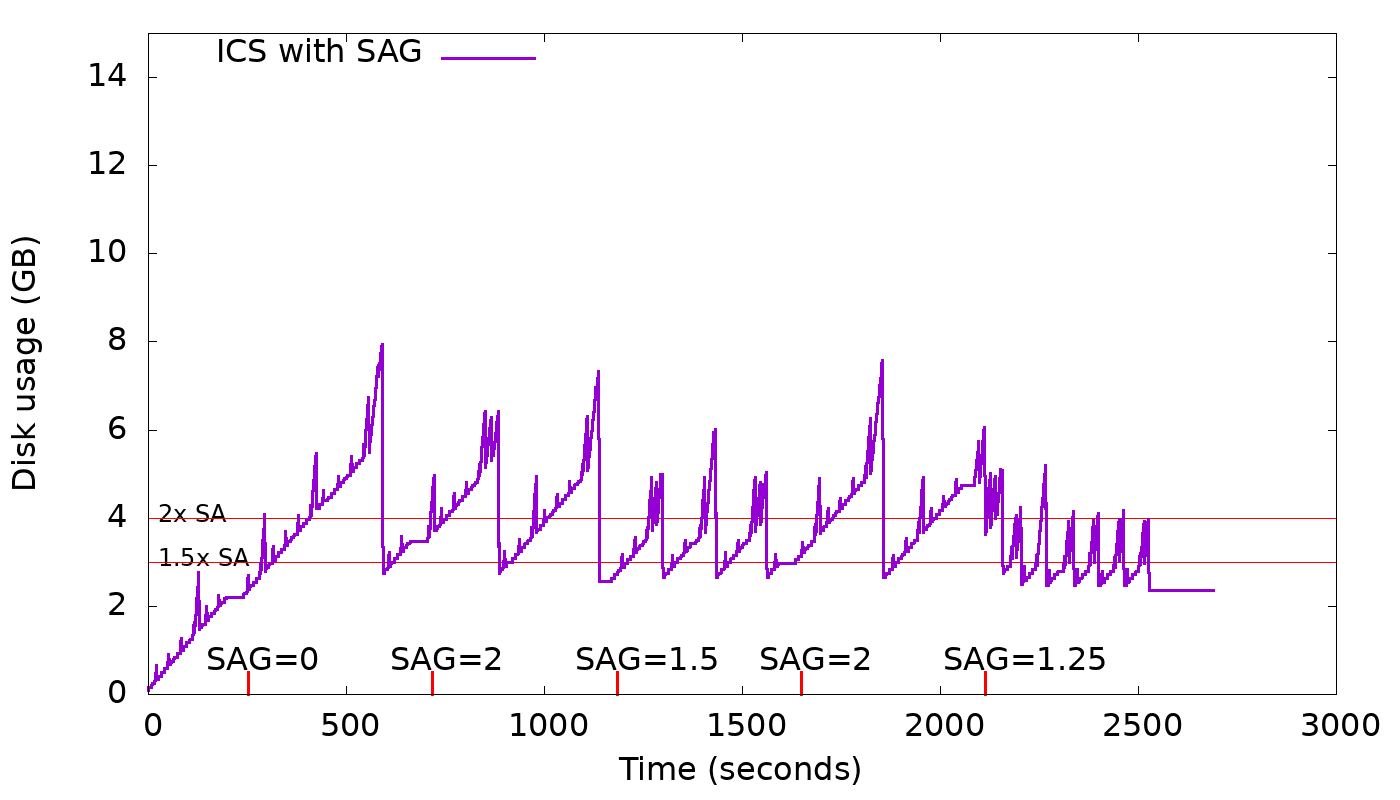
ICS is a compaction strategy that inherits size tiered properties -- therefore it's write optimized too -- but fixes its space overhead of 100% due to input files being only released on completion. That's achieved with the concept of sstable run (similar in concept to LCS levels) which breaks a large sstable into fixed-size chunks (1G by default), known as run fragments. ICS picks similar-sized runs for compaction, and fragments of those runs can be released incrementally as they're compacted, reducing the space overhead to about (number_of_input_runs * 1G). This allows user to increase storage density of nodes (from 50% to ~80%), reducing the cost of ownership. NOTE: test_system_schema_version_is_stable adjusted to account for batchlog using IncrementalCompactionStrategy contains: compaction/: added incremental_compaction_strategy.cc (.hh), incremental_backlog_tracker.cc (.hh) compaction/CMakeLists.txt: include ICS cc files configure.py: changes for ICS files, includes test db/legacy_schema_migrator.cc / db/schema_tables.cc: fallback to ICS when strategy is not supported db/system_keyspace: pick ICS for some system tables schema/schema.hh: ICS becomes default test/boost: Add incremental_compaction_test.cc test/boost/sstable_compaction_test.cc: ICS related changes test/cqlpy/test_compaction_strategy_validation.py: ICS related changes docs/architecture/compaction/compaction-strategies.rst: changes to ICS section docs/cql/compaction.rst: changes to ICS section docs/cql/ddl.rst: adds reference to ICS options docs/getting-started/system-requirements.rst: updates sentence mentioning ICS docs/kb/compaction.rst: changes to ICS section docs/kb/garbage-collection-ics.rst: add file docs/kb/index.rst: add reference to <garbage-collection-ics> docs/operating-scylla/procedures/tips/production-readiness.rst: add ICS section some relevant commits throughout the ICS history: commit 434b97699b39c570d0d849d372bf64f418e5c692 Merge: 105586f747 30250749b8 Author: Paweł Dziepak <pdziepak@scylladb.com> Date: Tue Mar 12 12:14:23 2019 +0000 Merge "Introduce Incremental Compaction Strategy (ICS)" from Raphael " Introduce new compaction strategy which is essentially like size tiered but will work with the existing incremental compaction. Thus incremental compaction strategy. It works like size tiered, but each element composing a tier is a sstable run, meaning that the compaction strategy will look for N similar-sized sstable runs to compact, not just individual sstables. Parameters: * "sstable_size_in_mb": defines the maximum sstable (fragment) size composing a sstable run, which impacts directly the disk space requirement which is improved with incremental compaction. The lower the value the lower the space requirement for compaction because fragments involved will be released more frequently. * all others available in size tiered compaction strategy HOWTO ===== To change an existing table to use it, do: ALTER TABLE mykeyspace.mytable WITH compaction = {'class' : 'IncrementalCompactionStrategy'}; Set fragment size: ALTER TABLE mykeyspace.mytable WITH compaction = {'class' : 'IncrementalCompactionStrategy', 'sstable_size_in_mb' : 1000 } " commit 94ef3cd29a196bedbbeb8707e20fe78a197f30a1 Merge: dca89ce7a5 e08ef3e1a3 Author: Avi Kivity <avi@scylladb.com> Date: Tue Sep 8 11:31:52 2020 +0300 Merge "Add feature to limit space amplification in Incremental Compaction" from Raphael " A new option, space_amplification_goal (SAG), is being added to ICS. This option will allow ICS user to set a goal on the space amplification (SA). It's not supposed to be an upper bound on the space amplification, but rather, a goal. This new option will be disabled by default as it doesn't benefit write-only (no overwrites) workloads and could hurt severely the write performance. The strategy is free to delay triggering this new behavior, in order to increase overall compaction efficiency. The graph below shows how this feature works in practice for different values of space_amplification_goal: https://user-images.githubusercontent.com/1409139/89347544-60b7b980-d681-11ea-87ab-e2fdc3ecb9f0.png When strategy finds space amplification crossed space_amplification_goal, it will work on reducing the SA by doing a cross-tier compaction on the two largest tiers. This feature works only on the two largest tiers, because taking into account others, could hurt the compaction efficiency which is based on the fact that the more similar-sized sstables are compacted together the higher the compaction efficiency will be. With SAG enabled, min_threshold only plays an important role on the smallest tiers, given that the second-largest tier could be compacted into the largest tier for a space_amplification_goal value < 2. By making the options space_amplification_goal and min_threshold independent, user will be able to tune write amplification and space amplification, based on the needs. The lower the space_amplification_goal the higher the write amplification, but by increasing the min threshold, the write amplification can be decreased to a desired amount. " commit 7d90911c5fb3fa891ad64a62147c3a6ca26d61b1 Author: Raphael S. Carvalho <raphaelsc@scylladb.com> Date: Sat Oct 16 13:41:46 2021 -0300 compaction: ICS: Add garbage collection Today, ICS lacks an approach to persist expired tombstones in a timely manner, which is a problem because accumulation of tombstones are known to affecting latency considerably. For an expired tombstone to be purged, it has to reach the top of the LSM tree and hope that older overlapping data wasn't introduced at the bottom. The condition are there and must be satisfied to avoid data resurrection. STCS, today, has an inefficient garbage collection approach because it only picks a single sstable, which satisfies the tombstone density threshold and file staleness. That's a problem because overlapping data either on same tier or smaller tiers will prevent tombstones from being purged. Also, nothing is done to push the tombstones to the top of the tree, for the conditions to be eventually satisfied. Due to incremental compaction, ICS can more easily have an effecient GC by doing cross-tier compaction of relevant tiers. The trigger will be file staleness and tombstone density, which threshold values can be configured by tombstone_compaction_interval and tombstone_threshold, respectively. If ICS finds a tier which meets both conditions, then that tier and the larger[1] *and* closest-in-size[2] tier will be compacted together. [1]: A larger tier is picked because we want tombstones to eventually reach the top of the tree. [2]: It also has to be the closest-in-size tier as the smaller the size difference the higher the efficiency of the compaction. We want to minimize write amplification as much as possible. The staleness condition is there to prevent the same file from being picked over and over again in a short interval. With this approach, ICS will be continuously working to purge garbage while not hurting overall efficiency on a steady state, as same-tier compactions are prioritized. Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com> Message-Id: <20211016164146.38010-1-raphaelsc@scylladb.com> Signed-off-by: Raphael S. Carvalho <raphaelsc@scylladb.com> Closes scylladb/scylladb#22063
{kind=link}
602 lines
28 KiB
C++
602 lines
28 KiB
C++
/*
|
|
* Modified by ScyllaDB
|
|
* Copyright (C) 2017-present ScyllaDB
|
|
*/
|
|
|
|
/*
|
|
* SPDX-License-Identifier: (LicenseRef-ScyllaDB-Source-Available-1.0 and Apache-2.0)
|
|
*/
|
|
|
|
// Since Scylla 2.0, we use system tables whose schemas were introduced in
|
|
// Cassandra 3. If Scylla boots to find a data directory with system tables
|
|
// with older schemas - produced by pre-2.0 Scylla or by pre-3.0 Cassandra,
|
|
// we need to migrate these old tables to the new format.
|
|
//
|
|
// We provide here a function, db::legacy_schema_migrator::migrate(),
|
|
// for a one-time migration from old to new system tables. The function
|
|
// reads old system tables, write them back in the new format, and finally
|
|
// delete the old system tables. Scylla's main should call this function and
|
|
// wait for the returned future, before starting to serve the database.
|
|
|
|
#include <boost/iterator/filter_iterator.hpp>
|
|
#include <seastar/core/future-util.hh>
|
|
#include <seastar/util/log.hh>
|
|
#include <map>
|
|
#include <unordered_set>
|
|
#include <chrono>
|
|
|
|
#include "replica/database.hh"
|
|
#include "legacy_schema_migrator.hh"
|
|
#include "system_keyspace.hh"
|
|
#include "schema_tables.hh"
|
|
#include "schema/schema_builder.hh"
|
|
#include "service/storage_proxy.hh"
|
|
#include "utils/rjson.hh"
|
|
#include "cql3/query_processor.hh"
|
|
#include "cql3/untyped_result_set.hh"
|
|
#include "cql3/util.hh"
|
|
#include "types/user.hh"
|
|
|
|
static seastar::logger mlogger("legacy_schema_migrator");
|
|
|
|
namespace db {
|
|
namespace legacy_schema_migrator {
|
|
|
|
// local data carriers
|
|
|
|
class migrator {
|
|
public:
|
|
static const std::unordered_set<sstring> legacy_schema_tables;
|
|
|
|
migrator(sharded<service::storage_proxy>& sp, sharded<replica::database>& db, sharded<db::system_keyspace>& sys_ks, cql3::query_processor& qp)
|
|
: _sp(sp), _db(db), _sys_ks(sys_ks), _qp(qp) {
|
|
}
|
|
migrator(migrator&&) = default;
|
|
|
|
typedef db_clock::time_point time_point;
|
|
|
|
// TODO: we don't support triggers.
|
|
// this is a placeholder.
|
|
struct trigger {
|
|
time_point timestamp;
|
|
sstring name;
|
|
std::unordered_map<sstring, sstring> options;
|
|
};
|
|
|
|
struct table {
|
|
time_point timestamp;
|
|
schema_ptr metadata;
|
|
std::vector<trigger> triggers;
|
|
};
|
|
|
|
struct type {
|
|
time_point timestamp;
|
|
user_type metadata;
|
|
};
|
|
|
|
struct function {
|
|
time_point timestamp;
|
|
sstring ks_name;
|
|
sstring fn_name;
|
|
std::vector<sstring> arg_names;
|
|
std::vector<sstring> arg_types;
|
|
sstring return_type;
|
|
bool called_on_null_input;
|
|
sstring language;
|
|
sstring body;
|
|
};
|
|
|
|
struct aggregate {
|
|
time_point timestamp;
|
|
sstring ks_name;
|
|
sstring fn_name;
|
|
std::vector<sstring> arg_names;
|
|
std::vector<sstring> arg_types;
|
|
sstring return_type;
|
|
sstring final_func;
|
|
sstring initcond;
|
|
sstring state_func;
|
|
sstring state_type;
|
|
};
|
|
|
|
struct keyspace {
|
|
time_point timestamp;
|
|
sstring name;
|
|
bool durable_writes;
|
|
std::map<sstring, sstring> replication_params;
|
|
|
|
std::vector<table> tables;
|
|
std::vector<type> types;
|
|
std::vector<function> functions;
|
|
std::vector<aggregate> aggregates;
|
|
};
|
|
|
|
class unsupported_feature : public std::runtime_error {
|
|
public:
|
|
using runtime_error::runtime_error;
|
|
};
|
|
|
|
static sstring fmt_query(const char* fmt, const char* table) {
|
|
return fmt::format(fmt::runtime(fmt), db::system_keyspace::NAME, table);
|
|
}
|
|
|
|
typedef ::shared_ptr<cql3::untyped_result_set> result_set_type;
|
|
typedef const cql3::untyped_result_set::row row_type;
|
|
|
|
future<> read_table(keyspace& dst, sstring cf_name, time_point timestamp) {
|
|
auto fmt = "SELECT * FROM {}.{} WHERE keyspace_name = ? AND columnfamily_name = ?";
|
|
auto tq = fmt_query(fmt, db::system_keyspace::legacy::COLUMNFAMILIES);
|
|
auto cq = fmt_query(fmt, db::system_keyspace::legacy::COLUMNS);
|
|
auto zq = fmt_query(fmt, db::system_keyspace::legacy::TRIGGERS);
|
|
|
|
typedef std::tuple<future<result_set_type>, future<result_set_type>, future<result_set_type>, future<db::schema_tables::legacy::schema_mutations>> result_tuple;
|
|
|
|
return when_all(_qp.execute_internal(tq, { dst.name, cf_name }, cql3::query_processor::cache_internal::yes),
|
|
_qp.execute_internal(cq, { dst.name, cf_name }, cql3::query_processor::cache_internal::yes),
|
|
_qp.execute_internal(zq, { dst.name, cf_name }, cql3::query_processor::cache_internal::yes),
|
|
db::schema_tables::legacy::read_table_mutations(_sp, dst.name, cf_name, db::system_keyspace::legacy::column_families()))
|
|
.then([&dst, cf_name, timestamp](result_tuple&& t) {
|
|
|
|
result_set_type tables = std::get<0>(t).get();
|
|
result_set_type columns = std::get<1>(t).get();
|
|
result_set_type triggers = std::get<2>(t).get();
|
|
db::schema_tables::legacy::schema_mutations sm = std::get<3>(t).get();
|
|
|
|
row_type& td = tables->one();
|
|
|
|
auto ks_name = td.get_as<sstring>("keyspace_name");
|
|
auto cf_name = td.get_as<sstring>("columnfamily_name");
|
|
auto id = table_id(td.get_or("cf_id", generate_legacy_id(ks_name, cf_name).uuid()));
|
|
|
|
schema_builder builder(dst.name, cf_name, id);
|
|
|
|
builder.with_version(sm.digest());
|
|
|
|
cf_type cf = sstring_to_cf_type(td.get_or("type", sstring("standard")));
|
|
if (cf == cf_type::super) {
|
|
fail(unimplemented::cause::SUPER);
|
|
}
|
|
|
|
auto comparator = td.get_as<sstring>("comparator");
|
|
bool is_compound = cell_comparator::check_compound(comparator);
|
|
builder.set_is_compound(is_compound);
|
|
cell_comparator::read_collections(builder, comparator);
|
|
|
|
bool filter_sparse = false;
|
|
|
|
data_type default_validator = {};
|
|
if (td.has("default_validator")) {
|
|
default_validator = db::schema_tables::parse_type(td.get_as<sstring>("default_validator"));
|
|
if (default_validator->is_counter()) {
|
|
builder.set_is_counter(true);
|
|
}
|
|
builder.set_default_validation_class(default_validator);
|
|
}
|
|
|
|
/*
|
|
* Determine whether or not the table is *really* dense
|
|
* We cannot trust is_dense value of true (see CASSANDRA-11502, that fixed the issue for 2.2 only, and not retroactively),
|
|
* but we can trust is_dense value of false.
|
|
*/
|
|
auto is_dense = td.get_opt<bool>("is_dense");
|
|
if (!is_dense || *is_dense) {
|
|
is_dense = [&] {
|
|
/*
|
|
* As said above, this method is only here because we need to deal with thrift upgrades.
|
|
* Once a CF has been "upgraded", i.e. we've rebuilt and save its CQL3 metadata at least once,
|
|
* then we'll have saved the "is_dense" value and will be good to go.
|
|
*
|
|
* But non-upgraded thrift CF (and pre-7744 CF) will have no value for "is_dense", so we need
|
|
* to infer that information without relying on it in that case. And for the most part this is
|
|
* easy, a CF that has at least one REGULAR definition is not dense. But the subtlety is that not
|
|
* having a REGULAR definition may not mean dense because of CQL3 definitions that have only the
|
|
* PRIMARY KEY defined.
|
|
*
|
|
* So we need to recognize those special case CQL3 table with only a primary key. If we have some
|
|
* clustering columns, we're fine as said above. So the only problem is that we cannot decide for
|
|
* sure if a CF without REGULAR columns nor CLUSTERING_COLUMN definition is meant to be dense, or if it
|
|
* has been created in CQL3 by say:
|
|
* CREATE TABLE test (k int PRIMARY KEY)
|
|
* in which case it should not be dense. However, we can limit our margin of error by assuming we are
|
|
* in the latter case only if the comparator is exactly CompositeType(UTF8Type).
|
|
*/
|
|
std::optional<column_id> max_cl_idx;
|
|
const cql3::untyped_result_set::row * regular = nullptr;
|
|
for (auto& row : *columns) {
|
|
auto kind_str = row.get_as<sstring>("type");
|
|
if (kind_str == "compact_value") {
|
|
continue;
|
|
}
|
|
|
|
auto kind = db::schema_tables::deserialize_kind(kind_str);
|
|
|
|
if (kind == column_kind::regular_column) {
|
|
if (regular != nullptr) {
|
|
return false;
|
|
}
|
|
regular = &row;
|
|
continue;
|
|
}
|
|
if (kind == column_kind::clustering_key) {
|
|
max_cl_idx = std::max(column_id(row.get_or("component_index", 0)), max_cl_idx.value_or(column_id()));
|
|
}
|
|
}
|
|
|
|
auto is_cql3_only_pk_comparator = [](const sstring& comparator) {
|
|
if (!cell_comparator::check_compound(comparator)) {
|
|
return false;
|
|
}
|
|
// CMH. We don't have composites, nor a parser for it. This is a simple way of c
|
|
// checking the same.
|
|
auto comma = comparator.find(',');
|
|
if (comma != sstring::npos) {
|
|
return false;
|
|
}
|
|
auto off = comparator.find('(');
|
|
auto end = comparator.find(')');
|
|
|
|
return comparator.compare(off, end - off, utf8_type->name()) == 0;
|
|
};
|
|
|
|
if (max_cl_idx) {
|
|
auto n = std::count(comparator.begin(), comparator.end(), ','); // num comp - 1
|
|
return *max_cl_idx == n;
|
|
}
|
|
|
|
if (regular) {
|
|
return false;
|
|
}
|
|
|
|
return !is_cql3_only_pk_comparator(comparator);
|
|
|
|
}();
|
|
|
|
// now, if switched to sparse, remove redundant compact_value column and the last clustering column,
|
|
// directly copying CASSANDRA-11502 logic. See CASSANDRA-11315.
|
|
|
|
filter_sparse = !*is_dense;
|
|
}
|
|
builder.set_is_dense(*is_dense);
|
|
|
|
auto is_cql = !*is_dense && is_compound;
|
|
auto is_static_compact = !*is_dense && !is_compound;
|
|
|
|
// org.apache.cassandra.schema.LegacySchemaMigrator#isEmptyCompactValueColumn
|
|
auto is_empty_compact_value = [](const cql3::untyped_result_set::row& column_row) {
|
|
auto kind_str = column_row.get_as<sstring>("type");
|
|
// Cassandra only checks for "compact_value", but Scylla generates "regular" instead (#2586)
|
|
return (kind_str == "compact_value" || kind_str == "regular")
|
|
&& column_row.get_as<sstring>("column_name").empty();
|
|
};
|
|
|
|
for (auto& row : *columns) {
|
|
auto kind_str = row.get_as<sstring>("type");
|
|
auto kind = db::schema_tables::deserialize_kind(kind_str);
|
|
auto component_index = kind > column_kind::clustering_key ? 0 : column_id(row.get_or("component_index", 0));
|
|
auto name = row.get_or<sstring>("column_name", sstring());
|
|
auto validator = db::schema_tables::parse_type(row.get_as<sstring>("validator"));
|
|
|
|
if (is_empty_compact_value(row)) {
|
|
continue;
|
|
}
|
|
|
|
if (filter_sparse) {
|
|
if (kind_str == "compact_value") {
|
|
continue;
|
|
}
|
|
if (kind == column_kind::clustering_key) {
|
|
if (cf == cf_type::super && component_index != 0) {
|
|
continue;
|
|
}
|
|
if (cf != cf_type::super && !is_compound) {
|
|
continue;
|
|
}
|
|
}
|
|
}
|
|
|
|
std::optional<index_metadata_kind> index_kind;
|
|
sstring index_name;
|
|
index_options_map options;
|
|
if (row.has("index_type")) {
|
|
index_kind = schema_tables::deserialize_index_kind(row.get_as<sstring>("index_type"));
|
|
}
|
|
if (row.has("index_name")) {
|
|
index_name = row.get_as<sstring>("index_name");
|
|
}
|
|
if (row.has("index_options")) {
|
|
sstring index_options_str = row.get_as<sstring>("index_options");
|
|
options = rjson::parse_to_map<index_options_map>(std::string_view(index_options_str));
|
|
sstring type;
|
|
auto i = options.find("index_keys");
|
|
if (i != options.end()) {
|
|
options.erase(i);
|
|
type = "KEYS";
|
|
}
|
|
i = options.find("index_keys_and_values");
|
|
if (i != options.end()) {
|
|
options.erase(i);
|
|
type = "KEYS_AND_VALUES";
|
|
}
|
|
if (type.empty()) {
|
|
if (validator->is_collection() && validator->is_multi_cell()) {
|
|
type = "FULL";
|
|
} else {
|
|
type = "VALUES";
|
|
}
|
|
}
|
|
auto column = cql3::util::maybe_quote(name);
|
|
options["target"] = validator->is_collection()
|
|
? type + "(" + column + ")"
|
|
: column;
|
|
}
|
|
if (index_kind) {
|
|
// Origin assumes index_name is always set, so let's do the same
|
|
builder.with_index(index_metadata(index_name, options, *index_kind, index_metadata::is_local_index::no));
|
|
}
|
|
|
|
data_type column_name_type = [&] {
|
|
if (is_static_compact && kind == column_kind::regular_column) {
|
|
return db::schema_tables::parse_type(comparator);
|
|
}
|
|
return utf8_type;
|
|
}();
|
|
auto column_name = [&] {
|
|
try {
|
|
return column_name_type->from_string(name);
|
|
} catch (marshal_exception&) {
|
|
// #2597: Scylla < 2.0 writes names in serialized form, try to recover
|
|
column_name_type->validate(to_bytes_view(name));
|
|
return to_bytes(name);
|
|
}
|
|
}();
|
|
builder.with_column_ordered(column_definition(std::move(column_name), std::move(validator), kind, component_index));
|
|
}
|
|
|
|
if (is_static_compact) {
|
|
builder.set_regular_column_name_type(db::schema_tables::parse_type(comparator));
|
|
}
|
|
|
|
if (td.has("gc_grace_seconds")) {
|
|
builder.set_gc_grace_seconds(td.get_as<int32_t>("gc_grace_seconds"));
|
|
}
|
|
if (td.has("min_compaction_threshold")) {
|
|
builder.set_min_compaction_threshold(td.get_as<int32_t>("min_compaction_threshold"));
|
|
}
|
|
if (td.has("max_compaction_threshold")) {
|
|
builder.set_max_compaction_threshold(td.get_as<int32_t>("max_compaction_threshold"));
|
|
}
|
|
if (td.has("comment")) {
|
|
builder.set_comment(td.get_as<sstring>("comment"));
|
|
}
|
|
if (td.has("memtable_flush_period_in_ms")) {
|
|
builder.set_memtable_flush_period(td.get_as<int32_t>("memtable_flush_period_in_ms"));
|
|
}
|
|
if (td.has("caching")) {
|
|
builder.set_caching_options(caching_options::from_sstring(td.get_as<sstring>("caching")));
|
|
}
|
|
if (td.has("default_time_to_live")) {
|
|
builder.set_default_time_to_live(gc_clock::duration(td.get_as<int32_t>("default_time_to_live")));
|
|
}
|
|
if (td.has("speculative_retry")) {
|
|
builder.set_speculative_retry(td.get_as<sstring>("speculative_retry"));
|
|
}
|
|
if (td.has("compaction_strategy_class")) {
|
|
auto strategy = td.get_as<sstring>("compaction_strategy_class");
|
|
try {
|
|
builder.set_compaction_strategy(sstables::compaction_strategy::type(strategy));
|
|
} catch (const exceptions::configuration_exception& e) {
|
|
// If compaction strategy class isn't supported, fallback to incremental.
|
|
mlogger.warn("Falling back to incremental compaction strategy after the problem: {}", e.what());
|
|
builder.set_compaction_strategy(sstables::compaction_strategy_type::incremental);
|
|
}
|
|
}
|
|
if (td.has("compaction_strategy_options")) {
|
|
sstring strategy_options_str = td.get_as<sstring>("compaction_strategy_options");
|
|
builder.set_compaction_strategy_options(rjson::parse_to_map<std::map<sstring, sstring>>(std::string_view(strategy_options_str)));
|
|
}
|
|
auto comp_param = td.get_as<sstring>("compression_parameters");
|
|
compression_parameters cp(rjson::parse_to_map<std::map<sstring, sstring>>(std::string_view(comp_param)));
|
|
builder.set_compressor_params(cp);
|
|
|
|
if (td.has("min_index_interval")) {
|
|
builder.set_min_index_interval(td.get_as<int32_t>("min_index_interval"));
|
|
} else if (td.has("index_interval")) { // compatibility
|
|
builder.set_min_index_interval(td.get_as<int32_t>("index_interval"));
|
|
}
|
|
if (td.has("max_index_interval")) {
|
|
builder.set_max_index_interval(td.get_as<int32_t>("max_index_interval"));
|
|
}
|
|
if (td.has("bloom_filter_fp_chance")) {
|
|
builder.set_bloom_filter_fp_chance(td.get_as<double>("bloom_filter_fp_chance"));
|
|
} else {
|
|
builder.set_bloom_filter_fp_chance(builder.get_bloom_filter_fp_chance());
|
|
}
|
|
if (td.has("dropped_columns")) {
|
|
auto map = td.get_map<sstring, int64_t>("dropped_columns");
|
|
for (auto&& e : map) {
|
|
builder.without_column(e.first, api::timestamp_type(e.second));
|
|
};
|
|
}
|
|
|
|
// ignore version. we're transient
|
|
if (!triggers->empty()) {
|
|
throw unsupported_feature("triggers");
|
|
}
|
|
|
|
dst.tables.emplace_back(table{timestamp, builder.build() });
|
|
});
|
|
}
|
|
|
|
future<> read_tables(keyspace& dst) {
|
|
auto query = fmt_query("SELECT columnfamily_name, writeTime(type) AS timestamp FROM {}.{} WHERE keyspace_name = ?",
|
|
db::system_keyspace::legacy::COLUMNFAMILIES);
|
|
return _qp.execute_internal(query, {dst.name}, cql3::query_processor::cache_internal::yes).then([this, &dst](result_set_type result) {
|
|
return parallel_for_each(*result, [this, &dst](row_type& row) {
|
|
return read_table(dst, row.get_as<sstring>("columnfamily_name"), row.get_as<time_point>("timestamp"));
|
|
}).finally([result] {});
|
|
});
|
|
}
|
|
|
|
future<time_point> read_type_timestamp(keyspace& dst, sstring type_name) {
|
|
// TODO: Unfortunately there is not a single REGULAR column in system.schema_usertypes, so annoyingly we cannot
|
|
// use the writeTime() CQL function, and must resort to a lower level.
|
|
// Origin digs up the actual cells of target partition and gets timestamp from there.
|
|
// We should do the same, but g-dam that's messy. Lets give back dung value for now.
|
|
return make_ready_future<time_point>(dst.timestamp);
|
|
}
|
|
|
|
future<> read_types(keyspace& dst) {
|
|
auto query = fmt_query("SELECT * FROM {}.{} WHERE keyspace_name = ?", db::system_keyspace::legacy::USERTYPES);
|
|
return _qp.execute_internal(query, {dst.name}, cql3::query_processor::cache_internal::yes).then([this, &dst](result_set_type result) {
|
|
return parallel_for_each(*result, [this, &dst](row_type& row) {
|
|
auto name = row.get_blob("type_name");
|
|
auto columns = row.get_list<bytes>("field_names");
|
|
auto types = row.get_list<sstring>("field_types");
|
|
std::vector<data_type> field_types;
|
|
for (auto&& value : types) {
|
|
field_types.emplace_back(db::schema_tables::parse_type(value));
|
|
}
|
|
auto ut = user_type_impl::get_instance(dst.name, name, columns, field_types, false);
|
|
return read_type_timestamp(dst, value_cast<sstring>(utf8_type->deserialize(name))).then([ut = std::move(ut), &dst](time_point timestamp) {
|
|
dst.types.emplace_back(type{timestamp, ut});
|
|
});
|
|
}).finally([result] {});
|
|
});
|
|
}
|
|
|
|
future<> read_functions(keyspace& dst) {
|
|
auto query = fmt_query("SELECT * FROM {}.{} WHERE keyspace_name = ?", db::system_keyspace::legacy::FUNCTIONS);
|
|
return _qp.execute_internal(query, {dst.name}, cql3::query_processor::cache_internal::yes).then([](result_set_type result) {
|
|
if (!result->empty()) {
|
|
throw unsupported_feature("functions");
|
|
}
|
|
});
|
|
}
|
|
|
|
future<> read_aggregates(keyspace& dst) {
|
|
auto query = fmt_query("SELECT * FROM {}.{} WHERE keyspace_name = ?", db::system_keyspace::legacy::AGGREGATES);
|
|
return _qp.execute_internal(query, {dst.name}, cql3::query_processor::cache_internal::yes).then([](result_set_type result) {
|
|
if (!result->empty()) {
|
|
throw unsupported_feature("aggregates");
|
|
}
|
|
});
|
|
}
|
|
|
|
future<keyspace> read_keyspace(sstring ks_name, bool durable_writes, sstring strategy_class, sstring strategy_options, time_point timestamp) {
|
|
auto map = rjson::parse_to_map<std::map<sstring, sstring>>(std::string_view(strategy_options));
|
|
map.emplace("class", std::move(strategy_class));
|
|
auto ks = ::make_lw_shared<keyspace>(keyspace{timestamp, std::move(ks_name), durable_writes, std::move(map) });
|
|
|
|
return read_tables(*ks).then([this, ks] {
|
|
//Collection<Type> types = readTypes(keyspaceName);
|
|
return read_types(*ks);
|
|
}).then([this, ks] {
|
|
return read_functions(*ks);
|
|
}).then([this, ks] {
|
|
return read_aggregates(*ks);
|
|
}).then([ks] {
|
|
return make_ready_future<keyspace>(std::move(*ks));
|
|
});
|
|
}
|
|
|
|
future<> read_all_keyspaces() {
|
|
static auto ks_filter = [](row_type& row) {
|
|
auto ks_name = row.get_as<sstring>("keyspace_name");
|
|
return ks_name != db::system_keyspace::NAME && ks_name != db::schema_tables::v3::NAME;
|
|
};
|
|
|
|
auto query = fmt_query("SELECT keyspace_name, durable_writes, strategy_options, strategy_class, writeTime(durable_writes) AS timestamp FROM {}.{}",
|
|
db::system_keyspace::legacy::KEYSPACES);
|
|
|
|
return _qp.execute_internal(query, cql3::query_processor::cache_internal::yes).then([this](result_set_type result) {
|
|
auto i = boost::make_filter_iterator(ks_filter, result->begin(), result->end());
|
|
auto e = boost::make_filter_iterator(ks_filter, result->end(), result->end());
|
|
return parallel_for_each(i, e, [this](row_type& row) {
|
|
return read_keyspace(row.get_as<sstring>("keyspace_name")
|
|
, row.get_as<bool>("durable_writes")
|
|
, row.get_as<sstring>("strategy_class")
|
|
, row.get_as<sstring>("strategy_options")
|
|
, row.get_as<db_clock::time_point>("timestamp")
|
|
).then([this](keyspace ks) {
|
|
_keyspaces.emplace_back(std::move(ks));
|
|
});
|
|
}).finally([result] {});
|
|
});
|
|
}
|
|
|
|
future<> drop_legacy_tables() {
|
|
mlogger.info("Dropping legacy schema tables");
|
|
auto with_snapshot = !_keyspaces.empty();
|
|
return parallel_for_each(legacy_schema_tables, [this, with_snapshot](const sstring& cfname) {
|
|
return replica::database::drop_table_on_all_shards(_db, _sys_ks, db::system_keyspace::NAME, cfname, with_snapshot);
|
|
});
|
|
}
|
|
|
|
future<> store_keyspaces_in_new_schema_tables() {
|
|
mlogger.info("Moving {} keyspaces from legacy schema tables to the new schema keyspace ({})",
|
|
_keyspaces.size(), db::schema_tables::v3::NAME);
|
|
|
|
std::vector<mutation> mutations;
|
|
|
|
for (auto& ks : _keyspaces) {
|
|
auto ksm = ::make_lw_shared<keyspace_metadata>(ks.name
|
|
, ks.replication_params["class"] // TODO, make ksm like c3?
|
|
, ks.replication_params
|
|
, std::nullopt
|
|
, ks.durable_writes);
|
|
|
|
// we want separate time stamps for tables/types, so cannot bulk them into the ksm.
|
|
for (auto&& m : db::schema_tables::make_create_keyspace_mutations(schema_features::full(), ksm, ks.timestamp.time_since_epoch().count(), false)) {
|
|
mutations.emplace_back(std::move(m));
|
|
}
|
|
for (auto& t : ks.tables) {
|
|
db::schema_tables::add_table_or_view_to_schema_mutation(t.metadata, t.timestamp.time_since_epoch().count(), true, mutations);
|
|
}
|
|
for (auto& t : ks.types) {
|
|
db::schema_tables::add_type_to_schema_mutation(t.metadata, t.timestamp.time_since_epoch().count(), mutations);
|
|
}
|
|
}
|
|
return _qp.proxy().mutate_locally(std::move(mutations), tracing::trace_state_ptr());
|
|
}
|
|
|
|
future<> flush_schemas() {
|
|
auto& db = _qp.db().real_database().container();
|
|
return replica::database::flush_tables_on_all_shards(db, db::schema_tables::NAME, db::schema_tables::all_table_names(schema_features::full()));
|
|
}
|
|
|
|
future<> migrate() {
|
|
return read_all_keyspaces().then([this]() {
|
|
// write metadata to the new schema tables
|
|
return store_keyspaces_in_new_schema_tables()
|
|
.then(std::bind(&migrator::flush_schemas, this))
|
|
.then(std::bind(&migrator::drop_legacy_tables, this))
|
|
.then([] { mlogger.info("Completed migration of legacy schema tables"); });
|
|
});
|
|
}
|
|
|
|
sharded<service::storage_proxy>& _sp;
|
|
sharded<replica::database>& _db;
|
|
sharded<db::system_keyspace>& _sys_ks;
|
|
cql3::query_processor& _qp;
|
|
std::vector<keyspace> _keyspaces;
|
|
};
|
|
|
|
const std::unordered_set<sstring> migrator::legacy_schema_tables = {
|
|
db::system_keyspace::legacy::KEYSPACES,
|
|
db::system_keyspace::legacy::COLUMNFAMILIES,
|
|
db::system_keyspace::legacy::COLUMNS,
|
|
db::system_keyspace::legacy::TRIGGERS,
|
|
db::system_keyspace::legacy::USERTYPES,
|
|
db::system_keyspace::legacy::FUNCTIONS,
|
|
db::system_keyspace::legacy::AGGREGATES,
|
|
};
|
|
|
|
}
|
|
}
|
|
|
|
future<>
|
|
db::legacy_schema_migrator::migrate(sharded<service::storage_proxy>& sp, sharded<replica::database>& db, sharded<db::system_keyspace>& sys_ks, cql3::query_processor& qp) {
|
|
return do_with(migrator(sp, db, sys_ks, qp), std::bind(&migrator::migrate, std::placeholders::_1));
|
|
}
|
|
|