in the `react-server-dom-webpack` package in `node_modules` and
confirmed that the output of the build looked good again.
There are two different switch statements that we use to unwrap a
`use`-ed promise, but there really only needs to be one. This was a
factoring artifact that arose because I implemented the yieldy `status`
instrumentation thing before I implemented `use` (for promises that are
thrown directly during render, which is the old Suspense pattern that
will be superseded by `use`).
This is a refactor to track the array of thenables that is preserved
across replays in the work loop instead of the Thenable module.
The reason is that I'm about to add additional state to the Thenable
module that is specific to a particular attempt — like the current
index — and is reset between replays. So it's helpful to keep the two
kinds of state separate so it's clearer which state gets reset when.
The array of thenables is not reset until the work-in-progress either
completes or unwinds.
This also makes the structure more similar to Fizz and Flight.
Same as #25537 but for Flight.
I was going to wait to do this later because the temporary
implementation of async components uses some of the same code that
non-used wakables do, but it's not so bad. I just had to inline one bit
of code, which we'll remove when we unify the implementation with `use`.
This diff adds styling to the compiler options editor. The floating input/output
toggle button on small screens now spans the bottom of the screen, so that it
doesn't block the compiler options.
Height overflows when adjusting screen size are complicated by Monaco Editor and
will be addressed in a later diff.
Test plan:
Start Playground and see the latest look of the compiler options editor beneath
the output section.
Removes all the `path: NodePath` values from various IR node types, replacing
them with `loc: SourceLocation`. This type is an alias for babel's source
location type plus a "generated" variant. The "OtherStatement" kind also used
the `path` to print back the original AST (since we don't look into these);
instead, we now capture the underlying `node` and emit that as-is during
codegen.
While I was doing this, i also fixed up the places where we had passed a null
path; the vast majority have a clear place we can pull a location from. For
example, `a ?? b` syntax creates some places/instructions for the `a != null`,
but those can all point back to the `a` location.
This commit introduces a small update to our fixture tests to allow certain jest
`test` modifiers to be added to fixture tests via a leading prefix in the
fixture name.
For example, `only.my-fixture.js` is the equivalent of writing
`test.only("my-fixture")`.
This currently basically lowers the code into the equivalent of
```
const vLeft = <left>;
const vNull = null;
const vCond = vLeft != vNull;
vCond ? vLeft : <right>
```
I created a temporary `Place` to hold the `null` constant value because the
binary operator in HIR accepts only `Place`s. Not sure if this is the preferred
approach. Alternatives I could think of:
- Allow constants as an alternative to Place?
- A `NotNull` operator for `<x> != null`
- Some other extension to the HIR?
## Proper Detection of Out-of-order Functions
The no-use-before-define rule from ESLint has a strange behavior in which it
treats variables differently than functions:
```javascript
function foo() {
return bar(X);
}
const X = null;
function bar(x) {}
```
By default, `bar(x)` has two errors: one because X is used before defined, and
once because `bar` is used before defined. The rule has an option `{variables:
false}` which only enables validation when the variable is from the same "scope"
as the reference, the net result of which is it means it doesn't report spurious
errors such as X being undefined. There is _also_ a `{functions: false}` option,
but for some reason that doesn't work the same way, it just turns off all
validation of references that came from functions. So enabling that option would
suppress the (spurious) error on invoking `bar()` above, but causes the rule to
miss invalid code such as:
```
function foo() {
return bar();
function bar() {}
}
```
This PR adds a fork of the rule that makes `{functions: false}` behave similarly
to `{variables: false}`, which should help avoid some of the spurious errors i
saw internally. The rule is exported from Forget itself, which will make it
easier to consume internally, in tests, and in the playground.
## Targeting the validation to Forget functions
Even with the above, there are still some false positives coming from code such
as:
```javascript
const x = foo();
function foo() {}
```
This PR changes codegen to ensure that the output of a function _always_ has the
body starting with 'use forget'. The ESLint rule then only looks at function
declarations/expressions whose body starts with that expression. The new unit
test confirms that the validation finds invalid reorderings even on functions
that weren't explicitly tagged as 'use forget'.
This just piggybacks on the infrastructure for handling Env.#variables.
In the future, a better approach would be to simplify the environment creation
and merging by leveraging the SSA property of the new IR -- 1) We don't need to
track IdentifierId per environment as they are all unique 2) Rather than
tracking values, we can just track Identifiers because Identifiers can never
be reassigned.
The semantics of lvalue changes based on whether lvalue.place.memberPath is null
or not. If it's null, then lvalue.place acts as the lvalue for the instruction,
otherwise it's just a reference to the memberPath specified location.
Ideally we'd have an MemberExpression IR that lowers this complex lvalue into a
temporary Place, uses this temporary place and stores back to the
MemberExpression.
Working around for now, will refactor to create a MemberExpression in the future
if necessary for other analysis.
Instead of using Place, use Identifier as the unit of comparison in SSA.
Place is too high level and can not be substituted for other Places (even those
with the same Identifier) as Place contain higher level metadata such as
memberPath.
Currently, HIR doesn't load global idenfifiers into a temporary Place which
means our SSA transform breaks when it tries to lookup this global identifier.
Instead of throwing, let's log and return the old place. This works for now but
will probably break when we start mutating globals, but at that point our HIR
builder will need fixes.
keys off `target` and `href`.
prepends on insertion similar to title.
only flushes on the server in the shell (should probably add a warning
if there are any to flush in a boundary)
This extends the scope of the cache and fetch instrumentation using
AsyncLocalStorage for microtasks. This is an intermediate step. It sets
up the dispatcher only once. This is unique to RSC because it uses the
react.shared-subset module for its shared state.
Ideally we should support multiple renderers. We should also have this
take over from an outer SSR's instrumented fetch. We should also be able
to have a fallback to global state per request where AsyncLocalStorage
doesn't exist and then the whole client-side solutions. I'm still
figuring out the right wiring for that so this is a temporary hack.
Revert fetch instrumentation so that it only affects RSC by applying it
only in the react-server condition of "react".
This helps make the rollout a little smoother because these affects
existing libraries that fetch during client components, and then gets
forever cached. We need to implement the GC first.
I haven't fully implemented the SSR part anyway.
The main problem that we discovered is that `"react"` and
`"react/react.shared-subset"` have separate dispatchers in an
environment that runs both Fizz and Flight. That's intentional and
sometimes a feature. However, in this case it means that we instrument
fetch twice and when you run Flight inside Fizz, that fetch goes into
both caches when it's supposed to only see the inner one. I'm not sure
how to solve that atm.
Adds some clarifying warnings when you render a component that is almost
a resource but isn't and the element was rendered outside the main
document tree (outside of `<body>` or `<head>`
replaces: https://github.com/facebook/react/pull/25535
This takes a more huerstic based approach with no new conditionals on
the hot path of fizz rendering.
If float is enabled
* title and script can only have simple children
* if non-simple children are found they will be ignored
* title and script are pushed in a single unit during pushStartInstance
including their children and closing tags
If float is not enabled
* the original pushing behaviors are in place and you can have complex
children but you will get warnings
To derisk the rollout of `use`, and simplify the implementation, this
reverts the yield-to-microtasks behavior for promises that are thrown
directly (as opposed to being unwrapped by `use`).
We may add this back later. However, the plan is to deprecate throwing a
promise directly and migrate all existing Suspense code to `use`, so the
extra code probably isn't worth it.
escapeTextForBrowser accepts any type so flow did not identify that we
were escaping a Chunk rather than a string. It's tricky because we
sometimes want to be able to escape non strings.
I've also updated the types for `Chunk` and `escapeTextForBrowser`
so that we should be able to catch this statically in the future.
The reason this did not show up in tests is almost all of our tests of
float (the areas affected by transpositions) are tested using the Node
runtime where a chunk type is a string. It may be wise to run these
tests in every runtime in the future or at least make sure there is
broad representation of resources in each specific runtime test suite.
stacked on https://github.com/facebook/react/pull/25514
This PR adds support for any type of Link as long as it has a string rel
and href and does not include an onLoad or onError property.
The semantics for generic link resources matches other head resources,
they will be inserted and removed as their ref counts go positive and
back to zero.
Keys are based on rel, href, sizes, and media.
on the server preconnect and prefetch-dns are privileged and will emit
near the start of the stream.
## Summary
resolves#24522
To upgrade to Manifest V3, one of the biggest issue is that we are no
longer allowed to add a script element with code in textContent so that
it would run synchronously. It's necessary for us because we need to
inject a global hook for react reconciler to detect whether devtools
exist.
To do that, we'll leverage a new API
`chrome.scripting.registerContentScripts` in V3. Particularly, we rely
on the "world" option (added in Chrome v102
[commit](e5ad3451c1))
to run it in the "main world" on the page.
This PR also renames a few content script files so that it's easier to
tell them apart from other extension scripts and understand the purpose
of each of them.
Manifest V3 is not yet ready for Firefox, so we need to keep some code
for compatibility.
## How did you test this change?
`yarn build:chrome && yarn test:chrome`
`yarn build:edge && yarn test:edge`
`yarn build:firefox && yarn test:firefox`
Stacked on #25508
This PR adds meta tags as a resource type.
metas are classified in the following priority
1. charset
2. http-equiv
3. property
4. name
5. itemprop
when using property, there is special logic for og type properties where
a `property="og:image:height"` following a `property="og:image"` will
inherit the key of the previous tag. this relies on timing effects to
stay consistent so when mounting new metas it is important that if
structured properties are being used all members of a structure mount
together. This is similarly true for arrays where the implicit
sequential order defines the array structure. if you need an array you
need to mount all array members in the same pass.
ESLint's default parser doesn't support any non-standard syntax, which includes
JSX. So when I added the ESLint validation step to the playground, it meant that
valid examples containing JSX still reported "invalid output". I tried to use an
alternative parser, but I couldn't figure out the right webpack incantations to
make `@babel/eslint-parser` or `hermes-eslint` work. I even tried recreating
some of their code to avoid problematic imports, no dice.
Instead this PR:
* No longer uses the `postCodegenValidator` step, and runs the validation on the
output after compilation completes. This is better anyway since we can see the
output *and* the error messages
* Shows rule violations as an "Invalid output" comment
* Shows parser errors as a note (mostly to indicate that the validation step
couldn't run, there could still be no-use-before-define violations that weren't
found)
Invalid example:
<img width="1502" alt="Screen Shot 2022-10-21 at 9 50 23 AM"
src="https://user-images.githubusercontent.com/6425824/197249007-1ec244a0-6dfe-4ec6-a0d0-60302efd86bd.png">
Sample example but with some JSX:
<img width="1500" alt="Screen Shot 2022-10-21 at 9 50 39 AM"
src="https://user-images.githubusercontent.com/6425824/197249030-e68ba968-4101-47c7-a148-f548f84f375c.png">
Imports the runtime from `React.unstable_ForgetRuntime` rather than from a
separate module. The hope is that any code that gets transformed already has a
dependency on React anyway, so we can avoid adding a new dependency that other
systems don't know about.
While here, i also cleaned up the `guardThrows` flag (we still parse it if
present and warn, rather than throwing, to make it easier to adopt the latest
version in various places).
#686 added an option to validate generated code after transformation and adds an
ESLint-based validator function to transform-test. Unfortunately it isn't super
easy to wire up ESLint for use in a browser: traditionally the ESLint project
specifically did _not_ support browser builds, but they recently have relaxed
this because they added a browser playground on their website. There isn't
official support, but the [playground
repo](f3b1f78cc1/webpack.config.js)
has a webpack config that, when combined with requiring a specific file, allows
making things work in a browser.
I tried using this directly in our playground app but Next's default webpack
config doesn't work. So I created a separate package, playground-validator,
which exports a webpack-built version of `eslint.Linter`. Then the playground
can consume that, and everything works:
## Test Plan 👀
Confirmed that a known problematic example displays the validation message in
playground (both locally and on the preview deployment):
<img width="1500" alt="Screen Shot 2022-10-20 at 12 22 59 PM"
src="https://user-images.githubusercontent.com/6425824/197041265-966ffda2-a3d0-450e-8fc4-fd1a7ca06e1a.png">
With the `react-dom/server-rendering-stub` you can import `react-dom` in
RSC so that you can call `preload` and `preinit` but if you don't alias
it, then requiring it breaks because we React.Component which doesn't
exist in the react subset.
Adds a category of Resources of type `head` which will be used to track
the tags that go into the <head>
Currently only implements for `<title>`.
titles are keyed off their textContent so each time the title changes a
new resource will be created. Currently insertion is done by prepending
in the <head>. The argument here is that the newest title should "win"
if there are multiple rendered. This also helps when a navigation or
update causes a server rendered title to hang around but it is not the
most recent one.
`use` can avoid suspending on already resolved data by yielding to
microtasks. In a real, browser environment, we do this by scheduling a
platform task (i.e. postTask).
In a test environment, tasks are scheduled on a special internal queue
so that they can be flushed by the `act` testing API. So we need to add
support for this in `act`.
This behavior only works if you `await` the thenable returned by the
`act` call. We currently do not require that users do this. So I added a
warning, but it only fires if `use` was called. The old Suspense pattern
will not trigger a warning. This is to avoid breaking existing tests
that use Suspense.
The implementation of `act` has gotten extremely complicated because of
the subtle changes in behavior over the years, and our commitment to
maintaining backwards compatibility. We really should consider being
more restrictive in a future major release.
The changes are a bit confusing so I did my best to add inline comments
explaining how it works.
## Test plan
I ran this against Facebook's internal Jest test suite to confirm
nothing broke
* Add fetch instrumentation in cached contexts
* Avoid unhandled rejection errors for Promises that we intentionally ignore
In the final passes, we ignore the newly generated Promises and use
the previous ones. This ensures that if those generate errors, that we
intentionally ignore those.
* Add extra fetch properties if there were any
Adds a new compiler option `validateNoUseBeforeDefine`, which enables a
post-codegen pass to validate that there are no usages of values before they are
defined (which causes a ReferenceError at runtime). This can occur when a value
is accessed when its in the TDZ (temporary dead zone), after the hoisted
_declaration_ but before the variable is defined:
```javascript
function foo() {
x; // x is in the TDX here: the binding from the subsequent statement is
hoisted, but x is not yet defined.
let x;
}
```
* The validation is off by default, but enabled in transform-test
* The validation crashes compilation, rather than bailout, because the code has
already been mangled and we can't roll back at the point the validation runs.
* The validator uses ESLint's no-use-before-define rule by printing the program
to source and then configuring ESLint to use Hermes parser.
* transform-test now supports tests prefixed with "error." to indicate tests for
which compilation is expected to crash (not just bailout), and the expect file
includes the error message.
* [useEvent] Lint for presence of useEvent functions in dependency lists
With #25473, the identity of useEvent's return value is no longer stable
across renders. Previously, the ExhaustiveDeps lint rule would only
allow the omission of the useEvent function, but you could still add it
as a dependency.
This PR updates the ExhaustiveDeps rule to explicitly check for the
presence of useEvent functions in dependency lists, and emits a warning
and suggestion/autofixer for removing the dependency.
* [useEvent] Non-stable function identity
Since useEvent shouldn't go in the dependency list of whatever is
consuming it (which is enforced by the fact that useEvent functions are
always locally created and never passed by reference), its identity
doesn't matter. Effectively, this PR is a runtime assertion
that you can't rely on the return value of useEvent to be stable.
* Test: Events should see latest bindings
The key feature of useEvent that makes it different from useCallback
is that events always see the latest committed values. There's no such
thing as a "stale" event handler.
* Don't queue a commit effect on mount
* Inline event function wrapping
- Inlines wrapping of the callback
- Use a mutable ref-style object instead of a callable object
- Fix types
Co-authored-by: Andrew Clark <git@andrewclark.io>
Some prior [microbenchmarking](https://jsbench.me/7ol98ws520/1) showed that a
for loop outperformed `fill` (which is about ~60% slower). This is the same
approach we use in the latest useMemoCache PR
This is a new module that holds:
- the `useMemoCache` stub (hopefully to be deleted next week)
- various helpers that can be imported by the compiler, e.g. the dispatcher
guard `$startLazy`
- skipped the implementation of `makeReadOnly` for now as there's already
multiple copies and I wanted to avoid typescript in this file for now to make
the build easier (i.e. no build)
I'm not sure why exactly but previously this diagnostic message was
unusually slow to typecheck. Lifting the getter for init outside of the
diagnostic to the callsite seems to fix the hotspot. Probably some
interaction with string interpolation, or something else.
Test case: ran `yarn ts:analyze-trace`, hotspot for Diagnostic.ts no
longer present
Previously the PassManager would console.error if an unexpected error was
thrown, to help with debugging jest. However because we now capture all
invariants in compiler passes as bailouts, these are already captured in fixture
tests.
Additionally, we also already console.error if we find an unexpected bailout in
a fixture test. So this is purely redundant and removing reduces some noise when
running tests.
The current allowlist for capitalized function identifiers only allows stdlib JS
modules. This PR introduces a new compiler option to allow passing in a set of
allowed capitalized user function identifiers. It's a hack (in the absence of a
type system) to let us check that capitalized function calls are only possible
for identifiers that aren't bound to a React component.
I considered adding a mechanism in fixtures to configure compiler options
per-fixture, but opted to keep it simple for now and special case a
`ReactForgetSecretInternals` identifier as one allowed user function in
transform tests.
The CompilerError module's `invariant` is wired up to our bailout system so in
compiler passes should be preferred to the raw `invariant` module.
We should probably add an internal eslint rule to suggest using CompilerError if
the file is in one of the compiler pass directories.
* Renames `Capability` to `Effect` and clarifies the kinds as Freeze, Read, and
Mutate. The real intent of what we're inferring/representing is "what effect
does this reference to the value have on its value". Ie freeze freezes the
value, mutate mutates it.
* Consolidates Capability and EffectKind into Effect
* Renames some properties on Place for clarity
* Adds `value: ValueKind` to Place, which indicates the (merged) kind of the
value at that place at that point in the program.
* Changes HIR printing to show the effect and the value kind
* Simplifies some inference logic
* Changes HIR to store blocks in reverse postorder, which allows forward data
flow analysis to iterate the blocks in order and (in the absence of loops) see
all predecessors before visiting a successor.
* Updates reference kind inference to exploit this ordering
Note that the approach of modifying the ordering in `mapTerminalSuccessors()`
feels gross, i'd like to split this up a bit.
Scaffolds out mutable lifetime inference and the potential two-pass approach,
with motivating examples. Also adds some fixtures that collectively demonstrate
a bunch of cases of aliasing:
* direct assignment `a = b`
* property assignment `a.b = b`
* array literals `a = [b]`
* object literals `a = {b}`
* mutable arguments to the same call `foo(mut a, mut b)`
* return values aliasing arguments `a = foo(mut b)`
* aliasing that occurs only after multiple loop iterations
All of these fixtures use an empty `if (varName) {}` as a way to check that an
otherwise readonly usage of a variable is correctly inferred as mutable.
This implements an alternative approach to reference kind inference in the new
architecture based on feedback. Here, we track an environment that maps
top-level identifiers (IdentifierId) to the "kind" of value stored: immutable,
mutable, frozen, or maybe-frozen. We then do a forward data flow analysis
updating this environment based on the semantics of each instruction combined
with the types of values present. For example a reference of a value in a
"mutable" position is inferred as readonly if the value is known to be frozen or
immutable. Similarly, a usage of a reference in a "freeze" position is inferred
as a freeze if the value is not yet definitively frozen, and inferred as
readonly if the value is already frozen.
When multiple control paths converge we merge the previous and new incoming
environments, and only reprocess the block if the environment changed relative
to the previous value. This has some noticeable benefits over the previous
version:
* We now infer precisely where `makeReadOnly()` calls need to be inserted, aka
points where a value needs to be frozen may not yet be frozen.
* We track immutable values and can infer their usage as readonly rather than
mutable.
* The system handles aliasing by representing values as distinct from variables,
so that we can handle situations such as:
```javascript
const a = []; // env: {a: value0; value0: mutable}
const b = a; // env: {a: value0, b: value0; value0: mutable}
freeze(a); // env: {a: value0, b: value0; value0: frozen}
mayMutate(b); // ordinarily inferred as a mutable reference, but we know its
readonly
```
I didn't make this an option as it's unclear we'll really need this. We can
always add an option later, I think.
This is the name that's available on facebook.com at the moment.
Control dep should only affect how things are invalidated, which are modeled as
defs including declarations, writable uses to variables and expressions.
Closes#633
commit-id:41bd6fe5
Inputs occured in depGraph cycle is dangenrous and should be treated as an
invariant since Forget _may_ generate broken code in this case, despite that
technically this is a stricter then what we needed for the particular case of
#633 and #634 and there could be case that this is safe (like many `cfg-`
tests that I have to mark as `bailout.`)
I expect the next diff will fix them though.
commit-id:0b13ed02
Distinguishes between `LValue` and `Place`. For the most part this is the same
data structure (LValue composes Place), but it's helpful to distinguish them
since LValue has other properties such as the kind of declaration. The
representations may diverge more in the future.
This change lets us correctly emit code for variable declarations: previously we
didn't emit `let` or `const`.
Flushes out basic codegen for switch statements. This is more indication that we
can recover nearly the original source even for complex control-flow, given the
right IR design.
NOTE: this improves the equivalent of "ref kind inference" in the new
architecture. I'd appreciate review here on the algorithm in particular, but in
general my plan is to try to implement this on the current architecture.
The previous InferMutability reference kind inference didn't properly handle
capturing or reassignment combined with control flow. This is a new version
(i'll clean up to delete InferMutability entirely) that is less ambitious but
fully accurate (i hope, hence WIP):
* Annotates all references of frozen variables as frozen. This includes
following reassignment, so if you do `const x = props.x; foo(x);` we know that
`x` is frozen because it derived from a frozen value. This even works
conditionally, so if `x` is conditionally assigned to some value derived from eg
props, and you later use `x`, that will be marked as frozen even if it could
have other values at runtime (since it must conservatively assume a frozen value
flowed in at runtime).
* Annotates references that may mutate as mutable.
* Annotates references that are not frozen, but not mutated _at this reference
site_, as readonly. It's possible that a readonly usage is followed by a mutable
usage, since we don't yet know the "lifetime" of the mutability.
The notable difference from the previous attempt is that we do not attempt to
find the point at which a formerly-mutable values becomes readonly (and
therefore eligible for caching). That requires pointer analysis, let's discuss
offline.
Var declarations were treated identical as other declarations which cause code
relying on them getting hoisted now triggers runtime exception on TDZ.
This diff fixed that by generating `var` for `var` so they can be hoisted as
usual.
commit-id:00ab02f6
* [hir] Core data types and lowering for new model
* Handle more expressions, including using babel for binding resolution
* test setup with pretty printing of ir
* Basic codegen and improved pretty printing
* avoid else block when if has no fallthrough
* emit function declarations with mapped name/params
* start of scope analysis
* saving state pre-run
* add slightly more complex example and flush out lowering/printing (jsx, new, variables)
* Various improvements:
* Convert logical expressions (|| and &&) to control flow, accounting
for lazy evaluation semantics.
* Handle expression statements
* Improve printing of HIR for unsupported node kinds
* Handle more cases of JSX by falling by to OtherStatement to wrap
subtrees at coarse granularity.
* improve HIR printing, lowering of expression statements
* handle object expression printing
* improve IR model for values/places along w codegen
* more test cases
* start of mutability inference
* passable but still incorrect mutability inference
* improved mutability inference, should cover most cases now
* visualization of reference graph
* correctly flow mutability backwards (have to actually set the capability)
* separate visualization in output
* consolidate on frozen/readonly/mutable capabilities
* cleanup
* conditional reassignment test (not quite working)
* hack to output svg files for debugging
* handle conditional reassignment
* improve capture analysis
* treat jsx as (interior) mutable; handle memberexpression lvalues
* lots of comments; hook return is frozen
* update main comment
* inference for switch, which reveals a bug
* fix yarn.lock
git diff --quiet || (echo "Found unminified errors. Either update the error codes map or disable error minification for the affected build, if appropriate." && false)
check_generated_fizz_runtime:
docker:*docker
environment:*environment
steps:
- checkout
- attach_workspace:*attach_workspace
- *restore_node_modules
- run:
name:Confirm generated inline Fizz runtime is up to date
command:|
yarn generate-inline-fizz-runtime
git diff --quiet || (echo "There was a change to the Fizz runtime. Run `yarn generate-inline-fizz-runtime` and check in the result." && false)
git diff --quiet || (echo "Reconciler forks are not the same! Run yarn replace-fork. Or, if this was intentional, add the commit SHA to scripts/merge-fork/forked-revisions." && false)
workflows:
version:2
# New workflow that will replace "stable" and "experimental"
Please indicate if this issue affects the following tools provided by React Compiler.
options:
- label:React Compiler core (the JS output is incorrect, or your app works incorrectly after optimization)
- label:babel-plugin-react-compiler (build issue installing or using the Babel plugin)
- label:eslint-plugin-react-compiler (build issue installing or using the eslint plugin)
- label:react-compiler-healthcheck (build issue installing or using the healthcheck script)
- type:input
attributes:
label:Link to repro
description:|
Please provide a repro by either sharing a [Playground link](https://playground.react.dev), or a public GitHub repo so the React team can reproduce the error being reported. Please do not share localhost links!
placeholder:|
e.g. public GitHub repo, or Playground link
validations:
required:true
- type:textarea
attributes:
label:Repro steps
description:|
What were you doing when the bug happened? Detailed information helps maintainers reproduce and fix bugs.
Issues filed without repro steps will be closed.
placeholder:|
Example bug report:
1. Log in with username/password
2. Click "Messages" on the left menu
3. Open any message in the list
validations:
required:true
- type:dropdown
attributes:
label:How often does this bug happen?
description:|
Following the repro steps above, how easily are you able to reproduce this bug?
options:
- Every time
- Often
- Sometimes
- Only once
validations:
required:true
- type:input
attributes:
label:What version of React are you using?
description:|
Please provide your React version in the app where this issue occurred.
validations:
required:true
- type:input
attributes:
label:What version of React Compiler are you using?
description:|
Please provide the exact React Compiler version in the app where this issue occurred.
# Configuration for probot-stale - https://github.com/probot/stale
# Number of days of inactivity before an issue becomes stale
daysUntilStale:90
# Number of days of inactivity before a stale issue is closed
daysUntilClose:7
# Issues with these labels will never be considered stale
exemptLabels:
- "Partner"
- "React Core Team"
- "Resolution: Backlog"
- "Type: Bug"
- "Type: Discussion"
- "Type: Needs Investigation"
- "Type: Regression"
# Label to use when marking an issue as stale
staleLabel:"Resolution: Stale"
issues:
# Comment to post when marking an issue as stale.
markComment:>
This issue has been automatically marked as stale.
**If this issue is still affecting you, please leave any comment** (for example, "bump"), and we'll keep it open.
We are sorry that we haven't been able to prioritize it yet. If you have any new additional information, please include it with your comment!
# Comment to post when closing a stale issue.
closeComment:>
Closing this issue after a prolonged period of inactivity. If this issue is still present in the latest release, please create a new issue with up-to-date information. Thank you!
pulls:
# Comment to post when marking a pull request as stale.
markComment:>
This pull request has been automatically marked as stale.
**If this pull request is still relevant, please leave any comment** (for example, "bump"), and we'll keep it open.
We are sorry that we haven't been able to prioritize reviewing it yet. Your contribution is very much appreciated.
# Comment to post when closing a stale pull request.
closeComment:>
Closing this pull request after a prolonged period of inactivity. If this issue is still present in the latest release, please ask for this pull request to be reopened. Thank you!
Please help us by providing a link to a CodeSandbox (https://codesandbox.io/s/new), a repository on GitHub, or a minimal code example that reproduces the problem. (Screenshots or videos can also be helpful if they help provide context on how to repro the bug.)
Here are some tips for providing a minimal example: https://stackoverflow.com/help/mcve
Issues without repros are automatically closed but we will re-open if you update with repro info.
`.trim();
if (url.includes("localhost")) {
closeWithComment(`
${COMMENT_HEADER}
Unfortunately the URL you provided ("localhost") is not publicly accessible. (This means that we will not be able to reproduce the problem you're reporting.)
${COMMENT_FOOTER}
`);
} else if (url.length < 10 || url.match(PROBABLY_NOT_A_URL_REGEX)) {
closeWithComment(`
${COMMENT_HEADER}
It looks like you forgot to specify a valid URL. (This means that we will not be able to reproduce the problem you're reporting.)
${COMMENT_FOOTER}
`);
} else if (reproSteps.length < 25) {
closeWithComment(`
${COMMENT_HEADER}
Unfortunately, it doesn't look like this issue has enough info for one of us to reproduce and fix it though.
${COMMENT_FOOTER}
`);
} else {
openWithComment(`
Thank you for providing repro steps! Re-opening issue now for triage.
- name:Search build artifacts for unminified errors
run:|
yarn extract-errors
git diff --quiet || (echo "Found unminified errors. Either update the error codes map or disable error minification for the affected build, if appropriate." && false)
- name:Insert @headers into eslint plugin and react-refresh
run:|
sed -i -e 's/ LICENSE file in the root directory of this source tree./ LICENSE file in the root directory of this source tree.\n *\n * @noformat\n * @nolint\n * @lightSyntaxTransform\n * @preventMunge\n * @oncall react_core/' \
# Number of days of inactivity before an issue or PR becomes stale
days-before-stale:90
# Number of days of inactivity before a stale issue or PR is closed
days-before-close:7
# API calls per run
operations-per-run:100
# --- Issues ---
stale-issue-label:"Resolution: Stale"
# Comment to post when marking an issue as stale
stale-issue-message:>
This issue has been automatically marked as stale.
**If this issue is still affecting you, please leave any comment** (for example, "bump"), and we'll keep it open.
We are sorry that we haven't been able to prioritize it yet. If you have any new additional information, please include it with your comment!
# Comment to post when closing a stale issue
close-issue-message:>
Closing this issue after a prolonged period of inactivity. If this issue is still present in the latest release, please create a new issue with up-to-date information. Thank you!
# Issues with these labels will never be considered stale
# Comment to post when marking a pull request as stale
stale-pr-message:>
This pull request has been automatically marked as stale.
**If this pull request is still relevant, please leave any comment** (for example, "bump"), and we'll keep it open.
We are sorry that we haven't been able to prioritize reviewing it yet. Your contribution is very much appreciated.
# Comment to post when closing a stale pull request
close-pr-message:>
Closing this pull request after a prolonged period of inactivity. If this issue is still present in the latest release, please ask for this pull request to be reopened. Thank you!
# PRs with these labels will never be considered stale
An Owner Stack is a string representing the components that are directly responsible for rendering a particular component. You can log Owner Stacks when debugging or use Owner Stacks to enhance error overlays or other development tools. Owner Stacks are only available in development builds. Component Stacks in production are unchanged.
* An Owner Stack is a development-only stack trace that helps identify which components are responsible for rendering a particular component. An Owner Stack is distinct from a Component Stacks, which shows the hierarchy of components leading to an error.
* The [captureOwnerStack API](https://react.dev/reference/react/captureOwnerStack) is only available in development mode and returns a Owner Stack, if available. The API can be used to enhance error overlays or log component relationships when debugging. [#29923](https://github.com/facebook/react/pull/29923), [#32353](https://github.com/facebook/react/pull/32353), [#30306](https://github.com/facebook/react/pull/30306),
* Enhanced support for Suspense boundaries to be used anywhere, including the client, server, and during hydration. [#32069](https://github.com/facebook/react/pull/32069), [#32163](https://github.com/facebook/react/pull/32163), [#32224](https://github.com/facebook/react/pull/32224), [#32252](https://github.com/facebook/react/pull/32252)
* Reduced unnecessary client rendering through improved hydration scheduling [#31751](https://github.com/facebook/react/pull/31751)
* Increased priority of client rendered Suspense boundaries [#31776](https://github.com/facebook/react/pull/31776)
* Fixed frozen fallback states by rendering unfinished Suspense boundaries on the client. [#31620](https://github.com/facebook/react/pull/31620)
* Fixed erroneous “Waiting for Paint” log when the passive effect phase was not delayed [#31526](https://github.com/facebook/react/pull/31526)
* Fixed a regression causing key warnings for flattened positional children in development mode. [#32117](https://github.com/facebook/react/pull/32117)
* Updated `useId` to use valid CSS selectors, changing format from `:r123:` to `«r123»`. [#32001](https://github.com/facebook/react/pull/32001)
* Added a dev-only warning for null/undefined created in useEffect, useInsertionEffect, and useLayoutEffect. [#32355](https://github.com/facebook/react/pull/32355)
* Fixed a bug where dev-only methods were exported in production builds. React.act is no longer available in production builds. [#32200](https://github.com/facebook/react/pull/32200)
* Improved consistency across prod and dev to improve compatibility with Google Closure Complier and bindings [#31808](https://github.com/facebook/react/pull/31808)
* Improve passive effect scheduling for consistent task yielding. [#31785](https://github.com/facebook/react/pull/31785)
* Fixed asserts in React Native when passChildrenWhenCloningPersistedNodes is enabled for OffscreenComponent rendering. [#32528](https://github.com/facebook/react/pull/32528)
* Fixed component name resolution for Portal [#32640](https://github.com/facebook/react/pull/32640)
* Added support for beforetoggle and toggle events on the dialog element. #32479 [#32479](https://github.com/facebook/react/pull/32479)
### React DOM
* Fixed double warning when the `href` attribute is an empty string [#31783](https://github.com/facebook/react/pull/31783)
* Fixed an edge case where `getHoistableRoot()` didn’t work properly when the container was a Document [#32321](https://github.com/facebook/react/pull/32321)
* Removed support for using HTML comments (e.g. `<!-- -->`) as a DOM container. [#32250](https://github.com/facebook/react/pull/32250)
* Added support for `<script>` and `<template>` tags to be nested within `<select>` tags. [#31837](https://github.com/facebook/react/pull/31837)
* Fixed responsive images to be preloaded as HTML instead of headers [#32445](https://github.com/facebook/react/pull/32445)
### use-sync-external-store
* Added `exports` field to `package.json` for `use-sync-external-store` to support various entrypoints. [#25231](https://github.com/facebook/react/pull/25231)
### React Server Components
* Added `unstable_prerender`, a new experimental API for prerendering React Server Components on the server [#31724](https://github.com/facebook/react/pull/31724)
* Fixed an issue where streams would hang when receiving new chunks after a global error [#31840](https://github.com/facebook/react/pull/31840), [#31851](https://github.com/facebook/react/pull/31851)
* Fixed an issue where pending chunks were counted twice. [#31833](https://github.com/facebook/react/pull/31833)
* Added support for streaming in edge environments [#31852](https://github.com/facebook/react/pull/31852)
* Added support for sending custom error names from a server so that they are available in the client for console replaying. [#32116](https://github.com/facebook/react/pull/32116)
* Updated the server component wire format to remove IDs for hints and console.log because they have no return value [#31671](https://github.com/facebook/react/pull/31671)
* Exposed `registerServerReference` in client builds to handle server references in different environments. [#32534](https://github.com/facebook/react/pull/32534)
* Added react-server-dom-parcel package which integrates Server Components with the [Parcel bundler](https://parceljs.org/) [#31725](https://github.com/facebook/react/pull/31725), [#32132](https://github.com/facebook/react/pull/32132), [#31799](https://github.com/facebook/react/pull/31799), [#32294](https://github.com/facebook/react/pull/32294), [#31741](https://github.com/facebook/react/pull/31741)
## 19.0.0 (December 5, 2024)
Below is a list of all new features, APIs, deprecations, and breaking changes. Read [React 19 release post](https://react.dev/blog/2024/04/25/react-19) and [React 19 upgrade guide](https://react.dev/blog/2024/04/25/react-19-upgrade-guide) for more information.
> Note: To help make the upgrade to React 19 easier, we’ve published a react@18.3 release that is identical to 18.2 but adds warnings for deprecated APIs and other changes that are needed for React 19. We recommend upgrading to React 18.3.1 first to help identify any issues before upgrading to React 19.
### New Features
#### React
* Actions: `startTransition` can now accept async functions. Functions passed to `startTransition` are called “Actions”. A given Transition can include one or more Actions which update state in the background and update the UI with one commit. In addition to updating state, Actions can now perform side effects including async requests, and the Action will wait for the work to finish before finishing the Transition. This feature allows Transitions to include side effects like `fetch()` in the pending state, and provides support for error handling, and optimistic updates.
*`useActionState`: is a new hook to order Actions inside of a Transition with access to the state of the action, and the pending state. It accepts a reducer that can call Actions, and the initial state used for first render. It also accepts an optional string that is used if the action is passed to a form `action` prop to support progressive enhancement in forms.
*`useOptimistic`: is a new hook to update state while a Transition is in progress. It returns the state, and a set function that can be called inside a transition to “optimistically” update the state to expected final value immediately while the Transition completes in the background. When the transition finishes, the state is updated to the new value.
*`use`: is a new API that allows reading resources in render. In React 19, `use` accepts a promise or Context. If provided a promise, `use` will suspend until a value is resolved. `use` can only be used in render but can be called conditionally.
*`ref` as a prop: Refs can now be used as props, removing the need for `forwardRef`.
* **Suspense sibling pre-warming**: When a component suspends, React will immediately commit the fallback of the nearest Suspense boundary, without waiting for the entire sibling tree to render. After the fallback commits, React will schedule another render for the suspended siblings to “pre-warm” lazy requests.
#### React DOM Client
*`<form> action` prop: Form Actions allow you to manage forms automatically and integrate with `useFormStatus`. When a `<form> action` succeeds, React will automatically reset the form for uncontrolled components. The form can be reset manually with the new `requestFormReset` API.
*`<button> and <input> formAction` prop: Actions can be passed to the `formAction` prop to configure form submission behavior. This allows using different Actions depending on the input.
*`useFormStatus`: is a new hook that provides the status of the parent `<form> action`, as if the form was a Context provider. The hook returns the values: `pending`, `data`, `method`, and `action`.
* Support for Document Metadata: We’ve added support for rendering document metadata tags in components natively. React will automatically hoist them into the `<head>` section of the document.
* Support for Stylesheets: React 19 will ensure stylesheets are inserted into the `<head>` on the client before revealing the content of a Suspense boundary that depends on that stylesheet.
* Support for async scripts: Async scripts can be rendered anywhere in the component tree and React will handle ordering and deduplication.
* Support for preloading resources: React 19 ships with `preinit`, `preload`, `prefetchDNS`, and `preconnect` APIs to optimize initial page loads by moving discovery of additional resources like fonts out of stylesheet loading. They can also be used to prefetch resources used by an anticipated navigation.
#### React DOM Server
* Added `prerender` and `prerenderToNodeStream` APIs for static site generation. They are designed to work with streaming environments like Node.js Streams and Web Streams. Unlike `renderToString`, they wait for data to load for HTML generation.
#### React Server Components
* RSC features such as directives, server components, and server functions are now stable. This means libraries that ship with Server Components can now target React 19 as a peer dependency with a react-server export condition for use in frameworks that support the Full-stack React Architecture. The underlying APIs used to implement a React Server Components bundler or framework do not follow semver and may break between minors in React 19.x. See [docs](https://19.react.dev/reference/rsc/server-components) for how to support React Server Components.
### Deprecations
* Deprecated: `element.ref` access: React 19 supports ref as a prop, so we’re deprecating `element.ref` in favor of `element.props.ref`. Accessing will result in a warning.
*`react-test-renderer`: In React 19, react-test-renderer logs a deprecation warning and has switched to concurrent rendering for web usage. We recommend migrating your tests to [@testing-library/react](https://testing-library.com/docs/react-testing-library/intro/) or [@testing-library/react-native](https://testing-library.com/docs/react-native-testing-library/intro)
### Breaking Changes
React 19 brings in a number of breaking changes, including the removals of long-deprecated APIs. We recommend first upgrading to `18.3.1`, where we've added additional deprecation warnings. Check out the [upgrade guide](https://19.react.dev/blog/2024/04/25/react-19-upgrade-guide) for more details and guidance on codemodding.
### React
* New JSX Transform is now required: We introduced [a new JSX transform](https://legacy.reactjs.org/blog/2020/09/22/introducing-the-new-jsx-transform.html) in 2020 to improve bundle size and use JSX without importing React. In React 19, we’re adding additional improvements like using ref as a prop and JSX speed improvements that require the new transform.
* Errors in render are not re-thrown: Errors that are not caught by an Error Boundary are now reported to window.reportError. Errors that are caught by an Error Boundary are reported to console.error. We’ve introduced `onUncaughtError` and `onCaughtError` methods to `createRoot` and `hydrateRoot` to customize this error handling.
* Removed: `propTypes`: Using `propTypes` will now be silently ignored. If required, we recommend migrating to TypeScript or another type-checking solution.
* Removed: `defaultProps` for functions: ES6 default parameters can be used in place. Class components continue to support `defaultProps` since there is no ES6 alternative.
* Removed: `contextTypes` and `getChildContext`: Legacy Context for class components has been removed in favor of the `contextType` API.
* Removed: string refs: Any usage of string refs need to be migrated to ref callbacks.
* Removed: Module pattern factories: A rarely used pattern that can be migrated to regular functions.
* Removed: `React.createFactory`: Now that JSX is broadly supported, all `createFactory` usage can be migrated to JSX components.
* Removed: `react-test-renderer/shallow`: This has been a re-export of [react-shallow-renderer](https://github.com/enzymejs/react-shallow-renderer) since React 18\. If needed, you can continue to use the third-party package directly. We recommend using [@testing-library/react](https://testing-library.com/docs/react-testing-library/intro/) or [@testing-library/react-native](https://testing-library.com/docs/react-native-testing-library/intro) instead.
#### React DOM
* Removed: `react-dom/test-utils`: We’ve moved `act` from `react-dom/test-utils` to react. All other utilities have been removed.
* Removed: `ReactDOM`.`render`, `ReactDOM`.`hydrate`: These have been removed in favor of the concurrent equivalents: `ReactDOM`.`createRoot` and `ReactDOM.hydrateRoot`.
* Removed: `unmountComponentAtNode`: Removed in favor of `root.unmount()`.
* Removed: `ReactDOM`.`findDOMNode`: You can replace `ReactDOM`.`findDOMNode` with DOM Refs.
### Notable Changes
#### React
*`<Context>` as a provider: You can now render `<Context>` as a provider instead of `<Context.Provider>`.
* Cleanup functions for refs: When the component unmounts, React will call the cleanup function returned from the ref callback.
*`useDeferredValue` initial value argument: When provided, `useDeferredValue` will return the initial value for the initial render of a component, then schedule a re-render in the background with the `deferredValue` returned.
* Support for Custom Elements: React 19 now passes all tests on [Custom Elements Everywhere](https://custom-elements-everywhere.com/).
* StrictMode changes: `useMemo` and `useCallback` will now reuse the memoized results from the first render, during the second render. Additionally, StrictMode will now double-invoke ref callback functions on initial mount.
* UMD builds removed: To load React 19 with a script tag, we recommend using an ESM-based CDN such as [esm.sh](http://esm.sh).
#### React DOM
* Diffs for hydration errors: In the case of a mismatch, React 19 logs a single error with a diff of the mismatched content.
* Compatibility with third-party scripts and extensions: React will now force a client re-render to fix up any mismatched content caused by elements inserted by third-party JS.
### TypeScript Changes
The most common changes can be codemodded with `npx types-react-codemod@latest preset-19 ./path-to-your-react-ts-files`.
* Removed deprecated TypeScript types:
*`ReactChild` (replacement: `React.ReactElement | number | string)`
* Moved to `prop-types`: `Requireable`, `ValidationMap`, `Validator`, `WeakValidationMap`
* Moved to `create-react-class`: `ClassicComponentClass`, `ClassicComponent`, `ClassicElement`, `ComponentSpec`, `Mixin`, `ReactChildren`, `ReactHTML`, `ReactSVG`, `SFCFactory`
* Disallow implicit return in refs: refs can now accept cleanup functions. When you return something else, we can’t tell if you intentionally returned something not meant to clean up or returned the wrong value. Implicit returns of anything but functions will now error.
* Require initial argument to `useRef`: The initial argument is now required to match `useState`, `createContext` etc
* Refs are mutable by default: Ref objects returned from `useRef()` are now always mutable instead of sometimes being immutable. This feature was too confusing for users and conflicted with legit cases where refs were managed by React and manually written to.
* Strict `ReactElement` typing: The props of React elements now default to `unknown` instead of `any` if the element is typed as `ReactElement`
* JSX namespace in TypeScript: The global `JSX` namespace is removed to improve interoperability with other libraries using JSX. Instead, the JSX namespace is available from the React package: `import { JSX } from 'react'`
* Better `useReducer` typings: Most `useReducer` usage should not require explicit type arguments.
* Add support for async Actions ([\#26621](https://github.com/facebook/react/pull/26621), [\#26726](https://github.com/facebook/react/pull/26726), [\#28078](https://github.com/facebook/react/pull/28078), [\#28097](https://github.com/facebook/react/pull/28097), [\#29226](https://github.com/facebook/react/pull/29226), [\#29618](https://github.com/facebook/react/pull/29618), [\#29670](https://github.com/facebook/react/pull/29670), [\#26716](https://github.com/facebook/react/pull/26716) by [@acdlite](https://github.com/acdlite) and [@sebmarkbage](https://github.com/sebmarkbage))
* Add `useActionState()` hook to update state based on the result of a Form Action ([\#27270](https://github.com/facebook/react/pull/27270), [\#27278](https://github.com/facebook/react/pull/27278), [\#27309](https://github.com/facebook/react/pull/27309), [\#27302](https://github.com/facebook/react/pull/27302), [\#27307](https://github.com/facebook/react/pull/27307), [\#27366](https://github.com/facebook/react/pull/27366), [\#27370](https://github.com/facebook/react/pull/27370), [\#27321](https://github.com/facebook/react/pull/27321), [\#27374](https://github.com/facebook/react/pull/27374), [\#27372](https://github.com/facebook/react/pull/27372), [\#27397](https://github.com/facebook/react/pull/27397), [\#27399](https://github.com/facebook/react/pull/27399), [\#27460](https://github.com/facebook/react/pull/27460), [\#28557](https://github.com/facebook/react/pull/28557), [\#27570](https://github.com/facebook/react/pull/27570), [\#27571](https://github.com/facebook/react/pull/27571), [\#28631](https://github.com/facebook/react/pull/28631), [\#28788](https://github.com/facebook/react/pull/28788), [\#29694](https://github.com/facebook/react/pull/29694), [\#29695](https://github.com/facebook/react/pull/29695), [\#29694](https://github.com/facebook/react/pull/29694), [\#29665](https://github.com/facebook/react/pull/29665), [\#28232](https://github.com/facebook/react/pull/28232), [\#28319](https://github.com/facebook/react/pull/28319) by [@acdlite](https://github.com/acdlite), [@eps1lon](https://github.com/eps1lon), and [@rickhanlonii](https://github.com/rickhanlonii))
* Add `use()` API to read resources in render ([\#25084](https://github.com/facebook/react/pull/25084), [\#25202](https://github.com/facebook/react/pull/25202), [\#25207](https://github.com/facebook/react/pull/25207), [\#25214](https://github.com/facebook/react/pull/25214), [\#25226](https://github.com/facebook/react/pull/25226), [\#25247](https://github.com/facebook/react/pull/25247), [\#25539](https://github.com/facebook/react/pull/25539), [\#25538](https://github.com/facebook/react/pull/25538), [\#25537](https://github.com/facebook/react/pull/25537), [\#25543](https://github.com/facebook/react/pull/25543), [\#25561](https://github.com/facebook/react/pull/25561), [\#25620](https://github.com/facebook/react/pull/25620), [\#25615](https://github.com/facebook/react/pull/25615), [\#25922](https://github.com/facebook/react/pull/25922), [\#25641](https://github.com/facebook/react/pull/25641), [\#25634](https://github.com/facebook/react/pull/25634), [\#26232](https://github.com/facebook/react/pull/26232), [\#26536](https://github.com/facebook/react/pull/26535), [\#26739](https://github.com/facebook/react/pull/26739), [\#28233](https://github.com/facebook/react/pull/28233) by [@acdlite](https://github.com/acdlite), [@MofeiZ](https://github.com/mofeiZ), [@sebmarkbage](https://github.com/sebmarkbage), [@sophiebits](https://github.com/sophiebits), [@eps1lon](https://github.com/eps1lon), and [@hansottowirtz](https://github.com/hansottowirtz))
* Add `useOptimistic()` hook to display mutated state optimistically during an async mutation ([\#26740](https://github.com/facebook/react/pull/26740), [\#26772](https://github.com/facebook/react/pull/26772), [\#27277](https://github.com/facebook/react/pull/27277), [\#27453](https://github.com/facebook/react/pull/27453), [\#27454](https://github.com/facebook/react/pull/27454), [\#27936](https://github.com/facebook/react/pull/27936) by [@acdlite](https://github.com/acdlite))
* Added an `initialValue` argument to `useDeferredValue()` hook ([\#27500](https://github.com/facebook/react/pull/27500), [\#27509](https://github.com/facebook/react/pull/27509), [\#27512](https://github.com/facebook/react/pull/27512), [\#27888](https://github.com/facebook/react/pull/27888), [\#27550](https://github.com/facebook/react/pull/27550) by [@acdlite](https://github.com/acdlite))
* Support refs as props, warn on `element.ref` access ([\#28348](https://github.com/facebook/react/pull/28348), [\#28464](https://github.com/facebook/react/pull/28464), [\#28731](https://github.com/facebook/react/pull/28731) by [@acdlite](https://github.com/acdlite))
* Support Custom Elements ([\#22184](https://github.com/facebook/react/pull/22184), [\#26524](https://github.com/facebook/react/pull/26524), [\#26523](https://github.com/facebook/react/pull/26523), [\#27511](https://github.com/facebook/react/pull/27511), [\#24541](https://github.com/facebook/react/pull/24541) by [@josepharhar](https://github.com/josepharhar), [@sebmarkbage](https://github.com/sebmarkbage), [@gnoff](https://github.com/gnoff) and [@eps1lon](https://github.com/eps1lon))
* Add ref cleanup function ([\#25686](https://github.com/facebook/react/pull/25686), [\#28883](https://github.com/facebook/react/pull/28883), [\#28910](https://github.com/facebook/react/pull/28910) by [@sammy-SC](https://github.com/sammy-SC), [@jackpope](https://github.com/jackpope), and [@kassens](https://github.com/kassens))
* Don’t rethrow errors at the root ([\#28627](https://github.com/facebook/react/pull/28627), [\#28641](https://github.com/facebook/react/pull/28641) by [@sebmarkbage](https://github.com/sebmarkbage))
* Batch sync discrete, continuous, and default lanes ([\#25700](https://github.com/facebook/react/pull/25700) by [@tyao1](https://github.com/tyao1))
* Switch `<Context>` to mean `<Context.Provider>` ([\#28226](https://github.com/facebook/react/pull/28226) by [@gaearon](https://github.com/gaearon))
* Changes to *StrictMode*
* Handle `info`, `group`, and `groupCollapsed` in *StrictMode* logging ([\#25172](https://github.com/facebook/react/pull/25172) by [@timneutkens](https://github.com/timneutkens))
* Refs are now attached/detached/attached in *StrictMode* ([\#25049](https://github.com/facebook/react/pull/25049) by [@sammy-SC](https://github.com/sammy-SC))
* Fix `useSyncExternalStore()` hydration in *StrictMode* ([\#26791](https://github.com/facebook/react/pull/26791) by [@sophiebits](https://github.com/sophiebits))
* Always trigger `componentWillUnmount()` in *StrictMode* ([\#26842](https://github.com/facebook/react/pull/26842) by [@tyao1](https://github.com/tyao1))
* Restore double invoking `useState()` and `useReducer()` initializer functions in *StrictMode* ([\#28248](https://github.com/facebook/react/pull/28248) by [@eps1lon](https://github.com/eps1lon))
* Reuse memoized result from first pass ([\#25583](https://github.com/facebook/react/pull/25583) by [@acdlite](https://github.com/acdlite))
* Fix `useId()` in *StrictMode* ([\#25713](https://github.com/facebook/react/pull/25713) by [@gnoff](https://github.com/gnoff))
* Add component name to *StrictMode* error messages ([\#25718](https://github.com/facebook/react/pull/25718) by [@sammy-SC](https://github.com/sammy-SC))
* Add support for rendering BigInt ([\#24580](https://github.com/facebook/react/pull/24580) by [@eps1lon](https://github.com/eps1lon))
* `act()` no longer checks `shouldYield` which can be inaccurate in test environments ([\#26317](https://github.com/facebook/react/pull/26317) by [@acdlite](https://github.com/acdlite))
* Warn when keys are spread with props ([\#25697](https://github.com/facebook/react/pull/25697), [\#26080](https://github.com/facebook/react/pull/26080) by [@sebmarkbage](https://github.com/sebmarkbage) and [@kassens](https://github.com/kassens))
* Generate sourcemaps for production build artifacts ([\#26446](https://github.com/facebook/react/pull/26446) by [@markerikson](https://github.com/markerikson))
* Improve stack diffing algorithm ([\#27132](https://github.com/facebook/react/pull/27132) by [@KarimP](https://github.com/KarimP))
* Suspense throttling lowered from 500ms to 300ms ([\#26803](https://github.com/facebook/react/pull/26803) by [@acdlite](https://github.com/acdlite))
* Lazily propagate context changes ([\#20890](https://github.com/facebook/react/pull/20890) by [@acdlite](https://github.com/acdlite) and [@gnoff](https://github.com/gnoff))
* Immediately rerender pinged fiber ([\#25074](https://github.com/facebook/react/pull/25074) by [@acdlite](https://github.com/acdlite))
* Move update scheduling to microtask ([\#26512](https://github.com/facebook/react/pull/26512) by [@acdlite](https://github.com/acdlite))
* Consistently apply throttled retries ([\#26611](https://github.com/facebook/react/pull/26611), [\#26802](https://github.com/facebook/react/pull/26802) by [@acdlite](https://github.com/acdlite))
* Suspend Thenable/Lazy if it's used in React.Children ([\#28284](https://github.com/facebook/react/pull/28284) by [@sebmarkbage](https://github.com/sebmarkbage))
* Detect infinite update loops caused by render phase updates ([\#26625](https://github.com/facebook/react/pull/26625) by [@acdlite](https://github.com/acdlite))
* Update conditional hooks warning ([\#29626](https://github.com/facebook/react/pull/29626) by [@sophiebits](https://github.com/sophiebits))
* Update error URLs to go to new docs ([\#27240](https://github.com/facebook/react/pull/27240) by [@rickhanlonii](https://github.com/rickhanlonii))
* Rename the `react.element` symbol to `react.transitional.element` ([\#28813](https://github.com/facebook/react/pull/28813) by [@sebmarkbage](https://github.com/sebmarkbage))
* Fix crash when suspending in shell during `useSyncExternalStore()` re-render ([\#27199](https://github.com/facebook/react/pull/27199) by [@acdlite](https://github.com/acdlite))
* Fix incorrect “detected multiple renderers" error in tests ([\#22797](https://github.com/facebook/react/pull/22797) by [@eps1lon](https://github.com/eps1lon))
* Fix bug where effect cleanup may be called twice after bailout ([\#26561](https://github.com/facebook/react/pull/26561) by [@acdlite](https://github.com/acdlite))
* Fix suspending in shell during discrete update ([\#25495](https://github.com/facebook/react/pull/25495) by [@acdlite](https://github.com/acdlite))
* Fix memory leak after repeated setState bailouts ([\#25309](https://github.com/facebook/react/pull/25309) by [@acdlite](https://github.com/acdlite))
* Fix `useSyncExternalStore()` dropped update when state is dispatched in render phase ([\#25578](https://github.com/facebook/react/pull/25578) by [@pandaiolo](https://github.com/pandaiolo))
* Fix logging when rendering a lazy fragment ([\#30372](https://github.com/facebook/react/pull/30372) by [@tom-sherman](https://github.com/tom-sherman))
* Remove string refs ([\#25383](https://github.com/facebook/react/pull/25383), [\#28322](https://github.com/facebook/react/pull/28322) by [@eps1lon](https://github.com/eps1lon) and [@acdlite](https://github.com/acdlite))
* Remove Legacy Context (\#30319 by [@kassens](https://github.com/kassens))
* Remove `RefreshRuntime.findAffectedHostInstances` ([\#30538](https://github.com/facebook/react/pull/30538) by [@gaearon](https://github.com/gaearon))
* Remove client caching from `cache()` API ([\#27977](https://github.com/facebook/react/pull/27977), [\#28250](https://github.com/facebook/react/pull/28250) by [@acdlite](https://github.com/acdlite) and [@gnoff](https://github.com/gnoff))
* Remove `propTypes` ([\#28324](https://github.com/facebook/react/pull/28324), [\#28326](https://github.com/facebook/react/pull/28326) by [@gaearon](https://github.com/gaearon))
* Remove `defaultProps` support, except for classes ([\#28733](https://github.com/facebook/react/pull/28733) by [@acdlite](https://github.com/acdlite))
* Remove UMD builds ([\#28735](https://github.com/facebook/react/pull/28735) by [@gnoff](https://github.com/gnoff))
* Remove delay for non-transition updates ([\#26597](https://github.com/facebook/react/pull/26597) by [@acdlite](https://github.com/acdlite))
* Remove `createFactory` ([\#27798](https://github.com/facebook/react/pull/27798) by [@kassens](https://github.com/kassens))
#### React DOM
* Adds Form Actions to handle form submission ([\#26379](https://github.com/facebook/react/pull/26379), [\#26674](https://github.com/facebook/react/pull/26674), [\#26689](https://github.com/facebook/react/pull/26689), [\#26708](https://github.com/facebook/react/pull/26708), [\#26714](https://github.com/facebook/react/pull/26714), [\#26735](https://github.com/facebook/react/pull/26735), [\#26846](https://github.com/facebook/react/pull/26846), [\#27358](https://github.com/facebook/react/pull/27358), [\#28056](https://github.com/facebook/react/pull/28056) by [@sebmarkbage](https://github.com/sebmarkbage), [@acdlite](https://github.com/acdlite), and [@jupapios](https://github.com/jupapios))
* Add `useFormStatus()` hook to provide status information of the last form submission ([\#26719](https://github.com/facebook/react/pull/26719), [\#26722](https://github.com/facebook/react/pull/26722), [\#26788](https://github.com/facebook/react/pull/26788), [\#29019](https://github.com/facebook/react/pull/29019), [\#28728](https://github.com/facebook/react/pull/28728), [\#28413](https://github.com/facebook/react/pull/28413) by [@acdlite](https://github.com/acdlite) and [@eps1lon](https://github.com/eps1lon))
* Support for Document Metadata. Adds `preinit`, `preinitModule`, `preconnect`, `prefetchDNS`, `preload`, and `preloadModule` APIs.
* Add `fetchPriority` to `<img>` and `<link>` ([\#25927](https://github.com/facebook/react/pull/25927) by [@styfle](https://github.com/styfle))
* Add support for SVG `transformOrigin` prop ([\#26130](https://github.com/facebook/react/pull/26130) by [@arav-ind](https://github.com/arav-ind))
* Add support for `onScrollEnd` event ([\#26789](https://github.com/facebook/react/pull/26789) by [@devongovett](https://github.com/devongovett))
* Allow `<hr>` as child of `<select>` ([\#27632](https://github.com/facebook/react/pull/27632) by [@SouSingh](https://github.com/SouSingh))
* Add support for Popover API ([\#27981](https://github.com/facebook/react/pull/27981) by [@eps1lon](https://github.com/eps1lon))
* Add support for `inert` ([\#24730](https://github.com/facebook/react/pull/24730) by [@eps1lon](https://github.com/eps1lon))
* Add support for `imageSizes` and `imageSrcSet` ([\#22550](https://github.com/facebook/react/pull/22550) by [@eps1lon](https://github.com/eps1lon))
* Synchronously flush transitions in popstate events ([\#26025](https://github.com/facebook/react/pull/26025), [\#27559](https://github.com/facebook/react/pull/27559), [\#27505](https://github.com/facebook/react/pull/27505), [\#30759](https://github.com/facebook/react/pull/30759) by [@tyao1](https://github.com/tyao1) and [@acdlite](https://github.com/acdlite))
* `flushSync` exhausts queue even if something throws ([\#26366](https://github.com/facebook/react/pull/26366) by [@acdlite](https://github.com/acdlite))
* Throw error if `react` and `react-dom` versions don’t match ([\#29236](https://github.com/facebook/react/pull/29236) by [@acdlite](https://github.com/acdlite))
* Ensure `srcset` and `src` are assigned last on `<img>` instances ([\#30340](https://github.com/facebook/react/pull/30340) by [@gnoff](https://github.com/gnoff))
* Javascript URLs are replaced with functions that throw errors ([\#26507](https://github.com/facebook/react/pull/26507), [\#29808](https://github.com/facebook/react/pull/29808) by [@sebmarkbage](https://github.com/sebmarkbage) and [@kassens](https://github.com/kassens))
* Treat toggle and beforetoggle as discrete events ([\#29176](https://github.com/facebook/react/pull/29176) by [@eps1lon](https://github.com/eps1lon))
* Filter out empty `src` and `href` attributes (unless for `<a href=”” />`) ([\#18513](https://github.com/facebook/react/pull/18513), [\#28124](https://github.com/facebook/react/pull/28124) by [@bvaughn](https://github.com/bvaughn) and [@eps1lon](https://github.com/eps1lon))
* Fix unitless `scale` style property ([\#25601](https://github.com/facebook/react/pull/25601) by [@JonnyBurger](https://github.com/JonnyBurger))
* Fix `onChange` error message for controlled `<select>` ([\#27740](https://github.com/facebook/react/pull/27740) by [@Biki-das](https://github.com/Biki-das))
* Fix focus restore in child windows after element reorder ([\#30951](https://github.com/facebook/react/pull/30951) by [@ling1726](https://github.com/ling1726))
* Remove `render`, `hydrate`, `findDOMNode`, `unmountComponentAtNode`, `unstable_createEventHandle`, `unstable_renderSubtreeIntoContainer`, and `unstable_runWithPriority`. Move `createRoot` and `hydrateRoot` to `react-dom/client`. ([\#28271](https://github.com/facebook/react/pull/28271) by [@gnoff](https://github.com/gnoff))
* Remove `test-utils` ([\#28541](https://github.com/facebook/react/pull/28541) by [@eps1lon](https://github.com/eps1lon))
* Remove `unstable_flushControlled` ([\#26397](https://github.com/facebook/react/pull/26397) by [@kassens](https://github.com/kassens))
* Remove legacy mode ([\#28468](https://github.com/facebook/react/pull/28468) by [@gnoff](https://github.com/gnoff))
* Remove `renderToStaticNodeStream()` ([\#28873](https://github.com/facebook/react/pull/28873) by @gnoff)
* Remove `unstable_renderSubtreeIntoContainer` ([\#29771](https://github.com/facebook/react/pull/29771) by [@kassens](https://github.com/kassens))
#### React DOM Server
* Stable release of React Server Components ([Many, many PRs](https://github.com/facebook/react/pulls?q=is%3Apr+is%3Aclosed+%5BFlight%5D+in%3Atitle+created%3A%3C2024-12-01+) by [@sebmarkbage](https://github.com/sebmarkbage), [@acdlite](https://github.com/acdlite), [@gnoff](https://github.com/gnoff), [@sammy-SC](https://github.com/sammy-SC), [@gaearon](https://github.com/gaearon), [@sophiebits](https://github.com/sophiebits), [@unstubbable](https://github.com/unstubbable), [@lubieowoce](https://github.com/lubieowoce))
* Support Server Actions ([\#26124](https://github.com/facebook/react/pull/26124), [\#26632](https://github.com/facebook/react/pull/26632), [\#27459](https://github.com/facebook/react/pull/27459) by [@sebmarkbage](https://github.com/sebmarkbage) and [@acdlite](https://github.com/acdlite))
* Changes to SSR
* Add external runtime which bootstraps hydration on the client for binary transparency ([\#25437](https://github.com/facebook/react/pull/25437), [\#26169](https://github.com/facebook/react/pull/26169), [\#25499](https://github.com/facebook/react/pull/25499) by [@MofeiZ](https://github.com/mofeiZ) and [@acdlite](https://github.com/acdlite))
* Support subresource integrity for `bootstrapScripts` and `bootstrapModules` ([\#25104](https://github.com/facebook/react/pull/25104) by [@gnoff](https://github.com/gnoff))
* Fix null bytes written at text chunk boundaries ([\#26228](https://github.com/facebook/react/pull/26228) by [@sophiebits](https://github.com/sophiebits))
* Fix logic around attribute serialization ([\#26526](https://github.com/facebook/react/pull/26526) by [@gnoff](https://github.com/gnoff))
* Fix precomputed chunk cleared on Node 18 ([\#25645](https://github.com/facebook/react/pull/25645) by [@feedthejim](https://github.com/feedthejim))
* Optimize end tag chunks ([\#27522](https://github.com/facebook/react/pull/27522) by [@yujunjung](https://github.com/yujunjung))
* Gracefully handle suspending in DOM configs ([\#26768](https://github.com/facebook/react/pull/26768) by [@sebmarkbage](https://github.com/sebmarkbage))
* Check for nullish values on ReactCustomFormAction ([\#26770](https://github.com/facebook/react/pull/26770) by [@sebmarkbage](https://github.com/sebmarkbage))
* Preload `bootstrapModules`, `bootstrapScripts`, and update priority queue ([\#26754](https://github.com/facebook/react/pull/26754), [\#26753](https://github.com/facebook/react/pull/26753), [\#27190](https://github.com/facebook/react/pull/27190), [\#27189](https://github.com/facebook/react/pull/27189) by [@gnoff](https://github.com/gnoff))
* Client render the nearest child or parent suspense boundary if replay errors or is aborted ([\#27386](https://github.com/facebook/react/pull/27386) by [@sebmarkbage](https://github.com/sebmarkbage))
* Don't bail out of flushing if we still have pending root tasks ([\#27385](https://github.com/facebook/react/pull/27385) by [@sebmarkbage](https://github.com/sebmarkbage))
* Ensure Resumable State is Serializable ([\#27388](https://github.com/facebook/react/pull/27388) by [@sebmarkbage](https://github.com/sebmarkbage))
* Remove extra render pass when reverting to client render ([\#26445](https://github.com/facebook/react/pull/26445) by [@acdlite](https://github.com/acdlite))
* Fix unwinding context during selective hydration ([\#25876](https://github.com/facebook/react/pull/25876) by [@tyao1](https://github.com/tyao1))
* Stop flowing and then abort if a stream is cancelled ([\#27405](https://github.com/facebook/react/pull/27405) by [@sebmarkbage](https://github.com/sebmarkbage))
* Pass cancellation reason to abort ([\#27536](https://github.com/facebook/react/pull/27536) by [@sebmarkbage](https://github.com/sebmarkbage))
* Add `onHeaders` entrypoint option ([\#27641](https://github.com/facebook/react/pull/27641), [\#27712](https://github.com/facebook/react/pull/27712) by [@gnoff](https://github.com/gnoff))
* Escape `<style>` and `<script>` textContent to enable rendering inner content without dangerouslySetInnerHTML ([\#28870](https://github.com/facebook/react/pull/28870), [\#28871](https://github.com/facebook/react/pull/28871) by [@gnoff](https://github.com/gnoff))
* Fallback to client replaying actions for Blob serialization ([\#28987](https://github.com/facebook/react/pull/28987) by [@sebmarkbage](https://github.com/sebmarkbage))
* Render Suspense fallback if boundary contains new stylesheet during sync update ([\#28965](https://github.com/facebook/react/pull/28965) by [@gnoff](https://github.com/gnoff))
* Fix header length tracking (\#30327 by [@gnoff](https://github.com/gnoff))
* Use `srcset` to trigger load event on mount (\#30351 by [@gnoff](https://github.com/gnoff))
* Don't perform work when closing stream (\#30497 by [@gnoff](https://github.com/gnoff))
* Allow aborting during render (\#30488, [\#30730](https://github.com/facebook/react/pull/30730) by [@gnoff](https://github.com/gnoff))
* Start initial work immediately (\#31079 by [@gnoff](https://github.com/gnoff))
* A transition flowing into a dehydrated boundary no longer suspends when showing fallback ([\#27230](https://github.com/facebook/react/pull/27230) by [@acdlite](https://github.com/acdlite))
* Warn for Child Iterator of all types but allow Generator Components ([\#28853](https://github.com/facebook/react/pull/28853) by [@sebmarkbage](https://github.com/sebmarkbage))
* Include regular stack trace in serialized errors ([\#28684](https://github.com/facebook/react/pull/28684), [\#28738](https://github.com/facebook/react/pull/28738) by [@sebmarkbage](https://github.com/sebmarkbage))
* Aborting early no longer infinitely suspends ([\#24751](https://github.com/facebook/react/pull/24751) by [@sebmarkbage](https://github.com/sebmarkbage))
* Fix hydration warning suppression in text comparisons ([\#24784](https://github.com/facebook/react/pull/24784) by [@gnoff](https://github.com/gnoff))
* Changes to error handling in SSR
* Add diffs to hydration warnings ([\#28502](https://github.com/facebook/react/pull/28502), [\#28512](https://github.com/facebook/react/pull/28512) by [@sebmarkbage](https://github.com/sebmarkbage))
* Make Error creation lazy ([\#24728](https://github.com/facebook/react/pull/24728) by [@sebmarkbage](https://github.com/sebmarkbage))
* Remove recoverable error when a sync update flows into a dehydrated boundary ([\#25692](https://github.com/facebook/react/pull/25692) by [@sebmarkbage](https://github.com/sebmarkbage))
* Don't "fix up" mismatched text content with suppressedHydrationWarning ([\#26391](https://github.com/facebook/react/pull/26391) by [@sebmarkbage](https://github.com/sebmarkbage))
* Fix component stacks in errors ([\#27456](https://github.com/facebook/react/pull/27456) by [@sebmarkbage](https://github.com/sebmarkbage))
* Add component stacks to `onError` ([\#27761](https://github.com/facebook/react/pull/27761), [\#27850](https://github.com/facebook/react/pull/27850) by [@gnoff](https://github.com/gnoff) and [@sebmarkbage](https://github.com/sebmarkbage))
* Throw hydration mismatch errors once ([\#28502](https://github.com/facebook/react/pull/28502) by [@sebmarkbage](https://github.com/sebmarkbage))
* Add Bun streaming server renderer ([\#25597](https://github.com/facebook/react/pull/25597) by [@colinhacks](https://github.com/colinhacks))
* Add nonce support to bootstrap scripts ([\#26738](https://github.com/facebook/react/pull/26738) by [@danieltott](https://github.com/danieltott))
* Add `crossorigin` support to bootstrap scripts ([\#26844](https://github.com/facebook/react/pull/26844) by [@HenriqueLimas](https://github.com/HenriqueLimas))
* Support `nonce` and `fetchpriority` in preload links ([\#26826](https://github.com/facebook/react/pull/26826) by [@liuyenwei](https://github.com/liuyenwei))
* Add `referrerPolicy` to `ReactDOM.preload()` ([\#27096](https://github.com/facebook/react/pull/27096) by [@styfle](https://github.com/styfle))
* Add server condition for `react/jsx-dev-runtime` ([\#28921](https://github.com/facebook/react/pull/28921) by [@himself65](https://github.com/himself65))
* Export version ([\#29596](https://github.com/facebook/react/pull/29596) by [@unstubbable](https://github.com/unstubbable))
* Rename the secret export of Client and Server internals ([\#28786](https://github.com/facebook/react/pull/28786), [\#28789](https://github.com/facebook/react/pull/28789) by [@sebmarkbage](https://github.com/sebmarkbage))
* Remove layout effect warning on server ([\#26395](https://github.com/facebook/react/pull/26395) by [@rickhanlonii](https://github.com/rickhanlonii))
* Remove `errorInfo.digest` from `onRecoverableError` ([\#28222](https://github.com/facebook/react/pull/28222) by [@gnoff](https://github.com/gnoff))
#### ReactTestRenderer
* Add deprecation error to `react-test-renderer` on web ([\#27903](https://github.com/facebook/react/pull/27903), [\#28904](https://github.com/facebook/react/pull/28904) by [@jackpope](https://github.com/jackpope) and [@acdlite](https://github.com/acdlite))
* Render with ConcurrentRoot on web ([\#28498](https://github.com/facebook/react/pull/28498) by [@jackpope](https://github.com/jackpope))
* Remove `react-test-renderer/shallow` export ([\#25475](https://github.com/facebook/react/pull/25475), [\#28497](https://github.com/facebook/react/pull/28497) by [@sebmarkbage](https://github.com/sebmarkbage) and [@jackpope](https://github.com/jackpope))
#### React Reconciler
* Enable suspending commits without blocking render ([\#26398](https://github.com/facebook/react/pull/26398), [\#26427](https://github.com/facebook/react/pull/26427) by [@acdlite](https://github.com/acdlite))
* Remove `prepareUpdate` ([\#26583](https://github.com/facebook/react/pull/26583), [\#27409](http://github.com/facebook/react/pull/27409) by [@sebmarkbage](https://github.com/sebmarkbage) and [@sophiebits](https://github.com/sophiebits))
#### React-Is
* Enable tree shaking ([\#27701](https://github.com/facebook/react/pull/27701) by [@markerikson](https://github.com/markerikson))
* Remove `isConcurrentMode` and `isAsyncMode` methods ([\#28224](https://github.com/facebook/react/pull/28224) by @gaearon)
#### useSyncExternalStore
* Remove React internals access ([\#29868](https://github.com/facebook/react/pull/29868) by [@phryneas](https://github.com/phryneas))
* Fix stale selectors keeping previous store references ([\#25969](https://github.com/facebook/react/pull/25968) by [@jellevoost](https://github.com/jellevoost))
## 18.3.1 (April 26, 2024)
- Export `act` from `react` [f1338f](https://github.com/facebook/react/commit/f1338f8080abd1386454a10bbf93d67bfe37ce85)
## 18.3.0 (April 25, 2024)
This release is identical to 18.2 but adds warnings for deprecated APIs and other changes that are needed for React 19.
Read the [React 19 Upgrade Guide](https://react.dev/blog/2024/04/25/react-19-upgrade-guide) for more info.
### React
- Allow writing to `this.refs` to support string ref codemod [909071](https://github.com/facebook/react/commit/9090712fd3ca4e1099e1f92e67933c2cb4f32552)
- Warn for deprecated `findDOMNode` outside StrictMode [c3b283](https://github.com/facebook/react/commit/c3b283964108b0e8dbcf1f9eb2e7e67815e39dfb)
- Warn for deprecated `test-utils` methods [d4ea75](https://github.com/facebook/react/commit/d4ea75dc4258095593b6ac764289f42bddeb835c)
- Warn for deprecated Legacy Context outside StrictMode [415ee0](https://github.com/facebook/react/commit/415ee0e6ea0fe3e288e65868df2e3241143d5f7f)
- Warn for deprecated string refs outside StrictMode [#25383](https://github.com/facebook/react/pull/25383)
- Warn for deprecated `defaultProps` for function components [#25699](https://github.com/facebook/react/pull/25699)
- Warn when spreading `key` [#25697](https://github.com/facebook/react/pull/25697)
- Warn when using `act` from `test-utils` [d4ea75](https://github.com/facebook/react/commit/d4ea75dc4258095593b6ac764289f42bddeb835c)
### React DOM
- Warn for deprecated `unmountComponentAtNode` [8a015b](https://github.com/facebook/react/commit/8a015b68cc060079878e426610e64e86fb328f8d)
- Warn for deprecated `renderToStaticNodeStream` [#28874](https://github.com/facebook/react/pull/28874)
## 18.2.0 (June 14, 2022)
### React DOM
@@ -17,7 +361,7 @@
### Server Components (Experimental)
* Add support for `useId()` inside Server Components. ([@gnoff](https://github.com/gnoff)) in [#24172](https://github.com/facebook/react/pull/24172)
* Add support for `useId()` inside Server Components. ([@gnoff](https://github.com/gnoff) in [#24172](https://github.com/facebook/react/pull/24172))
## 18.1.0 (April 26, 2022)
@@ -102,6 +446,10 @@ The existing `renderToString` method keeps working but is discouraged.
* **Layout Effects with Suspense**: When a tree re-suspends and reverts to a fallback, React will now clean up layout effects, and then re-create them when the content inside the boundary is shown again. This fixes an issue which prevented component libraries from correctly measuring layout when used with Suspense.
* **New JS Environment Requirements**: React now depends on modern browsers features including `Promise`, `Symbol`, and `Object.assign`. If you support older browsers and devices such as Internet Explorer which do not provide modern browser features natively or have non-compliant implementations, consider including a global polyfill in your bundled application.
### Scheduler (Experimental)
* Remove unstable `scheduler/tracing` API
## Notable Changes
### React
@@ -193,6 +541,10 @@ The existing `renderToString` method keeps working but is discouraged.
* Fix a mistake in the Node loader. ([#22537](https://github.com/facebook/react/pull/22537) by [@btea](https://github.com/btea))
* Use `globalThis` instead of `window` for edge environments. ([#22777](https://github.com/facebook/react/pull/22777) by [@huozhi](https://github.com/huozhi))
### Scheduler (Experimental)
* Remove unstable `scheduler/tracing` API ([#20037](https://github.com/facebook/react/pull/20037) by [@bvaughn](https://github.com/bvaughn))
React is a JavaScript library for building user interfaces.
* **Declarative:** React makes it painless to create interactive UIs. Design simple views for each state in your application, and React will efficiently update and render just the right components when your data changes. Declarative views make your code more predictable, simpler to understand, and easier to debug.
* **Component-Based:** Build encapsulated components that manage their own state, then compose them to make complex UIs. Since component logic is written in JavaScript instead of templates, you can easily pass rich data through your app and keep the state out of the DOM.
* **Learn Once, Write Anywhere:** We don't make assumptions about the rest of your technology stack, so you can develop new features in React without rewriting existing code. React can also render on the server using Node and power mobile apps using [React Native](https://reactnative.dev/).
* **Learn Once, Write Anywhere:** We don't make assumptions about the rest of your technology stack, so you can develop new features in React without rewriting existing code. React can also render on the server using [Node](https://nodejs.org/en) and power mobile apps using [React Native](https://reactnative.dev/).
[Learn how to use React in your project](https://reactjs.org/docs/getting-started.html).
[Learn how to use React in your project](https://react.dev/learn).
## Installation
React has been designed for gradual adoption from the start, and **you can use as little or as much React as you need**:
* Use [Online Playgrounds](https://reactjs.org/docs/getting-started.html#online-playgrounds) to get a taste of React.
* [Add React to a Website](https://reactjs.org/docs/add-react-to-a-website.html) as a `<script>` tag in one minute.
* [Create a New React App](https://reactjs.org/docs/create-a-new-react-app.html) if you're looking for a powerful JavaScript toolchain.
You can use React as a `<script>` tag from a [CDN](https://reactjs.org/docs/cdn-links.html), or as a `react` package on [npm](https://www.npmjs.com/package/react).
* Use [Quick Start](https://react.dev/learn) to get a taste of React.
* [Add React to an Existing Project](https://react.dev/learn/add-react-to-an-existing-project) to use as little or as much React as you need.
* [Create a New React App](https://react.dev/learn/start-a-new-react-project) if you're looking for a powerful JavaScript toolchain.
## Documentation
You can find the React documentation [on the website](https://reactjs.org/).
You can find the React documentation [on the website](https://react.dev/).
Check out the [Getting Started](https://reactjs.org/docs/getting-started.html) page for a quick overview.
Check out the [Getting Started](https://react.dev/learn) page for a quick overview.
The documentation is divided into several sections:
This example will render "Hello Taylor" into a container on the page.
You'll notice that we used an HTML-like syntax; [we call it JSX](https://reactjs.org/docs/introducing-jsx.html). JSX is not required to use React, but it makes code more readable, and writing it feels like writing HTML. If you're using React as a `<script>` tag, read [this section](https://reactjs.org/docs/add-react-to-a-website.html#optional-try-react-with-jsx) on integrating JSX; otherwise, the [recommended JavaScript toolchains](https://reactjs.org/docs/create-a-new-react-app.html) handle it automatically.
You'll notice that we used an HTML-like syntax; [we call it JSX](https://react.dev/learn#writing-markup-with-jsx). JSX is not required to use React, but it makes code more readable, and writing it feels like writing HTML.
## Contributing
@@ -62,11 +65,11 @@ The main purpose of this repository is to continue evolving React core, making i
Facebook has adopted a Code of Conduct that we expect project participants to adhere to. Please read [the full text](https://code.fb.com/codeofconduct) so that you can understand what actions will and will not be tolerated.
Read our [contributing guide](https://reactjs.org/docs/how-to-contribute.html) to learn about our development process, how to propose bugfixes and improvements, and how to build and test your changes to React.
Read our [contributing guide](https://legacy.reactjs.org/docs/how-to-contribute.html) to learn about our development process, how to propose bugfixes and improvements, and how to build and test your changes to React.
### Good First Issues
### [Good First Issues](https://github.com/facebook/react/labels/good%20first%20issue)
To help you get your feet wet and get you familiar with our contribution process, we have a list of [good first issues](https://github.com/facebook/react/labels/good%20first%20issue) that contain bugs that have a relatively limited scope. This is a great place to get started.
* Fix for string attribute values with emoji [#33096](https://github.com/facebook/react/pull/33096) by [@josephsavona](https://github.com/josephsavona)
## 19.1.0-rc.1 (April 21, 2025)
## eslint-plugin-react-hooks
* Temporarily disable ref access in render validation [#32839](https://github.com/facebook/react/pull/32839) by [@poteto](https://github.com/poteto)
* Fix type error with recommended config [#32666](https://github.com/facebook/react/pull/32666) by [@niklasholm](https://github.com/niklasholm)
* Merge rule from eslint-plugin-react-compiler into `react-hooks` plugin [#32416](https://github.com/facebook/react/pull/32416) by [@michaelfaith](https://github.com/michaelfaith)
* Add dev dependencies for typescript migration [#32279](https://github.com/facebook/react/pull/32279) by [@michaelfaith](https://github.com/michaelfaith)
* Support v9 context api [#32045](https://github.com/facebook/react/pull/32045) by [@michaelfaith](https://github.com/michaelfaith)
* Support eslint 8+ flat plugin syntax out of the box for eslint-plugin-react-compiler [#32120](https://github.com/facebook/react/pull/32120) by [@orta](https://github.com/orta)
## babel-plugin-react-compiler
* Support satisfies operator [#32742](https://github.com/facebook/react/pull/32742) by [@rodrigofariow](https://github.com/rodrigofariow)
* Fix inferEffectDependencies lint false positives [#32769](https://github.com/facebook/react/pull/32769) by [@mofeiZ](https://github.com/mofeiZ)
* Fix hoisting of let declarations [#32724](https://github.com/facebook/react/pull/32724) by [@mofeiZ](https://github.com/mofeiZ)
* Avoid failing builds when import specifiers conflict or shadow vars [#32663](https://github.com/facebook/react/pull/32663) by [@mofeiZ](https://github.com/mofeiZ)
* Optimize components declared with arrow function and implicit return and `compilationMode: 'infer'` [#31792](https://github.com/facebook/react/pull/31792) by [@dimaMachina](https://github.com/dimaMachina)
* Validate static components [#32683](https://github.com/facebook/react/pull/32683) by [@josephsavona](https://github.com/josephsavona)
* Hoist dependencies from functions more conservatively [#32616](https://github.com/facebook/react/pull/32616) by [@mofeiZ](https://github.com/mofeiZ)
* Implement NumericLiteral as ObjectPropertyKey [#31791](https://github.com/facebook/react/pull/31791) by [@dimaMachina](https://github.com/dimaMachina)
* Avoid bailouts when inserting gating [#32598](https://github.com/facebook/react/pull/32598) by [@mofeiZ](https://github.com/mofeiZ)
* Stop bailing out early for hoisted gated functions [#32597](https://github.com/facebook/react/pull/32597) by [@mofeiZ](https://github.com/mofeiZ)
* Add shape for Array.from [#32522](https://github.com/facebook/react/pull/32522) by [@mofeiZ](https://github.com/mofeiZ)
* Patch array and argument spread mutability [#32521](https://github.com/facebook/react/pull/32521) by [@mofeiZ](https://github.com/mofeiZ)
* Make CompilerError compatible with reflection [#32539](https://github.com/facebook/react/pull/32539) by [@poteto](https://github.com/poteto)
* Add simple walltime measurement [#32331](https://github.com/facebook/react/pull/32331) by [@poteto](https://github.com/poteto)
* Improve error messages for unhandled terminal and instruction kinds [#32324](https://github.com/facebook/react/pull/32324) by [@inottn](https://github.com/inottn)
* Handle TSInstantiationExpression in lowerExpression [#32302](https://github.com/facebook/react/pull/32302) by [@inottn](https://github.com/inottn)
* Fix invalid Array.map type [#32095](https://github.com/facebook/react/pull/32095) by [@mofeiZ](https://github.com/mofeiZ)
* Patch for JSX escape sequences in @babel/generator [#32131](https://github.com/facebook/react/pull/32131) by [@mofeiZ](https://github.com/mofeiZ)
*`JSXText` emits incorrect with bracket [#32138](https://github.com/facebook/react/pull/32138) by [@himself65](https://github.com/himself65)
* Validation against calling impure functions [#31960](https://github.com/facebook/react/pull/31960) by [@josephsavona](https://github.com/josephsavona)
* Always target node [#32091](https://github.com/facebook/react/pull/32091) by [@poteto](https://github.com/poteto)
* Patch compilationMode:infer object method edge case [#32055](https://github.com/facebook/react/pull/32055) by [@mofeiZ](https://github.com/mofeiZ)
* Generate ts defs [#31994](https://github.com/facebook/react/pull/31994) by [@poteto](https://github.com/poteto)
* Relax react peer dep requirement [#31915](https://github.com/facebook/react/pull/31915) by [@poteto](https://github.com/poteto)
* Allow type cast expressions with refs [#31871](https://github.com/facebook/react/pull/31871) by [@josephsavona](https://github.com/josephsavona)
* Add shape for global Object.keys [#31583](https://github.com/facebook/react/pull/31583) by [@mofeiZ](https://github.com/mofeiZ)
* Optimize method calls w props receiver [#31775](https://github.com/facebook/react/pull/31775) by [@josephsavona](https://github.com/josephsavona)
* Fix dropped ref with spread props in InlineJsxTransform [#31726](https://github.com/facebook/react/pull/31726) by [@jackpope](https://github.com/jackpope)
* Support for non-declatation for in/of iterators [#31710](https://github.com/facebook/react/pull/31710) by [@mvitousek](https://github.com/mvitousek)
* Support for context variable loop iterators [#31709](https://github.com/facebook/react/pull/31709) by [@mvitousek](https://github.com/mvitousek)
* Replace deprecated dependency in `eslint-plugin-react-compiler` [#31629](https://github.com/facebook/react/pull/31629) by [@rakleed](https://github.com/rakleed)
* Support enableRefAsProp in jsx transform [#31558](https://github.com/facebook/react/pull/31558) by [@jackpope](https://github.com/jackpope)
* Fix: ref.current now correctly reactive [#31521](https://github.com/facebook/react/pull/31521) by [@mofeiZ](https://github.com/mofeiZ)
* Outline JSX with non-jsx children [#31442](https://github.com/facebook/react/pull/31442) by [@gsathya](https://github.com/gsathya)
* Outline jsx with duplicate attributes [#31441](https://github.com/facebook/react/pull/31441) by [@gsathya](https://github.com/gsathya)
* Store original and new prop names [#31440](https://github.com/facebook/react/pull/31440) by [@gsathya](https://github.com/gsathya)
* Stabilize compiler output: sort deps and decls by name [#31362](https://github.com/facebook/react/pull/31362) by [@mofeiZ](https://github.com/mofeiZ)
* Bugfix for hoistable deps for nested functions [#31345](https://github.com/facebook/react/pull/31345) by [@mofeiZ](https://github.com/mofeiZ)
* Remove compiler runtime-compat fixture library [#31430](https://github.com/facebook/react/pull/31430) by [@poteto](https://github.com/poteto)
* Wrap inline jsx transform codegen in conditional [#31267](https://github.com/facebook/react/pull/31267) by [@jackpope](https://github.com/jackpope)
* Check if local identifier is a hook when resolving globals [#31384](https://github.com/facebook/react/pull/31384) by [@poteto](https://github.com/poteto)
* Handle member expr as computed property [#31344](https://github.com/facebook/react/pull/31344) by [@gsathya](https://github.com/gsathya)
* Fix to ref access check to ban ref?.current [#31360](https://github.com/facebook/react/pull/31360) by [@mvitousek](https://github.com/mvitousek)
* InlineJSXTransform transforms jsx inside function expressions [#31282](https://github.com/facebook/react/pull/31282) by [@josephsavona](https://github.com/josephsavona)
## Other
* Add shebang to banner [#32225](https://github.com/facebook/react/pull/32225) by [@Jeremy-Hibiki](https://github.com/Jeremy-Hibiki)
* remove terser from react-compiler-runtime build [#31326](https://github.com/facebook/react/pull/31326) by [@henryqdineen](https://github.com/henryqdineen)
React Compiler is a compiler that optimizes React applications, ensuring that only the minimal parts of components and hooks will re-render when state changes. The compiler also validates that components and hooks follow the Rules of React.
More information about the design and architecture of the compiler are covered in the [Design Goals](./docs/DESIGN_GOALS.md).
More information about developing the compiler itself is covered in the [Development Guide](./docs/DEVELOPMENT_GUIDE.md).
Some files were not shown because too many files have changed in this diff
Show More
Reference in New Issue
Block a user
Blocking a user prevents them from interacting with repositories, such as opening or commenting on pull requests or issues. Learn more about blocking a user.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
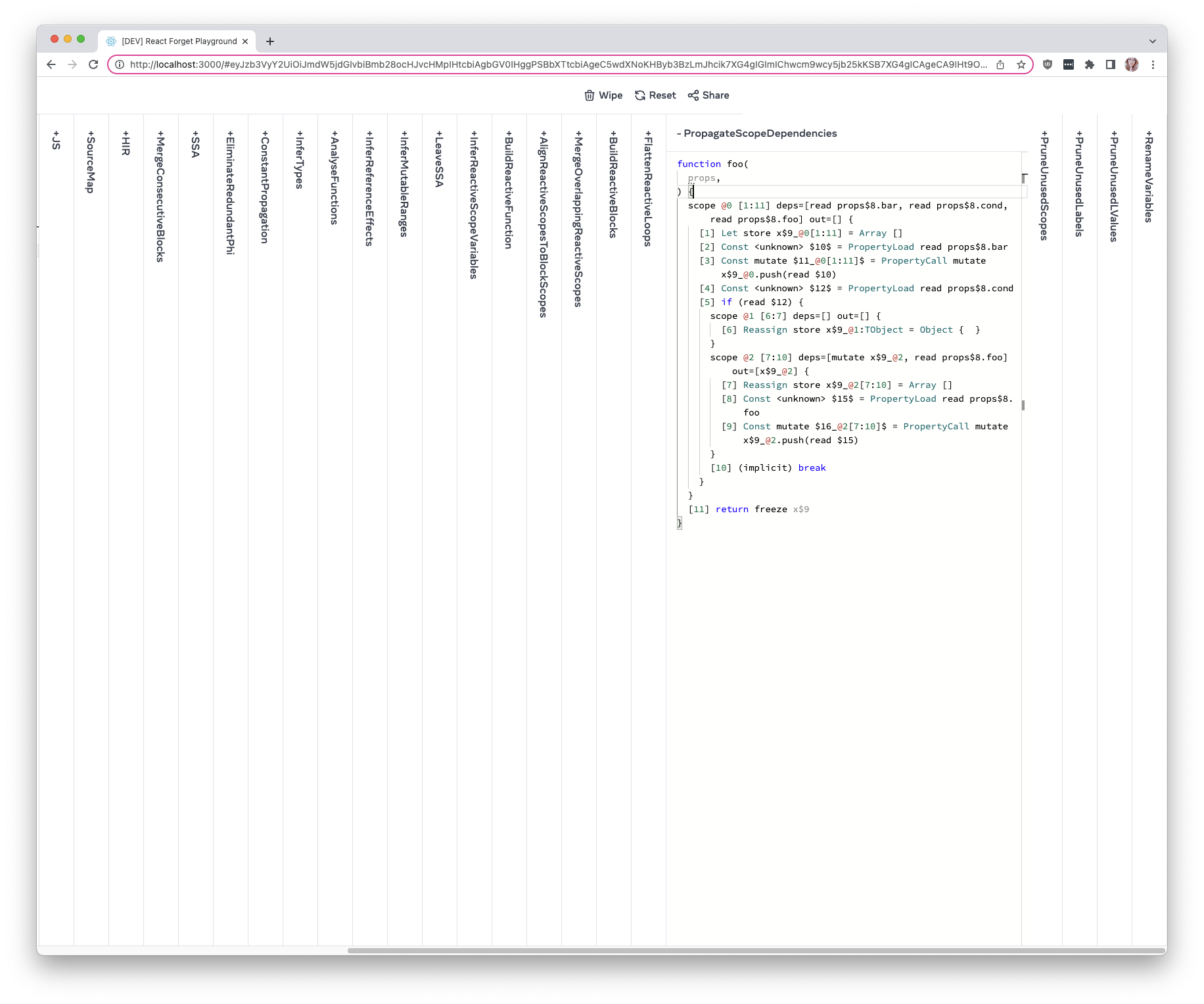{kind=link}
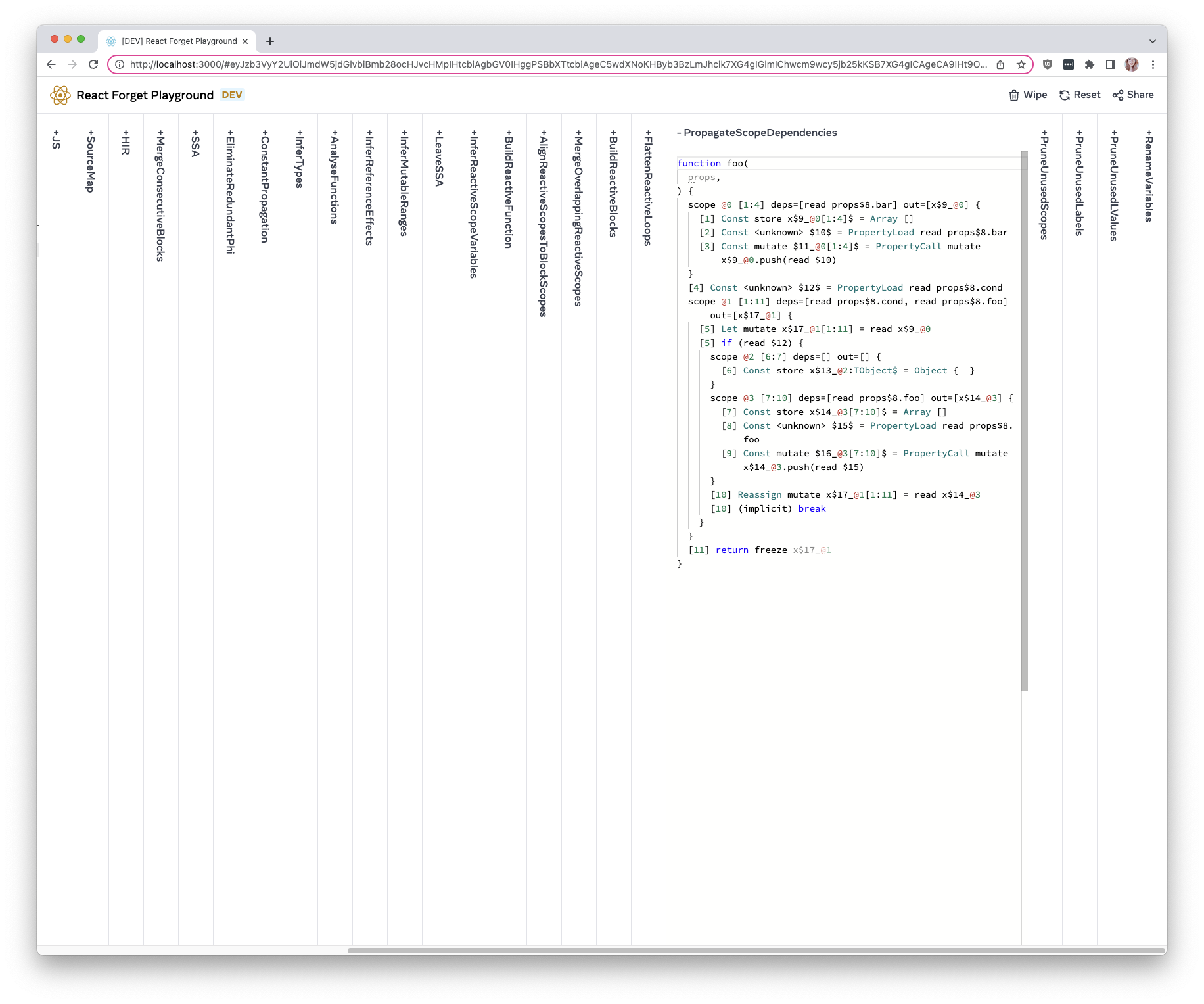{kind=link}
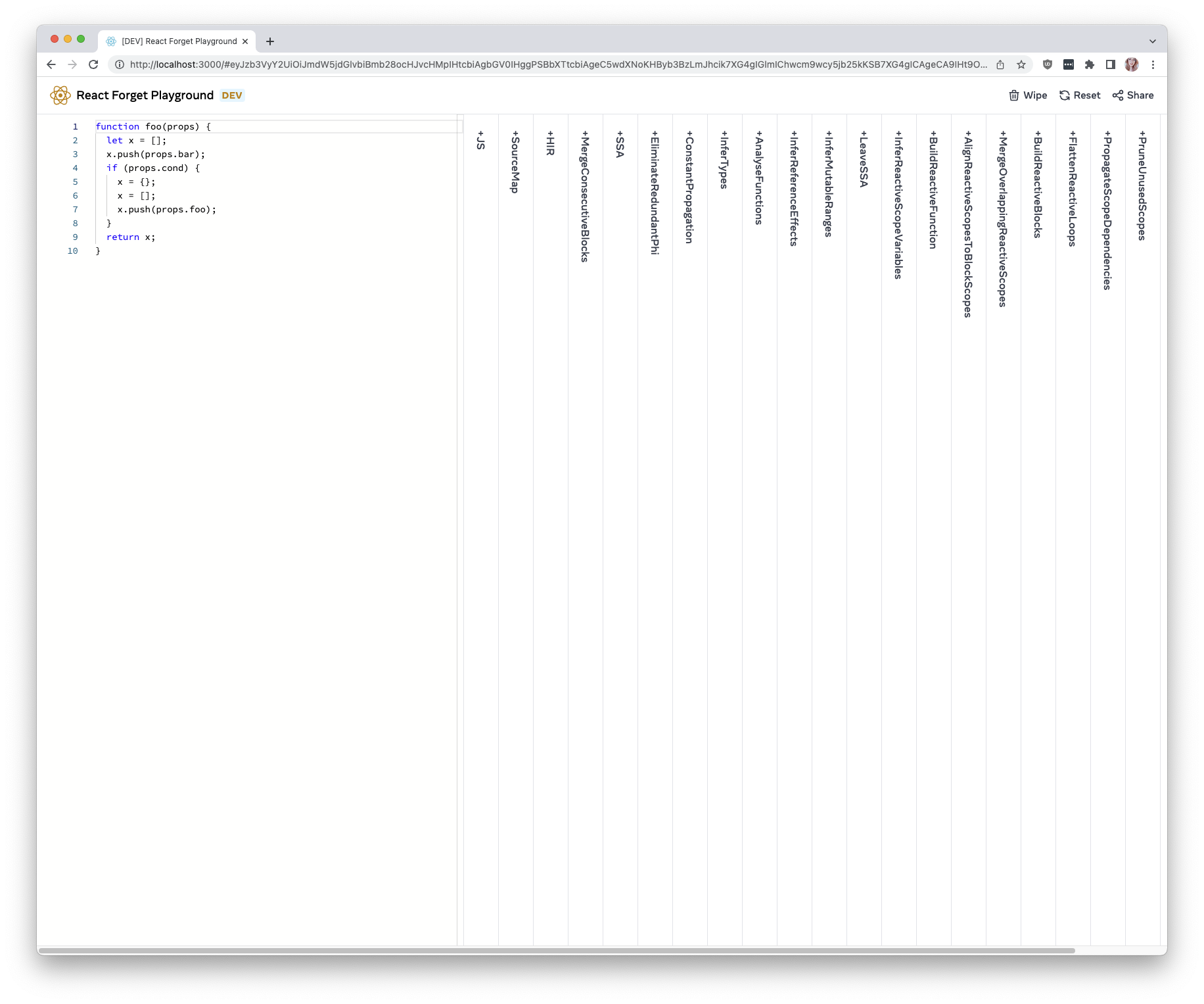{kind=link}
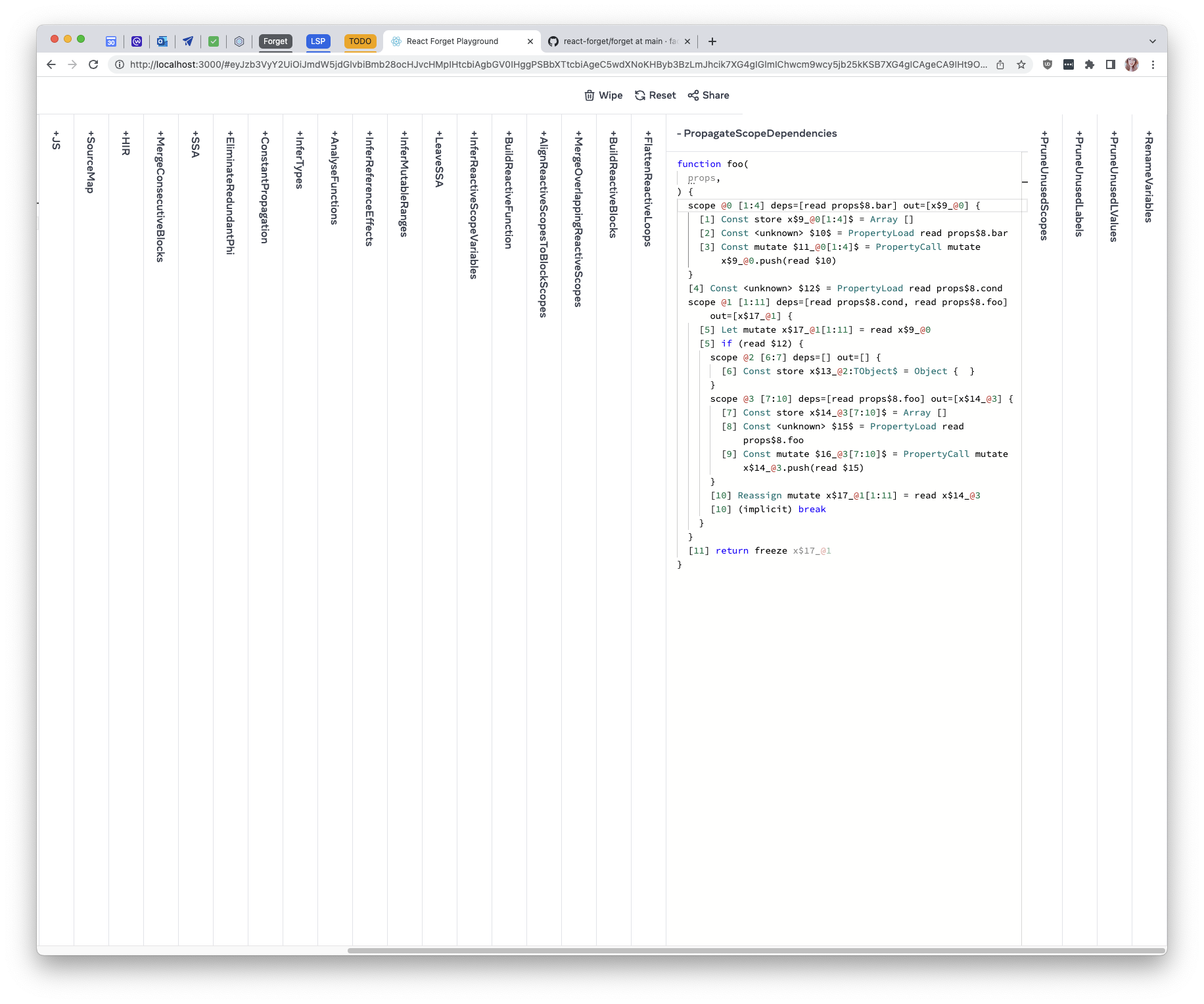{kind=link}
{kind=link}
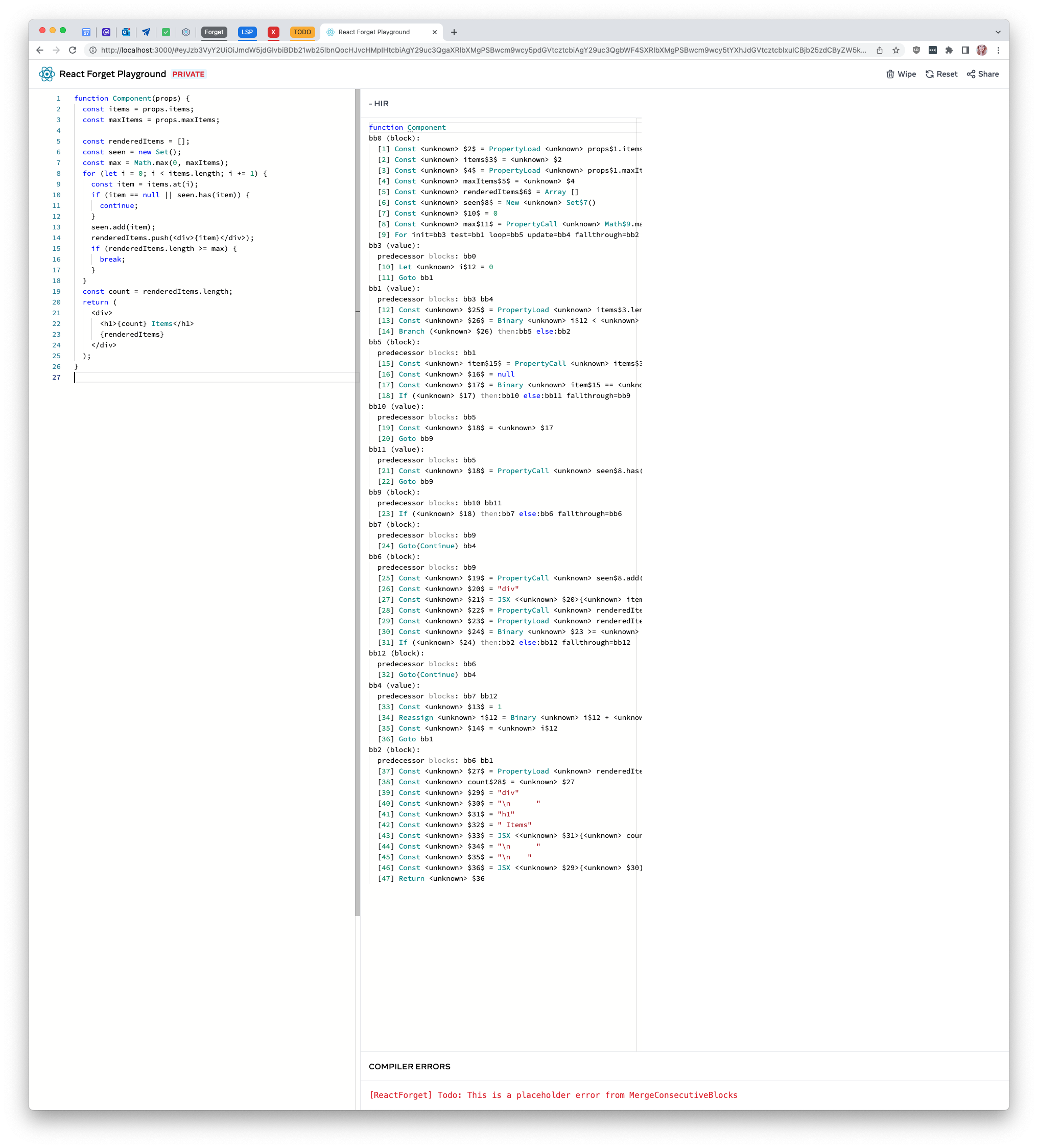{kind=link}
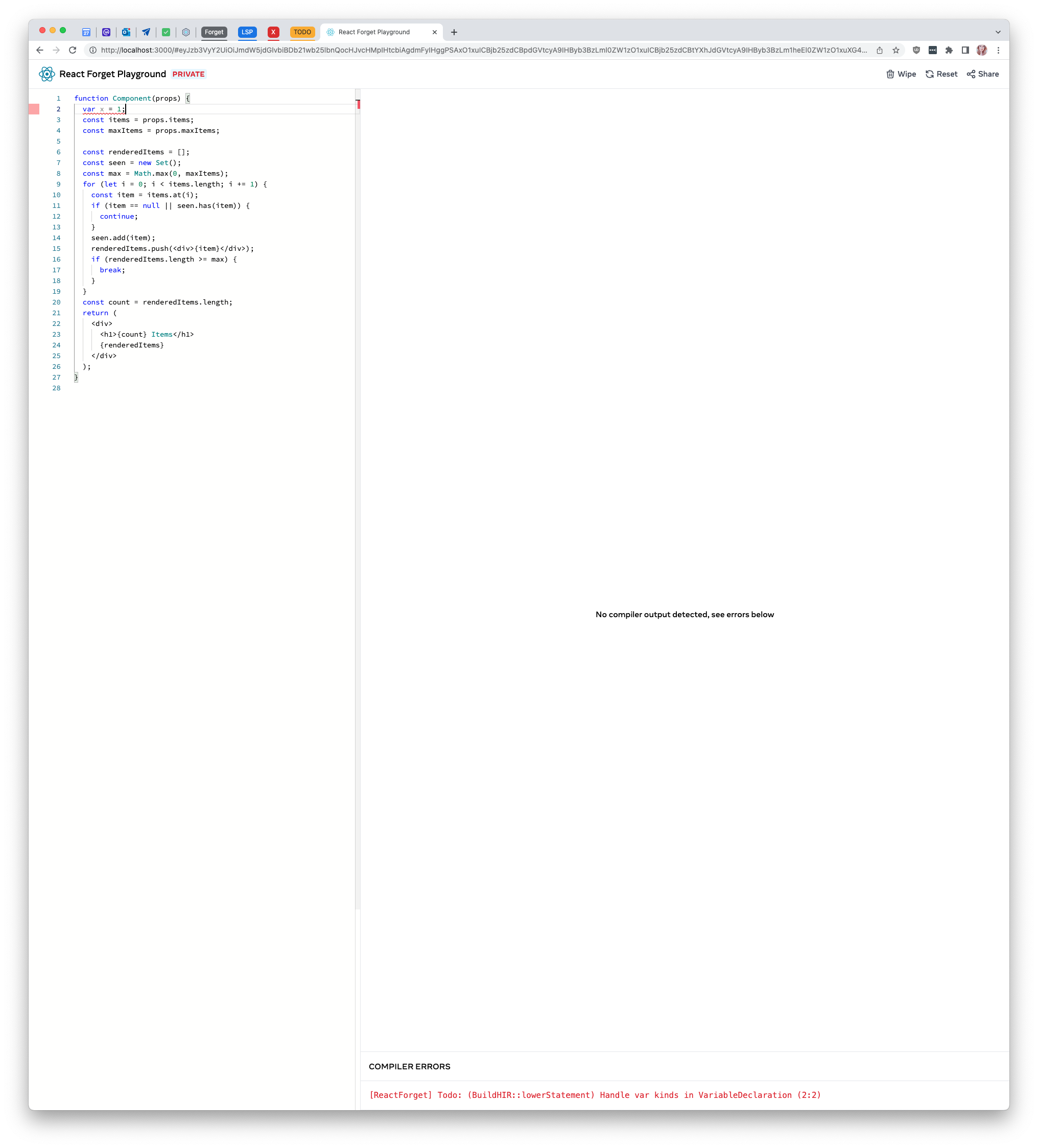{kind=link}
{kind=link}
{kind=link}
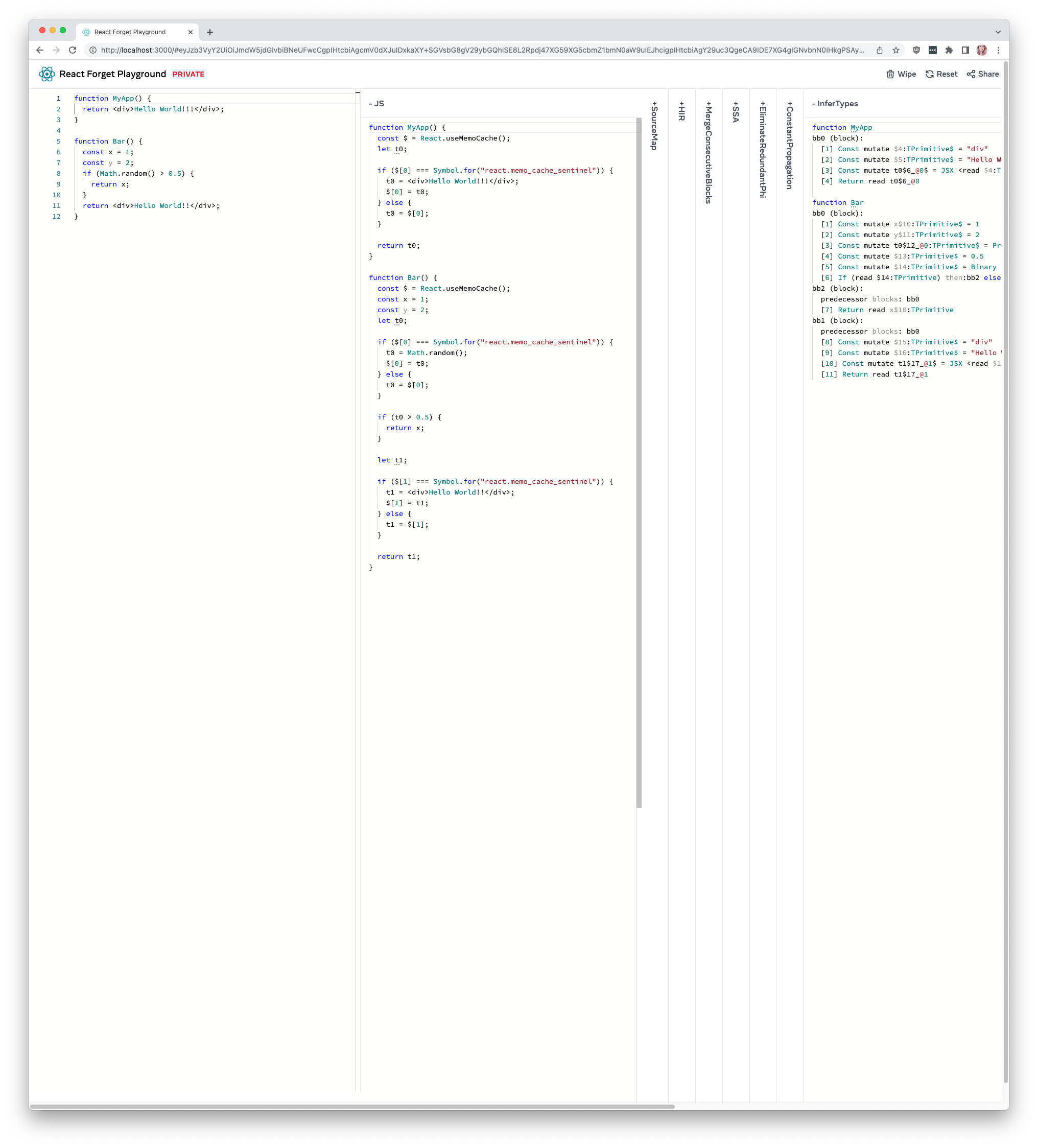{kind=link}
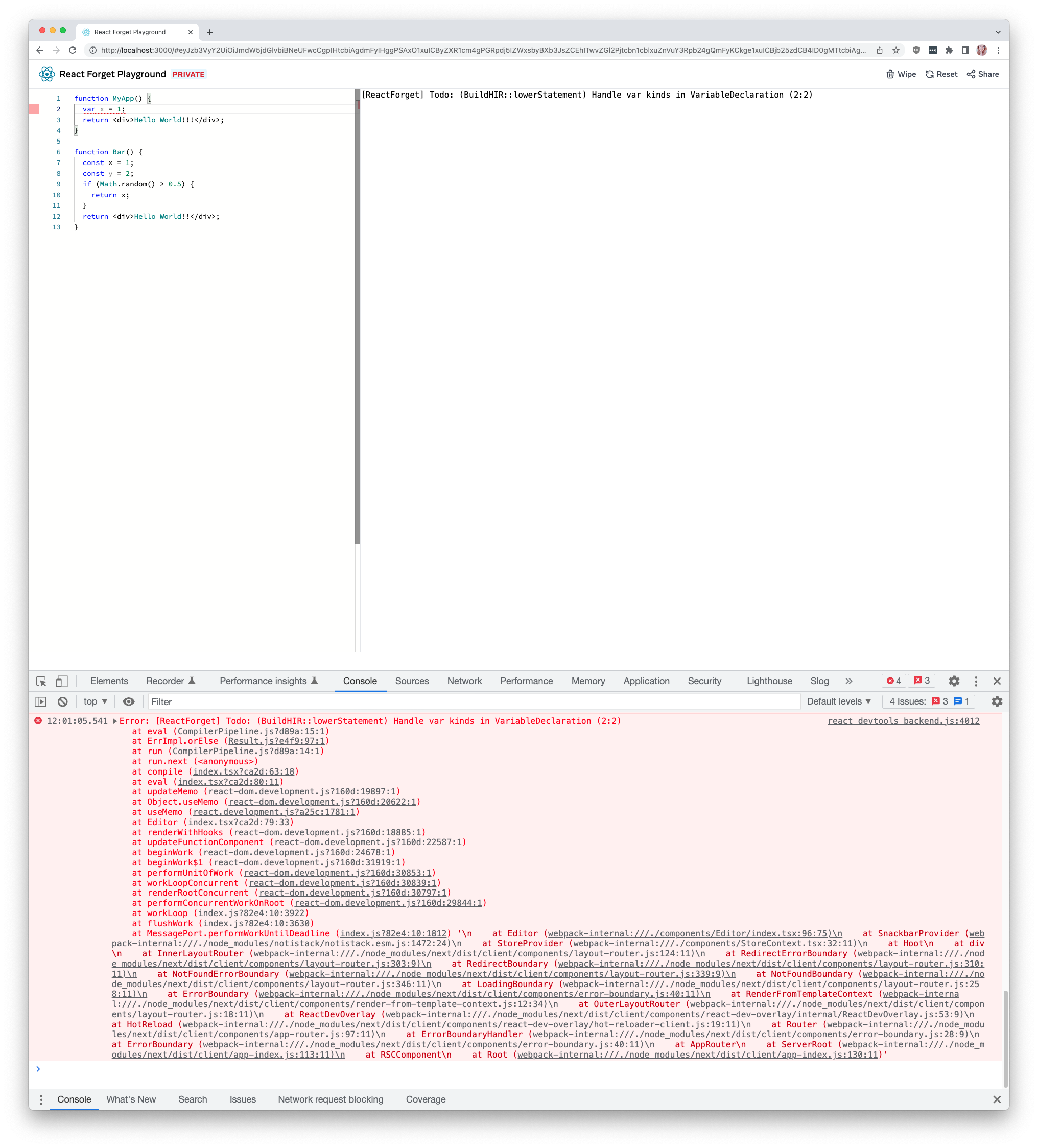{kind=link}
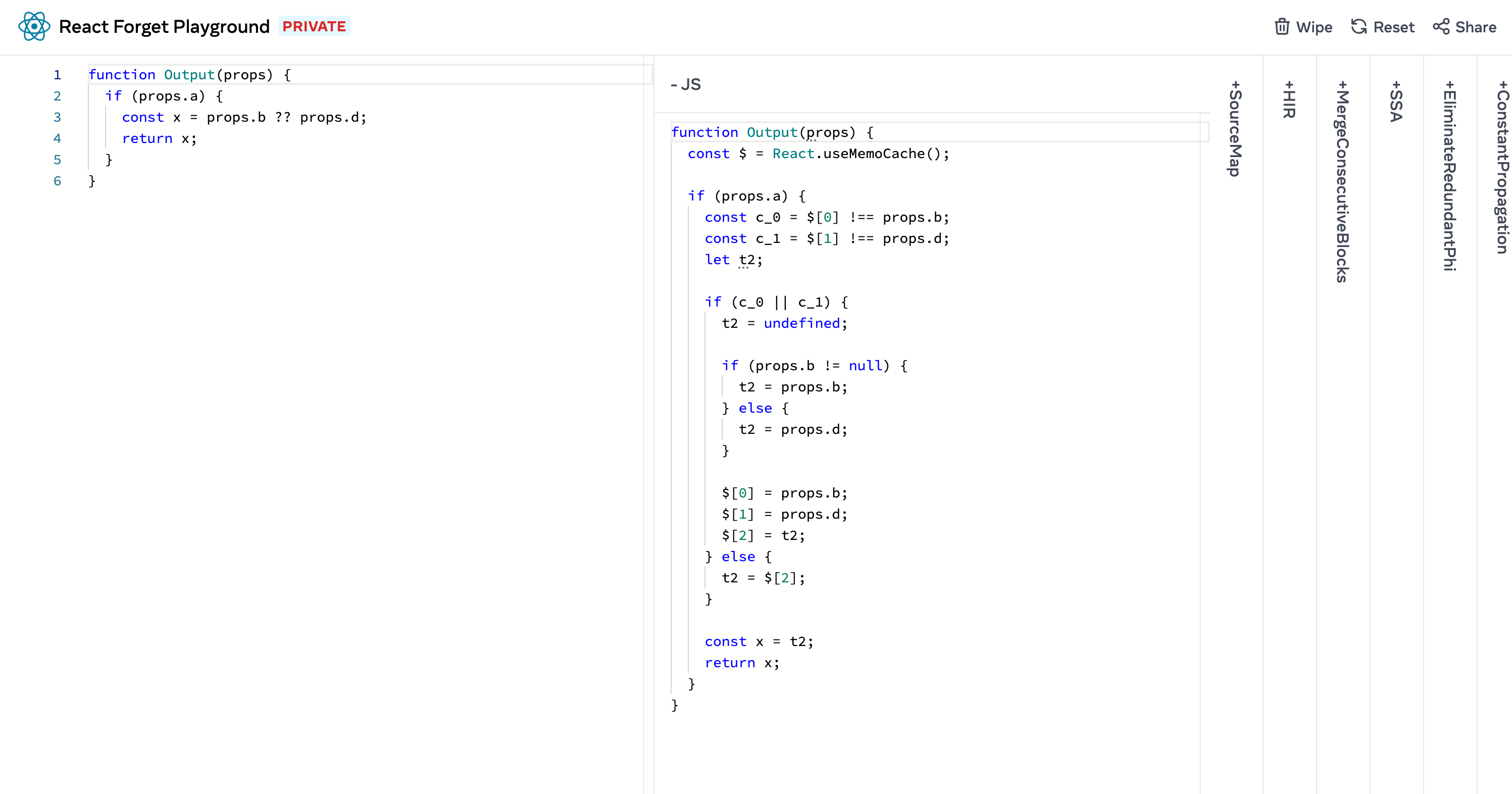{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
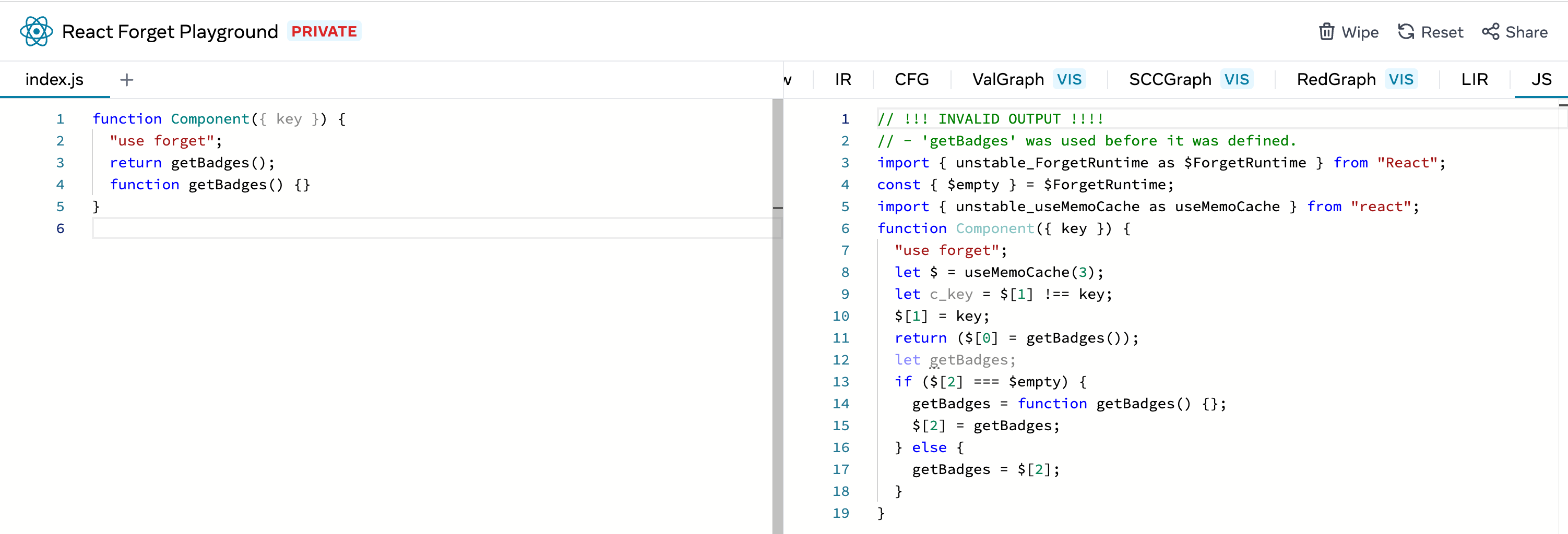{kind=link}
{kind=link}
{kind=link}